| title | Summary of Common Concurrent Containers in Java | |
|---|---|---|
| category | Java | |
| tag |
|
Most of the containers provided by the JDK are in the java.util.concurrent package.
ConcurrentHashMap: Thread-safeHashMapCopyOnWriteArrayList: Thread-safeList, performs very well in read-heavy scenarios, far better thanVector.ConcurrentLinkedQueue: Efficient concurrent queue implemented with a linked list. Can be seen as a thread-safeLinkedList, which is a non-blocking queue.BlockingQueue: This is an interface, implemented internally by the JDK using linked lists, arrays, etc. It represents a blocking queue, making it very suitable for use as a data-sharing channel.ConcurrentSkipListMap: An implementation of a skip list. This is a Map that uses skip list data structure for fast lookups.
We know that HashMap is thread-unsafe. In concurrent scenarios, a common solution is to wrap HashMap using Collections.synchronizedMap() to make it thread-safe. However, this approach synchronizes concurrent access between threads using a global lock, which can lead to severe performance bottlenecks, especially in high-concurrency situations.
To address this issue, ConcurrentHashMap was created as a thread-safe version of HashMap, providing more efficient concurrent processing capabilities.
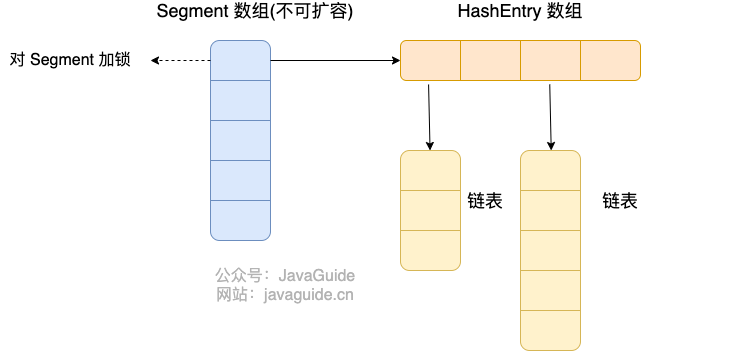
In JDK 1.7, ConcurrentHashMap split the entire bucket array into segments (Segment, segmented locks), where each lock only locks a portion of the data in the container (illustration below). Access to different data segments by multiple threads avoids lock contention, increasing the concurrent access rate.
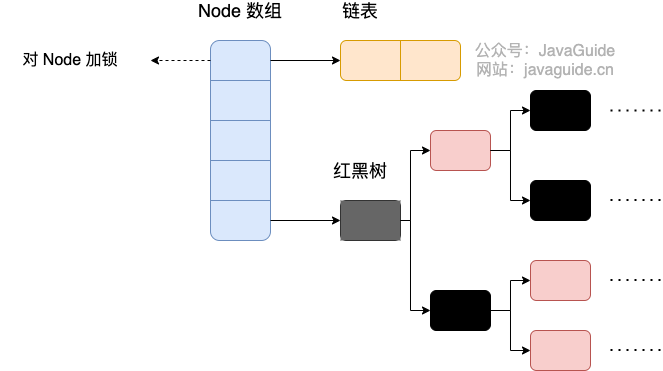
By JDK 1.8, ConcurrentHashMap abandoned the Segment locks and adopted Node + CAS + synchronized to ensure concurrent safety. The data structure is similar to that of HashMap 1.8, using an array combined with linked lists/red-black trees. In Java 8, when the length of a linked list exceeds a certain threshold (8), it converts the linked list (with a lookup time complexity of O(N)) into a red-black tree (with a lookup time complexity of O(log(N))).
In Java 8, the locking granularity is finer; synchronized only locks the head node of the current linked list or red-black tree. Therefore, as long as hashes do not collide, there will be no concurrency issues, and it will not affect the read and write of other nodes, significantly enhancing efficiency.
For a detailed introduction to ConcurrentHashMap, please refer to my article: ConcurrentHashMap Source Code Analysis.
Before JDK 1.5, the only option for a thread-safe List was Vector. However, Vector is an outdated collection and has been phased out. Vector essentially synchronized all methods like add, remove, etc. While this ensures synchronization, it effectively added a large lock to the entire Vector, requiring each method to acquire a lock to execute, which leads to significantly low performance.
JDK 1.5 introduced the Java.util.concurrent (JUC) package, which provides many thread-safe containers with good concurrent performance. The only thread-safe List implementation is CopyOnWriteArrayList.
In most business scenarios, read operations often far exceed write operations. Since read operations do not modify the original data, locking for each read is actually a waste of resources. Instead, we should allow multiple threads to access the internal data of the List simultaneously, as it is safe for read operations.
This concept is very similar to the design ideas of ReentrantReadWriteLock, where read-read operations do not interfere, read-write operations do, and write-write operations do (only read-read is non-blocking). CopyOnWriteArrayList takes this idea further. To maximize the performance of read operations, reading from CopyOnWriteArrayList does not require any locking. Even more impressively, write operations do not block read operations; only write operations will mutually exclude. This significantly enhances the performance of read operations.
The thread safety core of CopyOnWriteArrayList lies in its use of Copy-On-Write strategy, as indicated by its name.
When modifying the contents of CopyOnWriteArrayList (operations like add, set, remove), the original array is not directly modified. Instead, it first creates a copy of the underlying array, modifies the copied array, and then assigns the modified array back. This ensures that write operations do not affect read operations.
For a detailed introduction to CopyOnWriteArrayList, please refer to my article: CopyOnWriteArrayList Source Code Analysis.
Java provides thread-safe Queue, which can be divided into blocking queues and non-blocking queues, with BlockingQueue being a typical example of a blocking queue and ConcurrentLinkedQueue a typical example of a non-blocking queue. In practical applications, one must choose between blocking or non-blocking queues based on actual requirements. Blocking queues can be implemented with locks, while non-blocking queues can be implemented using CAS operations.
As the name suggests, ConcurrentLinkedQueue uses a linked list as its data structure. ConcurrentLinkedQueue is arguably the best-performing queue in high-concurrency environments. Its excellent performance results from its complex internal implementation.
We will not analyze the internal code of ConcurrentLinkedQueue; it suffices to know that it mainly uses CAS non-blocking algorithms to achieve thread safety.
ConcurrentLinkedQueue is suitable for scenarios requiring relatively high performance, where multiple threads simultaneously read from and write to the queue. If the cost of locking the queue is high, it is advisable to use the lock-free ConcurrentLinkedQueue as a replacement.
As mentioned above, ConcurrentLinkedQueue serves as a high-performance non-blocking queue. Now, we will discuss the blocking queue—BlockingQueue. The blocking queue (BlockingQueue) is widely used in the “producer-consumer” problem because it provides methods for inserting and removing elements that can block. When the queue container is full, the producer thread will be blocked until the queue is not full; when the queue is empty, the consumer thread will be blocked until the queue is non-empty.
BlockingQueue is an interface that extends Queue, so its implementation classes can also be used as implementations of Queue, and Queue extends the Collection interface. Here are some related implementation classes of BlockingQueue:
The following will primarily introduce three common implementations of BlockingQueue: ArrayBlockingQueue, LinkedBlockingQueue, and PriorityBlockingQueue.
ArrayBlockingQueue is a bounded queue implementation of the BlockingQueue interface, implemented using an array.
public class ArrayBlockingQueue<E>
extends AbstractQueue<E>
implements BlockingQueue<E>, Serializable{}Once ArrayBlockingQueue is created, its capacity cannot change. Concurrency control uses a reentrant lock (ReentrantLock), and both insert and read operations require acquiring the lock. When the queue is full, any attempt to add elements will block; similarly, attempting to remove an element from an empty queue will also block.
ArrayBlockingQueue does not guarantee the fairness of thread access to the queue by default. Fairness means that threads can access ArrayBlockingQueue in strict order of waiting time—meaning the first to wait can access ArrayBlockingQueue first. Non-fairness means that the order of access may not adhere to strict time order, potentially causing long-blocked threads to remain unable to access ArrayBlockingQueue when it is available. Ensuring fairness often reduces throughput. If fairness is required for ArrayBlockingQueue, it can be obtained with the following code:
private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);LinkedBlockingQueue is a blocking queue implemented based on a single linked list. It can be used as either an unbounded or a bounded queue while maintaining FIFO characteristics. Compared to ArrayBlockingQueue, it has higher throughput. To prevent LinkedBlockingQueue from rapidly increasing its capacity and consuming large amounts of memory, it typically specifies its size at the time of creation. If not specified, the capacity defaults to Integer.MAX_VALUE.
Related constructors:
/**
* Virtually an unbounded queue
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
/**
* Bounded queue
* Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
*
* @param capacity the capacity of this queue
* @throws IllegalArgumentException if {@code capacity} is not greater
* than zero
*/
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}PriorityBlockingQueue is an unbounded blocking queue that supports priorities. By default, the elements are sorted in their natural order; custom rules for sorting can be specified either by implementing the compareTo() method in a custom class or by providing a Comparator as a constructor argument.
PriorityBlockingQueue uses a reentrant lock (ReentrantLock) for concurrency control and is an unbounded queue (whereas ArrayBlockingQueue is a bounded queue, LinkedBlockingQueue can specify its maximum capacity using a capacity parameter in the constructor, but PriorityBlockingQueue can only set its initial queue size and will automatically resize when space is insufficient).
In simple terms, it is the thread-safe version of PriorityQueue. It does not allow inserting null values, and the objects inserted into the queue must be comparable; otherwise, a ClassCastException will be thrown. Its insertion operation (put method) will not block, as it is an unbounded queue (the take method will block when the queue is empty).
Recommended article: “Understanding Java Concurrent Queue BlockingQueue”
The following content references Geek Time column “The Beauty of Data Structures and Algorithms” and “Practical Java Concurrency Programming”.
To introduce ConcurrentSkipListMap, let's start with a brief understanding of skip lists.
For a singly linked list, even if it is ordered, finding a certain data point can only be done by traversing the list from beginning to end, which naturally is inefficient. Skip lists are different. They are a data structure designed for fast lookup, somewhat like balanced trees. Both allow for quick lookup of elements. However, a significant difference is that inserting and deleting in a balanced tree often requires a global adjustment of the tree, while operations on skip lists only require local modifications to the data structure. This provides the advantage that, in high concurrency, global locks are needed to ensure the thread safety of the entire balanced tree. For skip lists, only partial locks are necessary. Thus, in high concurrency environments, you can achieve better performance. Furthermore, with respect to lookup performance, the time complexity of skip lists is also O(logn), which is why the JDK uses skip lists to implement a Map.
The essence of skip lists is that they maintain multiple linked lists simultaneously, and these lists are hierarchical.
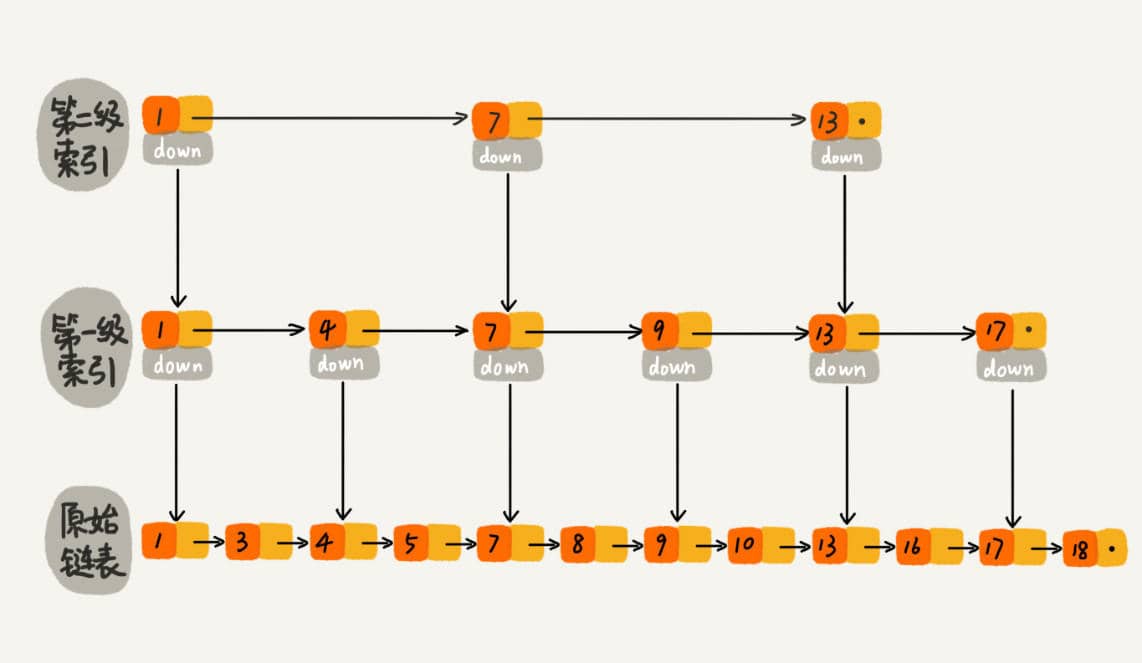
The lowest layer of the list maintains all elements within the skip list; each higher layer represents a subset of the layer below it.
All elements in the linked lists within a skip list are sorted. When searching, you can start from the top-level list. If the searched element is greater than the current list's value, you will move to the next lower level list to continue searching. This means that during the search process, it jumps through levels. For example, in searching for the element 18:
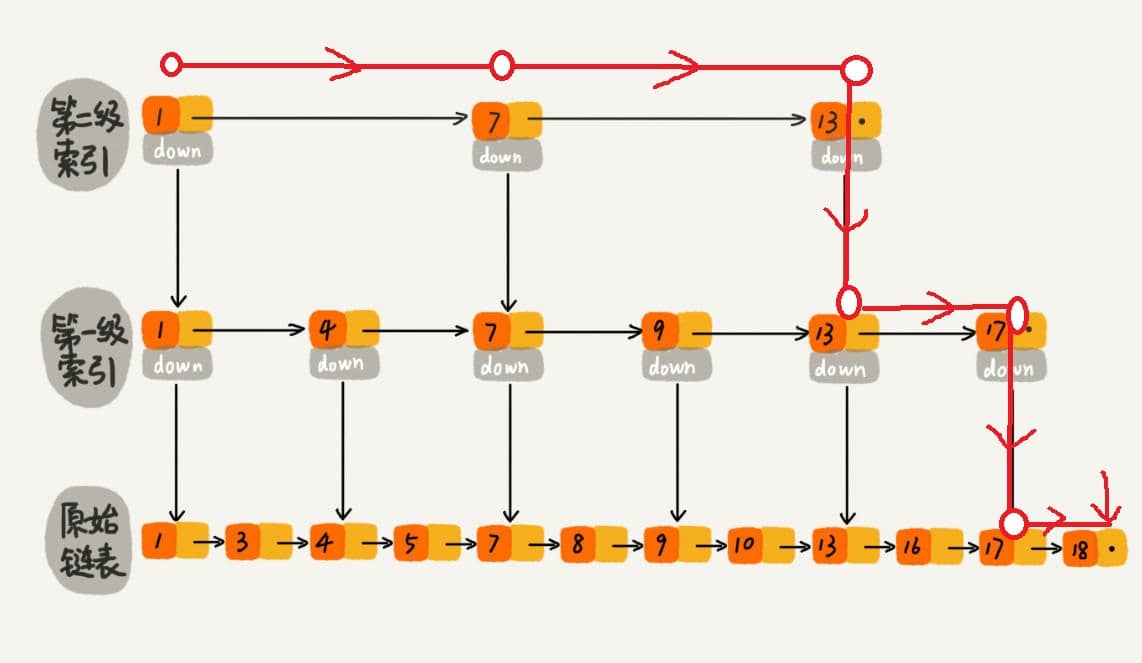
When searching for 18, it originally required traversing 18 times; now it only takes 7 times. When dealing with longer linked lists, the efficiency of constructing an index for lookups becomes significantly apparent.
It is easy to see that the skip list is an algorithm that trades space for time.
Using a skip list to implement Map differs from using hashing in that hashing does not preserve the order of elements, while all elements in a skip list are sorted. Therefore, traversing a skip list will yield an ordered result. If your application requires order, then a skip list is your best choice. The class that implements this data structure in the JDK is ConcurrentSkipListMap.
- “Practical Java Concurrency Programming”
- https://javadoop.com/post/java-concurrent-queue
- https://juejin.im/post/5aeebd02518825672f19c546