| title | Detailed Explanation of the Raft Algorithm | ||
|---|---|---|---|
| category | Distributed Systems | ||
| tag |
|
This article is jointly completed by SnailClimb and Xieqijun.
Today’s data centers and applications operate in highly dynamic environments. To cope with such environments, they horizontally scale with additional servers and adjust resources based on demand. At the same time, server and network failures are quite common.
Therefore, systems must handle server ups and downs during normal operations. They must react to incidents and adapt automatically within seconds; significant interruptions are usually unacceptable for customers.
Fortunately, distributed consensus can help address these challenges.
Before introducing consensus algorithms, let's first present a simplified example of Byzantine generals to help understand the consensus algorithm.
Suppose there are multiple Byzantine generals with no traitors, and the messenger's information is reliable but may get assassinated. How can the generals reach a consensus on whether to attack?
The solution can be roughly understood as: first, select a general to be the Grand General among all the generals, who will make all the decisions.
For example, suppose there are 3 generals A, B, and C. Each general has a countdown timer that runs for a random time. Once the timer reaches zero, that general declares themselves a candidate for Grand General and sends messages to generals B and C with details of the election vote. If generals B and C have not declared themselves candidates (their countdowners have not expired) and have not voted for anyone else, they will vote for general A. When messenger returns to general A, they will know they have received enough votes to become the Grand General. With the Grand General in place, whether to attack will be determined by Grand General A, who will then inform the other two generals about it. If there is still no response from generals B and C after a period of time (the messenger may have been assassinated), a new messenger will be dispatched until a response is received.
Consensus is a fundamental problem in fault-tolerant systems: even in the presence of failures, servers must agree on a shared state.
Consensus algorithms allow a group of nodes to work together as a whole, ensuring that the system can continue to function even if some nodes fail. Its correctness primarily stems from the properties of replicated state machines: a set of Servers computes replicas of the same state machine, which can continue to operate even if part of the Servers goes down.
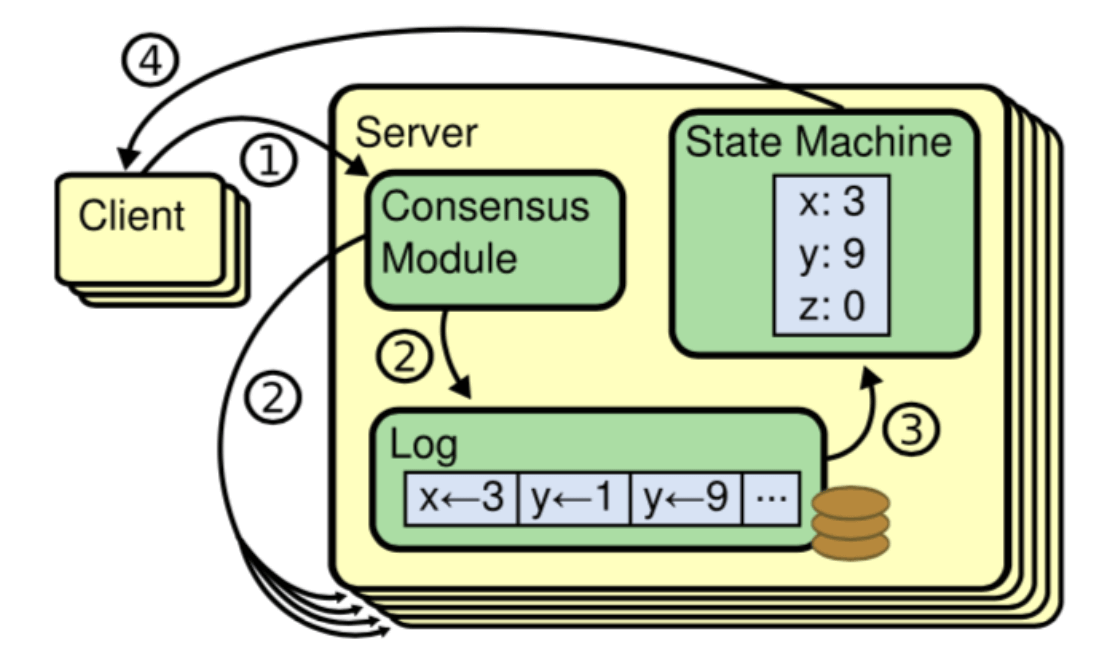
Figure 1: Replicated State Machine Architecture
Typically, replicated state machines are implemented using replicated logs. Each Server stores a log file that includes a sequence of commands; state machines execute these commands in order. Since each log contains the same commands executed in the same order, every state machine processes the same command sequence. As the state machine is deterministic, it produces the same output when processing the same state.
Thus, the job of the consensus algorithm is to maintain the consistency of the replicated logs. The consensus module on each server receives commands from clients and adds them to the log. It communicates with the consensus modules on other servers to ensure that all logs contain requests in the same order, even if some servers fail. Once commands are correctly replicated, they are said to be committed. The state machine of each server processes committed commands in log order and returns the output to the client; hence, these servers form a single, highly reliable state machine.
Consensus algorithms suitable for real systems typically have the following characteristics:
- Safety. Ensures safety under non-Byzantine conditions (i.e., the simplified version of Byzantine mentioned above), including network delays, partitions, packet losses, and message reordering.
- High availability. As long as a majority of servers are operational and can communicate with each other and with clients, these servers can be considered fully functional. Thus, a typical cluster of five servers can tolerate the failure of any two servers. If servers fail due to stoppage, they can later recover from stable storage and rejoin the cluster.
- Consistency does not depend on timing. Erroneous clocks and extreme message delays will only cause availability issues in the worst case and will not result in consistency problems.
- As long as the majority of servers respond in the cluster, commands can be completed without being affected by a few slow servers.
A Raft cluster consists of several servers. Taking a typical cluster of 5 servers as an example, at any given time, each server will be in one of the following three states:
Leader: Responsible for initiating heartbeats, responding to clients, creating logs, and synchronizing logs.Candidate: A temporary role during the leader election process, transformed from Follower, initiating votes to participate in the election.Follower: Accepts heartbeats and log synchronization data from the Leader, voting for the Candidate.
Under normal conditions, only one server is the Leader, while the remaining servers are Followers. Followers are passive; they do not send requests but only respond to requests from the Leader and Candidates.
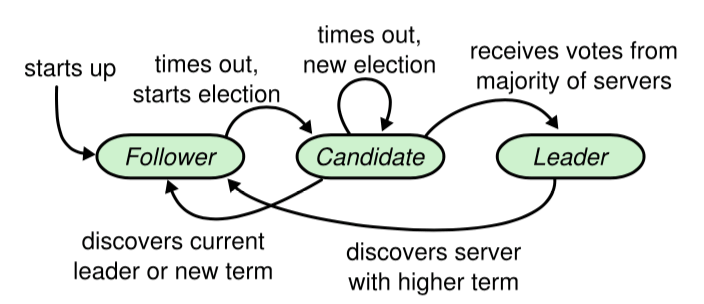
Figure 2: Server States
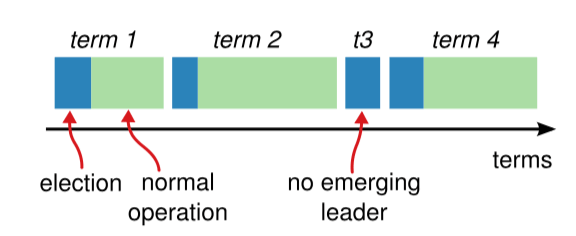
Figure 3: Terms
As shown in Figure 3, the Raft algorithm divides time into terms of arbitrary length, represented by consecutive numbers considered the current term number. The beginning of each term is an election; at the start of an election, one or more Candidates will attempt to become the Leader. If a Candidate wins the election, they will serve as the Leader for that term. If no Leader is elected, a new term will be initiated, and the next election will begin immediately. The Raft algorithm guarantees that there is at least one Leader in a given term.
Each node stores the current term number, and during communication between servers, they exchange their current term numbers. If a server finds its term number is smaller than others, it will update to the larger term value. If a Candidate or Leader finds its term has expired, it will revert to Follower immediately. If a server receives a request with an expired term number, it will reject the request.
entry: Each event becomes an entry, and only the Leader can create entries. The content of an entry is<term,index,cmd>where cmd is an operation that can be applied to the state machine.log: An array composed of entries, where each entry has an index indicating its position in the log. Only the Leader can change the logs of other nodes. Entries are always first added to the Leader's log array, and only after initiating a consensus request and obtaining agreement can they be committed to the state machine. Followers can only obtain new logs and the current commitIndex from the Leader and then apply the corresponding entries to their state machines.
Raft uses a heartbeat mechanism to trigger Leader elections.
If a server receives valid information from a Leader or Candidate, it will remain in the Follower state and refresh its electionElapsed timer.
The Leader periodically sends heartbeats to all Followers to ensure its leadership status. If a Follower does not receive heartbeat information within a cycle, it triggers an election timeout and assumes there is currently no available Leader, initiating an election to elect a new Leader.
To start a new election, the Follower increments its term number and changes its state to Candidate. It will then send a RequestVoteRPC to all nodes, and the Candidate's state will persist until one of the following occurs:
- Wins the election
- Other nodes win the election
- One round of the election ends with no winner
The condition for winning the election is: a Candidate must receive votes from a majority of the cluster (N/2+1) in one term to become the Leader.
While waiting for votes, a Candidate may receive heartbeat messages from other nodes claiming to be the Leader, resulting in two situations:
- The term number of that Leader is greater than or equal to its own; indicating that the other has become the Leader, it will revert to Follower.
- The term number of that Leader is less than its own. In this case, the request is rejected, prompting that node to update its term.
As multiple Candidates may appear simultaneously without any means to redistribute votes, it could lead to an infinite loop of elections.
Raft uses a random election timeout to avoid the above situation. Each Candidate randomizes a new election timeout after initiating an election, allowing servers to spread apart; in most cases, only one server will timeout first, winning the election before others do.
Once a Leader is elected, it starts receiving client requests. Each client's request includes a command that needs to be executed by the replicated state machine (Replicated State Machine).
After the Leader receives the client request, it generates an entry containing <index,term,cmd>, adds this entry to its log's end, and broadcasts it to all nodes, asking the other servers to replicate the entry.
If a Follower accepts the entry, it will append the entry to its log and return a consent response to the Leader.
If the Leader receives a majority of successful responses, it will apply this entry to its state machine, and this entry can then be termed as committed, eventually returning the execution result to the client.
Raft guarantees the following two properties:
- Among two logs, if two entries have the same index and term, their cmds must also be the same.
- Among two logs, if two entries have the same index and term, their preceding entries must also be the same.
The first property is guaranteed by "only the Leader can generate entries," while the second property requires consistency checks to ensure.
Generally, the logs of Leaders and Followers remain consistent; however, a Leader's crash may result in inconsistent logs, causing consistency checks to fail. The Leader handles log inconsistency by forcing Followers to replicate its logs, meaning any conflicting logs on Followers will be overwritten by the Leader's logs.
To ensure Followers' logs align with its own, the Leader must find the point of consistency in the Follower's log and delete any log entries after that point, then send the missing logs from that position onward to the Follower.
The Leader maintains a nextIndex for each Follower, representing the index of the next log entry that the Leader will send to that Follower. When a Leader begins authority, it initializes nextIndex to the number of its latest log entry index + 1. If a Follower's log is inconsistent with the Leader's, the consistency check in AppendEntries will return a failure in the next AppendEntries RPC. After a failure, the Leader decrements nextIndex and retries AppendEntries RPC. Eventually, nextIndex reaches a point of consistency between the Leader and Follower logs. At that point, AppendEntries succeeds, and any conflicting log entries on the Follower are removed, with the missing log entries appended from the Leader. Once AppendEntries succeeds, the logs of Follower and Leader are consistent, maintaining this state until the end of the term.
The Leader must ensure it stores all committed log entries. This assures that log entries have only one direction: from Leader to Follower; the Leader will never overwrite already existing log entries.
Every Candidate sends a RequestVoteRPC with information on the last entry. When all nodes receive the voting information, they compare this entry against their own updates; if they find their logs more up-to-date, they refuse to vote for that Candidate.
The way to determine the recency of logs: if the terms of the two logs differ, the log with the larger term updates; if the terms are the same, the longer index updates.
If the Leader crashes, nodes in the cluster that do not receive heartbeat information from the Leader within the electionTimeout period will trigger a new round of leader election, during which the entire cluster becomes unavailable to outside requests.
If Followers or Candidates crash, the process is much simpler. Subsequent RequestVoteRPCs and AppendEntriesRPCs sent to them will fail. Since all Raft requests are idempotent, failures will result in infinite retries. After recovery from a crash, they can receive new requests, choosing to append or reject entries.
One of Raft's requirements is that safety does not depend on time: the system cannot generate errors simply because some events occur faster or slower than expected. To ensure the above requirement, it is best to satisfy the following time conditions:
broadcastTime << electionTimeout << MTBF
broadcastTime: The average response time for concurrently sending messages to other nodes.electionTimeout: The timeout for elections.MTBF(mean time between failures): The average healthy uptime of a single machine.
broadcastTime should be an order of magnitude smaller than electionTimeout to allow the Leader to continually send heartbeat messages to prevent Follower from initiating elections.
electionTimeout should also be several orders smaller than MTBF to keep the system running stably. When Leader crashes, the system will be unavailable for approximately the entire duration of electionTimeout; we wish for this situation to occupy only a small part of the total time.
Since broadcastTime and MTBF are system-determined properties, it is necessary to set the duration of electionTimeout.
In general, broadcastTime is usually between 0.5-20ms, while electionTimeout can be set to 10-500ms, and MTBF is typically one to two months.