| title | 深度分页介绍及优化建议 | |||||||
|---|---|---|---|---|---|---|---|---|
| description | 深度分页是指查询偏移量过大导致性能下降的场景,本文详解深度分页产生的原因及四种优化方案:范围查询、子查询优化、INNER JOIN 延迟关联、覆盖索引,并分析各方案的适用场景与优缺点。 | |||||||
| category | 高性能 | |||||||
| head |
|
查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。
深度分页变慢的根本原因在于 MySQL 的执行机制:对于 LIMIT offset, N,MySQL 并非直接跳到 offset 处,而是必须从头扫描 offset + N 条记录。如果查询依赖二级索引且不满足覆盖索引,这意味着 MySQL 需要对前 offset 条记录执行毫无意义的回表查询(产生海量的随机 I/O),最后再将这些辛苦查出的数据丢弃。即便优化器最终因代价过高退化为全表扫描,顺序扫描百万行的成本依然巨大。
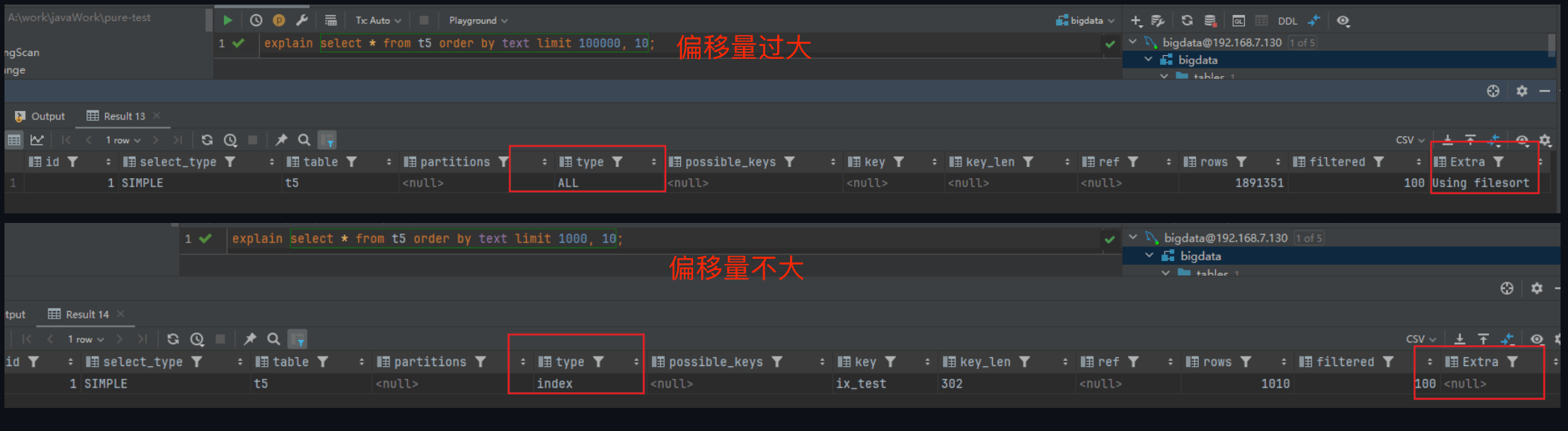
不同机器上这个查询偏移量过大的临界点可能不同,取决于多个因素,包括硬件配置(如 CPU 性能、磁盘速度)、表的大小、索引的类型和统计信息等。
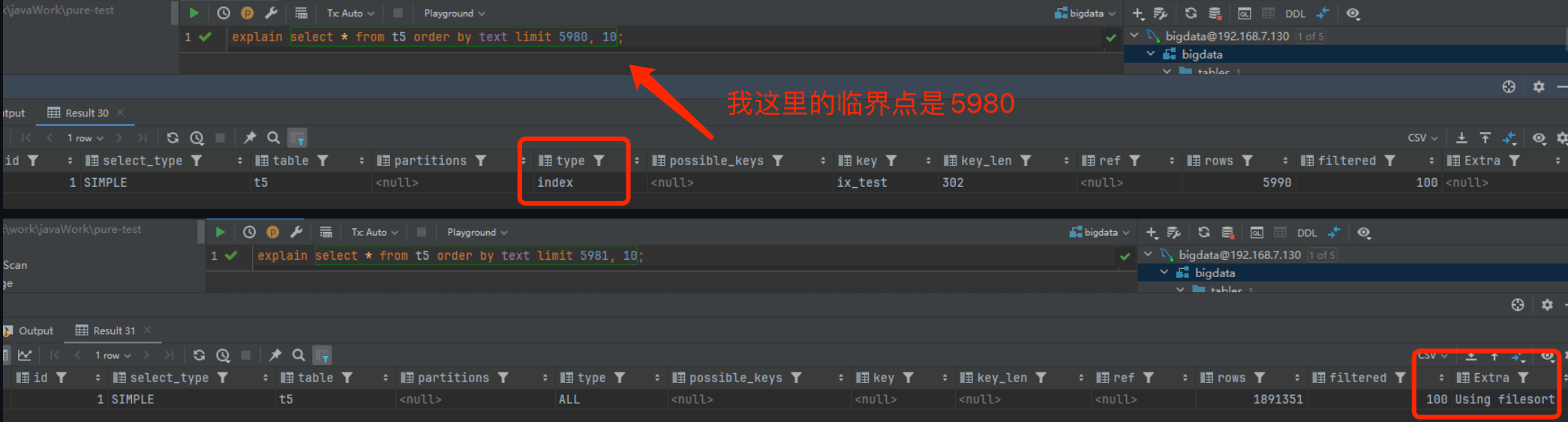
MySQL 的查询优化器采用基于成本的策略来选择最优的查询执行计划。它会根据 CPU 和 I/O 的成本来决定是否使用索引扫描或全表扫描。如果优化器认为全表扫描的成本更低,它就会放弃使用索引。不过,即使偏移量很大,如果查询中使用了覆盖索引(covering index),MySQL 仍然可能会使用索引,避免回表操作。
本文基于 MySQL 8.0 + InnoDB 存储引擎,不同版本优化器行为可能存在差异。
通过记录上一页最后一条记录的 ID,使用 WHERE id > last_id LIMIT n 获取下一页数据:
# 通过记录上次查询结果的最后一条记录的 ID 进行下一页的查询
SELECT * FROM t_order WHERE id > 100000 ORDER BY id LIMIT 10游标分页的核心优势:不依赖 ID 的连续性。MySQL 只需要在 B+ 树上定位到 last_id 的位置,然后顺序向后读取 n 条记录即可,中间是否有断层(如 ID 被删除)完全不影响结果的准确性和性能。
这种方式的限制:
- 不支持跳页:无法直接跳转到第 N 页,只能逐页向后(或向前)翻页。
- 排序字段受限:如果查询需要按照其他字段(如创建时间)排序而非 ID 排序,需使用联合游标
(sort_field, id)保证唯一性和顺序。 - 并发场景:当分页查询期间有新数据插入或删除时,可能出现:
- 数据遗漏:查询第二页时,有新数据插入到第一页范围内,导致该数据被"挤"到第二页,但第二页查询已基于旧的最后 ID 跳过它。
- 数据重复:查询第二页时,第一页末尾有数据被删除,原第二页的第一条数据"升"到第一页末尾,导致第二页查询再次返回它。
我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。
阿里巴巴《Java 开发手册》中也有对应的描述:
利用延迟关联或者子查询优化超多分页场景。

-- 先通过子查询在主键索引上进行偏移,快速找到起始ID
SELECT * FROM t_order
WHERE id >= (
SELECT id FROM t_order ORDER BY id LIMIT 1000000, 1
) ORDER BY id LIMIT 10;工作原理:
- 子查询
(SELECT id FROM t_order ORDER BY id LIMIT 1000000, 1)利用主键索引扫描并跳过前 1000000 条记录,返回第 1000001 条记录的主键值。 - 主查询
SELECT * FROM t_order WHERE id >= ... ORDER BY id LIMIT 10以该主键为起点,获取后续 10 条完整记录。
不过,某些情况下子查询可能会产生临时表,影响性能,因此在复杂查询中建议优先考虑延迟关联。
复杂过滤场景:在包含复杂过滤条件的分页场景中(如
WHERE status = 1 ORDER BY id LIMIT 1000000, 10),符合条件的 ID 往往是离散的。此时子查询的优势更加明显:通过在子查询中利用联合索引(如(status, id))实现覆盖索引扫描,可以高效地跳过前 100 万条符合条件的记录,定位到目标 ID 后,主查询只需回表 10 次。
当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
延迟关联与子查询的优化思路类似,都是通过将 LIMIT 操作转移到主键索引树上,减少回表次数。相比直接使用子查询,延迟关联通过 INNER JOIN 将子查询结果集成到主查询中,避免了子查询可能产生的临时表。在执行 INNER JOIN 时,MySQL 优化器能够利用索引进行高效的连接操作(如索引扫描或其他优化策略),因此在深度分页场景下,性能通常优于直接使用子查询。
-- 使用 INNER JOIN 进行延迟关联
SELECT t1.*
FROM t_order t1
INNER JOIN (
-- 这里的子查询可以利用覆盖索引,性能极高
SELECT id FROM t_order ORDER BY id LIMIT 1000000, 10
) t2 ON t1.id = t2.id
ORDER BY t1.id;工作原理:
- 子查询
(SELECT id FROM t_order ORDER BY id LIMIT 1000000, 10)利用主键索引扫描并跳过前 1000000 条记录,返回目标分页的 10 条记录的 ID。 - 通过
INNER JOIN将子查询结果与主表t_order关联,获取完整的记录数据。
除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。
-- 使用逗号进行延迟关联
SELECT t1.* FROM t_order t1,
(SELECT id FROM t_order ORDER BY id LIMIT 1000000, 10) t2
WHERE t1.id = t2.id
ORDER BY t1.id;注意: 虽然逗号连接子查询也能实现类似的效果,但为了代码可读性和可维护性,建议使用更规范的 INNER JOIN 语法。
索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
覆盖索引的好处:
- 避免 InnoDB 表进行索引的二次查询,也就是回表操作:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
- 减少回表带来的随机 IO:通过覆盖索引直接返回数据,避免了根据二级索引的主键值回表查询聚簇索引的随机 IO 操作。回表时每次按主键值查找聚簇索引,本质上是随机 IO。
假设建立了 (code, type) 联合索引,下面的查询即可使用覆盖索引:
# 在 InnoDB 中,辅助索引天然包含主键 id
# 如果只需要查询 id, code, type 这三列,只需建立 (code, type) 的联合索引即可实现覆盖
SELECT id, code, type FROM t_order
ORDER BY code
LIMIT 1000000, 10;- 当查询的结果集占表的总行数的很大一部分时,MySQL 查询优化器可能选择放弃使用索引,自动转换为全表扫描。
- 虽然可以使用
FORCE INDEX强制查询优化器走索引,但这种方式可能会导致查询优化器无法选择更优的执行计划,效果并不总是理想。
- 慢查询监控:监控慢查询日志中
LIMIT偏移量过大的 SQL,及时发现问题。 - 阈值告警:设置
long_query_time阈值捕获深度分页查询。 - 执行计划检查:使用
EXPLAIN定期检查关键分页 SQL 的执行计划,确保优化器按预期使用索引。
| 误区 | 事实 |
|---|---|
认为 FORCE INDEX 能解决所有问题 |
强制索引可能阻止优化器选择更优计划,应谨慎使用 |
| 认为覆盖索引适用于所有场景 | 字段过多时索引维护成本高,且大结果集仍可能走全表扫描 |
| 认为游标分页能解决所有问题 | 游标分页不支持跳页,且只能按特定字段顺序翻页 |
深度分页问题的根本原因在于:当 LIMIT 的偏移量过大时,MySQL 需要扫描并跳过大量记录才能获取目标数据,查询优化器可能放弃索引而选择全表扫描。此时即使有索引,也无法避免大量的回表操作,导致查询性能急剧下降。
本文介绍了四种常见的深度分页优化方案,各方案的特点及适用场景对比如下:
| 优化方案 | 核心思路 | 适用场景 | 限制 |
|---|---|---|---|
| 范围查询 | 记录上一页最后一条 ID,通过 WHERE id > last_id LIMIT n 获取下一页 |
按 ID 排序、允许游标式翻页 | 不支持跳页、非 ID 排序需使用联合游标 |
| 子查询 | 先通过子查询获取起始主键,再根据主键过滤 | 需要支持传统 OFFSET 翻页 | 子查询可能产生临时表、依赖排序字段的索引 |
| 延迟关联 | 用 INNER JOIN 将分页转移到主键索引,减少回表 |
大数据量分页、需要传统翻页逻辑 | SQL 相对复杂 |
| 覆盖索引 | 建立包含查询字段的联合索引,避免回表 | 查询字段固定、可建立合适索引 | 字段较多时索引维护成本高、大结果集可能走全表扫描 |
方案选择建议:
- 优先使用延迟关联:对于大多数需要支持传统
LIMIT offset, size翻页逻辑的场景,延迟关联是性能和可维护性较好的选择。 - 考虑范围查询(游标分页):如果业务允许使用"下一页"式的游标翻页(如社交媒体 feed 流、无限滚动),范围查询性能最佳且稳定。
- 覆盖索引作为补充:当查询字段固定且数量不多时,可配合其他方案建立覆盖索引进一步优化。
注意事项:
- 无论采用哪种方案,都应注意监控实际执行计划(
EXPLAIN),确保优化器按预期使用索引。 - 对于超深分页(如百万级偏移量),应从业务层面评估是否真的需要支持,考虑限制最大翻页数或采用其他检索方式(如搜索引擎)。
- 聊聊如何解决 MySQL 深分页问题 - 捡田螺的小男孩:https://juejin.cn/post/7012016858379321358
- 数据库深分页介绍及优化方案 - 京东零售技术:https://mp.weixin.qq.com/s/ZEwGKvRCyvAgGlmeseAS7g
- MySQL 深分页优化 - 得物技术:https://juejin.cn/post/6985478936683610149