From 35adb487536569f8ef51a9cd29ae952f98624c3c Mon Sep 17 00:00:00 2001
From: TommyMerlin <786731256@qq.com>
Date: Sat, 19 Jun 2021 11:09:40 +0800
Subject: [PATCH 01/10] =?UTF-8?q?fix=20typo=20=E5=A2=9E=E5=8A=A0=20redis?=
=?UTF-8?q?=20=E9=BB=98=E8=AE=A4=E8=BF=87=E6=9C=9F=E6=97=B6=E9=97=B4?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/database/Redis/redis-all.md | 17 ++++++++---------
1 file changed, 8 insertions(+), 9 deletions(-)
diff --git a/docs/database/Redis/redis-all.md b/docs/database/Redis/redis-all.md
index 8bfda557a2c..bfceaf13842 100644
--- a/docs/database/Redis/redis-all.md
+++ b/docs/database/Redis/redis-all.md
@@ -44,7 +44,7 @@
简单来说 **Redis 就是一个使用 C 语言开发的数据库**,不过与传统数据库不同的是 **Redis 的数据是存在内存中的** ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
-另外,**Redis 除了做缓存之外,Redis 也经常用来做分布式锁,甚至是消息队列。**
+另外,**Redis 除了做缓存之外,也经常用来做分布式锁,甚至是消息队列。**
**Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。**
@@ -54,7 +54,7 @@
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
-分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
+分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用信息的问题。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
### 3. 说一下 Redis 和 Memcached 的区别和共同点
@@ -72,7 +72,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。**
3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
-5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.**
+5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。**
6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 引入了多线程 IO )
7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
8. **Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
@@ -116,7 +116,7 @@ _简单,来说使用缓存主要是为了提升用户体验以及应对更多
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
-所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。
+由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
### 6. Redis 常见数据结构以及使用场景分析
@@ -126,9 +126,9 @@ _简单,来说使用缓存主要是为了提升用户体验以及应对更多
#### 6.1. string
-1. **介绍** :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(simple dynamic string,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
-2. **常用命令:** `set,get,strlen,exists,decr,incr,setex` 等等。
-3. **应用场景** :一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。
+1. **介绍** :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(simple dynamic string,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
+2. **常用命令:** `set,get,strlen,exists,decr,incr,setex` 等等。
+3. **应用场景:** 一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。
下面我们简单看看它的使用!
@@ -162,7 +162,6 @@ OK
**计数器(字符串的内容为整数的时候可以使用):**
```bash
-
127.0.0.1:6379> set number 1
OK
127.0.0.1:6379> incr number # 将 key 中储存的数字值增一
@@ -175,7 +174,7 @@ OK
"1"
```
-**过期**:
+**过期(默认为永不过期)**:
```bash
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
From 4685dd8a5ca4dd34a5774274b2502037a873b151 Mon Sep 17 00:00:00 2001
From: TommyMerlin <786731256@qq.com>
Date: Mon, 21 Jun 2021 16:53:08 +0800
Subject: [PATCH 02/10] fix typo
---
docs/database/Redis/redis-all.md | 41 ++++++++++++++++----------------
1 file changed, 20 insertions(+), 21 deletions(-)
diff --git a/docs/database/Redis/redis-all.md b/docs/database/Redis/redis-all.md
index bfceaf13842..3cd8ff627dc 100644
--- a/docs/database/Redis/redis-all.md
+++ b/docs/database/Redis/redis-all.md
@@ -1,6 +1,5 @@
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
-
@@ -187,8 +186,8 @@ OK
#### 6.2. list
-1. **介绍** :**list** 即是 **链表**。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 **LinkedList**,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
-2. **常用命令:** `rpush,lpop,lpush,rpop,lrange、llen` 等。
+1. **介绍** :**list** 即是 **链表**。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 **LinkedList**,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
+2. **常用命令:** `rpush,lpop,lpush,rpop,lrange,llen` 等。
3. **应用场景:** 发布与订阅或者说消息队列、慢查询。
下面我们简单看看它的使用!
@@ -340,9 +339,9 @@ OK
#### 6.6 bitmap
-1. **介绍 :** bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
+1. **介绍:** bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
2. **常用命令:** `setbit` 、`getbit` 、`bitcount`、`bitop`
-3. **应用场景:** 适合需要保存状态信息(比如是否签到、是否登录...)并需要进一步对这些信息进行分析的场景。比如用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
+3. **应用场景:** 适合需要保存状态信息(比如是否签到、是否登录...)并需要进一步对这些信息进行分析的场景。比如用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
```bash
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
@@ -375,7 +374,7 @@ OK
使用时间作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1
-那么我该如果计算某几天/月/年的活跃用户呢(暂且约定,统计时间内只有有一天在线就称为活跃),有请下一个 redis 的命令
+那么我该如何计算某几天/月/年的活跃用户呢(暂且约定,统计时间内只要有一天在线就称为活跃),有请下一个 redis 的命令
```bash
# 对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。
@@ -414,7 +413,7 @@ BITOP operation destkey key [key ...]
**使用场景三:用户在线状态**
-对于获取或者统计用户在线状态,使用 bitmap 是一个节约空间效率又高的一种方法。
+对于获取或者统计用户在线状态,使用 bitmap 是一个节约空间且效率又高的一种方法。
只需要一个 key,然后用户 ID 为 offset,如果在线就设置为 1,不在线就设置为 0。
@@ -424,17 +423,17 @@ BITOP operation destkey key [key ...]
**既然是单线程,那怎么监听大量的客户端连接呢?**
-Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
+Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
这样的好处非常明显: **I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
-另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件: 1. 文件事件; 2. 时间事件。
+另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件:1. 文件事件; 2. 时间事件。
时间事件不需要多花时间了解,我们接触最多的还是 **文件事件**(客户端进行读取写入等操作,涉及一系列网络通信)。
《Redis 设计与实现》有一段话是如是介绍文件事件的,我觉得写得挺不错。
-> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据 套接字目前执行的任务来为套接字关联不同的事件处理器。
+> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
>
> 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
>
@@ -453,7 +452,7 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
### 8. Redis 没有使用多线程?为什么不使用多线程?
-虽然说 Redis 是单线程模型,但是, 实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+虽然说 Redis 是单线程模型,但是,实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**

@@ -466,14 +465,14 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
我觉得主要原因有下面 3 个:
1. 单线程编程容易并且更容易维护;
-2. Redis 的性能瓶颈不再 CPU ,主要在内存和网络;
+2. Redis 的性能瓶颈不在 CPU ,主要在内存和网络;
3. 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
### 9. Redis6.0 之后为何引入了多线程?
**Redis6.0 引入多线程主要是为了提高网络 IO 读写性能**,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
-虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了, 执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
+虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 `redis.conf` :
@@ -501,7 +500,7 @@ io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的
Redis 自带了给缓存数据设置过期时间的功能,比如:
```bash
-127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
+127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
(integer) 1
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
OK
@@ -509,7 +508,7 @@ OK
(integer) 56
```
-注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间: **
+注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间。 **
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
@@ -548,7 +547,7 @@ typedef struct redisDb {
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
-怎么解决这个问题呢?答案就是: **Redis 内存淘汰机制。**
+怎么解决这个问题呢?答案就是:**Redis 内存淘汰机制。**
### 13. Redis 内存淘汰机制了解么?
@@ -565,7 +564,7 @@ Redis 提供 6 种数据淘汰策略:
4.0 版本后增加以下两种:
-7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
+7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
### 14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
@@ -590,7 +589,7 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
**AOF(append-only file)持久化**
-与快照持久化相比,AOF 持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
+与快照持久化相比,AOF 持久化的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
```conf
appendonly yes
@@ -622,7 +621,7 @@ AOF 重写可以产生一个新的 AOF 文件,这个新的 AOF 文件和原有
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
-在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作
+在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
### 15. Redis 事务
@@ -640,7 +639,7 @@ QUEUED
2) "Guide哥"
```
-使用 [`MULTI`](https://redis.io/commands/multi)命令后可以输入多个命令。Redis 不会立即执行这些命令,而是将它们放到队列,当调用了[`EXEC`](https://redis.io/commands/exec)命令将执行所有命令。
+使用 [`MULTI`](https://redis.io/commands/multi) 命令后可以输入多个命令。Redis 不会立即执行这些命令,而是将它们放到队列,当调用了 [`EXEC`](https://redis.io/commands/exec) 命令将执行所有命令。
这个过程是这样的:
@@ -809,7 +808,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
-2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
+2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
### 19. 参考
From a7a2225f07f373d016d69719f3fc1a35953a2081 Mon Sep 17 00:00:00 2001
From: TommyMerlin <786731256@qq.com>
Date: Mon, 21 Jun 2021 17:05:51 +0800
Subject: [PATCH 03/10] fix typo
---
.../data-structure/bloom-filter.md | 90 +++++++++----------
1 file changed, 45 insertions(+), 45 deletions(-)
diff --git a/docs/dataStructures-algorithms/data-structure/bloom-filter.md b/docs/dataStructures-algorithms/data-structure/bloom-filter.md
index b9d129d28cd..bfb7efe7f03 100644
--- a/docs/dataStructures-algorithms/data-structure/bloom-filter.md
+++ b/docs/dataStructures-algorithms/data-structure/bloom-filter.md
@@ -39,7 +39,7 @@
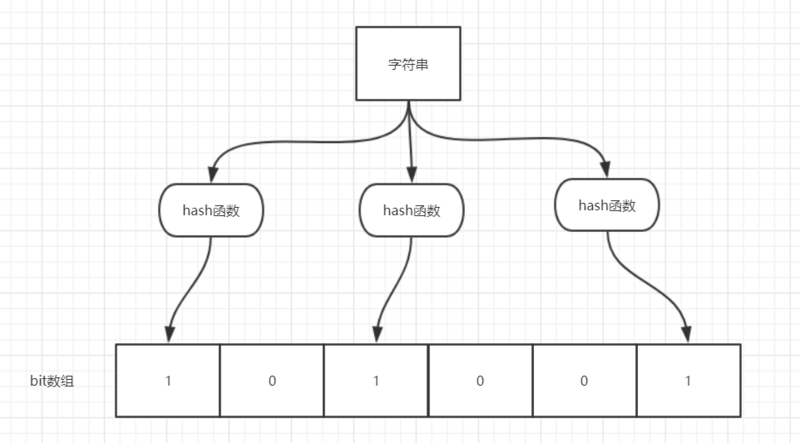
-如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
+如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
@@ -147,15 +147,15 @@ public class MyBloomFilter {
测试:
```java
- String value1 = "https://javaguide.cn/";
- String value2 = "https://github.com/Snailclimb";
- MyBloomFilter filter = new MyBloomFilter();
- System.out.println(filter.contains(value1));
- System.out.println(filter.contains(value2));
- filter.add(value1);
- filter.add(value2);
- System.out.println(filter.contains(value1));
- System.out.println(filter.contains(value2));
+String value1 = "https://javaguide.cn/";
+String value2 = "https://github.com/Snailclimb";
+MyBloomFilter filter = new MyBloomFilter();
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
+filter.add(value1);
+filter.add(value2);
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
```
Output:
@@ -170,15 +170,15 @@ true
测试:
```java
- Integer value1 = 13423;
- Integer value2 = 22131;
- MyBloomFilter filter = new MyBloomFilter();
- System.out.println(filter.contains(value1));
- System.out.println(filter.contains(value2));
- filter.add(value1);
- filter.add(value2);
- System.out.println(filter.contains(value1));
- System.out.println(filter.contains(value2));
+Integer value1 = 13423;
+Integer value2 = 22131;
+MyBloomFilter filter = new MyBloomFilter();
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
+filter.add(value1);
+filter.add(value2);
+System.out.println(filter.contains(value1));
+System.out.println(filter.contains(value2));
```
Output:
@@ -190,18 +190,18 @@ true
true
```
-### 5.利用Google开源的 Guava中自带的布隆过滤器
+### 5.利用 Google 开源的 Guava 中自带的布隆过滤器
自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
```java
-
- com.google.guava
- guava
- 28.0-jre
-
+
+ com.google.guava
+ guava
+ 28.0-jre
+
```
实际使用如下:
@@ -209,42 +209,42 @@ true
我们创建了一个最多存放 最多 1500个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
```java
- // 创建布隆过滤器对象
- BloomFilter filter = BloomFilter.create(
- Funnels.integerFunnel(),
- 1500,
- 0.01);
- // 判断指定元素是否存在
- System.out.println(filter.mightContain(1));
- System.out.println(filter.mightContain(2));
- // 将元素添加进布隆过滤器
- filter.put(1);
- filter.put(2);
- System.out.println(filter.mightContain(1));
- System.out.println(filter.mightContain(2));
+// 创建布隆过滤器对象
+BloomFilter filter = BloomFilter.create(
+ Funnels.integerFunnel(),
+ 1500,
+ 0.01);
+// 判断指定元素是否存在
+System.out.println(filter.mightContain(1));
+System.out.println(filter.mightContain(2));
+// 将元素添加进布隆过滤器
+filter.put(1);
+filter.put(2);
+System.out.println(filter.mightContain(1));
+System.out.println(filter.mightContain(2));
```
-在我们的示例中,当`mightContain()` 方法返回*true*时,我们可以99%确定该元素在过滤器中,当过滤器返回*false*时,我们可以100%确定该元素不存在于过滤器中。
+在我们的示例中,当`mightContain()` 方法返回 *true* 时,我们可以99%确定该元素在过滤器中,当过滤器返回 *false* 时,我们可以100%确定该元素不存在于过滤器中。
**Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。**
### 6.Redis 中的布隆过滤器
-#### 6.1介绍
+#### 6.1 介绍
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
-另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom. 其他还有:
+另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom。其他还有:
-- redis-lua-scaling-bloom-filter (lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
+- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
- pyreBloom(Python中的快速Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
- ......
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
-#### 6.2使用Docker安装
+#### 6.2 使用Docker安装
-如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索**docker redis bloomfilter** 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:https://hub.docker.com/r/redislabs/rebloom/ (介绍的很详细 )。
+如果我们需要体验 Redis 中的布隆过滤器非常简单,通过 Docker 就可以了!我们直接在 Google 搜索 **docker redis bloomfilter** 然后在排除广告的第一条搜素结果就找到了我们想要的答案(这是我平常解决问题的一种方式,分享一下),具体地址:https://hub.docker.com/r/redislabs/rebloom/ (介绍的很详细 )。
**具体操作如下:**
@@ -257,7 +257,7 @@ root@21396d02c252:/data# redis-cli
#### 6.3常用命令一览
-> 注意: key:布隆过滤器的名称,item : 添加的元素。
+> 注意: key : 布隆过滤器的名称,item : 添加的元素。
1. **`BF.ADD `**:将元素添加到布隆过滤器中,如果该过滤器尚不存在,则创建该过滤器。格式:`BF.ADD {key} {item}`。
2. **`BF.MADD `** : 将一个或多个元素添加到“布隆过滤器”中,并创建一个尚不存在的过滤器。该命令的操作方式`BF.ADD`与之相同,只不过它允许多个输入并返回多个值。格式:`BF.MADD {key} {item} [item ...]` 。
From 64cc847b61dcd0cf44a26a49f53f702b9872b524 Mon Sep 17 00:00:00 2001
From: VinterHe <37563054+VinterHe@users.noreply.github.com>
Date: Tue, 22 Jun 2021 09:53:11 +0800
Subject: [PATCH 04/10] =?UTF-8?q?=E8=B7=9F=E6=96=B0=E4=BA=86=E5=8D=95?=
=?UTF-8?q?=E6=A0=B8=E5=92=8C=E5=A4=9A=E6=A0=B8=E7=B3=BB=E7=BB=9F=E4=B8=AD?=
=?UTF-8?q?=E5=A4=9A=E7=BA=BF=E7=A8=8B=E7=9A=84=E4=B8=BB=E8=A6=81=E4=BD=9C?=
=?UTF-8?q?=E7=94=A8=E3=80=82?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
对系统中存在多个进程的情况进行了备注,防止读者迷惑
---
...242\350\257\225\351\242\230\346\200\273\347\273\223.md" | 7 +++++--
1 file changed, 5 insertions(+), 2 deletions(-)
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index 6ff3f381235..eab717bb3f1 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -126,8 +126,11 @@ public class MultiThread {
再深入到计算机底层来探讨:
-- **单核时代:** 在单核时代多线程主要是为了提高 CPU 和 IO 设备的综合利用率。举个例子:当只有一个线程的时候会导致 CPU 计算时,IO 设备空闲;进行 IO 操作时,CPU 空闲。我们可以简单地说这两者的利用率目前都是 50%左右。但是当有两个线程的时候就不一样了,当一个线程执行 CPU 计算时,另外一个线程可以进行 IO 操作,这样两个的利用率就可以在理想情况下达到 100%了。
-- **多核时代:** 多核时代多线程主要是为了提高 CPU 利用率。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,CPU 只会一个 CPU 核心被利用到,而创建多个线程就可以让多个 CPU 核心被利用到,这样就提高了 CPU 的利用率。
+- **单核时代**: 在单核时代多线程主要是为了提高单进程利用CPU和IO系统的效率。 当我们请求IO的时候,如果java进程中只有一个线程,此线程被IO阻塞则整个进程被阻塞。CPU和IO设备只有一个在运行,那么可以简单地说系统整体效率只有50%。当使用多线程的时候,一个线程被IO阻塞,其他线程还可以继续使用CPU。从而提高了java进程利用系统资源的整体效率。
+
+注意:此种情况是指的计算机只有一个CPU核心,并且假设只运行了一个java进程的情况,多进程的时候,操作系统会调度不同进程占用CPU,也不会存在浪费CPU的问题,只不过是因为大型项目中,作为服务器运行的机器中一般不会运行太多无关进程,所以才可作此假设。
+
+- **多核时代**: 多核时代多线程主要是为了提高进程利用多核CPU的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个CPU核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个CPU上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU核心数)。
## 5. 使用多线程可能带来什么问题?
From c50a6d2469b8747059b3c9c3856e806cb68367f7 Mon Sep 17 00:00:00 2001
From: VinterHe <37563054+VinterHe@users.noreply.github.com>
Date: Tue, 22 Jun 2021 11:05:19 +0800
Subject: [PATCH 05/10] =?UTF-8?q?=E4=BF=AE=E6=94=B9=E4=BA=86=E4=BB=80?=
=?UTF-8?q?=E4=B9=88=E6=98=AF=E4=B8=8A=E4=B8=8B=E6=96=87=E5=88=87=E6=8D=A2?=
=?UTF-8?q?=E7=9A=84=E6=8F=8F=E8=BF=B0=E3=80=82?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...0\257\225\351\242\230\346\200\273\347\273\223.md" | 12 +++++++-----
1 file changed, 7 insertions(+), 5 deletions(-)
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index 6ff3f381235..fc7beb79aaf 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -155,13 +155,15 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
## 7. 什么是上下文切换?
-多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
+线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用CPU状态中退出。
+- 主动让出CPU,比如调用了sleep(),wait()等。
+- 时间片用完,因为操作系统要防止一个线程或者进程长时间占用CPU导致其他线程或者进程饿死。
+- 调用了阻塞类型的系统中断,比如请求IO,线程被阻塞。
+- 被终止或结束运行
-概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
+这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用CPU的时候恢复现场。并加载下一个将要占用CPU的线程上下文。这就是所谓的上下文切换。
-上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
-
-Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
+上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
## 8. 什么是线程死锁?如何避免死锁?
From ae0f4f0c4c8e17183f7cd2cdf15cc4a47ee0f67a Mon Sep 17 00:00:00 2001
From: TommyMerlin <786731256@qq.com>
Date: Tue, 22 Jun 2021 11:27:26 +0800
Subject: [PATCH 06/10] fix typo
---
.../Redis\346\214\201\344\271\205\345\214\226.md" | 11 +++--------
1 file changed, 3 insertions(+), 8 deletions(-)
diff --git "a/docs/database/Redis/Redis\346\214\201\344\271\205\345\214\226.md" "b/docs/database/Redis/Redis\346\214\201\344\271\205\345\214\226.md"
index 0408c2764d1..2da52eec186 100644
--- "a/docs/database/Redis/Redis\346\214\201\344\271\205\345\214\226.md"
+++ "b/docs/database/Redis/Redis\346\214\201\344\271\205\345\214\226.md"
@@ -7,7 +7,7 @@
**很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后回复数据),或者是为了防止系统故障而将数据备份到一个远程位置。**
-Redis不同于Memcached的很重一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
+Redis不同于Memcached的很重要一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
## 快照(snapshotting)持久化
@@ -16,8 +16,8 @@ Redis可以通过创建快照来获得存储在内存里面的数据在某个时

**快照持久化是Redis默认采用的持久化方式**,在redis.conf配置文件中默认有此下配置:
-```
+```
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
@@ -39,8 +39,6 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
如果系统真的发生崩溃,用户将丢失最近一次生成快照之后更改的所有数据。因此,快照持久化只适用于即使丢失一部分数据也不会造成一些大问题的应用程序。不能接受这个缺点的话,可以考虑AOF持久化。
-
-
## **AOF(append-only file)持久化**
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
@@ -55,7 +53,6 @@ appendonly yes
**在Redis的配置文件中存在三种同步方式,它们分别是:**
```
-
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
@@ -65,7 +62,6 @@ appendfsync no #让操作系统决定何时进行同步
为了兼顾数据和写入性能,用户可以考虑 **appendfsync everysec选项** ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
-
**appendfsync no** 选项一般不推荐,这种方案会使Redis丢失不定量的数据而且如果用户的硬盘处理写入操作的速度不够的话,那么当缓冲区被等待写入的数据填满时,Redis的写入操作将被阻塞,这会导致Redis的请求速度变慢。
**虽然AOF持久化非常灵活地提供了多种不同的选项来满足不同应用程序对数据安全的不同要求,但AOF持久化也有缺陷——AOF文件的体积太大。**
@@ -100,7 +96,7 @@ auto-aof-rewrite-min-size 64mb
无论是AOF持久化还是快照持久化,将数据持久化到硬盘上都是非常有必要的,但除了进行持久化外,用户还必须对持久化得到的文件进行备份(最好是备份到不同的地方),这样才能尽量避免数据丢失事故发生。如果条件允许的话,最好能将快照文件和重新重写的AOF文件备份到不同的服务器上面。
-随着负载量的上升,或者数据的完整性变得 越来越重要时,用户可能需要使用到复制特性。
+随着负载量的上升,或者数据的完整性变得越来越重要时,用户可能需要使用到复制特性。
## Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
@@ -113,4 +109,3 @@ Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通
[深入学习Redis(2):持久化](https://www.cnblogs.com/kismetv/p/9137897.html)
-
From 09e88e476da46b7e4939c8b1c362c2ea4af4a28e Mon Sep 17 00:00:00 2001
From: TommyMerlin <786731256@qq.com>
Date: Tue, 22 Jun 2021 15:02:11 +0800
Subject: [PATCH 07/10] fix typo
---
...\212\345\272\224\347\224\250\345\234\272\346\231\257.md" | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff --git "a/docs/database/Redis/redis\351\233\206\347\276\244\344\273\245\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md" "b/docs/database/Redis/redis\351\233\206\347\276\244\344\273\245\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md"
index dfa0d40e834..cd54f067f2c 100644
--- "a/docs/database/Redis/redis\351\233\206\347\276\244\344\273\245\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md"
+++ "b/docs/database/Redis/redis\351\233\206\347\276\244\344\273\245\345\217\212\345\272\224\347\224\250\345\234\272\346\231\257.md"
@@ -77,7 +77,7 @@
- 优化参数不一致:内存不一致.
- 避免全量复制
- 选择小主节点(分片)、低峰期间操作.
- - 如果节点运行 id 不匹配(如主节点重启、运行 id 发送变化),此时要执行全量复制,应该配合哨兵和集群解决.
+ - 如果节点运行 id 不匹配(如主节点重启、运行 id 发生变化),此时要执行全量复制,应该配合哨兵和集群解决.
- 主从复制挤压缓冲区不足产生的问题(网络中断,部分复制无法满足),可增大复制缓冲区( rel_backlog_size 参数).
- 复制风暴
@@ -111,7 +111,7 @@
- 转移流程
1. Sentinel 选出一个合适的 Slave 作为新的 Master(slaveof no one 命令)。
2. 向其余 Slave 发出通知,让它们成为新 Master 的 Slave( parallel-syncs 参数)。
- 3. 等待旧 Master 复活,并使之称为新 Master 的 Slave。
+ 3. 等待旧 Master 复活,并使之成为新 Master 的 Slave。
4. 向客户端通知 Master 变化。
- 从 Slave 中选择新 Master 节点的规则(slave 升级成 master 之后)
1. 选择 slave-priority 最高的节点。
@@ -138,7 +138,7 @@
##### 集中式
-> 将集群元数据(节点信息、故障等等)几种存储在某个节点上。
+> 将集群元数据(节点信息、故障等等)集中存储在某个节点上。
- 优势
1. 元数据的更新读取具有很强的时效性,元数据修改立即更新
- 劣势
From 65926e5e549b923020f04bb515604d45cbd31c8f Mon Sep 17 00:00:00 2001
From: guide
Date: Wed, 23 Jun 2021 20:35:00 +0800
Subject: [PATCH 08/10] =?UTF-8?q?Update=202020=E6=9C=80=E6=96=B0Java?=
=?UTF-8?q?=E5=B9=B6=E5=8F=91=E5=9F=BA=E7=A1=80=E5=B8=B8=E8=A7=81=E9=9D=A2?=
=?UTF-8?q?=E8=AF=95=E9=A2=98=E6=80=BB=E7=BB=93.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...25\351\242\230\346\200\273\347\273\223.md" | 59 +++++++++----------
1 file changed, 27 insertions(+), 32 deletions(-)
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index eab717bb3f1..95e536994fb 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -1,25 +1,25 @@
-- [Java 并发基础常见面试题总结](#java-并发基础常见面试题总结)
- - [1. 什么是线程和进程?](#1-什么是线程和进程)
- - [1.1. 何为进程?](#11-何为进程)
- - [1.2. 何为线程?](#12-何为线程)
- - [2. 请简要描述线程与进程的关系,区别及优缺点?](#2-请简要描述线程与进程的关系区别及优缺点)
- - [2.1. 图解进程和线程的关系](#21-图解进程和线程的关系)
- - [2.2. 程序计数器为什么是私有的?](#22-程序计数器为什么是私有的)
- - [2.3. 虚拟机栈和本地方法栈为什么是私有的?](#23-虚拟机栈和本地方法栈为什么是私有的)
- - [2.4. 一句话简单了解堆和方法区](#24-一句话简单了解堆和方法区)
- - [3. 说说并发与并行的区别?](#3-说说并发与并行的区别)
- - [4. 为什么要使用多线程呢?](#4-为什么要使用多线程呢)
- - [5. 使用多线程可能带来什么问题?](#5-使用多线程可能带来什么问题)
- - [6. 说说线程的生命周期和状态?](#6-说说线程的生命周期和状态)
- - [7. 什么是上下文切换?](#7-什么是上下文切换)
- - [8. 什么是线程死锁?如何避免死锁?](#8-什么是线程死锁如何避免死锁)
- - [8.1. 认识线程死锁](#81-认识线程死锁)
- - [8.2. 如何避免线程死锁?](#82-如何避免线程死锁)
- - [9. 说说 sleep() 方法和 wait() 方法区别和共同点?](#9-说说-sleep-方法和-wait-方法区别和共同点)
- - [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
- - [公众号](#公众号)
+- [Java 并发基础常见面试题总结](#Java-并发基础常见面试题总结)
+ - [1. 什么是线程和进程?](#1-什么是线程和进程)
+ - [1.1. 何为进程?](#11-何为进程)
+ - [1.2. 何为线程?](#12-何为线程)
+ - [2. 请简要描述线程与进程的关系,区别及优缺点?](#2-请简要描述线程与进程的关系区别及优缺点)
+ - [2.1. 图解进程和线程的关系](#21-图解进程和线程的关系)
+ - [2.2. 程序计数器为什么是私有的?](#22-程序计数器为什么是私有的)
+ - [2.3. 虚拟机栈和本地方法栈为什么是私有的?](#23-虚拟机栈和本地方法栈为什么是私有的)
+ - [2.4. 一句话简单了解堆和方法区](#24-一句话简单了解堆和方法区)
+ - [3. 说说并发与并行的区别?](#3-说说并发与并行的区别)
+ - [4. 为什么要使用多线程呢?](#4-为什么要使用多线程呢)
+ - [5. 使用多线程可能带来什么问题?](#5-使用多线程可能带来什么问题)
+ - [6. 说说线程的生命周期和状态?](#6-说说线程的生命周期和状态)
+ - [7. 什么是上下文切换?](#7-什么是上下文切换)
+ - [8. 什么是线程死锁?如何避免死锁?](#8-什么是线程死锁如何避免死锁)
+ - [8.1. 认识线程死锁](#81-认识线程死锁)
+ - [8.2. 如何避免线程死锁?](#82-如何避免线程死锁)
+ - [9. 说说 sleep() 方法和 wait() 方法区别和共同点?](#9-说说-sleep-方法和-wait-方法区别和共同点)
+ - [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
+ - [公众号](#公众号)
@@ -126,11 +126,8 @@ public class MultiThread {
再深入到计算机底层来探讨:
-- **单核时代**: 在单核时代多线程主要是为了提高单进程利用CPU和IO系统的效率。 当我们请求IO的时候,如果java进程中只有一个线程,此线程被IO阻塞则整个进程被阻塞。CPU和IO设备只有一个在运行,那么可以简单地说系统整体效率只有50%。当使用多线程的时候,一个线程被IO阻塞,其他线程还可以继续使用CPU。从而提高了java进程利用系统资源的整体效率。
-
-注意:此种情况是指的计算机只有一个CPU核心,并且假设只运行了一个java进程的情况,多进程的时候,操作系统会调度不同进程占用CPU,也不会存在浪费CPU的问题,只不过是因为大型项目中,作为服务器运行的机器中一般不会运行太多无关进程,所以才可作此假设。
-
-- **多核时代**: 多核时代多线程主要是为了提高进程利用多核CPU的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个CPU核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个CPU上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU核心数)。
+- **单核时代**: 在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
+- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
## 5. 使用多线程可能带来什么问题?
@@ -146,11 +143,11 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
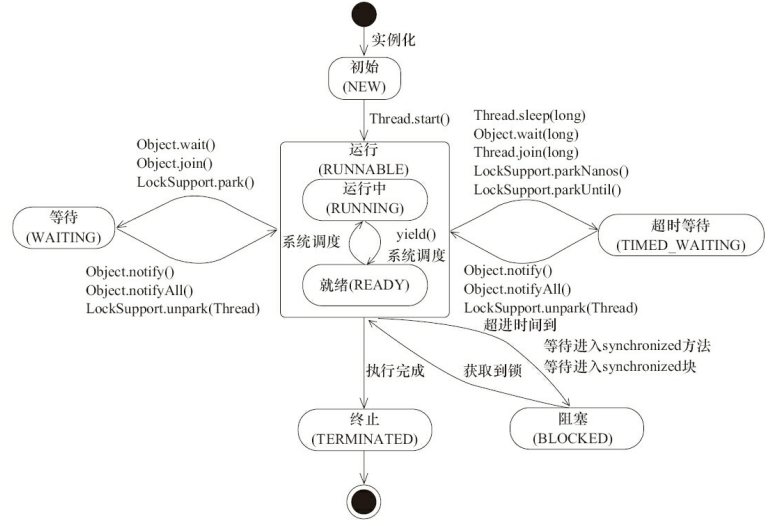
-> 订正(来自[issue736](https://github.com/Snailclimb/JavaGuide/issues/736)):原图中 wait到 runnable状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
+> 订正(来自[issue736](https://github.com/Snailclimb/JavaGuide/issues/736)):原图中 wait 到 runnable 状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
由上图可以看出:线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
-> 操作系统隐藏 Java 虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+> 操作系统隐藏 Java 虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinJava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinJava.com/Java/multi-threading/Java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。

@@ -239,7 +236,7 @@ Thread[线程 2,5,main]waiting get resource1
**如何预防死锁?** 破坏死锁的产生的必要条件即可:
-1. **破坏请求与保持条件** :一次性申请所有的资源。
+1. **破坏请求与保持条件** :一次性申请所有的资源。
2. **破坏不剥夺条件** :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
3. **破坏循环等待条件** :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
@@ -294,9 +291,9 @@ Process finished with exit code 0
## 10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
-这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
+这是另一个非常经典的 Java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
-new 一个 Thread,线程进入了新建状态。调用 `start()`方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 `start()` 会执行线程的相应准备工作,然后自动执行 ` run() ` 方法的内容,这是真正的多线程工作。 但是,直接执行 `run()` 方法,会把 `run()` 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
+new 一个 Thread,线程进入了新建状态。调用 `start()`方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 `start()` 会执行线程的相应准备工作,然后自动执行 `run()` 方法的内容,这是真正的多线程工作。 但是,直接执行 `run()` 方法,会把 `run()` 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
**总结: 调用 `start()` 方法方可启动线程并使线程进入就绪状态,直接执行 `run()` 方法的话不会以多线程的方式执行。**
@@ -309,5 +306,3 @@ new 一个 Thread,线程进入了新建状态。调用 `start()`方法,会
**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

-
-
From d342570fb709eeb710cbea1aecdc41708d66cc77 Mon Sep 17 00:00:00 2001
From: guide
Date: Wed, 23 Jun 2021 20:39:36 +0800
Subject: [PATCH 09/10] =?UTF-8?q?Update=202020=E6=9C=80=E6=96=B0Java?=
=?UTF-8?q?=E5=B9=B6=E5=8F=91=E5=9F=BA=E7=A1=80=E5=B8=B8=E8=A7=81=E9=9D=A2?=
=?UTF-8?q?=E8=AF=95=E9=A2=98=E6=80=BB=E7=BB=93.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...350\257\225\351\242\230\346\200\273\347\273\223.md" | 10 +++++-----
1 file changed, 5 insertions(+), 5 deletions(-)
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index d536dc0edbd..45a48544b40 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -155,15 +155,15 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
## 7. 什么是上下文切换?
-线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用CPU状态中退出。
-- 主动让出CPU,比如调用了sleep(),wait()等。
+线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用 CPU 状态中退出。
+- 主动让出 CPU,比如调用了 `sleep()`, `wait()` 等。
- 时间片用完,因为操作系统要防止一个线程或者进程长时间占用CPU导致其他线程或者进程饿死。
-- 调用了阻塞类型的系统中断,比如请求IO,线程被阻塞。
+- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞。
- 被终止或结束运行
-这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用CPU的时候恢复现场。并加载下一个将要占用CPU的线程上下文。这就是所谓的上下文切换。
+这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用 CPU 的时候恢复现场。并加载下一个将要占用 CPU 的线程上下文。这就是所谓的 **上下文切换**。
-上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
+上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用 CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
## 8. 什么是线程死锁?如何避免死锁?
From 0026f531af301dd9b515ae2f6555768e3f86c202 Mon Sep 17 00:00:00 2001
From: guide
Date: Wed, 23 Jun 2021 21:06:49 +0800
Subject: [PATCH 10/10] =?UTF-8?q?=E5=A4=9A=E7=BA=BF=E7=A8=8B=EF=BC=9A=20RE?=
=?UTF-8?q?ADY=20=E5=92=8C=20RUNNING=20=E7=8A=B6=E6=80=81?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\242\350\257\225\351\242\230\346\200\273\347\273\223.md" | 6 +++++-
1 file changed, 5 insertions(+), 1 deletion(-)
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index 45a48544b40..b5f2e57d082 100644
--- "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -147,12 +147,16 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
由上图可以看出:线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
-> 操作系统隐藏 Java 虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinJava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinJava.com/Java/multi-threading/Java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+> 在操作系统中层面线程有 READY 和 RUNNING 状态,而在 JVM 层面只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinJava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinJava.com/Java/multi-threading/Java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+>
+> **为什么 JVM 没有区分这两种状态呢?** (摘自:[java线程运行怎么有第六种状态? - Dawell的回答](https://www.zhihu.com/question/56494969/answer/154053599) ) 现在的时分(time-sharing)多任务(multi-task)操作系统架构通常都是用所谓的“时间分片(time quantum or time slice)”方式进行抢占式(preemptive)轮转调度(round-robin式)。这个时间分片通常是很小的,一个线程一次最多只能在 CPU 上运行比如 10-20ms 的时间(此时处于 running 状态),也即大概只有 0.01 秒这一量级,时间片用后就要被切换下来放入调度队列的末尾等待再次调度。(也即回到 ready 状态)。线程切换的如此之快,区分这两种状态就没什么意义了。

当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)** 状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的`run()`方法之后将会进入到 **TERMINATED(终止)** 状态。
+相关阅读:[挑错 |《Java 并发编程的艺术》中关于线程状态的三处错误](https://mp.weixin.qq.com/s/UOrXql_LhOD8dhTq_EPI0w) 。
+
## 7. 什么是上下文切换?
线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用 CPU 状态中退出。