
@@ -44,7 +44,7 @@
- [Java 基础常见知识点&面试题总结(中)](./docs/java/basis/java-basic-questions-02.md)
- [Java 基础常见知识点&面试题总结(下)](./docs/java/basis/java-basic-questions-03.md)
-**重要知识点详解** :
+**重要知识点详解**:
- [为什么 Java 中只有值传递?](./docs/java/basis/why-there-only-value-passing-in-java.md)
- [Java 序列化详解](./docs/java/basis/serialization.md)
@@ -58,13 +58,13 @@
### 集合
-**知识点/面试题总结** :
+**知识点/面试题总结**:
- [Java 集合常见知识点&面试题总结(上)](./docs/java/collection/java-collection-questions-01.md) (必看 :+1:)
- [Java 集合常见知识点&面试题总结(下)](./docs/java/collection/java-collection-questions-02.md) (必看 :+1:)
- [Java 容器使用注意事项总结](./docs/java/collection/java-collection-precautions-for-use.md)
-**源码分析** :
+**源码分析**:
- [ArrayList 源码+扩容机制分析](./docs/java/collection/arraylist-source-code.md)
- [HashMap(JDK1.8)源码+底层数据结构分析](./docs/java/collection/hashmap-source-code.md)
@@ -84,10 +84,10 @@
- [Java 并发常见知识点&面试题总结(中)](./docs/java/concurrent/java-concurrent-questions-02.md)
- [Java 并发常见知识点&面试题总结(下)](./docs/java/concurrent/java-concurrent-questions-03.md)
-**重要知识点详解** :
+**重要知识点详解**:
- [JMM(Java 内存模型)详解](./docs/java/concurrent/jmm.md)
-- **线程池** :[Java 线程池详解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./docs/java/concurrent/java-thread-pool-best-practices.md)
+- **线程池**:[Java 线程池详解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./docs/java/concurrent/java-thread-pool-best-practices.md)
- [ThreadLocal 详解](./docs/java/concurrent/threadlocal.md)
- [Java 并发容器总结](./docs/java/concurrent/java-concurrent-collections.md)
- [Atomic 原子类总结](./docs/java/concurrent/atomic-classes.md)
@@ -109,7 +109,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
### 新特性
-- **Java 8** :[Java 8 新特性总结(翻译)](./docs/java/new-features/java8-tutorial-translate.md)、[Java8 常用新特性总结](./docs/java/new-features/java8-common-new-features.md)
+- **Java 8**:[Java 8 新特性总结(翻译)](./docs/java/new-features/java8-tutorial-translate.md)、[Java8 常用新特性总结](./docs/java/new-features/java8-common-new-features.md)
- [Java 9 新特性概览](./docs/java/new-features/java9.md)
- [Java 10 新特性概览](./docs/java/new-features/java10.md)
- [Java 11 新特性概览](./docs/java/new-features/java11.md)
@@ -127,19 +127,19 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
- [操作系统常见知识点&面试题总结(上)](./docs/cs-basics/operating-system/operating-system-basic-questions-01.md)
- [操作系统常见知识点&面试题总结(下)](./docs/cs-basics/operating-system/operating-system-basic-questions-02.md)
-- **Linux** :
+- **Linux**:
- [后端程序员必备的 Linux 基础知识总结](./docs/cs-basics/operating-system/linux-intro.md)
- [Shell 编程基础知识总结](./docs/cs-basics/operating-system/shell-intro.md)
### 网络
-**知识点/面试题总结** :
+**知识点/面试题总结**:
- [计算机网络常见知识点&面试题总结(上)](./docs/cs-basics/network/other-network-questions.md)
- [计算机网络常见知识点&面试题总结(下)](./docs/cs-basics/network/other-network-questions2.md)
- [谢希仁老师的《计算机网络》内容总结(补充)](./docs/cs-basics/network/computer-network-xiexiren-summary.md)
-**重要知识点详解** :
+**重要知识点详解**:
- [OSI 和 TCP/IP 网络分层模型详解(基础)](./docs/cs-basics/network/osi-and-tcp-ip-model.md)
- [应用层常见协议总结(应用层)](./docs/cs-basics/network/application-layer-protocol.md)
@@ -160,9 +160,9 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
- [线性数据结构 :数组、链表、栈、队列](./docs/cs-basics/data-structure/linear-data-structure.md)
- [图](./docs/cs-basics/data-structure/graph.md)
- [堆](./docs/cs-basics/data-structure/heap.md)
-- [树](./docs/cs-basics/data-structure/tree.md) :重点关注[红黑树](./docs/cs-basics/data-structure/red-black-tree.md)、B-,B+,B\*树、LSM 树
+- [树](./docs/cs-basics/data-structure/tree.md):重点关注[红黑树](./docs/cs-basics/data-structure/red-black-tree.md)、B-,B+,B\*树、LSM 树
-其他常用数据结构 :
+其他常用数据结构:
- [布隆过滤器](./docs/cs-basics/data-structure/bloom-filter.md)
@@ -173,7 +173,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
- [算法学习书籍+资源推荐](https://www.zhihu.com/question/323359308/answer/1545320858) 。
- [如何刷 Leetcode?](https://www.zhihu.com/question/31092580/answer/1534887374)
-**常见算法问题总结** :
+**常见算法问题总结**:
- [几道常见的字符串算法题总结 ](./docs/cs-basics/algorithms/string-algorithm-problems.md)
- [几道常见的链表算法题总结 ](./docs/cs-basics/algorithms/linkedlist-algorithm-problems.md)
@@ -285,7 +285,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
- [Spring/Spring Boot 常用注解总结](./docs/system-design/framework/spring/spring-common-annotations.md)
- [SpringBoot 入门指南](https://github.com/Snailclimb/springboot-guide)
-**重要知识点详解** :
+**重要知识点详解**:
- [Spring 事务详解](./docs/system-design/framework/spring/spring-transaction.md)
- [Spring 中的设计模式详解](./docs/system-design/framework/spring/spring-design-patterns-summary.md)
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index e0421dd4fe1..9d7f835d3bb 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -116,9 +116,9 @@ tag:
通常来说,写下面这些方向的博客会比较好:
-1. **详细讲解某个知识点** :一定要有自己的思考而不是东拼西凑。不仅要介绍知识点的基本概念和原理,还需要适当结合实际案例和应用场景进行举例说明。
-2. **问题排查/性能优化经历** :需要详细描述清楚具体的场景以及解决办法。一定要有足够的细节描述,包括出现问题的具体场景、问题的根本原因、解决问题的思路和具体步骤等等。同时,要注重实践性和可操作性,帮助读者更好地学习理解。
-3. **源码阅读记录** :从一个功能点出发描述其底层源码实现,谈谈你从源码中学到了什么。
+1. **详细讲解某个知识点**:一定要有自己的思考而不是东拼西凑。不仅要介绍知识点的基本概念和原理,还需要适当结合实际案例和应用场景进行举例说明。
+2. **问题排查/性能优化经历**:需要详细描述清楚具体的场景以及解决办法。一定要有足够的细节描述,包括出现问题的具体场景、问题的根本原因、解决问题的思路和具体步骤等等。同时,要注重实践性和可操作性,帮助读者更好地学习理解。
+3. **源码阅读记录**:从一个功能点出发描述其底层源码实现,谈谈你从源码中学到了什么。
最重要的是一定要重视 Markdown 规范,不然内容再好也会显得不专业。
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index c4441fb7d6a..41f5cb04c27 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -123,11 +123,11 @@ star: 2
## 如何加入?
-**方式一** :扫描下面的二维码原价加入(续费半价)。
+**方式一**:扫描下面的二维码原价加入(续费半价)。
-**方式二(推荐)** :添加我的个人微信(**javaguide1024**)领取一个 **30** 元的星球专属优惠券(一定要备注“优惠卷”)。
+**方式二(推荐)**:添加我的个人微信(**javaguide1024**)领取一个 **30** 元的星球专属优惠券(一定要备注“优惠卷”)。
**一定要备注“优惠卷”**,不然通过不了。
diff --git a/docs/books/cs-basics.md b/docs/books/cs-basics.md
index 8acdbe4ad31..e67ac115964 100644
--- a/docs/books/cs-basics.md
+++ b/docs/books/cs-basics.md
@@ -36,12 +36,12 @@ head:
其他相关书籍推荐:
-- **[《自己动手写操作系统》](https://book.douban.com/subject/1422377/)** :不光会带着你详细分析操作系统原理的基础,还会用丰富的实例代码,一步一步地指导你用 C 语言和汇编语言编写出一个具备操作系统基本功能的操作系统框架。
-- **[《现代操作系统》](https://book.douban.com/subject/3852290/)** :内容很不错,不过,翻译的一般。如果你是精读本书的话,建议把课后习题都做了。
-- **[《操作系统真象还原》](https://book.douban.com/subject/26745156/)** :这本书的作者毕业于北京大学,前百度运维高级工程师。因为在大学期间曾重修操作系统这一科,后对操作系统进行深入研究,著下此书。
-- **[《深度探索 Linux 操作系统》](https://book.douban.com/subject/25743846/)** :跟着这本书的内容走,可以让你对如何制作一套完善的 GNU/Linux 系统有了清晰的认识。
-- **[《操作系统设计与实现》](https://book.douban.com/subject/2044818/)** :操作系统的权威教学教材。
-- **[《Orange'S:一个操作系统的实现》](https://book.douban.com/subject/3735649/)** :从只有二十行的引导扇区代码出发,一步一步地向读者呈现一个操作系统框架的完成过程。配合《操作系统设计与实现》一起食用更佳!
+- **[《自己动手写操作系统》](https://book.douban.com/subject/1422377/)**:不光会带着你详细分析操作系统原理的基础,还会用丰富的实例代码,一步一步地指导你用 C 语言和汇编语言编写出一个具备操作系统基本功能的操作系统框架。
+- **[《现代操作系统》](https://book.douban.com/subject/3852290/)**:内容很不错,不过,翻译的一般。如果你是精读本书的话,建议把课后习题都做了。
+- **[《操作系统真象还原》](https://book.douban.com/subject/26745156/)**:这本书的作者毕业于北京大学,前百度运维高级工程师。因为在大学期间曾重修操作系统这一科,后对操作系统进行深入研究,著下此书。
+- **[《深度探索 Linux 操作系统》](https://book.douban.com/subject/25743846/)**:跟着这本书的内容走,可以让你对如何制作一套完善的 GNU/Linux 系统有了清晰的认识。
+- **[《操作系统设计与实现》](https://book.douban.com/subject/2044818/)**:操作系统的权威教学教材。
+- **[《Orange'S:一个操作系统的实现》](https://book.douban.com/subject/3735649/)**:从只有二十行的引导扇区代码出发,一步一步地向读者呈现一个操作系统框架的完成过程。配合《操作系统设计与实现》一起食用更佳!
如果你比较喜欢看视频的话,推荐哈工大李治军老师主讲的慕课 [《操作系统》](https://www.icourse163.org/course/HIT-1002531008),内容质量吊打一众国家精品课程。
@@ -79,8 +79,8 @@ head:
如果你觉得上面这本书看着比较枯燥的话,我强烈推荐+安利你看看下面这两本非常有趣的网络相关的书籍:
-- [《图解 HTTP》](https://book.douban.com/subject/25863515/ "《图解 HTTP》") :讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
-- [《网络是怎样连接的》](https://book.douban.com/subject/26941639/ "《网络是怎样连接的》") :从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。
+- [《图解 HTTP》](https://book.douban.com/subject/25863515/ "《图解 HTTP》"):讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
+- [《网络是怎样连接的》](https://book.douban.com/subject/26941639/ "《网络是怎样连接的》"):从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。
@@ -95,11 +95,11 @@ GitHub 上就有一些名校的计算机网络试验/Project:
我知道,还有很多小伙伴可能比较喜欢边看视频边学习。所以,我这里再推荐几个顶好的计算机网络视频讲解。
-**1、[哈工大的计算机网络课程](http://www.icourse163.org/course/HIT-154005)** :国家精品课程,截止目前已经开了 10 次课了。大家对这门课的评价都非常高!所以,非常推荐大家看一下!
+**1、[哈工大的计算机网络课程](http://www.icourse163.org/course/HIT-154005)**:国家精品课程,截止目前已经开了 10 次课了。大家对这门课的评价都非常高!所以,非常推荐大家看一下!
-**2、[王道考研的计算机网络](https://www.bilibili.com/video/BV19E411D78Q?from=search&seid=17198507506906312317)** :非常适合 CS 专业考研的小朋友!这个视频目前在哔哩哔哩上已经有 1.6w+ 的点赞。
+**2、[王道考研的计算机网络](https://www.bilibili.com/video/BV19E411D78Q?from=search&seid=17198507506906312317)**:非常适合 CS 专业考研的小朋友!这个视频目前在哔哩哔哩上已经有 1.6w+ 的点赞。

@@ -185,7 +185,7 @@ GitHub 上就有一些名校的计算机网络试验/Project:
质量很高,介绍了常用的数据结构和算法。
-类似的还有 **[《数据结构与算法分析 :C 语言描述》](https://book.douban.com/subject/1139426/)**、**[《数据结构与算法分析:C++ 描述》](https://book.douban.com/subject/1971825/)**
+类似的还有 **[《数据结构与算法分析:C 语言描述》](https://book.douban.com/subject/1139426/)**、**[《数据结构与算法分析:C++ 描述》](https://book.douban.com/subject/1971825/)**
@@ -266,8 +266,8 @@ GitHub 上就有一些名校的计算机网络试验/Project:
其他书籍推荐:
-- **[《现代编译原理》](https://book.douban.com/subject/30191414/)** :编译原理的入门书。
-- **[《编译器设计》](https://book.douban.com/subject/20436488/)** :覆盖了编译器从前端到后端的全部主题。
+- **[《现代编译原理》](https://book.douban.com/subject/30191414/)**:编译原理的入门书。
+- **[《编译器设计》](https://book.douban.com/subject/20436488/)**:覆盖了编译器从前端到后端的全部主题。
我上面推荐的书籍的难度还是比较高的,真心很难坚持看完。这里强烈推荐[哈工大的编译原理视频课程](https://www.icourse163.org/course/HIT-1002123007),真心不错,还是国家精品课程,关键还是又漂亮有温柔的美女老师讲的!
diff --git a/docs/books/database.md b/docs/books/database.md
index 164b810159d..925b1419fc2 100644
--- a/docs/books/database.md
+++ b/docs/books/database.md
@@ -54,9 +54,9 @@ GitHub 上也已经有大佬用 Java 实现过一个简易的数据库,介绍
一般企业项目开发中,使用 MySQL 比较多。如果你要学习 MySQL 的话,可以看下面这 3 本书籍:
-- **[《MySQL 必知必会》](https://book.douban.com/subject/3354490/)** :非常薄!非常适合 MySQL 新手阅读,很棒的入门教材。
-- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)** :MySQL 领域的经典之作!学习 MySQL 必看!属于进阶内容,主要教你如何更好地使用 MySQL 。既有有理论,又有实践!如果你没时间都看一遍的话,我建议第 5 章(创建高性能的索引)、第 6 章(查询性能优化) 你一定要认真看一下。
-- **[《MySQL 技术内幕》](https://book.douban.com/subject/24708143/)** :你想深入了解 MySQL 存储引擎的话,看这本书准没错!
+- **[《MySQL 必知必会》](https://book.douban.com/subject/3354490/)**:非常薄!非常适合 MySQL 新手阅读,很棒的入门教材。
+- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)**:MySQL 领域的经典之作!学习 MySQL 必看!属于进阶内容,主要教你如何更好地使用 MySQL 。既有有理论,又有实践!如果你没时间都看一遍的话,我建议第 5 章(创建高性能的索引)、第 6 章(查询性能优化) 你一定要认真看一下。
+- **[《MySQL 技术内幕》](https://book.douban.com/subject/24708143/)**:你想深入了解 MySQL 存储引擎的话,看这本书准没错!

diff --git a/docs/books/distributed-system.md b/docs/books/distributed-system.md
index e712ecfea3b..d8f6e64b1ce 100644
--- a/docs/books/distributed-system.md
+++ b/docs/books/distributed-system.md
@@ -87,5 +87,5 @@ icon: "distributed-network"
## 其他
-- [《分布式系统 : 概念与设计》](https://book.douban.com/subject/21624776/) :偏教材类型,内容全而无趣,可作为参考书籍;
-- [《分布式架构原理与实践》](https://book.douban.com/subject/35689350/) :2021 年出版的,没什么热度,我也还没看过。
+- [《分布式系统 : 概念与设计》](https://book.douban.com/subject/21624776/):偏教材类型,内容全而无趣,可作为参考书籍;
+- [《分布式架构原理与实践》](https://book.douban.com/subject/35689350/):2021 年出版的,没什么热度,我也还没看过。
diff --git a/docs/books/java.md b/docs/books/java.md
index 0d4c5ecabe8..d1fa4af679d 100644
--- a/docs/books/java.md
+++ b/docs/books/java.md
@@ -122,10 +122,10 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
非常重要!非常重要!特别是 Git 和 Docker。
-- **IDEA** :熟悉基本操作以及常用快捷。你可以通过 GitHub 上的开源教程 [《IntelliJ IDEA 简体中文专题教程》](https://github.com/judasn/IntelliJ-IDEA-Tutorial) 来学习 IDEA 的使用。
-- **Maven** :强烈建议学习常用框架之前可以提前花几天时间学习一下**Maven**的使用。(到处找 Jar 包,下载 Jar 包是真的麻烦费事,使用 Maven 可以为你省很多事情)。
+- **IDEA**:熟悉基本操作以及常用快捷。你可以通过 GitHub 上的开源教程 [《IntelliJ IDEA 简体中文专题教程》](https://github.com/judasn/IntelliJ-IDEA-Tutorial) 来学习 IDEA 的使用。
+- **Maven**:强烈建议学习常用框架之前可以提前花几天时间学习一下**Maven**的使用。(到处找 Jar 包,下载 Jar 包是真的麻烦费事,使用 Maven 可以为你省很多事情)。
- **Git**:基本的 Git 技能也是必备的,试着在学习的过程中将自己的代码托管在 Github 上。你可以看看这篇 Github 上开源的 [《Git 极简入门》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Git) 。
-- **Docker** :学着用 Docker 安装学习中需要用到的软件比如 MySQL ,这样方便很多,可以为你节省不少时间。你可以看看这篇 Github 上开源的 [《Docker 基本概念解读》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker) 、[《一文搞懂 Docker 镜像的常用操作!》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker-Image)
+- **Docker**:学着用 Docker 安装学习中需要用到的软件比如 MySQL ,这样方便很多,可以为你节省不少时间。你可以看看这篇 Github 上开源的 [《Docker 基本概念解读》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker) 、[《一文搞懂 Docker 镜像的常用操作!》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Docker-Image)
除了这些工具之外,我强烈建议你一定要搞懂 GitHub 的使用。一些使用 GitHub 的小技巧,你可以看[《GitHub 小技巧》](https://snailclimb.gitee.io/javaguide/#/docs/tools/Github%E6%8A%80%E5%B7%A7)这篇文章。
@@ -229,6 +229,6 @@ O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是
[JavaGuide](https://javaguide.cn/) 的面试版本,涵盖了 Java 后端方面的大部分知识点比如 集合、JVM、多线程还有数据库 MySQL 等内容。
-公众号后台回复 :“**面试突击**” 即可免费获取,无任何套路。
+公众号后台回复:“**面试突击**” 即可免费获取,无任何套路。

diff --git a/docs/books/software-quality.md b/docs/books/software-quality.md
index 7978b919967..5cfce79dfaa 100644
--- a/docs/books/software-quality.md
+++ b/docs/books/software-quality.md
@@ -120,12 +120,12 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
## 其他
-- [《代码的未来》](https://book.douban.com/subject/24536403/) :这本书的作者是 Ruby 之父松本行弘,算是一本年代比较久远的书籍(13 年出版),不过,还是非常值得一读。这本书的内容主要介绍是编程/编程语言的本质。我个人还是比较喜欢松本行弘的文字风格,并且,你看他的文章也确实能够有所收获。
-- [《深入浅出设计模式》](https://book.douban.com/subject/1488876/) :比较有趣的风格,适合设计模式入门。
-- [《软件架构设计:大型网站技术架构与业务架构融合之道》](https://book.douban.com/subject/30443578/) :内容非常全面。适合面试前突击一些比较重要的理论知识,也适合拿来扩充/完善自己的技术广度。
-- [《微服务架构设计模式》](https://book.douban.com/subject/33425123/) :这本书是世界十大软件架构师之一、微服务架构先驱 Chris Richardson 亲笔撰写,豆瓣评分 9.6。示例代码使用 Java 语言和 Spring 框架。帮助你设计、实现、测试和部署基于微服务的应用程序。
+- [《代码的未来》](https://book.douban.com/subject/24536403/):这本书的作者是 Ruby 之父松本行弘,算是一本年代比较久远的书籍(13 年出版),不过,还是非常值得一读。这本书的内容主要介绍是编程/编程语言的本质。我个人还是比较喜欢松本行弘的文字风格,并且,你看他的文章也确实能够有所收获。
+- [《深入浅出设计模式》](https://book.douban.com/subject/1488876/):比较有趣的风格,适合设计模式入门。
+- [《软件架构设计:大型网站技术架构与业务架构融合之道》](https://book.douban.com/subject/30443578/):内容非常全面。适合面试前突击一些比较重要的理论知识,也适合拿来扩充/完善自己的技术广度。
+- [《微服务架构设计模式》](https://book.douban.com/subject/33425123/):这本书是世界十大软件架构师之一、微服务架构先驱 Chris Richardson 亲笔撰写,豆瓣评分 9.6。示例代码使用 Java 语言和 Spring 框架。帮助你设计、实现、测试和部署基于微服务的应用程序。
最后再推荐两个相关的文档:
-- **阿里巴巴 Java 开发手册** :
+- **阿里巴巴 Java 开发手册**:
- **Google Java 编程风格指南**:
diff --git a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
index 32c745a9d6f..fa88a078a57 100644
--- a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
+++ b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
@@ -17,8 +17,8 @@ tag:
排序算法可以分为:
-- **内部排序** :数据记录在内存中进行排序。
-- **[外部排序](https://zh.wikipedia.org/wiki/外排序)** :因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
+- **内部排序**:数据记录在内存中进行排序。
+- **[外部排序](https://zh.wikipedia.org/wiki/外排序)**:因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
常见的内部排序算法有:**插入排序**、**希尔排序**、**选择排序**、**冒泡排序**、**归并排序**、**快速排序**、**堆排序**、**基数排序**等,本文只讲解内部排序算法。用一张图概括:
@@ -104,9 +104,9 @@ public static int[] bubbleSort(int[] arr) {
### 算法分析
- **稳定性**:稳定
-- **时间复杂度** :最佳:O(n) ,最差:O(n2), 平均:O(n2)
-- **空间复杂度** :O(1)
-- **排序方式** :In-place
+- **时间复杂度**:最佳:O(n) ,最差:O(n2), 平均:O(n2)
+- **空间复杂度**:O(1)
+- **排序方式**:In-place
## 选择排序 (Selection Sort)
@@ -151,9 +151,9 @@ public static int[] selectionSort(int[] arr) {
### 算法分析
- **稳定性**:不稳定
-- **时间复杂度** :最佳:O(n2) ,最差:O(n2), 平均:O(n2)
-- **空间复杂度** :O(1)
-- **排序方式** :In-place
+- **时间复杂度**:最佳:O(n2) ,最差:O(n2), 平均:O(n2)
+- **空间复杂度**:O(1)
+- **排序方式**:In-place
## 插入排序 (Insertion Sort)
@@ -201,9 +201,9 @@ public static int[] insertionSort(int[] arr) {
### 算法分析
- **稳定性**:稳定
-- **时间复杂度** :最佳:O(n) ,最差:O(n2), 平均:O(n2)
-- **空间复杂度** :O(1)
-- **排序方式** :In-place
+- **时间复杂度**:最佳:O(n) ,最差:O(n2), 平均:O(n2)
+- **空间复杂度**:O(1)
+- **排序方式**:In-place
## 希尔排序 (Shell Sort)
@@ -258,8 +258,8 @@ public static int[] shellSort(int[] arr) {
### 算法分析
- **稳定性**:不稳定
-- **时间复杂度** :最佳:O(nlogn), 最差:O(n2) 平均:O(nlogn)
-- **空间复杂度** :`O(1)`
+- **时间复杂度**:最佳:O(nlogn), 最差:O(n2) 平均:O(nlogn)
+- **空间复杂度**:`O(1)`
## 归并排序 (Merge Sort)
@@ -341,8 +341,8 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
### 算法分析
- **稳定性**:稳定
-- **时间复杂度** :最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
-- **空间复杂度** :O(n)
+- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
+- **空间复杂度**:O(n)
## 快速排序 (Quick Sort)
@@ -395,9 +395,9 @@ public static void quickSort(int[] array, int low, int high) {
### 算法分析
-- **稳定性** :不稳定
-- **时间复杂度** :最佳:O(nlogn), 最差:O(nlogn),平均:O(nlogn)
-- **空间复杂度** :O(nlogn)
+- **稳定性**:不稳定
+- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn),平均:O(nlogn)
+- **空间复杂度**:O(nlogn)
## 堆排序 (Heap Sort)
@@ -484,9 +484,9 @@ public static int[] heapSort(int[] arr) {
### 算法分析
-- **稳定性** :不稳定
-- **时间复杂度** :最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
-- **空间复杂度** :O(1)
+- **稳定性**:不稳定
+- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
+- **空间复杂度**:O(1)
## 计数排序 (Counting Sort)
@@ -564,9 +564,9 @@ public static int[] countingSort(int[] arr) {
当输入的元素是 `n` 个 `0` 到 `k` 之间的整数时,它的运行时间是 `O(n+k)`。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组 `C` 的长度取决于待排序数组中数据的范围(等于待排序数组的**最大值与最小值的差加上 1**),这使得计数排序对于数据范围很大的数组,需要大量额外内存空间。
-- **稳定性** :稳定
-- **时间复杂度** :最佳:`O(n+k)` 最差:`O(n+k)` 平均:`O(n+k)`
-- **空间复杂度** :`O(k)`
+- **稳定性**:稳定
+- **时间复杂度**:最佳:`O(n+k)` 最差:`O(n+k)` 平均:`O(n+k)`
+- **空间复杂度**:`O(k)`
## 桶排序 (Bucket Sort)
@@ -647,9 +647,9 @@ public static List
bucketSort(List arr, int bucket_size) {
### 算法分析
-- **稳定性** :稳定
-- **时间复杂度** :最佳:`O(n+k)` 最差:`O(n²)` 平均:`O(n+k)`
-- **空间复杂度** :`O(k)`
+- **稳定性**:稳定
+- **时间复杂度**:最佳:`O(n+k)` 最差:`O(n²)` 平均:`O(n+k)`
+- **空间复杂度**:`O(k)`
## 基数排序 (Radix Sort)
@@ -715,9 +715,9 @@ public static int[] radixSort(int[] arr) {
### 算法分析
-- **稳定性** :稳定
-- **时间复杂度** :最佳:`O(n×k)` 最差:`O(n×k)` 平均:`O(n×k)`
-- **空间复杂度** :`O(n+k)`
+- **稳定性**:稳定
+- **时间复杂度**:最佳:`O(n×k)` 最差:`O(n×k)` 平均:`O(n×k)`
+- **空间复杂度**:`O(n+k)`
**基数排序 vs 计数排序 vs 桶排序**
diff --git a/docs/cs-basics/algorithms/linkedlist-algorithm-problems.md b/docs/cs-basics/algorithms/linkedlist-algorithm-problems.md
index a3a905ca713..91552af11de 100644
--- a/docs/cs-basics/algorithms/linkedlist-algorithm-problems.md
+++ b/docs/cs-basics/algorithms/linkedlist-algorithm-problems.md
@@ -293,8 +293,8 @@ public class Solution {
**复杂度分析:**
-- **时间复杂度 O(L)** :该算法对列表进行了两次遍历,首先计算了列表的长度 LL 其次找到第 (L - n)(L−n) 个结点。 操作执行了 2L-n2L−n 步,时间复杂度为 O(L)O(L)。
-- **空间复杂度 O(1)** :我们只用了常量级的额外空间。
+- **时间复杂度 O(L)**:该算法对列表进行了两次遍历,首先计算了列表的长度 LL 其次找到第 (L - n)(L−n) 个结点。 操作执行了 2L-n2L−n 步,时间复杂度为 O(L)O(L)。
+- **空间复杂度 O(1)**:我们只用了常量级的额外空间。
**进阶——一次遍历法:**
diff --git a/docs/cs-basics/data-structure/bloom-filter.md b/docs/cs-basics/data-structure/bloom-filter.md
index a9255ddabca..1171ed59ffc 100644
--- a/docs/cs-basics/data-structure/bloom-filter.md
+++ b/docs/cs-basics/data-structure/bloom-filter.md
@@ -239,13 +239,13 @@ System.out.println(filter.mightContain(2));
### 介绍
-Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
+Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍:https://redis.io/modules
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
其他还有:
- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
-- pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
+- pyreBloom(Python 中的快速 Redis 布隆过滤器):https://github.com/seomoz/pyreBloom
- ......
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
@@ -270,7 +270,7 @@ root@21396d02c252:/data# redis-cli
1. **`BF.ADD`**:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:`BF.ADD {key} {item}`。
2. **`BF.MADD`** : 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式`BF.ADD`与之相同,只不过它允许多个输入并返回多个值。格式:`BF.MADD {key} {item} [item ...]` 。
3. **`BF.EXISTS`** : 确定元素是否在布隆过滤器中存在。格式:`BF.EXISTS {key} {item}`。
-4. **`BF.MEXISTS`** :确定一个或者多个元素是否在布隆过滤器中存在格式:`BF.MEXISTS {key} {item} [item ...]`。
+4. **`BF.MEXISTS`**:确定一个或者多个元素是否在布隆过滤器中存在格式:`BF.MEXISTS {key} {item} [item ...]`。
另外, `BF. RESERVE` 命令需要单独介绍一下:
diff --git a/docs/cs-basics/data-structure/heap.md b/docs/cs-basics/data-structure/heap.md
index e9a122c8b3c..ea77e70d838 100644
--- a/docs/cs-basics/data-structure/heap.md
+++ b/docs/cs-basics/data-structure/heap.md
@@ -41,8 +41,8 @@ tag:
堆分为 **最大堆** 和 **最小堆**。二者的区别在于节点的排序方式。
-- **最大堆** :堆中的每一个节点的值都大于等于子树中所有节点的值
-- **最小堆** :堆中的每一个节点的值都小于等于子树中所有节点的值
+- **最大堆**:堆中的每一个节点的值都大于等于子树中所有节点的值
+- **最小堆**:堆中的每一个节点的值都小于等于子树中所有节点的值
如下图所示,图 1 是最大堆,图 2 是最小堆
@@ -123,8 +123,8 @@ tag:
### 堆的操作总结
-- **插入元素** :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
-- **删除堆顶元素** :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
+- **插入元素**:先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
+- **删除堆顶元素**:删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
## 堆排序
diff --git a/docs/cs-basics/data-structure/linear-data-structure.md b/docs/cs-basics/data-structure/linear-data-structure.md
index ac73f354105..7d7e8cc1020 100644
--- a/docs/cs-basics/data-structure/linear-data-structure.md
+++ b/docs/cs-basics/data-structure/linear-data-structure.md
@@ -302,7 +302,7 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
-- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如 :`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
+- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如:`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
- Linux 内核进程队列(按优先级排队)
- 现实生活中的派对,播放器上的播放列表;
- 消息队列
diff --git a/docs/cs-basics/data-structure/red-black-tree.md b/docs/cs-basics/data-structure/red-black-tree.md
index 9ccbf6a52ac..11043f45d0c 100644
--- a/docs/cs-basics/data-structure/red-black-tree.md
+++ b/docs/cs-basics/data-structure/red-black-tree.md
@@ -14,8 +14,8 @@ tag:
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
-**红黑树的应用** :TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。
+**红黑树的应用**:TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。
**为什么要用红黑树?** 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
-**相关阅读** :[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
+**相关阅读**:[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
diff --git a/docs/cs-basics/data-structure/tree.md b/docs/cs-basics/data-structure/tree.md
index eb1c7a337fe..eb9d9964857 100644
--- a/docs/cs-basics/data-structure/tree.md
+++ b/docs/cs-basics/data-structure/tree.md
@@ -19,16 +19,16 @@ tag:
如上图所示,通过上面这张图说明一下树中的常用概念:
-- **节点** :树中的每个元素都可以统称为节点。
-- **根节点** :顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
-- **父节点** :若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
-- **子节点** :一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
-- **兄弟节点** :具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
-- **叶子节点** :没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
-- **节点的高度** :该节点到叶子节点的最长路径所包含的边数。
-- **节点的深度** :根节点到该节点的路径所包含的边数
-- **节点的层数** :节点的深度+1。
-- **树的高度** :根节点的高度。
+- **节点**:树中的每个元素都可以统称为节点。
+- **根节点**:顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
+- **父节点**:若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
+- **子节点**:一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
+- **兄弟节点**:具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
+- **叶子节点**:没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
+- **节点的高度**:该节点到叶子节点的最长路径所包含的边数。
+- **节点的深度**:根节点到该节点的路径所包含的边数
+- **节点的层数**:节点的深度+1。
+- **树的高度**:根节点的高度。
> 关于树的深度和高度的定义可以看 stackoverflow 上的这个问题:[What is the difference between tree depth and height?](https://stackoverflow.com/questions/2603692/what-is-the-difference-between-tree-depth-and-height) 。
diff --git a/docs/cs-basics/network/application-layer-protocol.md b/docs/cs-basics/network/application-layer-protocol.md
index eb28c5df2d2..fd8ceec55a1 100644
--- a/docs/cs-basics/network/application-layer-protocol.md
+++ b/docs/cs-basics/network/application-layer-protocol.md
@@ -98,8 +98,8 @@ RTP(Real-time Transport Protocol,实时传输协议)通常基于 UDP 协
RTP 协议分为两种子协议:
-- **RTP(Real-time Transport Protocol,实时传输协议)** :传输具有实时特性的数据。
-- **RTCP(RTP Control Protocol,RTP 控制协议)** :提供实时传输过程中的统计信息(如网络延迟、丢包率等),WebRTC 正是根据这些信息处理丢包
+- **RTP(Real-time Transport Protocol,实时传输协议)**:传输具有实时特性的数据。
+- **RTCP(RTP Control Protocol,RTP 控制协议)**:提供实时传输过程中的统计信息(如网络延迟、丢包率等),WebRTC 正是根据这些信息处理丢包
## DNS:域名系统
diff --git a/docs/cs-basics/network/computer-network-xiexiren-summary.md b/docs/cs-basics/network/computer-network-xiexiren-summary.md
index 7ee06b57c75..9e87de2242a 100644
--- a/docs/cs-basics/network/computer-network-xiexiren-summary.md
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -15,41 +15,41 @@ tag:
### 1.1. 基本术语
-1. **结点 (node)** :网络中的结点可以是计算机,集线器,交换机或路由器等。
+1. **结点 (node)**:网络中的结点可以是计算机,集线器,交换机或路由器等。
2. **链路(link )** : 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-3. **主机(host)** :连接在因特网上的计算机。
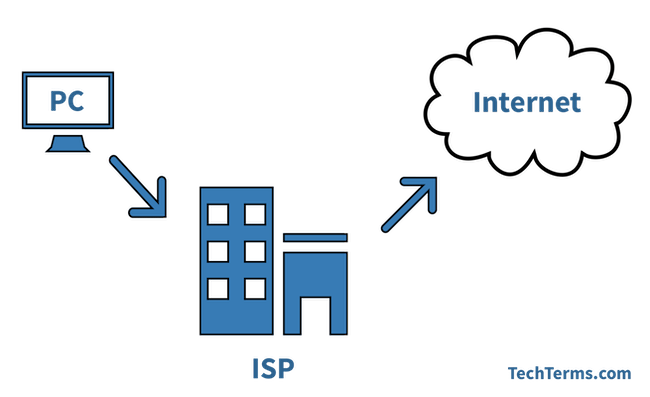
-4. **ISP(Internet Service Provider)** :因特网服务提供者(提供商)。
+3. **主机(host)**:连接在因特网上的计算机。
+4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
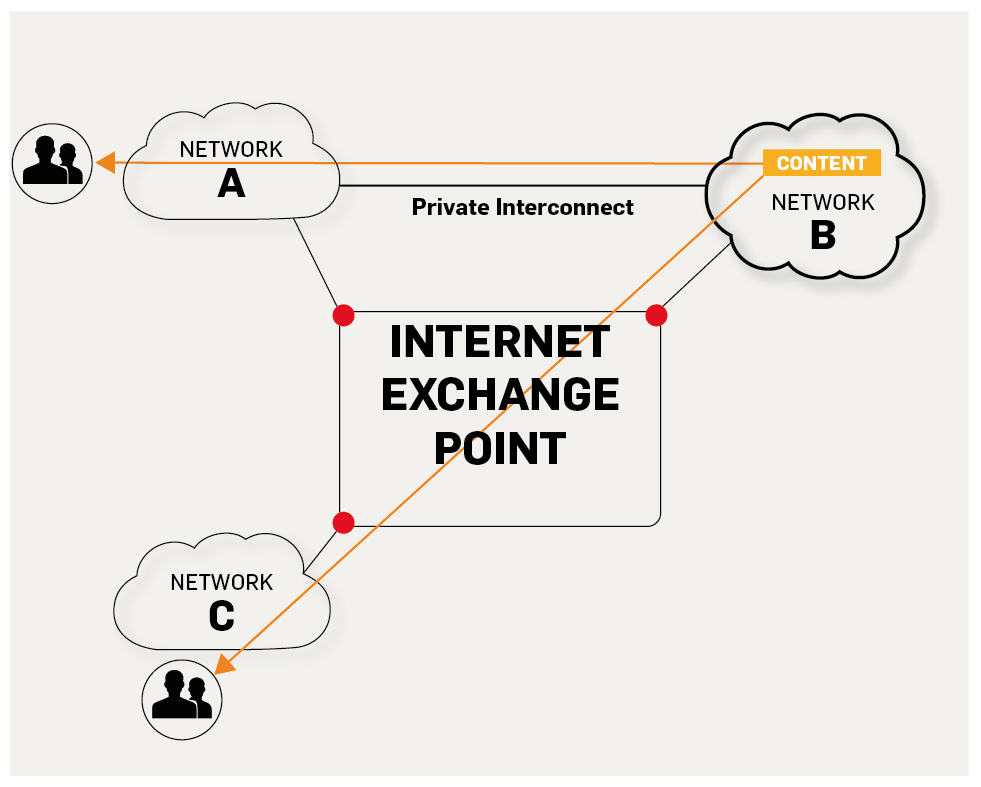
-5. **IXP(Internet eXchange Point)** :互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
+5. **IXP(Internet eXchange Point)**:互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
-6. **RFC(Request For Comments)** :意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
-7. **广域网 WAN(Wide Area Network)** :任务是通过长距离运送主机发送的数据。
+6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
+7. **广域网 WAN(Wide Area Network)**:任务是通过长距离运送主机发送的数据。
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
-9. **局域网 LAN(Local Area Network)** :学校或企业大多拥有多个互连的局域网。
+9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
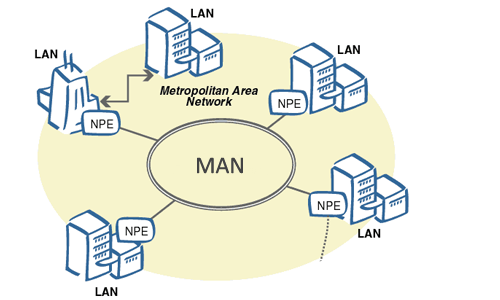
http://conexionesmanwman.blogspot.com/
-10. **个人区域网 PAN(Personal Area Network)** :在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
+10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
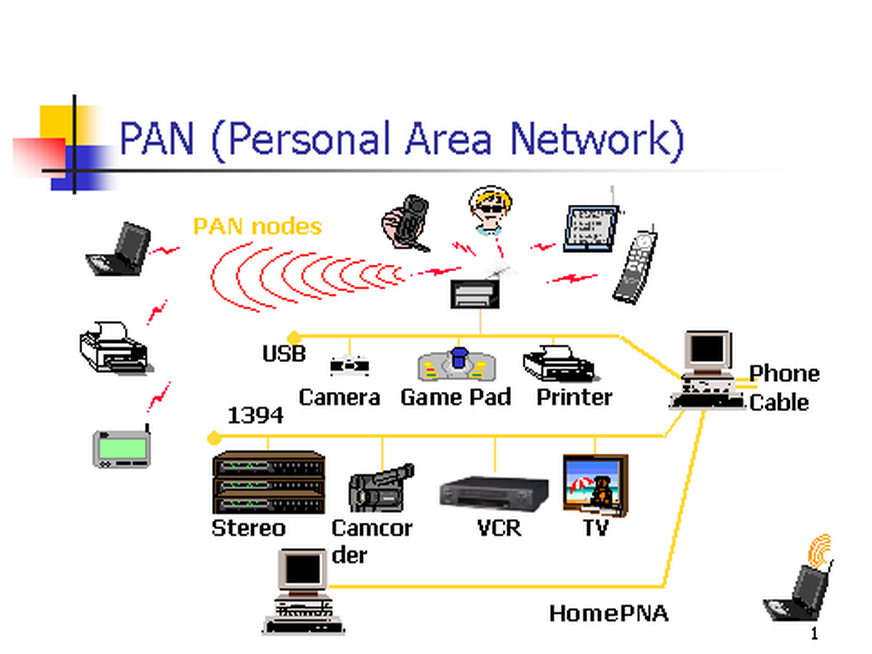
https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
-12. **分组(packet )** :因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
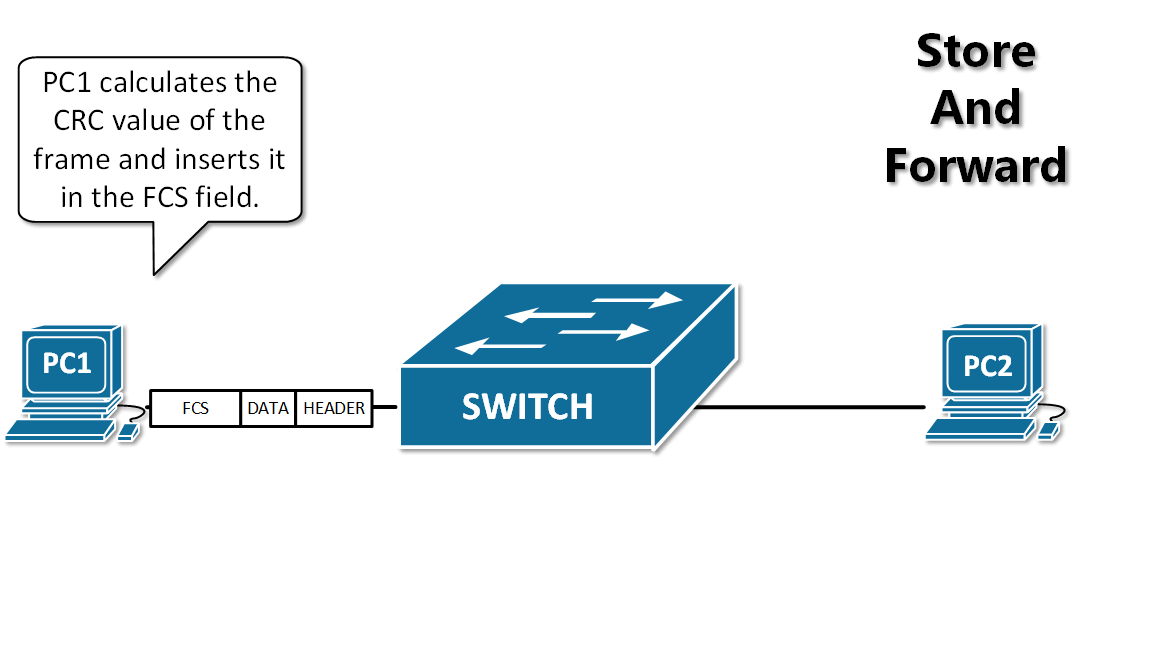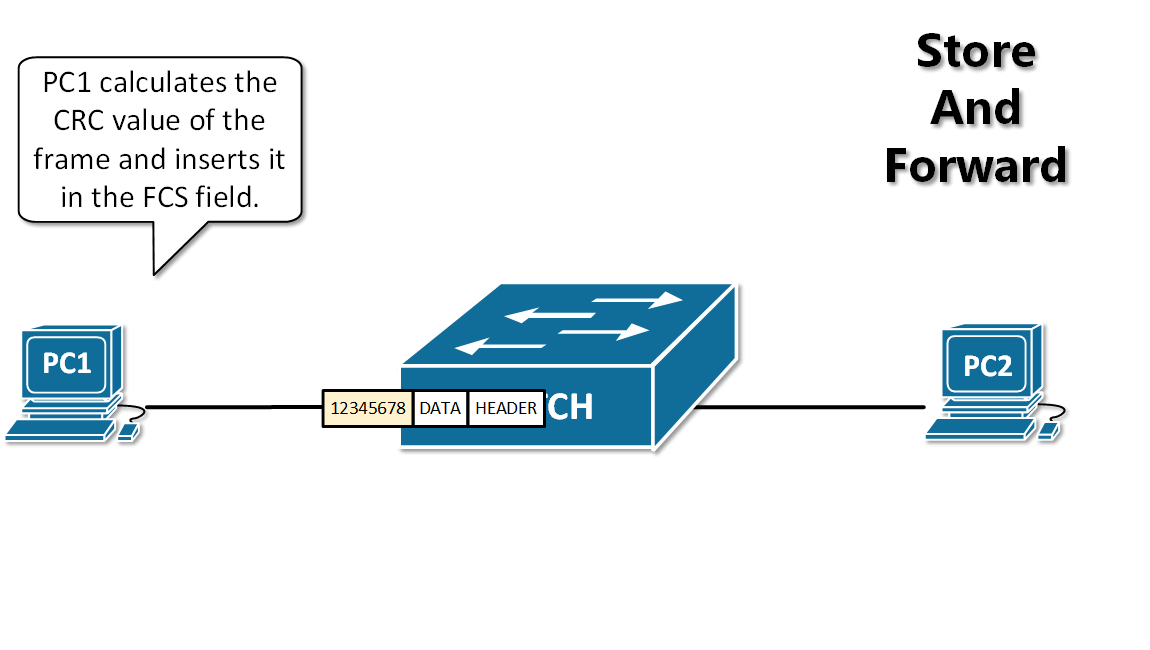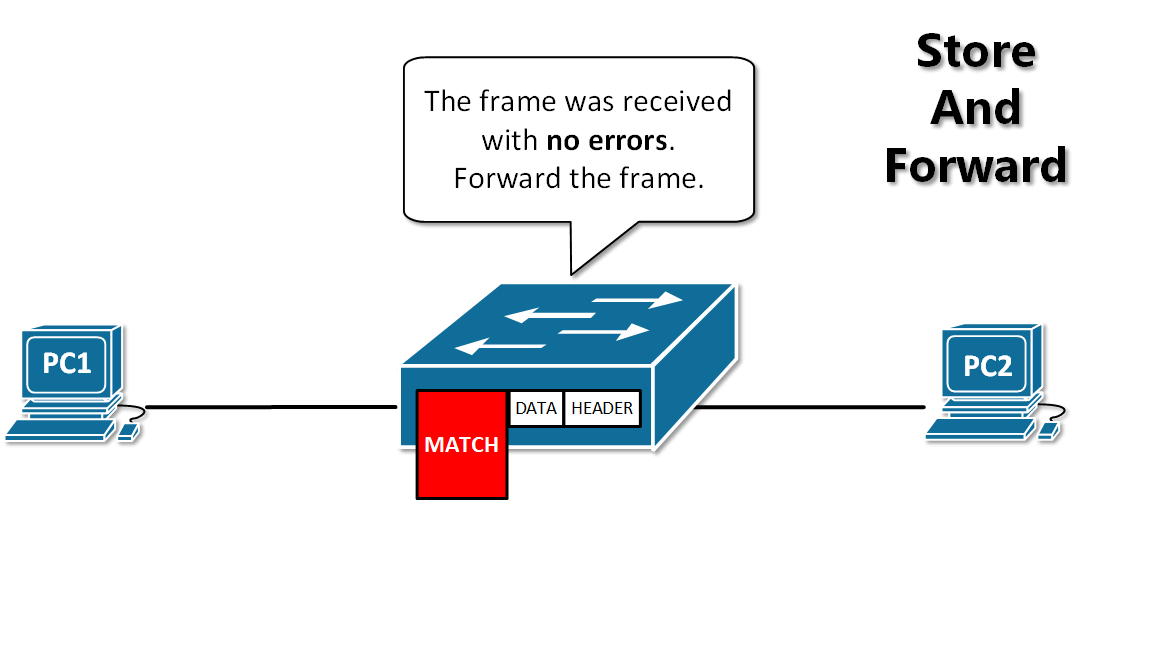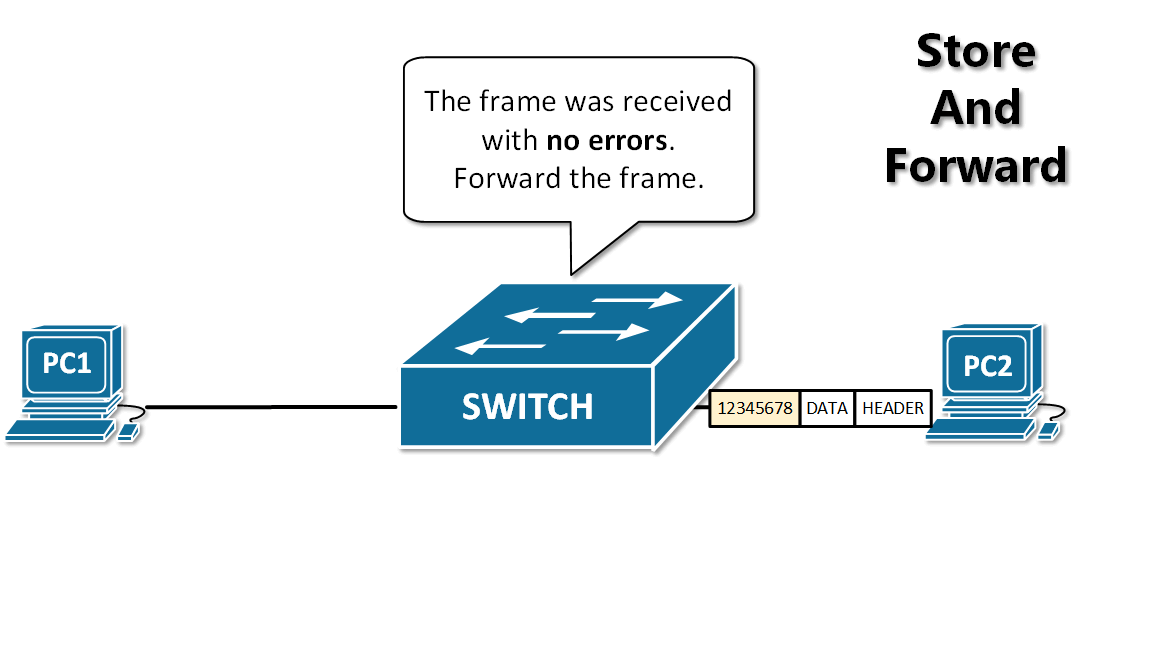
-13. **存储转发(store and forward )** :路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
+12. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
+13. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
-14. **带宽(bandwidth)** :在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
-15. **吞吐量(throughput )** :表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
+14. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
+15. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
### 1.2. 重要知识点总结
@@ -75,10 +75,10 @@ tag:
### 2.1. 基本术语
1. **数据(data)** :运送消息的实体。
-2. **信号(signal)** :数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
-3. **码元( code)** :在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
+2. **信号(signal)**:数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
+3. **码元( code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
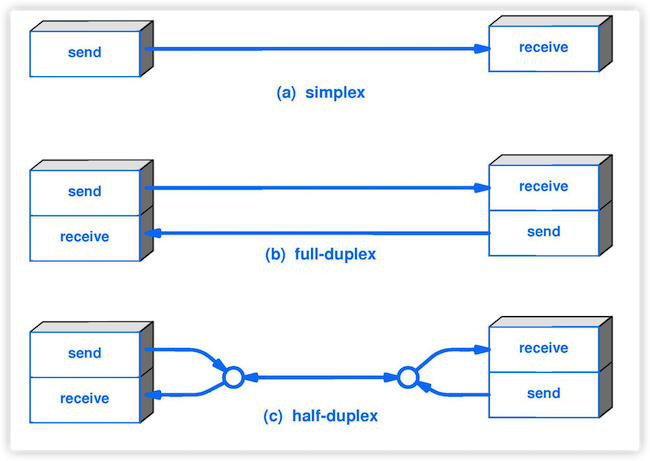
4. **单工(simplex )** : 只能有一个方向的通信而没有反方向的交互。
-5. **半双工(half duplex )** :通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
+5. **半双工(half duplex )**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
@@ -88,19 +88,19 @@ tag:
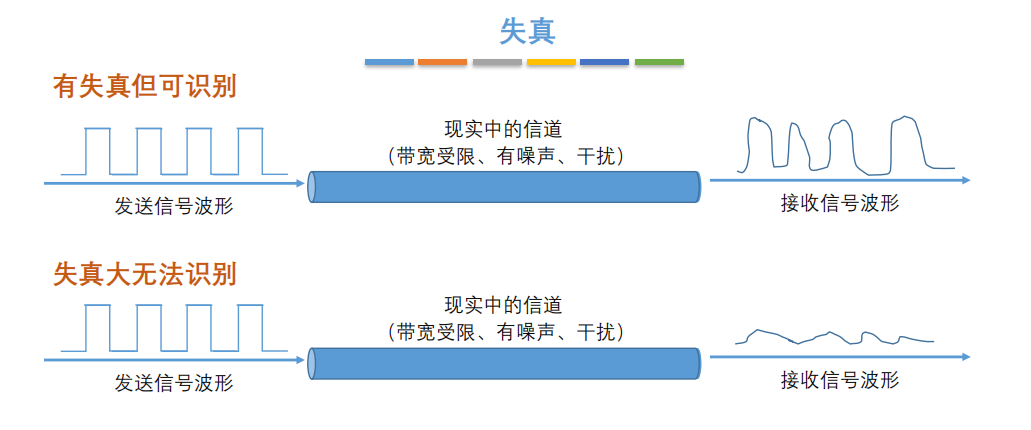
8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
-9. **香农定理** :在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
+9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
10. **基带信号(baseband signal)** : 来自信源的信号。指没有经过调制的数字信号或模拟信号。
-11. **带通(频带)信号(bandpass signal)** :把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
+11. **带通(频带)信号(bandpass signal)**:把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
12. **调制(modulation )** : 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
-14. **信道复用(channel multiplexing )** :指多个用户共享同一个信道。(并不一定是同时)。
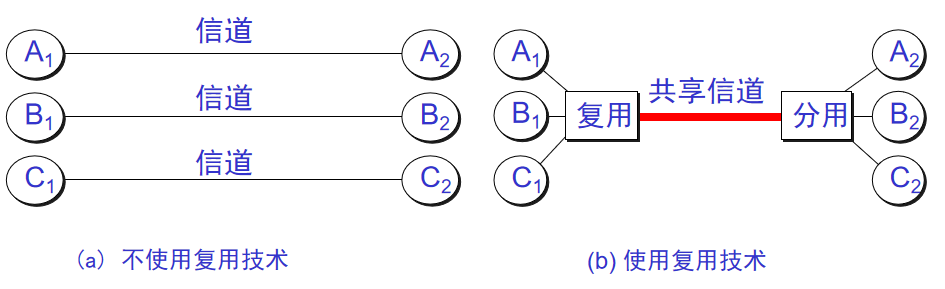
+14. **信道复用(channel multiplexing )**:指多个用户共享同一个信道。(并不一定是同时)。
-15. **比特率(bit rate )** :单位时间(每秒)内传送的比特数。
-16. **波特率(baud rate)** :单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
-17. **复用(multiplexing)** :共享信道的方法。
-18. **ADSL(Asymmetric Digital Subscriber Line )** :非对称数字用户线。
+15. **比特率(bit rate )**:单位时间(每秒)内传送的比特数。
+16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
+17. **复用(multiplexing)**:共享信道的方法。
+18. **ADSL(Asymmetric Digital Subscriber Line )**:非对称数字用户线。
19. **光纤同轴混合网(HFC 网)** :在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
### 2.2. 重要知识点总结
@@ -125,11 +125,11 @@ tag:
#### 2.3.2. 几种常用的信道复用技术
-1. **频分复用(FDM)** :所有用户在同样的时间占用不同的带宽资源。
-2. **时分复用(TDM)** :所有用户在不同的时间占用同样的频带宽度(分时不分频)。
-3. **统计时分复用 (Statistic TDM)** :改进的时分复用,能够明显提高信道的利用率。
-4. **码分复用(CDM)** :用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
-5. **波分复用( WDM)** :波分复用就是光的频分复用。
+1. **频分复用(FDM)**:所有用户在同样的时间占用不同的带宽资源。
+2. **时分复用(TDM)**:所有用户在不同的时间占用同样的频带宽度(分时不分频)。
+3. **统计时分复用 (Statistic TDM)**:改进的时分复用,能够明显提高信道的利用率。
+4. **码分复用(CDM)**:用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
+5. **波分复用( WDM)**:波分复用就是光的频分复用。
#### 2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx
@@ -141,20 +141,20 @@ tag:
### 3.1. 基本术语
-1. **链路(link)** :一个结点到相邻结点的一段物理链路。
-2. **数据链路(data link)** :把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
-3. **循环冗余检验 CRC(Cyclic Redundancy Check)** :为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
-4. **帧(frame)** :一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-5. **MTU(Maximum Transfer Uint )** :最大传送单元。帧的数据部分的的长度上限。
-6. **误码率 BER(Bit Error Rate )** :在一段时间内,传输错误的比特占所传输比特总数的比率。
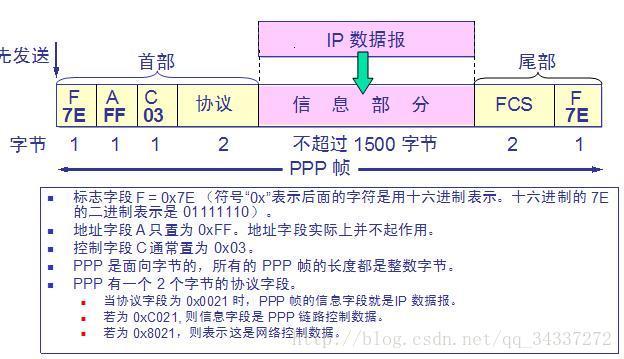
-7. **PPP(Point-to-Point Protocol )** :点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
+1. **链路(link)**:一个结点到相邻结点的一段物理链路。
+2. **数据链路(data link)**:把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
+3. **循环冗余检验 CRC(Cyclic Redundancy Check)**:为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
+4. **帧(frame)**:一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
+5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的的长度上限。
+6. **误码率 BER(Bit Error Rate )**:在一段时间内,传输错误的比特占所传输比特总数的比率。
+7. **PPP(Point-to-Point Protocol )**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
-8. **MAC 地址(Media Access Control 或者 Medium Access Control)** :意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
+8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
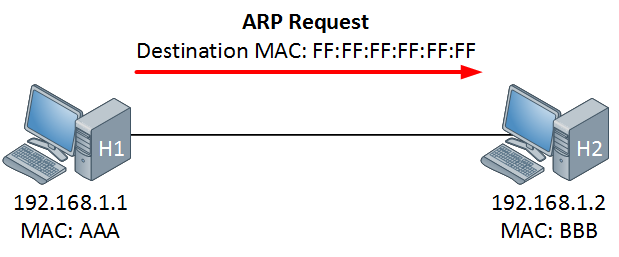
-9. **网桥(bridge)** :一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
-10. **交换机(switch )** :广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
+9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
+10. **交换机(switch )**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
### 3.2. 重要知识点总结
@@ -187,11 +187,11 @@ tag:
1. **虚电路(Virtual Circuit)** : 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
2. **IP(Internet Protocol )** : 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
3. **ARP(Address Resolution Protocol)** : 地址解析协议。地址解析协议 ARP 把 IP 地址解析为硬件地址。
-4. **ICMP(Internet Control Message Protocol )** :网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
-5. **子网掩码(subnet mask )** :它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
+4. **ICMP(Internet Control Message Protocol )**:网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
+5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
-7. **默认路由(default route)** :当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
-8. **路由选择算法(Virtual Circuit)** :路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
+8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
### 4.2. 重要知识点总结
@@ -212,18 +212,18 @@ tag:
### 5.1. 基本术语
-1. **进程(process)** :指计算机中正在运行的程序实体。
-2. **应用进程互相通信** :一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
-3. **传输层的复用与分用** :复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
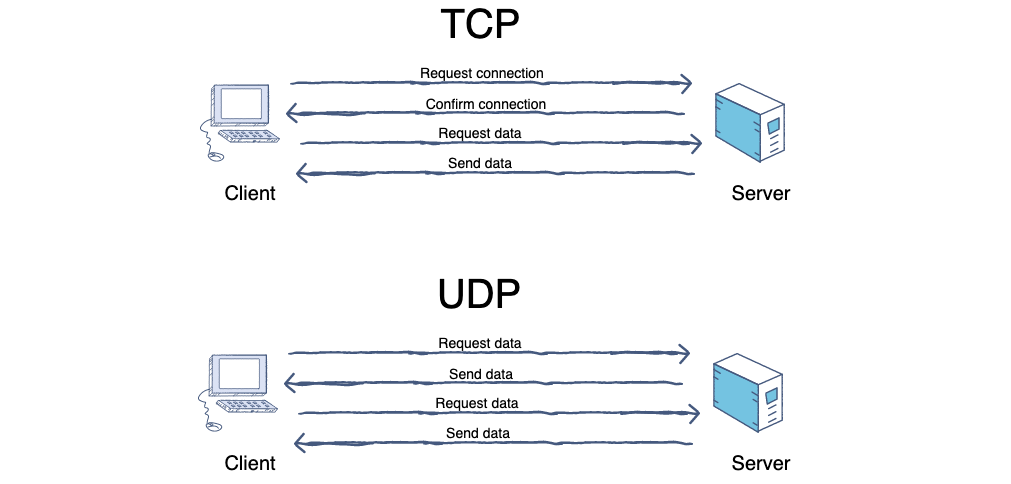
-4. **TCP(Transmission Control Protocol)** :传输控制协议。
-5. **UDP(User Datagram Protocol)** :用户数据报协议。
+1. **进程(process)**:指计算机中正在运行的程序实体。
+2. **应用进程互相通信**:一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
+3. **传输层的复用与分用**:复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
+4. **TCP(Transmission Control Protocol)**:传输控制协议。
+5. **UDP(User Datagram Protocol)**:用户数据报协议。
-6. **端口(port)** :端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
-7. **停止等待协议(stop-and-wait)** :指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
+6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
+7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
8. **流量控制** : 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
-9. **拥塞控制** :防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
+9. **拥塞控制**:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
### 5.2. 重要知识点总结
@@ -265,31 +265,31 @@ tag:
### 6.1. 基本术语
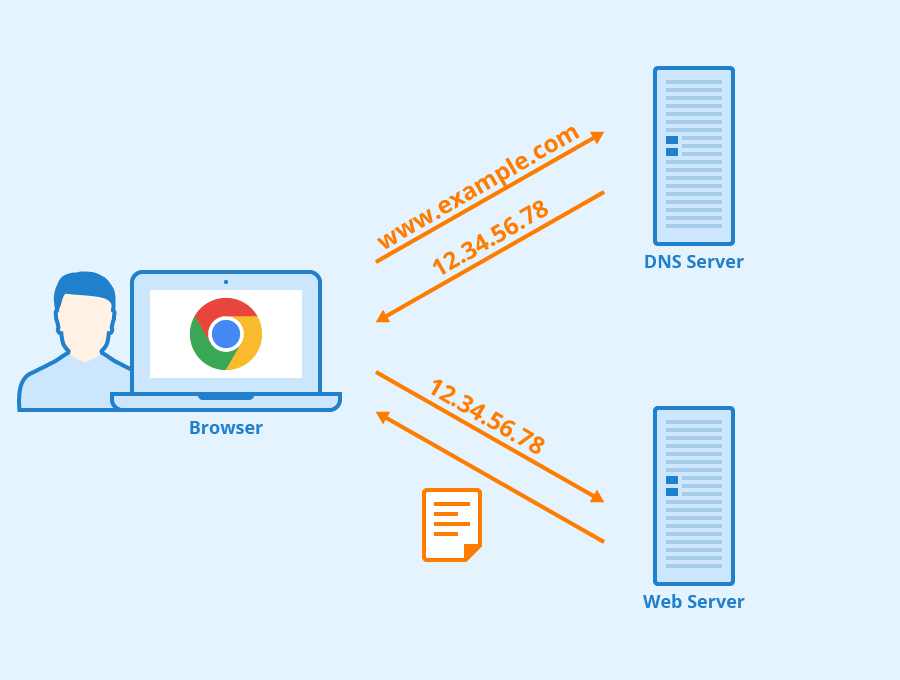
-1. **域名系统(DNS)** :域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
+1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
https://www.seobility.net/en/wiki/HTTP_headers
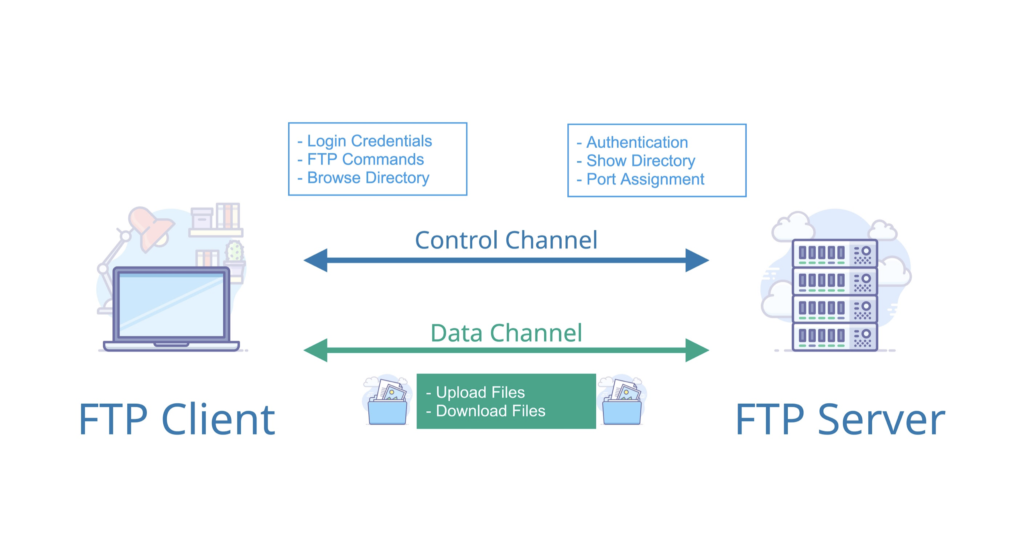
-2. **文件传输协议(FTP)** :FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
+2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
-3. **简单文件传输协议(TFTP)** :TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
-4. **远程终端协议(TELNET)** :Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
-5. **万维网(WWW)** :WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
+3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
+4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
+5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
6. **万维网的大致工作工程:**
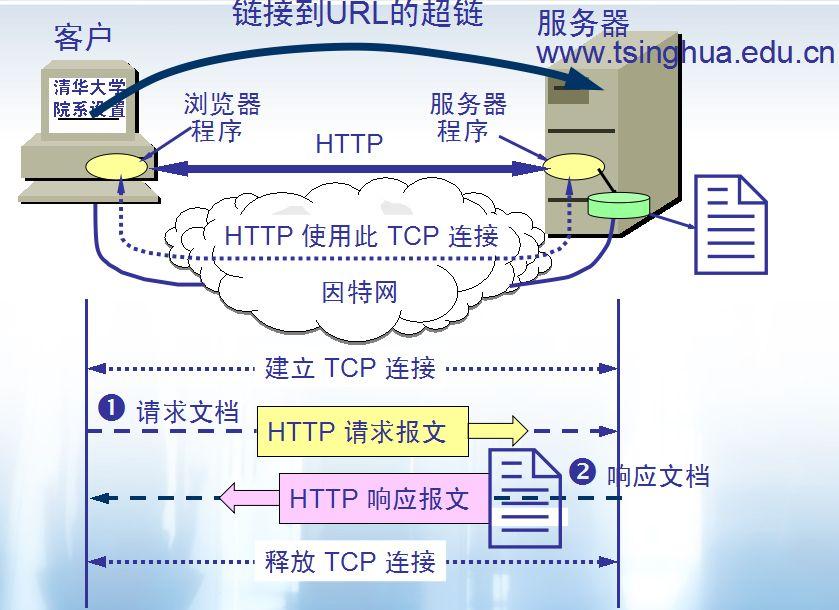
-7. **统一资源定位符(URL)** :统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
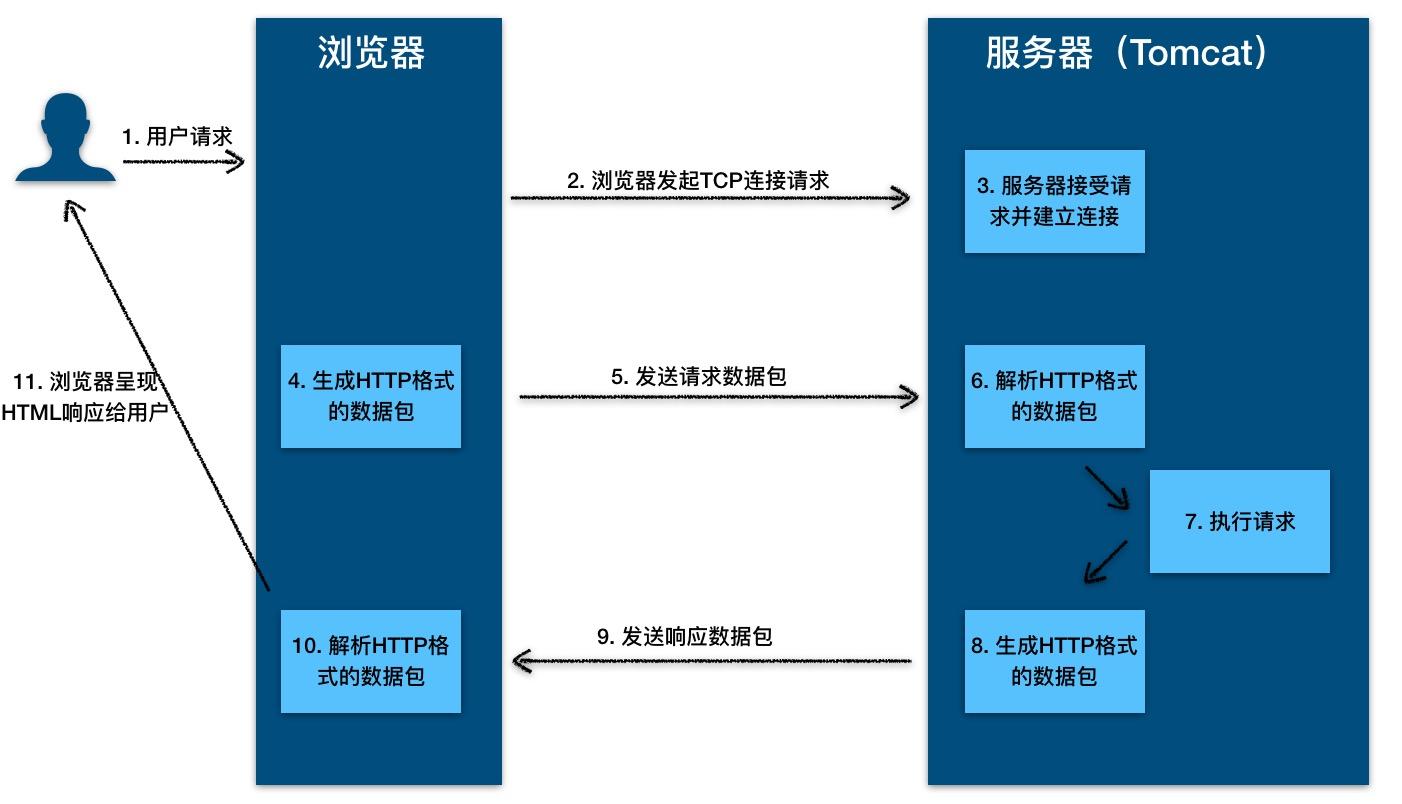
-8. **超文本传输协议(HTTP)** :超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
+7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
+8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
-10. **代理服务器(Proxy Server)** :代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
+10. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
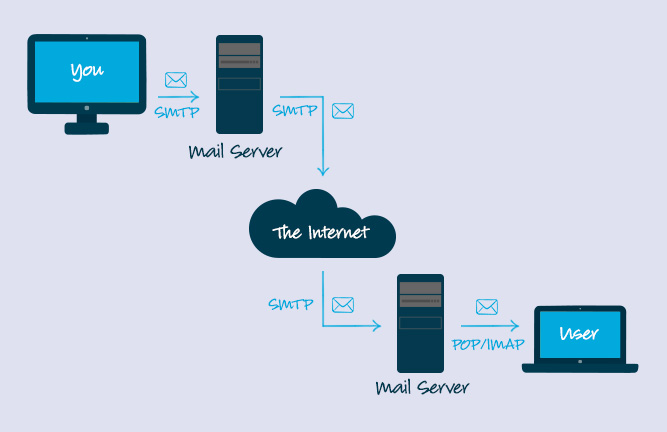
11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
@@ -300,9 +300,9 @@ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格

-12. **垂直搜索引擎** :垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
+12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
-14. **目录索引** :目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
+14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
### 6.2. 重要知识点总结
diff --git a/docs/cs-basics/network/http-status-codes.md b/docs/cs-basics/network/http-status-codes.md
index 82725494461..4cacb50cd42 100644
--- a/docs/cs-basics/network/http-status-codes.md
+++ b/docs/cs-basics/network/http-status-codes.md
@@ -15,10 +15,10 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
### 2xx Success(成功状态码)
-- **200 OK** :请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
-- **201 Created** :请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
-- **202 Accepted** :服务端已经接收到了请求,但是还未处理。
-- **204 No Content** :服务端已经成功处理了请求,但是没有返回任何内容。
+- **200 OK**:请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
+- **201 Created**:请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
+- **202 Accepted**:服务端已经接收到了请求,但是还未处理。
+- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。
这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
@@ -46,21 +46,21 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
### 3xx Redirection(重定向状态码)
-- **301 Moved Permanently** :资源被永久重定向了。比如你的网站的网址更换了。
-- **302 Found** :资源被临时重定向了。比如你的网站的某些资源被暂时转移到另外一个网址。
+- **301 Moved Permanently**:资源被永久重定向了。比如你的网站的网址更换了。
+- **302 Found**:资源被临时重定向了。比如你的网站的某些资源被暂时转移到另外一个网址。
### 4xx Client Error(客户端错误状态码)
-- **400 Bad Request** :发送的 HTTP 请求存在问题。比如请求参数不合法、请求方法错误。
-- **401 Unauthorized** :未认证却请求需要认证之后才能访问的资源。
-- **403 Forbidden** :直接拒绝 HTTP 请求,不处理。一般用来针对非法请求。
-- **404 Not Found** :你请求的资源未在服务端找到。比如你请求某个用户的信息,服务端并没有找到指定的用户。
-- **409 Conflict** :表示请求的资源与服务端当前的状态存在冲突,请求无法被处理。
+- **400 Bad Request**:发送的 HTTP 请求存在问题。比如请求参数不合法、请求方法错误。
+- **401 Unauthorized**:未认证却请求需要认证之后才能访问的资源。
+- **403 Forbidden**:直接拒绝 HTTP 请求,不处理。一般用来针对非法请求。
+- **404 Not Found**:你请求的资源未在服务端找到。比如你请求某个用户的信息,服务端并没有找到指定的用户。
+- **409 Conflict**:表示请求的资源与服务端当前的状态存在冲突,请求无法被处理。
### 5xx Server Error(服务端错误状态码)
-- **500 Internal Server Error** :服务端出问题了(通常是服务端出 Bug 了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
-- **502 Bad Gateway** :我们的网关将请求转发到服务端,但是服务端返回的却是一个错误的响应。
+- **500 Internal Server Error**:服务端出问题了(通常是服务端出 Bug 了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
+- **502 Bad Gateway**:我们的网关将请求转发到服务端,但是服务端返回的却是一个错误的响应。
### 参考
diff --git a/docs/cs-basics/network/http-vs-https.md b/docs/cs-basics/network/http-vs-https.md
index c55105bb8b7..98742292577 100644
--- a/docs/cs-basics/network/http-vs-https.md
+++ b/docs/cs-basics/network/http-vs-https.md
@@ -135,6 +135,6 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
## 总结
-- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
-- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
-- **安全性和资源消耗** :HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
+- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
+- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
index 9dcd1bb5425..48892cfee9f 100644
--- a/docs/cs-basics/network/network-attack-means.md
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -77,7 +77,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
### SYN Flood 的常见形式有哪些?
-**恶意用户可通过三种不同方式发起 SYN Flood 攻击** :
+**恶意用户可通过三种不同方式发起 SYN Flood 攻击**:
1. **直接攻击:**不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
2. **欺骗攻击:**恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
@@ -140,8 +140,8 @@ HTTP 洪水攻击是“第 7 层”DDoS 攻击的一种。第 7 层是 OSI 模
HTTP 洪水攻击有两种:
-- **HTTP GET 攻击** :在这种攻击形式下,多台计算机或其他设备相互协调,向目标服务器发送对图像、文件或其他资产的多个请求。当目标被传入的请求和响应所淹没时,来自正常流量源的其他请求将被拒绝服务。
-- **HTTP POST 攻击** :一般而言,在网站上提交表单时,服务器必须处理传入的请求并将数据推送到持久层(通常是数据库)。与发送 POST 请求所需的处理能力和带宽相比,处理表单数据和运行必要数据库命令的过程相对密集。这种攻击利用相对资源消耗的差异,直接向目标服务器发送许多 POST 请求,直到目标服务器的容量饱和并拒绝服务为止。
+- **HTTP GET 攻击**:在这种攻击形式下,多台计算机或其他设备相互协调,向目标服务器发送对图像、文件或其他资产的多个请求。当目标被传入的请求和响应所淹没时,来自正常流量源的其他请求将被拒绝服务。
+- **HTTP POST 攻击**:一般而言,在网站上提交表单时,服务器必须处理传入的请求并将数据推送到持久层(通常是数据库)。与发送 POST 请求所需的处理能力和带宽相比,处理表单数据和运行必要数据库命令的过程相对密集。这种攻击利用相对资源消耗的差异,直接向目标服务器发送许多 POST 请求,直到目标服务器的容量饱和并拒绝服务为止。
### 如何防护 HTTP Flood?
@@ -330,7 +330,7 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
之前几种都是国外的,我们国内自行研究了国密 **SM1 **和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
-**总结** :
+**总结**:

@@ -369,7 +369,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
国密算法**SM3**。加密强度和 SHA-256 想不多。主要是收到国家的支持。
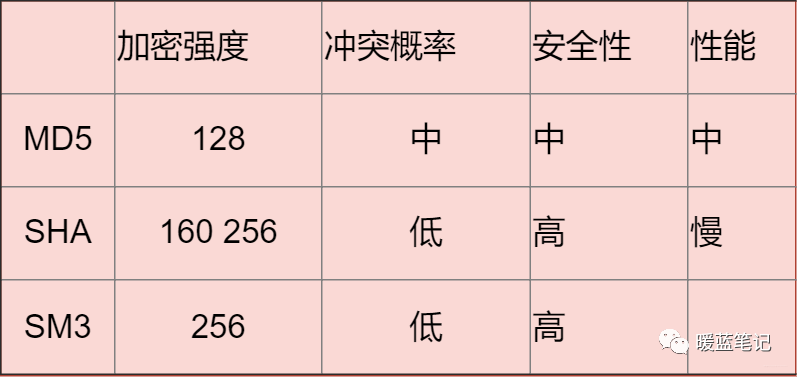
-**总结** :
+**总结**:
diff --git a/docs/cs-basics/network/osi-and-tcp-ip-model.md b/docs/cs-basics/network/osi-and-tcp-ip-model.md
index 966444c9554..d135894a851 100644
--- a/docs/cs-basics/network/osi-and-tcp-ip-model.md
+++ b/docs/cs-basics/network/osi-and-tcp-ip-model.md
@@ -55,16 +55,16 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
应用层协议定义了网络通信规则,对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如支持 Web 应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。
-**应用层常见协议** :
+**应用层常见协议**:
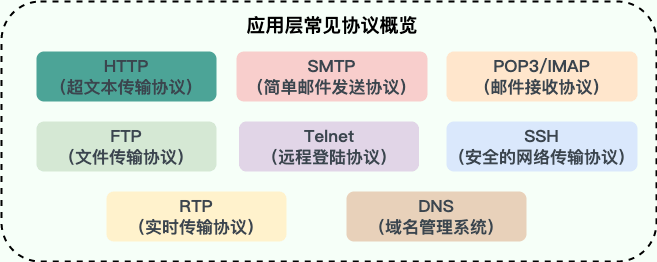
-- **HTTP(Hypertext Transfer Protocol,超文本传输协议)** :基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
-- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)** :基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
-- **POP3/IMAP(邮件接收协议)** :基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
+- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
+- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
-- **Telnet(远程登陆协议)** :基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
-- **SSH(Secure Shell Protocol,安全的网络传输协议)** :基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
+- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
+- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
@@ -74,7 +74,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
**传输层的主要任务就是负责向两台终端设备进程之间的通信提供通用的数据传输服务。** 应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。
-**传输层常见协议** :
+**传输层常见协议**:

@@ -85,7 +85,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
**网络层负责为分组交换网上的不同主机提供通信服务。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报,简称数据报。
-⚠️ 注意 :**不要把运输层的“用户数据报 UDP”和网络层的“IP 数据报”弄混**。
+⚠️ 注意:**不要把运输层的“用户数据报 UDP”和网络层的“IP 数据报”弄混**。
**网络层的还有一个任务就是选择合适的路由,使源主机运输层所传下来的分组,能通过网络层中的路由器找到目的主机。**
@@ -93,17 +93,17 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做 **网际层** 或 **IP 层**。
-**网络层常见协议** :
+**网络层常见协议**:

-- **IP(Internet Protocol,网际协议)** :TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
-- **ARP(Address Resolution Protocol,地址解析协议)** :ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
-- **ICMP(Internet Control Message Protocol,互联网控制报文协议)** :一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
-- **NAT(Network Address Translation,网络地址转换协议)** :NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
+- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
-- **RIP(Routing Information Protocol,路由信息协议)** :一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
-- **BGP(Border Gateway Protocol,边界网关协议)** :一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
### 网络接口层(Network interface layer)
@@ -180,8 +180,8 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
-2. **提高了整体灵活性** :每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
-3. **大问题化小** :分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
+2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
我想到了计算机世界非常非常有名的一句话,这里分享一下:
diff --git a/docs/cs-basics/network/other-network-questions.md b/docs/cs-basics/network/other-network-questions.md
index 22fd82eaf77..8928c423523 100644
--- a/docs/cs-basics/network/other-network-questions.md
+++ b/docs/cs-basics/network/other-network-questions.md
@@ -55,8 +55,8 @@ tag:
好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
-2. **提高了整体灵活性** :每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
-3. **大问题化小** :分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
+2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
我想到了计算机世界非常非常有名的一句话,这里分享一下:
@@ -68,12 +68,12 @@ tag:

-- **HTTP(Hypertext Transfer Protocol,超文本传输协议)** :基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
-- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)** :基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
-- **POP3/IMAP(邮件接收协议)** :基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
+- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
+- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
-- **Telnet(远程登陆协议)** :基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
-- **SSH(Secure Shell Protocol,安全的网络传输协议)** :基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
+- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
+- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
@@ -90,13 +90,13 @@ tag:

-- **IP(Internet Protocol,网际协议)** :TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
-- **ARP(Address Resolution Protocol,地址解析协议)** :ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
-- **ICMP(Internet Control Message Protocol,互联网控制报文协议)** :一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
-- **NAT(Network Address Translation,网络地址转换协议)** :NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
+- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
-- **RIP(Routing Information Protocol,路由信息协议)** :一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
-- **BGP(Border Gateway Protocol,边界网关协议)** :一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
## HTTP
@@ -173,10 +173,10 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被

-- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
-- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
-- **安全性和资源消耗** :HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
-- **SEO(搜索引擎优化)** :搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
+- **端口号**:HTTP 默认是 80,HTTPS 默认是 443。
+- **URL 前缀**:HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
+- **安全性和资源消耗**:HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
+- **SEO(搜索引擎优化)**:搜索引擎通常会更青睐使用 HTTPS 协议的网站,因为 HTTPS 能够提供更高的安全性和用户隐私保护。使用 HTTPS 协议的网站在搜索结果中可能会被优先显示,从而对 SEO 产生影响。
关于 HTTP 和 HTTPS 更详细的对比总结,可以看我写的这篇文章:[HTTP vs HTTPS(应用层)](./http-vs-https.md) 。
@@ -187,7 +187,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
-- **带宽** :HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](./http1.0-vs-http1.1.md) 。
@@ -196,20 +196,20 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被

-- **IO 多路复用(Multiplexing)** :HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
-- **二进制帧(Binary Frames)** :HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
-- **头部压缩(Header Compression)** :HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
+- **IO 多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
### HTTP/2.0 和 HTTP/3.0 有什么区别?

-- **传输协议** :HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
-- **连接建立** :HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
-- **队头阻塞** :HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
-- **错误恢复** :HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
-- **安全性** :HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
+- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
+- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
+- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
### HTTP 是不保存状态的协议, 如何保存用户状态?
@@ -257,10 +257,10 @@ round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
PING 命令的输出结果通常包括以下几部分信息:
-1. **ICMP Echo Request(请求报文)信息** :序列号、TTL(Time to Live)值。
-2. **目标主机的域名或 IP 地址** :输出结果的第一行。
-3. **往返时间(RTT,Round-Trip Time)** :从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
-4. **统计结果(Statistics)** :包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
+1. **ICMP Echo Request(请求报文)信息**:序列号、TTL(Time to Live)值。
+2. **目标主机的域名或 IP 地址**:输出结果的第一行。
+3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
+4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题。如果往返时间(RTT)过高,则表明网络延迟过高。
@@ -270,8 +270,8 @@ PING 基于网络层的 **ICMP(Internet Control Message Protocol,互联网
ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
-- **查询报文类型** :向目标主机发送请求并期望得到响应。
-- **差错报文类型** :向源主机发送错误信息,用于报告网络中的错误情况。
+- **查询报文类型**:向目标主机发送请求并期望得到响应。
+- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
diff --git a/docs/cs-basics/network/other-network-questions2.md b/docs/cs-basics/network/other-network-questions2.md
index 17e9a47be0a..dd0d7047db9 100644
--- a/docs/cs-basics/network/other-network-questions2.md
+++ b/docs/cs-basics/network/other-network-questions2.md
@@ -11,13 +11,13 @@ tag:
### TCP 与 UDP 的区别(重要)
-1. **是否面向连接** :UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
+1. **是否面向连接**:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。
2. **是否是可靠传输**:远地主机在收到 UDP 报文后,不需要给出任何确认,并且不保证数据不丢失,不保证是否顺序到达。TCP 提供可靠的传输服务,TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制。通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。
-3. **是否有状态** :这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(**这很渣男!**)。
-4. **传输效率** :由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
-5. **传输形式** :TCP 是面向字节流的,UDP 是面向报文的。
-6. **首部开销** :TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
-7. **是否提供广播或多播服务** :TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
+3. **是否有状态**:这个和上面的“是否可靠传输”相对应。TCP 传输是有状态的,这个有状态说的是 TCP 会去记录自己发送消息的状态比如消息是否发送了、是否被接收了等等。为此 ,TCP 需要维持复杂的连接状态表。而 UDP 是无状态服务,简单来说就是不管发出去之后的事情了(**这很渣男!**)。
+4. **传输效率**:由于使用 TCP 进行传输的时候多了连接、确认、重传等机制,所以 TCP 的传输效率要比 UDP 低很多。
+5. **传输形式**:TCP 是面向字节流的,UDP 是面向报文的。
+6. **首部开销**:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
+7. **是否提供广播或多播服务**:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
8. ......
我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
@@ -50,10 +50,10 @@ tag:
### 使用 TCP 的协议有哪些?使用 UDP 的协议有哪些?
-**运行于 TCP 协议之上的协议** :
+**运行于 TCP 协议之上的协议**:
-1. **HTTP 协议** :超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
-2. **HTTPS 协议** :更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
+1. **HTTP 协议**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+2. **HTTPS 协议**:更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
3. **FTP 协议**:文件传输协议 FTP(File Transfer Protocol)是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
4. **SMTP 协议**:简单邮件传输协议(SMTP,Simple Mail Transfer Protocol)的缩写,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
5. **POP3/IMAP 协议**:两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
@@ -61,15 +61,15 @@ tag:
7. **SSH 协议** : SSH( Secure Shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
8. ......
-**运行于 UDP 协议之上的协议** :
+**运行于 UDP 协议之上的协议**:
1. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
-2. **DNS** :**域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
+2. **DNS**:**域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
3. ......
### TCP 三次握手和四次挥手(非常重要)
-**相关面试题** :
+**相关面试题**:
- 为什么要三次握手?
- 第 2 次握手传回了 ACK,为什么还要传回 SYN?
@@ -78,7 +78,7 @@ tag:
- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
-**参考答案** :[TCP 三次握手和四次挥手(传输层)](./tcp-connection-and-disconnection.md) 。
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](./tcp-connection-and-disconnection.md) 。
### TCP 如何保证传输的可靠性?(重要)
@@ -122,11 +122,11 @@ IP 地址过滤是一种简单的网络安全措施,实际应用中一般会
除了更大的地址空间之外,IPv6 的优势还包括:
-- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)** :主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
-- **NAT(Network Address Translation,网络地址转换) 成为可选项** :IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
-- **对标头结构进行了改进** :IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
-- **可选的扩展头** :允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
-- **ICMPv6(Internet Control Message Protocol for IPv6)** :IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
+- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)**:主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
+- **NAT(Network Address Translation,网络地址转换) 成为可选项**:IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
+- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
+- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
+- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
- ......
### NAT 的作用是什么?
diff --git a/docs/cs-basics/network/tcp-connection-and-disconnection.md b/docs/cs-basics/network/tcp-connection-and-disconnection.md
index eec56a1aac1..6b3efac77a1 100644
--- a/docs/cs-basics/network/tcp-connection-and-disconnection.md
+++ b/docs/cs-basics/network/tcp-connection-and-disconnection.md
@@ -11,7 +11,7 @@ tag:
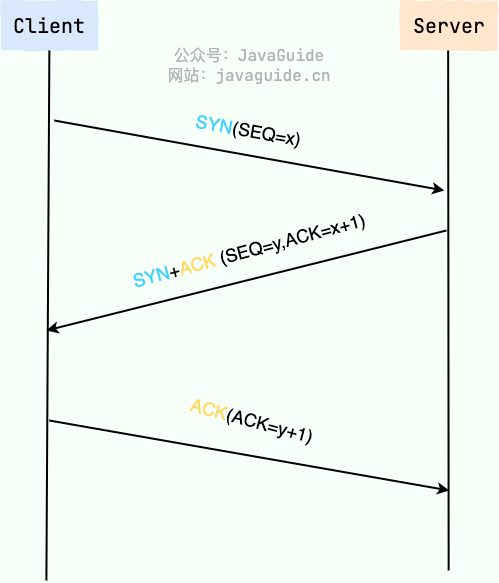
-建立一个 TCP 连接需要“三次握手”,缺一不可 :
+建立一个 TCP 连接需要“三次握手”,缺一不可:
- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
@@ -23,9 +23,9 @@ tag:
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
-1. **第一次握手** :Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
-2. **第二次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
-3. **第三次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
+1. **第一次握手**:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
+2. **第二次握手**:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
+3. **第三次握手**:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
三次握手就能确认双方收发功能都正常,缺一不可。
@@ -41,12 +41,12 @@ tag:
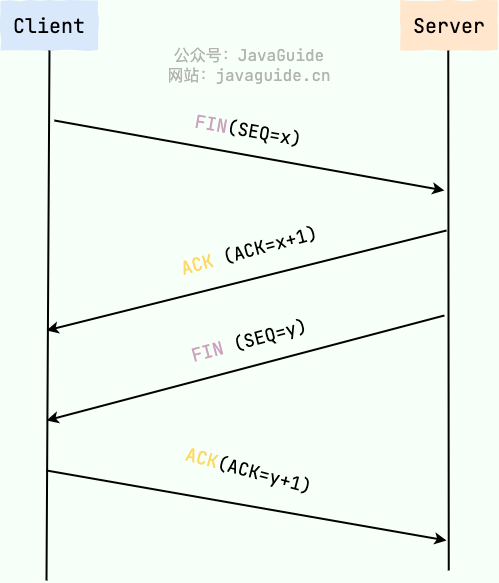
-断开一个 TCP 连接则需要“四次挥手”,缺一不可 :
+断开一个 TCP 连接则需要“四次挥手”,缺一不可:
-1. **第一次挥手** :客户端发送一个 FIN(SEQ=x) 标志的数据包->服务端,用来关闭客户端到服务器的数据传送。然后,客户端进入 **FIN-WAIT-1** 状态。
-2. **第二次挥手** :服务器收到这个 FIN(SEQ=X) 标志的数据包,它发送一个 ACK (ACK=x+1)标志的数据包->客户端 。然后,此时服务端进入 **CLOSE-WAIT** 状态,客户端进入 **FIN-WAIT-2** 状态。
-3. **第三次挥手** :服务端关闭与客户端的连接并发送一个 FIN (SEQ=y)标志的数据包->客户端请求关闭连接,然后,服务端进入 **LAST-ACK** 状态。
-4. **第四次挥手** :客户端发送 ACK (ACK=y+1)标志的数据包->服务端并且进入**TIME-WAIT**状态,服务端在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。此时,如果客户端等待 **2MSL** 后依然没有收到回复,就证明服务端已正常关闭,随后,客户端也可以关闭连接了。
+1. **第一次挥手**:客户端发送一个 FIN(SEQ=x) 标志的数据包->服务端,用来关闭客户端到服务器的数据传送。然后,客户端进入 **FIN-WAIT-1** 状态。
+2. **第二次挥手**:服务器收到这个 FIN(SEQ=X) 标志的数据包,它发送一个 ACK (ACK=x+1)标志的数据包->客户端 。然后,此时服务端进入 **CLOSE-WAIT** 状态,客户端进入 **FIN-WAIT-2** 状态。
+3. **第三次挥手**:服务端关闭与客户端的连接并发送一个 FIN (SEQ=y)标志的数据包->客户端请求关闭连接,然后,服务端进入 **LAST-ACK** 状态。
+4. **第四次挥手**:客户端发送 ACK (ACK=y+1)标志的数据包->服务端并且进入**TIME-WAIT**状态,服务端在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。此时,如果客户端等待 **2MSL** 后依然没有收到回复,就证明服务端已正常关闭,随后,客户端也可以关闭连接了。
**只要四次挥手没有结束,客户端和服务端就可以继续传输数据!**
@@ -56,10 +56,10 @@ TCP 是全双工通信,可以双向传输数据。任何一方都可以在数
举个例子:A 和 B 打电话,通话即将结束后。
-1. **第一次挥手** :A 说“我没啥要说的了”
-2. **第二次挥手** :B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话
-3. **第三次挥手** :于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”
-4. **第四次挥手** :A 回答“知道了”,这样通话才算结束。
+1. **第一次挥手**:A 说“我没啥要说的了”
+2. **第二次挥手**:B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话
+3. **第三次挥手**:于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”
+4. **第四次挥手**:A 回答“知道了”,这样通话才算结束。
### 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
diff --git a/docs/cs-basics/network/tcp-reliability-guarantee.md b/docs/cs-basics/network/tcp-reliability-guarantee.md
index a9dc6ae8441..c2f081f2327 100644
--- a/docs/cs-basics/network/tcp-reliability-guarantee.md
+++ b/docs/cs-basics/network/tcp-reliability-guarantee.md
@@ -7,7 +7,7 @@ tag:
## TCP 如何保证传输的可靠性?
-1. **基于数据块传输** :应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
+1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
4. **超时重传** : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
@@ -27,30 +27,30 @@ tag:
TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP 传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同
-**TCP 发送窗口可以划分成四个部分** :
+**TCP 发送窗口可以划分成四个部分**:
1. 已经发送并且确认的 TCP 段(已经发送并确认);
2. 已经发送但是没有确认的 TCP 段(已经发送未确认);
3. 未发送但是接收方准备接收的 TCP 段(可以发送);
4. 未发送并且接收方也并未准备接受的 TCP 段(不可发送)。
-**TCP 发送窗口结构图示** :
+**TCP 发送窗口结构图示**:
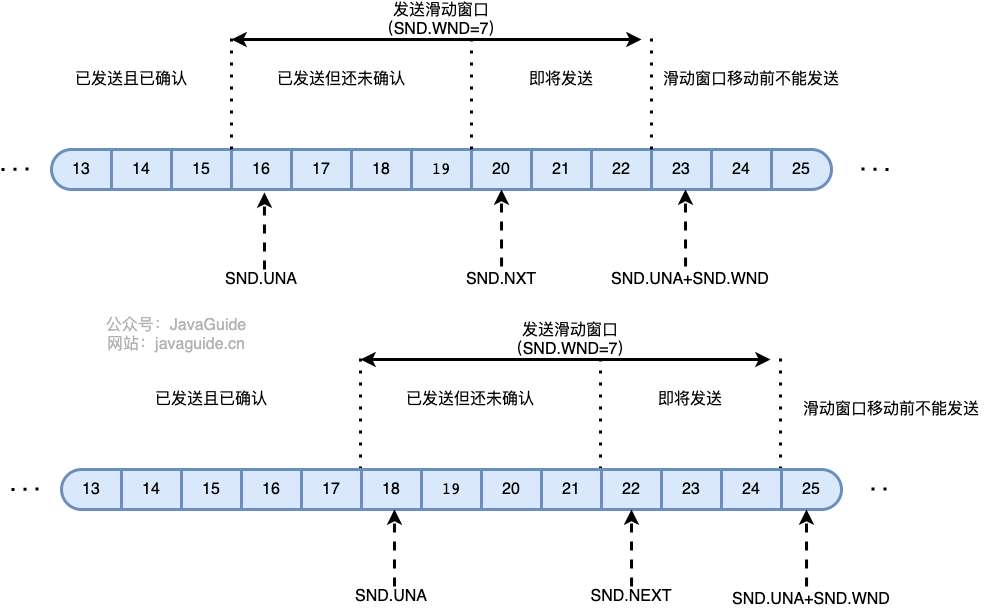
-- **SND.WND** :发送窗口。
+- **SND.WND**:发送窗口。
- **SND.UNA**:Send Unacknowledged 指针,指向发送窗口的第一个字节。
- **SND.NXT**:Send Next 指针,指向可用窗口的第一个字节。
**可用窗口大小** = `SND.UNA + SND.WND - SND.NXT` 。
-**TCP 接收窗口可以划分成三个部分** :
+**TCP 接收窗口可以划分成三个部分**:
1. 已经接收并且已经确认的 TCP 段(已经接收并确认);
2. 等待接收且允许发送方发送 TCP 段(可以接收未确认);
3. 不可接收且不允许发送方发送 TCP 段(不可接收)。
-**TCP 接收窗口结构图示** :
+**TCP 接收窗口结构图示**:
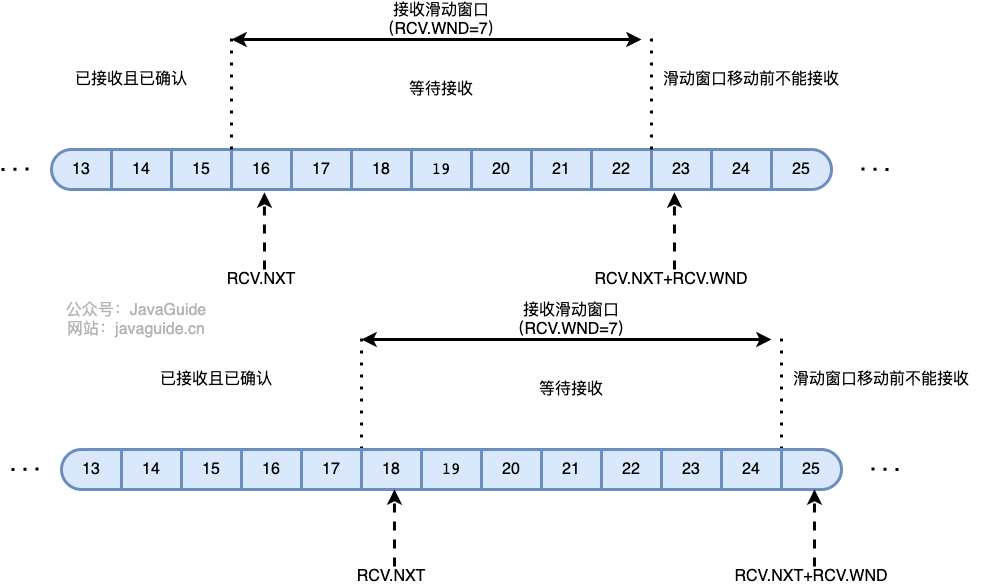
@@ -94,8 +94,8 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
**3) 确认丢失和确认迟到**
-- **确认丢失** :确认消息在传输过程丢失。当 A 发送 M1 消息,B 收到后,B 向 A 发送了一个 M1 确认消息,但却在传输过程中丢失。而 A 并不知道,在超时计时过后,A 重传 M1 消息,B 再次收到该消息后采取以下两点措施:1. 丢弃这个重复的 M1 消息,不向上层交付。 2. 向 A 发送确认消息。(不会认为已经发送过了,就不再发送。A 能重传,就证明 B 的确认消息丢失)。
-- **确认迟到** :确认消息在传输过程中迟到。A 发送 M1 消息,B 收到并发送确认。在超时时间内没有收到确认消息,A 重传 M1 消息,B 仍然收到并继续发送确认消息(B 收到了 2 份 M1)。此时 A 收到了 B 第二次发送的确认消息。接着发送其他数据。过了一会,A 收到了 B 第一次发送的对 M1 的确认消息(A 也收到了 2 份确认消息)。处理如下:1. A 收到重复的确认后,直接丢弃。2. B 收到重复的 M1 后,也直接丢弃重复的 M1。
+- **确认丢失**:确认消息在传输过程丢失。当 A 发送 M1 消息,B 收到后,B 向 A 发送了一个 M1 确认消息,但却在传输过程中丢失。而 A 并不知道,在超时计时过后,A 重传 M1 消息,B 再次收到该消息后采取以下两点措施:1. 丢弃这个重复的 M1 消息,不向上层交付。 2. 向 A 发送确认消息。(不会认为已经发送过了,就不再发送。A 能重传,就证明 B 的确认消息丢失)。
+- **确认迟到**:确认消息在传输过程中迟到。A 发送 M1 消息,B 收到并发送确认。在超时时间内没有收到确认消息,A 重传 M1 消息,B 仍然收到并继续发送确认消息(B 收到了 2 份 M1)。此时 A 收到了 B 第二次发送的确认消息。接着发送其他数据。过了一会,A 收到了 B 第一次发送的对 M1 的确认消息(A 也收到了 2 份确认消息)。处理如下:1. A 收到重复的确认后,直接丢弃。2. B 收到重复的 M1 后,也直接丢弃重复的 M1。
### 连续 ARQ 协议
diff --git a/docs/cs-basics/operating-system/linux-intro.md b/docs/cs-basics/operating-system/linux-intro.md
index 14d29f7543b..677f22899b6 100644
--- a/docs/cs-basics/operating-system/linux-intro.md
+++ b/docs/cs-basics/operating-system/linux-intro.md
@@ -18,9 +18,9 @@ head:
通过以下三点可以概括 Linux 到底是什么:
-- **类 Unix 系统** :Linux 是一种自由、开放源码的类似 Unix 的操作系统
-- **Linux 本质是指 Linux 内核** :严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
-- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)** :一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
+- **类 Unix 系统**:Linux 是一种自由、开放源码的类似 Unix 的操作系统
+- **Linux 本质是指 Linux 内核**:严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
+- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)**:一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。

@@ -44,8 +44,8 @@ Linus Torvalds 开源的只是 Linux 内核,我们上面也提到了操作系
Linux 的发行版本可以大体分为两类:
-- **商业公司维护的发行版本** :比如 Red Hat 公司维护支持的 Red Hat Enterprise Linux (RHEL)。
-- **社区组织维护的发行版本** :比如基于 Red Hat Enterprise Linux(RHEL)的 CentOS、基于 Debian 的 Ubuntu。
+- **商业公司维护的发行版本**:比如 Red Hat 公司维护支持的 Red Hat Enterprise Linux (RHEL)。
+- **社区组织维护的发行版本**:比如基于 Red Hat Enterprise Linux(RHEL)的 CentOS、基于 Debian 的 Ubuntu。
对于初学者学习 Linux ,推荐选择 CentOS,原因如下:
@@ -68,7 +68,7 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
通过以下五点可以概括 inode 到底是什么:
-1. 硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata** :如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 **每个文件都有一个唯一的 inode,存储文件的元信息。**
+1. 硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata**:如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 **每个文件都有一个唯一的 inode,存储文件的元信息。**
2. inode 是一种固定大小的数据结构,其大小在文件系统创建时就确定了,并且在文件的生命周期内保持不变。
3. inode 的访问速度非常快,因为系统可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
4. inode 的数量是有限的,每个文件系统只能包含固定数量的 inode。这意味着当文件系统中的 inode 用完时,无法再创建新的文件或目录,即使磁盘上还有可用空间。因此,在创建文件系统时,需要根据文件和目录的预期数量来合理分配 inode 的数量。
@@ -78,8 +78,8 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
再总结一下 inode 和 block:
-- **inode** :记录文件的属性信息,可以使用 `stat` 命令查看 inode 信息。
-- **block** :实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
+- **inode**:记录文件的属性信息,可以使用 `stat` 命令查看 inode 信息。
+- **block**:实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)

@@ -116,13 +116,13 @@ inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作
Linux 支持很多文件类型,其中非常重要的文件类型有: **普通文件**,**目录文件**,**链接文件**,**设备文件**,**管道文件**,**Socket 套接字文件** 等。
-- **普通文件(-)** :用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
-- **目录文件(d,directory file)** :目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
-- **符号链接文件(l,symbolic link)** :保留了指向文件的地址而不是文件本身。
-- **字符设备(c,char)** :用来访问字符设备比如键盘。
-- **设备文件(b,block)** :用来访问块设备比如硬盘、软盘。
+- **普通文件(-)**:用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
+- **目录文件(d,directory file)**:目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
+- **符号链接文件(l,symbolic link)**:保留了指向文件的地址而不是文件本身。
+- **字符设备(c,char)**:用来访问字符设备比如键盘。
+- **设备文件(b,block)**:用来访问块设备比如硬盘、软盘。
- **管道文件(p,pipe)** : 一种特殊类型的文件,用于进程之间的通信。
-- **套接字文件(s,socket)** :用于进程间的网络通信,也可以用于本机之间的非网络通信。
+- **套接字文件(s,socket)**:用于进程间的网络通信,也可以用于本机之间的非网络通信。
每种文件类型都有不同的用途和属性,可以通过命令如`ls`、`file`等来查看文件的类型信息。
@@ -147,7 +147,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
- **/bin:** 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
- **/etc:** 存放系统管理和配置文件;
- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
-- **/usr :** 用于存放系统应用程序;
+- **/usr:** 用于存放系统应用程序;
- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
@@ -155,7 +155,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
- **/dev:** 用于存放设备文件;
- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
- **/boot:** 存放用于系统引导时使用的各种文件;
-- **/lib 和/lib64 :** 存放着和系统运行相关的库文件 ;
+- **/lib 和/lib64:** 存放着和系统运行相关的库文件 ;
- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
@@ -198,7 +198,7 @@ Linux 使用一种称为目录树的层次结构来组织文件和目录。目
- `touch [选项] 文件名..`:创建新文件或更新已存在文件(增)。例如:`touch file1.txt file2.txt file3.txt` ,创建 3 个文件。
- `ln [选项] <源文件> <硬链接/软链接文件>`:创建硬链接/软链接。例如:`ln -s file.txt file_link`,创建名为 `file_link` 的软链接,指向 `file.txt` 文件。`-s` 选项代表的就是创建软链接,s 即 symbolic(软链接又名符号链接) 。
-- `cat/more/less/tail 文件名` :文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
+- `cat/more/less/tail 文件名`:文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
- `vim 文件名`:修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤:`vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
### 文件压缩
@@ -285,9 +285,9 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
**在 linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
-- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
-- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
-- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
+- **所有者(u)**:一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
+- **文件所在组(g)**:当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
+- **其它组(o)**:除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
> 我们再来看看如何修改文件/目录的权限。
@@ -339,7 +339,7 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
-- `vmstat [间隔时间] [重复次数]` :vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
+- `vmstat [间隔时间] [重复次数]`:vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
@@ -352,7 +352,7 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
- `ping [选项] 目标主机`:测试与目标主机的网络连接。
- `ifconfig` 或 `ip`:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。
- `netstat [选项]`:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。
-- `ss [选项]` :比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
+- `ss [选项]`:比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
### 其他
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-01.md b/docs/cs-basics/operating-system/operating-system-basic-questions-01.md
index 691fc05c335..7498b83ebf4 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-01.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-01.md
@@ -20,8 +20,8 @@ head:
开始本文的内容之前,我们先聊聊为什么要学习操作系统。
-- **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
-- **从面试角度来说** :尤其是校招,对于操作系统方面知识的考察是非常非常多的。
+- **从对个人能力方面提升来说**:操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
+- **从面试角度来说**:尤其是校招,对于操作系统方面知识的考察是非常非常多的。
**简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
@@ -51,12 +51,12 @@ head:
从资源管理的角度来看,操作系统有 6 大功能:
-1. **进程和线程的管理** :进程的创建、撤销、阻塞、唤醒,进程间的通信等。
-2. **存储管理** :内存的分配和管理、外存(磁盘等)的分配和管理等。
-3. **文件管理** :文件的读、写、创建及删除等。
-4. **设备管理** :完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
-5. **网络管理** :操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
-6. **安全管理** :用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
+1. **进程和线程的管理**:进程的创建、撤销、阻塞、唤醒,进程间的通信等。
+2. **存储管理**:内存的分配和管理、外存(磁盘等)的分配和管理等。
+3. **文件管理**:文件的读、写、创建及删除等。
+4. **设备管理**:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
+5. **网络管理**:操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
+6. **安全管理**:用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
### 常见的操作系统有哪些?
@@ -99,7 +99,7 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
- **用户态(User Mode)** : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
-- **内核态(Kernel Mode)** :内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
+- **内核态(Kernel Mode)**:内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
@@ -118,8 +118,8 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
用户态切换到内核态的 3 种方式:
-1. **系统调用(Trap)** :用户态进程 **主动** 要求切换到内核态的一种方式,主要是为了使用内核态才能做的事情比如读取磁盘资源。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
-2. **中断(Interrupt)** :当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
+1. **系统调用(Trap)**:用户态进程 **主动** 要求切换到内核态的一种方式,主要是为了使用内核态才能做的事情比如读取磁盘资源。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
+2. **中断(Interrupt)**:当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
3. **异常(Exception)**:当 CPU 在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
在系统的处理上,中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
@@ -201,10 +201,10 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
下面是几种常见的线程同步的方式:
-1. **互斥锁(Mutex)** :采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
+1. **互斥锁(Mutex)**:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
2. **读写锁(Read-Write Lock)**:允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
-3. **信号量(Semaphore)** :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
-4. **屏障(Barrier)** :屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
+3. **信号量(Semaphore)**:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
+4. **屏障(Barrier)**:屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
### PCB 是什么?包含哪些信息?
@@ -226,11 +226,11 @@ PCB 主要包含下面几部分的内容:
我们一般把进程大致分为 5 种状态,这一点和线程很像!
-- **创建状态(new)** :进程正在被创建,尚未到就绪状态。
-- **就绪状态(ready)** :进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
-- **运行状态(running)** :进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
-- **阻塞状态(waiting)** :又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
-- **结束状态(terminated)** :进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
+- **创建状态(new)**:进程正在被创建,尚未到就绪状态。
+- **就绪状态(ready)**:进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
+- **运行状态(running)**:进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
+- **阻塞状态(waiting)**:又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
+- **结束状态(terminated)**:进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
@@ -238,12 +238,12 @@ PCB 主要包含下面几部分的内容:
> 下面这部分总结参考了:[《进程间通信 IPC (InterProcess Communication)》](https://www.jianshu.com/p/c1015f5ffa74) 这篇文章,推荐阅读,总结的非常不错。
-1. **管道/匿名管道(Pipes)** :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
+1. **管道/匿名管道(Pipes)**:用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
2. **有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
-3. **信号(Signal)** :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
-4. **消息队列(Message Queuing)** :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
-5. **信号量(Semaphores)** :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
-6. **共享内存(Shared memory)** :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
+3. **信号(Signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
+4. **消息队列(Message Queuing)**:消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。**消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。**
+5. **信号量(Semaphores)**:信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
+6. **共享内存(Shared memory)**:使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
7. **套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
### 进程的调度算法有哪些?
@@ -255,8 +255,8 @@ PCB 主要包含下面几部分的内容:
- **先到先服务调度算法(FCFS,First Come, First Served)** : 从就绪队列中选择一个最先进入该队列的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
- **短作业优先的调度算法(SJF,Shortest Job First)** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源,使它立即执行并一直执行到完成或发生某事件而被阻塞放弃占用 CPU 时再重新调度。
- **时间片轮转调度算法(RR,Round-Robin)** : 时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
-- **多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)** :前面介绍的几种进程调度的算法都有一定的局限性。如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
-- **优先级调度算法(Priority)** :为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
+- **多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)**:前面介绍的几种进程调度的算法都有一定的局限性。如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
+- **优先级调度算法(Priority)**:为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推。具有相同优先级的进程以 FCFS 方式执行。可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
### 什么是僵尸进程和孤儿进程?
@@ -266,8 +266,8 @@ PCB 主要包含下面几部分的内容:
这样的设计可以让父进程在子进程结束时得到子进程的状态信息,并且可以防止出现“僵尸进程”(即子进程结束后 PCB 仍然存在但父进程无法得到状态信息的情况)。
-- **僵尸进程** :子进程已经终止,但是其父进程仍在运行,且父进程没有调用 wait()或 waitpid()等系统调用来获取子进程的状态信息,释放子进程占用的资源,导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。这种情况下,子进程被称为“僵尸进程”。避免僵尸进程的产生,父进程需要及时调用 wait()或 waitpid()系统调用来回收子进程。
-- **孤儿进程** :一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况下,该进程就是孤儿进程。孤儿进程通常是由于父进程意外终止或未及时调用 wait()或 waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
+- **僵尸进程**:子进程已经终止,但是其父进程仍在运行,且父进程没有调用 wait()或 waitpid()等系统调用来获取子进程的状态信息,释放子进程占用的资源,导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。这种情况下,子进程被称为“僵尸进程”。避免僵尸进程的产生,父进程需要及时调用 wait()或 waitpid()系统调用来回收子进程。
+- **孤儿进程**:一个进程的父进程已经终止或者不存在,但是该进程仍在运行。这种情况下,该进程就是孤儿进程。孤儿进程通常是由于父进程意外终止或未及时调用 wait()或 waitpid()等系统调用来回收子进程导致的。为了避免孤儿进程占用系统资源,操作系统会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
### 如何查看是否有僵尸进程?
@@ -305,7 +305,7 @@ ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,......,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
-**注意 ⚠️** :这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
+**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
下面是百度百科对必要条件的解释:
@@ -384,7 +384,7 @@ Thread[线程 2,5,main]waiting get resource1
破坏第一个条件 **互斥条件**:使得资源是可以同时访问的,这是种简单的方法,磁盘就可以用这种方法管理,但是我们要知道,有很多资源 **往往是不能同时访问的** ,所以这种做法在大多数的场合是行不通的。
-破坏第三个条件 **非抢占** :也就是说可以采用 **剥夺式调度算法**,但剥夺式调度方法目前一般仅适用于 **主存资源** 和 **处理器资源** 的分配,并不适用于所有的资源,会导致 **资源利用率下降**。
+破坏第三个条件 **非抢占**:也就是说可以采用 **剥夺式调度算法**,但剥夺式调度方法目前一般仅适用于 **主存资源** 和 **处理器资源** 的分配,并不适用于所有的资源,会导致 **资源利用率下降**。
所以一般比较实用的 **预防死锁的方法**,是通过考虑破坏第二个条件和第四个条件。
@@ -444,10 +444,10 @@ Thread[线程 2,5,main]waiting get resource1
当死锁检测程序检测到存在死锁发生时,应设法让其解除,让系统从死锁状态中恢复过来,常用的解除死锁的方法有以下四种:
-1. **立即结束所有进程的执行,重新启动操作系统** :这种方法简单,但以前所在的工作全部作废,损失很大。
-2. **撤销涉及死锁的所有进程,解除死锁后继续运行** :这种方法能彻底打破**死锁的循环等待**条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
+1. **立即结束所有进程的执行,重新启动操作系统**:这种方法简单,但以前所在的工作全部作废,损失很大。
+2. **撤销涉及死锁的所有进程,解除死锁后继续运行**:这种方法能彻底打破**死锁的循环等待**条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
3. **逐个撤销涉及死锁的进程,回收其资源直至死锁解除。**
-4. **抢占资源** :从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
+4. **抢占资源**:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
## 参考
diff --git a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
index e0cd1da737e..1c9d4f26822 100644
--- a/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
+++ b/docs/cs-basics/operating-system/operating-system-basic-questions-02.md
@@ -20,20 +20,20 @@ head:
操作系统的内存管理非常重要,主要负责下面这些事情:
-- **内存的分配与回收** :对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
-- **地址转换** :将程序中的虚拟地址转换成内存中的物理地址。
-- **内存扩充** :当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
-- **内存映射** :将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
-- **内存优化** :通过调整内存分配策略和回收算法来优化内存使用效率。
-- **内存安全** :保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
+- **内存的分配与回收**:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
+- **地址转换**:将程序中的虚拟地址转换成内存中的物理地址。
+- **内存扩充**:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
+- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
+- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
+- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
- ......
### 什么是内存碎片?
内存碎片是由内存的申请和释放产生的,通常分为下面两种:
-- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)** :已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
-- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)** :由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并为分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
+- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)**:已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
+- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并为分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
@@ -43,8 +43,8 @@ head:
内存管理方式可以简单分为下面两种:
-- **连续内存管理** :为一个用户程序分配一个连续的内存空间,内存利用率一般不高。
-- **非连续内存管理** :允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些。
+- **连续内存管理**:为一个用户程序分配一个连续的内存空间,内存利用率一般不高。
+- **非连续内存管理**:允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些。
#### 连续内存管理
@@ -68,9 +68,9 @@ head:
非连续内存管理存在下面 3 种方式:
-- **段式管理** :以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
-- **页式管理** :把物理内存分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页,现代操作系统广泛使用的一种内存管理方式。
-- **段页式管理机制** :结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+- **段式管理**:以段(—段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页,现代操作系统广泛使用的一种内存管理方式。
+- **段页式管理机制**:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
### 虚拟内存
@@ -82,12 +82,12 @@ head:
总结来说,虚拟内存主要提供了下面这些能力:
-- **隔离进程** :物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
-- **提升物理内存利用率** :有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
-- **简化内存管理** :进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
+- **隔离进程**:物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+- **提升物理内存利用率**:有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
+- **简化内存管理**:进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
- **多个进程共享物理内存**:进程在运行过程中,会加载许多操作系统的动态库。这些库对于每个进程而言都是公用的,它们在内存中实际只会加载一份,这部分称为共享内存。
-- **提高内存使用安全性** :控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
-- **提供更大的可使用内存空间** :可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
+- **提高内存使用安全性**:控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
+- **提供更大的可使用内存空间**:可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
#### 没有虚拟内存有什么问题?
@@ -139,8 +139,8 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
分段机制下的虚拟地址由两部分组成:
-- **段号** :标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
-- **段内偏移量** :相对于该段起始地址的偏移量。
+- **段号**:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
+- **段内偏移量**:相对于该段起始地址的偏移量。
具体的地址翻译过程如下:
@@ -156,8 +156,8 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
不一定。段表项可能并不存在:
-- **段表项被删除** :软件错误、软件恶意行为等情况可能会导致段表项被删除。
-- **段表项还未创建** :如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
+- **段表项被删除**:软件错误、软件恶意行为等情况可能会导致段表项被删除。
+- **段表项还未创建**:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
#### 分段机制为什么会导致内存外部碎片?
@@ -192,8 +192,8 @@ MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
分页机制下的虚拟地址由两部分组成:
-- **页号** :通过虚拟页号可以从页表中取出对应的物理页号;
-- **页内偏移量** :物理页起始地址+页内偏移量=物理内存地址。
+- **页号**:通过虚拟页号可以从页表中取出对应的物理页号;
+- **页内偏移量**:物理页起始地址+页内偏移量=物理内存地址。
具体的地址翻译过程如下:
@@ -264,7 +264,7 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
常见的页缺失有下面这两种:
-- **硬性页缺失(Hard Page Fault)** :物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
+- **硬性页缺失(Hard Page Fault)**:物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
- **软性页缺失(Soft Page Fault)**:物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 **无效缺页错误(Invalid Page Fault)** 。
@@ -281,18 +281,18 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
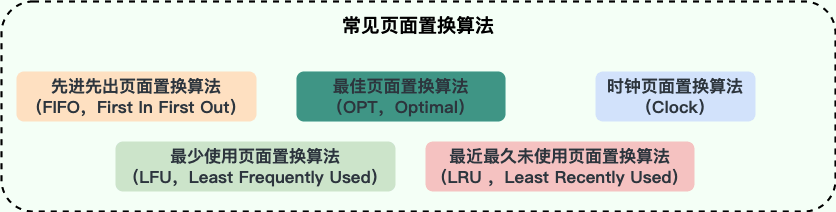
-1. **最佳页面置换算法(OPT,Optimal)** :优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
+1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
-3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)** :LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
+3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
-5. **时钟页面置换算法(Clock)** :可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
+5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
**FIFO 页面置换算法性能为何不好?**
主要原因主要有二:
-1. **经常访问或者需要长期存在的页面会被频繁调入调出** :较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出。
-2. **存在 Belady 现象** :被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性。
+1. **经常访问或者需要长期存在的页面会被频繁调入调出**:较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出。
+2. **存在 Belady 现象**:被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性。
**哪一种页面置换算法实际用的比较多?**
@@ -302,12 +302,12 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 分页机制和分段机制有哪些共同点和区别?
-**共同点** :
+**共同点**:
- 都是非连续内存管理的方式。
- 都采用了地址映射的方法,将虚拟地址映射到物理地址,以实现对内存的管理和保护。
-**区别** :
+**区别**:
- 分页机制以页面为单位进行内存管理,而分段机制以段为单位进行内存管理。页的大小是固定的,由操作系统决定,通常为 2 的幂次方。而段的大小不固定,取决于我们当前运行的程序。
- 页是物理单位,即操作系统将物理内存划分成固定大小的页面,每个页面的大小通常是 2 的幂次方,例如 4KB、8KB 等等。而段则是逻辑单位,是为了满足程序对内存空间的逻辑需求而设计的,通常根据程序中数据和代码的逻辑结构来划分。
@@ -332,8 +332,8 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
在分页机制中,页表的作用是将虚拟地址转换为物理地址,从而完成内存访问。在这个过程中,局部性原理的作用体现在两个方面:
-- **时间局部性** :由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
-- **空间局部性** :由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
+- **时间局部性**:由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
+- **空间局部性**:由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
总之,局部性原理是计算机体系结构设计的重要原则之一,也是许多优化算法的基础。在分页机制中,利用时间局部性和空间局部性,采用缓存和预取技术,可以提高页面的命中率,从而提高内存访问效率
@@ -343,10 +343,10 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
文件系统主要负责管理和组织计算机存储设备上的文件和目录,其功能包括以下几个方面:
-1. **存储管理** :将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
-2. **文件管理** :文件的创建、删除、移动、重命名、压缩、加密、共享等等。
-3. **目录管理** :目录的创建、删除、移动、重命名等等。
-4. **文件访问控制** :管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
+1. **存储管理**:将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
+2. **文件管理**:文件的创建、删除、移动、重命名、压缩、加密、共享等等。
+3. **目录管理**:目录的创建、删除、移动、重命名等等。
+4. **文件访问控制**:管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
### 硬链接和软链接有什么区别?
@@ -375,11 +375,11 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
### 提高文件系统性能的方式有哪些?
-- **优化硬件** :使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
-- **选择合适的文件系统选型** :不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
-- **运用缓存** :访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
-- **避免磁盘过度使用** :注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
-- **对磁盘进行合理的分区** :合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能。
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能。
+- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
+- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
+- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
+- **对磁盘进行合理的分区**:合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能。
### 常见的磁盘调度算法有哪些?
@@ -391,12 +391,12 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
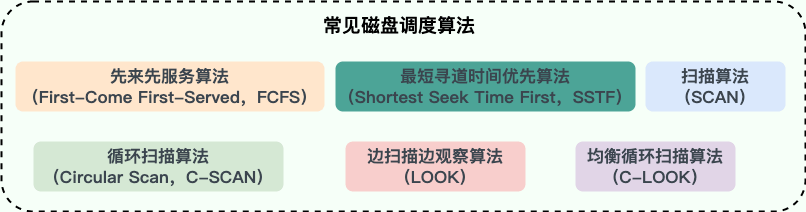
-1. **先来先服务算法(First-Come First-Served,FCFS)** :按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
-2. **最短寻道时间优先算法(Shortest Seek Time First,SSTF)** :也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
-3. **扫描算法(SCAN)** :也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
-4. **循环扫描算法(Circular Scan,C-SCAN)** :SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
-5. **边扫描边观察算法(LOOK)** :SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
-6. **均衡循环扫描算法(C-LOOK)** :C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
+1. **先来先服务算法(First-Come First-Served,FCFS)**:按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
+2. **最短寻道时间优先算法(Shortest Seek Time First,SSTF)**:也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
+3. **扫描算法(SCAN)**:也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
+4. **循环扫描算法(Circular Scan,C-SCAN)**:SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
+5. **边扫描边观察算法(LOOK)**:SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
+6. **均衡循环扫描算法(C-LOOK)**:C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
## 参考
diff --git a/docs/cs-basics/operating-system/shell-intro.md b/docs/cs-basics/operating-system/shell-intro.md
index 9956bc1f045..a9f666fb7d5 100644
--- a/docs/cs-basics/operating-system/shell-intro.md
+++ b/docs/cs-basics/operating-system/shell-intro.md
@@ -69,7 +69,7 @@ shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
-3. **Shell 变量** :Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
**常用的环境变量:**
diff --git a/docs/database/basis.md b/docs/database/basis.md
index e062466b333..8848dcfbad3 100644
--- a/docs/database/basis.md
+++ b/docs/database/basis.md
@@ -16,12 +16,12 @@ tag:
## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
-- **元组** :元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
-- **码** :码就是能唯一标识实体的属性,对应表中的列。
-- **候选码** :若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
+- **元组**:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
+- **码**:码就是能唯一标识实体的属性,对应表中的列。
+- **候选码**:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
-- **主属性** :候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
+- **主属性**:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
## 什么是 ER 图?
@@ -32,9 +32,9 @@ tag:
ER 图由下面 3 个要素组成:
-- **实体** :通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
-- **属性** :即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
-- **联系** :即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
+- **实体**:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
+- **属性**:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
+- **联系**:即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
@@ -60,10 +60,10 @@ ER 图由下面 3 个要素组成:
一些重要的概念:
-- **函数依赖(functional dependency)** :若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
-- **部分函数依赖(partial functional dependency)** :如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
-- **完全函数依赖(Full functional dependency)** :在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
-- **传递函数依赖** :在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
+- **函数依赖(functional dependency)**:若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
+- **部分函数依赖(partial functional dependency)**:如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
+- **完全函数依赖(Full functional dependency)**:在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
+- **传递函数依赖**:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
### 3NF(第三范式)
@@ -71,8 +71,8 @@ ER 图由下面 3 个要素组成:
## 主键和外键有什么区别?
-- **主键(主码)** :主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
-- **外键(外码)** :外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
+- **主键(主码)**:主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
+- **外键(外码)**:外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
## 为什么不推荐使用外键与级联?
@@ -86,7 +86,7 @@ ER 图由下面 3 个要素组成:
1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
-3. **对分库分表不友好** :因为分库分表下外键是无法生效的。
+3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
4. ......
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
diff --git a/docs/database/character-set.md b/docs/database/character-set.md
index e63b778e43e..2e5f829afc0 100644
--- a/docs/database/character-set.md
+++ b/docs/database/character-set.md
@@ -112,8 +112,8 @@ MySQL 支持很多种字符编码的方式,比如 UTF-8、GB2312、GBK、BIG5
MySQL 字符编码集中有两套 UTF-8 编码实现:
-- **`utf8`** :`utf8`编码只支持`1-3`个字节 。 在 `utf8` 编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
-- **`utf8mb4`** :UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
+- **`utf8`**:`utf8`编码只支持`1-3`个字节 。 在 `utf8` 编码中,中文是占 3 个字节,其他数字、英文、符号占一个字节。但 emoji 符号占 4 个字节,一些较复杂的文字、繁体字也是 4 个字节。
+- **`utf8mb4`**:UTF-8 的完整实现,正版!最多支持使用 4 个字节表示字符,因此,可以用来存储 emoji 符号。
**为什么有两套 UTF-8 编码实现呢?** 原因如下:
diff --git a/docs/database/mongodb/mongodb-questions-01.md b/docs/database/mongodb/mongodb-questions-01.md
index 7c9fec7161b..87dd4d9158b 100644
--- a/docs/database/mongodb/mongodb-questions-01.md
+++ b/docs/database/mongodb/mongodb-questions-01.md
@@ -20,13 +20,13 @@ MongoDB 是一个基于 **分布式文件存储** 的开源 NoSQL 数据库系
MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三个单元组成:
-- **文档(Document)** :MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
-- **集合(Collection)** :一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
-- **数据库(Database)** :一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
+- **文档(Document)**:MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
+- **集合(Collection)**:一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
+- **数据库(Database)**:一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
也就是说,MongoDB 将数据记录存储为文档 (更具体来说是[BSON 文档](https://www.mongodb.com/docs/manual/core/document/#std-label-bson-document-format)),这些文档在集合中聚集在一起,数据库中存储一个或多个文档集合。
-**SQL 与 MongoDB 常见术语对比** :
+**SQL 与 MongoDB 常见术语对比**:
| SQL | MongoDB |
| ------------------------ | ------------------------------- |
@@ -95,17 +95,17 @@ MongoDB 预留了几个特殊的数据库。
### MongoDB 有什么特点?
-- **数据记录被存储为文档** :MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
-- **模式自由** :集合的概念类似 MySQL 里的表,但它不需要定义任何模式,能够用更少的数据对象表现复杂的领域模型对象。
-- **支持多种查询方式** :MongoDB 查询 API 支持读写操作 (CRUD)以及数据聚合、文本搜索和地理空间查询。
-- **支持 ACID 事务** :NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。与关系型数据库一样,MongoDB 事务同样具有 ACID 特性。MongoDB 单文档原生支持原子性,也具备事务的特性。MongoDB 4.0 加入了对多文档事务的支持,但只支持复制集部署模式下的事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了分布式事务,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
-- **高效的二进制存储** :存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
-- **自带数据压缩功能** :存储同样的数据所需的资源更少。
-- **支持 mapreduce** :通过分治的方式完成复杂的聚合任务。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
-- **支持多种类型的索引** :MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
-- **支持 failover** :提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
-- **支持分片集群** :MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
-- **支持存储大文件** :MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
+- **数据记录被存储为文档**:MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
+- **模式自由**:集合的概念类似 MySQL 里的表,但它不需要定义任何模式,能够用更少的数据对象表现复杂的领域模型对象。
+- **支持多种查询方式**:MongoDB 查询 API 支持读写操作 (CRUD)以及数据聚合、文本搜索和地理空间查询。
+- **支持 ACID 事务**:NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。与关系型数据库一样,MongoDB 事务同样具有 ACID 特性。MongoDB 单文档原生支持原子性,也具备事务的特性。MongoDB 4.0 加入了对多文档事务的支持,但只支持复制集部署模式下的事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了分布式事务,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
+- **高效的二进制存储**:存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
+- **自带数据压缩功能**:存储同样的数据所需的资源更少。
+- **支持 mapreduce**:通过分治的方式完成复杂的聚合任务。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
+- **支持多种类型的索引**:MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
+- **支持 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+- **支持分片集群**:MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
+- **支持存储大文件**:MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
### MongoDB 适合什么应用场景?
@@ -132,8 +132,8 @@ MongoDB 预留了几个特殊的数据库。
现在主要有下面这两种存储引擎:
-- **WiredTiger 存储引擎** :自 MongoDB 3.2 以后,默认的存储引擎为 [WiredTiger 存储引擎](https://www.mongodb.com/docs/manual/core/wiredtiger/) 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
-- **In-Memory 存储引擎** :[In-Memory 存储引擎](https://www.mongodb.com/docs/manual/core/inmemory/)在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
+- **WiredTiger 存储引擎**:自 MongoDB 3.2 以后,默认的存储引擎为 [WiredTiger 存储引擎](https://www.mongodb.com/docs/manual/core/wiredtiger/) 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
+- **In-Memory 存储引擎**:[In-Memory 存储引擎](https://www.mongodb.com/docs/manual/core/inmemory/)在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
此外,MongoDB 3.0 提供了 **可插拔的存储引擎 API** ,允许第三方为 MongoDB 开发存储引擎,这点和 MySQL 也比较类似。
@@ -153,8 +153,8 @@ WiredTiger maintains a table's data in memory using a data structure called a B-
使用 B+ 树时,WiredTiger 以 **page** 为基本单位往磁盘读写数据。B+ 树的每个节点为一个 page,共有三种类型的 page:
-- **root page(根节点)** :B+ 树的根节点。
-- **internal page(内部节点)** :不实际存储数据的中间索引节点。
+- **root page(根节点)**:B+ 树的根节点。
+- **internal page(内部节点)**:不实际存储数据的中间索引节点。
- **leaf page(叶子节点)**:真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
其整体结构如下图所示:
@@ -179,8 +179,8 @@ WiredTiger maintains a table's data in memory using a data structure called a B-
MongoDB 提供了两种执行聚合的方法:
-- **聚合管道(Aggregation Pipeline)** :执行聚合操作的首选方法。
-- **单一目的聚合方法(Single purpose aggregation methods)** :也就是单一作用的聚合函数比如 `count()`、`distinct()`、`estimatedDocumentCount()`。
+- **聚合管道(Aggregation Pipeline)**:执行聚合操作的首选方法。
+- **单一目的聚合方法(Single purpose aggregation methods)**:也就是单一作用的聚合函数比如 `count()`、`distinct()`、`estimatedDocumentCount()`。
绝大部分文章中还提到了 **map-reduce** 这种聚合方法。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
@@ -194,7 +194,7 @@ MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时
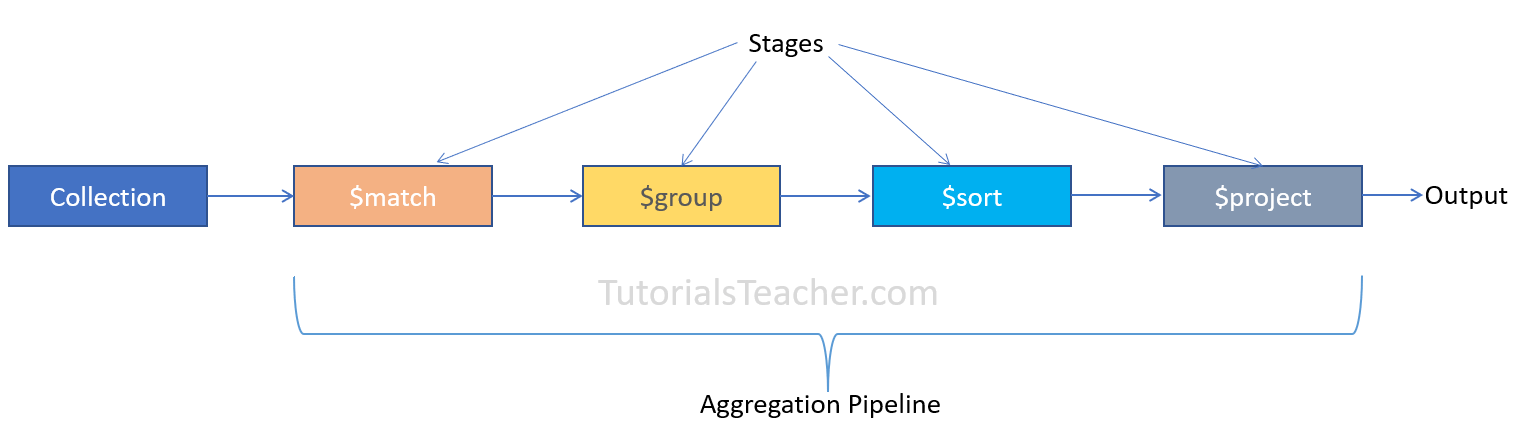
-**常用阶段操作符** :
+**常用阶段操作符**:
| 操作符 | 简述 |
| --------- | ---------------------------------------------------------------------------------------------------- |
@@ -241,7 +241,7 @@ db.orders.aggregate([
与关系型数据库一样,MongoDB 事务同样具有 ACID 特性:
-- **原子性**(`Atomicity`) :事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+- **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
- **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
- **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
@@ -256,7 +256,7 @@ MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 Mo
在大多数情况下,多文档事务比单文档写入会产生更大的性能成本。对于大部分场景来说, [非规范化数据模型(嵌入式文档和数组)](https://www.mongodb.com/docs/upcoming/core/data-model-design/#std-label-data-modeling-embedding) 依然是最佳选择。也就是说,适当地对数据进行建模可以最大限度地减少对多文档事务的需求。
-**注意** :
+**注意**:
- 从 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中:主节点使用 WiredTiger 存储引擎,同时从节点使用 WiredTiger 存储引擎或 In-Memory 存储引擎。在 MongoDB 4.0 中,只有使用 WiredTiger 存储引擎的副本集支持事务。
- 在 MongoDB 4.2 及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。有关详细信息,请参阅 [在事务中创建集合和索引](https://www.mongodb.com/docs/upcoming/core/transactions/#std-label-transactions-create-collections-indexes)。
diff --git a/docs/database/mongodb/mongodb-questions-02.md b/docs/database/mongodb/mongodb-questions-02.md
index acbf96e8be0..9e4ab9e5eb1 100644
--- a/docs/database/mongodb/mongodb-questions-02.md
+++ b/docs/database/mongodb/mongodb-questions-02.md
@@ -20,12 +20,12 @@ tag:
- **单字段索引:** 建立在单个字段上的索引,索引创建的排序顺序无所谓,MongoDB 可以头/尾开始遍历。
- **复合索引:** 建立在多个字段上的索引,也可以称之为组合索引、联合索引。
-- **多键索引** :MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
-- **哈希索引** :按数据的哈希值索引,用在哈希分片集群上。
+- **多键索引**:MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
+- **哈希索引**:按数据的哈希值索引,用在哈希分片集群上。
- **文本索引:** 支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。一个集合只能有一个文本搜索索引,但该索引可以覆盖多个字段。MongoDB 虽然支持全文索引,但是性能低下,暂时不建议使用。
- **地理位置索引:** 基于经纬度的索引,适合 2D 和 3D 的位置查询。
-- **唯一索引** :确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
-- **TTL 索引** :TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
+- **唯一索引**:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
+- **TTL 索引**:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
- ......
### 复合索引中字段的顺序有影响吗?
@@ -62,7 +62,7 @@ db.s2.find().sort({"score": -1, "userid": 1}).explain()
### 复合索引遵循左前缀原则吗?
-**MongoDB 的复合索引遵循左前缀原则** :拥有多个键的索引,可以同时得到所有这些键的前缀组成的索引,但不包括除左前缀之外的其他子集。比如说,有一个类似 `{a: 1, b: 1, c: 1, ..., z: 1}` 这样的索引,那么实际上也等于有了 `{a: 1}`、`{a: 1, b: 1}`、`{a: 1, b: 1, c: 1}` 等一系列索引,但是不会有 `{b: 1}` 这样的非左前缀的索引。
+**MongoDB 的复合索引遵循左前缀原则**:拥有多个键的索引,可以同时得到所有这些键的前缀组成的索引,但不包括除左前缀之外的其他子集。比如说,有一个类似 `{a: 1, b: 1, c: 1, ..., z: 1}` 这样的索引,那么实际上也等于有了 `{a: 1}`、`{a: 1, b: 1}`、`{a: 1, b: 1, c: 1}` 等一系列索引,但是不会有 `{b: 1}` 这样的非左前缀的索引。
### 什么是 TTL 索引?
@@ -70,12 +70,12 @@ TTL 索引提供了一个过期机制,允许为每一个文档设置一个过
数据过期对于某些类型的信息很有用,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间。
-**TTL 索引运行原理** :
+**TTL 索引运行原理**:
- MongoDB 会开启一个后台线程读取该 TTL 索引的值来判断文档是否过期,但不会保证已过期的数据会立马被删除,因后台线程每 60 秒触发一次删除任务,且如果删除的数据量较大,会存在上一次的删除未完成,而下一次的任务已经开启的情况,导致过期的数据也会出现超过了数据保留时间 60 秒以上的现象。
- 对于副本集而言,TTL 索引的后台进程只会在 Primary 节点开启,在从节点会始终处于空闲状态,从节点的数据删除是由主库删除后产生的 oplog 来做同步。
-**TTL 索引限制** :
+**TTL 索引限制**:
- TTL 索引是单字段索引。复合索引不支持 TTL
- `_id`字段不支持 TTL 索引。
@@ -131,9 +131,9 @@ MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合
通常来说,一个复制集群包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
-- **主节点** :整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
-- **从节点** :从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
-- **仲裁节点** :这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
+- **主节点**:整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
+- **从节点**:从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
+- **仲裁节点**:这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
下图是一个典型的三成员副本集群:
@@ -151,8 +151,8 @@ MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合
#### 为什么要用复制集群?
-- **实现 failover** :提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
-- **实现读写分离** :我们可以设置从节点上可以读取数据,主节点负责写入数据,这样的话就实现了读写分离,减轻了主节点读写压力过大的问题。MongoDB 4.0 之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据接受一定时间延迟。
+- **实现 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+- **实现读写分离**:我们可以设置从节点上可以读取数据,主节点负责写入数据,这样的话就实现了读写分离,减轻了主节点读写压力过大的问题。MongoDB 4.0 之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据接受一定时间延迟。
### 分片集群
@@ -207,7 +207,7 @@ MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文
MongoDB 支持两种分片算法来满足不同的查询需求(摘自[MongoDB 分片集群介绍 - 阿里云文档](https://help.aliyun.com/document_detail/64561.html?spm=a2c4g.11186623.0.0.3121565eQhUGGB#h2--shard-key-3)):
-**1、基于范围的分片** :
+**1、基于范围的分片**:
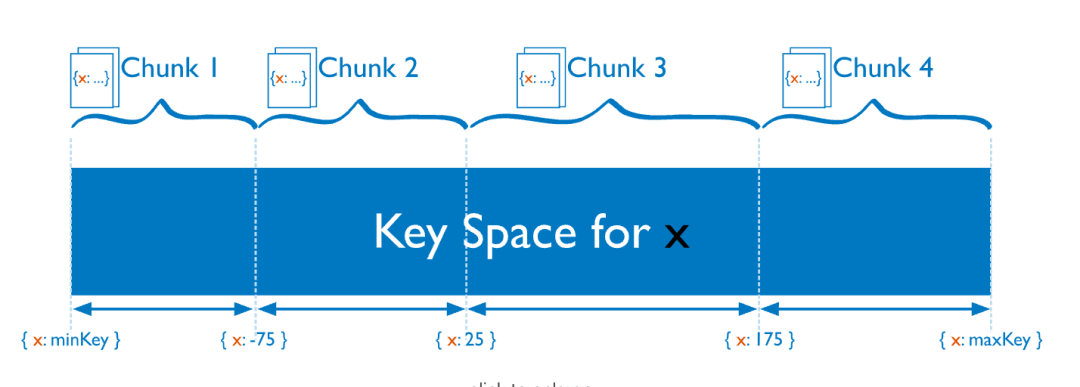
@@ -259,7 +259,7 @@ Rebalance 操作是比较耗费系统资源的,我们可以通过在业务低
- [MongoDB 中文手册|官方文档中文版](https://docs.mongoing.com/)(推荐):基于 4.2 版本,不断与官方最新版保持同步。
- [MongoDB 初学者教程——7 天学习 MongoDB](https://mongoing.com/archives/docs/mongodb%e5%88%9d%e5%ad%a6%e8%80%85%e6%95%99%e7%a8%8b/mongodb%e5%a6%82%e4%bd%95%e5%88%9b%e5%bb%ba%e6%95%b0%e6%8d%ae%e5%ba%93%e5%92%8c%e9%9b%86%e5%90%88):快速入门。
-- [SpringBoot 整合 MongoDB 实战 - 2022](https://www.cnblogs.com/dxflqm/p/16643981.html) :很不错的一篇 MongoDB 入门文章,主要围绕 MongoDB 的 Java 客户端使用进行基本的增删改查操作介绍。
+- [SpringBoot 整合 MongoDB 实战 - 2022](https://www.cnblogs.com/dxflqm/p/16643981.html):很不错的一篇 MongoDB 入门文章,主要围绕 MongoDB 的 Java 客户端使用进行基本的增删改查操作介绍。
## 参考
diff --git a/docs/database/mysql/innodb-implementation-of-mvcc.md b/docs/database/mysql/innodb-implementation-of-mvcc.md
index a98231b42f1..a4dbbb90261 100644
--- a/docs/database/mysql/innodb-implementation-of-mvcc.md
+++ b/docs/database/mysql/innodb-implementation-of-mvcc.md
@@ -85,13 +85,13 @@ private:
**在 `InnoDB` 存储引擎中 `undo log` 分为两种:`insert undo log` 和 `update undo log`:**
-1. **`insert undo log`** :指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
+1. **`insert undo log`**:指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
**`insert` 时的数据初始状态:**

-2. **`update undo log`** :`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
+2. **`update undo log`**:`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
**数据第一次被修改时:**
@@ -190,7 +190,7 @@ private:

-在 RR 级别下只会生成一次`Read View`,所以此时依然沿用 **`m_ids` :[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
+在 RR 级别下只会生成一次`Read View`,所以此时依然沿用 **`m_ids`:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
- 最新记录的 `DB_TRX_ID` 为 102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
@@ -204,7 +204,7 @@ private:

-此时情况跟 T6 完全一样,由于已经生成了 `Read View`,此时依然沿用 **`m_ids` :[101,102]** ,所以查询结果依然是 `name = 菜花`
+此时情况跟 T6 完全一样,由于已经生成了 `Read View`,此时依然沿用 **`m_ids`:[101,102]** ,所以查询结果依然是 `name = 菜花`
## MVCC➕Next-key-Lock 防止幻读
diff --git a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
index f2c9107977e..1f83a100287 100644
--- a/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
+++ b/docs/database/mysql/mysql-high-performance-optimization-specification-recommendations.md
@@ -90,7 +90,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
MySQL 提供了两个方法来处理 ip 地址
-- `INET_ATON()` :把 ip 转为无符号整型 (4-8 位)
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
- `INET_NTOA()` :把整型的 ip 转为地址
插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
@@ -150,8 +150,8 @@ TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高
### 同财务相关的金额类数据必须使用 decimal 类型
-- **非精准浮点** :float,double
-- **精准浮点** :decimal
+- **非精准浮点**:float,double
+- **精准浮点**:decimal
decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据
diff --git a/docs/database/mysql/mysql-index.md b/docs/database/mysql/mysql-index.md
index a4d447e42b4..e4408e45241 100644
--- a/docs/database/mysql/mysql-index.md
+++ b/docs/database/mysql/mysql-index.md
@@ -21,12 +21,12 @@ tag:
## 索引的优缺点
-**优点** :
+**优点**:
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-**缺点** :
+**缺点**:
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
@@ -131,11 +131,11 @@ MySQL 8.x 中实现的索引新特性:
PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
-1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
-2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
-3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
+1. **唯一索引(Unique Key)**:唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)**:**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
+3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
因为只取前几个字符。
-4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
二级索引:
@@ -153,15 +153,15 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
#### 聚簇索引的优缺点
-**优点** :
+**优点**:
-- **查询速度非常快** :聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
-- **对排序查找和范围查找优化** :聚簇索引对于主键的排序查找和范围查找速度非常快。
+- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
+- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
-**缺点** :
+**缺点**:
-- **依赖于有序的数据** :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
-- **更新代价大** :如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
+- **依赖于有序的数据**:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
### 非聚簇索引(非聚集索引)
@@ -173,14 +173,14 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
#### 非聚簇索引的优缺点
-**优点** :
+**优点**:
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
-**缺点** :
+**缺点**:
-- **依赖于有序的数据** :跟聚簇索引一样,非聚簇索引也依赖于有序的数据
-- **可能会二次查询(回表)** :这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据
+- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
这是 MySQL 的表的文件截图:
@@ -312,11 +312,11 @@ ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
### 选择合适的字段创建索引
-- **不为 NULL 的字段** :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
-- **被频繁查询的字段** :我们创建索引的字段应该是查询操作非常频繁的字段。
-- **被作为条件查询的字段** :被作为 WHERE 条件查询的字段,应该被考虑建立索引。
-- **频繁需要排序的字段** :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
-- **被经常频繁用于连接的字段** :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
### 被频繁更新的字段应该慎重建立索引
diff --git a/docs/database/mysql/mysql-logs.md b/docs/database/mysql/mysql-logs.md
index 1a89e5b6304..f3888285905 100644
--- a/docs/database/mysql/mysql-logs.md
+++ b/docs/database/mysql/mysql-logs.md
@@ -43,9 +43,9 @@ tag:
`InnoDB` 存储引擎为 `redo log` 的刷盘策略提供了 `innodb_flush_log_at_trx_commit` 参数,它支持三种策略:
-- **0** :设置为 0 的时候,表示每次事务提交时不进行刷盘操作
-- **1** :设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)
-- **2** :设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
+- **0**:设置为 0 的时候,表示每次事务提交时不进行刷盘操作
+- **1**:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)
+- **2**:设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
`innodb_flush_log_at_trx_commit` 参数默认为 1 ,也就是说当事务提交时会调用 `fsync` 对 redo log 进行刷盘
diff --git a/docs/database/mysql/mysql-query-cache.md b/docs/database/mysql/mysql-query-cache.md
index a676289393b..5d80e0f5a14 100644
--- a/docs/database/mysql/mysql-query-cache.md
+++ b/docs/database/mysql/mysql-query-cache.md
@@ -80,7 +80,7 @@ mysql> show variables like '%query_cache%';
- **`query_cache_min_res_unit`:** 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过 `query_cache_min_res_unit` 的值 ,这时候 MySQL 将一边检索结果,一边进行保存结果,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节 `query_cache_min_res_unit` 可以优化内存。
- **`query_cache_size`:** 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。默认值是 0,即禁用查询缓存。
- **`query_cache_type`:** 设置查询缓存类型,默认为 ON。设置 GLOBAL 值可以设置后面的所有客户端连接的类型。客户端可以设置 SESSION 值以影响他们自己对查询缓存的使用。
-- **`query_cache_wlock_invalidate`** :如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
+- **`query_cache_wlock_invalidate`**:如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
`query_cache_type` 可能的值(修改 `query_cache_type` 需要重启 MySQL Server):
@@ -88,7 +88,7 @@ mysql> show variables like '%query_cache%';
- 1 或 ON:开启查询缓存功能,但不缓存 `Select SQL_NO_CACHE` 开头的查询。
- 2 或 DEMAND:开启查询缓存功能,但仅缓存 `Select SQL_CACHE` 开头的查询。
-**建议** :
+**建议**:
- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
- 建议通过调整 `query_cache_size` 的值来开启、关闭查询缓存,因为修改`query_cache_type` 参数需要重启 MySQL Server 生效。
@@ -109,7 +109,7 @@ set global query_cache_size=600000;
手动清理缓存可以使用下面三个 SQL:
-- `flush query cache;` :清理查询缓存内存碎片。
+- `flush query cache;`:清理查询缓存内存碎片。
- `reset query cache;`:从查询缓存中移除所有查询。
- `flush tables;` 关闭所有打开的表,同时该操作会清空查询缓存中的内容。
diff --git a/docs/database/mysql/mysql-questions-01.md b/docs/database/mysql/mysql-questions-01.md
index e316053357b..ec57f20d628 100644
--- a/docs/database/mysql/mysql-questions-01.md
+++ b/docs/database/mysql/mysql-questions-01.md
@@ -85,7 +85,7 @@ MySQL 主要具有下面这些优点:
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- **优化器:** 按照 MySQL 认为最优的方案去执行。
- **执行器:** 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
-- **插件式存储引擎** :主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+- **插件式存储引擎**:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
## MySQL 存储引擎
@@ -209,7 +209,7 @@ InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是
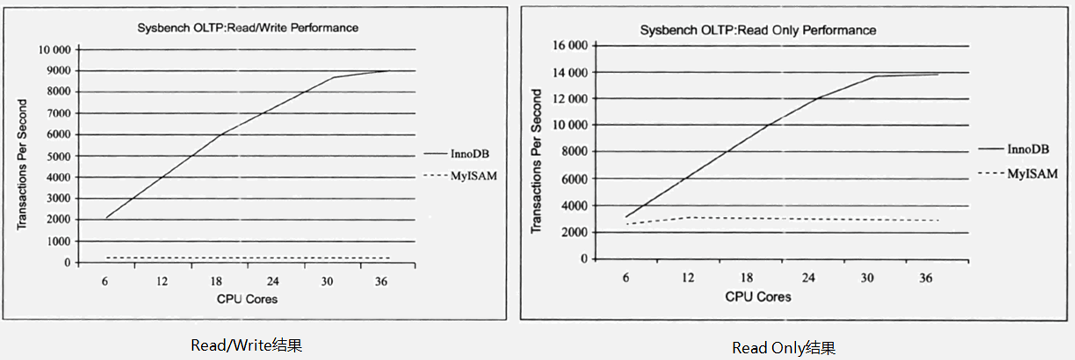
-**总结** :
+**总结**:
- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
@@ -335,7 +335,7 @@ COMMIT;
-1. **原子性**(`Atomicity`) :事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+1. **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
2. **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
3. **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
4. **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
@@ -408,8 +408,8 @@ MySQL 中并发事务的控制方式无非就两种:**锁** 和 **MVCC**。锁
**锁** 控制方式下会通过锁来显示控制共享资源而不是通过调度手段,MySQL 中主要是通过 **读写锁** 来实现并发控制。
-- **共享锁(S 锁)** :又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
-- **排他锁(X 锁)** :又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
+- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
+- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
读写锁可以做到读读并行,但是无法做到写读、写写并行。另外,根据根据锁粒度的不同,又被分为 **表级锁(table-level locking)** 和 **行级锁(row-level locking)** 。InnoDB 不光支持表级锁,还支持行级锁,默认为行级锁。行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类。
@@ -426,10 +426,10 @@ MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view
SQL 标准定义了四个隔离级别:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
+- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
+- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
+- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
---
@@ -471,7 +471,7 @@ MyISAM 仅仅支持表级锁(table-level locking),一锁就锁整张表,这
行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。
-**表级锁和行级锁对比** :
+**表级锁和行级锁对比**:
- **表级锁:** MySQL 中锁定粒度最大的一种锁(全局锁除外),是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。不过,触发锁冲突的概率最高,高并发下效率极低。表级锁和存储引擎无关,MyISAM 和 InnoDB 引擎都支持表级锁。
- **行级锁:** MySQL 中锁定粒度最小的一种锁,是 **针对索引字段加的锁** ,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。行级锁和存储引擎有关,是在存储引擎层面实现的。
@@ -486,9 +486,9 @@ InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字
InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
-- **记录锁(Record Lock)** :也被称为记录锁,属于单个行记录上的锁。
-- **间隙锁(Gap Lock)** :锁定一个范围,不包括记录本身。
-- **临键锁(Next-Key Lock)** :Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
+- **记录锁(Record Lock)**:也被称为记录锁,属于单个行记录上的锁。
+- **间隙锁(Gap Lock)**:锁定一个范围,不包括记录本身。
+- **临键锁(Next-Key Lock)**:Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
**在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。**
@@ -498,8 +498,8 @@ InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL Inno
不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类:
-- **共享锁(S 锁)** :又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
-- **排他锁(X 锁)** :又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
+- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
+- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
排他锁与任何的锁都不兼容,共享锁仅和共享锁兼容。
@@ -638,7 +638,7 @@ CREATE TABLE `sequence_id` (
MySQL 提供了两个方法来处理 ip 地址
-- `INET_ATON()` :把 ip 转为无符号整型 (4-8 位)
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
- `INET_NTOA()` :把整型的 ip 转为地址
插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
@@ -696,7 +696,7 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
## MySQL 学习资料推荐
-**书籍推荐** :参见:[https://javaguide.cn/books/database.html#mysql](https://javaguide.cn/books/database.html#mysql) 。
+**书籍推荐**:参见:[https://javaguide.cn/books/database.html#mysql](https://javaguide.cn/books/database.html#mysql) 。
**文章推荐** :
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
index 7994e4a22af..e295fb44f4b 100644
--- a/docs/database/mysql/some-thoughts-on-database-storage-time.md
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -102,7 +102,7 @@ SET GLOBAL time_zone = 'Europe/Helsinki';
Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
-- DateTime :1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
+- DateTime:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
> Timestamp 在不同版本的 MySQL 中有细微差别。
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index d143906aba5..647b80ee6eb 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -13,10 +13,10 @@ tag:
SQL 标准定义了四个隔离级别:
-- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
+- **READ-UNCOMMITTED(读取未提交)**:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
+- **READ-COMMITTED(读取已提交)**:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
+- **REPEATABLE-READ(可重复读)**:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
+- **SERIALIZABLE(可串行化)**:最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
---
@@ -42,8 +42,8 @@ MySQL> SELECT @@tx_isolation;
但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
-- **快照读** :由 MVCC 机制来保证不出现幻读。
-- **当前读** :使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
+- **快照读**:由 MVCC 机制来保证不出现幻读。
+- **当前读**:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ** 并不会有任何性能损失。
diff --git a/docs/database/nosql.md b/docs/database/nosql.md
index b1b392280b0..fd70056fd2c 100644
--- a/docs/database/nosql.md
+++ b/docs/database/nosql.md
@@ -43,10 +43,10 @@ NoSQL 数据库非常适合许多现代应用程序,例如移动、Web 和游
NoSQL 数据库主要可以分为下面四种类型:
-- **键值** :键值数据库是一种较简单的数据库,其中每个项目都包含键和值。这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制。Redis 和 DynanoDB 是两款非常流行的键值数据库。
-- **文档** :文档数据库中的数据被存储在类似于 JSON(JavaScript 对象表示法)对象的文档中,非常清晰直观。每个文档包含成对的字段和值。这些值通常可以是各种类型,包括字符串、数字、布尔值、数组或对象等,并且它们的结构通常与开发者在代码中使用的对象保持一致。MongoDB 就是一款非常流行的文档数据库。
-- **图形** :图形数据库旨在轻松构建和运行与高度连接的数据集一起使用的应用程序。图形数据库的典型使用案例包括社交网络、推荐引擎、欺诈检测和知识图形。Neo4j 和 Giraph 是两款非常流行的图形数据库。
-- **宽列** :宽列存储数据库非常适合需要存储大量的数据。Cassandra 和 HBase 是两款非常流行的宽列存储数据库。
+- **键值**:键值数据库是一种较简单的数据库,其中每个项目都包含键和值。这是极为灵活的 NoSQL 数据库类型,因为应用可以完全控制 value 字段中存储的内容,没有任何限制。Redis 和 DynanoDB 是两款非常流行的键值数据库。
+- **文档**:文档数据库中的数据被存储在类似于 JSON(JavaScript 对象表示法)对象的文档中,非常清晰直观。每个文档包含成对的字段和值。这些值通常可以是各种类型,包括字符串、数字、布尔值、数组或对象等,并且它们的结构通常与开发者在代码中使用的对象保持一致。MongoDB 就是一款非常流行的文档数据库。
+- **图形**:图形数据库旨在轻松构建和运行与高度连接的数据集一起使用的应用程序。图形数据库的典型使用案例包括社交网络、推荐引擎、欺诈检测和知识图形。Neo4j 和 Giraph 是两款非常流行的图形数据库。
+- **宽列**:宽列存储数据库非常适合需要存储大量的数据。Cassandra 和 HBase 是两款非常流行的宽列存储数据库。
下面这张图片来源于 [微软的官方文档 | 关系数据与 NoSQL 数据](https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/relational-vs-nosql-data)。
diff --git a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
index 04e7c87ecff..91427109697 100644
--- a/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
+++ b/docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md
@@ -21,7 +21,7 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
下面我们来看一下这个策略模式下的缓存读写步骤。
-**写** :
+**写**:
- 先更新 db
- 然后直接删除 cache 。
@@ -72,8 +72,8 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
解决办法:
-- 数据库和缓存数据强一致场景 :更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
-- 可以短暂地允许数据库和缓存数据不一致的场景 :更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
### Read/Write Through Pattern(读写穿透)
diff --git a/docs/database/redis/redis-common-blocking-problems-summary.md b/docs/database/redis/redis-common-blocking-problems-summary.md
index ffd3f99113e..adddb099b78 100644
--- a/docs/database/redis/redis-common-blocking-problems-summary.md
+++ b/docs/database/redis/redis-common-blocking-problems-summary.md
@@ -49,8 +49,8 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
-2. `appendfsync everysec` :主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
-3. `appendfsync no` :主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index 0b5f0b68c8e..81267a3c5c8 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -63,7 +63,7 @@ String 是一种二进制安全的数据结构,可以用来存储任何类型
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=string 。
-**基本操作** :
+**基本操作**:
```bash
> SET key value
@@ -80,7 +80,7 @@ OK
(nil)
```
-**批量设置** :
+**批量设置**:
```bash
> MSET key1 value1 key2 value2
@@ -120,13 +120,13 @@ OK
**需要存储常规数据的场景**
-- 举例 :缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
-- 相关命令 :`SET`、`GET`。
+- 举例:缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
+- 相关命令:`SET`、`GET`。
**需要计数的场景**
-- 举例 :用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
-- 相关命令 :`SET`、`GET`、 `INCR`、`DECR` 。
+- 举例:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
+- 相关命令:`SET`、`GET`、 `INCR`、`DECR` 。
**分布式锁**
@@ -156,7 +156,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
更多 Redis List 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=list 。
-**通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`实现队列** :
+**通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`实现队列**:
```bash
> RPUSH myList value1
@@ -173,7 +173,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
2) "value3"
```
-**通过 `RPUSH/RPOP`或者`LPUSH/LPOP` 实现栈** :
+**通过 `RPUSH/RPOP`或者`LPUSH/LPOP` 实现栈**:
```bash
> RPUSH myList2 value1 value2 value3
@@ -186,7 +186,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据

-**通过 `LRANGE` 查看对应下标范围的列表元素** :
+**通过 `LRANGE` 查看对应下标范围的列表元素**:
```bash
> RPUSH myList value1 value2 value3
@@ -202,7 +202,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
通过 `LRANGE` 命令,你可以基于 List 实现分页查询,性能非常高!
-**通过 `LLEN` 查看链表长度** :
+**通过 `LLEN` 查看链表长度**:
```bash
> LLEN myList
@@ -213,8 +213,8 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
**信息流展示**
-- 举例 :最新文章、最新动态。
-- 相关命令 :`LPUSH`、`LRANGE`。
+- 举例:最新文章、最新动态。
+- 相关命令:`LPUSH`、`LRANGE`。
**消息队列**
@@ -249,7 +249,7 @@ Hash 类似于 JDK1.8 前的 `HashMap`,内部实现也差不多(数组 + 链
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=hash 。
-**模拟对象数据存储** :
+**模拟对象数据存储**:
```bash
> HMSET userInfoKey name "guide" description "dev" age 24
@@ -278,8 +278,8 @@ OK
**对象数据存储场景**
-- 举例 :用户信息、商品信息、文章信息、购物车信息。
-- 相关命令 :`HSET` (设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
+- 举例:用户信息、商品信息、文章信息、购物车信息。
+- 相关命令:`HSET` (设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
## Set(集合)
@@ -310,7 +310,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=set 。
-**基本操作** :
+**基本操作**:
```bash
> SADD mySet value1 value2
@@ -329,9 +329,9 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
```
- `mySet` : `value1`、`value2` 。
-- `mySet2` :`value2`、`value3` 。
+- `mySet2`:`value2`、`value3` 。
-**求交集** :
+**求交集**:
```bash
> SINTERSTORE mySet3 mySet mySet2
@@ -340,7 +340,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
1) "value2"
```
-**求并集** :
+**求并集**:
```bash
> SUNION mySet mySet2
@@ -349,7 +349,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
3) "value1"
```
-**求差集** :
+**求差集**:
```bash
> SDIFF mySet mySet2 # 差集是由所有属于 mySet 但不属于 A 的元素组成的集合
@@ -367,14 +367,14 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
**需要获取多个数据源交集、并集和差集的场景**
-- 举例 :共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
+- 举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
- 相关命令:`SINTER`(交集)、`SINTERSTORE` (交集)、`SUNION` (并集)、`SUNIONSTORE`(并集)、`SDIFF`(差集)、`SDIFFSTORE` (差集)。
**需要随机获取数据源中的元素的场景**
-- 举例 :抽奖系统、随机点名等场景。
+- 举例:抽奖系统、随机点名等场景。
- 相关命令:`SPOP`(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、`SRANDMEMBER`(随机获取集合中的元素,适合允许重复中奖的场景)。
## Sorted Set(有序集合)
@@ -401,7 +401,7 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=sorted-set 。
-**基本操作** :
+**基本操作**:
```bash
> ZADD myZset 2.0 value1 1.0 value2
@@ -422,9 +422,9 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
```
- `myZset` : `value1`(2.0)、`value2`(1.0) 。
-- `myZset2` :`value2` (4.0)、`value3`(3.0) 。
+- `myZset2`:`value2` (4.0)、`value3`(3.0) 。
-**获取指定元素的排名** :
+**获取指定元素的排名**:
```bash
> ZREVRANK myZset value1
@@ -433,7 +433,7 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
1
```
-**求交集** :
+**求交集**:
```bash
> ZINTERSTORE myZset3 2 myZset myZset2
@@ -443,7 +443,7 @@ value2
5
```
-**求并集** :
+**求并集**:
```bash
> ZUNIONSTORE myZset4 2 myZset myZset2
@@ -457,7 +457,7 @@ value2
5
```
-**求差集** :
+**求差集**:
```bash
> ZDIFF 2 myZset myZset2 WITHSCORES
@@ -469,8 +469,8 @@ value1
**需要随机获取数据源中的元素根据某个权重进行排序的场景**
-- 举例 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
-- 相关命令 :`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+- 举例:各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
+- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。

@@ -480,12 +480,12 @@ value1
**需要存储的数据有优先级或者重要程度的场景** 比如优先级任务队列。
-- 举例 :优先级任务队列。
-- 相关命令 :`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+- 举例:优先级任务队列。
+- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
## 参考
-- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
-- Redis Commands :https://redis.io/commands/ 。
+- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
+- Redis Commands:https://redis.io/commands/ 。
- Redis Data types tutorial:https://redis.io/docs/manual/data-types/data-types-tutorial/ 。
- Redis 存储对象信息是用 Hash 还是 String : https://segmentfault.com/a/1190000040032006
diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 8332c304689..4a1c5ad1396 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -12,7 +12,7 @@ head:
content: Redis特殊数据结构总结:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
---
-除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构 :Bitmap、HyperLogLog、GEO。
+除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构:Bitmap、HyperLogLog、GEO。
## Bitmap
@@ -33,7 +33,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
-**Bitmap 基本操作演示** :
+**Bitmap 基本操作演示**:
```bash
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
@@ -56,8 +56,8 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
**需要保存状态信息(0/1 即可表示)的场景**
-- 举例 :用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
-- 相关命令 :`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
+- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
+- 相关命令:`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
## HyperLogLog
@@ -67,8 +67,8 @@ HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
-- **稀疏矩阵** :计数较少的时候,占用空间很小。
-- **稠密矩阵** :计数达到某个阈值的时候,占用 12k 的空间。
+- **稀疏矩阵**:计数较少的时候,占用空间很小。
+- **稠密矩阵**:计数达到某个阈值的时候,占用 12k 的空间。
Redis 官方文档中有对应的详细说明:
@@ -92,7 +92,7 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
-**HyperLogLog 基本操作演示** :
+**HyperLogLog 基本操作演示**:
```bash
> PFADD hll foo bar zap
@@ -117,8 +117,8 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
**数量量巨大(百万、千万级别以上)的计数场景**
-- 举例 :热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
-- 相关命令 :`PFADD`、`PFCOUNT` 。
+- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
+- 相关命令:`PFADD`、`PFCOUNT` 。
## Geospatial index
@@ -140,7 +140,7 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
-**基本操作** :
+**基本操作**:
```bash
> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
@@ -158,7 +158,7 @@ GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换
-**获取指定位置范围内的其他元素** :
+**获取指定位置范围内的其他元素**:
```bash
> GEORADIUS personLocation 116.33 39.87 3 km
@@ -180,7 +180,7 @@ user2
`GEORADIUS` 命令的底层原理解析可以看看阿里的这篇文章:[Redis 到底是怎么实现“附近的人”这个功能的呢?](https://juejin.cn/post/6844903966061363207) 。
-**移除元素** :
+**移除元素**:
GEO 底层是 Sorted Set ,你可以对 GEO 使用 Sorted Set 相关的命令。
@@ -203,6 +203,6 @@ user2
## 参考
-- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
+- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
- 布隆过滤器,位图,HyperLogLog:https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html
diff --git a/docs/database/redis/redis-persistence.md b/docs/database/redis/redis-persistence.md
index 75bb6db46b5..4e90e4b3979 100644
--- a/docs/database/redis/redis-persistence.md
+++ b/docs/database/redis/redis-persistence.md
@@ -69,18 +69,18 @@ AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 `dir` 参
AOF 持久化功能的实现可以简单分为 5 步:
-1. **命令追加(append)** :所有的写命令会追加到 AOF 缓冲区中。
-2. **文件写入(write)** :将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
-3. **文件同步(fsync)** :AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
-4. **文件重写(rewrite)** :随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
-5. **重启加载(load)** :当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
+1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
+2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
+3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
+5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
> Linux 系统直接提供了一些函数用于对文件和设备进行访问和控制,这些函数被称为 **系统调用(syscall)**。
这里对上面提到的一些 Linux 系统调用再做一遍解释:
-- `write` :写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
-- `fsync` :`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
+- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
+- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
AOF 工作流程图如下:
@@ -91,8 +91,8 @@ AOF 工作流程图如下:
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
-2. `appendfsync everysec` :主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
-3. `appendfsync no` :主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
@@ -106,7 +106,7 @@ AOF 工作流程图如下:
Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
-**相关 issue** :[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
+**相关 issue**:[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
### AOF 为什么是在执行完命令之后记录日志?
@@ -138,7 +138,7 @@ AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该
开启 AOF 重写功能,可以调用 `BGREWRITEAOF` 命令手动执行,也可以设置下面两个配置项,让程序自动决定触发时机:
-- `auto-aof-rewrite-min-size` :如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
+- `auto-aof-rewrite-min-size`:如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
- `auto-aof-rewrite-percentage`:执行 AOF 重写时,当前 AOF 大小(aof_current_size)和上一次重写时 AOF 大小(aof_base_size)的比值。如果当前 AOF 文件大小增加了这个百分比值,将触发 AOF 重写。将此值设置为 0 将禁用自动 AOF 重写。默认值为 100。
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
@@ -149,7 +149,7 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
>
> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
-**相关 issue** :[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
+**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
## Redis 4.0 对于持久化机制做了什么优化?
@@ -165,18 +165,18 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
-**RDB 比 AOF 优秀的地方** :
+**RDB 比 AOF 优秀的地方**:
- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会必 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
-**AOF 比 RDB 优秀的地方** :
+**AOF 比 RDB 优秀的地方**:
- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
-**综上** :
+**综上**:
- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
diff --git a/docs/database/redis/redis-questions-01.md b/docs/database/redis/redis-questions-01.md
index 268ff6f7438..2bfe0e776d4 100644
--- a/docs/database/redis/redis-questions-01.md
+++ b/docs/database/redis/redis-questions-01.md
@@ -58,13 +58,13 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
-**共同点** :
+**共同点**:
1. 都是基于内存的数据库,一般都用来当做缓存使用。
2. 都有过期策略。
3. 两者的性能都非常高。
-**区别** :
+**区别**:
1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。**
@@ -103,10 +103,10 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
### Redis 除了做缓存,还能做什么?
-- **分布式锁** :通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
-- **限流** :一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
-- **消息队列** :Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
-- **复杂业务场景** :通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
+- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
+- **消息队列**:Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
- ......
### 如何基于 Redis 实现分布式锁?
@@ -121,7 +121,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
-通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列 :
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列:
```bash
# 生产者生产消息
@@ -183,8 +183,8 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
### Redis 常用的数据结构有哪些?
-- **5 种基础数据结构** :String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
-- **3 种特殊数据结构** :HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
+- **5 种基础数据结构**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+- **3 种特殊数据结构**:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
### String 的应用场景有哪些?
@@ -259,17 +259,17 @@ struct __attribute__ ((__packed__)) sdshdr64 {
对于后四种实现都包含了下面这 4 个属性:
-- `len` :字符串的长度也就是已经使用的字节数
+- `len`:字符串的长度也就是已经使用的字节数
- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小
-- `buf[]` :实际存储字符串的数组
-- `flags` :低三位保存类型标志
+- `buf[]`:实际存储字符串的数组
+- `flags`:低三位保存类型标志
SDS 相比于 C 语言中的字符串有如下提升:
-1. **可以避免缓冲区溢出** :C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
-2. **获取字符串长度的复杂度较低** :C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
-3. **减少内存分配次数** :为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
-4. **二进制安全** :C 语言中的字符串以空字符 `\0` 作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
+1. **可以避免缓冲区溢出**:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
+2. **获取字符串长度的复杂度较低**:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
+3. **减少内存分配次数**:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
+4. **二进制安全**:C 语言中的字符串以空字符 `\0` 作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
🤐 多提一嘴,很多文章里 SDS 的定义是下面这样的:
@@ -329,7 +329,7 @@ Set 的常见应用场景如下:
如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
-- `SPOP key count` :随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
+- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
- `SRANDMEMBER key count` : 随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
### 使用 Bitmap 统计活跃用户怎么做?
@@ -454,7 +454,7 @@ Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
-Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 `redis.conf` :
+Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 `redis.conf`:
```bash
io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
@@ -562,8 +562,8 @@ typedef struct redisDb {
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
-1. **惰性删除** :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
-2. **定期删除** :每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
diff --git a/docs/database/redis/redis-questions-02.md b/docs/database/redis/redis-questions-02.md
index 286a530ea95..f548e7f1b1c 100644
--- a/docs/database/redis/redis-questions-02.md
+++ b/docs/database/redis/redis-questions-02.md
@@ -16,7 +16,7 @@ head:
### 什么是 Redis 事务?
-你可以将 Redis 中的事务理解为 :**Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
+你可以将 Redis 中的事务理解为:**Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
Redis 事务实际开发中使用的非常少,功能比较鸡肋,不要将其和我们平时理解的关系型数据库的事务混淆了。
@@ -86,7 +86,7 @@ QUEUED
"GoGuide"
```
-不过,如果 **WATCH** 与 **事务** 在同一个 Session 里,并且被 **WATCH** 监视的 Key 被修改的操作发生在事务内部,这个事务是可以被执行成功的(相关 issue :[WATCH 命令碰到 MULTI 命令时的不同效果](https://github.com/Snailclimb/JavaGuide/issues/1714))。
+不过,如果 **WATCH** 与 **事务** 在同一个 Session 里,并且被 **WATCH** 监视的 Key 被修改的操作发生在事务内部,这个事务是可以被执行成功的(相关 issue:[WATCH 命令碰到 MULTI 命令时的不同效果](https://github.com/Snailclimb/JavaGuide/issues/1714))。
事务内部修改 WATCH 监视的 Key:
@@ -319,17 +319,17 @@ Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28
网上有现成的代码/工具可以直接拿来使用:
-- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools) :Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
+- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools):Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys) : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
### Redis 内存碎片
-**相关问题** :
+**相关问题**:
1. 什么是内存碎片?为什么会有 Redis 内存碎片?
2. 如何清理 Redis 内存碎片?
-**参考答案** :[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
+**参考答案**:[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
## Redis 生产问题(重要)
@@ -412,7 +412,7 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
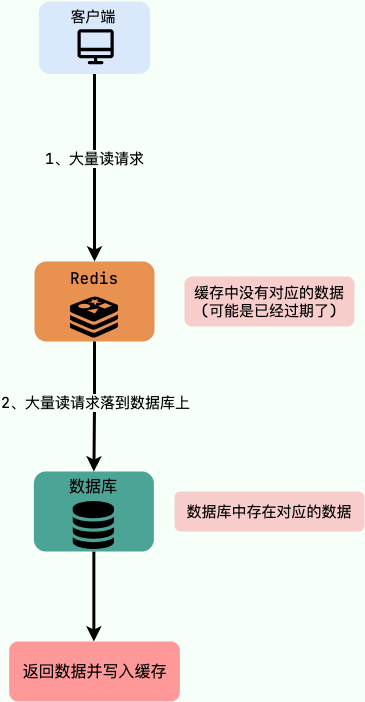
-举个例子 :秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
+举个例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
#### 有哪些解决办法?
@@ -438,7 +438,7 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
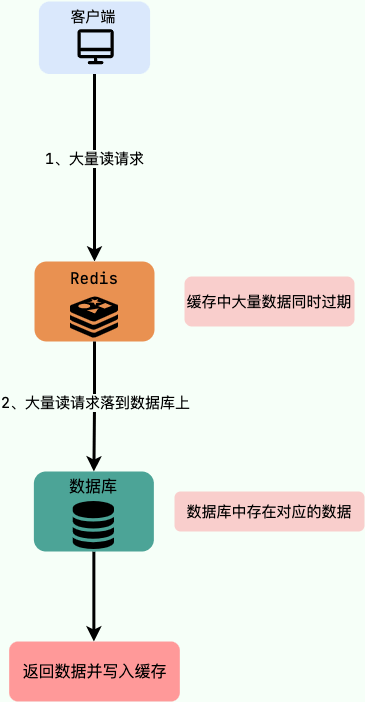
-举个例子 :数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
+举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
#### 有哪些解决办法?
@@ -467,7 +467,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
-1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
+1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
2. **增加 cache 更新重试机制(常用)**:如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
@@ -478,7 +478,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
## Redis 集群
-**Redis Sentinel** :
+**Redis Sentinel**:
1. 什么是 Sentinel? 有什么用?
2. Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
@@ -488,7 +488,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
6. 如何从 Sentinel 集群中选择出 Leader ?
7. Sentinel 可以防止脑裂吗?
-**Redis Cluster** :
+**Redis Cluster**:
1. 为什么需要 Redis Cluster?解决了什么问题?有什么优势?
2. Redis Cluster 是如何分片的?
@@ -498,21 +498,21 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
6. Redis Cluster 扩容缩容期间可以提供服务吗?
7. Redis Cluster 中的节点是怎么进行通信的?
-**参考答案** :[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
+**参考答案**:[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
## Redis 使用规范
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
1. 使用连接池:避免频繁创建关闭客户端连接。
-2. 尽量不使用 O(n)指令,使用 O(N)命令时要关注 N 的数量 :例如 `hgetall`、`lrange`、`smembers`、`zrange`、`sinter`、`sunion` 命令并非不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
-3. 使用批量操作减少网络传输 :原生批量操作命令(比如 `mget`、`mset`等等)、pipeline、Lua 脚本。
+2. 尽量不使用 O(n)指令,使用 O(N)命令时要关注 N 的数量:例如 `hgetall`、`lrange`、`smembers`、`zrange`、`sinter`、`sunion` 命令并非不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
+3. 使用批量操作减少网络传输:原生批量操作命令(比如 `mget`、`mset`等等)、pipeline、Lua 脚本。
4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
5. 禁止长时间开启 monitor:对性能影响比较大。
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
7. ......
-相关文章推荐 :[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
+相关文章推荐:[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
## 参考
diff --git a/docs/database/sql/sql-questions-01.md b/docs/database/sql/sql-questions-01.md
index e35b47f9663..c62ffa7ef1f 100644
--- a/docs/database/sql/sql-questions-01.md
+++ b/docs/database/sql/sql-questions-01.md
@@ -203,7 +203,7 @@ ORDER BY vend_name DESC
### 返回固定价格的产品
-有表 `Products` :
+有表 `Products`:
| prod_id | prod_name | prod_price |
| ------- | -------------- | ---------- |
@@ -223,7 +223,7 @@ WHERE prod_price = 9.49
### 返回更高价格的产品
-有表 `Products` :
+有表 `Products`:
| prod_id | prod_name | prod_price |
| ------- | -------------- | ---------- |
@@ -243,7 +243,7 @@ WHERE prod_price >= 9
### 返回产品并且按照价格排序
-有表 `Products` :
+有表 `Products`:
| prod_id | prod_name | prod_price |
| ------- | --------- | ---------- |
@@ -565,7 +565,7 @@ FROM Customers
知识点:
- 截取函数`SUBSTRING()`:截取字符串,`substring(str ,n ,m)`:返回字符串 str 从第 n 个字符截取到第 m 个字符(左闭右闭);
-- 拼接函数`CONCAT()`:将两个或多个字符串连接成一个字符串,select concat(A,B) :连接字符串 A 和 B。
+- 拼接函数`CONCAT()`:将两个或多个字符串连接成一个字符串,select concat(A,B):连接字符串 A 和 B。
- 大写函数 `UPPER()`:将指定字符串转换为大写。
diff --git a/docs/database/sql/sql-syntax-summary.md b/docs/database/sql/sql-syntax-summary.md
index 52777c678c5..cb1752efd82 100644
--- a/docs/database/sql/sql-syntax-summary.md
+++ b/docs/database/sql/sql-syntax-summary.md
@@ -171,8 +171,8 @@ TRUNCATE TABLE user;
`LIMIT` 限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
-- `ASC` :升序(默认)
-- `DESC` :降序
+- `ASC`:升序(默认)
+- `DESC`:降序
**查询单列**
@@ -225,7 +225,7 @@ ORDER BY prod_price DESC, prod_name ASC;
## 分组
-**`group by`** :
+**`group by`**:
- `group by` 子句将记录分组到汇总行中。
- `group by` 为每个组返回一个记录。
@@ -264,7 +264,7 @@ GROUP BY cust_name
HAVING COUNT(*) >= 1;
```
-**`having` vs `where`** :
+**`having` vs `where`**:
- `where`:过滤过滤指定的行,后面不能加聚合函数(分组函数)。`where` 在`group by` 前。
- `having`:过滤分组,一般都是和 `group by` 连用,不能单独使用。`having` 在 `group by` 之后。
@@ -751,12 +751,12 @@ DROP VIEW top_10_user_view;
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
-**优点** :
+**优点**:
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-**缺点** :
+**缺点**:
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
@@ -1140,7 +1140,7 @@ MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储
但是,从 MySQL 版本 5.7.2+开始,可以为同一触发事件和操作时间定义多个触发器。
-**`NEW` 和 `OLD`** :
+**`NEW` 和 `OLD`**:
- MySQL 中定义了 `NEW` 和 `OLD` 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。
- 在 `INSERT` 型触发器中,`NEW` 用来表示将要(`BEFORE`)或已经(`AFTER`)插入的新数据;
@@ -1169,7 +1169,7 @@ END;
说明:
-- `trigger_name` :触发器名
+- `trigger_name`:触发器名
- `trigger_time` : 触发器的触发时机。取值为 `BEFORE` 或 `AFTER`。
- `trigger_event` : 触发器的监听事件。取值为 `INSERT`、`UPDATE` 或 `DELETE`。
- `table_name` : 触发器的监听目标。指定在哪张表上建立触发器。
diff --git a/docs/distributed-system/api-gateway.md b/docs/distributed-system/api-gateway.md
index 87d609be3ac..8ced73cafe3 100644
--- a/docs/distributed-system/api-gateway.md
+++ b/docs/distributed-system/api-gateway.md
@@ -23,20 +23,20 @@ category: 分布式
绝大部分网关可以提供下面这些功能:
-- **请求转发** :将请求转发到目标微服务。
-- **负载均衡** :根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
-- **安全认证** :对用户请求进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBAC 等方式来授权。
-- **参数校验** :支持参数映射与校验逻辑。
-- **日志记录** :记录所有请求的行为日志供后续使用。
-- **监控告警** :从业务指标、机器指标、JVM 指标等方面进行监控并提供配套的告警机制。
-- **流量控制** :对请求的流量进行控制,也就是限制某一时刻内的请求数。
+- **请求转发**:将请求转发到目标微服务。
+- **负载均衡**:根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
+- **安全认证**:对用户请求进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBAC 等方式来授权。
+- **参数校验**:支持参数映射与校验逻辑。
+- **日志记录**:记录所有请求的行为日志供后续使用。
+- **监控告警**:从业务指标、机器指标、JVM 指标等方面进行监控并提供配套的告警机制。
+- **流量控制**:对请求的流量进行控制,也就是限制某一时刻内的请求数。
- **熔断降级**:实时监控请求的统计信息,达到配置的失败阈值后,自动熔断,返回默认值。
- **响应缓存**:当用户请求获取的是一些静态的或更新不频繁的数据时,一段时间内多次请求获取到的数据很可能是一样的。对于这种情况可以将响应缓存起来。这样用户请求可以直接在网关层得到响应数据,无需再去访问业务服务,减轻业务服务的负担。
- **响应聚合**:某些情况下用户请求要获取的响应内容可能会来自于多个业务服务。网关作为业务服务的调用方,可以把多个服务的响应整合起来,再一并返回给用户。
-- **灰度发布** :将请求动态分流到不同的服务版本(最基本的一种灰度发布)。
+- **灰度发布**:将请求动态分流到不同的服务版本(最基本的一种灰度发布)。
- **异常处理**:对于业务服务返回的异常响应,可以在网关层在返回给用户之前做转换处理。这样可以把一些业务侧返回的异常细节隐藏,转换成用户友好的错误提示返回。
- **API 文档:** 如果计划将 API 暴露给组织以外的开发人员,那么必须考虑使用 API 文档,例如 Swagger 或 OpenAPI。
-- **协议转换** :通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
+- **协议转换**:通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
@@ -75,7 +75,7 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网
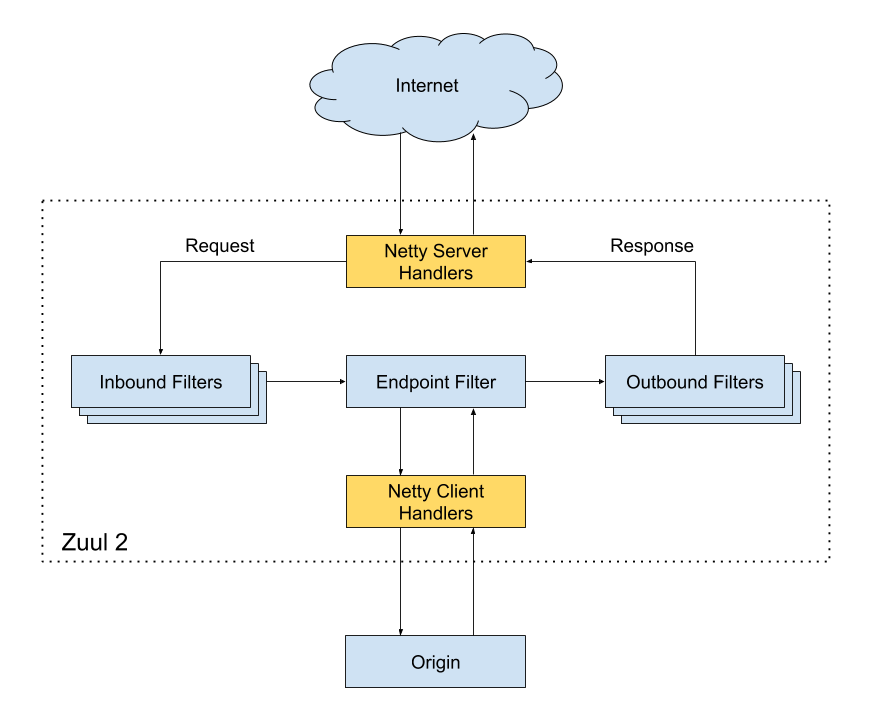
- GitHub 地址:
-- 官方 Wiki :
+- 官方 Wiki:
### Spring Cloud Gateway
@@ -89,15 +89,15 @@ Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链
Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
-- Github 地址 :
-- 官网 :
+- Github 地址:
+- 官网:
### Kong
Kong 是一款基于 [OpenResty](https://github.com/openresty/) (Nginx + Lua)的高性能、云原生、可扩展的网关系统,主要由 3 个组件组成:
-- Kong Server :基于 Nginx 的服务器,用来接收 API 请求。
-- Apache Cassandra/PostgreSQL :用来存储操作数据。
+- Kong Server:基于 Nginx 的服务器,用来接收 API 请求。
+- Apache Cassandra/PostgreSQL:用来存储操作数据。
- Kong Dashboard:官方推荐 UI 管理工具,当然,也可以使用 RESTful 方式 管理 Admin api。
> OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
@@ -118,7 +118,7 @@ $ curl -X POST http://kong:8001/services/{service}/plugins \
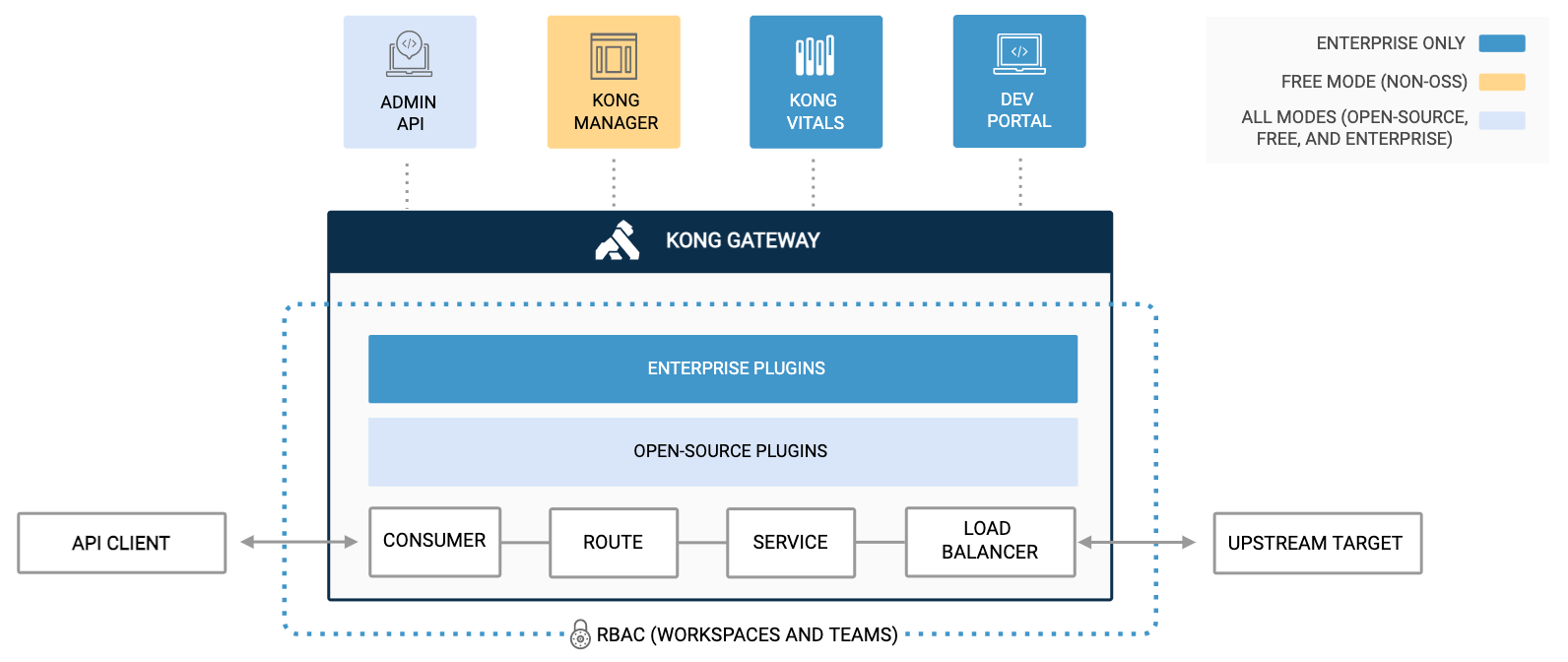
- Github 地址:
-- 官网地址 :
+- 官网地址:
### APISIX
@@ -143,7 +143,7 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua

-- Github 地址 :
+- Github 地址:
- 官网地址:
相关阅读:
@@ -162,7 +162,7 @@ Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apac
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发、重写、重定向、和路由监控等插件。
- Github 地址:
-- 官网地址 :
+- 官网地址:
## 参考
diff --git a/docs/distributed-system/distributed-id.md b/docs/distributed-system/distributed-id.md
index a71f96a461f..c0a3de56c59 100644
--- a/docs/distributed-system/distributed-id.md
+++ b/docs/distributed-system/distributed-id.md
@@ -35,17 +35,17 @@ category: 分布式
一个最基本的分布式 ID 需要满足下面这些要求:
-- **全局唯一** :ID 的全局唯一性肯定是首先要满足的!
-- **高性能** :分布式 ID 的生成速度要快,对本地资源消耗要小。
-- **高可用** :生成分布式 ID 的服务要保证可用性无限接近于 100%。
-- **方便易用** :拿来即用,使用方便,快速接入!
+- **全局唯一**:ID 的全局唯一性肯定是首先要满足的!
+- **高性能**:分布式 ID 的生成速度要快,对本地资源消耗要小。
+- **高可用**:生成分布式 ID 的服务要保证可用性无限接近于 100%。
+- **方便易用**:拿来即用,使用方便,快速接入!
除了这些之外,一个比较好的分布式 ID 还应保证:
-- **安全** :ID 中不包含敏感信息。
-- **有序递增** :如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
-- **有具体的业务含义** :生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
-- **独立部署** :也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
+- **安全**:ID 中不包含敏感信息。
+- **有序递增**:如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
+- **有具体的业务含义**:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
+- **独立部署**:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
## 分布式 ID 常见解决方案
@@ -89,8 +89,8 @@ COMMIT;
这种方式的优缺点也比较明显:
-- **优点** :实现起来比较简单、ID 有序递增、存储消耗空间小
-- **缺点** :支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
+- **优点**:实现起来比较简单、ID 有序递增、存储消耗空间小
+- **缺点**:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
#### 数据库号段模式
@@ -162,8 +162,8 @@ id current_max_id step version biz_type
**数据库号段模式的优缺点:**
-- **优点** :ID 有序递增、存储消耗空间小
-- **缺点** :存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
+- **优点**:ID 有序递增、存储消耗空间小
+- **缺点**:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
#### NoSQL
@@ -190,8 +190,8 @@ OK
**Redis 方案的优缺点:**
-- **优点** :性能不错并且生成的 ID 是有序递增的
-- **缺点** :和数据库主键自增方案的缺点类似
+- **优点**:性能不错并且生成的 ID 是有序递增的
+- **缺点**:和数据库主键自增方案的缺点类似
除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。
@@ -202,12 +202,12 @@ MongoDB ObjectId 一共需要 12 个字节存储:
- 0~3:时间戳
- 3~6:代表机器 ID
- 7~8:机器进程 ID
-- 9~11 :自增值
+- 9~11:自增值
**MongoDB 方案的优缺点:**
-- **优点** :性能不错并且生成的 ID 是有序递增的
-- **缺点** :需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)
+- **优点**:性能不错并且生成的 ID 是有序递增的
+- **缺点**:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)
### 算法
@@ -261,17 +261,17 @@ int version = uuid.version();// 4
最后,我们再简单分析一下 **UUID 的优缺点** (面试的时候可能会被问到的哦!) :
-- **优点** :生成速度比较快、简单易用
-- **缺点** :存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
+- **优点**:生成速度比较快、简单易用
+- **缺点**:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
#### Snowflake(雪花算法)
Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
- **第 0 位**:符号位(标识正负),始终为 0,没有用,不用管。
-- **第 1~41 位** :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
-- **第 42~52 位** :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
-- **第 53~64 位** :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+- **第 1~41 位**:一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
+- **第 42~52 位**:一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
+- **第 53~64 位**:一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。

@@ -279,10 +279,10 @@ Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit
另外,在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
-我们再来看看 Snowflake 算法的优缺点 :
+我们再来看看 Snowflake 算法的优缺点:
-- **优点** :生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
-- **缺点** :需要解决重复 ID 问题(依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID)。
+- **优点**:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
+- **缺点**:需要解决重复 ID 问题(依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID)。
### 开源框架
@@ -341,9 +341,9 @@ Tinyid 的原理比较简单,其架构如下图所示:
相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
-- **双号段缓存** :为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
-- **增加多 db 支持** :支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
-- **增加 tinyid-client** :纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
+- **双号段缓存**:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
+- **增加多 db 支持**:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
+- **增加 tinyid-client**:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺点和 Tinyid 的原理就能知道。
diff --git a/docs/distributed-system/distributed-lock.md b/docs/distributed-system/distributed-lock.md
index 696b8503cc4..c70b4264bb3 100644
--- a/docs/distributed-system/distributed-lock.md
+++ b/docs/distributed-system/distributed-lock.md
@@ -27,8 +27,8 @@ category: 分布式
一个最基本的分布式锁需要满足:
-- **互斥** :任意一个时刻,锁只能被一个线程持有;
-- **高可用** :锁服务是高可用的。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。
+- **互斥**:任意一个时刻,锁只能被一个线程持有;
+- **高可用**:锁服务是高可用的。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。
- **可重入**:一个节点获取了锁之后,还可以再次获取锁。
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点,我这里也以 Redis 为例介绍分布式锁的实现。
@@ -81,10 +81,10 @@ end
OK
```
-- **lockKey** :加锁的锁名;
-- **uniqueValue** :能够唯一标示锁的随机字符串;
-- **NX** :只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
-- **EX** :过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
+- **lockKey**:加锁的锁名;
+- **uniqueValue**:能够唯一标示锁的随机字符串;
+- **NX**:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
+- **EX**:过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
**一定要保证设置指定 key 的值和过期时间是一个原子操作!!!** 不然的话,依然可能会出现锁无法被释放的问题。
@@ -298,10 +298,10 @@ client.close();
我们通常是将 znode 分为 4 大类:
-- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
-- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
-- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
-- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
+- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
+- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
+- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
可以看出,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md
index 55fc1b10b56..04e49a7d218 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.md
@@ -206,9 +206,9 @@ zkClient.start();
对于一些基本参数的说明:
- `baseSleepTimeMs`:重试之间等待的初始时间
-- `maxRetries` :最大重试次数
-- `connectString` :要连接的服务器列表
-- `retryPolicy` :重试策略
+- `maxRetries`:最大重试次数
+- `connectString`:要连接的服务器列表
+- `retryPolicy`:重试策略
### 数据节点的增删改查
@@ -216,10 +216,10 @@ zkClient.start();
我们在 [ZooKeeper 常见概念解读](./zookeeper-intro.md) 中介绍到,我们通常是将 znode 分为 4 大类:
-- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
-- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,临时节点 **只能做叶子节点** ,不能创建子节点。
-- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
-- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
+- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,临时节点 **只能做叶子节点** ,不能创建子节点。
+- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
+- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
你在使用的 ZooKeeper 的时候,会发现 `CreateMode` 类中实际有 7 种 znode 类型 ,但是用的最多的还是上面介绍的 4 种。
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md
index 6f0da6eb2e7..f4102f61e6d 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.md
@@ -55,7 +55,7 @@ ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于
- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
-- **单一系统映像 :** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
+- **单一系统映像:** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
### ZooKeeper 应用场景
@@ -64,9 +64,9 @@ ZooKeeper 概览中,我们介绍到使用其通常被用于实现诸如数据
下面选 3 个典型的应用场景来专门说说:
-1. **命名服务** :可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
-2. **数据发布/订阅** :通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
-3. **分布式锁** :通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 **Watcher 机制** ,我在 [分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 这篇文章中有详细介绍到如何基于 ZooKeeper 实现分布式锁。
+1. **命名服务**:可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
+2. **数据发布/订阅**:通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
+3. **分布式锁**:通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 **Watcher 机制** ,我在 [分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 这篇文章中有详细介绍到如何基于 ZooKeeper 实现分布式锁。
实际上,这些功能的实现基本都得益于 ZooKeeper 可以保存数据的功能,但是 ZooKeeper 不适合保存大量数据,这一点需要注意。
@@ -90,15 +90,15 @@ ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都
我们通常是将 znode 分为 4 大类:
-- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
-- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
-- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
-- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
+- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
+- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
+- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
每个 znode 由 2 部分组成:
-- **stat** :状态信息
-- **data** :节点存放的数据的具体内容
+- **stat**:状态信息
+- **data**:节点存放的数据的具体内容
如下所示,我通过 get 命令来获取 根目录下的 dubbo 节点的内容。(get 命令在下面会介绍到)。
@@ -122,7 +122,7 @@ numChildren = 1
Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务 ID(cZxid)、节点创建时间(ctime) 和子节点个数(numChildren) 等等。
-下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ) :
+下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ):
| znode 状态信息 | 解释 |
| -------------- | --------------------------------------------------------------------------------------------------- |
@@ -142,9 +142,9 @@ Stat 类中包含了一个数据节点的所有状态信息的字段,包括事
在前面我们已经提到,对应于每个 znode,ZooKeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat 中记录了这个 znode 的三个相关的版本:
-- **dataVersion** :当前 znode 节点的版本号
-- **cversion** :当前 znode 子节点的版本
-- **aclVersion** :当前 znode 的 ACL 的版本。
+- **dataVersion**:当前 znode 节点的版本号
+- **cversion**:当前 znode 子节点的版本
+- **aclVersion**:当前 znode 的 ACL 的版本。
### ACL(权限控制)
@@ -153,7 +153,7 @@ ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似
对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
- **CREATE** : 能创建子节点
-- **READ** :能获取节点数据和列出其子节点
+- **READ**:能获取节点数据和列出其子节点
- **WRITE** : 能设置/更新节点数据
- **DELETE** : 能删除子节点
- **ADMIN** : 能设置节点 ACL 的权限
@@ -162,7 +162,7 @@ ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似
对于身份认证,提供了以下几种方式:
-- **world** :默认方式,所有用户都可无条件访问。
+- **world**:默认方式,所有用户都可无条件访问。
- **auth** :不使用任何 id,代表任何已认证的用户。
- **digest** :用户名:密码认证方式:_username:password_ 。
- **ip** : 对指定 ip 进行限制。
@@ -214,16 +214,16 @@ ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定
这个过程大致是这样的:
1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
-2. **Discovery(发现阶段)** :在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
+2. **Discovery(发现阶段)**:在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
4. **Broadcast(广播阶段)** :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZooKeeper 集群中的服务器状态有下面几种:
-- **LOOKING** :寻找 Leader。
-- **LEADING** :Leader 状态,对应的节点为 Leader。
-- **FOLLOWING** :Follower 状态,对应的节点为 Follower。
-- **OBSERVING** :Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
+- **LOOKING**:寻找 Leader。
+- **LEADING**:Leader 状态,对应的节点为 Leader。
+- **FOLLOWING**:Follower 状态,对应的节点为 Follower。
+- **OBSERVING**:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
### ZooKeeper 集群为啥最好奇数台?
@@ -258,8 +258,8 @@ ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服
ZAB 协议包括两种基本的模式,分别是
-- **崩溃恢复** :当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
-- **消息广播** :**当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。** 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
+- **崩溃恢复**:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
+- **消息广播**:**当集群中已经有过半的 Follower 服务器完成了和 Leader 服务器的状态同步,那么整个服务框架就可以进入消息广播模式了。** 当一台同样遵守 ZAB 协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个 Leader 服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到 Leader 所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
关于 **ZAB 协议&Paxos 算法** 需要讲和理解的东西太多了,具体可以看下面这几篇文章:
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
index 20fabd2bd0d..f046e189788 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
@@ -156,9 +156,9 @@ tag:
和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
-- `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
+- `Leader`:集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
- `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
-- `Observer` :就是没有选举权和被选举权的 `Follower` 。
+- `Observer`:就是没有选举权和被选举权的 `Follower` 。
在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
@@ -271,7 +271,7 @@ tag:
`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
-- `CREATE` :创建子节点的权限。
+- `CREATE`:创建子节点的权限。
- `READ`:获取节点数据和子节点列表的权限。
- `WRITE`:更新节点数据的权限。
- `DELETE`:删除子节点的权限。
diff --git a/docs/distributed-system/protocol/cap-and-base-theorem.md b/docs/distributed-system/protocol/cap-and-base-theorem.md
index 53871589274..3fca93f54e9 100644
--- a/docs/distributed-system/protocol/cap-and-base-theorem.md
+++ b/docs/distributed-system/protocol/cap-and-base-theorem.md
@@ -134,11 +134,11 @@ CAP 理论这节我们也说过了:
> 分布式一致性的 3 种级别:
>
-> 1. **强一致性** :系统写入了什么,读出来的就是什么。
+> 1. **强一致性**:系统写入了什么,读出来的就是什么。
>
-> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
+> 2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
>
-> 3. **最终一致性** :弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
+> 3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
>
> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
diff --git a/docs/distributed-system/protocol/gossip-protocl.md b/docs/distributed-system/protocol/gossip-protocl.md
index 08365419863..69b588cc75c 100644
--- a/docs/distributed-system/protocol/gossip-protocl.md
+++ b/docs/distributed-system/protocol/gossip-protocl.md
@@ -44,9 +44,9 @@ Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节
Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
-- **MEET** :在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
-- **PING/PONG** :Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
-- **FAIL** :Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
+- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
+- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
+- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
- ......
下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。
diff --git a/docs/distributed-system/protocol/paxos-algorithm.md b/docs/distributed-system/protocol/paxos-algorithm.md
index fd7d1fdc64e..fb62f923212 100644
--- a/docs/distributed-system/protocol/paxos-algorithm.md
+++ b/docs/distributed-system/protocol/paxos-algorithm.md
@@ -36,8 +36,8 @@ Paxos 算法是第一个被证明完备的分布式系统共识算法。共识
兰伯特当时提出的 Paxos 算法主要包含 2 个部分:
-- **Basic Paxos 算法** :描述的是多节点之间如何就某个值(提案 Value)达成共识。
-- **Multi-Paxos 思想** :描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
+- **Basic Paxos 算法**:描述的是多节点之间如何就某个值(提案 Value)达成共识。
+- **Multi-Paxos 思想**:描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
由于 Paxos 算法在国际上被公认的非常难以理解和实现,因此不断有人尝试简化这一算法。到了 2013 年才诞生了一个比 Paxos 算法更易理解和实现的共识算法—[Raft 算法](https://javaguide.cn/distributed-system/theorem&algorithm&protocol/raft-algorithm.html) 。更具体点来说,Raft 是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现。
@@ -69,7 +69,7 @@ Basic Paxos 中存在 3 个重要的角色:
Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Basic Paxos 思想。
-⚠️**注意** :Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
+⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。
diff --git a/docs/distributed-system/rpc/dubbo.md b/docs/distributed-system/rpc/dubbo.md
index 5776fe1063c..668de6b29d2 100644
--- a/docs/distributed-system/rpc/dubbo.md
+++ b/docs/distributed-system/rpc/dubbo.md
@@ -48,9 +48,9 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
-1. **负载均衡** :同一个服务部署在不同的机器时该调用哪一台机器上的服务。
-2. **服务调用链路生成** :随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
-3. **服务访问压力以及时长统计、资源调度和治理** :基于访问压力实时管理集群容量,提高集群利用率。
+1. **负载均衡**:同一个服务部署在不同的机器时该调用哪一台机器上的服务。
+2. **服务调用链路生成**:随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
+3. **服务访问压力以及时长统计、资源调度和治理**:基于访问压力实时管理集群容量,提高集群利用率。
4. ......
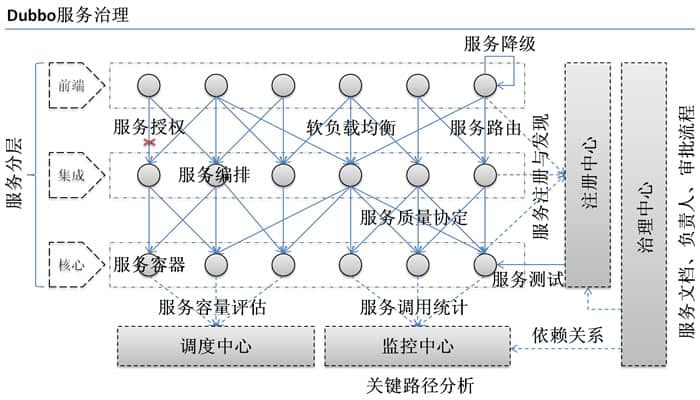
@@ -120,7 +120,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
- **protocol 远程调用层**:封装 RPC 调用,以 `Invocation`, `Result` 为中心。
- **exchange 信息交换层**:封装请求响应模式,同步转异步,以 `Request`, `Response` 为中心。
- **transport 网络传输层**:抽象 mina 和 netty 为统一接口,以 `Message` 为中心。
-- **serialize 数据序列化层** :对需要在网络传输的数据进行序列化。
+- **serialize 数据序列化层**:对需要在网络传输的数据进行序列化。
### Dubbo 的 SPI 机制了解么? 如何扩展 Dubbo 中的默认实现?
@@ -190,7 +190,7 @@ Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来
正是因为 Dubbo 基于微内核架构,才使得我们可以随心所欲替换 Dubbo 的功能点。比如你觉得 Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
-通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件 :**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
+通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件:**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
### 关于 Dubbo 架构的一些自测小问题
@@ -441,7 +441,7 @@ Dubbo 默认使用的序列化方式是 hessian2。
一般我们不会直接使用 JDK 自带的序列化方式。主要原因有两个:
1. **不支持跨语言调用** : 如果调用的是其他语言开发的服务的时候就不支持了。
-2. **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
+2. **性能差**:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
JSON 序列化由于性能问题,我们一般也不会考虑使用。
diff --git a/docs/distributed-system/rpc/rpc-intro.md b/docs/distributed-system/rpc/rpc-intro.md
index 71299fd1feb..529c5f3df89 100644
--- a/docs/distributed-system/rpc/rpc-intro.md
+++ b/docs/distributed-system/rpc/rpc-intro.md
@@ -23,11 +23,11 @@ tag:
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
-1. **客户端(服务消费端)** :调用远程方法的一端。
-1. **客户端 Stub(桩)** :这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
-1. **网络传输** :网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
-1. **服务端 Stub(桩)** :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
-1. **服务端(服务提供端)** :提供远程方法的一端。
+1. **客户端(服务消费端)**:调用远程方法的一端。
+1. **客户端 Stub(桩)**:这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
+1. **网络传输**:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
+1. **服务端 Stub(桩)**:这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
+1. **服务端(服务提供端)**:提供远程方法的一端。
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
@@ -66,7 +66,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
-- GitHub :[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
+- GitHub:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
- 官网:https://dubbo.apache.org/zh/
### Motan
@@ -130,7 +130,7 @@ Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
麻雀虽小五脏俱全,项目代码注释详细,结构清晰,并且集成了 Check Style 规范代码结构,非常适合阅读和学习。
-**内容概览** :
+**内容概览**:
diff --git a/docs/distributed-system/spring-cloud-gateway-questions.md b/docs/distributed-system/spring-cloud-gateway-questions.md
index e1cd0421870..a85c8ee189e 100644
--- a/docs/distributed-system/spring-cloud-gateway-questions.md
+++ b/docs/distributed-system/spring-cloud-gateway-questions.md
@@ -18,7 +18,7 @@ Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链
Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
- GitHub 地址:
-- 官网 :
+- 官网:
## Spring Cloud Gateway 的工作流程?
@@ -30,7 +30,7 @@ Spring Cloud Gateway 的工作流程如下图所示:
具体的流程分析:
-1. **路由判断** :客户端的请求到达网关后,先经过 Gateway Handler Mapping 处理,这里面会做断言(Predicate)判断,看下符合哪个路由规则,这个路由映射后端的某个服务。
+1. **路由判断**:客户端的请求到达网关后,先经过 Gateway Handler Mapping 处理,这里面会做断言(Predicate)判断,看下符合哪个路由规则,这个路由映射后端的某个服务。
2. **请求过滤**:然后请求到达 Gateway Web Handler,这里面有很多过滤器,组成过滤器链(Filter Chain),这些过滤器可以对请求进行拦截和修改,比如添加请求头、参数校验等等,有点像净化污水。然后将请求转发到实际的后端服务。这些过滤器逻辑上可以称作 Pre-Filters,Pre 可以理解为“在...之前”。
3. **服务处理**:后端服务会对请求进行处理。
4. **响应过滤**:后端处理完结果后,返回给 Gateway 的过滤器再次做处理,逻辑上可以称作 Post-Filters,Post 可以理解为“在...之后”。
diff --git a/docs/high-availability/limit-request.md b/docs/high-availability/limit-request.md
index 2503fb27edb..72593d3c713 100644
--- a/docs/high-availability/limit-request.md
+++ b/docs/high-availability/limit-request.md
@@ -188,15 +188,15 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
分布式限流常见的方案:
-- **借助中间件架限流** :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
-- **网关层限流** :比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
+- **借助中间件架限流**:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
+- **网关层限流**:比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。
**为什么建议 Redis+Lua 的方式?** 主要有两点原因:
-- **减少了网络开销** :我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
-- **原子性** :一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
+- **减少了网络开销**:我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
+- **原子性**:一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
我这里就不放具体的限流脚本代码了,网上也有很多现成的优秀的限流脚本供你参考,就比如 Apache 网关项目 ShenYu 的 RateLimiter 限流插件就基于 Redis + Lua 实现了令牌桶算法/并发令牌桶算法、漏桶算法、滑动窗口算法。
@@ -206,6 +206,6 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
## 相关阅读
-- 服务治理之轻量级熔断框架 Resilience4j :
+- 服务治理之轻量级熔断框架 Resilience4j:
- 超详细的 Guava RateLimiter 限流原理解析:
- 实战 Spring Cloud Gateway 之限流篇 👍:
diff --git a/docs/high-availability/performance-test.md b/docs/high-availability/performance-test.md
index 7ac4ade6bcf..c033e9aaa0c 100644
--- a/docs/high-availability/performance-test.md
+++ b/docs/high-availability/performance-test.md
@@ -125,10 +125,10 @@ category: 高可用
没记错的话,除了 LoadRunner 其他几款性能测试工具都是开源免费的。
-1. Jmeter :Apache JMeter 是 JAVA 开发的性能测试工具。
+1. Jmeter:Apache JMeter 是 JAVA 开发的性能测试工具。
2. LoadRunner:一款商业的性能测试工具。
-3. Galtling :一款基于 Scala 开发的高性能服务器性能测试工具。
-4. ab :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
+3. Galtling:一款基于 Scala 开发的高性能服务器性能测试工具。
+4. ab:全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
### 5.2 前端常用
diff --git a/docs/high-availability/redundancy.md b/docs/high-availability/redundancy.md
index 6222dedace7..71b86b46f72 100644
--- a/docs/high-availability/redundancy.md
+++ b/docs/high-availability/redundancy.md
@@ -16,9 +16,9 @@ category: 高可用
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
- **高可用集群** : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
-- **同城灾备** :一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
-- **异地灾备** :类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
-- **同城多活** :类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
+- **同城灾备**:一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
+- **异地灾备**:类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
+- **同城多活**:类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
- **异地多活** : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
diff --git a/docs/high-availability/timeout-and-retry.md b/docs/high-availability/timeout-and-retry.md
index 407ec9c0340..2dc78454ac1 100644
--- a/docs/high-availability/timeout-and-retry.md
+++ b/docs/high-availability/timeout-and-retry.md
@@ -19,8 +19,8 @@ category: 高可用
我们平时接触到的超时可以简单分为下面 2 种:
-- **连接超时(ConnectTimeout)** :客户端与服务端建立连接的最长等待时间。
-- **读取超时(ReadTimeout)** :客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
+- **连接超时(ConnectTimeout)**:客户端与服务端建立连接的最长等待时间。
+- **读取超时(ReadTimeout)**:客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
diff --git a/docs/high-performance/cdn.md b/docs/high-performance/cdn.md
index b97364d1dda..3049b979930 100644
--- a/docs/high-performance/cdn.md
+++ b/docs/high-performance/cdn.md
@@ -16,8 +16,8 @@ head:
我们可以将内容分发网络拆开来看:
-- 内容 :指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
-- 分发网络 :指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
+- 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
+- 分发网络:指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
所以,简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。**
@@ -99,7 +99,7 @@ CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
```
-- `wsSecret` :签名字符串。
+- `wsSecret`:签名字符串。
- `wsTime`: 过期时间。
diff --git a/docs/high-performance/load-balancing.md b/docs/high-performance/load-balancing.md
index 0ab0abc7967..a41af365247 100644
--- a/docs/high-performance/load-balancing.md
+++ b/docs/high-performance/load-balancing.md
@@ -161,18 +161,18 @@ Ribbon 是老牌负载均衡组件,由 Netflix 开发,功能比较全面,
Ribbon 支持的 7 种负载均衡策略:
-- `RandomRule` :随机策略。
-- `RoundRobinRule`(默认) :轮询策略
-- `WeightedResponseTimeRule` :权重(根据响应时间决定权重)策略
-- `BestAvailableRule` :最小连接数策略
+- `RandomRule`:随机策略。
+- `RoundRobinRule`(默认):轮询策略
+- `WeightedResponseTimeRule`:权重(根据响应时间决定权重)策略
+- `BestAvailableRule`:最小连接数策略
- `RetryRule`:重试策略(按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null)
-- `AvailabilityFilteringRule` :可用敏感性策略(先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例)
-- `ZoneAvoidanceRule` :区域敏感性策略(根据服务所在区域的性能和服务的可用性来选择服务实例)
+- `AvailabilityFilteringRule`:可用敏感性策略(先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例)
+- `ZoneAvoidanceRule`:区域敏感性策略(根据服务所在区域的性能和服务的可用性来选择服务实例)
Spring Cloud Load Balancer 支持的 2 种负载均衡策略:
-- `RandomLoadBalancer` :随机策略
-- `RoundRobinLoadBalancer`(默认) :轮询策略
+- `RandomLoadBalancer`:随机策略
+- `RoundRobinLoadBalancer`(默认):轮询策略
```java
public class CustomLoadBalancerConfiguration {
@@ -192,8 +192,8 @@ public class CustomLoadBalancerConfiguration {
这里举两个官方的例子:
-- `ZonePreferenceServiceInstanceListSupplier` :实现基于区域的负载平衡
-- `HintBasedServiceInstanceListSupplier` :实现基于 hint 提示的负载均衡
+- `ZonePreferenceServiceInstanceListSupplier`:实现基于区域的负载平衡
+- `HintBasedServiceInstanceListSupplier`:实现基于 hint 提示的负载均衡
```java
public class CustomLoadBalancerConfiguration {
diff --git a/docs/high-performance/message-queue/disruptor-questions.md b/docs/high-performance/message-queue/disruptor-questions.md
index 82c203241eb..b58e7edef10 100644
--- a/docs/high-performance/message-queue/disruptor-questions.md
+++ b/docs/high-performance/message-queue/disruptor-questions.md
@@ -40,7 +40,7 @@ Disruptor 提供的功能优点类似于 Kafka、RocketMQ 这类分布式队列
Disruptor 主要解决了 JDK 内置线程安全队列的性能和内存安全问题。
-**JDK 中常见的线程安全的队列如下** :
+**JDK 中常见的线程安全的队列如下**:
| 队列名字 | 锁 | 是否有界 |
| ----------------------- | ----------------------- | -------- |
@@ -65,31 +65,31 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
## Kafka 和 Disruptor 什么区别?
-- **Kafka** :分布式消息队列,一般用在系统或者服务之间的消息传递,还可以被用作流式处理平台。
-- **Disruptor** :内存级别的消息队列,一般用在系统内部中线程间的消息传递。
+- **Kafka**:分布式消息队列,一般用在系统或者服务之间的消息传递,还可以被用作流式处理平台。
+- **Disruptor**:内存级别的消息队列,一般用在系统内部中线程间的消息传递。
## 哪些组件用到了 Disruptor?
用到 Disruptor 的开源项目还是挺多的,这里简单举几个例子:
-- **Log4j2** :Log4j2 是一款常用的日志框架,它基于 Disruptor 来实现异步日志。
-- **SOFATracer** :SOFATracer 是蚂蚁金服开源的分布式应用链路追踪工具,它基于 Disruptor 来实现异步日志。
+- **Log4j2**:Log4j2 是一款常用的日志框架,它基于 Disruptor 来实现异步日志。
+- **SOFATracer**:SOFATracer 是蚂蚁金服开源的分布式应用链路追踪工具,它基于 Disruptor 来实现异步日志。
- **Storm** : Storm 是一个开源的分布式实时计算系统,它基于 Disruptor 来实现工作进程内发生的消息传递(同一 Storm 节点上的线程间,无需网络通信)。
-- **HBase** :HBase 是一个分布式列存储数据库系统,它基于 Disruptor 来提高写并发性能。
+- **HBase**:HBase 是一个分布式列存储数据库系统,它基于 Disruptor 来提高写并发性能。
- ......
## Disruptor 核心概念有哪些?
-- **Event** :你可以把 Event 理解为存放在队列中等待消费的消息对象。
-- **EventFactory** :事件工厂用于生产事件,我们在初始化 `Disruptor` 类的时候需要用到。
-- **EventHandler** :Event 在对应的 Handler 中被处理,你可以将其理解为生产消费者模型中的消费者。
-- **EventProcessor** :EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。
-- **Disruptor** :事件的生产和消费需要用到 `Disruptor` 对象。
-- **RingBuffer** :RingBuffer(环形数组)用于保存事件。
-- **WaitStrategy** :等待策略。决定了没有事件可以消费的时候,事件消费者如何等待新事件的到来。
-- **Producer** :生产者,只是泛指调用 `Disruptor` 对象发布事件的用户代码,Disruptor 没有定义特定接口或类型。
-- **ProducerType** :指定是单个事件发布者模式还是多个事件发布者模式(发布者和生产者的意思类似,我个人比较喜欢用发布者)。
-- **Sequencer** :Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 `SingleProducerSequencer`、`MultiProducerSequencer` ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
+- **Event**:你可以把 Event 理解为存放在队列中等待消费的消息对象。
+- **EventFactory**:事件工厂用于生产事件,我们在初始化 `Disruptor` 类的时候需要用到。
+- **EventHandler**:Event 在对应的 Handler 中被处理,你可以将其理解为生产消费者模型中的消费者。
+- **EventProcessor**:EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。
+- **Disruptor**:事件的生产和消费需要用到 `Disruptor` 对象。
+- **RingBuffer**:RingBuffer(环形数组)用于保存事件。
+- **WaitStrategy**:等待策略。决定了没有事件可以消费的时候,事件消费者如何等待新事件的到来。
+- **Producer**:生产者,只是泛指调用 `Disruptor` 对象发布事件的用户代码,Disruptor 没有定义特定接口或类型。
+- **ProducerType**:指定是单个事件发布者模式还是多个事件发布者模式(发布者和生产者的意思类似,我个人比较喜欢用发布者)。
+- **Sequencer**:Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 `SingleProducerSequencer`、`MultiProducerSequencer` ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
下面这张图摘自 Disruptor 官网,展示了 LMAX 系统使用 Disruptor 的示例。
@@ -115,14 +115,14 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
## Disruptor 为什么这么快?
- **RingBuffer(环形数组)** : Disruptor 内部的 RingBuffer 是通过数组实现的。由于这个数组中的所有元素在初始化时一次性全部创建,因此这些元素的内存地址一般来说是连续的。这样做的好处是,当生产者不断往 RingBuffer 中插入新的事件对象时,这些事件对象的内存地址就能够保持连续,从而利用 CPU 缓存的局部性原理,将相邻的事件对象一起加载到缓存中,提高程序的性能。这类似于 MySQL 的预读机制,将连续的几个页预读到内存里。除此之外,RingBuffer 基于数组还支持批量操作(一次处理多个元素)、还可以避免频繁的内存分配和垃圾回收(RingBuffer 是一个固定大小的数组,当向数组中添加新元素时,如果数组已满,则新元素将覆盖掉最旧的元素)。
-- **避免了伪共享问题** :CPU 缓存内部是按照 Cache Line(缓存行)管理的,一般的 Cache Line 大小在 64 字节左右。Disruptor 为了确保目标字段独占一个 Cache Line,会在目标字段前后增加了 64 个字节的填充(前 56 个字节和后 8 个字节),这样可以避免 Cache Line 的伪共享(False Sharing)问题。
-- **无锁设计** :Disruptor 采用无锁设计,避免了传统锁机制带来的竞争和延迟。Disruptor 的无锁实现起来比较复杂,主要是基于 CAS、内存屏障(Memory Barrier)、RingBuffer 等技术实现的。
+- **避免了伪共享问题**:CPU 缓存内部是按照 Cache Line(缓存行)管理的,一般的 Cache Line 大小在 64 字节左右。Disruptor 为了确保目标字段独占一个 Cache Line,会在目标字段前后增加了 64 个字节的填充(前 56 个字节和后 8 个字节),这样可以避免 Cache Line 的伪共享(False Sharing)问题。
+- **无锁设计**:Disruptor 采用无锁设计,避免了传统锁机制带来的竞争和延迟。Disruptor 的无锁实现起来比较复杂,主要是基于 CAS、内存屏障(Memory Barrier)、RingBuffer 等技术实现的。
综上所述,Disruptor 之所以能够如此快,是基于一系列优化策略的综合作用,既充分利用了现代 CPU 缓存结构的特点,又避免了常见的并发问题和性能瓶颈。
关于 Disruptor 高性能队列原理的详细介绍,可以查看这篇文章:[Disruptor 高性能队列原理浅析](https://qin.news/disruptor/) (参考了美团技术团队的[高性能队列——Disruptor](https://tech.meituan.com/2016/11/18/disruptor.html)这篇文章)。
-🌈 这里额外补充一点 :**数组中对象元素地址连续为什么可以提高性能?**
+🌈 这里额外补充一点:**数组中对象元素地址连续为什么可以提高性能?**
CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更快的读取速度,并使用预取机制提前加载相邻内存的数据以利用局部性原理。
diff --git a/docs/high-performance/message-queue/kafka-questions-01.md b/docs/high-performance/message-queue/kafka-questions-01.md
index 4f3b0733f30..7f124abbca5 100644
--- a/docs/high-performance/message-queue/kafka-questions-01.md
+++ b/docs/high-performance/message-queue/kafka-questions-01.md
@@ -17,15 +17,15 @@ Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
Kafka 主要有两大应用场景:
-1. **消息队列** :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
+1. **消息队列**:建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
2. **数据处理:** 构建实时的流数据处理程序来转换或处理数据流。
### 和其他消息队列相比,Kafka 的优势在哪里?
我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它跟 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
-1. **极致的性能** :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
-2. **生态系统兼容性无可匹敌** :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
+1. **极致的性能**:基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
+2. **生态系统兼容性无可匹敌**:Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
实际上在早期的时候 Kafka 并不是一个合格的消息队列,早期的 Kafka 在消息队列领域就像是一个衣衫褴褛的孩子一样,功能不完备并且有一些小问题比如丢失消息、不保证消息可靠性等等。当然,这也和 LinkedIn 最早开发 Kafka 用于处理海量的日志有很大关系,哈哈哈,人家本来最开始就不是为了作为消息队列滴,谁知道后面误打误撞在消息队列领域占据了一席之地。
@@ -103,9 +103,9 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
从图中我们可以看出,Zookeeper 主要为 Kafka 做了下面这些事情:
-1. **Broker 注册** :在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
-2. **Topic 注册** :在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
-3. **负载均衡** :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
+1. **Broker 注册**:在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
+2. **Topic 注册**:在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
+3. **负载均衡**:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
4. ......
### Kafka 如何保证消息的消费顺序?
diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md
index 4556c677b17..4d7b6717ce9 100644
--- a/docs/high-performance/message-queue/message-queue.md
+++ b/docs/high-performance/message-queue/message-queue.md
@@ -153,10 +153,10 @@ AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的
RPC 和消息队列都是分布式微服务系统中重要的组件之一,下面我们来简单对比一下两者:
-- **从用途来看** :RPC 主要用来解决两个服务的远程通信问题,不需要了解底层网络的通信机制。通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。消息队列主要用来降低系统耦合性、实现任务异步、有效地进行流量削峰。
-- **从通信方式来看** :RPC 是双向直接网络通讯,消息队列是单向引入中间载体的网络通讯。
-- **从架构上来看** :消息队列需要把消息存储起来,RPC 则没有这个要求,因为前面也说了 RPC 是双向直接网络通讯。
-- **从请求处理的时效性来看** :通过 RPC 发出的调用一般会立即被处理,存放在消息队列中的消息并不一定会立即被处理。
+- **从用途来看**:RPC 主要用来解决两个服务的远程通信问题,不需要了解底层网络的通信机制。通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。消息队列主要用来降低系统耦合性、实现任务异步、有效地进行流量削峰。
+- **从通信方式来看**:RPC 是双向直接网络通讯,消息队列是单向引入中间载体的网络通讯。
+- **从架构上来看**:消息队列需要把消息存储起来,RPC 则没有这个要求,因为前面也说了 RPC 是双向直接网络通讯。
+- **从请求处理的时效性来看**:通过 RPC 发出的调用一般会立即被处理,存放在消息队列中的消息并不一定会立即被处理。
RPC 和消息队列本质上是网络通讯的两种不同的实现机制,两者的用途不同,万不可将两者混为一谈。
diff --git a/docs/high-performance/message-queue/rabbitmq-questions.md b/docs/high-performance/message-queue/rabbitmq-questions.md
index 95b1d89afe4..0f0d9f8e519 100644
--- a/docs/high-performance/message-queue/rabbitmq-questions.md
+++ b/docs/high-performance/message-queue/rabbitmq-questions.md
@@ -138,17 +138,17 @@ RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STO
RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。
-**AMQP 协议的三层** :
+**AMQP 协议的三层**:
- **Module Layer**:协议最高层,主要定义了一些客户端调用的命令,客户端可以用这些命令实现自己的业务逻辑。
- **Session Layer**:中间层,主要负责客户端命令发送给服务器,再将服务端应答返回客户端,提供可靠性同步机制和错误处理。
- **TransportLayer**:最底层,主要传输二进制数据流,提供帧的处理、信道服用、错误检测和数据表示等。
-**AMQP 模型的三大组件** :
+**AMQP 模型的三大组件**:
-- **交换器 (Exchange)** :消息代理服务器中用于把消息路由到队列的组件。
-- **队列 (Queue)** :用来存储消息的数据结构,位于硬盘或内存中。
-- **绑定 (Binding)** :一套规则,告知交换器消息应该将消息投递给哪个队列。
+- **交换器 (Exchange)**:消息代理服务器中用于把消息路由到队列的组件。
+- **队列 (Queue)**:用来存储消息的数据结构,位于硬盘或内存中。
+- **绑定 (Binding)**:一套规则,告知交换器消息应该将消息投递给哪个队列。
## **说说生产者 Producer 和消费者 Consumer?**
@@ -157,14 +157,14 @@ RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都
- 消息生产者,就是投递消息的一方。
- 消息一般包含两个部分:消息体(`payload`)和标签(`Label`)。
-**消费者** :
+**消费者**:
- 消费消息,也就是接收消息的一方。
- 消费者连接到 RabbitMQ 服务器,并订阅到队列上。消费消息时只消费消息体,丢弃标签。
## 说说 Broker 服务节点、Queue 队列、Exchange 交换器?
-- **Broker** :可以看做 RabbitMQ 的服务节点。一般请下一个 Broker 可以看做一个 RabbitMQ 服务器。
+- **Broker**:可以看做 RabbitMQ 的服务节点。一般请下一个 Broker 可以看做一个 RabbitMQ 服务器。
- **Queue** :RabbitMQ 的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
- **Exchange** : 生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃。
diff --git a/docs/high-performance/read-and-write-separation-and-library-subtable.md b/docs/high-performance/read-and-write-separation-and-library-subtable.md
index 4e91f93962e..6847b6ad5c8 100644
--- a/docs/high-performance/read-and-write-separation-and-library-subtable.md
+++ b/docs/high-performance/read-and-write-separation-and-library-subtable.md
@@ -157,10 +157,10 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
-- **哈希分片** :求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
-- **范围分片** :按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
-- **地理位置分片** :很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
-- **融合算法** :灵活组合多种分片算法,比如将哈希分片和范围分片组合。
+- **哈希分片**:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
+- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
+- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
+- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
- ......
### 分库分表会带来什么问题呢?
@@ -169,9 +169,9 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
引入分库分表之后,会给系统带来什么挑战呢?
-- **join 操作** :同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
-- **事务问题** :同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
-- **分布式 id** :分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
+- **join 操作**:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。
+- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。
+- **分布式 id**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 id 了。
- ......
另外,引入分库分表之后,一般需要 DBA 的参与,同时还需要更多的数据库服务器,这些都属于成本。
diff --git a/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md b/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
index 379fe2a7d17..ea47e2965d1 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/20-bad-habits-of-bad-programmers.md
@@ -6,7 +6,7 @@ tag:
- 练级攻略
---
-> **推荐语** :Kaito 大佬的一篇文章,很实用的建议!
+> **推荐语**:Kaito 大佬的一篇文章,很实用的建议!
>
>
>
diff --git a/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md b/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
index aaff014b540..0dbe554eafb 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/seven-tips-for-becoming-an-advanced-programmer.md
@@ -6,9 +6,9 @@ tag:
- 练级攻略
---
-> **推荐语** :普通程序员要想成长为高级程序员甚至是专家等更高级别,应该注意在哪些方面注意加强?开发内功修炼号主飞哥在这篇文章中就给出了七条实用的建议。
+> **推荐语**:普通程序员要想成长为高级程序员甚至是专家等更高级别,应该注意在哪些方面注意加强?开发内功修炼号主飞哥在这篇文章中就给出了七条实用的建议。
>
-> **内容概览** :
+> **内容概览**:
>
> 1. 刻意加强需求评审能力
> 2. 主动思考效率
@@ -18,7 +18,7 @@ tag:
> 6. 关注全局
> 7. 归纳总结能力
>
-> **原文地址** :https://mp.weixin.qq.com/s/8lMGzBzXine-NAsqEaIE4g
+> **原文地址**:https://mp.weixin.qq.com/s/8lMGzBzXine-NAsqEaIE4g
### 建议 1:刻意加强需求评审能力
diff --git a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
index 0c66fab1c16..c3acee32889 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
@@ -6,7 +6,7 @@ tag:
- 练级攻略
---
-> **推荐语** :波波老师的一篇文章,写的非常好,不光是对技术成长有帮助,其他领域也是同样适用的!建议反复阅读,形成一套自己的技术成长策略。
+> **推荐语**:波波老师的一篇文章,写的非常好,不光是对技术成长有帮助,其他领域也是同样适用的!建议反复阅读,形成一套自己的技术成长策略。
>
>
>
diff --git a/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md b/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
index b1b9ee3bdf2..cef6e51c6e5 100644
--- a/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
+++ b/docs/high-quality-technical-articles/interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md
@@ -6,7 +6,7 @@ tag:
- 面试
---
-> **推荐语** :从面试官和面试者两个角度探讨了技术面试!非常不错!
+> **推荐语**:从面试官和面试者两个角度探讨了技术面试!非常不错!
>
>
>
@@ -18,7 +18,7 @@ tag:
>
>
>
-> **原文地址** :https://www.cnblogs.com/lovesqcc/p/15169365.html
+> **原文地址**:https://www.cnblogs.com/lovesqcc/p/15169365.html
## 灵魂三连问
@@ -313,7 +313,7 @@ tag:
如果候选人答不上,可以问:如果你来设计这样一个 XXX, 你会怎么做?
-时间占比大概为 :技术基础(25-30 分钟) + 项目(20-25 分钟) + 候选人提问(5-10 分钟)
+时间占比大概为:技术基础(25-30 分钟) + 项目(20-25 分钟) + 候选人提问(5-10 分钟)
## 给候选人的话
diff --git a/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md b/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
index 5963059dfae..c5e69a76d3d 100644
--- a/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
+++ b/docs/high-quality-technical-articles/interview/my-personal-experience-in-2021.md
@@ -6,11 +6,11 @@ tag:
- 面试
---
-> **推荐语** :这篇文章的作者校招最终去了飞书做开发。在这篇文章中,他分享了自己的校招经历以及个人经验。
+> **推荐语**:这篇文章的作者校招最终去了飞书做开发。在这篇文章中,他分享了自己的校招经历以及个人经验。
>
>
>
-> **原文地址** :https://www.ihewro.com/archives/1217/
+> **原文地址**:https://www.ihewro.com/archives/1217/
## 基本情况
diff --git a/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md b/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
index 7a534579f4a..b2ed4c772b3 100644
--- a/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
+++ b/docs/high-quality-technical-articles/interview/screen-candidates-for-packaging.md
@@ -6,11 +6,11 @@ tag:
- 面试
---
-> **推荐语** :经常听到培训班待过的朋友给我说他们的老师是怎么教他们“包装”自己的,不光是培训班,我认识的很多朋友也都会在面试之前“包装”一下自己,所以这个现象是普遍存在的。但是面试官也不都是傻子,通过下面这篇文章来看看面试官是如何甄别应聘者的包装程度。
+> **推荐语**:经常听到培训班待过的朋友给我说他们的老师是怎么教他们“包装”自己的,不光是培训班,我认识的很多朋友也都会在面试之前“包装”一下自己,所以这个现象是普遍存在的。但是面试官也不都是傻子,通过下面这篇文章来看看面试官是如何甄别应聘者的包装程度。
>
>
>
-> **原文地址** :https://my.oschina.net/hooker/blog/3014656
+> **原文地址**:https://my.oschina.net/hooker/blog/3014656
## 前言
diff --git a/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md b/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
index 089b011684e..32a33086c4e 100644
--- a/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
+++ b/docs/high-quality-technical-articles/interview/some-secrets-about-alibaba-interview.md
@@ -6,7 +6,7 @@ tag:
- 面试
---
-> **推荐语** :详细介绍了求职者在面试中应该具备哪些能力才会有更大概率脱颖而出。
+> **推荐语**:详细介绍了求职者在面试中应该具备哪些能力才会有更大概率脱颖而出。
>
>
>
diff --git a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
index 0288681822a..17644017cb3 100644
--- a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
+++ b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
@@ -6,7 +6,7 @@ tag:
- 面试
---
-> **推荐语** :牛客网热帖,写的很全面!暑期实习,投了阿里、腾讯、字节,拿到了阿里和腾讯的 offer。
+> **推荐语**:牛客网热帖,写的很全面!暑期实习,投了阿里、腾讯、字节,拿到了阿里和腾讯的 offer。
>
>
>
@@ -14,7 +14,7 @@ tag:
>
>
>
-> **下篇** :[十年饮冰,难凉热血——秋招总结](https://www.nowcoder.com/discuss/804679)
+> **下篇**:[十年饮冰,难凉热血——秋招总结](https://www.nowcoder.com/discuss/804679)
## 背景
@@ -64,11 +64,11 @@ tag:
我上面谈到的学习路线,我建议是跟着视频学,尚硅谷和黑马的教程都可以,一定要手敲一遍。
- [2021 南京大学 “操作系统:设计与实现” (蒋炎岩)](https://www.bilibili.com/video/BV1HN41197Ko):我不多说了,看评论就知道了。
-- [SpringSecurity-Social-OAuth2 社交登录接口授权鉴权系列课程](https://www.bilibili.com/video/BV16J41127jq) :字母哥讲的 Spring Security 也很好,Spring Security 或者 Shiro 是做项目必备的,会一个就好,根据实际场景以及个人喜好(笑)来选型。
-- [清华大学邓俊辉数据结构与算法](https://www.bilibili.com/video/BV1jt4y117KR) :清华不解释了。
+- [SpringSecurity-Social-OAuth2 社交登录接口授权鉴权系列课程](https://www.bilibili.com/video/BV16J41127jq):字母哥讲的 Spring Security 也很好,Spring Security 或者 Shiro 是做项目必备的,会一个就好,根据实际场景以及个人喜好(笑)来选型。
+- [清华大学邓俊辉数据结构与算法](https://www.bilibili.com/video/BV1jt4y117KR):清华不解释了。
- [MySQL 实战 45 讲](https://time.geekbang.org/column/intro/100020801):前 27 讲多看几遍基本可以秒杀面试中遇到的 MySQL 问题了。
- [Redis 核心技术与实战](https://time.geekbang.org/column/intro/100056701):讲解了大量的 Redis 在生产上的使用场景,和《Redis 设计与实现》配合着看,也可以秒杀面试中遇到的 Redis 问题了。
-- [JavaGuide](https://javaguide.cn/books/) :「Java 学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。
+- [JavaGuide](https://javaguide.cn/books/):「Java 学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。
- [《Java 面试指北》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247519384&idx=1&sn=bc7e71af75350b755f04ca4178395b1a&chksm=cea1c353f9d64a458f797696d4144b4d6e58639371a4612b8e4d106d83a66d2289e7b2cd7431&token=660789642&lang=zh_CN&scene=21#wechat_redirect):这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ......)、优质面经等内容。
## 找工作
diff --git a/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md b/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
index 446799ca380..4a7a3de9239 100644
--- a/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
+++ b/docs/high-quality-technical-articles/interview/technical-preliminary-preparation.md
@@ -6,7 +6,7 @@ tag:
- 面试
---
-> **推荐语** :从面试官和面试者两个角度探讨了技术面试!非常不错!
+> **推荐语**:从面试官和面试者两个角度探讨了技术面试!非常不错!
>
> **内容概览:**
>
diff --git a/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md b/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
index 234cbda5e38..02ccd59a266 100644
--- a/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
+++ b/docs/high-quality-technical-articles/interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md
@@ -6,9 +6,9 @@ tag:
- 面试
---
-> **推荐语** :本文的作者,今年 36 岁,已有 8 年 JAVA 开发经验。在阿里云三年半,有赞四年半,已是标准的大龄程序员了。在这篇文章中,作者给出了一些关于面试和个人能力提升的一些小建议,非常实用!
+> **推荐语**:本文的作者,今年 36 岁,已有 8 年 JAVA 开发经验。在阿里云三年半,有赞四年半,已是标准的大龄程序员了。在这篇文章中,作者给出了一些关于面试和个人能力提升的一些小建议,非常实用!
>
-> **内容概览** :
+> **内容概览**:
>
> 1. 个人介绍,是对自己的一个更为清晰、深入和全面的认识契机。
> 2. 简历是充分展示自己的浓缩精华,也是重新审视自己和过往经历的契机。不仅仅是简要介绍技能和经验,更要最大程度凸显自己的优势领域(差异化)。
@@ -17,7 +17,7 @@ tag:
> 5. 要善于从失败中学习。正是在杭州四个月空档期的持续学习、思考、积累和提炼,以及面试失败的反思、不断调整对策、完善准备、改善原有的短板,采取更为合理的方式,才在回武汉的短短两个周内拿到比较满意的 offer 。
> 6. 面试是通过沟通来理解双方的过程。面试中的问题,千变万化,但有一些问题是需要提前准备好的。
>
-> **原文地址** :https://www.cnblogs.com/lovesqcc/p/14354921.html
+> **原文地址**:https://www.cnblogs.com/lovesqcc/p/14354921.html
从每一段经历中学习,在每一件事情中修行。善于从挫折中学习。
@@ -80,7 +80,7 @@ tag:
每个人其实都有很多可说的东西,但记录下来的又有多少呢?值得谈道的有多少呢?过往不努力,面试徒伤悲。
-**简历更新的心得** :
+**简历更新的心得**:
- 简历是充分展示自己的浓缩精华,也是重新审视自己和过往经历的契机;
- 不仅仅是简要介绍技能和经验,更要最大程度凸显自己的优势领域(差异化);
diff --git a/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md b/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
index 2e6357419c3..16d8f9e4856 100644
--- a/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
+++ b/docs/high-quality-technical-articles/interview/the-experience-of-get-offer-from-over-20-big-companies.md
@@ -6,11 +6,11 @@ tag:
- 面试
---
-> **推荐语** :很实用的面试经验分享!
+> **推荐语**:很实用的面试经验分享!
>
>
>
-> **原文地址** :https://mp.weixin.qq.com/s/HXKg6-H0kGUU2OA1DS43Bw
+> **原文地址**:https://mp.weixin.qq.com/s/HXKg6-H0kGUU2OA1DS43Bw
突然回想起当年,我也在秋招时也斩获了 20+的互联网各大厂 offer。现在想起来也是有点唏嘘,毕竟拿得再多也只能选择一家。不过许多朋友想让我分享下互联网面试方法,今天就来给大家仔细讲讲打法!
diff --git a/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md b/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
index 27518f58e1b..f6362c7fa05 100644
--- a/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
+++ b/docs/high-quality-technical-articles/personal-experience/8-years-programmer-work-summary.md
@@ -6,11 +6,11 @@ tag:
- 个人经历
---
-> **推荐语** :这篇文章讲述了一位中科大的朋友 8 年的经历:从 2013 年毕业之后加入上海航天 x 院某卫星研究所,再到入职华为,从华为离职。除了丰富的经历之外,作者在文章还给出了很多自己对于工作/生活的思考。我觉得非常受用!我在这里,向这位作者表达一下衷心的感谢。
+> **推荐语**:这篇文章讲述了一位中科大的朋友 8 年的经历:从 2013 年毕业之后加入上海航天 x 院某卫星研究所,再到入职华为,从华为离职。除了丰富的经历之外,作者在文章还给出了很多自己对于工作/生活的思考。我觉得非常受用!我在这里,向这位作者表达一下衷心的感谢。
>
>
>
-> **原文地址** :https://www.cnblogs.com/scada/p/14259332.html
+> **原文地址**:https://www.cnblogs.com/scada/p/14259332.html
---
diff --git a/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md b/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
index ca6d3c2911f..56b1c1299a1 100644
--- a/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
+++ b/docs/high-quality-technical-articles/personal-experience/huawei-od-275-days.md
@@ -5,11 +5,11 @@ tag:
- 个人经历
---
-> **推荐语** :一位朋友的华为 OD 工作经历以及腾讯面试经历分享,内容很不错。
+> **推荐语**:一位朋友的华为 OD 工作经历以及腾讯面试经历分享,内容很不错。
>
>
>
-> **原文地址** :https://www.cnblogs.com/shoufeng/p/14322931.html
+> **原文地址**:https://www.cnblogs.com/shoufeng/p/14322931.html
## 时间线
diff --git a/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md b/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
index 80a1cfc1ea4..b3609658d43 100644
--- a/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
+++ b/docs/high-quality-technical-articles/personal-experience/two-years-of-back-end-develop--experience-in-didi-and-toutiao.md
@@ -5,9 +5,9 @@ tag:
- 个人经历
---
-> **推荐语** :很实用的工作经验分享,看完之后十分受用!
+> **推荐语**:很实用的工作经验分享,看完之后十分受用!
>
-> **内容概览** :
+> **内容概览**:
>
> - 要学会深入思考,总结沉淀,这是我觉得最重要也是最有意义的一件事。
> - 积极学习,保持技术热情。如果我们积极学习,保持技术能力、知识储备与工作年限成正比,这到了 35 岁哪还有什么焦虑呢,这样的大牛我觉得应该也是各大公司抢着要吧?
@@ -18,7 +18,7 @@ tag:
> - 平时积极总结沉淀,多跟别人交流,形成方法论。
> - ......
>
-> **原文地址** :https://www.nowcoder.com/discuss/351805
+> **原文地址**:https://www.nowcoder.com/discuss/351805
先简单交代一下背景吧,某不知名 985 的本硕,17 年毕业加入滴滴,当时找工作时候也是在牛客这里跟大家一起奋战的。今年下半年跳槽到了头条,一直从事后端研发相关的工作。之前没有实习经历,算是两年半的工作经验吧。这两年半之间完成了一次晋升,换了一家公司,有过开心满足的时光,也有过迷茫挣扎的日子,不过还算顺利地从一只职场小菜鸟转变为了一名资深划水员。在这个过程中,总结出了一些还算实用的划水经验,有些是自己领悟到的,有些是跟别人交流学到的,在这里跟大家分享一下。
diff --git a/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md b/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
index cbfcbf77690..e7077a592a5 100644
--- a/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
+++ b/docs/high-quality-technical-articles/programmer/efficient-book-publishing-and-practice-guide.md
@@ -6,11 +6,11 @@ tag:
- 程序员
---
-> **推荐语** :详细介绍了程序员出书的一些常见问题,强烈建议有出书想法的朋友看看这篇文章。
+> **推荐语**:详细介绍了程序员出书的一些常见问题,强烈建议有出书想法的朋友看看这篇文章。
>
>
>
-> **原文地址** :https://www.cnblogs.com/JavaArchitect/p/14128202.html
+> **原文地址**:https://www.cnblogs.com/JavaArchitect/p/14128202.html
古有三不朽, 所谓立德、立功、立言。程序员出一本属于自己的书,如果说是立言,可能过于高大上,但终究也算一件雅事。
diff --git a/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md b/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
index bda3cbe9672..1927c927127 100644
--- a/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
+++ b/docs/high-quality-technical-articles/programmer/how-do-programmers-publish-a-technical-book.md
@@ -6,11 +6,11 @@ tag:
- 程序员
---
-> **推荐语** :详细介绍了程序员应该如何从头开始出一本自己的书籍。
+> **推荐语**:详细介绍了程序员应该如何从头开始出一本自己的书籍。
>
>
>
-> **原文地址** :https://www.cnblogs.com/JavaArchitect/p/12195219.html
+> **原文地址**:https://www.cnblogs.com/JavaArchitect/p/12195219.html
在面试或联系副业的时候,如果能令人信服地证明自己的实力,那么很有可能事半功倍。如何证明自己的实力?最有信服力的是大公司职位背景背书,没有之一,比如在 BAT 担任资深架构,那么其它话甚至都不用讲了。
diff --git a/docs/high-quality-technical-articles/work/employee-performance.md b/docs/high-quality-technical-articles/work/employee-performance.md
index 46deda73b0d..11e0d4b0bbc 100644
--- a/docs/high-quality-technical-articles/work/employee-performance.md
+++ b/docs/high-quality-technical-articles/work/employee-performance.md
@@ -5,7 +5,7 @@ tag:
- 工作
---
-> **内容概览** :
+> **内容概览**:
>
> - 在大部分公司,绩效跟你的年终奖、职级晋升、薪水涨幅等等福利是直接相关的。
> - 你的上级、上上级对你的绩效拥有绝对的话语权,这是潜规则,放到任何公司都是。成年人的世界,没有绝对的公平,绩效考核尤为明显。
@@ -15,7 +15,7 @@ tag:
>
>
>
-> **原文地址** :https://mp.weixin.qq.com/s/D1s8p7z8Sp60c-ndGyh2yQ
+> **原文地址**:https://mp.weixin.qq.com/s/D1s8p7z8Sp60c-ndGyh2yQ
在新公司度过了一个完整的 Q3 季度,被打了绩效,也给下属打了绩效,感慨颇深。
@@ -35,7 +35,7 @@ tag:
然鹅,并非每个员工都会站在 CEO 的高度去理解 KPI 的价值,大家更关注的是 KPI 对于我个人来说到底有什么意义?
-在互联网大厂,每家公司都会设定一套绩效考核体系,字节用的是 OKR,阿里用的是 KPI,通常都是「271」 制度,即 :
+在互联网大厂,每家公司都会设定一套绩效考核体系,字节用的是 OKR,阿里用的是 KPI,通常都是「271」 制度,即:
> 20% 的比例是 A+ 和 A,对应明星员工。
>
diff --git a/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md b/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md
index 011d47ad67b..30b4e1cc0f3 100644
--- a/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md
+++ b/docs/high-quality-technical-articles/work/get-into-work-mode-quickly-when-you-join-a-company.md
@@ -5,11 +5,11 @@ tag:
- 工作
---
-> **推荐语** :强烈建议每一位即将入职/在职的小伙伴看看这篇文章,看完之后可以帮助你少踩很多坑。整篇文章逻辑清晰,内容全面!
+> **推荐语**:强烈建议每一位即将入职/在职的小伙伴看看这篇文章,看完之后可以帮助你少踩很多坑。整篇文章逻辑清晰,内容全面!
>
>
>
-> **原文地址** :https://www.cnblogs.com/hunternet/p/14675348.html
+> **原文地址**:https://www.cnblogs.com/hunternet/p/14675348.html
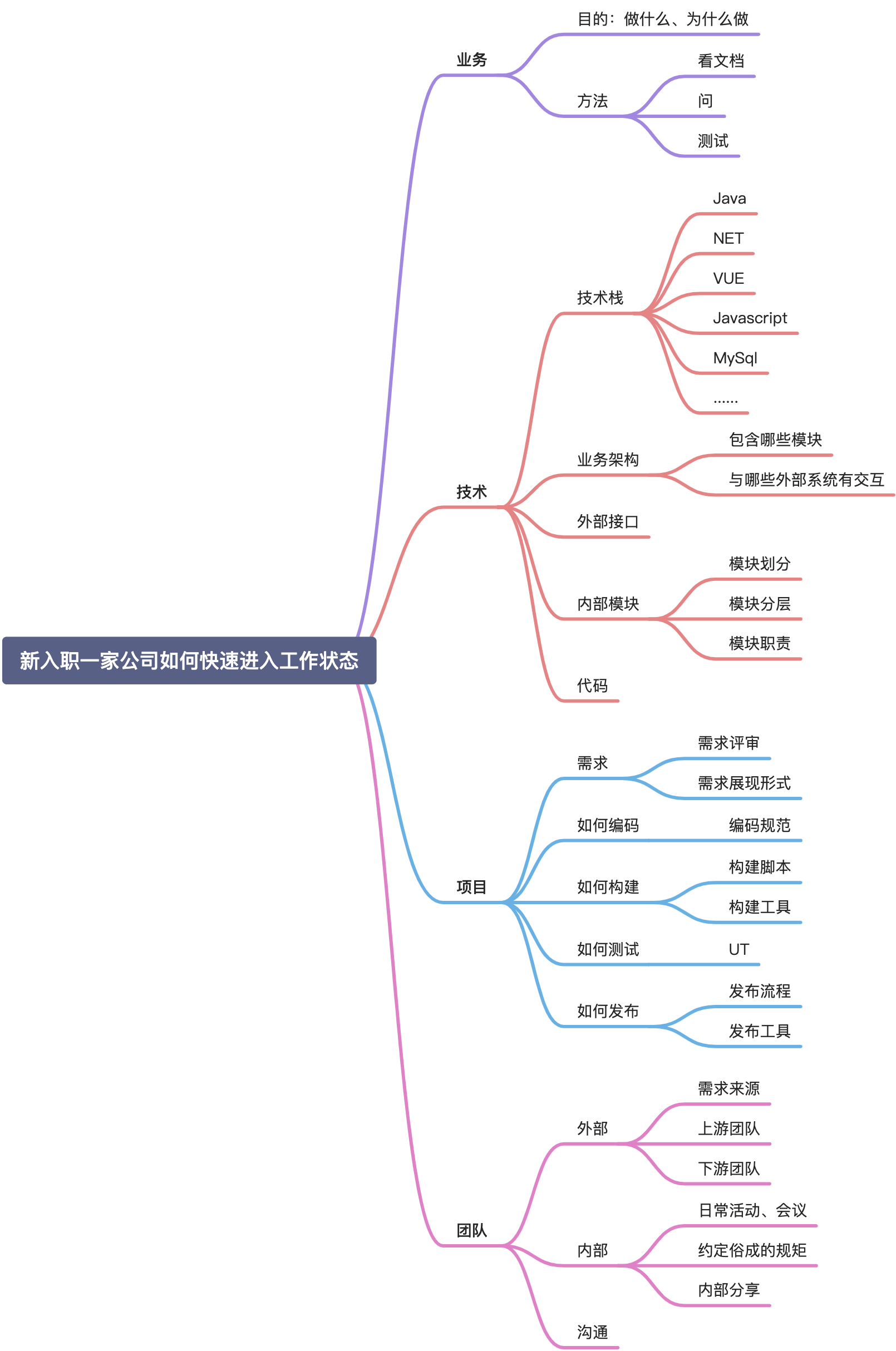
diff --git a/docs/home.md b/docs/home.md
index 528b64f1bcc..7c2407e9602 100644
--- a/docs/home.md
+++ b/docs/home.md
@@ -5,9 +5,9 @@ title: JavaGuide(Java学习&&面试指南)
::: tip 友情提示
-- **面试专版** :准备 Java 面试的小伙伴可以考虑面试专版:**[《Java 面试指北 》](./zhuanlan/java-mian-shi-zhi-bei.md)** (质量很高,专为面试打造,配合 JavaGuide 食用)。
-- **知识星球** :专属面试小册/一对一交流/简历修改/专属求职指南,欢迎加入 **[JavaGuide 知识星球](./about-the-author/zhishixingqiu-two-years.md)**(点击链接即可查看星球的详细介绍,一定确定自己真的需要再加入)。
-- **转载须知** :以下所有文章如非文首说明为转载皆为 JavaGuide 原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
+- **面试专版**:准备 Java 面试的小伙伴可以考虑面试专版:**[《Java 面试指北 》](./zhuanlan/java-mian-shi-zhi-bei.md)** (质量很高,专为面试打造,配合 JavaGuide 食用)。
+- **知识星球**:专属面试小册/一对一交流/简历修改/专属求职指南,欢迎加入 **[JavaGuide 知识星球](./about-the-author/zhishixingqiu-two-years.md)**(点击链接即可查看星球的详细介绍,一定确定自己真的需要再加入)。
+- **转载须知**:以下所有文章如非文首说明为转载皆为 JavaGuide 原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
:::
@@ -36,7 +36,7 @@ title: JavaGuide(Java学习&&面试指南)
- [Java 基础常见知识点&面试题总结(中)](./java/basis/java-basic-questions-02.md)
- [Java 基础常见知识点&面试题总结(下)](./java/basis/java-basic-questions-03.md)
-**重要知识点详解** :
+**重要知识点详解**:
- [为什么 Java 中只有值传递?](./java/basis/why-there-only-value-passing-in-java.md)
- [Java 序列化详解](./java/basis/serialization.md)
@@ -50,13 +50,13 @@ title: JavaGuide(Java学习&&面试指南)
### 集合
-**知识点/面试题总结** :
+**知识点/面试题总结**:
- [Java 集合常见知识点&面试题总结(上)](./java/collection/java-collection-questions-01.md) (必看 :+1:)
- [Java 集合常见知识点&面试题总结(下)](./java/collection/java-collection-questions-02.md) (必看 :+1:)
- [Java 容器使用注意事项总结](./java/collection/java-collection-precautions-for-use.md)
-**源码分析** :
+**源码分析**:
- [ArrayList 源码+扩容机制分析](./java/collection/arraylist-source-code.md)
- [HashMap(JDK1.8)源码+底层数据结构分析](./java/collection/hashmap-source-code.md)
@@ -76,10 +76,10 @@ title: JavaGuide(Java学习&&面试指南)
- [Java 并发常见知识点&面试题总结(中)](./java/concurrent/java-concurrent-questions-02.md)
- [Java 并发常见知识点&面试题总结(下)](./java/concurrent/java-concurrent-questions-03.md)
-**重要知识点详解** :
+**重要知识点详解**:
- [JMM(Java 内存模型)详解](./java/concurrent/jmm.md)
-- **线程池** :[Java 线程池详解](./java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./java/concurrent/java-thread-pool-best-practices.md)
+- **线程池**:[Java 线程池详解](./java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./java/concurrent/java-thread-pool-best-practices.md)
- [ThreadLocal 详解](./java/concurrent/threadlocal.md)
- [Java 并发容器总结](./java/concurrent/java-concurrent-collections.md)
- [Atomic 原子类总结](./java/concurrent/atomic-classes.md)
@@ -101,7 +101,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
### 新特性
-- **Java 8** :[Java 8 新特性总结(翻译)](./java/new-features/java8-tutorial-translate.md)、[Java8 常用新特性总结](./java/new-features/java8-common-new-features.md)
+- **Java 8**:[Java 8 新特性总结(翻译)](./java/new-features/java8-tutorial-translate.md)、[Java8 常用新特性总结](./java/new-features/java8-common-new-features.md)
- [Java 9 新特性概览](./java/new-features/java9.md)
- [Java 10 新特性概览](./java/new-features/java10.md)
- [Java 11 新特性概览](./java/new-features/java11.md)
@@ -119,20 +119,19 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
- [操作系统常见知识点&面试题总结(上)](./cs-basics/operating-system/operating-system-basic-questions-01.md)
- [操作系统常见知识点&面试题总结(下)](./cs-basics/operating-system/operating-system-basic-questions-02.md)
-- **Linux** :
+- **Linux**:
- [后端程序员必备的 Linux 基础知识总结](./cs-basics/operating-system/linux-intro.md)
- [Shell 编程基础知识总结](./cs-basics/operating-system/shell-intro.md)
-
### 网络
-**知识点/面试题总结** :
+**知识点/面试题总结**:
- [计算机网络常见知识点&面试题总结(上)](./cs-basics/network/other-network-questions.md)
- [计算机网络常见知识点&面试题总结(下)](./cs-basics/network/other-network-questions2.md)
- [谢希仁老师的《计算机网络》内容总结(补充)](./cs-basics/network/computer-network-xiexiren-summary.md)
-**重要知识点详解** :
+**重要知识点详解**:
- [OSI 和 TCP/IP 网络分层模型详解(基础)](./cs-basics/network/osi-and-tcp-ip-model.md)
- [应用层常见协议总结(应用层)](./cs-basics/network/application-layer-protocol.md)
@@ -153,9 +152,9 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
- [线性数据结构 :数组、链表、栈、队列](./cs-basics/data-structure/linear-data-structure.md)
- [图](./cs-basics/data-structure/graph.md)
- [堆](./cs-basics/data-structure/heap.md)
-- [树](./cs-basics/data-structure/tree.md) :重点关注[红黑树](./cs-basics/data-structure/red-black-tree.md)、B-,B+,B\*树、LSM 树
+- [树](./cs-basics/data-structure/tree.md):重点关注[红黑树](./cs-basics/data-structure/red-black-tree.md)、B-,B+,B\*树、LSM 树
-其他常用数据结构 :
+其他常用数据结构:
- [布隆过滤器](./cs-basics/data-structure/bloom-filter.md)
@@ -166,7 +165,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
- [算法学习书籍+资源推荐](https://www.zhihu.com/question/323359308/answer/1545320858) 。
- [如何刷 Leetcode?](https://www.zhihu.com/question/31092580/answer/1534887374)
-**常见算法问题总结** :
+**常见算法问题总结**:
- [几道常见的字符串算法题总结](./cs-basics/algorithms/string-algorithm-problems.md)
- [几道常见的链表算法题总结](./cs-basics/algorithms/linkedlist-algorithm-problems.md)
@@ -278,7 +277,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
- [Spring/Spring Boot 常用注解总结](./system-design/framework/spring/spring-common-annotations.md)
- [SpringBoot 入门指南](https://github.com/Snailclimb/springboot-guide)
-**重要知识点详解** :
+**重要知识点详解**:
- [Spring 事务详解](./system-design/framework/spring/spring-transaction.md)
- [Spring 中的设计模式详解](./system-design/framework/spring/spring-design-patterns-summary.md)
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index a60e0894921..b5f964e823f 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -90,11 +90,11 @@ GitHub 或者码云上面有很多实战类别项目,你可以选择一个来
简单说几个比较容易的优化点:
-1. **全局异常处理** :很多项目这方面都做的不是很好,可以参考我的这篇文章:[《使用枚举简单封装一个优雅的 Spring Boot 全局异常处理!》](https://mp.weixin.qq.com/s/Y4Q4yWRqKG_lw0GLUsY2qw) 来做优化。
-2. **项目的技术选型优化** :比如使用 Guava 做本地缓存的地方可以换成 **Caffeine** 。Caffeine 的各方面的表现要更加好!再比如 Controller 层是否放了太多的业务逻辑。
-3. **数据库方面** :数据库设计可否优化?索引是否使用使用正确?SQL 语句是否可以优化?是否需要进行读写分离?
-4. **缓存** :项目有没有哪些数据是经常被访问的?是否引入缓存来提高响应速度?
-5. **安全** :项目是否存在安全问题?
+1. **全局异常处理**:很多项目这方面都做的不是很好,可以参考我的这篇文章:[《使用枚举简单封装一个优雅的 Spring Boot 全局异常处理!》](https://mp.weixin.qq.com/s/Y4Q4yWRqKG_lw0GLUsY2qw) 来做优化。
+2. **项目的技术选型优化**:比如使用 Guava 做本地缓存的地方可以换成 **Caffeine** 。Caffeine 的各方面的表现要更加好!再比如 Controller 层是否放了太多的业务逻辑。
+3. **数据库方面**:数据库设计可否优化?索引是否使用使用正确?SQL 语句是否可以优化?是否需要进行读写分离?
+4. **缓存**:项目有没有哪些数据是经常被访问的?是否引入缓存来提高响应速度?
+5. **安全**:项目是否存在安全问题?
6. ......
另外,我在星球分享过常见的性能优化方向实践案例,涉及到多线程、异步、索引、缓存等方向,强烈推荐你看看: 。
diff --git a/docs/interview-preparation/resume-guide.md b/docs/interview-preparation/resume-guide.md
index 3eff900f567..263387c5036 100644
--- a/docs/interview-preparation/resume-guide.md
+++ b/docs/interview-preparation/resume-guide.md
@@ -37,13 +37,13 @@ icon: jianli
下面是我收集的一些还不错的简历模板:
- 适合中文的简历模板收集(推荐,免费):https://github.com/dyweb/awesome-resume-for-chinese
-- 木及简历(部分收费) :https://www.mujicv.com/。
+- 木及简历(部分收费):https://www.mujicv.com/。
- 简单简历(付费):https://easycv.cn/
- 站长简历:https://jianli.chinaz.com/
-- typora+markdown+css 自定义简历模板 :https://github.com/Snailclimb/typora-markdown-resume
-- 极简简历 :https://www.polebrief.com/index
+- typora+markdown+css 自定义简历模板:https://github.com/Snailclimb/typora-markdown-resume
+- 极简简历:https://www.polebrief.com/index
- Markdown 简历排版工具:https://resume.mdnice.com/
-- 超级简历(部分收费) :https://www.wondercv.com/
+- 超级简历(部分收费):https://www.wondercv.com/
上面这些简历模板大多是只有 1 页内容,很难展现足够的信息量。如果你不是顶级大牛(比如 ACM 大赛获奖)的话,我建议还是尽可能多写一点可以突出你自己能力的内容(校招生 2 页之内,社招生 3 页之内,记得精炼语言,不要过多废话)。
@@ -57,7 +57,7 @@ icon: jianli
### 个人信息
-- 最基本的 :姓名(身份证上的那个)、年龄、电话、籍贯、联系方式、邮箱地址
+- 最基本的:姓名(身份证上的那个)、年龄、电话、籍贯、联系方式、邮箱地址
- 潜在加分项: GitHub 地址、博客地址(如果技术博客和 GitHub 上没有什么内容的话,就不要写了)
示例:
@@ -129,7 +129,7 @@ icon: jianli
> 2017-05~2018-06 淘宝 Java 后端开发工程师
>
> - **项目描述** : 简单描述项目是做什么的。
-> - **技术栈** :用了什么技术(如 Spring Boot + MySQL + Redis + Mybatis-plus + Spring Security + Oauth2)
+> - **技术栈**:用了什么技术(如 Spring Boot + MySQL + Redis + Mybatis-plus + Spring Security + Oauth2)
> - **工作内容/个人职责** : 简单描述自己做了什么,解决了什么问题,带来了什么实质性的改善。突出自己的能力,不要过于平淡的叙述。
> - **个人收获(可选)** : 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用。通常是可以不用写个人收获的,因为你在个人职责介绍中写的东西已经表明了自己的主要收获。
> - **项目成果(可选)** :简单描述这个项目取得了什么成绩。
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index b222dcdf110..0fb6e5be442 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -28,8 +28,8 @@ icon: path
你会发现大厂面试你会用到,以后工作之后你也会用到。我分别列举 2 个例子吧!
-- **面试中** :像字节、腾讯这些大厂的技术面试以及几乎所有公司的笔试都会考操作系统相关的问题。
-- **工作中** :在实际使用缓存的时候,你会发现在操作系统中可以找到很多缓存思想的影子。比如 CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。再比如操作系统在页表方案基础之上引入了快表来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)。
+- **面试中**:像字节、腾讯这些大厂的技术面试以及几乎所有公司的笔试都会考操作系统相关的问题。
+- **工作中**:在实际使用缓存的时候,你会发现在操作系统中可以找到很多缓存思想的影子。比如 CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。再比如操作系统在页表方案基础之上引入了快表来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)。
**如何求职为导向学习呢?** 简答来说就是:根据招聘要求整理一份目标岗位的技能清单,然后按照技能清单去学习和提升。
@@ -60,13 +60,13 @@ icon: path
下面是常见的获取招聘信息的渠道:
-- **目标企业的官网/公众号** :最及时最权威的获取招聘信息的途径。
-- **招聘网站** :[BOSS 直聘](https://www.zhipin.com/)、[智联招聘](https://www.zhaopin.com/)、[拉勾招聘](https://www.lagou.com/)......。
-- **牛客网** :每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址: 。
-- **超级简历** :超级简历目前整合了各大企业的校园招聘入口,地址:
-- **认识的朋友** :如果你有认识的朋友在目标企业工作的话,你也可以找他们了解招聘信息,并且可以让他们帮你内推。
-- **宣讲会** :宣讲会也是一个不错的途径,不过,好的企业通常只会去比较好的学校,可以留意一下意向公司的宣讲会安排或者直接去到一所比较好的学校参加宣讲会。像我当时校招就去参加了几场宣讲会。不过,我是在荆州上学,那边没什么比较好的学校,一般没有公司去开宣讲会。所以,我当时是直接跑到武汉来了,参加了武汉理工大学以及华中科技大学的几场宣讲会。总体感觉还是很不错的!
-- **其他** :校园就业信息网、学校论坛、班级 or 年级 QQ 群。
+- **目标企业的官网/公众号**:最及时最权威的获取招聘信息的途径。
+- **招聘网站**:[BOSS 直聘](https://www.zhipin.com/)、[智联招聘](https://www.zhaopin.com/)、[拉勾招聘](https://www.lagou.com/)......。
+- **牛客网**:每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址: 。
+- **超级简历**:超级简历目前整合了各大企业的校园招聘入口,地址:
+- **认识的朋友**:如果你有认识的朋友在目标企业工作的话,你也可以找他们了解招聘信息,并且可以让他们帮你内推。
+- **宣讲会**:宣讲会也是一个不错的途径,不过,好的企业通常只会去比较好的学校,可以留意一下意向公司的宣讲会安排或者直接去到一所比较好的学校参加宣讲会。像我当时校招就去参加了几场宣讲会。不过,我是在荆州上学,那边没什么比较好的学校,一般没有公司去开宣讲会。所以,我当时是直接跑到武汉来了,参加了武汉理工大学以及华中科技大学的几场宣讲会。总体感觉还是很不错的!
+- **其他**:校园就业信息网、学校论坛、班级 or 年级 QQ 群。
校招的话,建议以官网为准,有宣讲会、靠谱一点的内推的话更好。社招的话,可以多留意一下各大招聘网站比如 BOSS 直聘、拉勾上的职位信息,也可以找被熟人内推,获得面试机会的概率更大一些,进度一般也更快一些。
@@ -137,19 +137,19 @@ icon: path
- Java 并发
- JVM
-**计算机基础** :
+**计算机基础**:
- 算法
- 数据结构
- 计算机网络
- 操作系统
-**数据库** :
+**数据库**:
- MySQL
- Redis
-**常用框架** :
+**常用框架**:
- Spring
- SpringBoot
@@ -165,13 +165,13 @@ icon: path
- 分布式事务
- 分布式 ID
-**高并发** :
+**高并发**:
- 消息队列
- 读写分离&分库分表
- 负载均衡
-**高可用** :
+**高可用**:
- 限流
- 降级
diff --git a/docs/java/basis/java-basic-questions-01.md b/docs/java/basis/java-basic-questions-01.md
index 5f7ffda88b0..0d580b6479e 100644
--- a/docs/java/basis/java-basic-questions-01.md
+++ b/docs/java/basis/java-basic-questions-01.md
@@ -27,7 +27,7 @@ head:
7. 支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);
8. 编译与解释并存;
-> **🐛 修正(参见:[issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))** :C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
+> **🐛 修正(参见:[issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))**:C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
🌈 拓展一下:
@@ -61,7 +61,7 @@ JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
-**Java 程序从源代码到运行的过程如下图所示** :
+**Java 程序从源代码到运行的过程如下图所示**:
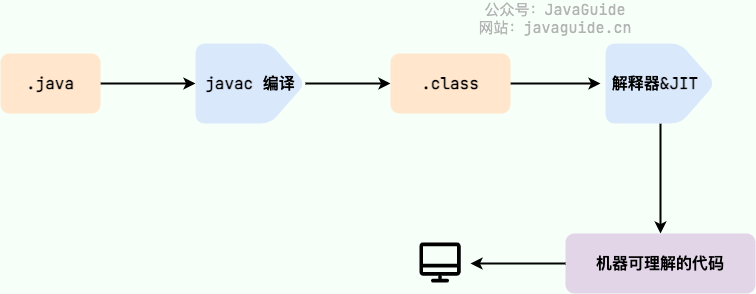
@@ -91,8 +91,8 @@ AOT 可以提前编译节省启动时间,那为什么不全部使用这种编
我们可以将高级编程语言按照程序的执行方式分为两种:
-- **编译型** :[编译型语言](https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E8%AA%9E%E8%A8%80) 会通过[编译器](https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E5%99%A8)将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
-- **解释型** :[解释型语言](https://zh.wikipedia.org/wiki/%E7%9B%B4%E8%AD%AF%E8%AA%9E%E8%A8%80)会通过[解释器](https://zh.wikipedia.org/wiki/直譯器)一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
+- **编译型**:[编译型语言](https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E8%AA%9E%E8%A8%80) 会通过[编译器](https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E5%99%A8)将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
+- **解释型**:[解释型语言](https://zh.wikipedia.org/wiki/%E7%9B%B4%E8%AD%AF%E8%AA%9E%E8%A8%80)会通过[解释器](https://zh.wikipedia.org/wiki/直譯器)一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
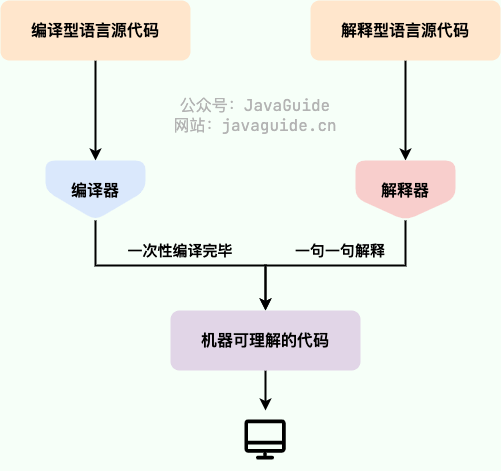
@@ -122,11 +122,11 @@ AOT 可以提前编译节省启动时间,那为什么不全部使用这种编
最后,简单总结一下 Oracle JDK 和 OpenJDK 的区别:
-1. **是否开源** :OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是基于 OpenJDK 实现的,并不是完全开源的(个人观点:众所周知,JDK 原来是 SUN 公司开发的,后来 SUN 公司又卖给了 Oracle 公司,Oracle 公司以 Oracle 数据库而著名,而 Oracle 数据库又是闭源的,这个时候 Oracle 公司就不想完全开源了,但是原来的 SUN 公司又把 JDK 给开源了,如果这个时候 Oracle 收购回来之后就把他给闭源,必然会引起很多 Java 开发者的不满,导致大家对 Java 失去信心,那 Oracle 公司收购回来不就把 Java 烂在手里了吗!然后,Oracle 公司就想了个骚操作,这样吧,我把一部分核心代码开源出来给你们玩,并且我要和你们自己搞的 JDK 区分下,你们叫 OpenJDK,我叫 Oracle JDK,我发布我的,你们继续玩你们的,要是你们搞出来什么好玩的东西,我后续发布 Oracle JDK 也会拿来用一下,一举两得!)OpenJDK 开源项目:[https://github.com/openjdk/jdk](https://github.com/openjdk/jdk) 。
-2. **是否免费** :Oracle JDK 会提供免费版本,但一般有时间限制。JDK17 之后的版本可以免费分发和商用,但是仅有 3 年时间,3 年后无法免费商用。不过,JDK8u221 之前只要不升级可以无限期免费。OpenJDK 是完全免费的。
-3. **功能性** :Oracle JDK 在 OpenJDK 的基础上添加了一些特有的功能和工具,比如 Java Flight Recorder(JFR,一种监控工具)、Java Mission Control(JMC,一种监控工具)等工具。不过,在 Java 11 之后,OracleJDK 和 OpenJDK 的功能基本一致,之前 OracleJDK 中的私有组件大多数也已经被捐赠给开源组织。
-4. **稳定性** :OpenJDK 不提供 LTS 服务,而 OracleJDK 大概每三年都会推出一个 LTS 版进行长期支持。不过,很多公司都基于 OpenJDK 提供了对应的和 OracleJDK 周期相同的 LTS 版。因此,两者稳定性其实也是差不多的。
-5. **协议** :Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。
+1. **是否开源**:OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是基于 OpenJDK 实现的,并不是完全开源的(个人观点:众所周知,JDK 原来是 SUN 公司开发的,后来 SUN 公司又卖给了 Oracle 公司,Oracle 公司以 Oracle 数据库而著名,而 Oracle 数据库又是闭源的,这个时候 Oracle 公司就不想完全开源了,但是原来的 SUN 公司又把 JDK 给开源了,如果这个时候 Oracle 收购回来之后就把他给闭源,必然会引起很多 Java 开发者的不满,导致大家对 Java 失去信心,那 Oracle 公司收购回来不就把 Java 烂在手里了吗!然后,Oracle 公司就想了个骚操作,这样吧,我把一部分核心代码开源出来给你们玩,并且我要和你们自己搞的 JDK 区分下,你们叫 OpenJDK,我叫 Oracle JDK,我发布我的,你们继续玩你们的,要是你们搞出来什么好玩的东西,我后续发布 Oracle JDK 也会拿来用一下,一举两得!)OpenJDK 开源项目:[https://github.com/openjdk/jdk](https://github.com/openjdk/jdk) 。
+2. **是否免费**:Oracle JDK 会提供免费版本,但一般有时间限制。JDK17 之后的版本可以免费分发和商用,但是仅有 3 年时间,3 年后无法免费商用。不过,JDK8u221 之前只要不升级可以无限期免费。OpenJDK 是完全免费的。
+3. **功能性**:Oracle JDK 在 OpenJDK 的基础上添加了一些特有的功能和工具,比如 Java Flight Recorder(JFR,一种监控工具)、Java Mission Control(JMC,一种监控工具)等工具。不过,在 Java 11 之后,OracleJDK 和 OpenJDK 的功能基本一致,之前 OracleJDK 中的私有组件大多数也已经被捐赠给开源组织。
+4. **稳定性**:OpenJDK 不提供 LTS 服务,而 OracleJDK 大概每三年都会推出一个 LTS 版进行长期支持。不过,很多公司都基于 OpenJDK 提供了对应的和 OracleJDK 周期相同的 LTS 版。因此,两者稳定性其实也是差不多的。
+5. **协议**:Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。
> 既然 Oracle JDK 这么好,那为什么还要有 OpenJDK?
>
@@ -173,11 +173,11 @@ Java 中的注释有三种:

-1. **单行注释** :通常用于解释方法内某单行代码的作用。
+1. **单行注释**:通常用于解释方法内某单行代码的作用。
-2. **多行注释** :通常用于解释一段代码的作用。
+2. **多行注释**:通常用于解释一段代码的作用。
-3. **文档注释** :通常用于生成 Java 开发文档。
+3. **文档注释**:通常用于生成 Java 开发文档。
用的比较多的还是单行注释和文档注释,多行注释在实际开发中使用的相对较少。
@@ -236,7 +236,7 @@ Java 中的注释有三种:
> - 在类,方法和变量修饰符中,从 JDK8 开始引入了默认方法,可以使用 `default` 关键字来定义一个方法的默认实现。
> - 在访问控制中,如果一个方法前没有任何修饰符,则默认会有一个修饰符 `default`,但是这个修饰符加上了就会报错。
-⚠️ 注意 :虽然 `true`, `false`, 和 `null` 看起来像关键字但实际上他们是字面值,同时你也不可以作为标识符来使用。
+⚠️ 注意:虽然 `true`, `false`, 和 `null` 看起来像关键字但实际上他们是字面值,同时你也不可以作为标识符来使用。
官方文档:[https://docs.oracle.com/javase/tutorial/java/nutsandbolts/\_keywords.html](https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html)
@@ -256,7 +256,7 @@ Java 中的注释有三种:
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
+ // ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
@@ -285,7 +285,7 @@ Java 中有三种移位运算符:
也就是说:`x<<42`等同于`x<<10`,`x>>42`等同于`x>>10`,`x >>>42`等同于`x >>> 10`。
-**左移运算符代码示例** :
+**左移运算符代码示例**:
```java
int i = -1;
@@ -322,13 +322,13 @@ System.out.println("左移 10 位后的数据对应的二进制字符 " + Intege
在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词:
-1. `continue` :指跳出当前的这一次循环,继续下一次循环。
-2. `break` :指跳出整个循环体,继续执行循环下面的语句。
+1. `continue`:指跳出当前的这一次循环,继续下一次循环。
+2. `break`:指跳出整个循环体,继续执行循环下面的语句。
`return` 用于跳出所在方法,结束该方法的运行。return 一般有两种用法:
-1. `return;` :直接使用 return 结束方法执行,用于没有返回值函数的方法
-2. `return value;` :return 一个特定值,用于有返回值函数的方法
+1. `return;`:直接使用 return 结束方法执行,用于没有返回值函数的方法
+2. `return value;`:return 一个特定值,用于有返回值函数的方法
思考一下:下列语句的运行结果是什么?
@@ -412,15 +412,15 @@ Java 中有 8 种基本数据类型,分别为:

-- **用途** :除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
-- **存储方式** :基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 `static` 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
-- **占用空间** :相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
-- **默认值** :成员变量包装类型不赋值就是 `null` ,而基本类型有默认值且不是 `null`。
-- **比较方式** :对于基本数据类型来说,`==` 比较的是值。对于包装数据类型来说,`==` 比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用 `equals()` 方法。
+- **用途**:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
+- **存储方式**:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 `static` 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
+- **占用空间**:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
+- **默认值**:成员变量包装类型不赋值就是 `null` ,而基本类型有默认值且不是 `null`。
+- **比较方式**:对于基本数据类型来说,`==` 比较的是值。对于包装数据类型来说,`==` 比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用 `equals()` 方法。
**为什么说是几乎所有对象实例都存在于堆中呢?** 这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
-⚠️ 注意 :**基本数据类型存放在栈中是一个常见的误区!** 基本数据类型的成员变量如果没有被 `static` 修饰的话(不建议这么使用,应该要使用基本数据类型对应的包装类型),就存放在堆中。
+⚠️ 注意:**基本数据类型存放在栈中是一个常见的误区!** 基本数据类型的成员变量如果没有被 `static` 修饰的话(不建议这么使用,应该要使用基本数据类型对应的包装类型),就存放在堆中。
```java
class BasicTypeVar{
@@ -652,10 +652,10 @@ System.out.println(l + 1 == Long.MIN_VALUE); // true

-- **语法形式** :从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 `public`,`private`,`static` 等修饰符所修饰,而局部变量不能被访问控制修饰符及 `static` 所修饰;但是,成员变量和局部变量都能被 `final` 所修饰。
-- **存储方式** :从变量在内存中的存储方式来看,如果成员变量是使用 `static` 修饰的,那么这个成员变量是属于类的,如果没有使用 `static` 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
-- **生存时间** :从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
-- **默认值** :从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被 `final` 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
+- **语法形式**:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 `public`,`private`,`static` 等修饰符所修饰,而局部变量不能被访问控制修饰符及 `static` 所修饰;但是,成员变量和局部变量都能被 `final` 所修饰。
+- **存储方式**:从变量在内存中的存储方式来看,如果成员变量是使用 `static` 修饰的,那么这个成员变量是属于类的,如果没有使用 `static` 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
+- **生存时间**:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
+- **默认值**:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被 `final` 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
成员变量与局部变量代码示例:
@@ -719,7 +719,7 @@ public class ConstantVariableExample {
- **形式** : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符。
- **含义** : 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)。
-- **占内存大小** :字符常量只占 2 个字节; 字符串常量占若干个字节。
+- **占内存大小**:字符常量只占 2 个字节; 字符串常量占若干个字节。
⚠️ 注意 `char` 在 Java 中占两个字节。
diff --git a/docs/java/basis/java-basic-questions-02.md b/docs/java/basis/java-basic-questions-02.md
index 260e07fe17b..71c6016e361 100644
--- a/docs/java/basis/java-basic-questions-02.md
+++ b/docs/java/basis/java-basic-questions-02.md
@@ -23,11 +23,11 @@ head:
另外,面向对象开发的程序一般更易维护、易复用、易扩展。
-相关 issue : [面向过程 :面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431) 。
+相关 issue : [面向过程:面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431) 。
下面是一个求圆的面积和周长的示例,简单分别展示了面向对象和面向过程两种不同的解决方案。
-**面向对象** :
+**面向对象**:
```java
public class Circle {
@@ -62,7 +62,7 @@ public class Circle {
我们定义了一个 `Circle` 类来表示圆,该类包含了圆的半径属性和计算面积、周长的方法。
-**面向过程** :
+**面向过程**:
```java
public class Main {
@@ -198,13 +198,13 @@ public class Student {
### 接口和抽象类有什么共同点和区别?
-**共同点** :
+**共同点**:
- 都不能被实例化。
- 都可以包含抽象方法。
- 都可以有默认实现的方法(Java 8 可以用 `default` 关键字在接口中定义默认方法)。
-**区别** :
+**区别**:
- 接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
- 一个类只能继承一个类,但是可以实现多个接口。
@@ -215,7 +215,7 @@ public class Student {
关于深拷贝和浅拷贝区别,我这里先给结论:
- **浅拷贝**:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
-- **深拷贝** :深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
+- **深拷贝**:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
上面的结论没有完全理解的话也没关系,我们来看一个具体的案例!
@@ -254,7 +254,7 @@ public class Person implements Cloneable {
}
```
-测试 :
+测试:
```java
Person person1 = new Person(new Address("武汉"));
@@ -282,7 +282,7 @@ public Person clone() {
}
```
-测试 :
+测试:
```java
Person person1 = new Person(new Address("武汉"));
@@ -373,8 +373,8 @@ public boolean equals(Object obj) {
`equals()` 方法存在两种使用情况:
-- **类没有重写 `equals()`方法** :通过`equals()`比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 `Object`类`equals()`方法。
-- **类重写了 `equals()`方法** :一般我们都重写 `equals()`方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
+- **类没有重写 `equals()`方法**:通过`equals()`比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 `Object`类`equals()`方法。
+- **类重写了 `equals()`方法**:一般我们都重写 `equals()`方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
举个例子(这里只是为了举例。实际上,你按照下面这种写法的话,像 IDEA 这种比较智能的 IDE 都会提示你将 `==` 换成 `equals()` ):
@@ -427,7 +427,7 @@ public boolean equals(Object anObject) {
`hashCode()` 定义在 JDK 的 `Object` 类中,这就意味着 Java 中的任何类都包含有 `hashCode()` 函数。另外需要注意的是:`Object` 的 `hashCode()` 方法是本地方法,也就是用 C 语言或 C++ 实现的。
-> ⚠️ 注意 :该方法在 **Oracle OpenJDK8** 中默认是 "使用线程局部状态来实现 Marsaglia's xor-shift 随机数生成", 并不是 "地址" 或者 "地址转换而来", 不同 JDK/VM 可能不同在 **Oracle OpenJDK8** 中有六种生成方式 (其中第五种是返回地址), 通过添加 VM 参数: -XX:hashCode=4 启用第五种。参考源码:
+> ⚠️ 注意:该方法在 **Oracle OpenJDK8** 中默认是 "使用线程局部状态来实现 Marsaglia's xor-shift 随机数生成", 并不是 "地址" 或者 "地址转换而来", 不同 JDK/VM 可能不同在 **Oracle OpenJDK8** 中有六种生成方式 (其中第五种是返回地址), 通过添加 VM 参数: -XX:hashCode=4 启用第五种。参考源码:
>
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp(1127行)
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp(537行开始)
@@ -462,7 +462,7 @@ public native int hashCode();
因为 `hashCode()` 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 `hashCode` )。
-总结下来就是 :
+总结下来就是:
- 如果两个对象的`hashCode` 值相等,那这两个对象不一定相等(哈希碰撞)。
- 如果两个对象的`hashCode` 值相等并且`equals()`方法也返回 `true`,我们才认为这两个对象相等。
@@ -476,9 +476,9 @@ public native int hashCode();
如果重写 `equals()` 时没有重写 `hashCode()` 方法的话就可能会导致 `equals` 方法判断是相等的两个对象,`hashCode` 值却不相等。
-**思考** :重写 `equals()` 时没有重写 `hashCode()` 方法的话,使用 `HashMap` 可能会出现什么问题。
+**思考**:重写 `equals()` 时没有重写 `hashCode()` 方法的话,使用 `HashMap` 可能会出现什么问题。
-**总结** :
+**总结**:
- `equals` 方法判断两个对象是相等的,那这两个对象的 `hashCode` 值也要相等。
- 两个对象有相同的 `hashCode` 值,他们也不一定是相等的(哈希碰撞)。
@@ -536,7 +536,7 @@ public final class String implements java.io.Serializable, Comparable, C
}
```
-> 🐛 修正 :我们知道被 `final` 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,`final` 关键字修饰的数组保存字符串并不是 `String` 不可变的根本原因,因为这个数组保存的字符串是可变的(`final` 修饰引用类型变量的情况)。
+> 🐛 修正:我们知道被 `final` 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,`final` 关键字修饰的数组保存字符串并不是 `String` 不可变的根本原因,因为这个数组保存的字符串是可变的(`final` 修饰引用类型变量的情况)。
>
> `String` 真正不可变有下面几点原因:
>
@@ -717,7 +717,7 @@ System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
```
-> **注意** :比较 String 字符串的值是否相等,可以使用 `equals()` 方法。 `String` 中的 `equals` 方法是被重写过的。 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是字符串的值是否相等。如果你使用 `==` 比较两个字符串是否相等的话,IDEA 还是提示你使用 `equals()` 方法替换。
+> **注意**:比较 String 字符串的值是否相等,可以使用 `equals()` 方法。 `String` 中的 `equals` 方法是被重写过的。 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是字符串的值是否相等。如果你使用 `==` 比较两个字符串是否相等的话,IDEA 还是提示你使用 `equals()` 方法替换。

diff --git a/docs/java/basis/java-basic-questions-03.md b/docs/java/basis/java-basic-questions-03.md
index 6fae3189679..f21aa72d589 100644
--- a/docs/java/basis/java-basic-questions-03.md
+++ b/docs/java/basis/java-basic-questions-03.md
@@ -14,7 +14,7 @@ head:
## 异常
-**Java 异常类层次结构图概览** :
+**Java 异常类层次结构图概览**:
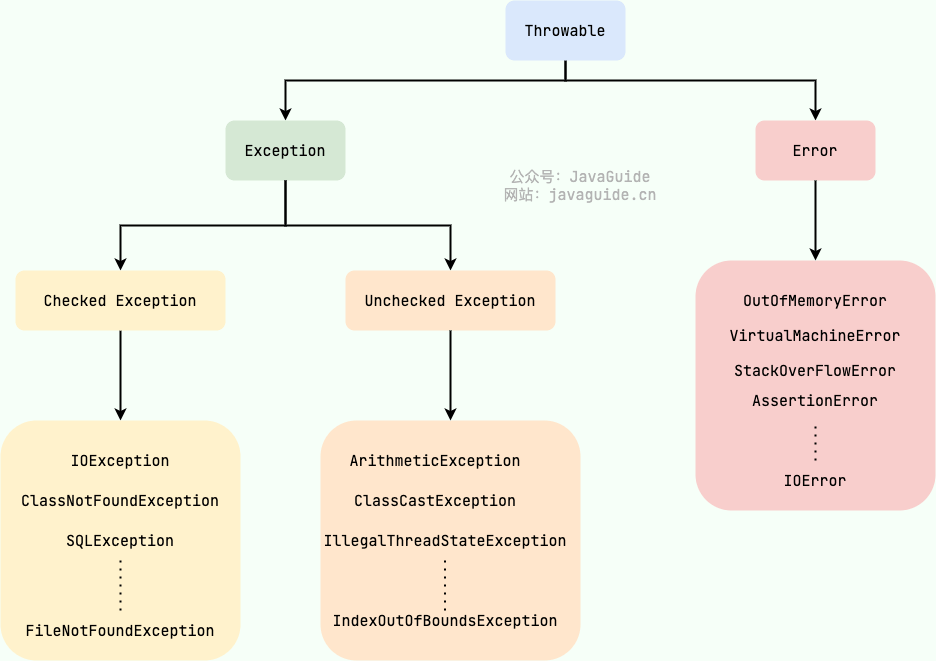
@@ -23,7 +23,7 @@ head:
在 Java 中,所有的异常都有一个共同的祖先 `java.lang` 包中的 `Throwable` 类。`Throwable` 类有两个重要的子类:
- **`Exception`** :程序本身可以处理的异常,可以通过 `catch` 来进行捕获。`Exception` 又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。
-- **`Error`** :`Error` 属于程序无法处理的错误 ,~~我们没办法通过 `catch` 来进行捕获~~不建议通过`catch`捕获 。例如 Java 虚拟机运行错误(`Virtual MachineError`)、虚拟机内存不够错误(`OutOfMemoryError`)、类定义错误(`NoClassDefFoundError`)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
+- **`Error`**:`Error` 属于程序无法处理的错误 ,~~我们没办法通过 `catch` 来进行捕获~~不建议通过`catch`捕获 。例如 Java 虚拟机运行错误(`Virtual MachineError`)、虚拟机内存不够错误(`OutOfMemoryError`)、类定义错误(`NoClassDefFoundError`)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
### Checked Exception 和 Unchecked Exception 有什么区别?
@@ -60,9 +60,9 @@ head:
### try-catch-finally 如何使用?
-- `try`块 :用于捕获异常。其后可接零个或多个 `catch` 块,如果没有 `catch` 块,则必须跟一个 `finally` 块。
-- `catch`块 :用于处理 try 捕获到的异常。
-- `finally` 块 :无论是否捕获或处理异常,`finally` 块里的语句都会被执行。当在 `try` 块或 `catch` 块中遇到 `return` 语句时,`finally` 语句块将在方法返回之前被执行。
+- `try`块:用于捕获异常。其后可接零个或多个 `catch` 块,如果没有 `catch` 块,则必须跟一个 `finally` 块。
+- `catch`块:用于处理 try 捕获到的异常。
+- `finally` 块:无论是否捕获或处理异常,`finally` 块里的语句都会被执行。当在 `try` 块或 `catch` 块中遇到 `return` 语句时,`finally` 语句块将在方法返回之前被执行。
代码示例:
@@ -262,7 +262,7 @@ public class Generic{
Generic genericInteger = new Generic(123456);
```
-**2.泛型接口** :
+**2.泛型接口**:
```java
public interface Generator {
@@ -292,7 +292,7 @@ class GeneratorImpl implements Generator{
}
```
-**3.泛型方法** :
+**3.泛型方法**:
```java
public static < E > void printArray( E[] inputArray )
@@ -400,8 +400,8 @@ JDK 提供了很多内置的注解(比如 `@Override`、`@Deprecated`),同
注解只有被解析之后才会生效,常见的解析方法有两种:
-- **编译期直接扫描** :编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用`@Override` 注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。
-- **运行期通过反射处理** :像框架中自带的注解(比如 Spring 框架的 `@Value`、`@Component`)都是通过反射来进行处理的。
+- **编译期直接扫描**:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用`@Override` 注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。
+- **运行期通过反射处理**:像框架中自带的注解(比如 Spring 框架的 `@Value`、`@Component`)都是通过反射来进行处理的。
## SPI
@@ -510,8 +510,8 @@ JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存
我们很少或者说几乎不会直接使用 JDK 自带的序列化方式,主要原因有下面这些原因:
- **不支持跨语言调用** : 如果调用的是其他语言开发的服务的时候就不支持了。
-- **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
-- **存在安全问题** :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:[应用安全:JAVA 反序列化漏洞之殇](https://cryin.github.io/blog/secure-development-java-deserialization-vulnerability/) 。
+- **性能差**:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
+- **存在安全问题**:序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:[应用安全:JAVA 反序列化漏洞之殇](https://cryin.github.io/blog/secure-development-java-deserialization-vulnerability/) 。
## I/O
diff --git a/docs/java/basis/java-keyword-summary.md b/docs/java/basis/java-keyword-summary.md
index 543f20d6498..34a05f66197 100644
--- a/docs/java/basis/java-keyword-summary.md
+++ b/docs/java/basis/java-keyword-summary.md
@@ -249,7 +249,7 @@ bar.method2();
不同点:静态代码块在非静态代码块之前执行(静态代码块 -> 非静态代码块 -> 构造方法)。静态代码块只在第一次 new 执行一次,之后不再执行,而非静态代码块在每 new 一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
-> **🐛 修正(参见:[issue #677](https://github.com/Snailclimb/JavaGuide/issues/677))** :静态代码块可能在第一次 new 对象的时候执行,但不一定只在第一次 new 的时候执行。比如通过 `Class.forName("ClassDemo")`创建 Class 对象的时候也会执行,即 new 或者 `Class.forName("ClassDemo")` 都会执行静态代码块。
+> **🐛 修正(参见:[issue #677](https://github.com/Snailclimb/JavaGuide/issues/677))**:静态代码块可能在第一次 new 对象的时候执行,但不一定只在第一次 new 的时候执行。比如通过 `Class.forName("ClassDemo")`创建 Class 对象的时候也会执行,即 new 或者 `Class.forName("ClassDemo")` 都会执行静态代码块。
> 一般情况下,如果有些代码比如一些项目最常用的变量或对象必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的。如果我们想要设计不需要创建对象就可以调用类中的方法,例如:`Arrays` 类,`Character` 类,`String` 类等,就需要使用静态方法, 两者的区别是 静态代码块是自动执行的而静态方法是被调用的时候才执行的.
Example:
diff --git a/docs/java/basis/proxy.md b/docs/java/basis/proxy.md
index f6d794de3ca..7ca450cfcdf 100644
--- a/docs/java/basis/proxy.md
+++ b/docs/java/basis/proxy.md
@@ -237,7 +237,7 @@ public class JdkProxyFactory {
}
```
-`getProxy()` :主要通过`Proxy.newProxyInstance()`方法获取某个类的代理对象
+`getProxy()`:主要通过`Proxy.newProxyInstance()`方法获取某个类的代理对象
**5.实际使用**
@@ -392,8 +392,8 @@ after method send
## 4. 静态代理和动态代理的对比
-1. **灵活性** :动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
-2. **JVM 层面** :静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
+1. **灵活性**:动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
+2. **JVM 层面**:静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
## 5. 总结
diff --git a/docs/java/basis/reflection.md b/docs/java/basis/reflection.md
index 23e5a179984..61161c59e6b 100644
--- a/docs/java/basis/reflection.md
+++ b/docs/java/basis/reflection.md
@@ -53,9 +53,9 @@ public class DebugInvocationHandler implements InvocationHandler {
## 谈谈反射机制的优缺点
-**优点** :可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
+**优点**:可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
-**缺点** :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。相关阅读:[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow)
+**缺点**:让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。相关阅读:[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow)
## 反射实战
diff --git a/docs/java/basis/serialization.md b/docs/java/basis/serialization.md
index b60d424dcb7..f8a8a491ffc 100644
--- a/docs/java/basis/serialization.md
+++ b/docs/java/basis/serialization.md
@@ -108,8 +108,8 @@ public class RpcRequest implements Serializable {
我们很少或者说几乎不会直接使用 JDK 自带的序列化方式,主要原因有下面这些原因:
- **不支持跨语言调用** : 如果调用的是其他语言开发的服务的时候就不支持了。
-- **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
-- **存在安全问题** :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:[应用安全:JAVA 反序列化漏洞之殇 - Cryin](https://cryin.github.io/blog/secure-development-java-deserialization-vulnerability/)、[Java 反序列化安全漏洞怎么回事? - Monica](https://www.zhihu.com/question/37562657/answer/1916596031)。
+- **性能差**:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
+- **存在安全问题**:序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:[应用安全:JAVA 反序列化漏洞之殇 - Cryin](https://cryin.github.io/blog/secure-development-java-deserialization-vulnerability/)、[Java 反序列化安全漏洞怎么回事? - Monica](https://www.zhihu.com/question/37562657/answer/1916596031)。
### Kryo
diff --git a/docs/java/basis/why-there-only-value-passing-in-java.md b/docs/java/basis/why-there-only-value-passing-in-java.md
index 8fc156e6141..0be87d092f9 100644
--- a/docs/java/basis/why-there-only-value-passing-in-java.md
+++ b/docs/java/basis/why-there-only-value-passing-in-java.md
@@ -14,8 +14,8 @@ tag:
方法的定义可能会用到 **参数**(有参的方法),参数在程序语言中分为:
-- **实参(实际参数,Arguments)** :用于传递给函数/方法的参数,必须有确定的值。
-- **形参(形式参数,Parameters)** :用于定义函数/方法,接收实参,不需要有确定的值。
+- **实参(实际参数,Arguments)**:用于传递给函数/方法的参数,必须有确定的值。
+- **形参(形式参数,Parameters)**:用于定义函数/方法,接收实参,不需要有确定的值。
```java
String hello = "Hello!";
@@ -31,8 +31,8 @@ void sayHello(String str) {
程序设计语言将实参传递给方法(或函数)的方式分为两种:
-- **值传递** :方法接收的是实参值的拷贝,会创建副本。
-- **引用传递** :方法接收的直接是实参所引用的对象在堆中的地址,不会创建副本,对形参的修改将影响到实参。
+- **值传递**:方法接收的是实参值的拷贝,会创建副本。
+- **引用传递**:方法接收的直接是实参所引用的对象在堆中的地址,不会创建副本,对形参的修改将影响到实参。
很多程序设计语言(比如 C++、 Pascal )提供了两种参数传递的方式,不过,在 Java 中只有值传递。
@@ -116,7 +116,7 @@ num2 = 20
为了更强有力地反驳 Java 对引用类型的参数采用的不是引用传递,我们再来看下面这个案例!
-### 案例 3 :传递引用类型参数 2
+### 案例 3:传递引用类型参数 2
```java
public class Person {
@@ -204,7 +204,7 @@ invoke after: 11
## 总结
-Java 中将实参传递给方法(或函数)的方式是 **值传递** :
+Java 中将实参传递给方法(或函数)的方式是 **值传递**:
- 如果参数是基本类型的话,很简单,传递的就是基本类型的字面量值的拷贝,会创建副本。
- 如果参数是引用类型,传递的就是实参所引用的对象在堆中地址值的拷贝,同样也会创建副本。
diff --git a/docs/java/collection/arraylist-source-code.md b/docs/java/collection/arraylist-source-code.md
index cc1e2e5e9a2..bd5d2d294f0 100644
--- a/docs/java/collection/arraylist-source-code.md
+++ b/docs/java/collection/arraylist-source-code.md
@@ -602,7 +602,7 @@ public class ArrayList extends AbstractList
```
-细心的同学一定会发现 :**以无参数构造方法创建 `ArrayList` 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
+细心的同学一定会发现:**以无参数构造方法创建 `ArrayList` 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
> 补充:JDK6 new 无参构造的 `ArrayList` 对象时,直接创建了长度是 10 的 `Object[]` 数组 elementData 。
@@ -625,7 +625,7 @@ public class ArrayList extends AbstractList
}
```
-> **注意** :JDK11 移除了 `ensureCapacityInternal()` 和 `ensureExplicitCapacity()` 方法
+> **注意**:JDK11 移除了 `ensureCapacityInternal()` 和 `ensureExplicitCapacity()` 方法
#### 再来看看 `ensureCapacityInternal()` 方法
@@ -701,11 +701,11 @@ public class ArrayList extends AbstractList
}
```
-**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)!** 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
+**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)!** 奇偶不同,比如:10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
> ">>"(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
-**我们再来通过例子探究一下`grow()` 方法 :**
+**我们再来通过例子探究一下`grow()` 方法:**
- 当 add 第 1 个元素时,oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会进入 `hugeCapacity` 方法。数组容量为 10,add 方法中 return true,size 增为 1。
- 当 add 第 11 个元素进入 grow 方法时,newCapacity 为 15,比 minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
diff --git a/docs/java/collection/hashmap-source-code.md b/docs/java/collection/hashmap-source-code.md
index 47d77296005..211058378a3 100644
--- a/docs/java/collection/hashmap-source-code.md
+++ b/docs/java/collection/hashmap-source-code.md
@@ -35,7 +35,7 @@ JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
+ // ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
diff --git a/docs/java/collection/java-collection-precautions-for-use.md b/docs/java/collection/java-collection-precautions-for-use.md
index b6bb9a8935e..380f63ce2bb 100644
--- a/docs/java/collection/java-collection-precautions-for-use.md
+++ b/docs/java/collection/java-collection-precautions-for-use.md
@@ -122,7 +122,7 @@ public static T requireNonNull(T obj) {
这就导致 `Iterator` 莫名其妙地发现自己有元素被 `remove/add` ,然后,它就会抛出一个 `ConcurrentModificationException` 来提示用户发生了并发修改异常。这就是单线程状态下产生的 **fail-fast 机制**。
-> **fail-fast 机制** :多个线程对 fail-fast 集合进行修改的时候,可能会抛出`ConcurrentModificationException`。 即使是单线程下也有可能会出现这种情况,上面已经提到过。
+> **fail-fast 机制**:多个线程对 fail-fast 集合进行修改的时候,可能会抛出`ConcurrentModificationException`。 即使是单线程下也有可能会出现这种情况,上面已经提到过。
>
> 相关阅读:[什么是 fail-fast](https://www.cnblogs.com/54chensongxia/p/12470446.html) 。
diff --git a/docs/java/collection/java-collection-questions-02.md b/docs/java/collection/java-collection-questions-02.md
index e29d656de71..e0e72262c44 100644
--- a/docs/java/collection/java-collection-questions-02.md
+++ b/docs/java/collection/java-collection-questions-02.md
@@ -19,7 +19,7 @@ head:
- **线程是否安全:** `HashMap` 是非线程安全的,`Hashtable` 是线程安全的,因为 `Hashtable` 内部的方法基本都经过`synchronized` 修饰。(如果你要保证线程安全的话就使用 `ConcurrentHashMap` 吧!);
- **效率:** 因为线程安全的问题,`HashMap` 要比 `Hashtable` 效率高一点。另外,`Hashtable` 基本被淘汰,不要在代码中使用它;
- **对 Null key 和 Null value 的支持:** `HashMap` 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出 `NullPointerException`。
-- **初始容量大小和每次扩充容量大小的不同 :** ① 创建时如果不指定容量初始值,`Hashtable` 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。`HashMap` 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 `Hashtable` 会直接使用你给定的大小,而 `HashMap` 会将其扩充为 2 的幂次方大小(`HashMap` 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 `HashMap` 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
+- **初始容量大小和每次扩充容量大小的不同:** ① 创建时如果不指定容量初始值,`Hashtable` 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。`HashMap` 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 `Hashtable` 会直接使用你给定的大小,而 `HashMap` 会将其扩充为 2 的幂次方大小(`HashMap` 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 `HashMap` 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
- **底层数据结构:** JDK1.8 以后的 `HashMap` 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。`Hashtable` 没有这样的机制。
**`HashMap` 中带有初始容量的构造函数:**
@@ -183,7 +183,7 @@ JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
+ // ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
@@ -290,7 +290,7 @@ final void treeifyBin(Node[] tab, int hash) {
[HashMap 的 7 种遍历方式与性能分析!](https://mp.weixin.qq.com/s/zQBN3UvJDhRTKP6SzcZFKw)
-**🐛 修正(参见:[issue#1411](https://github.com/Snailclimb/JavaGuide/issues/1411))** :
+**🐛 修正(参见:[issue#1411](https://github.com/Snailclimb/JavaGuide/issues/1411))**:
这篇文章对于 parallelStream 遍历方式的性能分析有误,先说结论:**存在阻塞时 parallelStream 性能最高, 非阻塞时 parallelStream 性能最低** 。
@@ -332,7 +332,7 @@ Test.parallelStream avgt 5 186345456.667 ± 3210435.590 ns/op
https://www.cnblogs.com/chengxiao/p/6842045.html>
-**JDK1.7 的 ConcurrentHashMap** :
+**JDK1.7 的 ConcurrentHashMap**:
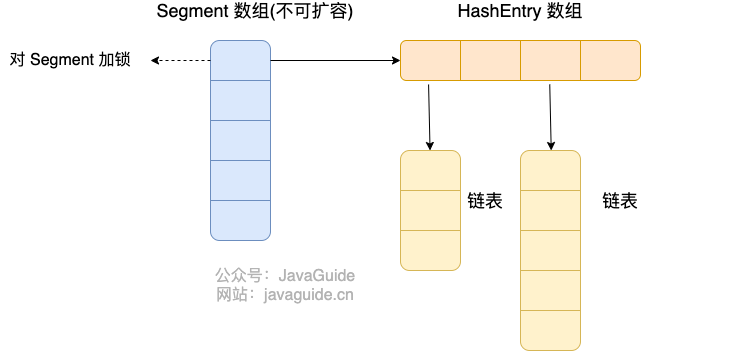
@@ -340,7 +340,7 @@ Test.parallelStream avgt 5 186345456.667 ± 3210435.590 ns/op
`Segment` 数组中的每个元素包含一个 `HashEntry` 数组,每个 `HashEntry` 数组属于链表结构。
-**JDK1.8 的 ConcurrentHashMap** :
+**JDK1.8 的 ConcurrentHashMap**:
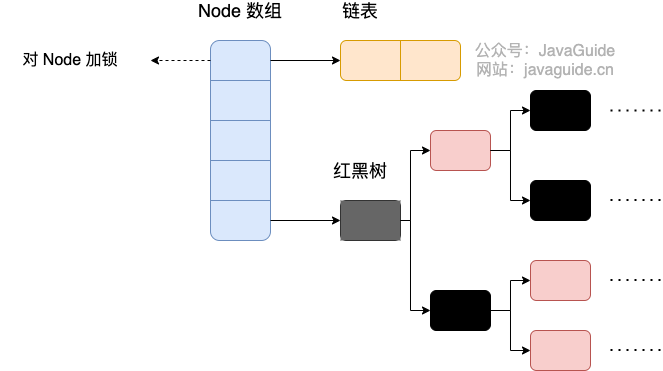
@@ -395,9 +395,9 @@ Java 8 中,锁粒度更细,`synchronized` 只锁定当前链表或红黑二
### JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
-- **线程安全实现方式** :JDK 1.7 采用 `Segment` 分段锁来保证安全, `Segment` 是继承自 `ReentrantLock`。JDK1.8 放弃了 `Segment` 分段锁的设计,采用 `Node + CAS + synchronized` 保证线程安全,锁粒度更细,`synchronized` 只锁定当前链表或红黑二叉树的首节点。
+- **线程安全实现方式**:JDK 1.7 采用 `Segment` 分段锁来保证安全, `Segment` 是继承自 `ReentrantLock`。JDK1.8 放弃了 `Segment` 分段锁的设计,采用 `Node + CAS + synchronized` 保证线程安全,锁粒度更细,`synchronized` 只锁定当前链表或红黑二叉树的首节点。
- **Hash 碰撞解决方法** : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
-- **并发度** :JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
+- **并发度**:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
## Collections 工具类(不重要)
diff --git a/docs/java/concurrent/aqs.md b/docs/java/concurrent/aqs.md
index 135fa2e6e33..e004b872c94 100644
--- a/docs/java/concurrent/aqs.md
+++ b/docs/java/concurrent/aqs.md
@@ -253,7 +253,7 @@ semaphore.release(5);// 释放5个许可
除了 `acquire()` 方法之外,另一个比较常用的与之对应的方法是 `tryAcquire()` 方法,该方法如果获取不到许可就立即返回 false。
-[issue645 补充内容](https://github.com/Snailclimb/JavaGuide/issues/645) :
+[issue645 补充内容](https://github.com/Snailclimb/JavaGuide/issues/645):
> `Semaphore` 与 `CountDownLatch` 一样,也是共享锁的一种实现。它默认构造 AQS 的 `state` 为 `permits`。当执行任务的线程数量超出 `permits`,那么多余的线程将会被放入阻塞队列 `Park`,并自旋判断 `state` 是否大于 0。只有当 `state` 大于 0 的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执行 `release()` 方法,`release()` 方法使得 state 的变量会加 1,那么自旋的线程便会判断成功。
> 如此,每次只有最多不超过 `permits` 数量的线程能自旋成功,便限制了执行任务线程的数量。
@@ -272,12 +272,12 @@ semaphore.release(5);// 释放5个许可
#### 实战
-**CountDownLatch 的两种典型用法** :
+**CountDownLatch 的两种典型用法**:
1. 某一线程在开始运行前等待 n 个线程执行完毕 : 将 `CountDownLatch` 的计数器初始化为 n (`new CountDownLatch(n)`),每当一个任务线程执行完毕,就将计数器减 1 (`countdownlatch.countDown()`),当计数器的值变为 0 时,在 `CountDownLatch 上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
-2. 实现多个线程开始执行任务的最大并行性 :注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 (`new CountDownLatch(1)`),多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 `countDown()` 时,计数器变为 0,多个线程同时被唤醒。
+2. 实现多个线程开始执行任务的最大并行性:注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 (`new CountDownLatch(1)`),多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 `countDown()` 时,计数器变为 0,多个线程同时被唤醒。
-**CountDownLatch 代码示例** :
+**CountDownLatch 代码示例**:
```java
/**
diff --git a/docs/java/concurrent/atomic-classes.md b/docs/java/concurrent/atomic-classes.md
index f95831ad0f7..bcc32153888 100644
--- a/docs/java/concurrent/atomic-classes.md
+++ b/docs/java/concurrent/atomic-classes.md
@@ -23,7 +23,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
- `AtomicInteger`:整型原子类
- `AtomicLong`:长整型原子类
-- `AtomicBoolean` :布尔型原子类
+- `AtomicBoolean`:布尔型原子类
**数组类型**
@@ -31,13 +31,13 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
- `AtomicIntegerArray`:整型数组原子类
- `AtomicLongArray`:长整型数组原子类
-- `AtomicReferenceArray` :引用类型数组原子类
+- `AtomicReferenceArray`:引用类型数组原子类
**引用类型**
- `AtomicReference`:引用类型原子类
- `AtomicMarkableReference`:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题~~。
-- `AtomicStampedReference` :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- `AtomicStampedReference`:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
**🐛 修正(参见:[issue#626](https://github.com/Snailclimb/JavaGuide/issues/626))** : `AtomicMarkableReference` 不能解决 ABA 问题。
@@ -53,7 +53,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
- `AtomicInteger`:整型原子类
- `AtomicLong`:长整型原子类
-- `AtomicBoolean` :布尔型原子类
+- `AtomicBoolean`:布尔型原子类
上面三个类提供的方法几乎相同,所以我们这里以 `AtomicInteger` 为例子来介绍。
@@ -156,11 +156,11 @@ CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则
- `AtomicIntegerArray`:整形数组原子类
- `AtomicLongArray`:长整形数组原子类
-- `AtomicReferenceArray` :引用类型数组原子类
+- `AtomicReferenceArray`:引用类型数组原子类
上面三个类提供的方法几乎相同,所以我们这里以 `AtomicIntegerArray` 为例子来介绍。
-**`AtomicIntegerArray` 类常用方法** :
+**`AtomicIntegerArray` 类常用方法**:
```java
public final int get(int i) //获取 index=i 位置元素的值
@@ -203,7 +203,7 @@ public class AtomicIntegerArrayTest {
- `AtomicReference`:引用类型原子类
- `AtomicStampedReference`:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
-- `AtomicMarkableReference` :原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
+- `AtomicMarkableReference`:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
上面三个类提供的方法几乎相同,所以我们这里以 `AtomicReference` 为例子来介绍。
@@ -386,7 +386,7 @@ currentValue=true, currentMark=true, wCasResult=true
- `AtomicIntegerFieldUpdater`:原子更新整形字段的更新器
- `AtomicLongFieldUpdater`:原子更新长整形字段的更新器
-- `AtomicReferenceFieldUpdater` :原子更新引用类型里的字段的更新器
+- `AtomicReferenceFieldUpdater`:原子更新引用类型里的字段的更新器
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
diff --git a/docs/java/concurrent/completablefuture-intro.md b/docs/java/concurrent/completablefuture-intro.md
index a7f26bb8d5f..c85e3948f6a 100644
--- a/docs/java/concurrent/completablefuture-intro.md
+++ b/docs/java/concurrent/completablefuture-intro.md
@@ -26,11 +26,11 @@ public class CompletableFuture implements Future, CompletionStage {
`Future` 接口有 5 个方法:
-- `boolean cancel(boolean mayInterruptIfRunning)` :尝试取消执行任务。
-- `boolean isCancelled()` :判断任务是否被取消。
-- `boolean isDone()` :判断任务是否已经被执行完成。
-- `get()` :等待任务执行完成并获取运算结果。
-- `get(long timeout, TimeUnit unit)` :多了一个超时时间。
+- `boolean cancel(boolean mayInterruptIfRunning)`:尝试取消执行任务。
+- `boolean isCancelled()`:判断任务是否被取消。
+- `boolean isDone()`:判断任务是否已经被执行完成。
+- `get()`:等待任务执行完成并获取运算结果。
+- `get(long timeout, TimeUnit unit)`:多了一个超时时间。
`CompletionStage` 接口描述了一个异步计算的阶段。很多计算可以分成多个阶段或步骤,此时可以通过它将所有步骤组合起来,形成异步计算的流水线。
diff --git a/docs/java/concurrent/java-concurrent-questions-01.md b/docs/java/concurrent/java-concurrent-questions-01.md
index 7ebfc0bd0f5..d2bfdb1b55a 100644
--- a/docs/java/concurrent/java-concurrent-questions-01.md
+++ b/docs/java/concurrent/java-concurrent-questions-01.md
@@ -108,8 +108,8 @@ public class MultiThread {
## 同步和异步的区别
-- **同步** :发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
-- **异步** :调用在发出之后,不用等待返回结果,该调用直接返回。
+- **同步**:发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
+- **异步**:调用在发出之后,不用等待返回结果,该调用直接返回。
## 为什么要使用多线程?
@@ -133,7 +133,7 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
- NEW: 初始状态,线程被创建出来但没有被调用 `start()` 。
- RUNNABLE: 运行状态,线程被调用了 `start()`等待运行的状态。
-- BLOCKED :阻塞状态,需要等待锁释放。
+- BLOCKED:阻塞状态,需要等待锁释放。
- WAITING:等待状态,表示该线程需要等待其他线程做出一些特定动作(通知或中断)。
- TIME_WAITING:超时等待状态,可以在指定的时间后自行返回而不是像 WAITING 那样一直等待。
- TERMINATED:终止状态,表示该线程已经运行完毕。
@@ -245,9 +245,9 @@ Thread[线程 2,5,main]waiting get resource1
**如何预防死锁?** 破坏死锁的产生的必要条件即可:
-1. **破坏请求与保持条件** :一次性申请所有的资源。
-2. **破坏不剥夺条件** :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
-3. **破坏循环等待条件** :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
+1. **破坏请求与保持条件**:一次性申请所有的资源。
+2. **破坏不剥夺条件**:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
+3. **破坏循环等待条件**:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
**如何避免死锁?**
@@ -293,9 +293,9 @@ Process finished with exit code 0
## sleep() 方法和 wait() 方法对比
-**共同点** :两者都可以暂停线程的执行。
+**共同点**:两者都可以暂停线程的执行。
-**区别** :
+**区别**:
- **`sleep()` 方法没有释放锁,而 `wait()` 方法释放了锁** 。
- `wait()` 通常被用于线程间交互/通信,`sleep()`通常被用于暂停执行。
diff --git a/docs/java/concurrent/java-concurrent-questions-02.md b/docs/java/concurrent/java-concurrent-questions-02.md
index dd6236639d4..2477362b5c1 100644
--- a/docs/java/concurrent/java-concurrent-questions-02.md
+++ b/docs/java/concurrent/java-concurrent-questions-02.md
@@ -48,7 +48,7 @@ public native void fullFence();
面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
-**双重校验锁实现对象单例(线程安全)** :
+**双重校验锁实现对象单例(线程安全)**:
```java
public class Singleton {
@@ -230,7 +230,7 @@ sum.increment();
一般是在数据表中加上一个数据版本号 `version` 字段,表示数据被修改的次数。当数据被修改时,`version` 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 `version` 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 `version` 值相等时才更新,否则重试更新操作,直到更新成功。
-**举一个简单的例子** :假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( `balance` )为 \$100 。
+**举一个简单的例子**:假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( `balance` )为 \$100 。
1. 操作员 A 此时将其读出( `version`=1 ),并从其帐户余额中扣除 $50( $100-\$50 )。
2. 在操作员 A 操作的过程中,操作员 B 也读入此用户信息( `version`=1 ),并从其帐户余额中扣除 $20 ( $100-\$20 )。
@@ -249,13 +249,13 @@ CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
-- **V** :要更新的变量值(Var)
-- **E** :预期值(Expected)
-- **N** :拟写入的新值(New)
+- **V**:要更新的变量值(Var)
+- **E**:预期值(Expected)
+- **N**:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
-**举一个简单的例子** :线程 A 要修改变量 i 的值为 6,i 原值为 1(V = 1,E=1,N=6,假设不存在 ABA 问题)。
+**举一个简单的例子**:线程 A 要修改变量 i 的值为 6,i 原值为 1(V = 1,E=1,N=6,假设不存在 ABA 问题)。
1. i 与 1 进行比较,如果相等, 则说明没被其他线程修改,可以被设置为 6 。
2. i 与 1 进行比较,如果不相等,则说明被其他线程修改,当前线程放弃更新,CAS 操作失败。
@@ -502,7 +502,7 @@ public ReentrantLock(boolean fair) {
### 公平锁和非公平锁有什么区别?
- **公平锁** : 锁被释放之后,先申请的线程先得到锁。性能较差一些,因为公平锁为了保证时间上的绝对顺序,上下文切换更频繁。
-- **非公平锁** :锁被释放之后,后申请的线程可能会先获取到锁,是随机或者按照其他优先级排序的。性能更好,但可能会导致某些线程永远无法获取到锁。
+- **非公平锁**:锁被释放之后,后申请的线程可能会先获取到锁,是随机或者按照其他优先级排序的。性能更好,但可能会导致某些线程永远无法获取到锁。
### synchronized 和 ReentrantLock 有什么区别?
@@ -551,8 +551,8 @@ public class ReentrantLockDemo {
### 可中断锁和不可中断锁有什么区别?
-- **可中断锁** :获取锁的过程中可以被中断,不需要一直等到获取锁之后 才能进行其他逻辑处理。`ReentrantLock` 就属于是可中断锁。
-- **不可中断锁** :一旦线程申请了锁,就只能等到拿到锁以后才能进行其他的逻辑处理。 `synchronized` 就属于是不可中断锁。
+- **可中断锁**:获取锁的过程中可以被中断,不需要一直等到获取锁之后 才能进行其他逻辑处理。`ReentrantLock` 就属于是可中断锁。
+- **不可中断锁**:一旦线程申请了锁,就只能等到拿到锁以后才能进行其他的逻辑处理。 `synchronized` 就属于是不可中断锁。
## ReentrantReadWriteLock
@@ -598,8 +598,8 @@ public ReentrantReadWriteLock(boolean fair) {
### 共享锁和独占锁有什么区别?
-- **共享锁** :一把锁可以被多个线程同时获得。
-- **独占锁** :一把锁只能被一个线程获得。
+- **共享锁**:一把锁可以被多个线程同时获得。
+- **独占锁**:一把锁只能被一个线程获得。
### 线程持有读锁还能获取写锁吗?
@@ -633,7 +633,7 @@ public class StampedLock implements java.io.Serializable {
- **写锁**:独占锁,一把锁只能被一个线程获得。当一个线程获取写锁后,其他请求读锁和写锁的线程必须等待。类似于 `ReentrantReadWriteLock` 的写锁,不过这里的写锁是不可重入的。
- **读锁** (悲观读):共享锁,没有线程获取写锁的情况下,多个线程可以同时持有读锁。如果己经有线程持有写锁,则其他线程请求获取该读锁会被阻塞。类似于 `ReentrantReadWriteLock` 的读锁,不过这里的读锁是不可重入的。
-- **乐观读** :允许多个线程获取乐观读以及读锁。同时允许一个写线程获取写锁。
+- **乐观读**:允许多个线程获取乐观读以及读锁。同时允许一个写线程获取写锁。
另外,`StampedLock` 还支持这三种锁在一定条件下进行相互转换 。
diff --git a/docs/java/concurrent/java-concurrent-questions-03.md b/docs/java/concurrent/java-concurrent-questions-03.md
index c7ebf5ee781..3b4b93ac813 100644
--- a/docs/java/concurrent/java-concurrent-questions-03.md
+++ b/docs/java/concurrent/java-concurrent-questions-03.md
@@ -211,10 +211,10 @@ static class Entry extends WeakReference> {
我们可以创建多种类型的 `ThreadPoolExecutor`:
-- **`FixedThreadPool`** :该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
+- **`FixedThreadPool`**:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- **`SingleThreadExecutor`:** 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- **`CachedThreadPool`:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
-- **`ScheduledThreadPool`** :该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
+- **`ScheduledThreadPool`**:该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
对应 `Executors` 工具类中的方法如图所示:
@@ -232,8 +232,8 @@ static class Entry extends WeakReference> {
`Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
-- **`FixedThreadPool` 和 `SingleThreadExecutor`** :使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
-- **`CachedThreadPool`** :使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
+- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`** : 使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
```java
@@ -347,7 +347,7 @@ public static class CallerRunsPolicy implements RejectedExecutionHandler {
不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程。
-- `SynchronousQueue`(同步队列) :`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
+- `SynchronousQueue`(同步队列):`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
- `DelayedWorkQueue`(延迟阻塞队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
### 线程池处理任务的流程了解吗?
@@ -479,8 +479,8 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
如果我们的项目也想要实现这种效果的话,可以借助现成的开源项目:
-- **[Hippo-4](https://github.com/opengoofy/hippo4j)** :一款强大的动态线程池框架,解决了传统线程池使用存在的一些痛点比如线程池参数没办法动态修改、不支持运行时变量的传递、无法执行优雅关闭。除了支持动态修改线程池参数、线程池任务传递上下文,还支持通知报警、运行监控等开箱即用的功能。
-- **[Dynamic TP](https://github.com/dromara/dynamic-tp)** :轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心(已支持 Nacos、Apollo,Zookeeper、Consul、Etcd,可通过 SPI 自定义实现)。
+- **[Hippo-4](https://github.com/opengoofy/hippo4j)**:一款强大的动态线程池框架,解决了传统线程池使用存在的一些痛点比如线程池参数没办法动态修改、不支持运行时变量的传递、无法执行优雅关闭。除了支持动态修改线程池参数、线程池任务传递上下文,还支持通知报警、运行监控等开箱即用的功能。
+- **[Dynamic TP](https://github.com/dromara/dynamic-tp)**:轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心(已支持 Nacos、Apollo,Zookeeper、Consul、Etcd,可通过 SPI 自定义实现)。
## Future
diff --git a/docs/java/concurrent/java-thread-pool-best-practices.md b/docs/java/concurrent/java-thread-pool-best-practices.md
index 41cab8924af..30efff30239 100644
--- a/docs/java/concurrent/java-thread-pool-best-practices.md
+++ b/docs/java/concurrent/java-thread-pool-best-practices.md
@@ -13,8 +13,8 @@ tag:
`Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
-- **`FixedThreadPool` 和 `SingleThreadExecutor`** :使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
-- **`CachedThreadPool`** :使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
+- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` ** : 使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
说白了就是:**使用有界队列,控制线程创建数量。**
@@ -195,8 +195,8 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
如果我们的项目也想要实现这种效果的话,可以借助现成的开源项目:
-- **[Hippo-4](https://github.com/opengoofy/hippo4j)** :一款强大的动态线程池框架,解决了传统线程池使用存在的一些痛点比如线程池参数没办法动态修改、不支持运行时变量的传递、无法执行优雅关闭。除了支持动态修改线程池参数、线程池任务传递上下文,还支持通知报警、运行监控等开箱即用的功能。
-- **[Dynamic TP](https://github.com/dromara/dynamic-tp)** :轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心(已支持 Nacos、Apollo,Zookeeper、Consul、Etcd,可通过 SPI 自定义实现)。
+- **[Hippo-4](https://github.com/opengoofy/hippo4j)**:一款强大的动态线程池框架,解决了传统线程池使用存在的一些痛点比如线程池参数没办法动态修改、不支持运行时变量的传递、无法执行优雅关闭。除了支持动态修改线程池参数、线程池任务传递上下文,还支持通知报警、运行监控等开箱即用的功能。
+- **[Dynamic TP](https://github.com/dromara/dynamic-tp)**:轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心(已支持 Nacos、Apollo,Zookeeper、Consul、Etcd,可通过 SPI 自定义实现)。
## 6、别忘记关闭线程池
diff --git a/docs/java/concurrent/java-thread-pool-summary.md b/docs/java/concurrent/java-thread-pool-summary.md
index 2f006585522..fd7b04a150f 100644
--- a/docs/java/concurrent/java-thread-pool-summary.md
+++ b/docs/java/concurrent/java-thread-pool-summary.md
@@ -67,7 +67,7 @@ public class ScheduledThreadPoolExecutor
当我们把 **`Runnable`接口** 或 **`Callable` 接口** 的实现类提交给 **`ThreadPoolExecutor`** 或 **`ScheduledThreadPoolExecutor`** 执行。(调用 `submit()` 方法时会返回一个 **`FutureTask`** 对象)
-**`Executor` 框架的使用示意图** :
+**`Executor` 框架的使用示意图**:

@@ -135,10 +135,10 @@ public class ScheduledThreadPoolExecutor
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
-- **`ThreadPoolExecutor.AbortPolicy`** :抛出 `RejectedExecutionException`来拒绝新任务的处理。
-- **`ThreadPoolExecutor.CallerRunsPolicy`** :调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
-- **`ThreadPoolExecutor.DiscardPolicy`** :不处理新任务,直接丢弃掉。
-- **`ThreadPoolExecutor.DiscardOldestPolicy`** :此策略将丢弃最早的未处理的任务请求。
+- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
+- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.DiscardPolicy`**:不处理新任务,直接丢弃掉。
+- **`ThreadPoolExecutor.DiscardOldestPolicy`**:此策略将丢弃最早的未处理的任务请求。
举个例子:
@@ -154,10 +154,10 @@ Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecu
我们可以创建多种类型的 `ThreadPoolExecutor`:
-- **`FixedThreadPool`** :该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
+- **`FixedThreadPool`**:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- **`SingleThreadExecutor`:** 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- **`CachedThreadPool`:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
-- **`ScheduledThreadPool`** :该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
+- **`ScheduledThreadPool`**:该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
对应 `Executors` 工具类中的方法如图所示:
@@ -167,8 +167,8 @@ Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecu
`Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
-- **`FixedThreadPool` 和 `SingleThreadExecutor`** :使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
-- **`CachedThreadPool`** :使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
+- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`** : 使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
```java
@@ -210,7 +210,7 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程。
-- `SynchronousQueue`(同步队列) :`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
+- `SynchronousQueue`(同步队列):`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
- `DelayedWorkQueue`(延迟阻塞队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
## 线程池原理分析(重要)
@@ -307,13 +307,13 @@ public class ThreadPoolExecutorDemo {
可以看到我们上面的代码指定了:
- `corePoolSize`: 核心线程数为 5。
-- `maximumPoolSize` :最大线程数 10
+- `maximumPoolSize`:最大线程数 10
- `keepAliveTime` : 等待时间为 1L。
- `unit`: 等待时间的单位为 TimeUnit.SECONDS。
- `workQueue`:任务队列为 `ArrayBlockingQueue`,并且容量为 100;
- `handler`:饱和策略为 `CallerRunsPolicy`。
-**输出结构** :
+**输出结构**:
```
pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
@@ -666,7 +666,7 @@ Exception in thread "main" java.util.concurrent.TimeoutException
#### 为什么不推荐使用`FixedThreadPool`?
-`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`(队列的容量为 Integer.MAX_VALUE)作为线程池的工作队列会对线程池带来如下影响 :
+`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`(队列的容量为 Integer.MAX_VALUE)作为线程池的工作队列会对线程池带来如下影响:
1. 当线程池中的线程数达到 `corePoolSize` 后,新任务将在无界队列中等待,因此线程池中的线程数不会超过 `corePoolSize`;
2. 由于使用无界队列时 `maximumPoolSize` 将是一个无效参数,因为不可能存在任务队列满的情况。所以,通过创建 `FixedThreadPool`的源码可以看出创建的 `FixedThreadPool` 的 `corePoolSize` 和 `maximumPoolSize` 被设置为同一个值。
diff --git a/docs/java/concurrent/jmm.md b/docs/java/concurrent/jmm.md
index d31da1beb99..18954c19737 100644
--- a/docs/java/concurrent/jmm.md
+++ b/docs/java/concurrent/jmm.md
@@ -52,8 +52,8 @@ JMM(Java 内存模型)主要定义了对于一个共享变量,当另一个线
常见的指令重排序有下面 2 种情况:
-- **编译器优化重排** :编译器(包括 JVM、JIT 编译器等)在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
-- **指令并行重排** :现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
+- **编译器优化重排**:编译器(包括 JVM、JIT 编译器等)在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
+- **指令并行重排**:现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
另外,内存系统也会有“重排序”,但又不是真正意义上的重排序。在 JMM 里表现为主存和本地内存的内容可能不一致,进而导致程序在多线程下执行可能出现问题。
@@ -89,8 +89,8 @@ JMM 说白了就是定义了一些规范来解决这些问题,开发者可以
**什么是主内存?什么是本地内存?**
-- **主内存** :所有线程创建的实例对象都存放在主内存中,不管该实例对象是成员变量还是方法中的本地变量(也称局部变量)
-- **本地内存** :每个线程都有一个私有的本地内存来存储共享变量的副本,并且,每个线程只能访问自己的本地内存,无法访问其他线程的本地内存。本地内存是 JMM 抽象出来的一个概念,存储了主内存中的共享变量副本。
+- **主内存**:所有线程创建的实例对象都存放在主内存中,不管该实例对象是成员变量还是方法中的本地变量(也称局部变量)
+- **本地内存**:每个线程都有一个私有的本地内存来存储共享变量的副本,并且,每个线程只能访问自己的本地内存,无法访问其他线程的本地内存。本地内存是 JMM 抽象出来的一个概念,存储了主内存中的共享变量副本。
Java 内存模型的抽象示意图如下:
@@ -130,7 +130,7 @@ Java 内存模型的抽象示意图如下:
### Java 内存区域和 JMM 有何区别?
-这是一个比较常见的问题,很多初学者非常容易搞混。 **Java 内存区域和内存模型是完全不一样的两个东西** :
+这是一个比较常见的问题,很多初学者非常容易搞混。 **Java 内存区域和内存模型是完全不一样的两个东西**:
- JVM 内存结构和 Java 虚拟机的运行时区域相关,定义了 JVM 在运行时如何分区存储程序数据,就比如说堆主要用于存放对象实例。
- Java 内存模型和 Java 的并发编程相关,抽象了线程和主内存之间的关系就比如说线程之间的共享变量必须存储在主内存中,规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的。
@@ -179,11 +179,11 @@ int totalNum = userNum + teacherNum; // 3
happens-before 的规则就 8 条,说多不多,重点了解下面列举的 5 条即可。全记是不可能的,很快就忘记了,意义不大,随时查阅即可。
-1. **程序顺序规则** :一个线程内,按照代码顺序,书写在前面的操作 happens-before 于书写在后面的操作;
-2. **解锁规则** :解锁 happens-before 于加锁;
-3. **volatile 变量规则** :对一个 volatile 变量的写操作 happens-before 于后面对这个 volatile 变量的读操作。说白了就是对 volatile 变量的写操作的结果对于发生于其后的任何操作都是可见的。
-4. **传递规则** :如果 A happens-before B,且 B happens-before C,那么 A happens-before C;
-5. **线程启动规则** :Thread 对象的 `start()`方法 happens-before 于此线程的每一个动作。
+1. **程序顺序规则**:一个线程内,按照代码顺序,书写在前面的操作 happens-before 于书写在后面的操作;
+2. **解锁规则**:解锁 happens-before 于加锁;
+3. **volatile 变量规则**:对一个 volatile 变量的写操作 happens-before 于后面对这个 volatile 变量的读操作。说白了就是对 volatile 变量的写操作的结果对于发生于其后的任何操作都是可见的。
+4. **传递规则**:如果 A happens-before B,且 B happens-before C,那么 A happens-before C;
+5. **线程启动规则**:Thread 对象的 `start()`方法 happens-before 于此线程的每一个动作。
如果两个操作不满足上述任意一个 happens-before 规则,那么这两个操作就没有顺序的保障,JVM 可以对这两个操作进行重排序。
diff --git a/docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md b/docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md
index 4b3e2b6c89c..77564054a10 100644
--- a/docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md
+++ b/docs/java/concurrent/optimistic-lock-and-pessimistic-lock.md
@@ -68,7 +68,7 @@ longAdder.sum();
一般是在数据表中加上一个数据版本号 `version` 字段,表示数据被修改的次数。当数据被修改时,`version` 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 `version` 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 `version` 值相等时才更新,否则重试更新操作,直到更新成功。
-**举一个简单的例子** :假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( `balance` )为 \$100 。
+**举一个简单的例子**:假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( `balance` )为 \$100 。
1. 操作员 A 此时将其读出( `version`=1 ),并从其帐户余额中扣除 $50( $100-\$50 )。
2. 在操作员 A 操作的过程中,操作员 B 也读入此用户信息( `version`=1 ),并从其帐户余额中扣除 $20 ( $100-\$20 )。
@@ -87,13 +87,13 @@ CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
-- **V** :要更新的变量值(Var)
-- **E** :预期值(Expected)
-- **N** :拟写入的新值(New)
+- **V**:要更新的变量值(Var)
+- **E**:预期值(Expected)
+- **N**:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
-**举一个简单的例子** :线程 A 要修改变量 i 的值为 6,i 原值为 1(V = 1,E=1,N=6,假设不存在 ABA 问题)。
+**举一个简单的例子**:线程 A 要修改变量 i 的值为 6,i 原值为 1(V = 1,E=1,N=6,假设不存在 ABA 问题)。
1. i 与 1 进行比较,如果相等, 则说明没被其他线程修改,可以被设置为 6 。
2. i 与 1 进行比较,如果不相等,则说明被其他线程修改,当前线程放弃更新,CAS 操作失败。
diff --git a/docs/java/io/io-design-patterns.md b/docs/java/io/io-design-patterns.md
index df1ee8f0851..f7d09053cbb 100644
--- a/docs/java/io/io-design-patterns.md
+++ b/docs/java/io/io-design-patterns.md
@@ -262,7 +262,7 @@ WatchKey register(WatchService watcher,
常用的监听事件有 3 种:
-- `StandardWatchEventKinds.ENTRY_CREATE` :文件创建。
+- `StandardWatchEventKinds.ENTRY_CREATE`:文件创建。
- `StandardWatchEventKinds.ENTRY_DELETE` : 文件删除。
- `StandardWatchEventKinds.ENTRY_MODIFY` : 文件修改。
diff --git a/docs/java/jvm/class-file-structure.md b/docs/java/jvm/class-file-structure.md
index 1e28cd2ef45..f7fdfbf3e87 100644
--- a/docs/java/jvm/class-file-structure.md
+++ b/docs/java/jvm/class-file-structure.md
@@ -111,7 +111,7 @@ ClassFile {
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
-`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
+`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt`:将结果输出到 temp.txt 文件)。
### 访问标志(Access Flags)
diff --git a/docs/java/jvm/class-loading-process.md b/docs/java/jvm/class-loading-process.md
index 2957b40e53f..295385ef3d2 100644
--- a/docs/java/jvm/class-loading-process.md
+++ b/docs/java/jvm/class-loading-process.md
@@ -83,7 +83,7 @@ tag:
2. 从概念上讲,类变量所使用的内存都应当在 **方法区** 中进行分配。不过有一点需要注意的是:JDK 7 之前,HotSpot 使用永久代来实现方法区的时候,实现是完全符合这种逻辑概念的。 而在 JDK 7 及之后,HotSpot 已经把原本放在永久代的字符串常量池、静态变量等移动到堆中,这个时候类变量则会随着 Class 对象一起存放在 Java 堆中。相关阅读:[《深入理解 Java 虚拟机(第 3 版)》勘误#75](https://github.com/fenixsoft/jvm_book/issues/75 "《深入理解Java虚拟机(第3版)》勘误#75")
3. 这里所设置的初始值"通常情况"下是数据类型默认的零值(如 0、0L、null、false 等),比如我们定义了`public static int value=111` ,那么 value 变量在准备阶段的初始值就是 0 而不是 111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 final 关键字`public static final int value=111` ,那么准备阶段 value 的值就被赋值为 111。
-**基本数据类型的零值** :(图片来自《深入理解 Java 虚拟机》第 3 版 7.33 )
+**基本数据类型的零值**:(图片来自《深入理解 Java 虚拟机》第 3 版 7.33 )
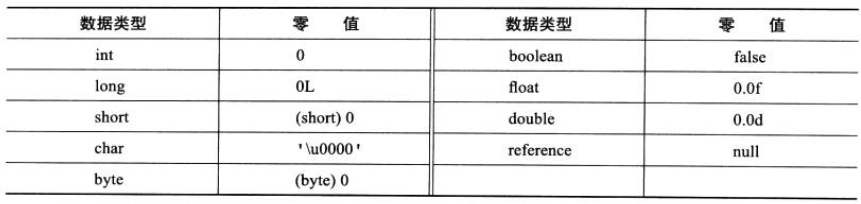
diff --git a/docs/java/jvm/classloader.md b/docs/java/jvm/classloader.md
index b7ff4e42290..cf5fc3f00e7 100644
--- a/docs/java/jvm/classloader.md
+++ b/docs/java/jvm/classloader.md
@@ -86,13 +86,13 @@ public abstract class ClassLoader {
JVM 中内置了三个重要的 `ClassLoader`:
-1. **`BootstrapClassLoader`(启动类加载器)** :最顶层的加载类,由 C++实现,通常表示为 null,并且没有父级,主要用来加载 JDK 内部的核心类库( `%JAVA_HOME%/lib`目录下的 `rt.jar`、`resources.jar`、`charsets.jar`等 jar 包和类)以及被 `-Xbootclasspath`参数指定的路径下的所有类。
-2. **`ExtensionClassLoader`(扩展类加载器)** :主要负责加载 `%JRE_HOME%/lib/ext` 目录下的 jar 包和类以及被 `java.ext.dirs` 系统变量所指定的路径下的所有类。
-3. **`AppClassLoader`(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
+1. **`BootstrapClassLoader`(启动类加载器)**:最顶层的加载类,由 C++实现,通常表示为 null,并且没有父级,主要用来加载 JDK 内部的核心类库( `%JAVA_HOME%/lib`目录下的 `rt.jar`、`resources.jar`、`charsets.jar`等 jar 包和类)以及被 `-Xbootclasspath`参数指定的路径下的所有类。
+2. **`ExtensionClassLoader`(扩展类加载器)**:主要负责加载 `%JRE_HOME%/lib/ext` 目录下的 jar 包和类以及被 `java.ext.dirs` 系统变量所指定的路径下的所有类。
+3. **`AppClassLoader`(应用程序类加载器)**:面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
> 🌈 拓展一下:
>
-> - **`rt.jar`** :rt 代表“RunTime”,`rt.jar`是 Java 基础类库,包含 Java doc 里面看到的所有的类的类文件。也就是说,我们常用内置库 `java.xxx.* `都在里面,比如`java.util.*`、`java.io.*`、`java.nio.*`、`java.lang.*`、`java.sql.*`、`java.math.*`。
+> - **`rt.jar`**:rt 代表“RunTime”,`rt.jar`是 Java 基础类库,包含 Java doc 里面看到的所有的类的类文件。也就是说,我们常用内置库 `java.xxx.* `都在里面,比如`java.util.*`、`java.io.*`、`java.nio.*`、`java.lang.*`、`java.sql.*`、`java.math.*`。
> - Java 9 引入了模块系统,并且略微更改了上述的类加载器。扩展类加载器被改名为平台类加载器(platform class loader)。Java SE 中除了少数几个关键模块,比如说 `java.base` 是由启动类加载器加载之外,其他的模块均由平台类加载器所加载。
除了这三种类加载器之外,用户还可以加入自定义的类加载器来进行拓展,以满足自己的特殊需求。就比如说,我们可以对 Java 类的字节码( `.class` 文件)进行加密,加载时再利用自定义的类加载器对其解密。
@@ -276,7 +276,7 @@ protected Class loadClass(String name, boolean resolve)
🌈 拓展一下:
-**JVM 判定两个 Java 类是否相同的具体规则** :JVM 不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即使两个类来源于同一个 `Class` 文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相同。
+**JVM 判定两个 Java 类是否相同的具体规则**:JVM 不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即使两个类来源于同一个 `Class` 文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相同。
### 双亲委派模型的好处
@@ -288,7 +288,7 @@ protected Class loadClass(String name, boolean resolve)
~~为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重写 `loadClass()` 即可。~~
-**🐛 修正(参见:[issue871](https://github.com/Snailclimb/JavaGuide/issues/871) )** :自定义加载器的话,需要继承 `ClassLoader` 。如果我们不想打破双亲委派模型,就重写 `ClassLoader` 类中的 `findClass()` 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 `loadClass()` 方法。
+**🐛 修正(参见:[issue871](https://github.com/Snailclimb/JavaGuide/issues/871) )**:自定义加载器的话,需要继承 `ClassLoader` 。如果我们不想打破双亲委派模型,就重写 `ClassLoader` 类中的 `findClass()` 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 `loadClass()` 方法。
为什么是重写 `loadClass()` 方法打破双亲委派模型呢?双亲委派模型的执行流程已经解释了:
diff --git a/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md b/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md
index 7b9f11e888d..aff34a7f375 100644
--- a/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md
+++ b/docs/java/jvm/jdk-monitoring-and-troubleshooting-tools.md
@@ -20,7 +20,7 @@ tag:
`jps`(JVM Process Status) 命令类似 UNIX 的 `ps` 命令。
-`jps`:显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。`jps -q` :只输出进程的本地虚拟机唯一 ID。
+`jps`:显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。`jps -q`:只输出进程的本地虚拟机唯一 ID。
```powershell
C:\Users\SnailClimb>jps
@@ -60,16 +60,16 @@ jstat -