| title | MySQL查询缓存详解 | |||||||
|---|---|---|---|---|---|---|---|---|
| description | 深入解析MySQL查询缓存的工作原理、配置管理及其优缺点,分析为什么MySQL 8.0移除了查询缓存功能,以及生产环境中的最佳实践建议。 | |||||||
| category | 数据库 | |||||||
| tag |
|
|||||||
| head |
|
缓存是一个有效且实用的系统性能优化手段,无论是操作系统,还是各类应用软件与 Web 服务,均广泛采用了缓存机制。
然而,有经验的 DBA 都建议生产环境中把 MySQL 自带的 Query Cache(查询缓存)给关掉。而且,从 MySQL 5.7.20 开始,就已经默认弃用查询缓存了。在 MySQL 8.0 及之后,更是直接删除了查询缓存的功能。
这又是为什么呢?查询缓存真就这么鸡肋么?
带着如下几个问题,我们正式进入本文。
- MySQL 查询缓存是什么?适用范围?
- MySQL 缓存规则是什么?
- MySQL 缓存的优缺点是什么?
- MySQL 缓存对性能有什么影响?
MySQL 体系架构如下图所示:
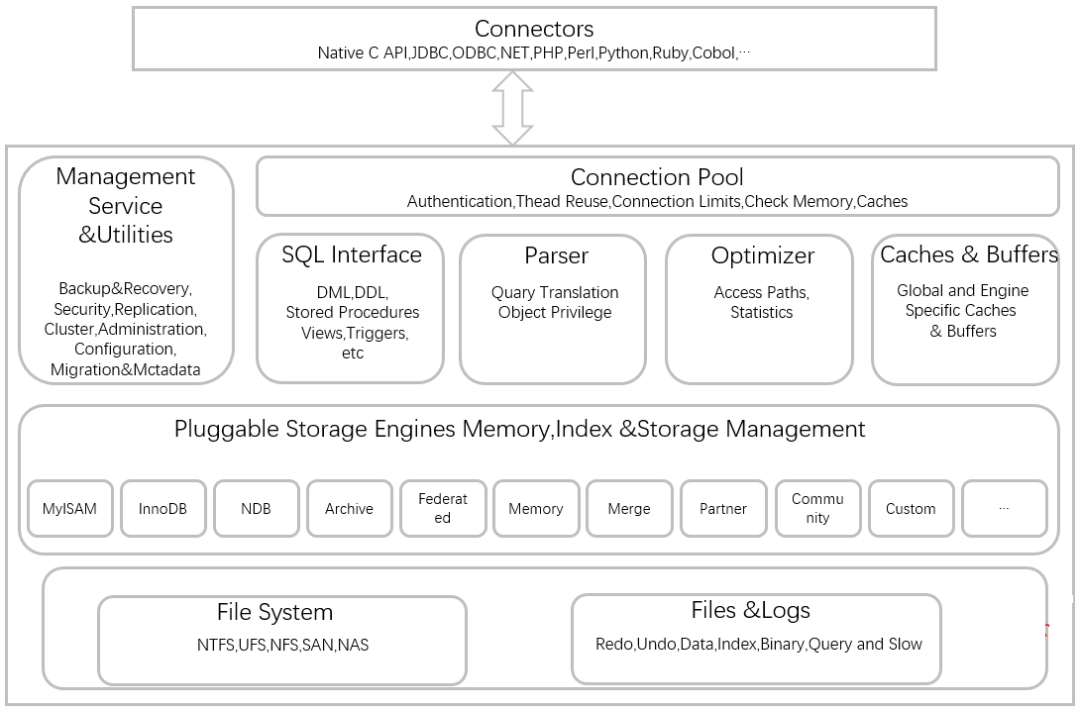
为了提高完全相同的查询语句的响应速度,MySQL Server 会对查询语句进行 Hash 计算得到一个 Hash 值。MySQL Server 不会对 SQL 做任何处理,SQL 必须完全一致 Hash 值才会一样。得到 Hash 值之后,通过该 Hash 值到查询缓存中匹配该查询的结果。
- 如果匹配(命中),则将查询的结果集直接返回给客户端,不必再解析、执行查询。
- 如果没有匹配(未命中),则将 Hash 值和结果集保存在查询缓存中,以便以后使用。
也就是说,一个查询语句(select)到了 MySQL Server 之后,会先到查询缓存看看,如果曾经执行过的话,就直接返回结果集给客户端。

通过 show variables like '%query_cache%'命令可以查看查询缓存相关的信息。
8.0 版本之前的话,打印的信息可能是下面这样的:
mysql> show variables like '%query_cache%';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| have_query_cache | YES |
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 599040 |
| query_cache_type | ON |
| query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
6 rows in set (0.02 sec)8.0 以及之后版本之后,打印的信息是下面这样的:
mysql> show variables like '%query_cache%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | NO |
+------------------+-------+
1 row in set (0.01 sec)我们这里对 8.0 版本之前show variables like '%query_cache%';命令打印出来的信息进行解释。
have_query_cache: 该 MySQL Server 是否支持查询缓存,如果是 YES 表示支持,否则表示不支持。query_cache_limit: MySQL 查询缓存的最大查询结果,查询结果大于该值时不会被缓存。query_cache_min_res_unit: 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过query_cache_min_res_unit的值,此时 MySQL 将在检索结果的同时保存数据,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节query_cache_min_res_unit可以优化内存。query_cache_size: 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。MySQL 5.7 官方文档显示默认值为1048576(1 MB),设置为 0 时禁用查询缓存。不同小版本的默认值存在差异,建议在配置文件中显式指定,不依赖默认行为。query_cache_type: 设置查询缓存类型,默认为 ON。设置 GLOBAL 值可以设置后面的所有客户端连接的类型。客户端可以设置 SESSION 值以影响他们自己对查询缓存的使用。query_cache_wlock_invalidate:如果某个表被锁住,是否返回缓存中的数据,默认处于关闭状态,生产环境通常建议保持此默认配置。
query_cache_type 可能的值(query_cache_type 在 MySQL 5.6/5.7 中是动态变量,但有前提:若实例启动时 query_cache_type=0,服务器会跳过查询缓存互斥锁的分配,此时通过 SET GLOBAL 动态修改将报错,必须修改配置文件并重启;若启动时非 0,则可通过 SET GLOBAL query_cache_type=N 在线生效,无需重启):
- 0 或 OFF:关闭查询功能。
- 1 或 ON:开启查询缓存功能,但不缓存
Select SQL_NO_CACHE开头的查询。 - 2 或 DEMAND:开启查询缓存功能,但仅缓存
Select SQL_CACHE开头的查询。
建议:
-
query_cache_size不建议设置得过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。 -
建议通过将
query_cache_size设置为 0 来禁用查询缓存,而非仅依赖query_cache_type。两者虽都是动态变量,但query_cache_size=0会完全跳过缓存内存分配和检查路径,禁用更彻底。8.0 版本之前,
my.cnf加入以下配置,重启 MySQL 开启查询缓存
query_cache_type=1
query_cache_size=614400或者,当实例启动时 query_cache_type 非 0 的情况下,也可以通过以下命令在线开启查询缓存(若启动值为 0 则该命令会报错,需修改配置文件后重启):
set global query_cache_type=1;
set global query_cache_size=614400;手动清理缓存可以使用下面三个 SQL:
flush query cache;:清理查询缓存内存碎片。reset query cache;:从查询缓存中移除所有查询。flush tables;关闭所有打开的表,同时该操作会清空查询缓存中的内容。
- 查询缓存会将查询语句和结果集保存到内存(一般是 key-value 的形式,其中 Key 是由查询语句文本、当前所在的 Database、客户端字符集以及协议版本等环境参数共同计算生成的 Hash 值,Value 则是查询的结果集),下次再查直接从内存中取。
- 缓存的结果是通过 sessions 共享的,所以一个 client 查询的缓存结果,另一个 client 也可以使用。
- SQL 必须完全一致才会导致查询缓存命中(大小写、空格、使用的数据库、协议版本、字符集等必须一致)。检查查询缓存时,MySQL Server 不会对 SQL 做任何处理,它精确地使用客户端传来的查询。
- 不缓存查询中的子查询结果集,仅缓存查询最终结果集。
- 不确定的函数将永远不会被缓存, 比如
now()、curdate()、last_insert_id()、rand()等。 - 不缓存产生告警(Warnings)的查询。
- 结果集超过
query_cache_limit(默认 1 MB)时不会被缓存。 - 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
- 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
- MySQL 缓存在分库分表环境下几乎不起作用。原因在于:查询通常经由中间件(如 ShardingSphere、MyCat)路由到不同的 MySQL 实例,各实例维护各自独立的 Query Cache;中间件在路由时往往会改写 SQL(添加分片键条件等),导致改写后的语句与原始语句 Hash 值不一致,缓存无法命中。
- 不缓存使用
SQL_NO_CACHE的查询。 - ……
查询缓存 SELECT 选项示例:
SELECT SQL_CACHE id, name FROM customer;# 会缓存
SELECT SQL_NO_CACHE id, name FROM customer;# 不会缓存查询缓存是完全存储在内存中的,所以在配置和使用它之前,我们需要先了解它是如何使用内存的。
MySQL 查询缓存使用内存池技术,自己管理内存释放和分配,而不是通过操作系统。内存池使用的基本单位是变长的 block, 用来存储类型、大小、数据等信息。一个结果集的缓存通过链表把这些 block 串起来。block 最短长度为 query_cache_min_res_unit。
当服务器启动的时候,会初始化缓存需要的内存,是一个完整的空闲块。当查询开始返回结果时,由于此时无法预知完整的结果集有多大,MySQL 会先向内存池申请一个大小为 query_cache_min_res_unit 的基础数据块。如果结果集超出该块容量,则会在生成结果的过程中持续按需申请新的数据块,并将其通过链表拼接起来。
分配内存块需要先锁住空间块,所以操作很慢,MySQL 会尽量避免这个操作,选择尽可能小的内存块,如果不够,继续申请,如果存储完时有空余则释放多余的。
随着并发读写的进行,不同大小的缓存块被无序且随机地释放,加上分配时剩余的微小空间(小于 query_cache_min_res_unit)无法被复用,内存池中会迅速产生大量不连续的空闲内存块(类似操作系统层面的外部碎片),进而触发更频繁的内存整理消耗。
优点:
- 查询缓存的查询,发生在 MySQL 接收到客户端的查询请求、查询权限验证之后和查询 SQL 解析之前。也就是说,当 MySQL 接收到客户端的查询 SQL 之后,仅仅只需要对其进行相应的权限验证之后,就会通过查询缓存来查找结果,甚至都不需要经过 Optimizer 模块进行执行计划的分析优化,更不需要发生任何存储引擎的交互。
- 由于查询缓存是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘 I/O 和 CPU 计算。但此优势仅在低并发且读多写少的静态场景下成立;在多核高并发环境下,
LOCK_query_cache全局互斥锁的激烈竞争会导致大量线程处于等锁状态(可通过SHOW PROCESSLIST看到Waiting for query cache lock),实际 TPS/QPS 反而大幅下降。
缺点:
- MySQL 会对每条接收到的 SELECT 类型的查询进行 Hash 计算,然后查找这个查询的缓存结果是否存在。虽然 Hash 计算和查找本身的 CPU 开销微乎其微,但 Query Cache 底层依赖单一全局互斥锁(
LOCK_query_cache)来保证并发安全。一旦涉及到高并发,成千上万条查询语句同时争抢该互斥锁进行缓存检查或写入,极其激烈的锁冲突和线程上下文切换开销将成为致命的性能瓶颈。 - 查询缓存的失效问题。如果表的变更比较频繁,则会造成查询缓存的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
- 查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,查询缓存都会认为是不同的查询(因为他们的 Hash 值会不同)。
- 相关系统变量设置不合理会造成大量的内存碎片,这样便会导致查询缓存频繁清理内存。
在 MySQL Server 中打开查询缓存对数据库的读和写都会带来额外的消耗:
- 读操作需持锁检查:读查询开始前必须检查缓存命中,这需要获取
LOCK_query_cache共享锁。高并发下,大量读请求同时争抢锁会形成排队。 - 缓存写入开销:若读查询可缓存,执行后需将结果写入缓存,涉及内存分配和链表拼接操作,同样需要持有锁。
- 写操作触发全局失效:向表写入数据时,必须使该表所有缓存失效。这需要获取独占锁扫描整个缓存区,
query_cache_size越大持锁时间越长。Query Cache 的单一全局互斥锁设计导致写操作会阻塞所有其他读写请求,这也是 MySQL 8.0 移除它的首要原因。 - InnoDB 长事务加剧问题:MVCC 特性下,事务提交前相关缓存无法使用。长事务不仅降低缓存命中率,写操作触发的独占锁还会阻塞对其他不相关表的缓存读取。
可以通过以下命令查看查询缓存的使用情况,判断是否值得开启:
SHOW STATUS LIKE 'Qcache%';关键指标说明:
| 状态变量 | 含义 |
|---|---|
Qcache_hits |
缓存命中次数 |
Qcache_inserts |
写入缓存的查询次数 |
Qcache_not_cached |
未被缓存的查询次数(不可缓存或未命中) |
Qcache_lowmem_prunes |
因内存不足而被淘汰的缓存条目数,持续升高说明缓存空间不足或碎片严重 |
Qcache_free_memory |
缓存剩余空闲内存(字节) |
命中率参考公式:
命中率 = Qcache_hits / (Qcache_hits + Qcache_inserts + Qcache_not_cached)
若命中率长期低于 50%,说明工作负载不适合 Query Cache,建议关闭。此外,还需关注 Qcache_lowmem_prunes 与 Qcache_inserts 的比值:若比值极高,意味着刚写入缓存的数据很快因内存碎片或空间不足被剔除,此时开启缓存是纯负收益。Qcache_lowmem_prunes 持续增长时,可执行 FLUSH QUERY CACHE 整理内存碎片,或适当降低 query_cache_min_res_unit 的值。
MySQL 中的查询缓存虽然能够提升数据库的查询性能,但查询缓存机制本身也引入了额外的管理开销,每次查询后都要做一次缓存操作,失效后还要销毁。
查询缓存是一个适用较少情况的缓存机制。如果你的应用对数据库的更新很少,那么查询缓存将会作用显著。比较典型的如博客系统,一般博客更新相对较慢,数据表相对稳定不变,这时候查询缓存的作用会比较明显。
简单总结一下查询缓存的适用场景:
- 表数据修改不频繁、数据较静态。
- 查询(Select)重复度高。
- 查询结果集小于 1 MB。
对于一个更新频繁的系统来说,查询缓存的作用是很微小的,在某些情况下开启查询缓存会带来性能的下降。
简单总结一下查询缓存不适用的场景:
- 表中的数据、表结构或者索引变动频繁
- 重复的查询很少
- 查询的结果集很大
《高性能 MySQL》这样写到:
根据我们的经验,在高并发压力环境中查询缓存会导致系统性能的下降,甚至僵死。如果你一 定要使用查询缓存,那么不要设置太大内存,而且只有在明确收益的时候才使用(数据库内容修改次数较少)。
确实是这样的!实际项目中,更建议使用本地缓存(比如 Caffeine)或者分布式缓存(比如 Redis) ,性能更好,更通用一些。
- 《高性能 MySQL》
- MySQL 缓存机制:https://zhuanlan.zhihu.com/p/55947158
- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:https://help.aliyun.com/document_detail/41717.html
- 8.10.3 The MySQL Query Cache - MySQL 官方文档:https://dev.mysql.com/doc/refman/5.7/en/query-cache.html