 -
\ No newline at end of file
+
diff --git a/docs/database/redis/redis-cluster.md b/docs/database/redis/redis-cluster.md
index 73224676af0..a8e93bd0f2c 100644
--- a/docs/database/redis/redis-cluster.md
+++ b/docs/database/redis/redis-cluster.md
@@ -9,7 +9,6 @@ tag:
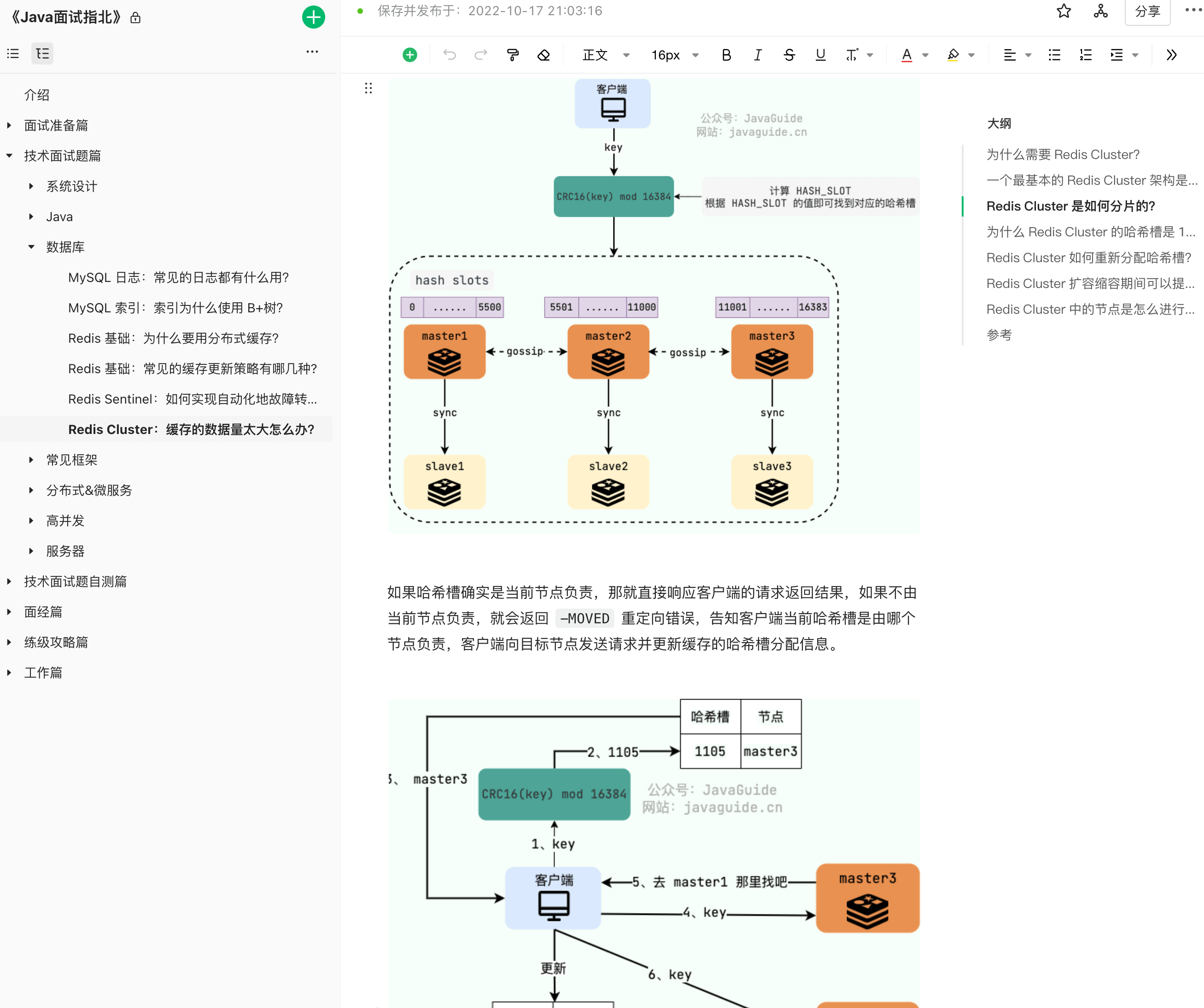
-
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn) 的补充完善,两者可以配合使用。

@@ -52,4 +51,4 @@ tag:
-
\ No newline at end of file
+
diff --git a/docs/database/redis/redis-common-blocking-problems-summary.md b/docs/database/redis/redis-common-blocking-problems-summary.md
index a601bdf7d07..6249c42e78c 100644
--- a/docs/database/redis/redis-common-blocking-problems-summary.md
+++ b/docs/database/redis/redis-common-blocking-problems-summary.md
@@ -5,7 +5,7 @@ tag:
- Redis
---
-> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿Q说代码
+> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿 Q 说代码
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
@@ -54,7 +54,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
-关于 AOF 工作流程的详细介绍可以查看:[Redis持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
+关于 AOF 工作流程的详细介绍可以查看:[Redis 持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
### AOF 重写阻塞
@@ -64,7 +64,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生**阻塞**。
-相关阅读:[Redis AOF重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
+相关阅读:[Redis AOF 重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
## 大 Key
@@ -111,13 +111,13 @@ Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处
## Swap(内存交换)
-什么是 Swap?Swap 直译过来是交换的意思,Linux中的Swap常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
+什么是 Swap?Swap 直译过来是交换的意思,Linux 中的 Swap 常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
-Swap 对于Redis来说是非常致命的,Redis保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把Redis使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的Redis性能急剧下降。
+Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的 Redis 性能急剧下降。
识别 Redis 发生 Swap 的检查方法如下:
-1、查询Redis进程号
+1、查询 Redis 进程号
```bash
reids-cli -p 6383 info server | grep process_id
@@ -136,19 +136,19 @@ Swap: 0kB
.....
```
-如果交换量都是0KB或者个别的是4KB,则正常。
+如果交换量都是 0KB 或者个别的是 4KB,则正常。
预防内存交换的方法:
- 保证机器充足的可用内存
-- 确保所有Redis实例设置最大可用内存(maxmemory),防止极端情况Redis内存不可控的增长
-- 降低系统使用swap优先级,如`echo 10 > /proc/sys/vm/swappiness`
+- 确保所有 Redis 实例设置最大可用内存(maxmemory),防止极端情况 Redis 内存不可控的增长
+- 降低系统使用 swap 优先级,如`echo 10 > /proc/sys/vm/swappiness`
## CPU 竞争
-Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务部署在一起。当其他进程过度消耗CPU时,将严重影响Redis的吞吐量。
+Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
-可以通过`reids-cli --stat`获取当前Redis使用情况。通过`top`命令获取进程对CPU的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
+可以通过`reids-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
## 网络问题
@@ -156,5 +156,5 @@ Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务
## 参考
-- Redis阻塞的6大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
-- Redis开发与运维笔记-Redis的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
+- Redis 阻塞的 6 大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
+- Redis 开发与运维笔记-Redis 的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index a3d0afdd9fe..1d2eb28b262 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -387,17 +387,17 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
### 常用命令
-| 命令 | 介绍 |
-| --------------------------------------------- | ------------------------------------------------------------ |
-| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
-| ZCARD KEY | 获取指定有序集合的元素数量 |
-| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
+| 命令 | 介绍 |
+| --------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
+| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
+| ZCARD KEY | 获取指定有序集合的元素数量 |
+| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
| ZINTERSTORE destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
-| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
-| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
-| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
-| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
-| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
+| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
+| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
+| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
+| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
+| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=sorted-set 。
diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 864197cdace..8332c304689 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -26,11 +26,11 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
### 常用命令
-| 命令 | 介绍 |
-| ------------------------------------- | ------------------------------------------------------------ |
-| SETBIT key offset value | 设置指定 offset 位置的值 |
-| GETBIT key offset | 获取指定 offset 位置的值 |
-| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
+| 命令 | 介绍 |
+| ------------------------------------- | ---------------------------------------------------------------- |
+| SETBIT key offset value | 设置指定 offset 位置的值 |
+| GETBIT key offset | 获取指定 offset 位置的值 |
+| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
**Bitmap 基本操作演示** :
@@ -86,10 +86,10 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
-| 命令 | 介绍 |
-| ----------------------------------------- | ------------------------------------------------------------ |
-| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
-| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
+| 命令 | 介绍 |
+| ----------------------------------------- | -------------------------------------------------------------------------------- |
+| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
+| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
**HyperLogLog 基本操作演示** :
@@ -132,13 +132,13 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
### 常用命令
-| 命令 | 介绍 |
-| ------------------------------------------------ | ------------------------------------------------------------ |
-| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
-| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
-| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
+| 命令 | 介绍 |
+| ------------------------------------------------ | ---------------------------------------------------------------------------------------------------- |
+| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
+| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
+| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
-| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
+| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
**基本操作** :
@@ -205,4 +205,4 @@ user2
- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
-- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
\ No newline at end of file
+- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
diff --git a/docs/database/redis/redis-memory-fragmentation.md b/docs/database/redis/redis-memory-fragmentation.md
index 7de708a736c..799e2131acc 100644
--- a/docs/database/redis/redis-memory-fragmentation.md
+++ b/docs/database/redis/redis-memory-fragmentation.md
@@ -119,4 +119,4 @@ config set active-defrag-cycle-max 50
- Redis 官方文档:https://redis.io/topics/memory-optimization
- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:https://time.geekbang.org/column/article/289140
-- Redis 源码解析——内存分配:
-
\ No newline at end of file
+
diff --git a/docs/database/redis/redis-cluster.md b/docs/database/redis/redis-cluster.md
index 73224676af0..a8e93bd0f2c 100644
--- a/docs/database/redis/redis-cluster.md
+++ b/docs/database/redis/redis-cluster.md
@@ -9,7 +9,6 @@ tag:

-
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn) 的补充完善,两者可以配合使用。

@@ -52,4 +51,4 @@ tag:
-
\ No newline at end of file
+
diff --git a/docs/database/redis/redis-common-blocking-problems-summary.md b/docs/database/redis/redis-common-blocking-problems-summary.md
index a601bdf7d07..6249c42e78c 100644
--- a/docs/database/redis/redis-common-blocking-problems-summary.md
+++ b/docs/database/redis/redis-common-blocking-problems-summary.md
@@ -5,7 +5,7 @@ tag:
- Redis
---
-> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿Q说代码
+> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿 Q 说代码
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
@@ -54,7 +54,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
-关于 AOF 工作流程的详细介绍可以查看:[Redis持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
+关于 AOF 工作流程的详细介绍可以查看:[Redis 持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
### AOF 重写阻塞
@@ -64,7 +64,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生**阻塞**。
-相关阅读:[Redis AOF重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
+相关阅读:[Redis AOF 重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
## 大 Key
@@ -111,13 +111,13 @@ Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处
## Swap(内存交换)
-什么是 Swap?Swap 直译过来是交换的意思,Linux中的Swap常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
+什么是 Swap?Swap 直译过来是交换的意思,Linux 中的 Swap 常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
-Swap 对于Redis来说是非常致命的,Redis保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把Redis使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的Redis性能急剧下降。
+Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的 Redis 性能急剧下降。
识别 Redis 发生 Swap 的检查方法如下:
-1、查询Redis进程号
+1、查询 Redis 进程号
```bash
reids-cli -p 6383 info server | grep process_id
@@ -136,19 +136,19 @@ Swap: 0kB
.....
```
-如果交换量都是0KB或者个别的是4KB,则正常。
+如果交换量都是 0KB 或者个别的是 4KB,则正常。
预防内存交换的方法:
- 保证机器充足的可用内存
-- 确保所有Redis实例设置最大可用内存(maxmemory),防止极端情况Redis内存不可控的增长
-- 降低系统使用swap优先级,如`echo 10 > /proc/sys/vm/swappiness`
+- 确保所有 Redis 实例设置最大可用内存(maxmemory),防止极端情况 Redis 内存不可控的增长
+- 降低系统使用 swap 优先级,如`echo 10 > /proc/sys/vm/swappiness`
## CPU 竞争
-Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务部署在一起。当其他进程过度消耗CPU时,将严重影响Redis的吞吐量。
+Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
-可以通过`reids-cli --stat`获取当前Redis使用情况。通过`top`命令获取进程对CPU的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
+可以通过`reids-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
## 网络问题
@@ -156,5 +156,5 @@ Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务
## 参考
-- Redis阻塞的6大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
-- Redis开发与运维笔记-Redis的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
+- Redis 阻塞的 6 大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
+- Redis 开发与运维笔记-Redis 的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index a3d0afdd9fe..1d2eb28b262 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -387,17 +387,17 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
### 常用命令
-| 命令 | 介绍 |
-| --------------------------------------------- | ------------------------------------------------------------ |
-| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
-| ZCARD KEY | 获取指定有序集合的元素数量 |
-| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
+| 命令 | 介绍 |
+| --------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
+| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
+| ZCARD KEY | 获取指定有序集合的元素数量 |
+| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
| ZINTERSTORE destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
-| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
-| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
-| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
-| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
-| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
+| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
+| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
+| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
+| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
+| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=sorted-set 。
diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 864197cdace..8332c304689 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -26,11 +26,11 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
### 常用命令
-| 命令 | 介绍 |
-| ------------------------------------- | ------------------------------------------------------------ |
-| SETBIT key offset value | 设置指定 offset 位置的值 |
-| GETBIT key offset | 获取指定 offset 位置的值 |
-| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
+| 命令 | 介绍 |
+| ------------------------------------- | ---------------------------------------------------------------- |
+| SETBIT key offset value | 设置指定 offset 位置的值 |
+| GETBIT key offset | 获取指定 offset 位置的值 |
+| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
**Bitmap 基本操作演示** :
@@ -86,10 +86,10 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
-| 命令 | 介绍 |
-| ----------------------------------------- | ------------------------------------------------------------ |
-| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
-| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
+| 命令 | 介绍 |
+| ----------------------------------------- | -------------------------------------------------------------------------------- |
+| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
+| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
**HyperLogLog 基本操作演示** :
@@ -132,13 +132,13 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
### 常用命令
-| 命令 | 介绍 |
-| ------------------------------------------------ | ------------------------------------------------------------ |
-| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
-| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
-| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
+| 命令 | 介绍 |
+| ------------------------------------------------ | ---------------------------------------------------------------------------------------------------- |
+| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
+| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
+| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
-| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
+| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
**基本操作** :
@@ -205,4 +205,4 @@ user2
- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
-- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
\ No newline at end of file
+- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
diff --git a/docs/database/redis/redis-memory-fragmentation.md b/docs/database/redis/redis-memory-fragmentation.md
index 7de708a736c..799e2131acc 100644
--- a/docs/database/redis/redis-memory-fragmentation.md
+++ b/docs/database/redis/redis-memory-fragmentation.md
@@ -119,4 +119,4 @@ config set active-defrag-cycle-max 50
- Redis 官方文档:https://redis.io/topics/memory-optimization
- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:https://time.geekbang.org/column/article/289140
-- Redis 源码解析——内存分配:
-
-  -
-
-
-
-
-
-下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
-
-
-
-
-
-  -
-
-
-
-
-
-**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
-
-如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
-
-这里再送一个 30 元的新人优惠券(续费半价)。
-
-
-
-
-
-  -
-
-
-
-
-
-进入星球之后,记得添加微信,我会发你详细的星球使用指南。
-
-
-
-
-
-
-
-
+
diff --git a/docs/distributed-system/distributed-id.md b/docs/distributed-system/distributed-id.md
index 17ff01b842e..357523f9627 100644
--- a/docs/distributed-system/distributed-id.md
+++ b/docs/distributed-system/distributed-id.md
@@ -84,9 +84,9 @@ COMMIT;
插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
-1)第一步: 尝试把数据插入到表中。
+- 第一步: 尝试把数据插入到表中。
-2)第二步: 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
+- 第二步: 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
这种方式的优缺点也比较明显:
@@ -103,7 +103,7 @@ COMMIT;
以 MySQL 举例,我们通过下面的方式即可。
-**1.创建一个数据库表。**
+**1. 创建一个数据库表。**
```sql
CREATE TABLE `sequence_id_generator` (
@@ -122,15 +122,15 @@ CREATE TABLE `sequence_id_generator` (
`version` 字段主要用于解决并发问题(乐观锁),`biz_type` 主要用于表示业务类型。
-**2.先插入一行数据。**
+**2. 先插入一行数据。**
```sql
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
VALUES
- (1, 0, 100, 0, 101);
+ (1, 0, 100, 0, 101);
```
-**3.通过 SELECT 获取指定业务下的批量唯一 ID**
+**3. 通过 SELECT 获取指定业务下的批量唯一 ID**
```sql
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
@@ -139,11 +139,11 @@ SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `bi
结果:
```
-id current_max_id step version biz_type
-1 0 100 0 101
+id current_max_id step version biz_type
+1 0 100 0 101
```
-**4.不够用的话,更新之后重新 SELECT 即可。**
+**4. 不够用的话,更新之后重新 SELECT 即可。**
```sql
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
@@ -153,8 +153,8 @@ SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `bi
结果:
```
-id current_max_id step version biz_type
-1 100 100 1 101
+id current_max_id step version biz_type
+1 100 100 1 101
```
相比于数据库主键自增的方式,**数据库的号段模式对于数据库的访问次数更少,数据库压力更小。**
diff --git a/docs/distributed-system/distributed-lock.md b/docs/distributed-system/distributed-lock.md
index 8c99a56c996..bb00373e1ca 100644
--- a/docs/distributed-system/distributed-lock.md
+++ b/docs/distributed-system/distributed-lock.md
@@ -95,7 +95,7 @@ OK
### 如何实现锁的优雅续期?
-对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:https://redis.io/topics/distlock 。
+对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:
-
-
-
-
-
-
-
-下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
-
-
-
-
-
-
-
-
-
-**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
-
-如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
-
-这里再送一个 30 元的新人优惠券(续费半价)。
-
-
-
-
-
-
-
-
-
-进入星球之后,记得添加微信,我会发你详细的星球使用指南。
-
-
-
-
-
-
-
-
\ No newline at end of file
+
diff --git a/docs/distributed-system/protocol/gossip-protocl.md b/docs/distributed-system/protocol/gossip-protocl.md
index 261bdcdc348..71331737f69 100644
--- a/docs/distributed-system/protocol/gossip-protocl.md
+++ b/docs/distributed-system/protocol/gossip-protocl.md
@@ -26,13 +26,13 @@ Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic
正如 Gossip 协议其名一样,这是一种随机且带有传染性的方式将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。
-在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。
+在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。
下面我们来对 Gossip 协议的定义做一个总结: **Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。**
## Gossip 协议应用
-NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等知名项目都用到了 Gossip 协议,学习 Gossip 协议有助于我们搞清很多技术的底层原理。
+NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等知名项目都用到了 Gossip 协议,学习 Gossip 协议有助于我们搞清很多技术的底层原理。
我们这里以 Redis Cluster 为例说明 Gossip 协议的实际应用。
@@ -55,7 +55,7 @@ Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
有了 Redis Cluster 之后,不需要专门部署 Sentinel 集群服务了。Redis Cluster 相当于是内置了 Sentinel 机制,Redis Cluster 内部的各个 Redis 节点通过 Gossip 协议互相探测健康状态,在故障时可以自动切换。
-关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 。
+关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 。
## Gossip 协议消息传播模式
@@ -140,4 +140,4 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
- 一万字详解 Redis Cluster Gossip 协议:https://segmentfault.com/a/1190000038373546
- 《分布式协议与算法实战》
-- 《Redis 设计与实现》
\ No newline at end of file
+- 《Redis 设计与实现》
diff --git a/docs/distributed-system/protocol/paxos-algorithm.md b/docs/distributed-system/protocol/paxos-algorithm.md
index 89edd3fde2b..5f5a65f5c52 100644
--- a/docs/distributed-system/protocol/paxos-algorithm.md
+++ b/docs/distributed-system/protocol/paxos-algorithm.md
@@ -73,7 +73,7 @@ Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列
由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。
-不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。像 Raft 算法就是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。
+不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。像 Raft 算法就是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。
## 参考
diff --git a/docs/distributed-system/protocol/raft-algorithm.md b/docs/distributed-system/protocol/raft-algorithm.md
index 86faeca5568..61462eb0a5d 100644
--- a/docs/distributed-system/protocol/raft-algorithm.md
+++ b/docs/distributed-system/protocol/raft-algorithm.md
@@ -167,4 +167,3 @@ raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为
- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
-
diff --git a/docs/distributed-system/rpc/dubbo.md b/docs/distributed-system/rpc/dubbo.md
index 70bc9d6bc13..4078ab7530a 100644
--- a/docs/distributed-system/rpc/dubbo.md
+++ b/docs/distributed-system/rpc/dubbo.md
@@ -5,21 +5,21 @@ tag:
- rpc
---
-> 说明: Dubbo3 已经发布,这篇文章是基于 Dubbo2 写的。Dubbo3 基于 Dubbo2 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全设计等几大方向上进行了全面升级。
+> 说明: Dubbo3 已经发布,这篇文章是基于 Dubbo2 写的。Dubbo3 基于 Dubbo2 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全设计等几大方向上进行了全面升级。
这篇文章是我根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。欢迎补充!
-## Dubbo基础
+## Dubbo 基础
### 什么是 Dubbo?
-[Apache Dubbo](https://github.com/apache/dubbo) |ˈdʌbəʊ| 是一款高性能、轻量级的开源 Java RPC 框架。
+[Apache Dubbo](https://github.com/apache/dubbo) |ˈdʌbəʊ| 是一款高性能、轻量级的开源 Java RPC 框架。
根据 [Dubbo 官方文档](https://dubbo.apache.org/zh/)的介绍,Dubbo 提供了六大核心能力
-1. 面向接口代理的高性能RPC调用。
+1. 面向接口代理的高性能 RPC 调用。
2. 智能容错和负载均衡。
3. 服务自动注册和发现。
4. 高度可扩展能力。
@@ -30,9 +30,9 @@ tag:
简单来说就是: **Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。**
-Dubbo 目前已经有接近 34.4 k 的 Star 。
+Dubbo 目前已经有接近 34.4 k 的 Star 。
-在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第7名。相比几年前来说,热度和排名有所下降。
+在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第 7 名。相比几年前来说,热度和排名有所下降。

@@ -44,12 +44,12 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
-我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
+我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian 这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
1. **负载均衡** : 同一个服务部署在不同的机器时该调用哪一台机器上的服务。
-2. **服务调用链路生成** : 随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
+2. **服务调用链路生成** : 随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
3. **服务访问压力以及时长统计、资源调度和治理** :基于访问压力实时管理集群容量,提高集群利用率。
4. ......
@@ -97,12 +97,12 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
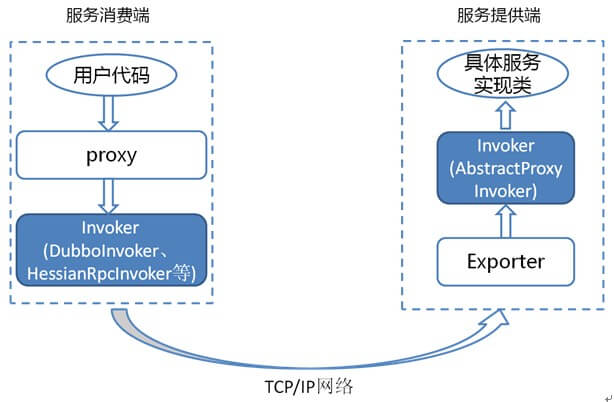
-按照 Dubbo 官方的话来说,`Invoker` 分为
+按照 Dubbo 官方的话来说,`Invoker` 分为
-- 服务提供 `Invoker`
+- 服务提供 `Invoker`
- 服务消费 `Invoker`
-假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 `Invoker` 实现, `Invoker` 实现了真正的远程服务调用。
+假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 `Invoker` 实现, `Invoker` 实现了真正的远程服务调用。
### Dubbo 的工作原理了解么?
@@ -112,7 +112,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
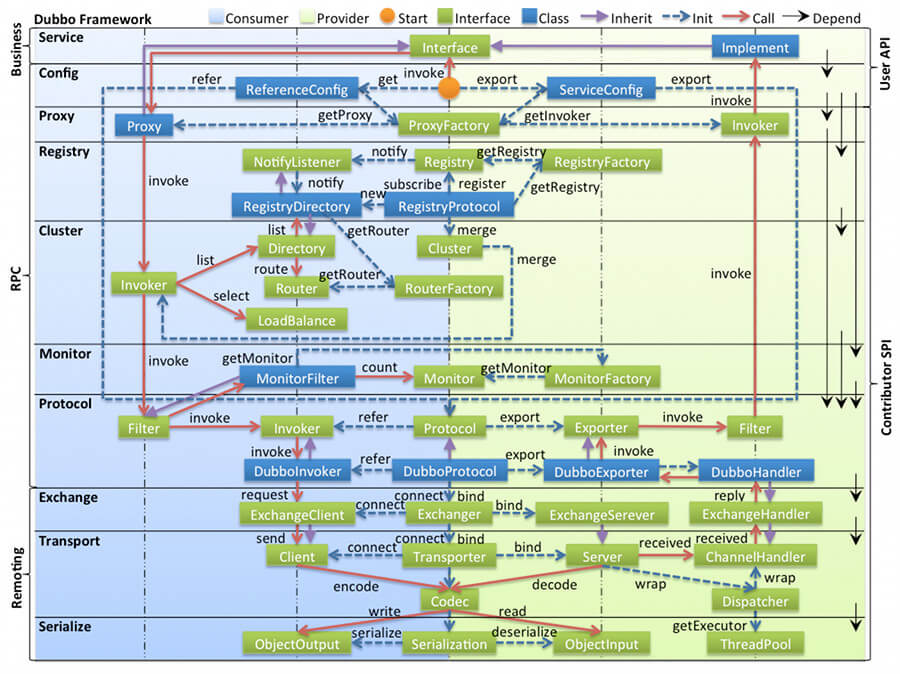
-- **config 配置层**:Dubbo相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
+- **config 配置层**:Dubbo 相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
- **proxy 服务代理层**:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以 `ServiceProxy` 为中心。
- **registry 注册中心层**:封装服务地址的注册与发现。
- **cluster 路由层**:封装多个提供者的路由及负载均衡,并桥接注册中心,以 `Invoker` 为中心。
@@ -128,7 +128,7 @@ SPI(Service Provider Interface) 机制被大量用在开源项目中,它
SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
-Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java原生的 SPI机制进行了增强,以便更好满足自己的需求。
+Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java 原生的 SPI 机制进行了增强,以便更好满足自己的需求。
**那我们如何扩展 Dubbo 中的默认实现呢?**
@@ -136,12 +136,12 @@ Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,
```java
package com.xxx;
-
+
import org.apache.dubbo.rpc.cluster.LoadBalance;
import org.apache.dubbo.rpc.Invoker;
import org.apache.dubbo.rpc.Invocation;
-import org.apache.dubbo.rpc.RpcException;
-
+import org.apache.dubbo.rpc.RpcException;
+
public class XxxLoadBalance implements LoadBalance {
public
-
-
-
-
-
-
-
-
-下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
-
-
-
-
-
-
-
-
-
-
-**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
-
-如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
-
-这里再送一个 30 元的新人优惠券(续费半价)。
-
-
-
-
-
-
-
-
-
-
-进入星球之后,记得添加微信,我会发你详细的星球使用指南。
-
-
-
-
-
-
-
-
+
diff --git a/docs/high-availability/performance-test.md b/docs/high-availability/performance-test.md
index 1a5bad36f2c..b58e929b416 100644
--- a/docs/high-availability/performance-test.md
+++ b/docs/high-availability/performance-test.md
@@ -28,7 +28,7 @@ category: 高可用
5. 系统用到的算法是否还需要优化?
6. 系统是否存在内存泄露的问题?
7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
-8. ......
+8. ......
### 1.3 测试人员
@@ -63,7 +63,7 @@ category: 高可用
**响应时间就是用户发出请求到用户收到系统处理结果所需要的时间。** 重要吗?实在太重要!
-比较出名的 2-5-8 原则是这样描述的:通常来说,2到5秒,页面体验会比较好,5到8秒还可以接受,8秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
+比较出名的 2-5-8 原则是这样描述的:通常来说,2 到 5 秒,页面体验会比较好,5 到 8 秒还可以接受,8 秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
但是,在某些场景下我们也并不需要太看重 2-5-8 原则 ,比如我觉得系统导出导入大数据量这种就不需要,系统生成系统报告这种也不需要。
@@ -85,15 +85,15 @@ category: 高可用
理清他们的概念,就很容易搞清楚他们之间的关系了。
- **QPS(TPS)** = 并发数/平均响应时间
-- **并发数** = QPS*平均响应时间
+- **并发数** = QPS\*平均响应时间
书中是这样描述 QPS 和 TPS 的区别的。
-> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器2次,一次访问,产生一个“T”,产生2个“Q”。
+> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
### 3.4 性能计数器
-**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU使用、磁盘与网络I/O等情况。**
+**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU 使用、磁盘与网络 I/O 等情况。**
### 四 几种常见的性能测试
@@ -127,13 +127,13 @@ category: 高可用
1. Jmeter :Apache JMeter 是 JAVA 开发的性能测试工具。
2. LoadRunner:一款商业的性能测试工具。
-3. Galtling :一款基于Scala 开发的高性能服务器性能测试工具。
+3. Galtling :一款基于 Scala 开发的高性能服务器性能测试工具。
4. ab :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
### 5.2 前端常用
-1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是Web 调试的利器。
-2. HttpWatch: 可用于录制HTTP请求信息的工具。
+1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
+2. HttpWatch: 可用于录制 HTTP 请求信息的工具。
## 六 常见的性能优化策略
diff --git a/docs/high-availability/redundancy.md b/docs/high-availability/redundancy.md
index b6cf853fe6f..ebe0a4b8df0 100644
--- a/docs/high-availability/redundancy.md
+++ b/docs/high-availability/redundancy.md
@@ -41,4 +41,4 @@ category: 高可用
- [四步构建异地多活](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg)
- [《从零开始学架构》— 28 | 业务高可用的保障:异地多活架构](http://gk.link/a/10pKZ)
-不过,这些文章大多也都是在介绍概念知识。目前,网上还缺少真正介绍具体要如何去实践落地异地多活架构的资料。
\ No newline at end of file
+不过,这些文章大多也都是在介绍概念知识。目前,网上还缺少真正介绍具体要如何去实践落地异地多活架构的资料。
diff --git a/docs/high-availability/timeout-and-retry.md b/docs/high-availability/timeout-and-retry.md
index e3121623784..407ec9c0340 100644
--- a/docs/high-availability/timeout-and-retry.md
+++ b/docs/high-availability/timeout-and-retry.md
@@ -38,7 +38,7 @@ category: 高可用
没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
-更上一层,参考[美团的Java线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
+更上一层,参考[美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
## 重试机制
@@ -66,6 +66,5 @@ category: 高可用
## 参考
-- 微服务之间调用超时的设置治理:https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx
-- 超时、重试和抖动回退:https://aws.amazon.com/cn/builders-library/timeouts-retries-and-backoff-with-jitter/
-
+- 微服务之间调用超时的设置治理:
-
- @@ -110,7 +108,7 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
3. **负载均衡** :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
4. ......
-### Kafka 如何保证消息的消费顺序?
+### Kafka 如何保证消息的消费顺序?
我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了 2 个消息,这 2 个消息对应的操作分别对应的数据库操作是:
@@ -142,11 +140,11 @@ Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data
#### 生产者丢失消息的情况
-生产者(Producer) 调用`send`方法发送消息之后,消息可能因为网络问题并没有发送过去。
+生产者(Producer) 调用`send`方法发送消息之后,消息可能因为网络问题并没有发送过去。
-所以,我们不能默认在调用`send`方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 `send` 方法发送消息实际上是异步的操作,我们可以通过 `get()`方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
+所以,我们不能默认在调用`send`方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 `send` 方法发送消息实际上是异步的操作,我们可以通过 `get()`方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
-> **详细代码见我的这篇文章:[Kafka系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
+> **详细代码见我的这篇文章:[Kafka 系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
```java
SendResult
@@ -110,7 +108,7 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
3. **负载均衡** :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
4. ......
-### Kafka 如何保证消息的消费顺序?
+### Kafka 如何保证消息的消费顺序?
我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了 2 个消息,这 2 个消息对应的操作分别对应的数据库操作是:
@@ -142,11 +140,11 @@ Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data
#### 生产者丢失消息的情况
-生产者(Producer) 调用`send`方法发送消息之后,消息可能因为网络问题并没有发送过去。
+生产者(Producer) 调用`send`方法发送消息之后,消息可能因为网络问题并没有发送过去。
-所以,我们不能默认在调用`send`方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 `send` 方法发送消息实际上是异步的操作,我们可以通过 `get()`方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
+所以,我们不能默认在调用`send`方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 `send` 方法发送消息实际上是异步的操作,我们可以通过 `get()`方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
-> **详细代码见我的这篇文章:[Kafka系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
+> **详细代码见我的这篇文章:[Kafka 系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
```java
SendResult
-
-
-
-
-
-下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
-
-
-
-
-
-
-
-
-
-**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
-
-如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
-
-这里再送一个 30 元的新人优惠券(续费半价)。
-
-
-
-
-
-
-
-
-
-进入星球之后,记得添加微信,我会发你详细的星球使用指南。
-
-
-
-
-
-
-
-
\ No newline at end of file
+
diff --git a/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md b/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
index c76fd79ca1a..7054cb46842 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
@@ -12,7 +12,7 @@ tag:
>
> **原文地址:** https://mp.weixin.qq.com/s/6hUU6SZsxGPWAIIByq93Rw
-我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别****人沟通,都显得特别专业**。每次遇到这类人,我都在想,他们到底是怎么做到的?
+我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别\*\***人沟通,都显得特别专业\*\*。每次遇到这类人,我都在想,他们到底是怎么做到的?
随着工作时间的增长,渐渐地我也总结出一些经验,他们身上都保持着一些看似很微小的优秀习惯,但正是因为这些习惯,体现出了一个优秀程序员的基本素养。
@@ -143,4 +143,4 @@ tag:
优秀程序员的专业技能,我们可能很难在短时间内学会,但这些基本的职业素养,是可以在短期内做到的。
-希望你我可以有则改之,无则加勉。
\ No newline at end of file
+希望你我可以有则改之,无则加勉。
diff --git a/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md b/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
index 5dae09085e1..aaff014b540 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
@@ -20,7 +20,7 @@ tag:
>
> **原文地址** :https://mp.weixin.qq.com/s/8lMGzBzXine-NAsqEaIE4g
-### 建议1:刻意加强需求评审能力
+### 建议 1:刻意加强需求评审能力
先从需求评审开始说。在互联网公司,需求评审是开发工作的主要入口。
@@ -38,7 +38,7 @@ tag:
所以,**普通程序员要想成长为更高级别的开发,一定要加强需求评审能力的培养**。
-### 建议2:主动思考效率
+### 建议 2:主动思考效率
普通的程序员,按部就班的去写代码,有活儿来我就干,没活儿的时候我就呆着。很少去深度思考现有的这些代码为什么要这么写,这么写的好处是啥,有哪些地方存在瓶颈,我是否可以把它优化一些。
@@ -50,7 +50,7 @@ tag:
所以,**第二个建议就是要主动思考一下现有工作中哪些地方效率有改进的空间,想到了就主动去改进它!**
-### 建议3:加强内功能力
+### 建议 3:加强内功能力
哪些算是内功呢,我想内功修炼的读者们肯定也都很熟悉的了,指的就是大家学校里都学过的操作系统、网络等这些基础。
@@ -64,7 +64,7 @@ tag:
所以,**还建议多多锻炼底层技术内功能力**。如果你不知道怎么练,那就坚持看「开发内功修炼」公众号。
-### 建议4:思考性能
+### 建议 4:思考性能
普通程序员往往就是把需求开发完了就不管了,只要需求实现了,测试通过了就可以交付了。将来流量会有多大,没想过。自己的服务 QPS 能支撑多少,不清楚。
@@ -76,7 +76,7 @@ tag:
所以,**第四个建议就是一定要多多主动你所负责业务的性能,并多多进行优化和改进**。我想这个建议的重要程度非常之高。但这是需要你具备深厚的内功才可以办的到的,否则如果你连网络是怎么工作的都不清楚,谈何优化!
-### 建议5:重视线上
+### 建议 5:重视线上
普通程序员往往对线上的事情很少去关注,手里记录的服务器就是自己的开发机和发布机,线上机器有几台,流量多大,最近有没有波动这些可能都不清楚。
@@ -88,7 +88,7 @@ tag:
所以,**飞哥给的第五个建议就是要多多观察线上运行情况**。只有多多关注线上,当线上出故障的时候,你才能承担的起快速排出线上问题的重任。
-### 建议6:关注全局
+### 建议 6:关注全局
普通程序员是你分配给我哪个模块,我就干哪个模块,给自己的工作设定了非常小的一个边界,自己所有的眼光都聚集在这个小框框内。
@@ -98,8 +98,8 @@ tag:
所以,**建议要有大局观,不仅仅是你负责的模块,整个项目其实你都应该去关注**。而不是连自己组内同学做的是啥都不知道。
-### 建议7:归纳总结能力
+### 建议 7:归纳总结能力
普通程序员往往是工作的事情做完就拉到,很少回头去对自己的技术,对业务进行归纳和总结。
-而高级的程序员往往都会在一件比较大的事情做完之后总结一下,做个ppt,写个博客啥的记录下来。这样既对自己的工作是一个归纳,也可以分享给其它同学,促进团队的共同成长。
+而高级的程序员往往都会在一件比较大的事情做完之后总结一下,做个 ppt,写个博客啥的记录下来。这样既对自己的工作是一个归纳,也可以分享给其它同学,促进团队的共同成长。
diff --git a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
index 601d8b27984..5d3c2c9a6fd 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
@@ -204,4 +204,4 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
>
> 实现战略目标,就像种树一样。刚开始只是一个小根芽,树干还没有长出来;树干长出来了,枝叶才能慢慢长出来;树枝长出来,然后才能开花和结果。刚开始种树的时候,只管栽培灌溉,别老是纠结枝什么时候长出来,花什么时候开,果实什么时候结出来。纠结有什么好处呢?只要你坚持投入栽培,还怕没有枝叶花实吗?
-
\ No newline at end of file
+
diff --git a/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md b/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
index a625aec4cb8..9f36a152ab4 100644
--- a/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
+++ b/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
@@ -341,4 +341,4 @@ tag:
## 参考资料
- [技术面试官的 9 大误区](https://zhuanlan.zhihu.com/p/51404304)
-- [如何当一个好的面试官?](https://www.zhihu.com/question/26240321)
\ No newline at end of file
+- [如何当一个好的面试官?](https://www.zhihu.com/question/26240321)
diff --git a/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md b/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
index d397d99c400..73131440eae 100644
--- a/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
+++ b/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
@@ -198,4 +198,4 @@ tag:
- 对于实习工作,**看的知识点常见的问题一定要全!!!!!**,不是那么精问题不大,一定要全,一定要全!!!!
- **对于自己不会的,尽量多的说!!!!** 实在不行,就往别的地方说!!!总之是引导面试官往自己会的地方上说。
- 面试中的笔试和前面的笔试风格不同,面试笔试题目不太难,但是考察是冷静思考,代码优雅,没有 bug,先思考清楚!!!在写!!!
-- 在描述项目的难点的时候,不要去聊文档调研是难点,回答这部分问题更应该是技术上的难点,最后通过了什么技术解决了这个问题,这部分技术可以让面试官来更多提问以便知道自己的技术能力。
\ No newline at end of file
+- 在描述项目的难点的时候,不要去聊文档调研是难点,回答这部分问题更应该是技术上的难点,最后通过了什么技术解决了这个问题,这部分技术可以让面试官来更多提问以便知道自己的技术能力。
diff --git a/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md b/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
index 7840fffae8e..4d576f8310f 100644
--- a/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
+++ b/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
@@ -93,14 +93,14 @@ tag:
笔者最近接待的面试者,很多面试者的简历上,写着层出不穷的各种技术,为了不跨越求职者的技术栈,笔者专门挑应聘者简历写到或用到的技术来进行询问。笔者举几个例子。
-**1)某求职者简历上写着熟练使用 Redis。**
+**1)某求职者简历上写着熟练使用 Redis。**
1. 介绍一下你使用过 Redis 的哪些数据结构,并描述一下使用的业务场景;
2. 介绍一下你操作 Redis 用到的是什么插件;
3. 介绍一下你们使用的序列化方式;
4. 介绍一下你们使用 Redis 遇到过给你印象较深的问题;
-**2)某求职者声称熟练 HTTP 协议并编写过爬虫。**
+**2)某求职者声称熟练 HTTP 协议并编写过爬虫。**
1. 介绍一下你所了解的几个 HTTP head 头并描述其用途;
2. 如果前端提交成功,后端无法接受数据,这时候你将如何排查问题;
diff --git a/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md b/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
index a40bdcafdda..806f00f3b8f 100644
--- a/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
+++ b/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
@@ -116,4 +116,4 @@ action,action,action ,重要的事情说三遍,做技术的不可能光
但是,面试时间有限,同学们一定要在有限的时间里展现出自己的**能力**和**无限的潜力** 。
-最后,祝愿优秀的你能找到自己理想的工作!
\ No newline at end of file
+最后,祝愿优秀的你能找到自己理想的工作!
diff --git a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
index e3d46fc3f3e..8cfb4f13a8d 100644
--- a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
+++ b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
@@ -160,4 +160,4 @@ Java 卷吗?毫无疑问,很卷,我个人认为开发属于没有什么门
## 祝福
-惟愿诸君,前程似锦!
\ No newline at end of file
+惟愿诸君,前程似锦!
diff --git a/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md b/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
index ccd80d86745..60c0388975a 100644
--- a/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
+++ b/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
@@ -211,4 +211,4 @@ tag:
重点是:有些问题你答得很有深度,也体现了你的深度思考能力。
-这一点是我当了技术面试官才领会到的。当然,并不是每位技术面试官都是这么想的,但我觉得这应该是个更合适的方式。
\ No newline at end of file
+这一点是我当了技术面试官才领会到的。当然,并不是每位技术面试官都是这么想的,但我觉得这应该是个更合适的方式。
diff --git a/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md b/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
index 275bc9889bf..5d3f1e7eb6c 100644
--- a/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
+++ b/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
@@ -11,12 +11,12 @@ tag:
> **内容概览** :
>
> 1. 个人介绍,是对自己的一个更为清晰、深入和全面的认识契机。
->2. 简历是充分展示自己的浓缩精华,也是重新审视自己和过往经历的契机。不仅仅是简要介绍技能和经验,更要最大程度凸显自己的优势领域(差异化)。
+> 2. 简历是充分展示自己的浓缩精华,也是重新审视自己和过往经历的契机。不仅仅是简要介绍技能和经验,更要最大程度凸显自己的优势领域(差异化)。
> 3. 我个人是不赞成海投的,而倾向于定向投。找准方向投,虽然目标更少,但更有效率。
> 4. 技术探索,一定要先理解原理。原理不懂,就会浮于表层,不能真正掌握它。技术原理探究要掌握到什么程度?数据结构与算法设计、考量因素、技术机制、优化思路。要在脑中回放,直到一切细节而清晰可见。如果能够清晰有条理地表述出来,就更好了。技术原理探究,一定要看源码。看了源码与没看源码是有区别的。没看源码,虽然说得出来,但终是隔了一层纸;看了源码,才捅破了那层纸,有了自己的理解,也就能说得更加有底气了。当然,也可能是我缺乏演戏的本领。
> 5. 要善于从失败中学习。正是在杭州四个月空档期的持续学习、思考、积累和提炼,以及面试失败的反思、不断调整对策、完善准备、改善原有的短板,采取更为合理的方式,才在回武汉的短短两个周内拿到比较满意的 offer 。
> 6. 面试是通过沟通来理解双方的过程。面试中的问题,千变万化,但有一些问题是需要提前准备好的。
->
+>
> **原文地址** :https://www.cnblogs.com/lovesqcc/p/14354921.html
从每一段经历中学习,在每一件事情中修行。善于从挫折中学习。
@@ -357,4 +357,4 @@ ZOOM 的一位面试官或许是我见过的所有面试官中最差劲的。共
经过这一段面试的历炼,我觉得现在相比离职时的自己,又有了不少进步的。不说脱胎换骨,至少也是蜕了一层皮吧。差距,差距还是有的。起码面试那些知名大厂企业的技术专家和架构师还有差距。这与我平时工作的挑战性、认知视野的局限性及总结不足有关。下一次,我希望积蓄足够实力做到更好,和内心热爱的有价值有意义的事情再近一些些。
-面试,其实也是一段工作经历。
\ No newline at end of file
+面试,其实也是一段工作经历。
diff --git a/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md b/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
index 4b4a7906db2..bcb42dfc63b 100644
--- a/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
+++ b/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
@@ -194,4 +194,4 @@ tag:
这篇文章其实算讲的是方法论,很多我们一看就明白的「道理」实施起来可能会很难。可能会遇到一个不按常理出牌的面试官,也可能也会遇到一个沟通困难的面试官,当然也可能会撞上一个不怎么匹配的岗位。
-总而言之,为了自己想要争取的东西,做好足够的准备总是没有坏处的。祝愿大家能成为`π`型人才,获得想要的`offer`!
\ No newline at end of file
+总而言之,为了自己想要争取的东西,做好足够的准备总是没有坏处的。祝愿大家能成为`π`型人才,获得想要的`offer`!
diff --git a/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md b/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
index 986d281dd83..27518f58e1b 100644
--- a/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
+++ b/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
@@ -12,7 +12,7 @@ tag:
>
> **原文地址** :https://www.cnblogs.com/scada/p/14259332.html
-------
+---
## 前言
@@ -20,7 +20,7 @@ tag:
近 8 年有些事情做对了,也有更多事情做错了,在这里记录一下,希望能够给后人一些帮助吧,也欢迎私信交流。文笔不好,见谅,有些细节记不清了,如果有出入,就当是我编的这个故事吧。
-*PS:有几个问题先在这里解释一下,评论就不一一回复了*
+_PS:有几个问题先在这里解释一下,评论就不一一回复了_
1. 关于差生,我本人在科大时确实成绩偏下,差生主要讲这一点,没其他意思。
2. 因为买房是我人生中的大事,我认为需要记录和总结一下,本文中会有买房,房价之类的信息出现,您如果对房价,炒房等反感的话,请您停止阅读,并且我再这里为浪费您的时间先道个歉。
@@ -231,4 +231,4 @@ tag:
## 总结
-好了 7 年多,近 8 年的职场讲完了,不管过去如何,未来还是要继续努力,希望看到这篇文章觉得有帮助的朋友,可以帮忙点个推荐,这样可能更多的人看到,也许可以避免更多的人犯我犯的错误。另外欢迎私信或者其他方式交流(某 Xin 号,jingyewandeng),可以讨论职场经验,方向,我也可以帮忙改简历(免费啊),不用怕打扰,能帮助别人是一项很有成绩感的事,并且过程中也会有收获,程序员也不要太腼腆呵呵
\ No newline at end of file
+好了 7 年多,近 8 年的职场讲完了,不管过去如何,未来还是要继续努力,希望看到这篇文章觉得有帮助的朋友,可以帮忙点个推荐,这样可能更多的人看到,也许可以避免更多的人犯我犯的错误。另外欢迎私信或者其他方式交流(某 Xin 号,jingyewandeng),可以讨论职场经验,方向,我也可以帮忙改简历(免费啊),不用怕打扰,能帮助别人是一项很有成绩感的事,并且过程中也会有收获,程序员也不要太腼腆呵呵
diff --git a/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md b/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md
index 95a22b2834a..c0d82be8417 100644
--- a/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md
+++ b/docs/high-quality-technical-articles/personal-experience/four-year-work-in-tencent-summary.md
@@ -30,17 +30,17 @@ tag:
## 工作情况
-我在腾讯内部没有转过岗,但是做过的项目也还是比较丰富的,包括:BUGLY、分布式调用链(Huskie)、众包系统(SOHO),EPC度量系统。其中一些是对外的,一些是内部系统,可能有些大家不知道。还是比较感谢这些项目经历,既有纯业务的系统,也有偏框架的系统,让我学到了不少知识。
+我在腾讯内部没有转过岗,但是做过的项目也还是比较丰富的,包括:BUGLY、分布式调用链(Huskie)、众包系统(SOHO),EPC 度量系统。其中一些是对外的,一些是内部系统,可能有些大家不知道。还是比较感谢这些项目经历,既有纯业务的系统,也有偏框架的系统,让我学到了不少知识。
接下来,简单介绍一下每个项目吧,毕竟每一个项目都付出了很多心血的:
-BUGLY,这是一个终端Crash联网上报的系统,很多APP都接入了。Huskie,这是一个基于zipkin搭建的分布式调用链跟踪项目。SOHO,这是一个众包系统,主要是将数据标准和语音采集任务众包出去,让人家做。EPC度量系统,这是研发效能度量系统,主要是度量研发效能情况的。这里我谈一下对于业务开发的理解和认识,很多人可能都跟我最开始一样,有一个疑惑,整天做业务开发如何成长?换句话说,就是说整天做CRUD,如何成长?我开始也有这样的疑惑,后来我转变了观念。
+BUGLY,这是一个终端 Crash 联网上报的系统,很多 APP 都接入了。Huskie,这是一个基于 zipkin 搭建的分布式调用链跟踪项目。SOHO,这是一个众包系统,主要是将数据标准和语音采集任务众包出去,让人家做。EPC 度量系统,这是研发效能度量系统,主要是度量研发效能情况的。这里我谈一下对于业务开发的理解和认识,很多人可能都跟我最开始一样,有一个疑惑,整天做业务开发如何成长?换句话说,就是说整天做 CRUD,如何成长?我开始也有这样的疑惑,后来我转变了观念。
我觉得对于系统的复杂度,可以粗略的分为技术复杂度和业务复杂度,对于业务系统,就是业务复杂度高一些,对于框架系统就是技术复杂度偏高一些。解决这两种复杂度,都具有很大的挑战。
-此前做过的众包系统,就是各种业务逻辑,搞过去,搞过来,其实这就是业务复杂度高。为了解决这个问题,我们开始探索和实践领域驱动(DDD),确实带来了一些帮助,不至于系统那么混乱了。同时,我觉得这个过程中,自己对于DDD的感悟,对于我后来的项目系统划分和设计以及开发都带来了帮助。
+此前做过的众包系统,就是各种业务逻辑,搞过去,搞过来,其实这就是业务复杂度高。为了解决这个问题,我们开始探索和实践领域驱动(DDD),确实带来了一些帮助,不至于系统那么混乱了。同时,我觉得这个过程中,自己对于 DDD 的感悟,对于我后来的项目系统划分和设计以及开发都带来了帮助。
-当然DDD不是银弹,我也不是吹嘘它有多好,只是了解了它后,有时候设计和开发时,能换一种思路。
+当然 DDD 不是银弹,我也不是吹嘘它有多好,只是了解了它后,有时候设计和开发时,能换一种思路。
可以发现,其实平时咱们做业务,想做好,其实也没那么容易,如果可以多探索多实践,将一些好的方法或思想或架构引入进来,与个人和业务都会有有帮助。
@@ -52,19 +52,19 @@ BUGLY,这是一个终端Crash联网上报的系统,很多APP都接入了。H
PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎不发了)
-印象比较深的是两次五星获得经历。第一次五星是工作的第二年,那一年是在做众包项目,因为项目本身难度不大,因此我把一些精力投入到了团队的基础建设中,帮团队搭建了java以及golang的项目脚手架,又做了几次中心技术分享,最终Leader觉得我表现比较突出,因此给了我五星。看来,主动一些,与个人与团队都是有好处的,最终也能获得一些回报。
+印象比较深的是两次五星获得经历。第一次五星是工作的第二年,那一年是在做众包项目,因为项目本身难度不大,因此我把一些精力投入到了团队的基础建设中,帮团队搭建了 java 以及 golang 的项目脚手架,又做了几次中心技术分享,最终 Leader 觉得我表现比较突出,因此给了我五星。看来,主动一些,与个人与团队都是有好处的,最终也能获得一些回报。
-第二次五星,就是与EPC有关了。说一个搞笑的事,我也是后来才知道的,项目初期,总监去汇报时,给老板演示系统,加载了很久指标才刷出来,总监很不好意思的说正在优化;过了一段时间,又去汇报演示,结果又很尴尬的刷了很久才出来,总监无赖表示还是在优化。没想到,自己曾经让总监这么丢脸,哈哈。好吧,说一下结果,最终,我自己写了一个查询引擎替换了Mondrian,之后再也没有出现那种尴尬的情况了。随之而来,也给了好绩效鼓励。做EPC度量项目,我觉得自己成长很大,比如抗压能力,当你从零到一搭建一个系统时,会有一个先扛住再优化的过程,此外如果你的项目很重要,尤其是数据相关,那么任何一点问题,都可能让你神经紧绷,得想尽办法降低风险和故障。此外,另一个不同的感受就是,以前得项目,我大多是开发者,而这个系统,我是Owner负责人,当你Owner一个系统时,你得时刻负责,同时还需要思考系统的规划和方向,此外还需要分配好需求和把控进度,角色体验跟以前完全不一样。
+第二次五星,就是与 EPC 有关了。说一个搞笑的事,我也是后来才知道的,项目初期,总监去汇报时,给老板演示系统,加载了很久指标才刷出来,总监很不好意思的说正在优化;过了一段时间,又去汇报演示,结果又很尴尬的刷了很久才出来,总监无赖表示还是在优化。没想到,自己曾经让总监这么丢脸,哈哈。好吧,说一下结果,最终,我自己写了一个查询引擎替换了 Mondrian,之后再也没有出现那种尴尬的情况了。随之而来,也给了好绩效鼓励。做 EPC 度量项目,我觉得自己成长很大,比如抗压能力,当你从零到一搭建一个系统时,会有一个先扛住再优化的过程,此外如果你的项目很重要,尤其是数据相关,那么任何一点问题,都可能让你神经紧绷,得想尽办法降低风险和故障。此外,另一个不同的感受就是,以前得项目,我大多是开发者,而这个系统,我是 Owner 负责人,当你 Owner 一个系统时,你得时刻负责,同时还需要思考系统的规划和方向,此外还需要分配好需求和把控进度,角色体验跟以前完全不一样。
-## 谈谈EPC
+## 谈谈 EPC
-很多人都骂EPC,或者笑EPC,作为度量平台核心开发者之一,我来谈谈客观的看法。
+很多人都骂 EPC,或者笑 EPC,作为度量平台核心开发者之一,我来谈谈客观的看法。
-其实EPC初衷是好的,希望通过全方位多维度的研效指标,来度量研发效能各环节的质量,进而反推业务,提升研发效能。然而,最终在实践的过程中,才发现,客观条件并不支持(工具还没建设好);此外,一味的追求指标数据,使得下面的人想方设法让指标好看,最终违背了初衷。
+其实 EPC 初衷是好的,希望通过全方位多维度的研效指标,来度量研发效能各环节的质量,进而反推业务,提升研发效能。然而,最终在实践的过程中,才发现,客观条件并不支持(工具还没建设好);此外,一味的追求指标数据,使得下面的人想方设法让指标好看,最终违背了初衷。
-为什么,说EPC好了,其实如果你仔细了解下EPC,你就会发现,他是一套相当完善且比较先进的指标度量体系。覆盖了需求,代码,缺陷,测试,持续集成,运营部署各个环节。
+为什么,说 EPC 好了,其实如果你仔细了解下 EPC,你就会发现,他是一套相当完善且比较先进的指标度量体系。覆盖了需求,代码,缺陷,测试,持续集成,运营部署各个环节。
-此外,这个过程中,虽然一些人和一些业务做弊,但绝大多数业务还是做出了改变的,比如微视那边的人反馈是,以前的代码写的跟屎一样,当有了EPC后,代码质量好了很多。虽然最后微视还是亡了,但是大厦将倾,EPC是救不了的,亡了也更不能怪EPC。
+此外,这个过程中,虽然一些人和一些业务做弊,但绝大多数业务还是做出了改变的,比如微视那边的人反馈是,以前的代码写的跟屎一样,当有了 EPC 后,代码质量好了很多。虽然最后微视还是亡了,但是大厦将倾,EPC 是救不了的,亡了也更不能怪 EPC。
## 谈谈嫡系
@@ -74,7 +74,7 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
但另一方面,后来我负责了团队内很重要的事情,应该是中心内都算很重要的事,我独自负责一个方向,直接向总监汇报,似乎又有点像。
-网上也有其他说法,一针见血,是不是嫡系,就看钱到不到位,这么说也有道理。我在7级时,就发了股票,自我感觉,还是不错的。我当时以为不出意外的话,我以后的钱途和发展是不是就会一帆风顺。不出意外就出了意外,第二年,EPC不达预期,部门总经理和总监都被换了,中心来了一个新的的总监。
+网上也有其他说法,一针见血,是不是嫡系,就看钱到不到位,这么说也有道理。我在 7 级时,就发了股票,自我感觉,还是不错的。我当时以为不出意外的话,我以后的钱途和发展是不是就会一帆风顺。不出意外就出了意外,第二年,EPC 不达预期,部门总经理和总监都被换了,中心来了一个新的的总监。
好吧,又要重新建立信任了。再到后来,是不是嫡系已经不重要了,因为大环境不好,又加上裁员,大家主动的被动的差不多都走了。
@@ -87,7 +87,7 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
先说一些可量化的吧,我觉得有:
- 级别上,升上了九级,高级工程师。虽然大家都在说腾讯职级缩水,但是有没有高工的能力自己其实是知道的,我个人感觉,通过我这几年的努力,我算是达到了我当时认为的我需要在高工时达到的状态;
-- 绩效上,自我评价,个人不是一个特别卷的人,或者说不会为了卷而卷。但是,如果我认定我应该把它做好得,我的Owner意识,以及负责态度,我觉得还是可以的。最终在腾讯四年的绩效也还算过的去。再谈一些其他软技能方面:
+- 绩效上,自我评价,个人不是一个特别卷的人,或者说不会为了卷而卷。但是,如果我认定我应该把它做好得,我的 Owner 意识,以及负责态度,我觉得还是可以的。最终在腾讯四年的绩效也还算过的去。再谈一些其他软技能方面:
**1、文档能力**
@@ -104,4 +104,4 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
- 选一个业务方向,比如电商,广告,不断地积累业务领域知识和业务相关技能,随着经验的不断积累,最终你就是这个领域的专家。
- 深入一个技术方向,不断钻研底层技术知识,这样就有希望成为此技术专家。坦白来说,虽然我深入研究并实践过领域驱动设计,也用来建模和解决了一些复杂业务问题,但是发自内心的,我其实更喜欢钻研技术,同时,我又对大数据很感兴趣。因此,我决定了,以后的方向,就做数据相关的工作。
-腾讯的四年,是我的第一份工作经历,认识了很多厉害的人,学到了很多。最后自己主动离开,也算走的体面(即使损失了大礼包),还是感谢腾讯。
\ No newline at end of file
+腾讯的四年,是我的第一份工作经历,认识了很多厉害的人,学到了很多。最后自己主动离开,也算走的体面(即使损失了大礼包),还是感谢腾讯。
diff --git a/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md b/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
index 7b96890962e..ca6d3c2911f 100644
--- a/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
+++ b/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
@@ -159,7 +159,7 @@ OD 同学能拿到 A 吗?不知道,我入职晚,都没有经历一个完
## 投简历,找面试官求虐
-20年11月初的一天,在同事们讨论“某某被其他公司高薪挖去了,钱景无限”的消息。
+20 年 11 月初的一天,在同事们讨论“某某被其他公司高薪挖去了,钱景无限”的消息。
我忽然惊觉,自己来到华为半年多,除了熟悉内部的系统和流程,好像没有什么成长和进步?
@@ -332,6 +332,6 @@ blabla 有少量的基础问题和一面有重复,还有几个和大数据相
## 文末的絮叨
-**入职鹅厂已经1月有余。不同的岗位,不同的工作内容,也是不同的挑战。**
+**入职鹅厂已经 1 月有余。不同的岗位,不同的工作内容,也是不同的挑战。**
-感受比较深的是,作为程序员,还是要自我驱动,努力提升个人技术能力,横向纵向都要扩充,这样才能走得长远。
\ No newline at end of file
+感受比较深的是,作为程序员,还是要自我驱动,努力提升个人技术能力,横向纵向都要扩充,这样才能走得长远。
diff --git a/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md b/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
index 25a8c8bdb5e..6db454a72cd 100644
--- a/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
+++ b/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
@@ -147,4 +147,4 @@ tag:
本来还想分享一些生活方面的故事,发现已经这么长了,那就先这样叭。上面写的一些总结和建议我自己做的也不是很好,还需要继续加油,和大家共勉。另外,其中某些观点,由于个人视角的局限性也不保证是普适和正确的,可能再工作几年这些观点也会发生改变,欢迎大家跟我交流~(甩锅成功)
-最后祝大家都能找到心仪的工作,快乐工作,幸福生活,广阔天地,大有作为。
\ No newline at end of file
+最后祝大家都能找到心仪的工作,快乐工作,幸福生活,广阔天地,大有作为。
diff --git a/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md b/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
index d5c0c8673fd..79089c7aa89 100644
--- a/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
+++ b/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
@@ -137,4 +137,4 @@ tag:
可能当下,写公众号和录视频等的方式,挣钱收益要高于出书,不过话可以这样说,经营公众号和录制视频也是个长期的事情,在短时间里可能未必有收益,如果不是系统地发表内容的话,可能甚至不会有收益。所以出书可能是个非常好的前期准备工作,你靠出书系统积累了素材,靠出书整合了你的知识体系,那么在此基础上,靠公众号或者录视频挣钱可能就会事半功倍。
-从上文里大家可以看到,在出书前期,联系出版社编辑和定选题并不难,如果要写案例书,那么在参考别人内容的基础上,要写完一般书可能也不是高不可攀的事情。甚至可以这样说,出书是个体力活,只要坚持,要出本书并不难,只是你愿不愿意坚持下去的问题。但一旦你有了属于自己的技术书,那么在找工作时,你就能自信地和面试官说你是这方面的专家,在你的视频、公众号和文字里,你也能正大光明地说,你是计算机图书的作者。更为重要的是,和名校、大厂经历一样,属于你的技术书同样是证明程序员能力的重要证据,当你通过出书有效整合了相关方面的知识体系后,那么在这方面,不管是找工作,或者是干私活,或者是接项目做,你都能理直气壮地和别人说:我能行!
\ No newline at end of file
+从上文里大家可以看到,在出书前期,联系出版社编辑和定选题并不难,如果要写案例书,那么在参考别人内容的基础上,要写完一般书可能也不是高不可攀的事情。甚至可以这样说,出书是个体力活,只要坚持,要出本书并不难,只是你愿不愿意坚持下去的问题。但一旦你有了属于自己的技术书,那么在找工作时,你就能自信地和面试官说你是这方面的专家,在你的视频、公众号和文字里,你也能正大光明地说,你是计算机图书的作者。更为重要的是,和名校、大厂经历一样,属于你的技术书同样是证明程序员能力的重要证据,当你通过出书有效整合了相关方面的知识体系后,那么在这方面,不管是找工作,或者是干私活,或者是接项目做,你都能理直气壮地和别人说:我能行!
diff --git a/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md b/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
index 3884a41077b..43afec1e206 100644
--- a/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
+++ b/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
@@ -1,5 +1,5 @@
---
-title: 程序员怎样出版一本技术书
+title: 程序员怎样出版一本技术书
category: 技术文章精选集
author: hsm_computer
tag:
@@ -90,4 +90,4 @@ tag:
其实出书收益并不高,算下来月入大概能在 3k 左右,如果是和图书出版公司合作,估计更少,但这好歹能证明自己的实力。不过在出书后不能止步于此,因为在大厂里有太多的牛人,甚至不用靠出书来证明自己的实力。
-那么如何让出书带来的利益最大化呢?第一可以靠这进大厂,面试时有自己的书绝对是加分项。第二可以用这个去各大网站开专栏,录视频,或者开公众号,毕竟有出版社的背书,能更让别人信服你的能力。第三更得用写书时积累的学习方法和上进的态势继续专研更高深技术,技术有了,不仅能到大厂挣更多的钱,还能通过企业培训等方式更高效地挣钱。
\ No newline at end of file
+那么如何让出书带来的利益最大化呢?第一可以靠这进大厂,面试时有自己的书绝对是加分项。第二可以用这个去各大网站开专栏,录视频,或者开公众号,毕竟有出版社的背书,能更让别人信服你的能力。第三更得用写书时积累的学习方法和上进的态势继续专研更高深技术,技术有了,不仅能到大厂挣更多的钱,还能通过企业培训等方式更高效地挣钱。
diff --git a/docs/high-quality-technical-articles/readme.md b/docs/high-quality-technical-articles/readme.md
index 58a66081727..f68a253c7c6 100644
--- a/docs/high-quality-technical-articles/readme.md
+++ b/docs/high-quality-technical-articles/readme.md
@@ -1,4 +1,3 @@
-
# 程序人生
::: tip 这是一则或许对你有用的小广告
@@ -24,7 +23,7 @@
## 程序员
-- [程序员怎样出版一本技术书](./programmer/how-do-programmers-publish-a-technical-book.md)
+- [程序员怎样出版一本技术书](./programmer/how-do-programmers-publish-a-technical-book.md)
- [程序员高效出书避坑和实践指南](./programmer/efficient-book-publishing-and-practice-guide.md)
## 面试
@@ -32,9 +31,9 @@
- [斩获 20+ 大厂 offer 的面试经验分享](./interview/the-experience-of-get-offer-from-over-20-big-companies.md)
- [一位大龄程序员所经历的面试的历炼和思考](./interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md)
- [从面试官和候选者的角度谈如何准备技术初试](./interview/technical-preliminary-preparation.md)
-- [包装严重的IT行业,作为面试官,我是如何甄别应聘者的包装程度](./interview/screen-candidates-for-packaging.md)
-- [普通人的春招总结(阿里、腾讯offer)](./interview/summary-of-spring-recruitment.md)
-- [2021校招我的个人经历和经验](./interview/my-personal-experience-in-2021.md)
+- [包装严重的 IT 行业,作为面试官,我是如何甄别应聘者的包装程度](./interview/screen-candidates-for-packaging.md)
+- [普通人的春招总结(阿里、腾讯 offer)](./interview/summary-of-spring-recruitment.md)
+- [2021 校招我的个人经历和经验](./interview/my-personal-experience-in-2021.md)
- [如何在技术初试中考察程序员的技术能力](./interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md)
- [阿里技术面试的一些秘密](./interview/some-secrets-about-alibaba-interview.md)
diff --git a/docs/high-quality-technical-articles/work/employee-performance.md b/docs/high-quality-technical-articles/work/employee-performance.md
index 99dcba52a99..8f40afb1bf8 100644
--- a/docs/high-quality-technical-articles/work/employee-performance.md
+++ b/docs/high-quality-technical-articles/work/employee-performance.md
@@ -77,7 +77,7 @@ tag:
另外就是,技术岗的绩效考核不同于销售或者运营岗,很容易指标化。
-需求吞吐量、BUG数、线上事故... 的确有一大堆研发效能指标,但这些指标在绩效考核时是否会被参考?具体又该如何分配比重?本身就是一个扯不清楚的难题。
+需求吞吐量、BUG 数、线上事故... 的确有一大堆研发效能指标,但这些指标在绩效考核时是否会被参考?具体又该如何分配比重?本身就是一个扯不清楚的难题。
最终决定你绩效结果的还是你领导的主观判断。你所见到的 360 环评,以及弄一些指标排序,这些都只是将绩效结果合理化的一种方式,并非关键所在。
@@ -89,7 +89,7 @@ tag:
下面我再展开聊聊,大家最最关心的 A 和 C,它们背后的逻辑。
-## 绩效被打A和C的逻辑是什么?
+## 绩效被打 A 和 C 的逻辑是什么?
“铆足了劲拿不到 A,一不留神居然拿了个 C”,这是绝大多数打工人最真实的职场现状。
@@ -123,10 +123,10 @@ A 和 C 属于绩效的两个极端,背后的逻辑类似,反着理解即可
上面两种打法都是大的思路,还有很多锦上添花的技巧,比如:加强主动汇报(抹平领导的信息差)、让关键干系人给你点赞(能影响到你领导做出绩效决策的人)。
-## 写在最后
+## 写在最后
有人的地方就有江湖,有江湖就一定有规则,大厂平面看似平静,其实在绩效考核、晋升等利益点面前,都是一场厮杀。
当大家攻山头的能力都很强时,**到底做成什么样才算做好了?**当你弄清楚了这个玄机,职场也就看透了。
-如果这篇文章让你有一点启发,来个点赞和在看呀!我是武哥,我们下期见!
\ No newline at end of file
+如果这篇文章让你有一点启发,来个点赞和在看呀!我是武哥,我们下期见!
diff --git a/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md b/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md
index 1845d5cb5ce..011d47ad67b 100644
--- a/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md
+++ b/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md
@@ -91,4 +91,4 @@ tag:
关于如何快速进入工作状态,如果你有好的方法与建议,欢迎在评论区留言。
-最后我们用一张思维导图来回顾一下这篇文章的内容。如果你觉得这篇文章对你有所帮助,可以关注文末公众号,我会经常分享一些自己成长过程中的经验与心得,与大家一起学习与进步。
\ No newline at end of file
+最后我们用一张思维导图来回顾一下这篇文章的内容。如果你觉得这篇文章对你有所帮助,可以关注文末公众号,我会经常分享一些自己成长过程中的经验与心得,与大家一起学习与进步。
diff --git a/docs/home.md b/docs/home.md
index 7058f46d480..1d10c683ab6 100644
--- a/docs/home.md
+++ b/docs/home.md
@@ -20,7 +20,7 @@ title: JavaGuide(Java学习&&面试指南)
[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)
-
+
## 项目相关
@@ -91,7 +91,7 @@ title: JavaGuide(Java学习&&面试指南)
### JVM (必看 :+1:)
-JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
+JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
- **[Java 内存区域](./java/jvm/memory-area.md)**
- **[JVM 垃圾回收](./java/jvm/jvm-garbage-collection.md)**
@@ -167,8 +167,8 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
**常见算法问题总结** :
-- [几道常见的字符串算法题总结 ](./cs-basics/algorithms/string-algorithm-problems.md)
-- [几道常见的链表算法题总结 ](./cs-basics/algorithms/linkedlist-algorithm-problems.md)
+- [几道常见的字符串算法题总结](./cs-basics/algorithms/string-algorithm-problems.md)
+- [几道常见的链表算法题总结](./cs-basics/algorithms/linkedlist-algorithm-problems.md)
- [剑指 offer 部分编程题](./cs-basics/algorithms/the-sword-refers-to-offer.md)
- [十大经典排序算法](./cs-basics/algorithms/10-classical-sorting-algorithms.md)
diff --git a/docs/interview-preparation/interview-experience.md b/docs/interview-preparation/interview-experience.md
index 1c695bb6eba..1954a69bd6d 100644
--- a/docs/interview-preparation/interview-experience.md
+++ b/docs/interview-preparation/interview-experience.md
@@ -19,39 +19,4 @@ category: 知识星球

-欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
-
-
-
-
-
-
-
-
-
-下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
-
-
-
-
-
-
-
-
-
-**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
-
-如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
-
-这里再送一个 30 元的新人优惠券(续费半价)。
-
-
-
-
-
-
-
-
-
-进入星球之后,记得添加微信,我会发你详细的星球使用指南。
-
-
-
-
-
-
-
-
-
+
diff --git a/docs/interview-preparation/key-points-of-interview.md b/docs/interview-preparation/key-points-of-interview.md
index bfe6eab42e1..7d9fe50f961 100644
--- a/docs/interview-preparation/key-points-of-interview.md
+++ b/docs/interview-preparation/key-points-of-interview.md
@@ -34,4 +34,4 @@ category: 面试准备
另外,记录博客或者用自己的理解把对应的知识点讲给别人听也是一个不错的选择。
-最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
\ No newline at end of file
+最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index b0aa15a415a..f7693ced59a 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -71,7 +71,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
## 有没有还不错的项目推荐?
- **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
+**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
@@ -96,7 +96,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
5. **安全** : 项目是否存在安全问题?
6. ......
-另外,我在星球分享过常见的性能优化方向实践案例,涉及到多线程、异步、索引、缓存等方向,强烈推荐你看看:https://t.zsxq.com/06EqfeMZZ 。
+另外,我在星球分享过常见的性能优化方向实践案例,涉及到多线程、异步、索引、缓存等方向,强烈推荐你看看:
-
-
-
-
-
-
-
-我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!
-
-如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://www.yuque.com/docs/share/8a30ffb5-83f3-40f9-baf9-38de68b906dc)(文末有优惠券)。
-
-
-
-
-
-
-
-
+
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index 5ff34aa4eb7..f0fb7effddc 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -61,15 +61,15 @@ category: 知识星球
- **目标企业的官网/公众号** :最及时最权威的获取招聘信息的途径。
- **招聘网站** :[BOSS 直聘](https://www.zhipin.com/)、[智联招聘](https://www.zhaopin.com/)、[拉勾招聘](https://www.lagou.com/)......。
-- **牛客网** :每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址:https://www.nowcoder.com/jobs/recommend/campus 。
-- **超级简历** :超级简历目前整合了各大企业的校园招聘入口,地址:https://www.wondercv.com/jobs/。如果你是校招的话,点击“校招网申”就可以直接跳转到各大企业的校园招聘入口的整合页面了。
+- **牛客网** :每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址:
-
-
-
\ No newline at end of file
+
diff --git a/docs/java/basis/java-basic-questions-01.md b/docs/java/basis/java-basic-questions-01.md
index c9b74aabcbd..27309343f90 100644
--- a/docs/java/basis/java-basic-questions-01.md
+++ b/docs/java/basis/java-basic-questions-01.md
@@ -825,8 +825,6 @@ public class Example {
}
```
-
-
### 静态方法和实例方法有何不同?
**1、调用方式**
@@ -897,14 +895,14 @@ public class Person {
综上:**重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。**
-| 区别点 | 重载方法 | 重写方法 |
-| :--------- | :------- | :----------------------------------------------------------- |
-| 发生范围 | 同一个类 | 子类 |
-| 参数列表 | 必须修改 | 一定不能修改 |
-| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
+| 区别点 | 重载方法 | 重写方法 |
+| :--------- | :------- | :--------------------------------------------------------------- |
+| 发生范围 | 同一个类 | 子类 |
+| 参数列表 | 必须修改 | 一定不能修改 |
+| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
| 异常 | 可修改 | 子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等; |
-| 访问修饰符 | 可修改 | 一定不能做更严格的限制(可以降低限制) |
-| 发生阶段 | 编译期 | 运行期 |
+| 访问修饰符 | 可修改 | 一定不能做更严格的限制(可以降低限制) |
+| 发生阶段 | 编译期 | 运行期 |
**方法的重写要遵循“两同两小一大”**(以下内容摘录自《疯狂 Java 讲义》,[issue#892](https://github.com/Snailclimb/JavaGuide/issues/892) ):
diff --git a/docs/java/basis/java-basic-questions-02.md b/docs/java/basis/java-basic-questions-02.md
index 04f32715e22..afe41d43f0e 100644
--- a/docs/java/basis/java-basic-questions-02.md
+++ b/docs/java/basis/java-basic-questions-02.md
@@ -102,11 +102,11 @@ String str1 = "hello";
String str2 = new String("hello");
String str3 = "hello";
// 使用 == 比较字符串的引用相等
-System.out.println(str1 == str2);
-System.out.println(str1 == str3);
+System.out.println(str1 == str2);
+System.out.println(str1 == str3);
// 使用 equals 方法比较字符串的相等
System.out.println(str1.equals(str2));
-System.out.println(str1.equals(str3));
+System.out.println(str1.equals(str3));
```
@@ -121,8 +121,8 @@ true
从上面的代码输出结果可以看出:
-- `str1` 和 `str2` 不相等,而 `str1` 和 `str3` 相等。这是因为 `==` 运算符比较的是字符串的引用是否相等。
-- `str1` 、 `str2` 、`str3` 三者的内容都相等。这是因为`equals` 方法比较的是字符串的内容,即使这些字符串的对象引用不同,只要它们的内容相等,就认为它们是相等的。
+- `str1` 和 `str2` 不相等,而 `str1` 和 `str3` 相等。这是因为 `==` 运算符比较的是字符串的引用是否相等。
+- `str1` 、 `str2` 、`str3` 三者的内容都相等。这是因为`equals` 方法比较的是字符串的内容,即使这些字符串的对象引用不同,只要它们的内容相等,就认为它们是相等的。
### 如果一个类没有声明构造方法,该程序能正确执行吗?
@@ -548,10 +548,10 @@ public final class String implements java.io.Serializable, Comparable