|
| 1 | +最近,当我在做一个项目的时候需要过滤掉重复的 URL ,为了完成这个任务,我学到了一种称为 Bloom Filter (布隆过滤器)的东西,然后我学会了它并写下了这个博客。 |
| 2 | + |
| 3 | +下面我们将分为几个方面来介绍布隆过滤器: |
| 4 | + |
| 5 | +1. 什么是布隆过滤器? |
| 6 | +2. 布隆过滤器的原理介绍。 |
| 7 | +3. 布隆过滤器使用场景。 |
| 8 | +4. 通过 Java 编程手动实现布隆过滤器。 |
| 9 | +5. 利用Google开源的Guava中自带的布隆过滤器。 |
| 10 | +6. Redis 中的布隆过滤器。 |
| 11 | +7. 总结。 |
| 12 | + |
| 13 | +### 1.什么是布隆过滤器? |
| 14 | + |
| 15 | +首先,我们需要了解布隆过滤器的概念。 |
| 16 | + |
| 17 | +布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。 |
| 18 | + |
| 19 | + |
| 20 | + |
| 21 | +位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000 / 8 = 125000 B = 15625 byte ≈ 15.3kb 的空间。 |
| 22 | + |
| 23 | +总结:**一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。** |
| 24 | + |
| 25 | +### 2.布隆过滤器的原理介绍 |
| 26 | + |
| 27 | +**当一个元素加入布隆过滤器中的时候,会进行如下操作:** |
| 28 | + |
| 29 | +1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。 |
| 30 | +2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。 |
| 31 | + |
| 32 | +**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:** |
| 33 | + |
| 34 | +1. 对给定元素再次进行相同的哈希计算; |
| 35 | +2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。 |
| 36 | + |
| 37 | +举个简单的例子: |
| 38 | + |
| 39 | + |
| 40 | + |
| 41 | +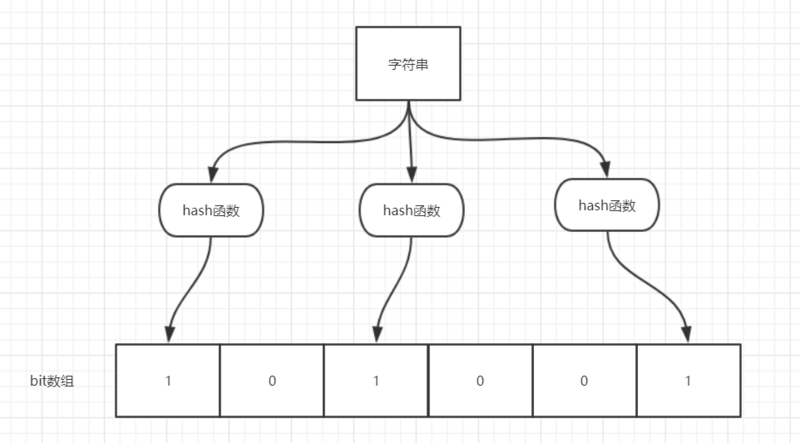 |
| 42 | + |
| 43 | +如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为1,所以很容易知道此值已经存在(去重非常方便)。 |
| 44 | + |
| 45 | +如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。 |
| 46 | + |
| 47 | +**不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。** |
| 48 | + |
| 49 | +综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。** |
| 50 | + |
| 51 | +### 3.布隆过滤器使用场景 |
| 52 | + |
| 53 | +1. 判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。 |
| 54 | +2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。 |
| 55 | + |
| 56 | +### 4.通过 Java 编程手动实现布隆过滤器 |
| 57 | + |
| 58 | +我们上面已经说了布隆过滤器的原理,知道了布隆过滤器的原理之后就可以自己手动实现一个了。 |
| 59 | + |
| 60 | +如果你想要手动实现一个的话,你需要: |
| 61 | + |
| 62 | +1. 一个合适大小的位数组保存数据 |
| 63 | +2. 几个不同的哈希函数 |
| 64 | +3. 添加元素到位数组(布隆过滤器)的方法实现 |
| 65 | +4. 判断给定元素是否存在于位数组(布隆过滤器)的方法实现。 |
| 66 | + |
| 67 | +下面给出一个我觉得写的还算不错的代码(参考网上已有代码改进得到,对于所有类型对象皆适用): |
| 68 | + |
| 69 | +```java |
| 70 | +import java.util.BitSet; |
| 71 | + |
| 72 | +public class MyBloomFilter { |
| 73 | + |
| 74 | + /** |
| 75 | + * 位数组的大小 |
| 76 | + */ |
| 77 | + private static final int DEFAULT_SIZE = 2 << 24; |
| 78 | + /** |
| 79 | + * 通过这个数组可以创建 6 个不同的哈希函数 |
| 80 | + */ |
| 81 | + private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134}; |
| 82 | + |
| 83 | + /** |
| 84 | + * 位数组。数组中的元素只能是 0 或者 1 |
| 85 | + */ |
| 86 | + private BitSet bits = new BitSet(DEFAULT_SIZE); |
| 87 | + |
| 88 | + /** |
| 89 | + * 存放包含 hash 函数的类的数组 |
| 90 | + */ |
| 91 | + private SimpleHash[] func = new SimpleHash[SEEDS.length]; |
| 92 | + |
| 93 | + /** |
| 94 | + * 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样 |
| 95 | + */ |
| 96 | + public MyBloomFilter() { |
| 97 | + // 初始化多个不同的 Hash 函数 |
| 98 | + for (int i = 0; i < SEEDS.length; i++) { |
| 99 | + func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]); |
| 100 | + } |
| 101 | + } |
| 102 | + |
| 103 | + /** |
| 104 | + * 添加元素到位数组 |
| 105 | + */ |
| 106 | + public void add(Object value) { |
| 107 | + for (SimpleHash f : func) { |
| 108 | + bits.set(f.hash(value), true); |
| 109 | + } |
| 110 | + } |
| 111 | + |
| 112 | + /** |
| 113 | + * 判断指定元素是否存在于位数组 |
| 114 | + */ |
| 115 | + public boolean contains(Object value) { |
| 116 | + boolean ret = true; |
| 117 | + for (SimpleHash f : func) { |
| 118 | + ret = ret && bits.get(f.hash(value)); |
| 119 | + } |
| 120 | + return ret; |
| 121 | + } |
| 122 | + |
| 123 | + /** |
| 124 | + * 静态内部类。用于 hash 操作! |
| 125 | + */ |
| 126 | + public static class SimpleHash { |
| 127 | + |
| 128 | + private int cap; |
| 129 | + private int seed; |
| 130 | + |
| 131 | + public SimpleHash(int cap, int seed) { |
| 132 | + this.cap = cap; |
| 133 | + this.seed = seed; |
| 134 | + } |
| 135 | + |
| 136 | + /** |
| 137 | + * 计算 hash 值 |
| 138 | + */ |
| 139 | + public int hash(Object value) { |
| 140 | + int h; |
| 141 | + return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16))); |
| 142 | + } |
| 143 | + |
| 144 | + } |
| 145 | +} |
| 146 | +``` |
| 147 | + |
| 148 | +测试: |
| 149 | + |
| 150 | +```java |
| 151 | + String value1 = "https://javaguide.cn/"; |
| 152 | + String value2 = "https://github.com/Snailclimb"; |
| 153 | + MyBloomFilter filter = new MyBloomFilter(); |
| 154 | + System.out.println(filter.contains(value1)); |
| 155 | + System.out.println(filter.contains(value2)); |
| 156 | + filter.add(value1); |
| 157 | + filter.add(value2); |
| 158 | + System.out.println(filter.contains(value1)); |
| 159 | + System.out.println(filter.contains(value2)); |
| 160 | +``` |
| 161 | + |
| 162 | +Output: |
| 163 | + |
| 164 | +``` |
| 165 | +false |
| 166 | +false |
| 167 | +true |
| 168 | +true |
| 169 | +``` |
| 170 | + |
| 171 | +测试: |
| 172 | + |
| 173 | +```java |
| 174 | + Integer value1 = 13423; |
| 175 | + Integer value2 = 22131; |
| 176 | + MyBloomFilter filter = new MyBloomFilter(); |
| 177 | + System.out.println(filter.contains(value1)); |
| 178 | + System.out.println(filter.contains(value2)); |
| 179 | + filter.add(value1); |
| 180 | + filter.add(value2); |
| 181 | + System.out.println(filter.contains(value1)); |
| 182 | + System.out.println(filter.contains(value2)); |
| 183 | +``` |
| 184 | + |
| 185 | +Output: |
| 186 | + |
| 187 | +```java |
| 188 | +false |
| 189 | +false |
| 190 | +true |
| 191 | +true |
| 192 | +``` |
| 193 | + |
| 194 | +### 5.利用Google开源的 Guava中自带的布隆过滤器 |
| 195 | + |
| 196 | +自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。 |
| 197 | + |
| 198 | +首先我们需要在项目中引入 Guava 的依赖: |
| 199 | + |
| 200 | +```java |
| 201 | + <dependency> |
| 202 | + <groupId>com.google.guava</groupId> |
| 203 | + <artifactId>guava</artifactId> |
| 204 | + <version>28.0-jre</version> |
| 205 | + </dependency> |
| 206 | +``` |
| 207 | + |
| 208 | +实际使用如下: |
| 209 | + |
| 210 | +我们创建了一个最多存放 最多 1500个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01) |
| 211 | + |
| 212 | +```java |
| 213 | + // 创建布隆过滤器对象 |
| 214 | + BloomFilter<Integer> filter = BloomFilter.create( |
| 215 | + Funnels.integerFunnel(), |
| 216 | + 1500, |
| 217 | + 0.01); |
| 218 | + // 判断指定元素是否存在 |
| 219 | + System.out.println(filter.mightContain(1)); |
| 220 | + System.out.println(filter.mightContain(2)); |
| 221 | + // 将元素添加进布隆过滤器 |
| 222 | + filter.put(1); |
| 223 | + filter.put(2); |
| 224 | + System.out.println(filter.mightContain(1)); |
| 225 | + System.out.println(filter.mightContain(2)); |
| 226 | +``` |
| 227 | + |
| 228 | +在我们的示例中,当`mightContain()` 方法返回*true*时,我们可以99%确定该元素在过滤器中,当过滤器返回*false*时,我们可以100%确定该元素不存在于过滤器中。 |
| 229 | + |
| 230 | +### 6.Redis 中的布隆过滤器 |
| 231 | + |
| 232 | +- https://juejin.im/post/5bc7446e5188255c791b3360 |
| 233 | + |
| 234 | +### 8.其他推荐阅读 |
| 235 | + |
| 236 | +1. 详解布隆过滤器的原理,使用场景和注意事项:https://zhuanlan.zhihu.com/p/43263751 |
| 237 | +2. |
0 commit comments