| title | Detailed Explanation of JMM (Java Memory Model) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| category | Java | ||||||||||||||
| tag |
|
||||||||||||||
| head |
|
JMM (Java Memory Model) mainly defines the visibility of a shared variable after another thread performs a write operation on that shared variable.
To thoroughly understand JMM (Java Memory Model), we first need to discuss CPU Cache Model and Instruction Reordering!
Why do we need a CPU cache? It is analogous to the cache we use in developing backend systems for websites (like Redis) to solve the disparity between the speed of program processing and the speed of accessing conventional relational databases. The CPU cache is designed to address the disparity between CPU processing speed and memory processing speed.
We can even think of memory as a high-speed cache for external storage. When a program runs, we copy data from external storage to memory, as the processing speed of memory is significantly higher than that of external storage, thus improving processing speed.
In summary: CPU Cache caches memory data to solve the mismatch between CPU processing speed and memory, while memory caches disk data to solve the problem of slow disk access speed.
To better understand, I have drawn a simple diagram of the CPU Cache as shown below.
🐛 Correction (see: issue#1848): Improvements have been made to the drawing of the CPU cache model.
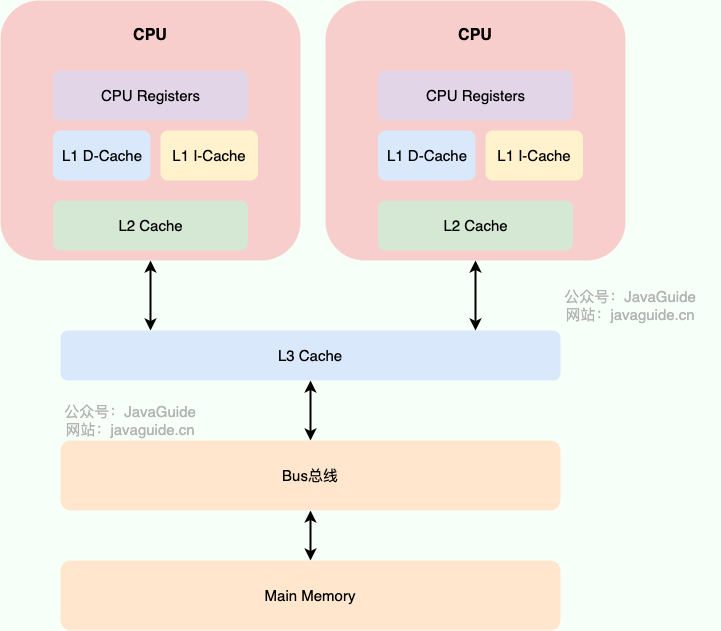
Modern CPU caches are typically divided into three levels: L1, L2, and L3 Cache. Some CPUs may also have L4 Cache, but this is not commonly discussed.
How CPU Cache Works: It first copies a piece of data into the CPU Cache. When the CPU needs to use it, it can read the data directly from the CPU Cache. After the computation is complete, the computed data is written back to Main Memory. However, this can lead to memory cache inconsistency issues! For example, if I perform an i++ operation and two threads execute it simultaneously, assuming both threads read i=1 from the CPU Cache, after both threads perform the i++ operation and write back to Main Memory, i=2, while the correct result should be i=3.
To solve the memory cache inconsistency problem, the CPU can establish cache coherence protocols (like the MESI protocol) or other means. This cache coherence protocol refers to the principles and norms that must be followed when interacting between the CPU cache and main memory. Different CPUs may use different cache coherence protocols.
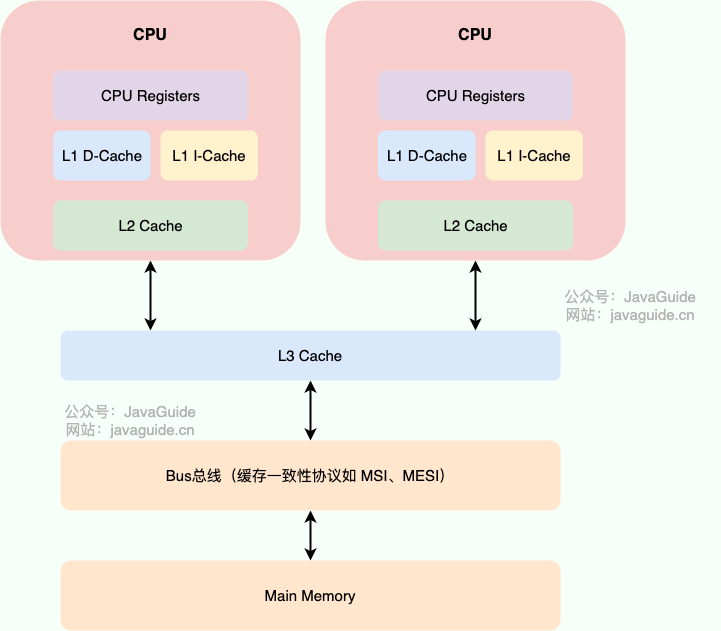
Our programs run on top of the operating system, which abstracts the operational details of the underlying hardware and virtualizes various hardware resources. Therefore, the operating system also needs to address the memory cache inconsistency problem.
The operating system defines a series of specifications through the Memory Model to solve this problem. Whether it is Windows or Linux, they both have specific memory models.
After discussing the CPU cache model, let's look at another important concept: Instruction Reordering.
To improve execution speed/performance, computers may reorder instructions when executing program code.
What is instruction reordering? Simply put, it means that the system does not necessarily execute the code in the order you wrote it.
Common types of instruction reordering include the following two situations:
- Compiler Optimization Reordering: The compiler (including JVM, JIT compiler, etc.) rearranges the execution order of statements without changing the semantics of single-threaded programs.
- Instruction-Level Parallelism Reordering: Modern processors use instruction-level parallelism (ILP) to overlap the execution of multiple instructions. If there are no data dependencies, the processor can change the execution order of the corresponding machine instructions.
Additionally, the memory system may also have "reordering," but it is not true reordering in the strict sense. In JMM, this manifests as inconsistencies between main memory and local memory, which can lead to issues when programs are