https://www.corejavaguru.com/java/serialization/interview-questions-1
- -### Java 序列化中如果有些字段不想进行序列化,怎么办? - -`对于不想进行序列化的变量,使用`transient`关键字修饰。` - -`transient` 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 `transient` 修饰的变量值不会被持久化和恢复。`transient` 只能修饰变量,不能修饰类和方法。 - -### 获取用键盘输入常用的两种方法 - -方法 1:通过 `Scanner` - -```java -Scanner input = new Scanner(System.in); -String s = input.nextLine(); -input.close(); -``` - -方法 2:通过 `BufferedReader` - -```java -BufferedReader input = new BufferedReader(new InputStreamReader(System.in)); -String s = input.readLine(); -``` -### Java 中 IO 流分为几种? - -- 按照流的流向分,可以分为输入流和输出流; -- 按照操作单元划分,可以划分为字节流和字符流; -- 按照流的角色划分为节点流和处理流。 - -Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。 - -- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。 -- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。 - -按操作方式分类结构图: - -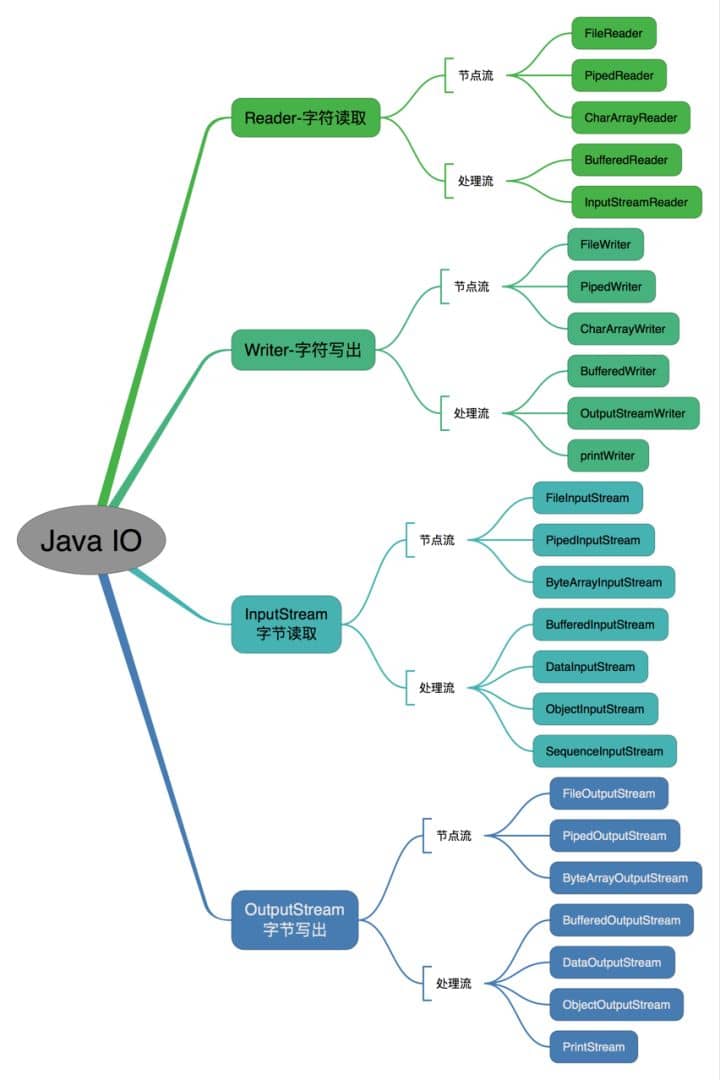 - -按操作对象分类结构图: - -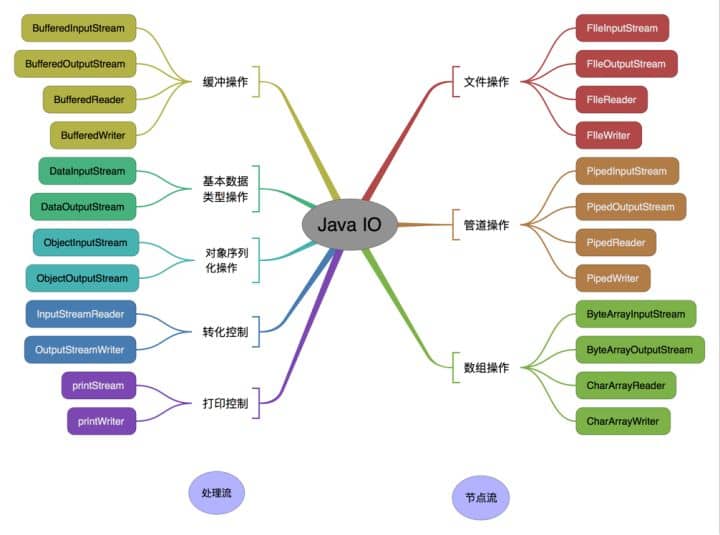 - -### 既然有了字节流,为什么还要有字符流? - -问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?** - -回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。 - -## 4. 参考 - -- https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre -- https://www.educba.com/oracle-vs-openjdk/ -- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk?answertab=active#tab-top## 基础概念与常识 +## 基础概念与常识 ### Java 语言有哪些特点? 1. 简单易学; 2. 面向对象(封装,继承,多态); 3. 平台无关性( Java 虚拟机实现平台无关性); -4. 可靠性; -5. 安全性; -6. 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持); +4. 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持); +5. 可靠性; +6. 安全性; 7. 支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便); 8. 编译与解释并存; @@ -2776,4 +2656,4 @@ Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上 - https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre - https://www.educba.com/oracle-vs-openjdk/ -- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk?answertab=active#tab-top \ No newline at end of file +- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk?answertab=active#tab-top## 基础概念与常识 \ No newline at end of file From c3212de2475a295aba6ca37a1302d77ffa6c823c Mon Sep 17 00:00:00 2001 From: guide图片来自:https://simplesnippets.tech/exception-handling-in-java-part-1/
- -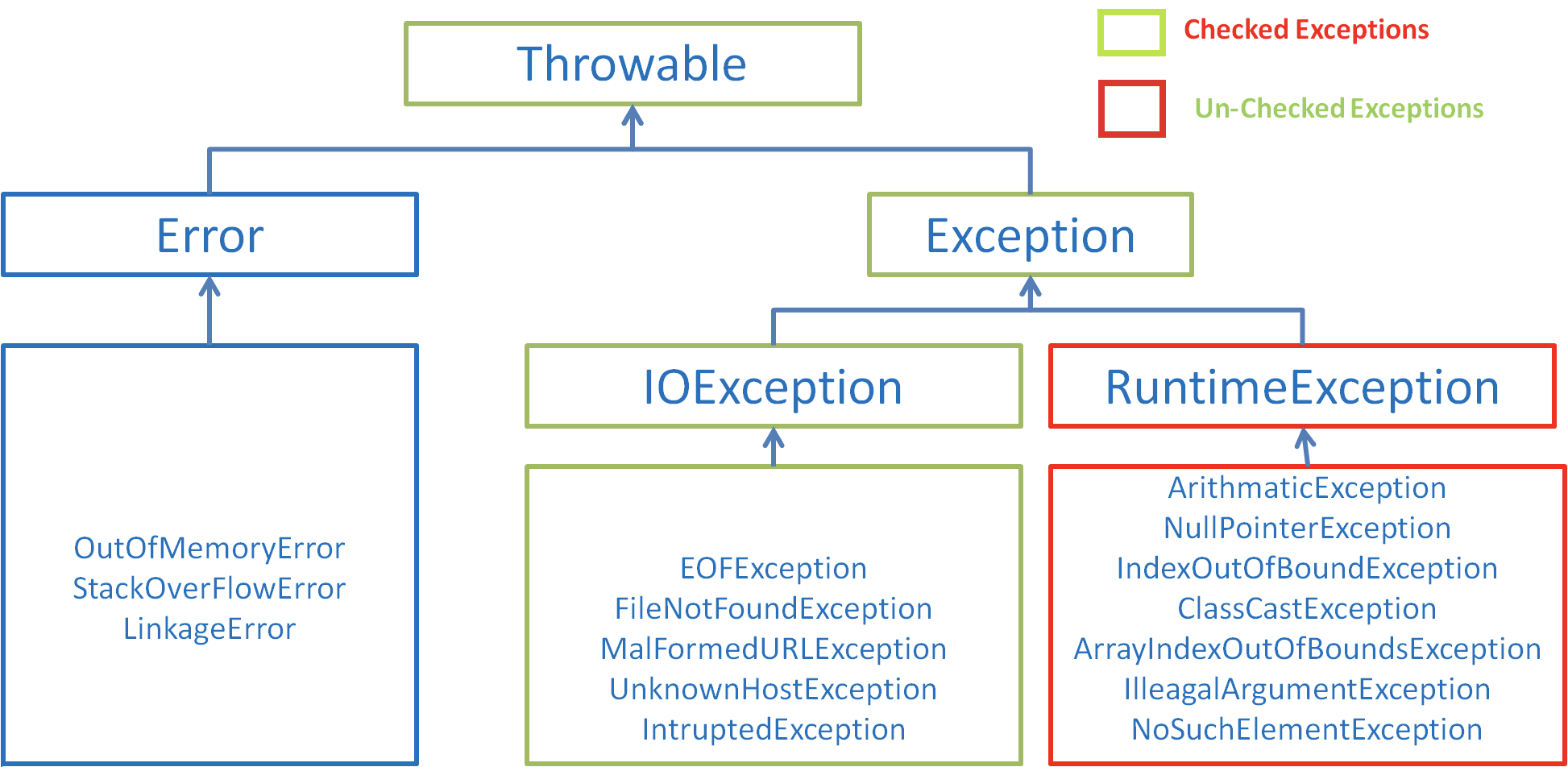 - -图片来自:https://chercher.tech/java-programming/exceptions-java
- -在 Java 中,所有的异常都有一个共同的祖先 `java.lang` 包中的 `Throwable` 类。`Throwable` 类有两个重要的子类 `Exception`(异常)和 `Error`(错误)。`Exception` 能被程序本身处理(`try-catch`), `Error` 是无法处理的(只能尽量避免)。 - -`Exception` 和 `Error` 二者都是 Java 异常处理的重要子类,各自都包含大量子类。 - -- **`Exception`** :程序本身可以处理的异常,可以通过 `catch` 来进行捕获。`Exception` 又可以分为 受检查异常(必须处理) 和 不受检查异常(可以不处理)。 -- **`Error`** :`Error` 属于程序无法处理的错误 ,我们没办法通过 `catch` 来进行捕获 。例如,Java 虚拟机运行错误(`Virtual MachineError`)、虚拟机内存不够错误(`OutOfMemoryError`)、类定义错误(`NoClassDefFoundError`)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。 - -**受检查异常** - -Java 代码在编译过程中,如果受检查异常没有被 `catch`/`throw` 处理的话,就没办法通过编译 。比如下面这段 IO 操作的代码。 - - - -除了`RuntimeException`及其子类以外,其他的`Exception`类及其子类都属于受检查异常 。常见的受检查异常有: IO 相关的异常、`ClassNotFoundException` 、`SQLException`...。 - -**不受检查异常** - -Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。 - -`RuntimeException` 及其子类都统称为非受检查异常,例如:`NullPointerException`、`NumberFormatException`(字符串转换为数字)、`ArrayIndexOutOfBoundsException`(数组越界)、`ClassCastException`(类型转换错误)、`ArithmeticException`(算术错误)等。 - -### Throwable 类常用方法 - -- **`public string getMessage()`**:返回异常发生时的简要描述 -- **`public string toString()`**:返回异常发生时的详细信息 -- **`public string getLocalizedMessage()`**:返回异常对象的本地化信息。使用 `Throwable` 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 `getMessage()`返回的结果相同 -- **`public void printStackTrace()`**:在控制台上打印 `Throwable` 对象封装的异常信息 - -### try-catch-finally - -- **`try`块:** 用于捕获异常。其后可接零个或多个 `catch` 块,如果没有 `catch` 块,则必须跟一个 `finally` 块。 -- **`catch`块:** 用于处理 try 捕获到的异常。 -- **`finally` 块:** 无论是否捕获或处理异常,`finally` 块里的语句都会被执行。当在 `try` 块或 `catch` 块中遇到 `return` 语句时,`finally` 语句块将在方法返回之前被执行。 - -**在以下 3 种特殊情况下,`finally` 块不会被执行:** - -2. 在 `try` 或 `finally`块中用了 `System.exit(int)`退出程序。但是,如果 `System.exit(int)` 在异常语句之后,`finally` 还是会被执行 -3. 程序所在的线程死亡。 -4. 关闭 CPU。 - -下面这部分内容来自 issue: