From 2a4f95308de1424dcb61deb3fda2bb6af64a2748 Mon Sep 17 00:00:00 2001
From: guide
Date: Sat, 14 Aug 2021 09:16:39 +0800
Subject: [PATCH 1/2] =?UTF-8?q?[feat]=20=E8=A1=A5=E5=85=85=20redis=20?=
=?UTF-8?q?=E5=BA=94=E7=94=A8=E5=9C=BA=E6=99=AF?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/database/Redis/redis-all.md | 120 ++++++++++---------------------
1 file changed, 39 insertions(+), 81 deletions(-)
diff --git a/docs/database/Redis/redis-all.md b/docs/database/Redis/redis-all.md
index 64ea49d563a..93227374d2e 100644
--- a/docs/database/Redis/redis-all.md
+++ b/docs/database/Redis/redis-all.md
@@ -1,45 +1,5 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
-
-
-
-
-
-- [1. 简单介绍一下 Redis 呗!](#1-简单介绍一下-redis-呗)
-- [2. 分布式缓存常见的技术选型方案有哪些?](#2-分布式缓存常见的技术选型方案有哪些)
-- [3. 说一下 Redis 和 Memcached 的区别和共同点](#3-说一下-redis-和-memcached-的区别和共同点)
-- [4. 缓存数据的处理流程是怎样的?](#4-缓存数据的处理流程是怎样的)
-- [5. 为什么要用 Redis/为什么要用缓存?](#5-为什么要用-redis为什么要用缓存)
-- [6. Redis 常见数据结构以及使用场景分析](#6-redis-常见数据结构以及使用场景分析)
- - [6.1. string](#61-string)
- - [6.2. list](#62-list)
- - [6.3. hash](#63-hash)
- - [6.4. set](#64-set)
- - [6.5. sorted set](#65-sorted-set)
- - [6.6 bitmap](#66-bitmap)
-- [7. Redis 单线程模型详解](#7-redis-单线程模型详解)
-- [8. Redis 没有使用多线程?为什么不使用多线程?](#8-redis-没有使用多线程为什么不使用多线程)
-- [9. Redis6.0 之后为何引入了多线程?](#9-redis60-之后为何引入了多线程)
-- [10. Redis 给缓存数据设置过期时间有啥用?](#10-redis-给缓存数据设置过期时间有啥用)
-- [11. Redis 是如何判断数据是否过期的呢?](#11-redis-是如何判断数据是否过期的呢)
-- [12. 过期的数据的删除策略了解么?](#12-过期的数据的删除策略了解么)
-- [13. Redis 内存淘汰机制了解么?](#13-redis-内存淘汰机制了解么)
-- [14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)](#14-redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
-- [15. Redis 事务](#15-redis-事务)
-- [16. 缓存穿透](#16-缓存穿透)
- - [16.1. 什么是缓存穿透?](#161-什么是缓存穿透)
- - [16.2. 缓存穿透情况的处理流程是怎样的?](#162-缓存穿透情况的处理流程是怎样的)
- - [16.3. 有哪些解决办法?](#163-有哪些解决办法)
-- [17. 缓存雪崩](#17-缓存雪崩)
- - [17.1. 什么是缓存雪崩?](#171-什么是缓存雪崩)
- - [17.2. 有哪些解决办法?](#172-有哪些解决办法)
-- [18. 如何保证缓存和数据库数据的一致性?](#18-如何保证缓存和数据库数据的一致性)
-- [19. 参考](#19-参考)
-- [20. 公众号](#20-公众号)
-
-
-
-
-### 1. 简单介绍一下 Redis 呗!
+
+### 简单介绍一下 Redis 呗!
简单来说 **Redis 就是一个使用 C 语言开发的数据库**,不过与传统数据库不同的是 **Redis 的数据是存在内存中的** ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
@@ -47,7 +7,7 @@
**Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。**
-### 2. 分布式缓存常见的技术选型方案有哪些?
+### 分布式缓存常见的技术选型方案有哪些?
分布式缓存的话,使用的比较多的主要是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
@@ -55,7 +15,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用信息的问题。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
-### 3. 说一下 Redis 和 Memcached 的区别和共同点
+### 说一下 Redis 和 Memcached 的区别和共同点
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
@@ -78,7 +38,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
-### 4. 缓存数据的处理流程是怎样的?
+### 缓存数据的处理流程是怎样的?
作为暖男一号,我给大家画了一个草图。
@@ -91,7 +51,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
3. 数据库中存在的话就更新缓存中的数据。
4. 数据库中不存在的话就返回空数据。
-### 5. 为什么要用 Redis/为什么要用缓存?
+### 为什么要用 Redis/为什么要用缓存?
_简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户。_
@@ -117,13 +77,21 @@ _简单,来说使用缓存主要是为了提升用户体验以及应对更多
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
-### 6. Redis 常见数据结构以及使用场景分析
+### Redis 除了做缓存,还能做什么?
+
+- **分布式锁** : 通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。相关阅读:[《分布式锁中的王者方案 - Redisson》](https://mp.weixin.qq.com/s/CbnPRfvq4m1sqo2uKI6qQw)。
+- **限流** :一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
+- **消息队列** :Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **复杂业务场景** :通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
+- ......
+
+### Redis 常见数据结构以及使用场景分析
你可以自己本机安装 redis 或者通过 redis 官网提供的[在线 redis 环境](https://try.redis.io/)。

-#### 6.1. string
+#### string
1. **介绍** :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(simple dynamic string,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
2. **常用命令:** `set,get,strlen,exists,decr,incr,setex` 等等。
@@ -184,7 +152,7 @@ OK
(integer) 56
```
-#### 6.2. list
+#### list
1. **介绍** :**list** 即是 **链表**。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 **LinkedList**,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
2. **常用命令:** `rpush,lpop,lpush,rpop,lrange,llen` 等。
@@ -245,7 +213,7 @@ OK
(integer) 3
```
-#### 6.3. hash
+#### hash
1. **介绍** :hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 hash 做了更多优化。另外,hash 是一个 string 类型的 field 和 value 的映射表,**特别适合用于存储对象**,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
2. **常用命令:** `hset,hmset,hexists,hget,hgetall,hkeys,hvals` 等。
@@ -282,7 +250,7 @@ OK
"GuideGeGe"
```
-#### 6.4. set
+#### set
1. **介绍 :** set 类似于 Java 中的 `HashSet` 。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
2. **常用命令:** `sadd,spop,smembers,sismember,scard,sinterstore,sunion` 等。
@@ -310,7 +278,7 @@ OK
1) "value2"
```
-#### 6.5. sorted set
+#### sorted set
1. **介绍:** 和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
2. **常用命令:** `zadd,zcard,zscore,zrange,zrevrange,zrem` 等。
@@ -337,7 +305,7 @@ OK
2) "value2"
```
-#### 6.6 bitmap
+#### bitmap
1. **介绍:** bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
2. **常用命令:** `setbit` 、`getbit` 、`bitcount`、`bitop`
@@ -417,7 +385,7 @@ BITOP operation destkey key [key ...]
只需要一个 key,然后用户 ID 为 offset,如果在线就设置为 1,不在线就设置为 0。
-### 7. Redis 单线程模型详解
+### Redis 单线程模型详解
**Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
@@ -450,7 +418,7 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
《Redis设计与实现:12章》
-### 8. Redis 没有使用多线程?为什么不使用多线程?
+### Redis 没有使用多线程?为什么不使用多线程?
虽然说 Redis 是单线程模型,但是,实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
@@ -468,7 +436,7 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
2. Redis 的性能瓶颈不在 CPU ,主要在内存和网络;
3. 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
-### 9. Redis6.0 之后为何引入了多线程?
+### Redis6.0 之后为何引入了多线程?
**Redis6.0 引入多线程主要是为了提高网络 IO 读写性能**,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
@@ -491,7 +459,7 @@ io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的
1. [Redis 6.0 新特性-多线程连环 13 问!](https://mp.weixin.qq.com/s/FZu3acwK6zrCBZQ_3HoUgw)
2. [为什么 Redis 选择单线程模型](https://draveness.me/whys-the-design-redis-single-thread/)
-### 10. Redis 给缓存数据设置过期时间有啥用?
+### Redis 给缓存数据设置过期时间有啥用?
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
@@ -516,7 +484,7 @@ OK
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
-### 11. Redis 是如何判断数据是否过期的呢?
+### Redis 是如何判断数据是否过期的呢?
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
@@ -534,7 +502,7 @@ typedef struct redisDb {
} redisDb;
```
-### 12. 过期的数据的删除策略了解么?
+### 过期的数据的删除策略了解么?
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
@@ -549,7 +517,7 @@ typedef struct redisDb {
怎么解决这个问题呢?答案就是:**Redis 内存淘汰机制。**
-### 13. Redis 内存淘汰机制了解么?
+### Redis 内存淘汰机制了解么?
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
@@ -567,7 +535,7 @@ Redis 提供 6 种数据淘汰策略:
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
-### 14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
+### Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
@@ -629,7 +597,7 @@ AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
-### 15. Redis 事务
+### Redis 事务
Redis 可以通过 **`MULTI`,`EXEC`,`DISCARD` 和 `WATCH`** 等命令来实现事务(transaction)功能。
@@ -704,19 +672,19 @@ Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis
- [issue452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) 。
- [Issue491:关于 redis 没有事务回滚?](https://github.com/Snailclimb/JavaGuide/issues/491)
-### 16. 缓存穿透
+### 缓存穿透
-#### 16.1. 什么是缓存穿透?
+#### 什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
-#### 16.2. 缓存穿透情况的处理流程是怎样的?
+#### 缓存穿透情况的处理流程是怎样的?
如下图所示,用户的请求最终都要跑到数据库中查询一遍。

-#### 16.3. 有哪些解决办法?
+#### 有哪些解决办法?
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
@@ -777,9 +745,9 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
-### 17. 缓存雪崩
+### 缓存雪崩
-#### 17.1. 什么是缓存雪崩?
+#### 什么是缓存雪崩?
我发现缓存雪崩这名字起的有点意思,哈哈。
@@ -791,7 +759,7 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
举个例子 :秒杀开始 12 个小时之前,我们统一存放了一批商品到 Redis 中,设置的缓存过期时间也是 12 个小时,那么秒杀开始的时候,这些秒杀的商品的访问直接就失效了。导致的情况就是,相应的请求直接就落到了数据库上,就像雪崩一样可怕。
-#### 17.2. 有哪些解决办法?
+#### 有哪些解决办法?
**针对 Redis 服务不可用的情况:**
@@ -803,7 +771,7 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
1. 设置不同的失效时间比如随机设置缓存的失效时间。
2. 缓存永不失效。
-### 18. 如何保证缓存和数据库数据的一致性?
+### 如何保证缓存和数据库数据的一致性?
细说的话可以扯很多,但是我觉得其实没太大必要(小声 BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
@@ -816,20 +784,10 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
-### 19. 参考
+### 参考
- 《Redis 开发与运维》
- 《Redis 设计与实现》
- Redis 命令总结:http://Redisdoc.com/string/set.html
- 通俗易懂的 Redis 数据结构基础教程:[https://juejin.im/post/5b53ee7e5188251aaa2d2e16](https://juejin.im/post/5b53ee7e5188251aaa2d2e16)
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
-
-### 20. 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
-
-**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
\ No newline at end of file
From 2e813341619f8d92eaae850f78005a63b9629f80 Mon Sep 17 00:00:00 2001
From: guide
Date: Sat, 14 Aug 2021 10:05:36 +0800
Subject: [PATCH 2/2] =?UTF-8?q?Update=20=E4=B8=87=E5=AD=97=E8=AF=A6?=
=?UTF-8?q?=E8=A7=A3ThreadLocal=E5=85=B3=E9=94=AE=E5=AD=97.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...al\345\205\263\351\224\256\345\255\227.md" | 124 ++++++++----------
1 file changed, 58 insertions(+), 66 deletions(-)
diff --git "a/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md" "b/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
index 3650ddbb25e..a7c79807775 100644
--- "a/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
+++ "b/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
@@ -1,19 +1,19 @@
-> 本文来自一枝花算不算浪漫投稿, 原文地址:[https://juejin.im/post/5eacc1c75188256d976df748](https://juejin.im/post/5eacc1c75188256d976df748)。
+> 本文来自一枝花算不算浪漫投稿, 原文地址:[https://juejin.im/post/5eacc1c75188256d976df748](https://juejin.im/post/5eacc1c75188256d976df748)。
### 前言

-**全文共10000+字,31张图,这篇文章同样耗费了不少的时间和精力才创作完成,原创不易,请大家点点关注+在看,感谢。**
+**全文共 10000+字,31 张图,这篇文章同样耗费了不少的时间和精力才创作完成,原创不易,请大家点点关注+在看,感谢。**
对于`ThreadLocal`,大家的第一反应可能是很简单呀,线程的变量副本,每个线程隔离。那这里有几个问题大家可以思考一下:
-- `ThreadLocal`的key是**弱引用**,那么在 `ThreadLocal`.get()的时候,发生**GC**之后,key是否为**null**?
+- `ThreadLocal`的 key 是**弱引用**,那么在 `ThreadLocal`.get()的时候,发生**GC**之后,key 是否为**null**?
- `ThreadLocal`中`ThreadLocalMap`的**数据结构**?
-- `ThreadLocalMap`的**Hash算法**?
-- `ThreadLocalMap`中**Hash冲突**如何解决?
+- `ThreadLocalMap`的**Hash 算法**?
+- `ThreadLocalMap`中**Hash 冲突**如何解决?
- `ThreadLocalMap`的**扩容机制**?
-- `ThreadLocalMap`中**过期key的清理机制**?**探测式清理**和**启发式清理**流程?
+- `ThreadLocalMap`中**过期 key 的清理机制**?**探测式清理**和**启发式清理**流程?
- `ThreadLocalMap.set()`方法实现原理?
- `ThreadLocalMap.get()`方法实现原理?
- 项目中`ThreadLocal`使用情况?遇到的坑?
@@ -23,8 +23,6 @@
### 目录
-
-
**注明:** 本文源码基于`JDK 1.8`
### `ThreadLocal`代码演示
@@ -80,19 +78,18 @@ size: 0
我们还要注意`Entry`, 它的`key`是`ThreadLocal k` ,继承自`WeakReference`, 也就是我们常说的弱引用类型。
-### GC 之后key是否为null?
+### GC 之后 key 是否为 null?
回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在`ThreadLocal.get()`的时候,发生`GC`之后,`key`是否是`null`?
为了搞清楚这个问题,我们需要搞清楚`Java`的**四种引用类型**:
-- **强引用**:我们常常new出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
-- **软引用**:使用SoftReference修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
-- **弱引用**:使用WeakReference修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
+- **强引用**:我们常常 new 出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
+- **软引用**:使用 SoftReference 修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
+- **弱引用**:使用 WeakReference 修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
- **虚引用**:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
-
-接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942 本地运行演示GC回收场景)
+接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942 本地运行演示 GC 回收场景)
```java
public class ThreadLocalDemo {
@@ -140,6 +137,7 @@ public class ThreadLocalDemo {
```
结果如下:
+
```java
弱引用key:java.lang.ThreadLocal@433619b6,值:abc
弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12
@@ -192,7 +190,7 @@ void createMap(Thread t, T firstValue) {
主要的核心逻辑还是在`ThreadLocalMap`中的,一步步往下看,后面还有更详细的剖析。
-### `ThreadLocalMap` Hash算法
+### `ThreadLocalMap` Hash 算法
既然是`Map`结构,那么`ThreadLocalMap`当然也要实现自己的`hash`算法来解决散列表数组冲突问题。
@@ -200,7 +198,7 @@ void createMap(Thread t, T firstValue) {
int i = key.threadLocalHashCode & (len-1);
```
-`ThreadLocalMap`中`hash`算法很简单,这里`i`就是当前key在散列表中对应的数组下标位置。
+`ThreadLocalMap`中`hash`算法很简单,这里`i`就是当前 key 在散列表中对应的数组下标位置。
这里最关键的就是`threadLocalHashCode`值的计算,`ThreadLocal`中有一个属性为`HASH_INCREMENT = 0x61c88647`
@@ -215,7 +213,7 @@ public class ThreadLocal {
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
-
+
static class ThreadLocalMap {
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
@@ -231,7 +229,7 @@ public class ThreadLocal {
每当创建一个`ThreadLocal`对象,这个`ThreadLocal.nextHashCode` 这个值就会增长 `0x61c88647` 。
-这个值很特殊,它是**斐波那契数** 也叫 **黄金分割数**。`hash`增量为 这个数字,带来的好处就是 `hash` **分布非常均匀**。
+这个值很特殊,它是**斐波那契数** 也叫 **黄金分割数**。`hash`增量为 这个数字,带来的好处就是 `hash` **分布非常均匀**。
我们自己可以尝试下:
@@ -239,7 +237,7 @@ public class ThreadLocal {
可以看到产生的哈希码分布很均匀,这里不去细纠**斐波那契**具体算法,感兴趣的可以自行查阅相关资料。
-### `ThreadLocalMap` Hash冲突
+### `ThreadLocalMap` Hash 冲突
> **注明:** 下面所有示例图中,**绿色块**`Entry`代表**正常数据**,**灰色块**代表`Entry`的`key`值为`null`,**已被垃圾回收**。**白色块**表示`Entry`为`null`。
@@ -247,22 +245,21 @@ public class ThreadLocal {
`HashMap`中解决冲突的方法是在数组上构造一个**链表**结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成**红黑树**。
-而`ThreadLocalMap`中并没有链表结构,所以这里不能适用`HashMap`解决冲突的方式了。
+而 `ThreadLocalMap` 中并没有链表结构,所以这里不能使用 `HashMap` 解决冲突的方式了。

+如上图所示,如果我们插入一个`value=27`的数据,通过 `hash` 计算后应该落入第 4 个槽位中,而槽位 4 已经有了 `Entry` 数据。
-如上图所示,如果我们插入一个`value=27`的数据,通过`hash`计算后应该落入第4个槽位中,而槽位4已经有了`Entry`数据。
-
-此时就会线性向后查找,一直找到`Entry`为`null`的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了`Entry`不为`null`且`key`值相等的情况,还有`Entry`中的`key`值为`null`的情况等等都会有不同的处理,后面会一一详细讲解。
+此时就会线性向后查找,一直找到 `Entry` 为 `null` 的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了 `Entry` 不为 `null` 且 `key` 值相等的情况,还有 `Entry` 中的 `key` 值为 `null` 的情况等等都会有不同的处理,后面会一一详细讲解。
-这里还画了一个`Entry`中的`key`为`null`的数据(**Entry=2的灰色块数据**),因为`key`值是**弱引用**类型,所以会有这种数据存在。在`set`过程中,如果遇到了`key`过期的`Entry`数据,实际上是会进行一轮**探测式清理**操作的,具体操作方式后面会讲到。
+这里还画了一个`Entry`中的`key`为`null`的数据(**Entry=2 的灰色块数据**),因为`key`值是**弱引用**类型,所以会有这种数据存在。在`set`过程中,如果遇到了`key`过期的`Entry`数据,实际上是会进行一轮**探测式清理**操作的,具体操作方式后面会讲到。
### `ThreadLocalMap.set()`详解
#### `ThreadLocalMap.set()`原理图解
-看完了`ThreadLocal` **hash算法**后,我们再来看`set`是如何实现的。
+看完了`ThreadLocal` **hash 算法**后,我们再来看`set`是如何实现的。
往`ThreadLocalMap`中`set`数据(**新增**或者**更新**数据)分为好几种情况,针对不同的情况我们画图来说说明。
@@ -282,36 +279,33 @@ public class ThreadLocal {

-遍历散列数组,线性往后查找,如果找到`Entry`为`null`的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了**key值相等**的数据,直接更新即可。
+遍历散列数组,线性往后查找,如果找到`Entry`为`null`的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了**key 值相等**的数据,直接更新即可。
**第四种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,遇到`key`过期的`Entry`,如下图,往后遍历过程中,一到了`index=7`的槽位数据`Entry`的`key=null`:

-散列数组下标为7位置对应的`Entry`数据`key`为`null`,表明此数据`key`值已经被垃圾回收掉了,此时就会执行`replaceStaleEntry()`方法,该方法含义是**替换过期数据的逻辑**,以**index=7**位起点开始遍历,进行探测式数据清理工作。
+散列数组下标为 7 位置对应的`Entry`数据`key`为`null`,表明此数据`key`值已经被垃圾回收掉了,此时就会执行`replaceStaleEntry()`方法,该方法含义是**替换过期数据的逻辑**,以**index=7**位起点开始遍历,进行探测式数据清理工作。
初始化探测式清理过期数据扫描的开始位置:`slotToExpunge = staleSlot = 7`
以当前`staleSlot`开始 向前迭代查找,找其他过期的数据,然后更新过期数据起始扫描下标`slotToExpunge`。`for`循环迭代,直到碰到`Entry`为`null`结束。
-如果找到了过期的数据,继续向前迭代,直到遇到`Entry=null`的槽位才停止迭代,如下图所示,**slotToExpunge被更新为0**:
+如果找到了过期的数据,继续向前迭代,直到遇到`Entry=null`的槽位才停止迭代,如下图所示,**slotToExpunge 被更新为 0**:

-以当前节点(`index=7`)向前迭代,检测是否有过期的`Entry`数据,如果有则更新`slotToExpunge`值。碰到`null`则结束探测。以上图为例`slotToExpunge`被更新为0。
+以当前节点(`index=7`)向前迭代,检测是否有过期的`Entry`数据,如果有则更新`slotToExpunge`值。碰到`null`则结束探测。以上图为例`slotToExpunge`被更新为 0。
上面向前迭代的操作是为了更新探测清理过期数据的起始下标`slotToExpunge`的值,这个值在后面会讲解,它是用来判断当前过期槽位`staleSlot`之前是否还有过期元素。
-接着开始以`staleSlot`位置(index=7)向后迭代,**如果找到了相同key值的Entry数据:**
+接着开始以`staleSlot`位置(index=7)向后迭代,**如果找到了相同 key 值的 Entry 数据:**

从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,找到后更新`Entry`的值并交换`staleSlot`元素的位置(`staleSlot`位置为过期元素),更新`Entry`数据,然后开始进行过期`Entry`的清理工作,如下图所示:
-
-
-
-**向后遍历过程中,如果没有找到相同key值的Entry数据:**
+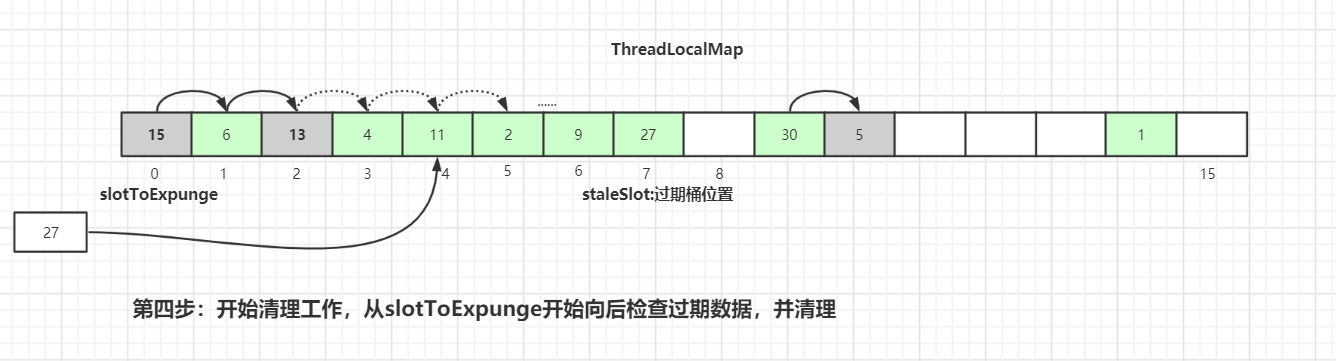向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:

@@ -367,6 +361,7 @@ int i = key.threadLocalHashCode & (len-1);
```
什么情况下桶才是可以使用的呢?
+
1. `k = key` 说明是替换操作,可以使用
2. 碰到一个过期的桶,执行替换逻辑,占用过期桶
3. 查找过程中,碰到桶中`Entry=null`的情况,直接使用
@@ -386,16 +381,17 @@ private static int prevIndex(int i, int len) {
```
接着看剩下`for`循环中的逻辑:
+
1. 遍历当前`key`值对应的桶中`Entry`数据为空,这说明散列数组这里没有数据冲突,跳出`for`循环,直接`set`数据到对应的桶中
2. 如果`key`值对应的桶中`Entry`数据不为空
-2.1 如果`k = key`,说明当前`set`操作是一个替换操作,做替换逻辑,直接返回
-2.2 如果`key = null`,说明当前桶位置的`Entry`是过期数据,执行`replaceStaleEntry()`方法(核心方法),然后返回
+ 2.1 如果`k = key`,说明当前`set`操作是一个替换操作,做替换逻辑,直接返回
+ 2.2 如果`key = null`,说明当前桶位置的`Entry`是过期数据,执行`replaceStaleEntry()`方法(核心方法),然后返回
3. `for`循环执行完毕,继续往下执行说明向后迭代的过程中遇到了`entry`为`null`的情况
-3.1 在`Entry`为`null`的桶中创建一个新的`Entry`对象
-3.2 执行`++size`操作
+ 3.1 在`Entry`为`null`的桶中创建一个新的`Entry`对象
+ 3.2 执行`++size`操作
4. 调用`cleanSomeSlots()`做一次启发式清理工作,清理散列数组中`Entry`的`key`过期的数据
-4.1 如果清理工作完成后,未清理到任何数据,且`size`超过了阈值(数组长度的2/3),进行`rehash()`操作
-4.2 `rehash()`中会先进行一轮探测式清理,清理过期`key`,清理完成后如果**size >= threshold - threshold / 4**,就会执行真正的扩容逻辑(扩容逻辑往后看)
+ 4.1 如果清理工作完成后,未清理到任何数据,且`size`超过了阈值(数组长度的 2/3),进行`rehash()`操作
+ 4.2 `rehash()`中会先进行一轮探测式清理,清理过期`key`,清理完成后如果**size >= threshold - threshold / 4**,就会执行真正的扩容逻辑(扩容逻辑往后看)
接着重点看下`replaceStaleEntry()`方法,`replaceStaleEntry()`方法提供替换过期数据的功能,我们可以对应上面**第四种情况**的原理图来再回顾下,具体代码如下:
@@ -446,7 +442,7 @@ private void replaceStaleEntry(ThreadLocal key, Object value,
}
```
-`slotToExpunge`表示开始探测式清理过期数据的开始下标,默认从当前的`staleSlot`开始。以当前的`staleSlot`开始,向前迭代查找,找到没有过期的数据,`for`循环一直碰到`Entry`为`null`才会结束。如果向前找到了过期数据,更新探测清理过期数据的开始下标为i,即`slotToExpunge=i`
+`slotToExpunge`表示开始探测式清理过期数据的开始下标,默认从当前的`staleSlot`开始。以当前的`staleSlot`开始,向前迭代查找,找到没有过期的数据,`for`循环一直碰到`Entry`为`null`才会结束。如果向前找到了过期数据,更新探测清理过期数据的开始下标为 i,即`slotToExpunge=i`
```java
for (int i = prevIndex(staleSlot, len);
@@ -460,7 +456,7 @@ for (int i = prevIndex(staleSlot, len);
```
接着开始从`staleSlot`向后查找,也是碰到`Entry`为`null`的桶结束。
-如果迭代过程中,**碰到k == key**,这说明这里是替换逻辑,替换新数据并且交换当前`staleSlot`位置。如果`slotToExpunge == staleSlot`,这说明`replaceStaleEntry()`一开始向前查找过期数据时并未找到过期的`Entry`数据,接着向后查找过程中也未发现过期数据,修改开始探测式清理过期数据的下标为当前循环的index,即`slotToExpunge = i`。最后调用`cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);`进行启发式过期数据清理。
+如果迭代过程中,**碰到 k == key**,这说明这里是替换逻辑,替换新数据并且交换当前`staleSlot`位置。如果`slotToExpunge == staleSlot`,这说明`replaceStaleEntry()`一开始向前查找过期数据时并未找到过期的`Entry`数据,接着向后查找过程中也未发现过期数据,修改开始探测式清理过期数据的下标为当前循环的 index,即`slotToExpunge = i`。最后调用`cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);`进行启发式过期数据清理。
```java
if (k == key) {
@@ -468,7 +464,7 @@ if (k == key) {
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
-
+
if (slotToExpunge == staleSlot)
slotToExpunge = i;
@@ -479,7 +475,7 @@ if (k == key) {
`cleanSomeSlots()`和`expungeStaleEntry()`方法后面都会细讲,这两个是和清理相关的方法,一个是过期`key`相关`Entry`的启发式清理(`Heuristically scan`),另一个是过期`key`相关`Entry`的探测式清理。
-**如果k != key**则会接着往下走,`k == null`说明当前遍历的`Entry`是一个过期数据,`slotToExpunge == staleSlot`说明,一开始的向前查找数据并未找到过期的`Entry`。如果条件成立,则更新`slotToExpunge` 为当前位置,这个前提是前驱节点扫描时未发现过期数据。
+**如果 k != key**则会接着往下走,`k == null`说明当前遍历的`Entry`是一个过期数据,`slotToExpunge == staleSlot`说明,一开始的向前查找数据并未找到过期的`Entry`。如果条件成立,则更新`slotToExpunge` 为当前位置,这个前提是前驱节点扫描时未发现过期数据。
```java
if (k == null && slotToExpunge == staleSlot)
@@ -494,12 +490,13 @@ tab[staleSlot] = new Entry(key, value);
```
最后判断除了`staleSlot`以外,还发现了其他过期的`slot`数据,就要开启清理数据的逻辑:
+
```java
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
```
-### `ThreadLocalMap`过期key的探测式清理流程
+### `ThreadLocalMap`过期 key 的探测式清理流程
上面我们有提及`ThreadLocalMap`的两种过期`key`数据清理方式:**探测式清理**和**启发式清理**。
@@ -507,7 +504,7 @@ if (slotToExpunge != staleSlot)

-如上图,`set(27)` 经过hash计算后应该落到`index=4`的桶中,由于`index=4`桶已经有了数据,所以往后迭代最终数据放入到`index=7`的桶中,放入后一段时间后`index=5`中的`Entry`数据`key`变为了`null`
+如上图,`set(27)` 经过 hash 计算后应该落到`index=4`的桶中,由于`index=4`桶已经有了数据,所以往后迭代最终数据放入到`index=7`的桶中,放入后一段时间后`index=5`中的`Entry`数据`key`变为了`null`

@@ -529,7 +526,7 @@ if (slotToExpunge != staleSlot)

-执行完第二步后,index=4的元素挪到index=3的槽位中。
+执行完第二步后,index=4 的元素挪到 index=3 的槽位中。
继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算`slot`位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置
@@ -581,7 +578,7 @@ if (k == null) {
e.value = null;
tab[i] = null;
size--;
-}
+}
```
如果`key`没有过期,重新计算当前`key`的下标位置是不是当前槽位下标位置,如果不是,那么说明产生了`hash`冲突,此时以新计算出来正确的槽位位置往后迭代,找到最近一个可以存放`entry`的位置。
@@ -686,7 +683,7 @@ private void resize() {

-我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于`ThreadLocal1`,所以需要继续往后迭代查找。
+我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是 4,而`index=4`的槽位已经有了数据,且`key`值不等于`ThreadLocal1`,所以需要继续往后迭代查找。
迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
@@ -724,9 +721,7 @@ private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
}
```
-
-### `ThreadLocalMap`过期key的启发式清理流程
-
+### `ThreadLocalMap`过期 key 的启发式清理流程
上面多次提及到`ThreadLocalMap`过期可以的两种清理方式:**探测式清理(expungeStaleEntry())**、**启发式清理(cleanSomeSlots())**
@@ -760,7 +755,7 @@ private boolean cleanSomeSlots(int i, int n) {
我们使用`ThreadLocal`的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
-为了解决这个问题,JDK中还有一个`InheritableThreadLocal`类,我们来看一个例子:
+为了解决这个问题,JDK 中还有一个`InheritableThreadLocal`类,我们来看一个例子:
```java
public class InheritableThreadLocalDemo {
@@ -816,11 +811,11 @@ private void init(ThreadGroup g, Runnable target, String name,
我们现在项目中日志记录用的是`ELK+Logstash`,最后在`Kibana`中进行展示和检索。
-现在都是分布式系统统一对外提供服务,项目间调用的关系可以通过traceId来关联,但是不同项目之间如何传递`traceId`呢?
+现在都是分布式系统统一对外提供服务,项目间调用的关系可以通过 `traceId` 来关联,但是不同项目之间如何传递 `traceId` 呢?
-这里我们使用`org.slf4j.MDC`来实现此功能,内部就是通过`ThreadLocal`来实现的,具体实现如下:
+这里我们使用 `org.slf4j.MDC` 来实现此功能,内部就是通过 `ThreadLocal` 来实现的,具体实现如下:
-当前端发送请求到**服务A**时,**服务A**会生成一个类似`UUID`的`traceId`字符串,将此字符串放入当前线程的`ThreadLocal`中,在调用**服务B**的时候,将`traceId`写入到请求的`Header`中,**服务B**在接收请求时会先判断请求的`Header`中是否有`traceId`,如果存在则写入自己线程的`ThreadLocal`中。
+当前端发送请求到**服务 A**时,**服务 A**会生成一个类似`UUID`的`traceId`字符串,将此字符串放入当前线程的`ThreadLocal`中,在调用**服务 B**的时候,将`traceId`写入到请求的`Header`中,**服务 B**在接收请求时会先判断请求的`Header`中是否有`traceId`,如果存在则写入自己线程的`ThreadLocal`中。

@@ -830,9 +825,10 @@ private void init(ThreadGroup g, Runnable target, String name,
针对于这些场景,我们都可以有相应的解决方案,如下所示
-#### Feign远程调用解决方案
+#### Feign 远程调用解决方案
**服务发送请求:**
+
```java
@Component
@Slf4j
@@ -849,6 +845,7 @@ public class FeignInvokeInterceptor implements RequestInterceptor {
```
**服务接收请求:**
+
```java
@Slf4j
@Component
@@ -876,13 +873,13 @@ public class LogInterceptor extends HandlerInterceptorAdapter {
}
```
-#### 线程池异步调用,requestId传递
+#### 线程池异步调用,requestId 传递
因为`MDC`是基于`ThreadLocal`去实现的,异步过程中,子线程并没有办法获取到父线程`ThreadLocal`存储的数据,所以这里可以自定义线程池执行器,修改其中的`run()`方法:
```java
public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
-
+
@Override
public void execute(Runnable runnable) {
Map context = MDC.getCopyOfContextMap();
@@ -903,11 +900,6 @@ public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
}
```
-#### 使用MQ发送消息给第三方系统
-
-在MQ发送的消息体中自定义属性`requestId`,接收方消费消息后,自己解析`requestId`使用即可。
-
-
-
-
+#### 使用 MQ 发送消息给第三方系统
+在 MQ 发送的消息体中自定义属性`requestId`,接收方消费消息后,自己解析`requestId`使用即可。