 +
**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
-
+
**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
- +
**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
@@ -32,7 +32,7 @@
### 经典
-
+
**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
@@ -32,7 +32,7 @@
### 经典
- +
**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
@@ -42,7 +42,7 @@
> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
-
+
**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
@@ -42,7 +42,7 @@
> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
- +
**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
@@ -50,15 +50,13 @@
很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
-
-
-
+
**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
@@ -50,15 +50,13 @@
很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
-
-
- +
**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
-
+
**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
- +
**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
@@ -80,15 +78,13 @@
-
+
**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
@@ -80,15 +78,13 @@
- +
**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
-
-
-
+
**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
-
-
- +
diff --git "a/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md" "b/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
index 5f001636c4a..f6ede78512e 100644
--- "a/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
+++ "b/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
@@ -332,7 +332,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
-
+
diff --git "a/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md" "b/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
index 5f001636c4a..f6ede78512e 100644
--- "a/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
+++ "b/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
@@ -332,7 +332,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
- +
### 3.3 标记-整理算法
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index e55612460b6..59c1484834a 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -1,1119 +1,305 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
-
-
-
-
-
-
-- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
- - [1.synchronized 关键字](#1synchronized-关键字)
- - [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
- - [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
- - [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
- - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
- - [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
- - [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
- - [1.3.3.总结](#133总结)
- - [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
- - [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
- - [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
- - [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
- - [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
- - [2. volatile 关键字](#2-volatile-关键字)
- - [2.1. CPU 缓存模型](#21-cpu-缓存模型)
- - [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
- - [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
- - [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
- - [3. ThreadLocal](#3-threadlocal)
- - [3.1. ThreadLocal 简介](#31-threadlocal-简介)
- - [3.2. ThreadLocal 示例](#32-threadlocal-示例)
- - [3.3. ThreadLocal 原理](#33-threadlocal-原理)
- - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
- - [4. 线程池](#4-线程池)
- - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
- - [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
- - [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
- - [4.4. 如何创建线程池](#44-如何创建线程池)
- - [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
- - [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
- - [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
- - [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
- - [4.7 线程池原理分析](#47-线程池原理分析)
- - [5. Atomic 原子类](#5-atomic-原子类)
- - [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
- - [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
- - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
- - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
- - [6. AQS](#6-aqs)
- - [6.1. AQS 介绍](#61-aqs-介绍)
- - [6.2. AQS 原理分析](#62-aqs-原理分析)
- - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
- - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
- - [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
- - [6.3. AQS 组件总结](#63-aqs-组件总结)
- - [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
- - [7 Reference](#7-reference)
- - [公众号](#公众号)
-
-
-
-
-# Java 并发进阶常见面试题总结
-
-## 1.synchronized 关键字
-
-
-
-### 1.1.说一说自己对于 synchronized 关键字的了解
-
-**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
-
-另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
-
-**为什么呢?**
-
-因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
-
-庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-
-所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 synchronized 关键字。
-
-### 1.2. 说说自己是怎么使用 synchronized 关键字
-
-**synchronized 关键字最主要的三种使用方式:**
-
-**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+
-```java
-synchronized void method() {
- //业务代码
-}
-```
-
-**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
-
-```java
-synchronized void staic method() {
- //业务代码
-}
-```
-
-**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
-
-```java
-synchronized(this) {
- //业务代码
-}
-```
-
-**总结:**
-
-- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
-- `synchronized` 关键字加到实例方法上是给对象实例上锁。
-- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
-
-下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
-
-面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
-
-**双重校验锁实现对象单例(线程安全)**
-
-```java
-public class Singleton {
-
- private volatile static Singleton uniqueInstance;
-
- private Singleton() {
- }
-
- public static Singleton getUniqueInstance() {
- //先判断对象是否已经实例过,没有实例化过才进入加锁代码
- if (uniqueInstance == null) {
- //类对象加锁
- synchronized (Singleton.class) {
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
+- [Java 并发基础常见面试题总结](#java-并发基础常见面试题总结)
+ - [1. 什么是线程和进程?](#1-什么是线程和进程)
+ - [1.1. 何为进程?](#11-何为进程)
+ - [1.2. 何为线程?](#12-何为线程)
+ - [2. 请简要描述线程与进程的关系,区别及优缺点?](#2-请简要描述线程与进程的关系区别及优缺点)
+ - [2.1. 图解进程和线程的关系](#21-图解进程和线程的关系)
+ - [2.2. 程序计数器为什么是私有的?](#22-程序计数器为什么是私有的)
+ - [2.3. 虚拟机栈和本地方法栈为什么是私有的?](#23-虚拟机栈和本地方法栈为什么是私有的)
+ - [2.4. 一句话简单了解堆和方法区](#24-一句话简单了解堆和方法区)
+ - [3. 说说并发与并行的区别?](#3-说说并发与并行的区别)
+ - [4. 为什么要使用多线程呢?](#4-为什么要使用多线程呢)
+ - [5. 使用多线程可能带来什么问题?](#5-使用多线程可能带来什么问题)
+ - [6. 说说线程的生命周期和状态?](#6-说说线程的生命周期和状态)
+ - [7. 什么是上下文切换?](#7-什么是上下文切换)
+ - [8. 什么是线程死锁?如何避免死锁?](#8-什么是线程死锁如何避免死锁)
+ - [8.1. 认识线程死锁](#81-认识线程死锁)
+ - [8.2. 如何避免线程死锁?](#82-如何避免线程死锁)
+ - [9. 说说 sleep() 方法和 wait() 方法区别和共同点?](#9-说说-sleep-方法和-wait-方法区别和共同点)
+ - [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
+ - [公众号](#公众号)
-另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
+
-`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
+# Java 并发基础常见面试题总结
-1. 为 `uniqueInstance` 分配内存空间
-2. 初始化 `uniqueInstance`
-3. 将 `uniqueInstance` 指向分配的内存地址
+## 1. 什么是线程和进程?
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
+### 1.1. 何为进程?
-使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
-### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
+在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
-先说结论:**构造方法不能使用 synchronized 关键字修饰。**
+如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
-构造方法本身就属于线程安全的,不存在同步的构造方法一说。
+
-### 1.3. 讲一下 synchronized 关键字的底层原理
+### 1.2. 何为线程?
-**synchronized 关键字底层原理属于 JVM 层面。**
+线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-#### 1.3.1. synchronized 同步语句块的情况
+Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
```java
-public class SynchronizedDemo {
- public void method() {
- synchronized (this) {
- System.out.println("synchronized 代码块");
+public class MultiThread {
+ public static void main(String[] args) {
+ // 获取 Java 线程管理 MXBean
+ ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
+ // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
+ ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
+ // 遍历线程信息,仅打印线程 ID 和线程名称信息
+ for (ThreadInfo threadInfo : threadInfos) {
+ System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
}
}
}
-
```
-通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
-
-
-
-从上面我们可以看出:
-
-**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
-
-当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
-
-> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
->
-> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
-
-在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
-
-在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
-
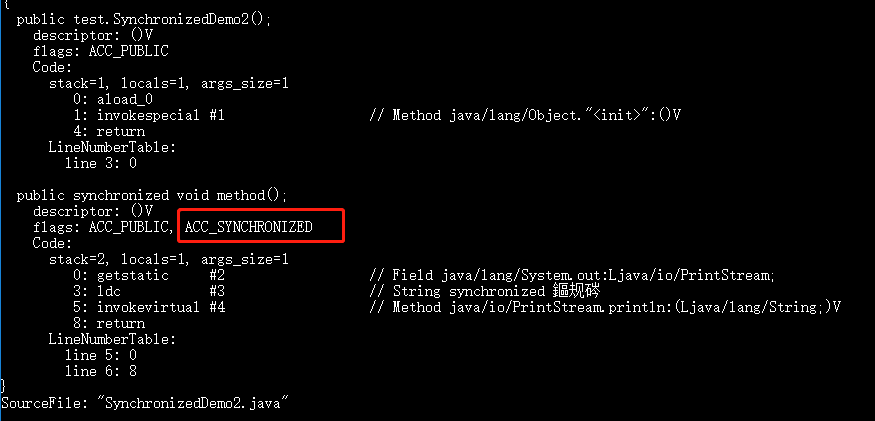
-#### 1.3.2. `synchronized` 修饰方法的的情况
-
-```java
-public class SynchronizedDemo2 {
- public synchronized void method() {
- System.out.println("synchronized 方法");
- }
-}
+上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
```
-
-
-
-`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
-
-#### 1.3.3.总结
-
-`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
-
-`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
-
-**不过两者的本质都是对对象监视器 monitor 的获取。**
-
-### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
-
-JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
-
-锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
-关于这几种优化的详细信息可以查看下面这几篇文章:
-
-- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
-- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
-
-### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
-
-#### 1.5.1. 两者都是可重入锁
-
-**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
-
-#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
-
-`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-
-#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
-
-相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
-
-- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
-
-> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
-
-**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
-
-## 2. volatile 关键字
-
-我们先要从 **CPU 缓存模型** 说起!
-
-### 2.1. CPU 缓存模型
-
-**为什么要弄一个 CPU 高速缓存呢?**
-
-类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
-
-我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
-
-总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
-
-为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
-
-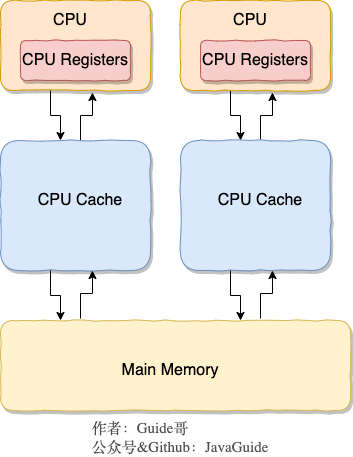
-
-**CPU Cache 的工作方式:**
-
-先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
-
-**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
-
-### 2.2. 讲一下 JMM(Java 内存模型)
-
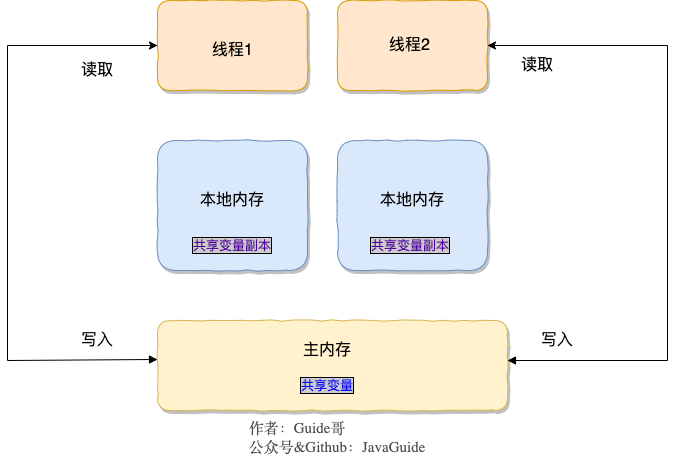
-在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
-
-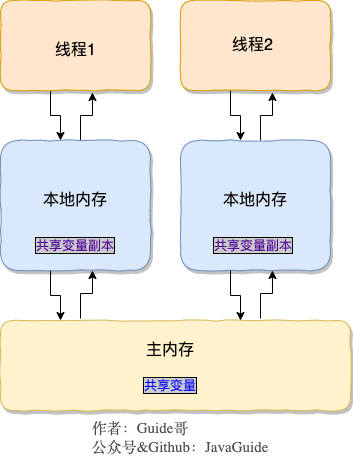
-
-要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
-
-所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
-
-
-
-### 2.3. 并发编程的三个重要特性
-
-1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
-2. **可见性** :当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
-3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
-
-### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
-
-`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
-
-- **volatile 关键字**是线程同步的**轻量级实现**,所以**volatile 性能肯定比 synchronized 关键字要好**。但是**volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块**。
-- **volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。**
-- **volatile 关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性。**
-
-## 3. ThreadLocal
-
-### 3.1. ThreadLocal 简介
-
-通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
-
-**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
-
-再举个简单的例子:
-
-比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
-
-### 3.2. ThreadLocal 示例
-
-相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
-
-```java
-import java.text.SimpleDateFormat;
-import java.util.Random;
-
-public class ThreadLocalExample implements Runnable{
-
- // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
- private static final ThreadLocal
+
### 3.3 标记-整理算法
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index e55612460b6..59c1484834a 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -1,1119 +1,305 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
-
-
-
-
-
-
-- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
- - [1.synchronized 关键字](#1synchronized-关键字)
- - [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
- - [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
- - [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
- - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
- - [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
- - [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
- - [1.3.3.总结](#133总结)
- - [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
- - [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
- - [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
- - [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
- - [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
- - [2. volatile 关键字](#2-volatile-关键字)
- - [2.1. CPU 缓存模型](#21-cpu-缓存模型)
- - [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
- - [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
- - [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
- - [3. ThreadLocal](#3-threadlocal)
- - [3.1. ThreadLocal 简介](#31-threadlocal-简介)
- - [3.2. ThreadLocal 示例](#32-threadlocal-示例)
- - [3.3. ThreadLocal 原理](#33-threadlocal-原理)
- - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
- - [4. 线程池](#4-线程池)
- - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
- - [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
- - [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
- - [4.4. 如何创建线程池](#44-如何创建线程池)
- - [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
- - [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
- - [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
- - [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
- - [4.7 线程池原理分析](#47-线程池原理分析)
- - [5. Atomic 原子类](#5-atomic-原子类)
- - [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
- - [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
- - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
- - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
- - [6. AQS](#6-aqs)
- - [6.1. AQS 介绍](#61-aqs-介绍)
- - [6.2. AQS 原理分析](#62-aqs-原理分析)
- - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
- - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
- - [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
- - [6.3. AQS 组件总结](#63-aqs-组件总结)
- - [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
- - [7 Reference](#7-reference)
- - [公众号](#公众号)
-
-
-
-
-# Java 并发进阶常见面试题总结
-
-## 1.synchronized 关键字
-
-
-
-### 1.1.说一说自己对于 synchronized 关键字的了解
-
-**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
-
-另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
-
-**为什么呢?**
-
-因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
-
-庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-
-所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 synchronized 关键字。
-
-### 1.2. 说说自己是怎么使用 synchronized 关键字
-
-**synchronized 关键字最主要的三种使用方式:**
-
-**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+
-```java
-synchronized void method() {
- //业务代码
-}
-```
-
-**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
-
-```java
-synchronized void staic method() {
- //业务代码
-}
-```
-
-**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
-
-```java
-synchronized(this) {
- //业务代码
-}
-```
-
-**总结:**
-
-- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
-- `synchronized` 关键字加到实例方法上是给对象实例上锁。
-- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
-
-下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
-
-面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
-
-**双重校验锁实现对象单例(线程安全)**
-
-```java
-public class Singleton {
-
- private volatile static Singleton uniqueInstance;
-
- private Singleton() {
- }
-
- public static Singleton getUniqueInstance() {
- //先判断对象是否已经实例过,没有实例化过才进入加锁代码
- if (uniqueInstance == null) {
- //类对象加锁
- synchronized (Singleton.class) {
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
+- [Java 并发基础常见面试题总结](#java-并发基础常见面试题总结)
+ - [1. 什么是线程和进程?](#1-什么是线程和进程)
+ - [1.1. 何为进程?](#11-何为进程)
+ - [1.2. 何为线程?](#12-何为线程)
+ - [2. 请简要描述线程与进程的关系,区别及优缺点?](#2-请简要描述线程与进程的关系区别及优缺点)
+ - [2.1. 图解进程和线程的关系](#21-图解进程和线程的关系)
+ - [2.2. 程序计数器为什么是私有的?](#22-程序计数器为什么是私有的)
+ - [2.3. 虚拟机栈和本地方法栈为什么是私有的?](#23-虚拟机栈和本地方法栈为什么是私有的)
+ - [2.4. 一句话简单了解堆和方法区](#24-一句话简单了解堆和方法区)
+ - [3. 说说并发与并行的区别?](#3-说说并发与并行的区别)
+ - [4. 为什么要使用多线程呢?](#4-为什么要使用多线程呢)
+ - [5. 使用多线程可能带来什么问题?](#5-使用多线程可能带来什么问题)
+ - [6. 说说线程的生命周期和状态?](#6-说说线程的生命周期和状态)
+ - [7. 什么是上下文切换?](#7-什么是上下文切换)
+ - [8. 什么是线程死锁?如何避免死锁?](#8-什么是线程死锁如何避免死锁)
+ - [8.1. 认识线程死锁](#81-认识线程死锁)
+ - [8.2. 如何避免线程死锁?](#82-如何避免线程死锁)
+ - [9. 说说 sleep() 方法和 wait() 方法区别和共同点?](#9-说说-sleep-方法和-wait-方法区别和共同点)
+ - [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
+ - [公众号](#公众号)
-另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
+
-`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
+# Java 并发基础常见面试题总结
-1. 为 `uniqueInstance` 分配内存空间
-2. 初始化 `uniqueInstance`
-3. 将 `uniqueInstance` 指向分配的内存地址
+## 1. 什么是线程和进程?
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
+### 1.1. 何为进程?
-使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
-### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
+在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
-先说结论:**构造方法不能使用 synchronized 关键字修饰。**
+如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
-构造方法本身就属于线程安全的,不存在同步的构造方法一说。
+
-### 1.3. 讲一下 synchronized 关键字的底层原理
+### 1.2. 何为线程?
-**synchronized 关键字底层原理属于 JVM 层面。**
+线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-#### 1.3.1. synchronized 同步语句块的情况
+Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
```java
-public class SynchronizedDemo {
- public void method() {
- synchronized (this) {
- System.out.println("synchronized 代码块");
+public class MultiThread {
+ public static void main(String[] args) {
+ // 获取 Java 线程管理 MXBean
+ ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
+ // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
+ ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
+ // 遍历线程信息,仅打印线程 ID 和线程名称信息
+ for (ThreadInfo threadInfo : threadInfos) {
+ System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
}
}
}
-
```
-通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
-
-
-
-从上面我们可以看出:
-
-**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
-
-当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
-
-> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
->
-> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
-
-在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
-
-在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
-
-#### 1.3.2. `synchronized` 修饰方法的的情况
-
-```java
-public class SynchronizedDemo2 {
- public synchronized void method() {
- System.out.println("synchronized 方法");
- }
-}
+上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
```
-
-
-
-`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
-
-#### 1.3.3.总结
-
-`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
-
-`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
-
-**不过两者的本质都是对对象监视器 monitor 的获取。**
-
-### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
-
-JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
-
-锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
-关于这几种优化的详细信息可以查看下面这几篇文章:
-
-- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
-- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
-
-### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
-
-#### 1.5.1. 两者都是可重入锁
-
-**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
-
-#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
-
-`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-
-#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
-
-相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
-
-- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
-
-> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
-
-**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
-
-## 2. volatile 关键字
-
-我们先要从 **CPU 缓存模型** 说起!
-
-### 2.1. CPU 缓存模型
-
-**为什么要弄一个 CPU 高速缓存呢?**
-
-类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
-
-我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
-
-总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
-
-为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
-
-
-
-**CPU Cache 的工作方式:**
-
-先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
-
-**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
-
-### 2.2. 讲一下 JMM(Java 内存模型)
-
-在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
-
-
-
-要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
-
-所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
-
-
-
-### 2.3. 并发编程的三个重要特性
-
-1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
-2. **可见性** :当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
-3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
-
-### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
-
-`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
-
-- **volatile 关键字**是线程同步的**轻量级实现**,所以**volatile 性能肯定比 synchronized 关键字要好**。但是**volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块**。
-- **volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。**
-- **volatile 关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性。**
-
-## 3. ThreadLocal
-
-### 3.1. ThreadLocal 简介
-
-通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
-
-**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
-
-再举个简单的例子:
-
-比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
-
-### 3.2. ThreadLocal 示例
-
-相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
-
-```java
-import java.text.SimpleDateFormat;
-import java.util.Random;
-
-public class ThreadLocalExample implements Runnable{
-
- // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
- private static final ThreadLocal +
-
+
- -
- -
- -
-### CPU
-
-针对应用程序,我们通常关注的是内核CPU调度器功能和性能。
-
-线程的状态分析主要是分析线程的时间用在什么地方,而线程状态的分类一般分为:
-
-a. on-CPU:执行中,执行中的时间通常又分为用户态时间user和系统态时间sys。
- b. off-CPU:等待下一轮上CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡 眠、锁、空闲等状态。
-
-#### **分析工具**
-
-| 工具 | 描述 |
-| -------- | ------------------------------ |
-| uptime/w | 查看服务器运行时间、平均负载 |
-| top | 监控每个进程的CPU用量分解 |
-| vmstat | 系统的CPU平均负载情况 |
-| mpstat | 查看多核CPU信息 |
-| sar -u | 查看CPU过去或未来时点CPU利用率 |
-| pidstat | 查看每个进程的用量分解 |
-
-#### uptime
-
-uptime 命令可以用来查看服务器已经运行了多久,当前登录的用户有多少,以及服务器在过去的1分钟、5分钟、15分钟的系统平均负载值
-
-
-
-### CPU
-
-针对应用程序,我们通常关注的是内核CPU调度器功能和性能。
-
-线程的状态分析主要是分析线程的时间用在什么地方,而线程状态的分类一般分为:
-
-a. on-CPU:执行中,执行中的时间通常又分为用户态时间user和系统态时间sys。
- b. off-CPU:等待下一轮上CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡 眠、锁、空闲等状态。
-
-#### **分析工具**
-
-| 工具 | 描述 |
-| -------- | ------------------------------ |
-| uptime/w | 查看服务器运行时间、平均负载 |
-| top | 监控每个进程的CPU用量分解 |
-| vmstat | 系统的CPU平均负载情况 |
-| mpstat | 查看多核CPU信息 |
-| sar -u | 查看CPU过去或未来时点CPU利用率 |
-| pidstat | 查看每个进程的用量分解 |
-
-#### uptime
-
-uptime 命令可以用来查看服务器已经运行了多久,当前登录的用户有多少,以及服务器在过去的1分钟、5分钟、15分钟的系统平均负载值
-
- -
-第一项是当前时间,up 表示系统正在运行,6:47是系统启动的总时间,最后是系统的负载load信息
-
-w 同上,增加了具体登陆了那些用户及登陆时间。
-
-#### top
-
-常用来监控[Linux](http://lib.csdn.net/base/linux)的系统状况,比如cpu、内存的使用,显示系统上正在运行的进程。
-
-
-
-第一项是当前时间,up 表示系统正在运行,6:47是系统启动的总时间,最后是系统的负载load信息
-
-w 同上,增加了具体登陆了那些用户及登陆时间。
-
-#### top
-
-常用来监控[Linux](http://lib.csdn.net/base/linux)的系统状况,比如cpu、内存的使用,显示系统上正在运行的进程。
-
- -
-1. **系统运行时间和平均负载:**
-
- top命令的顶部显示与uptime命令相似的输出。
-
- 这些字段显示:
-
- - 当前时间
- - 系统已运行的时间
- - 当前登录用户的数量
- - 相应最近5、10和15分钟内的平均负载。
-
-2. **任务**
-
- 第二行显示的是任务或者进程的总结。进程可以处于不同的状态。这里显示了全部进程的数量。除此之外,还有正在运行、睡眠、停止、僵尸进程的数量(僵尸是一种进程的状态)。这些进程概括信息可以用’t’切换显示。
-
-3. **CPU状态**
-
- 下一行显示的是CPU状态。 这里显示了不同模式下的所占CPU时间的百分比。这些不同的CPU时间表示:
-
- - us, user: 运行(未调整优先级的) 用户进程的CPU时间
- - sy,system: 运行内核进程的CPU时间
- - ni,niced:运行已调整优先级的用户进程的CPU时间
- - wa,IO wait: 用于等待IO完成的CPU时间
- - hi:处理硬件中断的CPU时间
- - si: 处理软件中断的CPU时间
- - st:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)。
-
-4. **内存使用**
-
- 接下来两行显示内存使用率,有点像’free’命令。第一行是物理内存使用,第二行是虚拟内存使用(交换空间)。
-
- 物理内存显示如下:全部可用内存、已使用内存、空闲内存、缓冲内存。相似地:交换部分显示的是:全部、已使用、空闲和缓冲交换空间。
-
- > 这里要说明的是不能用windows的内存概念理解这些数据,如果按windows的方式此台服务器“危矣”:8G的内存总量只剩下530M的可用内存。Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。
- >
- > 第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在[linux](http://lib.csdn.net/base/linux)上free内存会越来越少,但不用为此担心。
- >
- > 如果出于习惯去计算可用内存数,这里有个近似的计算公式:
- >
- > **第四行的free + 第四行的buffers + 第五行的cached。**
- >
- > 对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
-
-5. **字段/列**
-
- | 进程的属性 | 属性含义 |
- | ---------- | ------------------------------------------------------------ |
- | PID | 进程ID,进程的唯一标识符 |
- | USER | 进程所有者的实际用户名。 |
- | PR | 进程的调度优先级。这个字段的一些值是’rt’。这意味这这些进程运行在实时态。 |
- | NI | 进程的nice值(优先级)。越小的值意味着越高的优先级。 |
- | VIRT | 进程使用的虚拟内存。 |
- | RES | 驻留内存大小。驻留内存是任务使用的非交换物理内存大小。 |
- | SHR | SHR是进程使用的共享内存。 |
- | S | 这个是进程的状态。它有以下不同的值:
-
-1. **系统运行时间和平均负载:**
-
- top命令的顶部显示与uptime命令相似的输出。
-
- 这些字段显示:
-
- - 当前时间
- - 系统已运行的时间
- - 当前登录用户的数量
- - 相应最近5、10和15分钟内的平均负载。
-
-2. **任务**
-
- 第二行显示的是任务或者进程的总结。进程可以处于不同的状态。这里显示了全部进程的数量。除此之外,还有正在运行、睡眠、停止、僵尸进程的数量(僵尸是一种进程的状态)。这些进程概括信息可以用’t’切换显示。
-
-3. **CPU状态**
-
- 下一行显示的是CPU状态。 这里显示了不同模式下的所占CPU时间的百分比。这些不同的CPU时间表示:
-
- - us, user: 运行(未调整优先级的) 用户进程的CPU时间
- - sy,system: 运行内核进程的CPU时间
- - ni,niced:运行已调整优先级的用户进程的CPU时间
- - wa,IO wait: 用于等待IO完成的CPU时间
- - hi:处理硬件中断的CPU时间
- - si: 处理软件中断的CPU时间
- - st:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的)。
-
-4. **内存使用**
-
- 接下来两行显示内存使用率,有点像’free’命令。第一行是物理内存使用,第二行是虚拟内存使用(交换空间)。
-
- 物理内存显示如下:全部可用内存、已使用内存、空闲内存、缓冲内存。相似地:交换部分显示的是:全部、已使用、空闲和缓冲交换空间。
-
- > 这里要说明的是不能用windows的内存概念理解这些数据,如果按windows的方式此台服务器“危矣”:8G的内存总量只剩下530M的可用内存。Linux的内存管理有其特殊性,复杂点需要一本书来说明,这里只是简单说点和我们传统概念(windows)的不同。
- >
- > 第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在[linux](http://lib.csdn.net/base/linux)上free内存会越来越少,但不用为此担心。
- >
- > 如果出于习惯去计算可用内存数,这里有个近似的计算公式:
- >
- > **第四行的free + 第四行的buffers + 第五行的cached。**
- >
- > 对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
-
-5. **字段/列**
-
- | 进程的属性 | 属性含义 |
- | ---------- | ------------------------------------------------------------ |
- | PID | 进程ID,进程的唯一标识符 |
- | USER | 进程所有者的实际用户名。 |
- | PR | 进程的调度优先级。这个字段的一些值是’rt’。这意味这这些进程运行在实时态。 |
- | NI | 进程的nice值(优先级)。越小的值意味着越高的优先级。 |
- | VIRT | 进程使用的虚拟内存。 |
- | RES | 驻留内存大小。驻留内存是任务使用的非交换物理内存大小。 |
- | SHR | SHR是进程使用的共享内存。 |
- | S | 这个是进程的状态。它有以下不同的值:D–不可中断的睡眠态、R–运行态、S–睡眠态、T–被跟踪或已停止、Z – 僵尸态 | - | %CPU | 自从上一次更新时到现在任务所使用的CPU时间百分比。 | - | %MEM | 进程使用的可用物理内存百分比。 | - | TIME+ | 任务启动后到现在所使用的全部CPU时间,精确到百分之一秒。 | - | COMMAND | 运行进程所使用的命令。 | - - 还有许多在默认情况下不会显示的输出,它们可以显示进程的页错误、有效组和组ID和其他更多的信息。 - - 常用交互命令: - - ‘B’:一些重要信息会以加粗字体显示(高亮)。这个命令可以切换粗体显示。 - - ‘b’: - - ‘D’或’S‘: 你将被提示输入一个值(以秒为单位),它会以设置的值作为刷新间隔。如果你这里输入了1,top将会每秒刷新。 top默认为3秒刷新 - - ‘l’、‘t’、‘m’: 切换负载、任务、内存信息的显示,这会相应地切换顶部的平均负载、任务/CPU状态和内存信息的概况显示。 - - ‘z’ : 切换彩色显示 - - ‘x’ 或者 ‘y’ - - 切换高亮信息:’x’将排序字段高亮显示(纵列);’y’将运行进程高亮显示(横行)。依赖于你的显示设置,你可能需要让输出彩色来看到这些高亮。 - - ‘u’: 特定用户的进程 - - ‘n’ 或 ‘#’: 任务的数量 - - ‘k’: 结束任务 - - **命令行选项** - - > top //每隔3秒显式所有进程的资源占用情况 - > - > top -u oracle -c //按照用户显示进程、并显示完整命令 - > - > top -d 2 //每隔2秒显式所有进程的资源占用情况 - > - > top -c //每隔3秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名) - > - > top -p 12345 -p 6789//每隔3秒显示pid是12345和pid是6789的两个进程的资源占用情况 - > - > top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数 - > - > top -n 设置显示多少次后就退出 - - **补充** - - top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。 - -#### vmstat - - vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。 - - 一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如: - -
 -
-每个参数的含义:
-
-**Procs(进程)**
-
-| r: | 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1) |
-| ---- | ------------------------------------------------------------ |
-| b | 等待IO的进程数量。 |
-
-**Memory(内存)**
-
-| swpd | 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。 |
-| ----- | ------------------------------------------------------------ |
-| free | 空闲物理内存大小。 |
-| buff | 用作缓冲的内存大小。 |
-| cache | 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。 |
-
-**Swap**
-
-| si | 每秒从交换区写到内存的大小,由磁盘调入内存。 |
-| ---- | -------------------------------------------- |
-| so | 每秒写入交换区的内存大小,由内存调入磁盘。 |
-
-注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。因为linux总是先把内存用光.
-
-**IO**
-
-| bi | 每秒读取的块数 |
-| ---- | -------------- |
-| bo | 每秒写入的块数 |
-
-注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
-
-**system(系统)**
-
-| in | 每秒中断数,包括时钟中断。 |
-| ---- | -------------------------- |
-| cs | 每秒上下文切换数。 |
-
-注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
-
-**CPU(以百分比表示)**
-
-| us | 用户进程执行时间百分比(user time) us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。 |
-| ---- | ------------------------------------------------------------ |
-| sy: | 内核系统进程执行时间百分比(system time) sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 |
-| wa | IO等待时间百分比 wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 |
-| id | 空闲时间百分比 |
-
-#### mpstat
-
- mpstat是一个实时监控工具,主要报告与CPU相关统计信息,在多核心cpu系统中,不仅可以查看cpu平均信息,还可以查看指定cpu信息。
-
-> mpstat -P ALL //查看全部CPU的负载情况。
->
-> mpstat 2 5 //可指定间隔时间和次数。
-
-| CPU: 处理器编号。关键字all表示统计信息计算为所有处理器之间的平均值。 |
-| ------------------------------------------------------------ |
-| %usr: 显示在用户级(应用程序)执行时发生的CPU利用率百分比。 |
-| %nice: 显示以优先级较高的用户级别执行时发生的CPU利用率百分比。 |
-| %sys: 显示在系统级(内核)执行时发生的CPU利用率百分比。请注意,这不包括维护硬件和软件的时间中断。 |
-| %iowait: 显示系统具有未完成磁盘I / O请求的CPU或CPU空闲的时间百分比。 |
-| %irq: 显示CPU或CPU用于服务硬件中断的时间百分比。 |
-| %soft: 显示CPU或CPU用于服务软件中断的时间百分比。 |
-| %steal: 显示虚拟CPU或CPU在管理程序为另一个虚拟处理器提供服务时非自愿等待的时间百分比。 |
-| %guest: 显示CPU或CPU运行虚拟处理器所花费的时间百分比。 |
-
-#### sar
-
-系统活动情况报告,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等
-
-CPU相关:
-
-sar -p (查看全天)
-
-sar -u 1 10 (1:每隔一秒,10:写入10次)
-
-CPU输出项-详细说明
-
-CPU:all 表示统计信息为所有 CPU 的平均值。
-
-%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
-
-%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。
-
-%system:在核心级别(kernel)运行所使用 CPU 总时间的百分比。
-
-%iowait:显示用于等待I/O操作占用 CPU 总时间的百分比。
-
-%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
-
-%idle:显示 CPU 空闲时间占用 CPU 总时间的百分比。
-
-#### pidstat
-
-用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。
-
-pidstat 和 pidstat -u -p ALL 是等效的。
- pidstat 默认显示了所有进程的cpu使用率。
-
-详细说明
-
-PID:进程ID
-
-%usr:进程在用户空间占用cpu的百分比
-
-%system:进程在内核空间占用cpu的百分比
-
-%guest:进程在虚拟机占用cpu的百分比
-
-%CPU:进程占用cpu的百分比
-
-CPU:处理进程的cpu编号
-
-Command:当前进程对应的命令
-
-### 内存
-
-内存是为提高效率而生,实际分析问题的时候,内存出现问题可能不只是影响性能,而是影响服务或者引起其他问题。同样对于内存有些概念需要清楚:
-
-- 主存
-- 虚拟内存
-- 常驻内存
-- 地址空间
-- OOM
-- 页缓存
-- 缺页
-- 换页
-- 交换空间
-- 交换
-- 用户分配器libc、glibc、libmalloc和mtmalloc
-- LINUX内核级SLUB分配器
-
-#### 分析工具
-
-| 工具 | 描述 |
-| ------- | ------------------------------ |
-| free | 查看内存的使用情况 |
-| top | 监控每个进程的内存使用情况 |
-| vmstat | 虚拟内存统计信息 |
-| sar -r | 查看内存 |
-| sar | 查看CPU过去或未来时点CPU利用率 |
-| pidstat | 查看每个进程的内存使用情况 |
-
-#### free
-
-free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
-
-Mem 行(第二行)是内存的使用情况。
- Swap 行(第三行)是交换空间的使用情况。
- total 列显示系统总的可用物理内存和交换空间大小。
- used 列显示已经被使用的物理内存和交换空间。
- free 列显示还有多少物理内存和交换空间可用使用。
- shared 列显示被共享使用的物理内存大小。
- buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
- available 列显示还可以被应用程序使用的物理内存大小。
-
-常用命令:
-
-> free
->
-> free -g 以GB显示
->
-> free -m 以MB显示
->
-> free -h 自动转换展示
->
-> free -h -s 3 有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数
-
-所以从应用程序的角度来说,**available = free + buffer + cache**
-
-可用内存=系统free memory+buffers+cached。
-
-#### top
-
-请参考上面top的详解
-
-#### vmstat
-
-请参考上面vmstat的详解
-
-#### sar
-
-sar -r #查看内存使用情况
-
-详解:
-
-kbmemfree 空闲的物理内存大小
-
-kbmemused 使用中的物理内存大小
-
-%memused 物理内存使用率
-
-kbbuffers 内核中作为缓冲区使用的物理内存大小,kbbuffers和kbcached:这两个值就是free命令中的buffer 和cache.
-
-kbcached 缓存的文件大小
-
-kbcommit 保证当前系统正常运行所需要的最小内存,即为了确保内存不溢出而需要的最少内存(物理内存 +Swap分区)
-
-commt 这个值是kbcommit与内存总量(物理内存+swap分区)的一个百分比的值
-
-#### pidstat
-
-pidstat -r 查看内存使用情况 pidstat将显示各活动进程的内存使用统计
-
-PID:进程标识符
-
-Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页
-
-Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页
-
-VSZ:虚拟地址大小,虚拟内存的使用KB
-
-RSS:常驻集合大小,非交换区五里内存使用KB
-
-Command:task命令名
-
-### 磁盘IO
-
-磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。
-
-在理解磁盘IO之前,同样我们需要理解一些概念,例如:
-
-- 文件系统
-- VFS
-- 文件系统缓存
-- 页缓存page cache
-- 缓冲区高速缓存buffer cache
-- 目录缓存
-- inode
-- inode缓存
-- noop调用策略
-
-#### 分析工具
-
-| 工具 | 描述 |
-| ------- | ---------------------------- |
-| iostat | 磁盘详细统计信息 |
-| iotop | 按进程查看磁盘IO统计信息 |
-| pidstat | 查看每个进程的磁盘IO使用情况 |
-
-#### iostat
-
-iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况
-
-
-
-每个参数的含义:
-
-**Procs(进程)**
-
-| r: | 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1) |
-| ---- | ------------------------------------------------------------ |
-| b | 等待IO的进程数量。 |
-
-**Memory(内存)**
-
-| swpd | 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。 |
-| ----- | ------------------------------------------------------------ |
-| free | 空闲物理内存大小。 |
-| buff | 用作缓冲的内存大小。 |
-| cache | 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。 |
-
-**Swap**
-
-| si | 每秒从交换区写到内存的大小,由磁盘调入内存。 |
-| ---- | -------------------------------------------- |
-| so | 每秒写入交换区的内存大小,由内存调入磁盘。 |
-
-注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。因为linux总是先把内存用光.
-
-**IO**
-
-| bi | 每秒读取的块数 |
-| ---- | -------------- |
-| bo | 每秒写入的块数 |
-
-注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
-
-**system(系统)**
-
-| in | 每秒中断数,包括时钟中断。 |
-| ---- | -------------------------- |
-| cs | 每秒上下文切换数。 |
-
-注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
-
-**CPU(以百分比表示)**
-
-| us | 用户进程执行时间百分比(user time) us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。 |
-| ---- | ------------------------------------------------------------ |
-| sy: | 内核系统进程执行时间百分比(system time) sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 |
-| wa | IO等待时间百分比 wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 |
-| id | 空闲时间百分比 |
-
-#### mpstat
-
- mpstat是一个实时监控工具,主要报告与CPU相关统计信息,在多核心cpu系统中,不仅可以查看cpu平均信息,还可以查看指定cpu信息。
-
-> mpstat -P ALL //查看全部CPU的负载情况。
->
-> mpstat 2 5 //可指定间隔时间和次数。
-
-| CPU: 处理器编号。关键字all表示统计信息计算为所有处理器之间的平均值。 |
-| ------------------------------------------------------------ |
-| %usr: 显示在用户级(应用程序)执行时发生的CPU利用率百分比。 |
-| %nice: 显示以优先级较高的用户级别执行时发生的CPU利用率百分比。 |
-| %sys: 显示在系统级(内核)执行时发生的CPU利用率百分比。请注意,这不包括维护硬件和软件的时间中断。 |
-| %iowait: 显示系统具有未完成磁盘I / O请求的CPU或CPU空闲的时间百分比。 |
-| %irq: 显示CPU或CPU用于服务硬件中断的时间百分比。 |
-| %soft: 显示CPU或CPU用于服务软件中断的时间百分比。 |
-| %steal: 显示虚拟CPU或CPU在管理程序为另一个虚拟处理器提供服务时非自愿等待的时间百分比。 |
-| %guest: 显示CPU或CPU运行虚拟处理器所花费的时间百分比。 |
-
-#### sar
-
-系统活动情况报告,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等
-
-CPU相关:
-
-sar -p (查看全天)
-
-sar -u 1 10 (1:每隔一秒,10:写入10次)
-
-CPU输出项-详细说明
-
-CPU:all 表示统计信息为所有 CPU 的平均值。
-
-%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
-
-%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。
-
-%system:在核心级别(kernel)运行所使用 CPU 总时间的百分比。
-
-%iowait:显示用于等待I/O操作占用 CPU 总时间的百分比。
-
-%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
-
-%idle:显示 CPU 空闲时间占用 CPU 总时间的百分比。
-
-#### pidstat
-
-用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。
-
-pidstat 和 pidstat -u -p ALL 是等效的。
- pidstat 默认显示了所有进程的cpu使用率。
-
-详细说明
-
-PID:进程ID
-
-%usr:进程在用户空间占用cpu的百分比
-
-%system:进程在内核空间占用cpu的百分比
-
-%guest:进程在虚拟机占用cpu的百分比
-
-%CPU:进程占用cpu的百分比
-
-CPU:处理进程的cpu编号
-
-Command:当前进程对应的命令
-
-### 内存
-
-内存是为提高效率而生,实际分析问题的时候,内存出现问题可能不只是影响性能,而是影响服务或者引起其他问题。同样对于内存有些概念需要清楚:
-
-- 主存
-- 虚拟内存
-- 常驻内存
-- 地址空间
-- OOM
-- 页缓存
-- 缺页
-- 换页
-- 交换空间
-- 交换
-- 用户分配器libc、glibc、libmalloc和mtmalloc
-- LINUX内核级SLUB分配器
-
-#### 分析工具
-
-| 工具 | 描述 |
-| ------- | ------------------------------ |
-| free | 查看内存的使用情况 |
-| top | 监控每个进程的内存使用情况 |
-| vmstat | 虚拟内存统计信息 |
-| sar -r | 查看内存 |
-| sar | 查看CPU过去或未来时点CPU利用率 |
-| pidstat | 查看每个进程的内存使用情况 |
-
-#### free
-
-free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
-
-Mem 行(第二行)是内存的使用情况。
- Swap 行(第三行)是交换空间的使用情况。
- total 列显示系统总的可用物理内存和交换空间大小。
- used 列显示已经被使用的物理内存和交换空间。
- free 列显示还有多少物理内存和交换空间可用使用。
- shared 列显示被共享使用的物理内存大小。
- buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
- available 列显示还可以被应用程序使用的物理内存大小。
-
-常用命令:
-
-> free
->
-> free -g 以GB显示
->
-> free -m 以MB显示
->
-> free -h 自动转换展示
->
-> free -h -s 3 有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数
-
-所以从应用程序的角度来说,**available = free + buffer + cache**
-
-可用内存=系统free memory+buffers+cached。
-
-#### top
-
-请参考上面top的详解
-
-#### vmstat
-
-请参考上面vmstat的详解
-
-#### sar
-
-sar -r #查看内存使用情况
-
-详解:
-
-kbmemfree 空闲的物理内存大小
-
-kbmemused 使用中的物理内存大小
-
-%memused 物理内存使用率
-
-kbbuffers 内核中作为缓冲区使用的物理内存大小,kbbuffers和kbcached:这两个值就是free命令中的buffer 和cache.
-
-kbcached 缓存的文件大小
-
-kbcommit 保证当前系统正常运行所需要的最小内存,即为了确保内存不溢出而需要的最少内存(物理内存 +Swap分区)
-
-commt 这个值是kbcommit与内存总量(物理内存+swap分区)的一个百分比的值
-
-#### pidstat
-
-pidstat -r 查看内存使用情况 pidstat将显示各活动进程的内存使用统计
-
-PID:进程标识符
-
-Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页
-
-Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页
-
-VSZ:虚拟地址大小,虚拟内存的使用KB
-
-RSS:常驻集合大小,非交换区五里内存使用KB
-
-Command:task命令名
-
-### 磁盘IO
-
-磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。
-
-在理解磁盘IO之前,同样我们需要理解一些概念,例如:
-
-- 文件系统
-- VFS
-- 文件系统缓存
-- 页缓存page cache
-- 缓冲区高速缓存buffer cache
-- 目录缓存
-- inode
-- inode缓存
-- noop调用策略
-
-#### 分析工具
-
-| 工具 | 描述 |
-| ------- | ---------------------------- |
-| iostat | 磁盘详细统计信息 |
-| iotop | 按进程查看磁盘IO统计信息 |
-| pidstat | 查看每个进程的磁盘IO使用情况 |
-
-#### iostat
-
-iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况
-
- -
-CPU属性
-
-%user:CPU处在用户模式下的时间百分比。
-
-%nice:CPU处在带NICE值的用户模式下的时间百分比。
-
-%system:CPU处在系统模式下的时间百分比。
-
-%iowait:CPU等待输入输出完成时间的百分比。
-
-%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
-
-%idle:CPU空闲时间百分比。
-
-备注:
-
-如果%iowait的值过高,表示硬盘存在I/O瓶颈
-
-如果%idle值高,表示CPU较空闲
-
-如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
-
-如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
-
-Device属性
-
-tps:该设备每秒的传输次数
-
-kB_read/s:每秒从设备(drive expressed)读取的数据量;
-
-kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
-
-kB_read: 读取的总数据量;
-
-kB_wrtn:写入的总数量数据量
-
-常用命令:
-
-iostat 2 3 每隔2秒刷新显示,且显示3次
-
-iostat -m 以M为单位显示所有信息
-
-查看设备使用率(%util)、响应时间(await)
-
-iostat -d -x -k 1 1
-
-#### iotop
-
-在一般运维工作中经常会遇到这么一个场景,服务器的IO负载很高(iostat中的util),但是无法快速的定位到IO负载的来源进程和来源文件导致无法进行相应的策略来解决问题。
-
-如果你想检查那个进程实际在做 I/O,那么运行 `iotop` 命令加上 `-o` 或者 `--only` 参数。
-
-iotop --only
-
-#### pidstat
-
-显示各个进程的IO使用情况
-
-pidstat -d
-
-报告IO统计显示以下信息:
-
-- PID:进程id
-- kB_rd/s:每秒从磁盘读取的KB
-- kB_wr/s:每秒写入磁盘KB
-- kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
-- COMMAND:task的命令名
-
-### 网络
-
-#### 分析工具
-
-| ping | 测试网络的连通性 |
-| -------- | ---------------------------- |
-| netstat | 检验本机各端口的网络连接情况 |
-| hostname | 查看主机和域名 |
-
-#### ping
-
-常用命令参数:
-
--d 使用Socket的SO_DEBUG功能。
-
--f 极限检测。大量且快速地送网络封包给一台机器,看它的回应。
-
--n 只输出数值。
-
--q 不显示任何传送封包的信息,只显示最后的结果。
-
--r 忽略普通的Routing Table,直接将数据包送到远端主机上。通常是查看本机的网络接口是否有问题。
-
--R 记录路由过程。
-
--v 详细显示指令的执行过程。
-
-
-
-CPU属性
-
-%user:CPU处在用户模式下的时间百分比。
-
-%nice:CPU处在带NICE值的用户模式下的时间百分比。
-
-%system:CPU处在系统模式下的时间百分比。
-
-%iowait:CPU等待输入输出完成时间的百分比。
-
-%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
-
-%idle:CPU空闲时间百分比。
-
-备注:
-
-如果%iowait的值过高,表示硬盘存在I/O瓶颈
-
-如果%idle值高,表示CPU较空闲
-
-如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
-
-如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
-
-Device属性
-
-tps:该设备每秒的传输次数
-
-kB_read/s:每秒从设备(drive expressed)读取的数据量;
-
-kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
-
-kB_read: 读取的总数据量;
-
-kB_wrtn:写入的总数量数据量
-
-常用命令:
-
-iostat 2 3 每隔2秒刷新显示,且显示3次
-
-iostat -m 以M为单位显示所有信息
-
-查看设备使用率(%util)、响应时间(await)
-
-iostat -d -x -k 1 1
-
-#### iotop
-
-在一般运维工作中经常会遇到这么一个场景,服务器的IO负载很高(iostat中的util),但是无法快速的定位到IO负载的来源进程和来源文件导致无法进行相应的策略来解决问题。
-
-如果你想检查那个进程实际在做 I/O,那么运行 `iotop` 命令加上 `-o` 或者 `--only` 参数。
-
-iotop --only
-
-#### pidstat
-
-显示各个进程的IO使用情况
-
-pidstat -d
-
-报告IO统计显示以下信息:
-
-- PID:进程id
-- kB_rd/s:每秒从磁盘读取的KB
-- kB_wr/s:每秒写入磁盘KB
-- kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
-- COMMAND:task的命令名
-
-### 网络
-
-#### 分析工具
-
-| ping | 测试网络的连通性 |
-| -------- | ---------------------------- |
-| netstat | 检验本机各端口的网络连接情况 |
-| hostname | 查看主机和域名 |
-
-#### ping
-
-常用命令参数:
-
--d 使用Socket的SO_DEBUG功能。
-
--f 极限检测。大量且快速地送网络封包给一台机器,看它的回应。
-
--n 只输出数值。
-
--q 不显示任何传送封包的信息,只显示最后的结果。
-
--r 忽略普通的Routing Table,直接将数据包送到远端主机上。通常是查看本机的网络接口是否有问题。
-
--R 记录路由过程。
-
--v 详细显示指令的执行过程。
-
--c 数目:在发送指定数目的包后停止。
-
--i 秒数:设定间隔几秒送一个网络封包给一台机器,预设值是一秒送一次。
-
--I 网络界面:使用指定的网络界面送出数据包。
-
--l 前置载入:设置在送出要求信息之前,先行发出的数据包。
-
--p 范本样式:设置填满数据包的范本样式。
-
--s 字节数:指定发送的数据字节数,预设值是56,加上8字节的ICMP头,一共是64ICMP数据字节。
-
--t 存活数值:设置存活数值TTL的大小。
-
-> ping -b 192.168.120.1 --ping网关
->
-> ping -c 10 192.168.120.206 --ping指定次数
->
-> ping -c 10 -i 0.5 192.168.120.206 --时间间隔和次数限制的ping
-
-#### netstat
-
-netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
-
-netstat [选项]
-
-```
--a或--all:显示所有连线中的Socket;
--a (all) 显示所有选项,默认不显示LISTEN相关。
--t (tcp) 仅显示tcp相关选项。
--u (udp) 仅显示udp相关选项。
--n 拒绝显示别名,能显示数字的全部转化成数字。
--l 仅列出有在 Listen (监听) 的服务状态。
--p 显示建立相关链接的程序名
--r 显示路由信息,路由表
--e 显示扩展信息,例如uid等
--s 按各个协议进行统计
--c 每隔一个固定时间,执行该netstat命令。
-```
-
-常用命令:
-
-列出所有端口情况
-
-```
-netstat -a # 列出所有端口
-netstat -at # 列出所有TCP端口
-netstat -au # 列出所有UDP端口
-```
-
-列出所有处于监听状态的 Sockets
-
-```
-netstat -l # 只显示监听端口
-netstat -lt # 显示监听TCP端口
-netstat -lu # 显示监听UDP端口
-netstat -lx # 显示监听UNIX端口
-```
-
-显示每个协议的统计信息
-
-```
-netstat -s # 显示所有端口的统计信息
-netstat -st # 显示所有TCP的统计信息
-netstat -su # 显示所有UDP的统计信息
-```
-
-显示 PID 和进程名称
-
-```
-netstat -p
-```
-
-显示网络统计信息
-
-```
-netstat -s
-```
-
-统计机器中网络连接各个状态个数
-
-```
-netstat` `-an | ``awk` `'/^tcp/ {++S[$NF]} END {for (a in S) print a,S[a]} '
-```
-
-**补充netstat网络状态详解:**
-
-一个正常的TCP连接,都会有三个阶段:1、TCP三次握手;2、数据传送;3、TCP四次挥手
-
- -
-
-
-**TCP的连接释放**
-
-
-
-
-
-**TCP的连接释放**
-
- -
-```
-LISTEN:侦听来自远方的TCP端口的连接请求
-SYN-SENT:再发送连接请求后等待匹配的连接请求(如果有大量这样的状态包,检查是否中招了)
-SYN-RECEIVED:再收到和发送一个连接请求后等待对方对连接请求的确认(如有大量此状态估计被flood攻击了)
-ESTABLISHED:代表一个打开的连接
-FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认
-FIN-WAIT-2:从远程TCP等待连接中断请求
-CLOSE-WAIT:等待从本地用户发来的连接中断请求
-CLOSING:等待远程TCP对连接中断的确认
-LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认(不是什么好东西,此项出现,检查是否被攻击)
-TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认
-CLOSED:没有任何连接状态
-```
-
-------
-
-本文参考的文章: https://rdc.hundsun.com/portal/article/731.html?ref=myread
-
-
-
diff --git a/docs/system-design/authority-certification/basis-of-authority-certification.md b/docs/system-design/authority-certification/basis-of-authority-certification.md
index 86352a50d3f..b576a28cf36 100644
--- a/docs/system-design/authority-certification/basis-of-authority-certification.md
+++ b/docs/system-design/authority-certification/basis-of-authority-certification.md
@@ -105,7 +105,7 @@ public String readAllCookies(HttpServletRequest request) {
花了个图简单总结了一下Session认证涉及的一些东西。
-
-
-```
-LISTEN:侦听来自远方的TCP端口的连接请求
-SYN-SENT:再发送连接请求后等待匹配的连接请求(如果有大量这样的状态包,检查是否中招了)
-SYN-RECEIVED:再收到和发送一个连接请求后等待对方对连接请求的确认(如有大量此状态估计被flood攻击了)
-ESTABLISHED:代表一个打开的连接
-FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认
-FIN-WAIT-2:从远程TCP等待连接中断请求
-CLOSE-WAIT:等待从本地用户发来的连接中断请求
-CLOSING:等待远程TCP对连接中断的确认
-LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认(不是什么好东西,此项出现,检查是否被攻击)
-TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认
-CLOSED:没有任何连接状态
-```
-
-------
-
-本文参考的文章: https://rdc.hundsun.com/portal/article/731.html?ref=myread
-
-
-
diff --git a/docs/system-design/authority-certification/basis-of-authority-certification.md b/docs/system-design/authority-certification/basis-of-authority-certification.md
index 86352a50d3f..b576a28cf36 100644
--- a/docs/system-design/authority-certification/basis-of-authority-certification.md
+++ b/docs/system-design/authority-certification/basis-of-authority-certification.md
@@ -105,7 +105,7 @@ public String readAllCookies(HttpServletRequest request) {
花了个图简单总结了一下Session认证涉及的一些东西。
- +
另外,Spring Session提供了一种跨多个应用程序或实例管理用户会话信息的机制。如果想详细了解可以查看下面几篇很不错的文章:
@@ -192,7 +192,7 @@ OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了
微信支付账户相关参数:
-
+
另外,Spring Session提供了一种跨多个应用程序或实例管理用户会话信息的机制。如果想详细了解可以查看下面几篇很不错的文章:
@@ -192,7 +192,7 @@ OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了
微信支付账户相关参数:
- +
**推荐阅读:**
diff --git a/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.jpeg b/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.jpeg
new file mode 100644
index 00000000000..feca0114904
Binary files /dev/null and b/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.jpeg differ
diff --git a/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.png b/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.png
deleted file mode 100644
index b4ef47acbd3..00000000000
Binary files a/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.png and /dev/null differ
diff --git a/docs/system-design/micro-service/api-gateway-intro.md "b/docs/system-design/distributed-system/api-gateway/\344\270\272\344\273\200\344\271\210\350\246\201\347\275\221\347\253\231\346\234\211\345\223\252\344\272\233\345\270\270\350\247\201\347\232\204\347\275\221\347\253\231\347\263\273\347\273\237.md"
similarity index 100%
rename from docs/system-design/micro-service/api-gateway-intro.md
rename to "docs/system-design/distributed-system/api-gateway/\344\270\272\344\273\200\344\271\210\350\246\201\347\275\221\347\253\231\346\234\211\345\223\252\344\272\233\345\270\270\350\247\201\347\232\204\347\275\221\347\253\231\347\263\273\347\273\237.md"
diff --git "a/docs/system-design/micro-service/API\347\275\221\345\205\263.md" "b/docs/system-design/distributed-system/api-gateway/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\344\272\277\347\272\247\347\275\221\345\205\263.md"
similarity index 100%
rename from "docs/system-design/micro-service/API\347\275\221\345\205\263.md"
rename to "docs/system-design/distributed-system/api-gateway/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\344\272\277\347\272\247\347\275\221\345\205\263.md"
diff --git a/docs/system-design/framework/zookeeper/images/curator.png b/docs/system-design/distributed-system/zookeeper/images/curator.png
similarity index 100%
rename from docs/system-design/framework/zookeeper/images/curator.png
rename to docs/system-design/distributed-system/zookeeper/images/curator.png
diff --git "a/docs/system-design/framework/zookeeper/images/watche\346\234\272\345\210\266.png" "b/docs/system-design/distributed-system/zookeeper/images/watche\346\234\272\345\210\266.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/watche\346\234\272\345\210\266.png"
rename to "docs/system-design/distributed-system/zookeeper/images/watche\346\234\272\345\210\266.png"
diff --git a/docs/system-design/framework/zookeeper/images/znode-structure.png b/docs/system-design/distributed-system/zookeeper/images/znode-structure.png
similarity index 100%
rename from docs/system-design/framework/zookeeper/images/znode-structure.png
rename to docs/system-design/distributed-system/zookeeper/images/znode-structure.png
diff --git "a/docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244.png" "b/docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
rename to "docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
diff --git "a/docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png" "b/docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
rename to "docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
diff --git "a/docs/system-design/framework/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png" "b/docs/system-design/distributed-system/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
rename to "docs/system-design/distributed-system/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
diff --git a/docs/system-design/framework/zookeeper/zookeeper-in-action.md b/docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md
similarity index 100%
rename from docs/system-design/framework/zookeeper/zookeeper-in-action.md
rename to docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md
diff --git a/docs/system-design/framework/zookeeper/zookeeper-intro.md b/docs/system-design/distributed-system/zookeeper/zookeeper-intro.md
similarity index 100%
rename from docs/system-design/framework/zookeeper/zookeeper-intro.md
rename to docs/system-design/distributed-system/zookeeper/zookeeper-intro.md
diff --git a/docs/system-design/framework/zookeeper/zookeeper-plus.md b/docs/system-design/distributed-system/zookeeper/zookeeper-plus.md
similarity index 100%
rename from docs/system-design/framework/zookeeper/zookeeper-plus.md
rename to docs/system-design/distributed-system/zookeeper/zookeeper-plus.md
diff --git a/docs/system-design/framework/spring/Spring-Design-Patterns.md b/docs/system-design/framework/spring/Spring-Design-Patterns.md
index b37e318b1d7..c5d56ff6d37 100644
--- a/docs/system-design/framework/spring/Spring-Design-Patterns.md
+++ b/docs/system-design/framework/spring/Spring-Design-Patterns.md
@@ -154,8 +154,6 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
模板方法模式是一种行为设计模式,它定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤的实现方式。
-
-
```java
public abstract class Template {
//这是我们的模板方法
diff --git a/docs/system-design/framework/spring/spring-transaction.md "b/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
similarity index 99%
rename from docs/system-design/framework/spring/spring-transaction.md
rename to "docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
index f465cd0c951..1e82a2aae38 100644
--- a/docs/system-design/framework/spring/spring-transaction.md
+++ "b/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
@@ -179,7 +179,7 @@ public interface PlatformTransactionManager {
主要是因为要将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。我前段时间分享过:**“为什么我们要用接口?”**
-
+
**推荐阅读:**
diff --git a/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.jpeg b/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.jpeg
new file mode 100644
index 00000000000..feca0114904
Binary files /dev/null and b/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.jpeg differ
diff --git a/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.png b/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.png
deleted file mode 100644
index b4ef47acbd3..00000000000
Binary files a/docs/system-design/authority-certification/images/basis-of-authority-certification/session-cookie-intro.png and /dev/null differ
diff --git a/docs/system-design/micro-service/api-gateway-intro.md "b/docs/system-design/distributed-system/api-gateway/\344\270\272\344\273\200\344\271\210\350\246\201\347\275\221\347\253\231\346\234\211\345\223\252\344\272\233\345\270\270\350\247\201\347\232\204\347\275\221\347\253\231\347\263\273\347\273\237.md"
similarity index 100%
rename from docs/system-design/micro-service/api-gateway-intro.md
rename to "docs/system-design/distributed-system/api-gateway/\344\270\272\344\273\200\344\271\210\350\246\201\347\275\221\347\253\231\346\234\211\345\223\252\344\272\233\345\270\270\350\247\201\347\232\204\347\275\221\347\253\231\347\263\273\347\273\237.md"
diff --git "a/docs/system-design/micro-service/API\347\275\221\345\205\263.md" "b/docs/system-design/distributed-system/api-gateway/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\344\272\277\347\272\247\347\275\221\345\205\263.md"
similarity index 100%
rename from "docs/system-design/micro-service/API\347\275\221\345\205\263.md"
rename to "docs/system-design/distributed-system/api-gateway/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\344\272\277\347\272\247\347\275\221\345\205\263.md"
diff --git a/docs/system-design/framework/zookeeper/images/curator.png b/docs/system-design/distributed-system/zookeeper/images/curator.png
similarity index 100%
rename from docs/system-design/framework/zookeeper/images/curator.png
rename to docs/system-design/distributed-system/zookeeper/images/curator.png
diff --git "a/docs/system-design/framework/zookeeper/images/watche\346\234\272\345\210\266.png" "b/docs/system-design/distributed-system/zookeeper/images/watche\346\234\272\345\210\266.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/watche\346\234\272\345\210\266.png"
rename to "docs/system-design/distributed-system/zookeeper/images/watche\346\234\272\345\210\266.png"
diff --git a/docs/system-design/framework/zookeeper/images/znode-structure.png b/docs/system-design/distributed-system/zookeeper/images/znode-structure.png
similarity index 100%
rename from docs/system-design/framework/zookeeper/images/znode-structure.png
rename to docs/system-design/distributed-system/zookeeper/images/znode-structure.png
diff --git "a/docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244.png" "b/docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
rename to "docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244.png"
diff --git "a/docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png" "b/docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
rename to "docs/system-design/distributed-system/zookeeper/images/zookeeper\351\233\206\347\276\244\344\270\255\347\232\204\350\247\222\350\211\262.png"
diff --git "a/docs/system-design/framework/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png" "b/docs/system-design/distributed-system/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
similarity index 100%
rename from "docs/system-design/framework/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
rename to "docs/system-design/distributed-system/zookeeper/images/\350\277\236\346\216\245ZooKeeper\346\234\215\345\212\241.png"
diff --git a/docs/system-design/framework/zookeeper/zookeeper-in-action.md b/docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md
similarity index 100%
rename from docs/system-design/framework/zookeeper/zookeeper-in-action.md
rename to docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md
diff --git a/docs/system-design/framework/zookeeper/zookeeper-intro.md b/docs/system-design/distributed-system/zookeeper/zookeeper-intro.md
similarity index 100%
rename from docs/system-design/framework/zookeeper/zookeeper-intro.md
rename to docs/system-design/distributed-system/zookeeper/zookeeper-intro.md
diff --git a/docs/system-design/framework/zookeeper/zookeeper-plus.md b/docs/system-design/distributed-system/zookeeper/zookeeper-plus.md
similarity index 100%
rename from docs/system-design/framework/zookeeper/zookeeper-plus.md
rename to docs/system-design/distributed-system/zookeeper/zookeeper-plus.md
diff --git a/docs/system-design/framework/spring/Spring-Design-Patterns.md b/docs/system-design/framework/spring/Spring-Design-Patterns.md
index b37e318b1d7..c5d56ff6d37 100644
--- a/docs/system-design/framework/spring/Spring-Design-Patterns.md
+++ b/docs/system-design/framework/spring/Spring-Design-Patterns.md
@@ -154,8 +154,6 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
模板方法模式是一种行为设计模式,它定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤的实现方式。
-
-
```java
public abstract class Template {
//这是我们的模板方法
diff --git a/docs/system-design/framework/spring/spring-transaction.md "b/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
similarity index 99%
rename from docs/system-design/framework/spring/spring-transaction.md
rename to "docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
index f465cd0c951..1e82a2aae38 100644
--- a/docs/system-design/framework/spring/spring-transaction.md
+++ "b/docs/system-design/framework/spring/Spring\344\272\213\345\212\241\346\200\273\347\273\223.md"
@@ -179,7 +179,7 @@ public interface PlatformTransactionManager {
主要是因为要将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。我前段时间分享过:**“为什么我们要用接口?”**
- +
#### 3.2.2. TransactionDefinition:事务属性
diff --git a/docs/system-design/framework/spring/SpringInterviewQuestions.md "b/docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md"
similarity index 100%
rename from docs/system-design/framework/spring/SpringInterviewQuestions.md
rename to "docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md"
diff --git a/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png b/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png
deleted file mode 100644
index d868e0515cb..00000000000
Binary files a/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png and /dev/null differ
diff --git "a/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png" "b/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png"
new file mode 100644
index 00000000000..eb7e6748411
Binary files /dev/null and "b/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png" differ
diff --git "a/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md" "b/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md"
index e69de29bb2d..770ffd62a90 100644
--- "a/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md"
+++ "b/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md"
@@ -0,0 +1,50 @@
+## 简介
+
+**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+
+## BASE 理论的核心思想
+
+即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
+
+**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。**
+
+**为什么这样说呢?**
+
+CAP 理论这节我们也说过了:
+
+> 如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。因此,**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+
+因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。
+
+## BASE 理论三要素
+
+
+
+### 1. 基本可用
+
+基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
+
+**什么叫允许损失部分可用性呢?**
+
+- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
+- **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
+
+### 2. 软状态
+
+软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
+
+### 3. 最终一致性
+
+最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
+
+> 分布式一致性的 3 种级别:
+>
+> 1. **强一致性** :系统写入了什么,读出来的就是什么。
+> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
+> 3. **最终一致性** :弱一致性的升级版。,系统会保证在一定时间内达到数据一致的状态,
+>
+> 业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
+
+## 总结
+
+**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。**
\ No newline at end of file
diff --git "a/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md" "b/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md"
index 381cda57ed7..32993c3f80a 100644
--- "a/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md"
+++ "b/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md"
@@ -12,15 +12,21 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细
- **一致性(Consistence)** : 所有节点访问同一份最新的数据副本
- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
-- **分区容错性(Partition tolerance)** : 分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供服务。
+- **分区容错性(Partition tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。现在的分布式系统具有更多特性比如扩展性、可用性等等,在进行系统设计和开发时,我们不应该仅仅局限在 CAP 问题上。
+**什么是网络分区?**
+
+> 分布式系统中,多个节点之前的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫网络分区。
+
## 不是所谓的“3 选 2”
大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
+>
+> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。**
@@ -38,7 +44,7 @@ CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
-
+
#### 3.2.2. TransactionDefinition:事务属性
diff --git a/docs/system-design/framework/spring/SpringInterviewQuestions.md "b/docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md"
similarity index 100%
rename from docs/system-design/framework/spring/SpringInterviewQuestions.md
rename to "docs/system-design/framework/spring/Spring\345\270\270\350\247\201\351\227\256\351\242\230\346\200\273\347\273\223.md"
diff --git a/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png b/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png
deleted file mode 100644
index d868e0515cb..00000000000
Binary files a/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png and /dev/null differ
diff --git "a/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png" "b/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png"
new file mode 100644
index 00000000000..eb7e6748411
Binary files /dev/null and "b/docs/system-design/framework/spring/images/spring-transaction/\346\216\245\345\217\243\344\275\277\347\224\250\345\216\237\345\233\240.png" differ
diff --git "a/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md" "b/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md"
index e69de29bb2d..770ffd62a90 100644
--- "a/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md"
+++ "b/docs/system-design/high-availability/BASE\347\220\206\350\256\272.md"
@@ -0,0 +1,50 @@
+## 简介
+
+**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+
+## BASE 理论的核心思想
+
+即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
+
+**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。**
+
+**为什么这样说呢?**
+
+CAP 理论这节我们也说过了:
+
+> 如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。因此,**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+
+因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。
+
+## BASE 理论三要素
+
+
+
+### 1. 基本可用
+
+基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
+
+**什么叫允许损失部分可用性呢?**
+
+- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
+- **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
+
+### 2. 软状态
+
+软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
+
+### 3. 最终一致性
+
+最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
+
+> 分布式一致性的 3 种级别:
+>
+> 1. **强一致性** :系统写入了什么,读出来的就是什么。
+> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
+> 3. **最终一致性** :弱一致性的升级版。,系统会保证在一定时间内达到数据一致的状态,
+>
+> 业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
+
+## 总结
+
+**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。**
\ No newline at end of file
diff --git "a/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md" "b/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md"
index 381cda57ed7..32993c3f80a 100644
--- "a/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md"
+++ "b/docs/system-design/high-availability/CAP\347\220\206\350\256\272.md"
@@ -12,15 +12,21 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细
- **一致性(Consistence)** : 所有节点访问同一份最新的数据副本
- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
-- **分区容错性(Partition tolerance)** : 分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供服务。
+- **分区容错性(Partition tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。现在的分布式系统具有更多特性比如扩展性、可用性等等,在进行系统设计和开发时,我们不应该仅仅局限在 CAP 问题上。
+**什么是网络分区?**
+
+> 分布式系统中,多个节点之前的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫网络分区。
+
## 不是所谓的“3 选 2”
大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
+>
+> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。**
@@ -38,7 +44,7 @@ CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
- +
常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
diff --git a/docs/system-design/high-availability/images/cap/cap.png b/docs/system-design/high-availability/images/cap/cap.png
index 4ac6504d1a0..64ffddcace3 100644
Binary files a/docs/system-design/high-availability/images/cap/cap.png and b/docs/system-design/high-availability/images/cap/cap.png differ
diff --git a/docs/system-design/high-availability/images/cap/dubbo-architecture.png b/docs/system-design/high-availability/images/cap/dubbo-architecture.png
index 530fd53ff5d..e00cd474aac 100644
Binary files a/docs/system-design/high-availability/images/cap/dubbo-architecture.png and b/docs/system-design/high-availability/images/cap/dubbo-architecture.png differ
diff --git "a/docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\357\274\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271\357\274\237.md" "b/docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271.md"
similarity index 100%
rename from "docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\357\274\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271\357\274\237.md"
rename to "docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271.md"
diff --git a/index.html b/index.html
index 974e7e7ee83..6b0768a5feb 100644
--- a/index.html
+++ b/index.html
@@ -8,11 +8,16 @@
-
+
+
+
常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
diff --git a/docs/system-design/high-availability/images/cap/cap.png b/docs/system-design/high-availability/images/cap/cap.png
index 4ac6504d1a0..64ffddcace3 100644
Binary files a/docs/system-design/high-availability/images/cap/cap.png and b/docs/system-design/high-availability/images/cap/cap.png differ
diff --git a/docs/system-design/high-availability/images/cap/dubbo-architecture.png b/docs/system-design/high-availability/images/cap/dubbo-architecture.png
index 530fd53ff5d..e00cd474aac 100644
Binary files a/docs/system-design/high-availability/images/cap/dubbo-architecture.png and b/docs/system-design/high-availability/images/cap/dubbo-architecture.png differ
diff --git "a/docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\357\274\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271\357\274\237.md" "b/docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271.md"
similarity index 100%
rename from "docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\357\274\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271\357\274\237.md"
rename to "docs/system-design/high-availability/\345\246\202\344\275\225\350\256\276\350\256\241\344\270\200\344\270\252\351\253\230\345\217\257\347\224\250\347\263\273\347\273\237\350\246\201\350\200\203\350\231\221\345\223\252\344\272\233\345\234\260\346\226\271.md"
diff --git a/index.html b/index.html
index 974e7e7ee83..6b0768a5feb 100644
--- a/index.html
+++ b/index.html
@@ -8,11 +8,16 @@
-
+
+