diff --git "a/docs/b-3Java\345\244\232\347\272\277\347\250\213.md" "b/docs/b-3Java\345\244\232\347\272\277\347\250\213.md"
index ce3bcb6..5ced96a 100755
--- "a/docs/b-3Java\345\244\232\347\272\277\347\250\213.md"
+++ "b/docs/b-3Java\345\244\232\347\272\277\347\250\213.md"
@@ -132,7 +132,7 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种

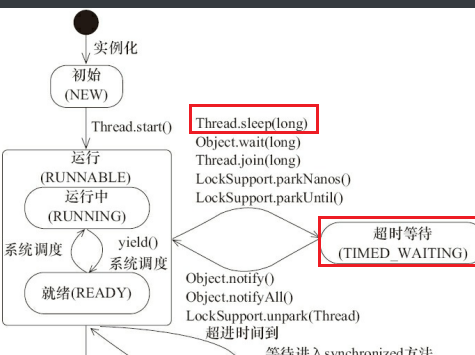
-当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)** 状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的`run()`方法之后将会进入到 **TERMINATED(终止)** 状态。
+当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)** 状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。**当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态**。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的`run()`方法之后将会进入到 **TERMINATED(终止)** 状态。
### 2.3.7. 什么是上下文切换?
@@ -142,7 +142,7 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
-Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
+Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
### 2.3.8. 什么是线程死锁?如何避免死锁?
@@ -204,6 +204,8 @@ Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
```
+
+
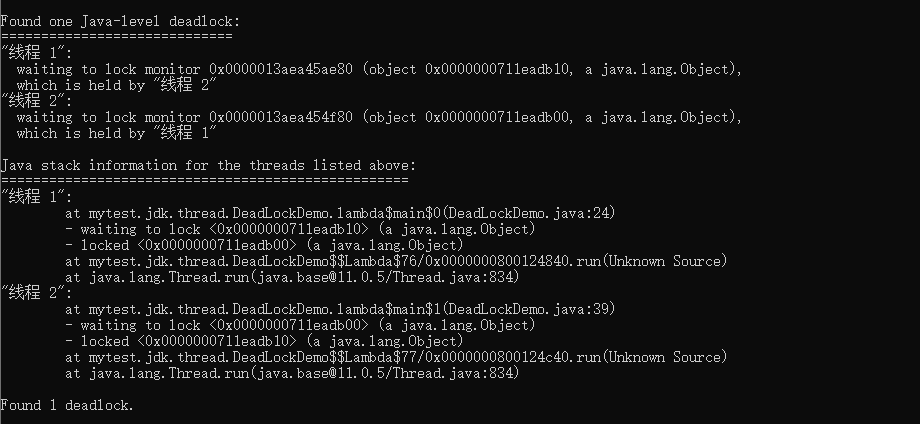
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。上面的例子符合产生死锁的四个必要条件。
学过操作系统的朋友都知道产生死锁必须具备以下四个条件:
@@ -222,7 +224,7 @@ Thread[线程 2,5,main]waiting get resource1
3. **破坏不剥夺条件** :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
4. **破坏循环等待条件** :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
-我们对线程 2 的代码修改成下面这样就不会产生死锁了。
+我们对线程 2 的代码修改成下面这样就不会产生死锁了。(不要形成闭环,破坏条件四)
```java
new Thread(() -> {
@@ -265,6 +267,14 @@ Process finished with exit code 0
- `wait()` 通常被用于线程间交互/通信,`sleep()`通常被用于暂停执行。
- `wait()` 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 `notify()`或者 `notifyAll()` 方法。`sleep()`方法执行完成后,线程会自动苏醒。或者可以使用 `wait(long timeout)` 超时后线程会自动苏醒。
+**问题:sleep()还是runnable吗?**
+
+相当于超时等待。
+
+
+
+
+
### 2.3.10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
@@ -428,6 +438,10 @@ public class SynchronizedDemo2 {
**不过两者的本质都是对对象监视器 monitor 的获取。**
+---
+
+
+
### 2.3.15. 为什么要弄一个 CPU 高速缓存呢?
类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
@@ -444,7 +458,7 @@ public class SynchronizedDemo2 {
先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
-**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
+CPU 为了解决内存缓存不一致性问题可以通过**制定缓存一致协议**或者其他手段来解决。
### 2.3.16. 讲一下 JMM(Java 内存模型)
@@ -526,6 +540,79 @@ ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {

+相当于一个ThreadLocal可以注册很多个Thread,然后就可以保存对应的值。
+
+```java
+public class ThreadLocalMapTest {
+ public static void main(String[] args) {
+ for (int i = 0; i < 10; i++) {
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ ThreadLocal