| title | 数据冷热分离详解 | |||||||
|---|---|---|---|---|---|---|---|---|
| description | 本文详解数据冷热分离的核心原理与实践方案,涵盖冷热数据判定策略、多级分层设计、数据迁移一致性保障、冷数据查询优化、存储选型(HBase/TiDB/对象存储),以及订单/日志/内容系统的典型落地案例。 | |||||||
| category | 高性能 | |||||||
| head |
|
数据冷热分离是指根据数据的访问频率和业务重要性,将数据划分为冷数据和热数据,并分别存储在不同性能和成本的存储介质中的架构策略。
这种架构的核心目标有三个:
- 提升查询性能:热数据存储在高性能介质(如 SSD、内存)中,保障核心业务的响应速度。
- 降低存储成本:冷数据迁移至低成本介质(如 HDD、对象存储),大幅削减存储开支。
- 满足合规要求:部分行业(如金融、医疗)要求数据长期归档,冷热分离可兼顾合规与成本。
热数据是指被频繁访问和修改、且需要快速响应的数据;冷数据是指访问频率极低、对当前业务价值较小、但需要长期保留的数据。
冷热数据的区分方法主要有两种:
- 时间维度区分:按照数据的创建时间、更新时间或过期时间划分。例如,订单系统将一段时间前(如 90 天或 1 年)的订单数据标记为冷数据。该方法适用于数据访问频率与时间强相关的场景,实现简单、成本低。
- 访问频率区分:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统将浏览量低于阈值的文章标记为冷数据。该方法需要额外记录访问频率,适用于访问频率与数据本身特性强相关的场景。
如何选择区分策略?
- 若业务数据天然具有时效性(如订单、日志、账单),优先选择时间维度,实现成本最低。
- 若数据价值与时间无关(如文章、商品、用户画像),需结合访问频率进行判定。
- 实际项目中,可将两者结合使用:以时间维度为主、访问频率为辅,覆盖更多业务场景。
实际落地时,"冷"与"热"往往不是非此即彼的二分法,而是渐进式多级分层:
| 层级 | 数据特性 | 判定规则示例 | 存储策略 |
|---|---|---|---|
| 热数据 | 高频访问、实时响应 | 最近 30 天 + 所有未完成订单 | MySQL 热库(SSD) |
| 温数据 | 中频访问、可能被查询 | 30~90 天前的订单 | MySQL 温库(HDD) |
| 冷数据 | 低频访问、偶发查询 | 90 天~3 年的历史订单 | 独立冷库或对象存储 |
| 归档数据 | 极少访问、仅合规留存 | 超过 3 年的订单 | 对象存储(仅保留汇总) |
实践建议:判定规则应通过配置中心动态管理,避免因业务变化导致频繁修改代码。
如果冷数据突然被访问(如用户查询 3 年前的订单),是否需要"热升级"?
| 策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 不回迁 | 偶发查询、查询频率极低 | 实现简单 | 查询速度慢 |
| 缓存层 | 中等频率查询 | 加速查询、不改变存储 | 需要额外缓存组件 |
| 异步回迁 | 高频查询、需要持续访问 | 彻底解决性能问题 | 实现复杂、可能产生一致性问题 |
推荐做法:绝大多数场景采用"不回迁 + 缓存层"的组合方案。冷数据查询时,先查缓存,命中则直接返回;未命中则查冷库并将结果写入缓存(针对偶发查询,设置 5~15 分钟的短暂 TTL 即可)。
冷热分离的核心思想是分层存储(Tiered Storage),根据数据的访问特性将其分配到不同层级的存储介质中。在企业级存储架构中,通常划分为以下层级:
| 层级 | 数据特性 | 典型存储介质 | 访问延迟 |
|---|---|---|---|
| Hot(热层) | 高频访问、实时响应 | NVMe SSD、内存 | 毫秒级 |
| Warm(温层) | 中频访问、近期数据 | SATA SSD、高速 HDD | 百毫秒级 |
| Cold(冷层) | 低频访问、历史数据 | 大容量 HDD、对象存储 | 秒级 |
| Archive(归档层) | 极少访问、合规留存 | 磁带库、冰川存储 | 分钟~小时级 |
这种分层思想在 IT 基础设施中被广泛应用,不仅限于数据库,还包括文件系统、对象存储、CDN 缓存等场景。
优点:
- 热数据查询性能优化:热数据集中在高性能存储上,表数据量大幅减少,索引效率显著提升,用户的绝大部分操作体验会更好。
- 存储成本大幅降低:冷数据可迁移至 HDD 或对象存储,SSD 与 HDD 的单位成本差距可达 5~10 倍,对于海量数据场景节省效果显著。
- 系统可维护性增强:热库数据量可控,备份恢复速度更快,DDL 操作(如加索引)耗时更短。
缺点:
- 系统复杂性增加:需要额外的迁移组件、路由逻辑和监控体系,数据一致性风险增加。
- 跨库查询效率低:若业务需要同时查询冷热数据(如年度统计报表),需进行跨库关联或数据聚合,查询性能和开发成本均会上升。
- 迁移策略维护成本:冷热数据的判定规则需要持续调优,避免误判导致热数据被错误迁移。
冷数据迁移是冷热分离的核心环节,主流方案有以下三种:
| 方案 | 实现原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 业务层代码实现 | 写操作时判断冷热,直接路由到对应库 | 实时性高 | 侵入业务代码、判定逻辑复杂 | 几乎不使用 |
| 任务调度迁移 | 定时任务扫描热库,批量迁移符合条件的数据 | 实现简单 | 存在迁移延迟、扫表可能污染 Buffer Pool | 时间维度区分场景 |
| Binlog 监听迁移 | 监听数据库变更日志,实时或准实时迁移 | 实时性好、对业务无侵入 | 需要额外组件(如 Canal)、不适合时间维度判定 | 访问频率区分场景(推荐) |
任务调度迁移是最常用的方案,可借助 XXL-Job、Elastic-Job 等分布式任务调度平台实现。关于任务调度的方案,我也写过文章详细介绍,可以查看这篇文章:Java 定时任务详解 。
⚠️ 风险提示:任务调度迁移在大数据量下存在性能隐患。大范围的扫表操作(如SELECT * FROM orders WHERE create_time < 'xxx' LIMIT 10000)会严重污染 InnoDB Buffer Pool,将真正的业务热数据挤出内存。生产环境建议:
- 使用基于主键的范围查询,避免全表扫描;
- 控制单次迁移批量大小,分批执行;
- 在业务低峰期执行迁移任务;
- 对于海量数据,优先考虑 Binlog 监听方案,将对热库的冲击降到最低。
典型流程如下:
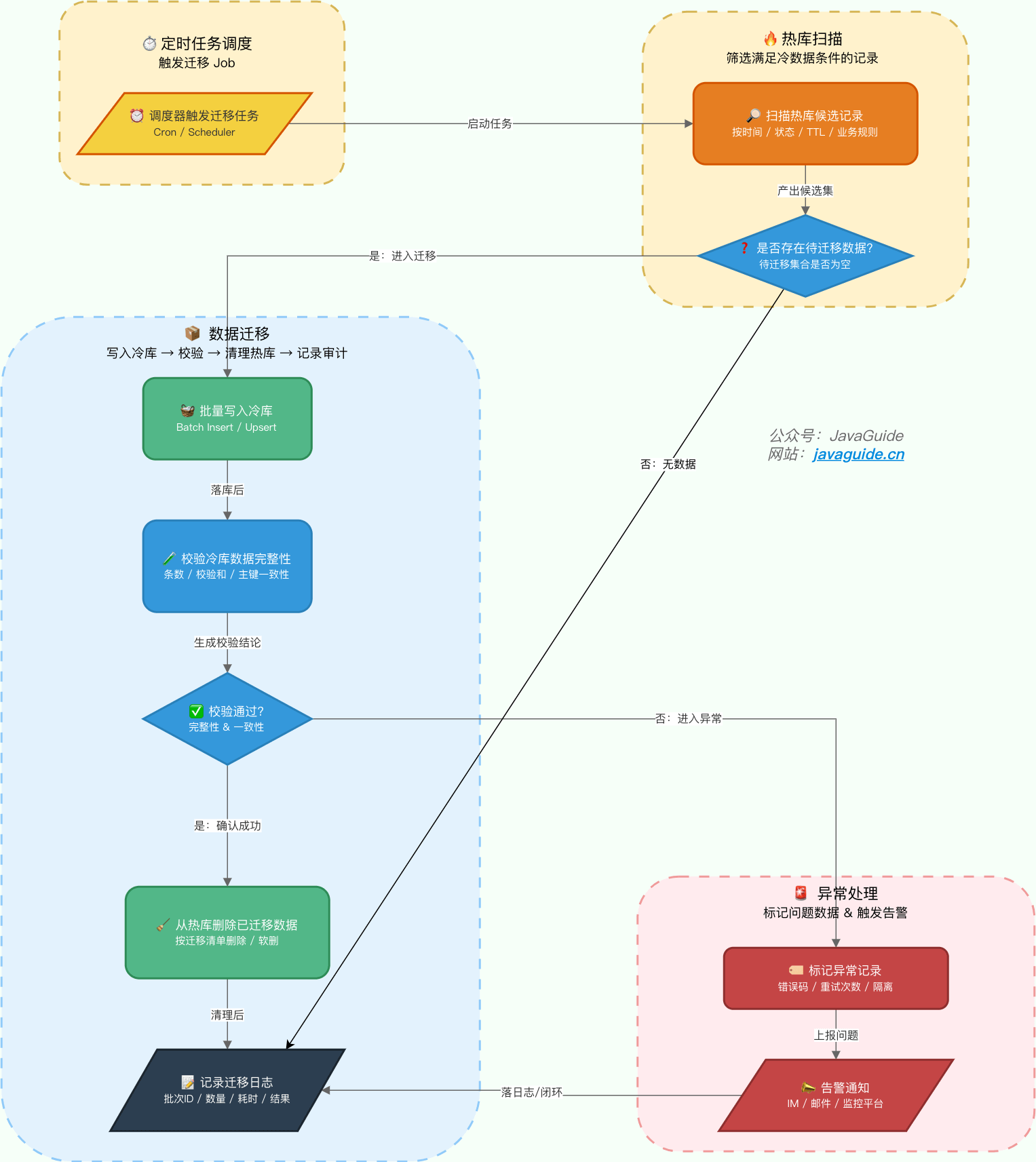
实践建议:若公司有 DBA 支持,可先进行一次存量冷数据的人工迁移,将历史数据批量导入冷库;后续再通过任务调度实现增量迁移的自动化。
数据迁移过程中,最棘手的问题是:如果数据在迁移过程中被更新,如何处理?
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 迁移前锁定 | 迁移前对记录加写锁,迁移完成后释放 | 一致性强 | 影响业务写入、吞吐量下降 |
| 版本号乐观锁 | 迁移时记录版本,删除前校验版本是否变化 | 无锁、性能好 | 需要业务表增加版本字段、冲突时需重试 |
| 状态标记 + 幂等 | 热库增加迁移状态字段,先标记再迁移 | 可追溯、支持回滚 | 需要改造业务表 |
注意:冷热库通常是不同的数据库实例,
INSERT(冷库)和DELETE(热库)无法放在同一个本地事务中,需要特殊处理跨库原子性问题。
在热库表中增加 migrate_status 字段,通过状态机保证迁移的原子性和可追溯性:
-- 1. 热库表增加迁移状态字段
ALTER TABLE orders ADD COLUMN migrate_status TINYINT DEFAULT 0
COMMENT '0-未迁移 1-迁移中 2-已迁移';// 2. 迁移流程(伪代码,独立冷库场景需在应用层分步执行)
// Step 1: 标记为迁移中(热库事务)
hotDb.execute("UPDATE orders SET migrate_status = 1 WHERE id = ? AND migrate_status = 0", id);
// Step 2: 读取热库数据并写入冷库(需切换数据库连接)
Order order = hotDb.query("SELECT * FROM orders WHERE id = ?", id);
coldDb.execute("INSERT IGNORE INTO orders_cold VALUES (?, ?, ...)", order.id, order.data...);
// Step 3: 标记为已迁移(热库事务)
hotDb.execute("UPDATE orders SET migrate_status = 2 WHERE id = ? AND migrate_status = 1", id);
// Step 4: 延迟删除热库数据(可选,确认冷库数据无误后执行)
hotDb.execute("DELETE FROM orders WHERE id = ? AND migrate_status = 2", id);注意:独立冷库场景下,标准 MySQL 无法直接执行跨库
INSERT ... SELECT,必须在应用层拆分为"读取热库 → 写入冷库"两步。
方案优势:
- 幂等性:
INSERT IGNORE保证冷库写入幂等,migrate_status状态流转保证热库更新幂等。 - 可追溯:通过状态字段可以查询迁移进度,异常时可以人工介入。
- 可回滚:迁移失败时可以将状态重置为 0,重新迁移。
- 渐进式删除:不立即删除热库数据,确认冷库无误后再清理,降低风险。
空间回收:InnoDB 执行
DELETE后仅将数据页标记为删除,物理空间不会立即释放给操作系统。需在业务低峰期执行OPTIMIZE TABLE或ALTER TABLE ENGINE=InnoDB重建表,才能真正回收磁盘空间。
兜底机制:
- 定时对账:定期扫描
migrate_status = 1超过阈值的记录,自动重置或告警。注意:migrate_status字段区分度极低,必须配合联合索引(如idx_create_time_migrate_status)限定扫描区间,避免全表扫描。 - 高频更新兜底:对于因频繁更新导致多次跳过的记录,设置最大重试次数,超过后强制迁移或人工介入。
冷数据存储方案的选型原则是:容量大、成本低、可靠性高,访问速度可适当牺牲。
直接使用 MySQL/PostgreSQL 即可,保持与热库相同的数据库类型,降低运维复杂度。具体实现方式:
- 同库分表:在同一数据库中新增冷数据表(如
order_history),通过表名区分冷热数据。 - 独立冷库:部署单独的数据库实例作为冷库,热库与冷库通过应用层路由访问。
大厂通常采用专门针对海量数据优化的存储引擎:
| 存储方案 | 特点 | 适用场景 |
|---|---|---|
| HBase | 列族存储、高吞吐、支持 PB 级数据 | 日志、用户行为、IoT 数据归档 |
| RocksDB | 高性能 KV 存储、LSM-Tree 结构 | 嵌入式场景、作为其他系统底层存储 |
| Doris/ClickHouse | OLAP 引擎、支持实时分析 | 冷数据需要进行聚合分析的场景 |
| Cassandra | 分布式、高可用、无单点故障 | 跨地域部署、高可用要求的归档场景 |
| 对象存储(OSS/S3) | 成本极低、无限扩展 | 超大规模冷数据、合规归档 |
如果公司技术栈允许,可以直接使用 TiDB 这类分布式关系型数据库,原生支持冷热分离,一步到位。
TiDB 6.0 引入了 基于 SQL 接口的数据放置框架(Placement Rules in SQL) 功能,用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。
- 热数据:通过 Placement Rules 指定存储在 SSD 节点上,保障查询性能。
- 冷数据:指定存储在 HDD 节点上,降低存储成本。
-- 创建放置策略:热数据存储在 SSD 节点
CREATE PLACEMENT POLICY hot_data
CONSTRAINTS="[+disk=ssd]";
-- 创建放置策略:冷数据存储在 HDD 节点
CREATE PLACEMENT POLICY cold_data
CONSTRAINTS="[+disk=hdd]";
-- 对表或分区应用放置策略
ALTER TABLE orders PLACEMENT POLICY = hot_data;
ALTER TABLE orders PARTITION p2022 PLACEMENT POLICY = cold_data;这种方案的优势在于:业务无需感知冷热分离逻辑,数据路由由 TiDB 自动完成,大幅降低了应用层的复杂度。
完整实践:
Placement Rules指定了数据存放的介质类型,但数据如何从"热分区"流转到"冷分区"仍需结合分区表(Range Partitioning)。按时间跨度创建分区,为历史分区绑定 HDD 放置策略,为当前活跃分区绑定 SSD 放置策略。随着时间推移,只需维护分区的创建与销毁,底层数据即可在不同介质间自然流转。
冷数据虽然访问频率低,但一旦需要查询(如审计、对账、年度报表),如何保证查询效率?
首先需要明确:业务是否真的需要查询冷数据?
- 不需要:可将冷数据完全移出业务库,仅保留归档(如对象存储),需要时人工提取。
- 需要:需设计合理的查询方案,平衡性能与成本。
| 优化手段 | 实现方式 | 适用场景 |
|---|---|---|
| 冷库独立只读实例 | 冷库部署只读副本,避免冷查询影响热库 | 高频冷查询场景 |
| 查询路由 | 应用层根据时间范围自动路由到热库或冷库 | 跨冷热查询场景 |
| 预聚合 | 定期对冷数据生成月度/季度报表,查询时直接查聚合结果 | 统计分析场景 |
| 列式存储 | 冷库采用 ClickHouse、Doris 等 OLAP 引擎 | 大规模分析查询 |
跨冷热查询的处理:
若查询范围同时涉及冷热数据(如"查询近 2 年的订单"),有两种处理方式:
- 拆分查询:分别查询热库和冷库,应用层合并结果。
- 限制范围:提示用户缩小查询范围,避免跨库查询。
防雪崩预警:若业务包含全局分页排序(如
ORDER BY create_time LIMIT 10000, 20),应用层必须从冷热库各拉取10000 + 20条记录进行内存归并,偏移量较大时极易引发 OOM。强制要求:
- 限制查询时间范围,避免大跨度跨库查询;
- 或引流至底层同步的宽表(如 ClickHouse)进行计算;
- 严禁在应用层执行大深度的归并分页。
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 硬编码 | 代码中直接判断路由 | 实现简单 | 维护成本高、规则变更需改代码 |
| 配置中心 | 路由规则存入配置中心(如 Nacos、Apollo) | 动态调整、无需重启 | 需要额外组件支持 |
| Proxy 层 | 引入 ShardingSphere、ProxySQL 等中间件 | 业务无感知 | 架构复杂度高 |
推荐做法:中小规模采用配置中心方案,大规模采用Proxy 层方案。
⚠️ 风险提示:引入 Proxy 层后,所有跨冷热库的聚合计算(如全局排序、GROUP BY归并分页)都会压在 Proxy 节点的内存与 CPU 上。需严格限制此类操作的最大返回行数,否则极易导致 Proxy 节点 OOM(内存溢出)。
这三个概念容易混淆,需要区分清楚:
| 对比维度 | 冷热分离 | 数据归档 | 分区表 |
|---|---|---|---|
| 数据是否可访问 | 冷数据仍在业务访问路径上 | 归档数据通常移出业务库 | 所有分区均可访问 |
| 存储介质 | 冷热数据可跨实例、跨存储 | 通常迁移到低成本存储 | 同一实例内 |
| 实现复杂度 | 中等 | 低 | 低 |
| 典型场景 | 订单、日志等有时效性的数据 | 合规留存、数据备份 | 单表数据量大但无需分离存储 |
分区表的局限性:MySQL 分区表可以按时间分区,但所有分区仍在同一个实例中,无法实现存储介质的分离。如果目标是降低存储成本,分区表无法替代冷热分离。
说明:以下存储策略仅供参考,实际选型需结合数据量、查询需求、团队技术栈和成本预算综合考虑。
| 阶段 | 数据范围 | 存储策略 | 说明 |
|---|---|---|---|
| 热数据 | 最近 90 天 + 未完成订单 | MySQL 热库(SSD) | 高频访问,保障查询性能 |
| 冷数据 | 90 天~3 年 | MySQL 冷库(HDD)或 TiDB | 可能需要查询,保持关系型存储 |
| 归档数据 | 超过 3 年 | 对象存储 / HBase / 仅保留汇总表 | 极少查询,优先考虑成本 |
| 阶段 | 数据范围 | 存储策略 | 说明 |
|---|---|---|---|
| 热数据 | 近 7 天 | Elasticsearch 热节点 | 实时检索、高频查询 |
| 温数据 | 7~30 天 | Elasticsearch 温节点 | 偶发查询,降低存储成本 |
| 冷数据 | 30 天以上 | Elasticsearch 冷节点 / 压缩归档至对象存储 / ClickHouse | 根据查询需求选择,ClickHouse 适合分析场景 |
| 阶段 | 数据范围 | 存储策略 | 说明 |
|---|---|---|---|
| 热数据 | 发布后 3 个月内 + 高阅读量 | MySQL 热库 | 频繁被访问 |
| 冷数据 | 3 个月后 + 低阅读量 | MySQL 冷库 / HBase / 对象存储 | 访问频率低,可迁移至低成本存储 |
选型建议:
- 需要支持事务或复杂查询:优先选择 MySQL 冷库或 TiDB
- 需要大规模聚合分析:优先选择 ClickHouse 或 Doris
- 仅需偶尔查询明细:可选择对象存储(如 OSS/S3),查询时临时加载
- 数据量极大且访问极低:HBase 或对象存储是性价比最高的选择