Date: Tue, 7 May 2019 19:21:49 +0800
Subject: [PATCH 034/102] Update readme
---
README.md | 1 -
docs/HomePage.md | 159 ++++++++++++++++++++++++-----------------------
2 files changed, 80 insertions(+), 80 deletions(-)
diff --git a/README.md b/README.md
index ec0d29134ce..4c35bde9edb 100644
--- a/README.md
+++ b/README.md
@@ -93,7 +93,6 @@
* [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
* [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
-
### JVM
* [Java内存区域](docs/java/jvm/Java内存区域.md)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index 43c740363e2..2f9aeaab351 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -1,6 +1,6 @@
Java后端技术交流群(限工作一年及以上,架构视频免费领取) :[](https://jq.qq.com/?_wv=1027&k=5QqyxIx)
-点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/docs/9BJjNsNg7S4dCnz3/)
+点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
Java 学习/面试指南
@@ -15,177 +15,178 @@ Java后端技术交流群(限工作一年及以上,架构视频免费领取)
-
## Java
### 基础
-* [Java 基础知识回顾](java/Java基础知识.md)
-* [J2EE 基础知识回顾](java/J2EE基础知识.md)
-* [Collections 工具类和 Arrays 工具类常见方法](java/Basis/Arrays%2CCollectionsCommonMethods.md)
-* [Java常见关键字总结:static、final、this、super](java/Basis/final、static、this、super.md)
+* [Java 基础知识回顾](./java/Java基础知识.md)
+* [J2EE 基础知识回顾](./java/J2EE基础知识.md)
+* [Collections 工具类和 Arrays 工具类常见方法](./java/Basis/Arrays%2CCollectionsCommonMethods.md)
+* [Java常见关键字总结:static、final、this、super](./java/Basis/final、static、this、super.md)
### 容器
* **常见问题总结:**
- * [这几道Java集合框架面试题几乎必问](java/这几道Java集合框架面试题几乎必问.md)
- * [Java 集合框架常见面试题总结](java/Java集合框架常见面试题总结.md)
+ * [这几道Java集合框架面试题几乎必问](./java/这几道Java集合框架面试题几乎必问.md)
+ * [Java 集合框架常见面试题总结](./java/Java集合框架常见面试题总结.md)
* **源码分析:**
- * [ArrayList 源码学习](java/ArrayList.md)
- * [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](java/ArrayList-Grow.md)
- * [LinkedList 源码学习](java/LinkedList.md)
- * [HashMap(JDK1.8)源码学习](java/HashMap.md)
+ * [ArrayList 源码学习](./java/ArrayList.md)
+ * [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](./java/ArrayList-Grow.md)
+ * [LinkedList 源码学习](./java/LinkedList.md)
+ * [HashMap(JDK1.8)源码学习](./java/HashMap.md)
### 并发
-* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
-* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
-* [并发编程面试必备:synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReentrantLock 的对比](java/synchronized.md)
-* [并发编程面试必备:乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
-* [并发编程面试必备:JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
-* [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
-* [并发容器总结](java/Multithread/并发容器总结.md)
+
+* [Java 并发基础常见面试题总结](./java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](./java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](./java/Multithread/并发容器总结.md)
+* [synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReentrantLock 的对比](./java/synchronized.md)
+* [乐观锁与悲观锁](./essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](./java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](./java/Multithread/AQS.md)
### JVM
-* [可能是把Java内存区域讲的最清楚的一篇文章](java/可能是把Java内存区域讲的最清楚的一篇文章.md)
-* [搞定JVM垃圾回收就是这么简单](java/搞定JVM垃圾回收就是这么简单.md)
-* [《深入理解Java虚拟机》第2版学习笔记](java/Java虚拟机(jvm).md)
+* [Java内存区域](./java/jvm/Java内存区域.md)
+* [JVM垃圾回收](./java/jvm/JVM垃圾回收.md)
+* [JDK 监控和故障处理工具](./java/jvm/JDK监控和故障处理工具总结.md)
+* [《深入理解Java虚拟机》第2版学习笔记](./java/Java虚拟机(jvm).md)
### I/O
-* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
-* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
+* [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](./java/Java%20IO与NIO.md)
### Java 8
-* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
-* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+* [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
### 编程规范
-- [Java 编程规范](java/Java编程规范.md)
+- [Java 编程规范](./java/Java编程规范.md)
## 网络
-* [计算机网络常见面试题](network/计算机网络.md)
-* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
-* [HTTPS中的TLS](network/HTTPS中的TLS.md)
+* [计算机网络常见面试题](./network/计算机网络.md)
+* [计算机网络基础知识总结](./network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](./network/HTTPS中的TLS.md)
## 操作系统
### Linux相关
-* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
-* [Shell 编程入门](operating-system/Shell.md)
+* [后端程序员必备的 Linux 基础知识](./operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](./operating-system/Shell.md)
## 数据结构与算法
### 数据结构
-- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
+- [数据结构知识学习与面试](./dataStructures-algorithms/数据结构.md)
### 算法
-- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
-- [算法总结——几道常见的子符串算法题 ](dataStructures-algorithms/几道常见的子符串算法题.md)
-- [算法总结——几道常见的链表算法题 ](dataStructures-algorithms/几道常见的链表算法题.md)
-- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
-- [公司真题](dataStructures-algorithms/公司真题.md)
-- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
+- [算法学习资源推荐](./dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的子符串算法题总结 ](./dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](./dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](./dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](./dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](./dataStructures-algorithms/Backtracking-NQueens.md)
## 数据库
### MySQL
-* [MySQL 学习与面试](database/MySQL.md)
-* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
-* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
-* [搞定数据库索引就是这么简单](database/MySQL%20Index.md)
-* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
-* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
+* [MySQL 学习与面试](./database/MySQL.md)
+* [一千行MySQL学习笔记](./database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](./database/MySQL高性能优化规范建议.md)
+* [搞定数据库索引就是这么简单](./database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](./database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](./database/一条sql语句在mysql中如何执行的.md)
### Redis
-* [Redis 总结](database/Redis/Redis.md)
-* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
-* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+* [Redis 总结](./database/Redis/Redis.md)
+* [Redlock分布式锁](./database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](./database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
## 系统设计
### 设计模式
-- [设计模式系列文章](system-design/设计模式.md)
+- [设计模式系列文章](./system-design/设计模式.md)
### 常用框架
#### Spring
-- [Spring 学习与面试](system-design/framework/Spring学习与面试.md)
-- [Spring中bean的作用域与生命周期](system-design/framework/SpringBean.md)
-- [SpringMVC 工作原理详解](system-design/framework/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
+- [Spring 学习与面试](./system-design/framework/Spring学习与面试.md)
+- [Spring中bean的作用域与生命周期](./system-design/framework/SpringBean.md)
+- [SpringMVC 工作原理详解](./system-design/framework/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
#### ZooKeeper
-- [可能是把 ZooKeeper 概念讲的最清楚的一篇文章](system-design/framework/ZooKeeper.md)
-- [ZooKeeper 数据模型和常见命令了解一下,速度收藏!](system-design/framework/ZooKeeper数据模型和常见命令.md)
+- [ZooKeeper 相关概念总结](./system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](./system-design/framework/ZooKeeper数据模型和常见命令.md)
### 数据通信
-- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/数据通信(RESTful、RPC、消息队列).md)
-- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
-- [消息队列总结:新手也能看懂,消息队列其实很简单](system-design/data-communication/message-queue.md)
-- [一文搞懂 RabbitMQ 的重要概念以及安装](system-design/data-communication/rabbitmq.md)
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](./system-design/data-communication/数据通信(RESTful、RPC、消息队列).md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](./system-design/data-communication/dubbo.md)
+- [消息队列总结](./system-design/data-communication/message-queue.md)
+- [RabbitMQ 的重要概念以及安装](./system-design/data-communication/rabbitmq.md)
### 网站架构
-- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
-- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
-- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+- [一文读懂分布式应该学什么](./system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](./system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](./system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
## 面试指南
### 备战面试
-* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
-* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
-* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
-* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
-* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
-* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+* [【备战面试1】程序员的简历就该这样写](./essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](./essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](./essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](./essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](./essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](./essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
### 常见面试题总结
-* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
-* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
-* [第三周(2018-08-22)](java/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
-* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+* [第一周(2018-8-7)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](./java/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
### 面经
-- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
-- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
-- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+- [5面阿里,终获offer(2018年秋招)](./essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](./essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](./essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
## 工具
### Git
-* [Git入门](tools/Git.md)
+* [Git入门](./tools/Git.md)
### Docker
-* [Docker 入门](tools/Docker.md)
-* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
+* [Docker 入门](./tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](./tools/Docker-Image.md)
## 资料
### 书单
-- [Java程序员必备书单](data/java-recommended-books.md)
+- [Java程序员必备书单](./data/java-recommended-books.md)
### Github榜单
-- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
+- [Java 项目月榜单](./github-trending/JavaGithubTrending.md)
***
From e12c55be220e2eba7b1900c22988800bee398971 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 19:37:51 +0800
Subject: [PATCH 035/102] Change file position
---
docs/java/{ => Multithread}/synchronized.md | 0
1 file changed, 0 insertions(+), 0 deletions(-)
rename docs/java/{ => Multithread}/synchronized.md (100%)
diff --git a/docs/java/synchronized.md b/docs/java/Multithread/synchronized.md
similarity index 100%
rename from docs/java/synchronized.md
rename to docs/java/Multithread/synchronized.md
From 8f3ac231149f6339263a8f4c1b18d9cdd25a2dcf Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 19:38:25 +0800
Subject: [PATCH 036/102] Update
JavaConcurrencyAdvancedCommonInterviewQuestions.md
---
.../JavaConcurrencyAdvancedCommonInterviewQuestions.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
index 21fe5034d70..de97d2376f7 100644
--- a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
+++ b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
@@ -144,7 +144,7 @@ JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484539&idx=1&sn=3500cdcd5188bdc253fb19a1bfa805e6&chksm=fd98521acaefdb0c5167247a1fa903a1a53bb4e050b558da574f894f9feda5378ec9d0fa1ac7&token=1604028915&lang=zh_CN#rd)
+关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](synchronized.md)
### 1.5. 谈谈 synchronized和ReentrantLock 的区别
@@ -612,4 +612,4 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
- 《Java并发编程的艺术》
- http://www.cnblogs.com/waterystone/p/4920797.html
- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
--
\ No newline at end of file
+-
From ec60cfa9b82d4f781773b196d7bc4c13a43d14ae Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 19:38:39 +0800
Subject: [PATCH 037/102] Update README.md
---
README.md | 1 -
1 file changed, 1 deletion(-)
diff --git a/README.md b/README.md
index 4c35bde9edb..cdd53520f1b 100644
--- a/README.md
+++ b/README.md
@@ -88,7 +88,6 @@
* [Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
* [Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
* [并发容器总结](docs/java/Multithread/并发容器总结.md)
-* [synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReentrantLock 的对比](docs/java/synchronized.md)
* [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
* [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
* [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
From 271c551dafbe453dfc510c37396dba88f5300f6f Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:04:47 +0800
Subject: [PATCH 038/102] Change file position
---
README.md | 12 +-
...25\351\242\230\346\200\273\347\273\223.md" | 353 --------------
docs/java/{ => collection}/ArrayList-Grow.md | 0
docs/java/{ => collection}/ArrayList.md | 0
docs/java/{ => collection}/HashMap.md | 0
...01\351\235\242\350\257\225\351\242\230.md" | 439 ++++++++++++++++++
docs/java/{ => collection}/LinkedList.md | 0
...40\344\271\216\345\277\205\351\227\256.md" | 273 -----------
8 files changed, 443 insertions(+), 634 deletions(-)
delete mode 100644 "docs/java/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
rename docs/java/{ => collection}/ArrayList-Grow.md (100%)
rename docs/java/{ => collection}/ArrayList.md (100%)
rename docs/java/{ => collection}/HashMap.md (100%)
create mode 100644 "docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
rename docs/java/{ => collection}/LinkedList.md (100%)
delete mode 100644 "docs/java/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md"
diff --git a/README.md b/README.md
index cdd53520f1b..64e2a08fc89 100644
--- a/README.md
+++ b/README.md
@@ -74,14 +74,10 @@
### 容器
-* **常见问题总结:**
- * [这几道Java集合框架面试题几乎必问](docs/java/这几道Java集合框架面试题几乎必问.md)
- * [Java 集合框架常见面试题总结](docs/java/Java集合框架常见面试题总结.md)
-* **源码分析:**
- * [ArrayList 源码学习](docs/java/ArrayList.md)
- * [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](docs/java/ArrayList-Grow.md)
- * [LinkedList 源码学习](docs/java/LinkedList.md)
- * [HashMap(JDK1.8)源码学习](docs/java/HashMap.md)
+* [这几道Java集合框架面试题几乎必问](docs/java/这几道Java集合框架面试题几乎必问.md)
+* [ArrayList 源码学习](docs/java/collection/ArrayList.md)
+* [LinkedList 源码学习](docs/java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](docs/java/collection/HashMap.md)
### 并发
diff --git "a/docs/java/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
deleted file mode 100644
index cb0bd1fe0e3..00000000000
--- "a/docs/java/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
+++ /dev/null
@@ -1,353 +0,0 @@
-
-
-1. [List,Set,Map三者的区别及总结](#list,setmap三者的区别及总结)
-1. [Arraylist 与 LinkedList 区别](#arraylist-与-linkedlist-区别)
-1. [ArrayList 与 Vector 区别(为什么要用Arraylist取代Vector呢?)](#arraylist-与-vector-区别)
-1. [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
-1. [HashSet 和 HashMap 区别](#hashset-和-hashmap-区别)
-1. [HashMap 和 ConcurrentHashMap 的区别](#hashmap-和-concurrenthashmap-的区别)
-1. [HashSet如何检查重复](#hashset如何检查重复)
-1. [comparable 和 comparator的区别](#comparable-和-comparator的区别)
- 1. [Comparator定制排序](#comparator定制排序)
- 1. [重写compareTo方法实现按年龄来排序](#重写compareto方法实现按年龄来排序)
-1. [如何对Object的list排序?](#如何对object的list排序)
-1. [如何实现数组与List的相互转换?](#如何实现数组与list的相互转换)
-1. [如何求ArrayList集合的交集 并集 差集 去重复并集](#如何求arraylist集合的交集-并集-差集-去重复并集)
-1. [HashMap 的工作原理及代码实现](#hashmap-的工作原理及代码实现)
-1. [ConcurrentHashMap 的工作原理及代码实现](#concurrenthashmap-的工作原理及代码实现)
-1. [集合框架底层数据结构总结](#集合框架底层数据结构总结)
- 1. [- Collection](#--collection)
- 1. [1. List](#1-list)
- 1. [2. Set](#2-set)
- 1. [- Map](#--map)
-1. [集合的选用](#集合的选用)
-1. [集合的常用方法](#集合的常用方法)
-
-
-
-
-## List,Set,Map三者的区别及总结
-- **List:对付顺序的好帮手**
-
- List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
-- **Set:注重独一无二的性质**
-
- 不允许重复的集合。不会有多个元素引用相同的对象。
-
-- **Map:用Key来搜索的专家**
-
- 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
-
-
-## Arraylist 与 LinkedList 区别
-Arraylist底层使用的是数组(存读数据效率高,插入删除特定位置效率低),LinkedList 底层使用的是双向链表数据结构(插入,删除效率特别高)(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别:); 详细可阅读JDK1.7-LinkedList循环链表优化。学过数据结构这门课后我们就知道采用链表存储,插入,删除元素时间复杂度不受元素位置的影响,都是近似O(1)而数组为近似O(n),因此当数据特别多,而且经常需要插入删除元素时建议选用LinkedList.一般程序只用Arraylist就够用了,因为一般数据量都不会蛮大,Arraylist是使用最多的集合类。
-
-## ArrayList 与 Vector 区别
-Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector
-,代码要在同步操作上耗费大量的时间。Arraylist不是同步的,所以在不需要同步时建议使用Arraylist。
-
-## HashMap 和 Hashtable 的区别
-1. HashMap是非线程安全的,HashTable是线程安全的;HashTable内部的方法基本都经过synchronized修饰。
-
-2. 因为线程安全的问题,HashMap要比HashTable效率高一点,HashTable基本被淘汰。
-3. HashMap允许有null值的存在,而在HashTable中put进的键值只要有一个null,直接抛出NullPointerException。
-
-Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java5或以上的话,请使用ConcurrentHashMap吧
-
-## HashSet 和 HashMap 区别
-
-
-## HashMap 和 ConcurrentHashMap 的区别
-[HashMap与ConcurrentHashMap的区别](https://blog.csdn.net/xuefeng0707/article/details/40834595)
-
-1. ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
-2. HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
-
-## HashSet如何检查重复
-当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
-
-**hashCode()与equals()的相关规定:**
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个equals方法返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
-4. 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
-5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
-
-**==与equals的区别**
-
-1. ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
-2. ==是指对内存地址进行比较 equals()是对字符串的内容进行比较
-3. ==指引用是否相同 equals()指的是值是否相同
-
-## comparable 和 comparator的区别
-- comparable接口实际上是出自java.lang包 它有一个 compareTo(Object obj)方法用来排序
-- comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
-
-一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo方法或compare方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的Collections.sort().
-
-### Comparator定制排序
-```java
-import java.util.ArrayList;
-import java.util.Collections;
-import java.util.Comparator;
-
-/**
- * TODO Collections类方法测试之排序
- * @author 寇爽
- * @date 2017年11月20日
- * @version 1.8
- */
-public class CollectionsSort {
-
- public static void main(String[] args) {
-
- ArrayList arrayList = new ArrayList();
- arrayList.add(-1);
- arrayList.add(3);
- arrayList.add(3);
- arrayList.add(-5);
- arrayList.add(7);
- arrayList.add(4);
- arrayList.add(-9);
- arrayList.add(-7);
- System.out.println("原始数组:");
- System.out.println(arrayList);
- // void reverse(List list):反转
- Collections.reverse(arrayList);
- System.out.println("Collections.reverse(arrayList):");
- System.out.println(arrayList);
-/*
- * void rotate(List list, int distance),旋转。
- * 当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将
- * list的前distance个元素整体移到后面。
-
- Collections.rotate(arrayList, 4);
- System.out.println("Collections.rotate(arrayList, 4):");
- System.out.println(arrayList);*/
-
- // void sort(List list),按自然排序的升序排序
- Collections.sort(arrayList);
- System.out.println("Collections.sort(arrayList):");
- System.out.println(arrayList);
-
- // void shuffle(List list),随机排序
- Collections.shuffle(arrayList);
- System.out.println("Collections.shuffle(arrayList):");
- System.out.println(arrayList);
-
- // 定制排序的用法
- Collections.sort(arrayList, new Comparator() {
-
- @Override
- public int compare(Integer o1, Integer o2) {
- return o2.compareTo(o1);
- }
- });
- System.out.println("定制排序后:");
- System.out.println(arrayList);
- }
-
-}
-
-```
-### 重写compareTo方法实现按年龄来排序
-```java
-package map;
-
-import java.util.Set;
-import java.util.TreeMap;
-
-public class TreeMap2 {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- TreeMap pdata = new TreeMap();
- pdata.put(new Person("张三", 30), "zhangsan");
- pdata.put(new Person("李四", 20), "lisi");
- pdata.put(new Person("王五", 10), "wangwu");
- pdata.put(new Person("小红", 5), "xiaohong");
- // 得到key的值的同时得到key所对应的值
- Set keys = pdata.keySet();
- for (Person key : keys) {
- System.out.println(key.getAge() + "-" + key.getName());
-
- }
- }
-}
-
-// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
-// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
-// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
-
-class Person implements Comparable {
- private String name;
- private int age;
-
- public Person(String name, int age) {
- super();
- this.name = name;
- this.age = age;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- /**
- * TODO重写compareTo方法实现按年龄来排序
- */
- @Override
- public int compareTo(Person o) {
- // TODO Auto-generated method stub
- if (this.age > o.getAge()) {
- return 1;
- } else if (this.age < o.getAge()) {
- return -1;
- }
- return age;
- }
-}
-```
-
-## 如何对Object的list排序
-- 对objects数组进行排序,我们可以用Arrays.sort()方法
-- 对objects的集合进行排序,需要使用Collections.sort()方法
-
-
-## 如何实现数组与List的相互转换
-List转数组:toArray(arraylist.size()方法;数组转List:Arrays的asList(a)方法
-```java
-List arrayList = new ArrayList();
- arrayList.add("s");
- arrayList.add("e");
- arrayList.add("n");
- /**
- * ArrayList转数组
- */
- int size=arrayList.size();
- String[] a = arrayList.toArray(new String[size]);
- //输出第二个元素
- System.out.println(a[1]);//结果:e
- //输出整个数组
- System.out.println(Arrays.toString(a));//结果:[s, e, n]
- /**
- * 数组转list
- */
- List list=Arrays.asList(a);
- /**
- * list转Arraylist
- */
- List arrayList2 = new ArrayList();
- arrayList2.addAll(list);
- System.out.println(list);
-```
-## 如何求ArrayList集合的交集 并集 差集 去重复并集
-需要用到List接口中定义的几个方法:
-
-- addAll(Collection c) :按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾
-实例代码:
-- retainAll(Collection c): 仅保留此列表中包含在指定集合中的元素。
-- removeAll(Collection c) :从此列表中删除指定集合中包含的所有元素。
-```java
-package list;
-
-import java.util.ArrayList;
-import java.util.List;
-
-/**
- *TODO 两个集合之间求交集 并集 差集 去重复并集
- * @author 寇爽
- * @date 2017年11月21日
- * @version 1.8
- */
-public class MethodDemo {
-
- public static void main(String[] args) {
- // TODO Auto-generated method stub
- List list1 = new ArrayList();
- list1.add(1);
- list1.add(2);
- list1.add(3);
- list1.add(4);
-
- List list2 = new ArrayList();
- list2.add(2);
- list2.add(3);
- list2.add(4);
- list2.add(5);
- // 并集
- // list1.addAll(list2);
- // 交集
- //list1.retainAll(list2);
- // 差集
- // list1.removeAll(list2);
- // 无重复并集
- list2.removeAll(list1);
- list1.addAll(list2);
- for (Integer i : list1) {
- System.out.println(i);
- }
- }
-
-}
-
-```
-
-## HashMap 的工作原理及代码实现
-
-[集合框架源码学习之HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
-
-## ConcurrentHashMap 的工作原理及代码实现
-
-[ConcurrentHashMap实现原理及源码分析](http://www.cnblogs.com/chengxiao/p/6842045.html)
-
-
-## 集合框架底层数据结构总结
-### - Collection
-
-#### 1. List
- - Arraylist:数组(查询快,增删慢 线程不安全,效率高 )
- - Vector:数组(查询快,增删慢 线程安全,效率低 )
- - LinkedList:链表(查询慢,增删快 线程不安全,效率高 )
-
-#### 2. Set
- - HashSet(无序,唯一):哈希表或者叫散列集(hash table)
- - LinkedHashSet:链表和哈希表组成 。 由链表保证元素的排序 , 由哈希表证元素的唯一性
- - TreeSet(有序,唯一):红黑树(自平衡的排序二叉树。)
-
-### - Map
- - HashMap:基于哈希表的Map接口实现(哈希表对键进行散列,Map结构即映射表存放键值对)
- - LinkedHashMap:HashMap 的基础上加上了链表数据结构
- - HashTable:哈希表
- - TreeMap:红黑树(自平衡的排序二叉树)
-
-
-## 集合的选用
-主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap.当我们只需要存放元素值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。
-
-2018/3/11更新
-## 集合的常用方法
-今天下午无意看见一道某大厂的面试题,面试题的内容就是问你某一个集合常见的方法有哪些。虽然平时也经常见到这些集合,但是猛一下让我想某一个集合的常用的方法难免会有遗漏或者与其他集合搞混,所以建议大家还是照着API文档把常见的那几个集合的常用方法看一看。
-
-会持续更新。。。
-
-**参考书籍:**
-
-《Head first java 》第二版 推荐阅读真心不错 (适合基础较差的)
-
- 《Java核心技术卷1》推荐阅读真心不错 (适合基础较好的)
-
- 《算法》第四版 (适合想对数据结构的Java实现感兴趣的)
-
diff --git a/docs/java/ArrayList-Grow.md b/docs/java/collection/ArrayList-Grow.md
similarity index 100%
rename from docs/java/ArrayList-Grow.md
rename to docs/java/collection/ArrayList-Grow.md
diff --git a/docs/java/ArrayList.md b/docs/java/collection/ArrayList.md
similarity index 100%
rename from docs/java/ArrayList.md
rename to docs/java/collection/ArrayList.md
diff --git a/docs/java/HashMap.md b/docs/java/collection/HashMap.md
similarity index 100%
rename from docs/java/HashMap.md
rename to docs/java/collection/HashMap.md
diff --git "a/docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md" "b/docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
new file mode 100644
index 00000000000..98892078ef9
--- /dev/null
+++ "b/docs/java/collection/Java\351\233\206\345\220\210\346\241\206\346\236\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230.md"
@@ -0,0 +1,439 @@
+
+
+- [剖析面试最常见问题之Java基础知识](#剖析面试最常见问题之java基础知识)
+ - [说说List,Set,Map三者的区别?](#说说listsetmap三者的区别)
+ - [Arraylist 与 LinkedList 区别?](#arraylist-与-linkedlist-区别)
+ - [**补充内容:RandomAccess接口**](#补充内容randomaccess接口)
+ - [补充内容:双向链表和双向循环链表](#补充内容双向链表和双向循环链表)
+ - [ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?](#arraylist-与-vector-区别呢为什么要用arraylist取代vector呢)
+ - [说一说 ArrayList 的扩容机制吧](#说一说-arraylist-的扩容机制吧)
+ - [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
+ - [HashMap 和 HashSet区别](#hashmap-和-hashset区别)
+ - [HashSet如何检查重复](#hashset如何检查重复)
+ - [HashMap的底层实现](#hashmap的底层实现)
+ - [JDK1.8之前](#jdk18之前)
+ - [JDK1.8之后](#jdk18之后)
+ - [HashMap 的长度为什么是2的幂次方](#hashmap-的长度为什么是2的幂次方)
+ - [HashMap 多线程操作导致死循环问题](#hashmap-多线程操作导致死循环问题)
+ - [ConcurrentHashMap 和 Hashtable 的区别](#concurrenthashmap-和-hashtable-的区别)
+ - [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](#concurrenthashmap线程安全的具体实现方式底层具体实现)
+ - [JDK1.7(上面有示意图)](#jdk17上面有示意图)
+ - [JDK1.8 (上面有示意图)](#jdk18-上面有示意图)
+ - [comparable 和 Comparator的区别](#comparable-和-comparator的区别)
+ - [Comparator定制排序](#comparator定制排序)
+ - [重写compareTo方法实现按年龄来排序](#重写compareto方法实现按年龄来排序)
+ - [集合框架底层数据结构总结](#集合框架底层数据结构总结)
+ - [Collection](#collection)
+ - [1. List](#1-list)
+ - [2. Set](#2-set)
+ - [Map](#map)
+ - [如何选用集合?](#如何选用集合)
+ - [集合的选用](#集合的选用)
+
+
+
+# 剖析面试最常见问题之Java基础知识
+
+## 说说List,Set,Map三者的区别?
+
+- **List(对付顺序的好帮手):** List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
+- **Set(注重独一无二的性质):** 不允许重复的集合。不会有多个元素引用相同的对象。
+- **Map(用Key来搜索的专家):** 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
+
+## Arraylist 与 LinkedList 区别?
+
+- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
+
+- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
+
+- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
+
+- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
+
+- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+### **补充内容:RandomAccess接口**
+
+```
+public interface RandomAccess {
+}
+```
+
+查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
+
+在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
+
+```
+ public static
+ int binarySearch(List> list, T key) {
+ if (list instanceof RandomAccess || list.size()< 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+ }
+ public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+ }
+```
+
+下面这个方法保证了 HashMap 总是使用2的幂作为哈希表的大小。
+
+```java
+ /**
+ * Returns a power of two size for the given target capacity.
+ */
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+```
+
+## HashMap 和 HashSet区别
+
+如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 `clone() `、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
+
+| HashMap | HashSet |
+| :------------------------------: | :----------------------------------------------------------: |
+| 实现了Map接口 | 实现Set接口 |
+| 存储键值对 | 仅存储对象 |
+| 调用 `put()`向map中添加元素 | 调用 `add()`方法向Set中添加元素 |
+| HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性, |
+
+## HashSet如何检查重复
+
+当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
+
+**hashCode()与equals()的相关规定:**
+
+1. 如果两个对象相等,则hashcode一定也是相同的
+2. 两个对象相等,对两个equals方法返回true
+3. 两个对象有相同的hashcode值,它们也不一定是相等的
+4. 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
+5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
+
+**==与equals的区别**
+
+1. ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
+2. ==是指对内存地址进行比较 equals()是对字符串的内容进行比较
+3. ==指引用是否相同 equals()指的是值是否相同
+
+## HashMap的底层实现
+
+### JDK1.8之前
+
+JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
+
+**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
+
+**JDK 1.8 HashMap 的 hash 方法源码:**
+
+JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
+
+```
+ static final int hash(Object key) {
+ int h;
+ // key.hashCode():返回散列值也就是hashcode
+ // ^ :按位异或
+ // >>>:无符号右移,忽略符号位,空位都以0补齐
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+ }
+```
+
+对比一下 JDK1.7的 HashMap 的 hash 方法源码.
+
+```
+static int hash(int h) {
+ // This function ensures that hashCodes that differ only by
+ // constant multiples at each bit position have a bounded
+ // number of collisions (approximately 8 at default load factor).
+
+ h ^= (h >>> 20) ^ (h >>> 12);
+ return h ^ (h >>> 7) ^ (h >>> 4);
+}
+```
+
+相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
+
+所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
+
+[](https://camo.githubusercontent.com/eec1c575aa5ff57906dd9c9130ec7a82e212c96a/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f332f32302f313632343064626363333033643837323f773d33343826683d34323726663d706e6726733d3130393931)
+
+### JDK1.8之后
+
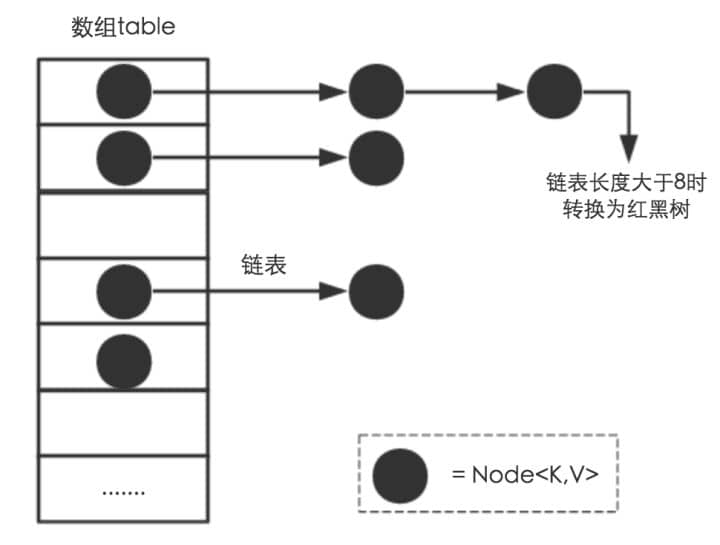
+相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
+
+[](https://camo.githubusercontent.com/20de7e465cac279842851258ec4d1ec1c4d3d7d1/687474703a2f2f6d792d626c6f672d746f2d7573652e6f73732d636e2d6265696a696e672e616c6979756e63732e636f6d2f31382d382d32322f36373233333736342e6a7067)
+
+> TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
+
+**推荐阅读:**
+
+- 《Java 8系列之重新认识HashMap》 :
+
+## HashMap 的长度为什么是2的幂次方
+
+为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
+
+**这个算法应该如何设计呢?**
+
+我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。**
+
+## HashMap 多线程操作导致死循环问题
+
+主要原因在于 并发下的Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
+
+详情请查看:
+
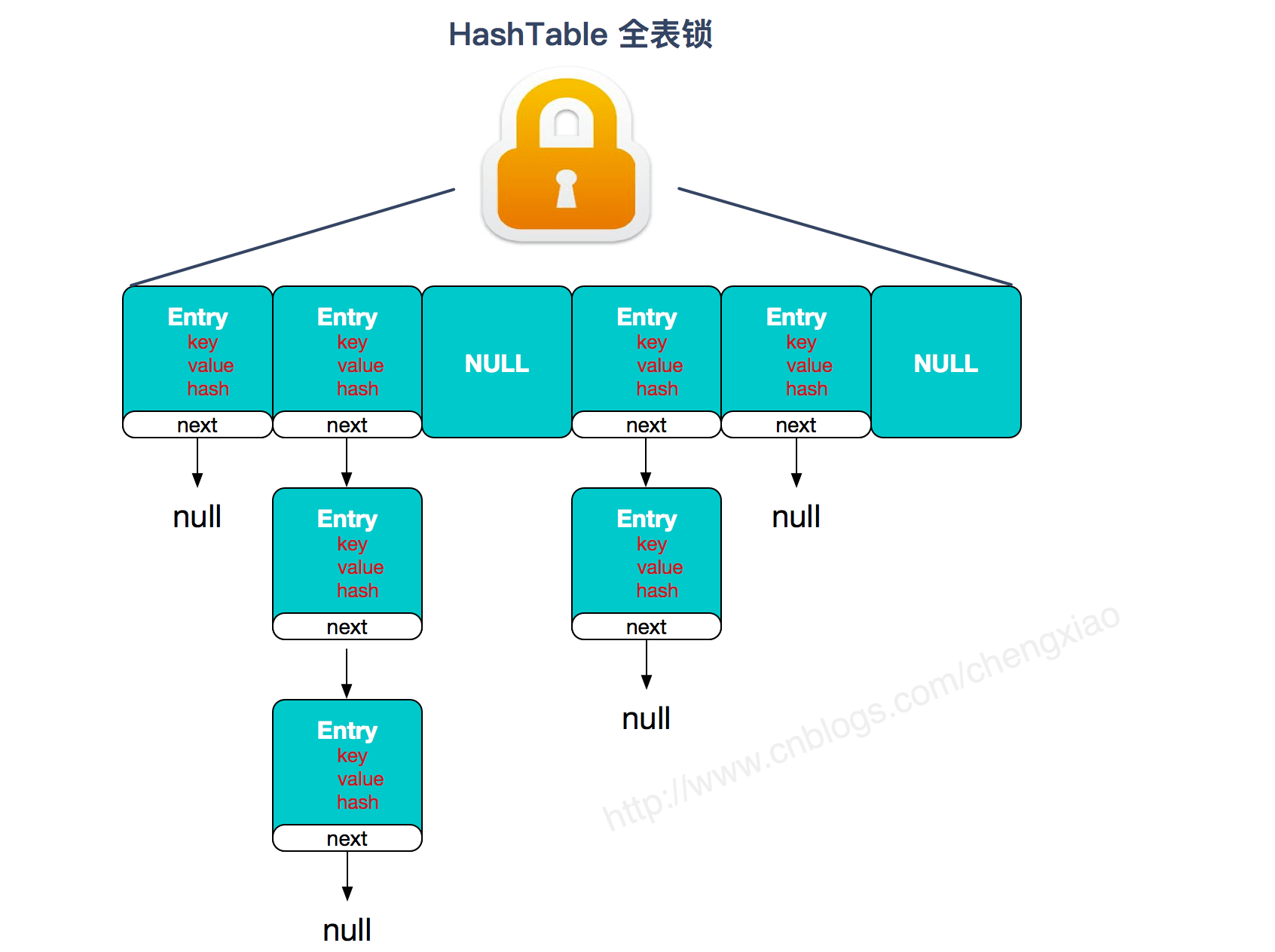
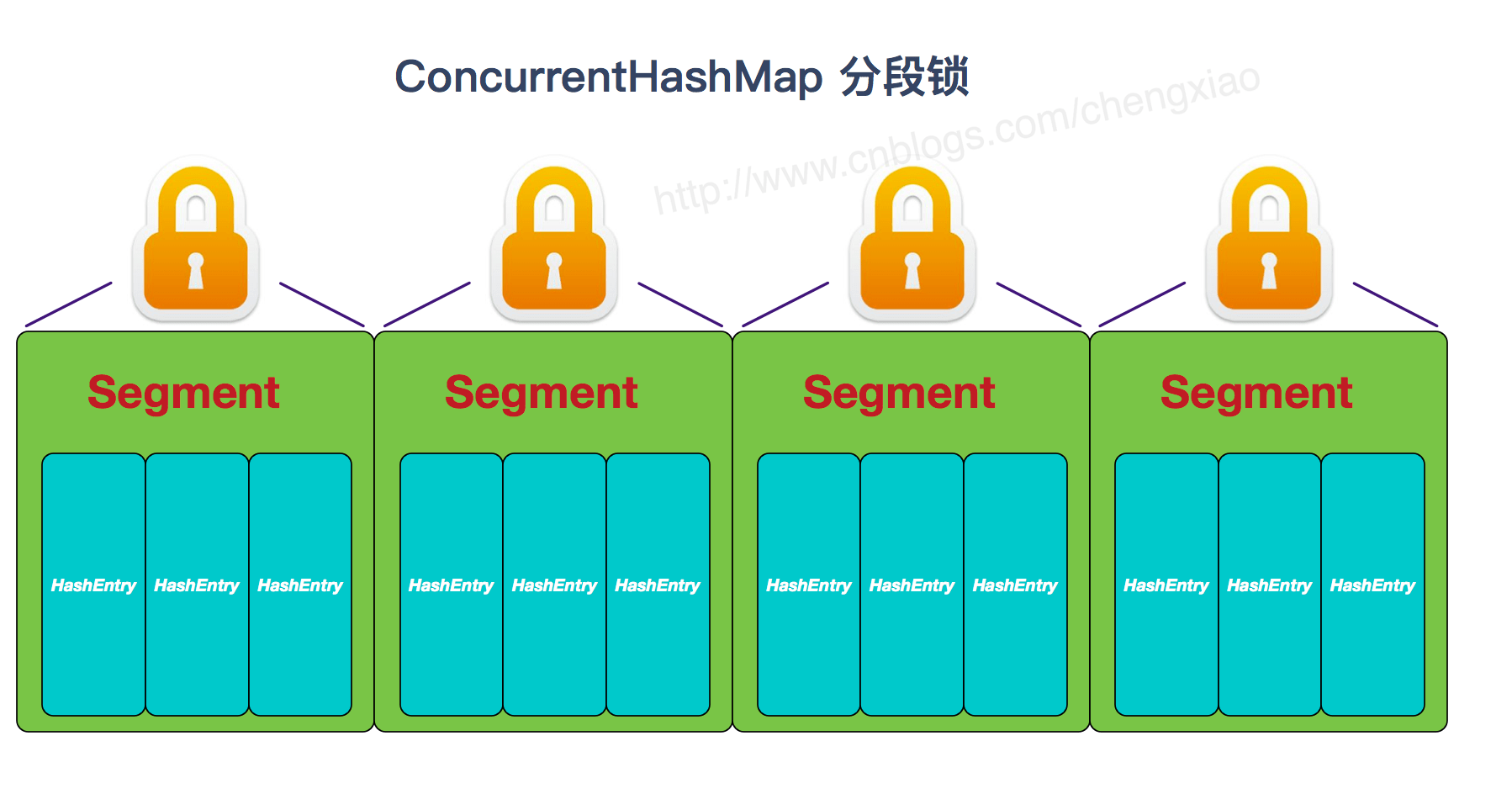
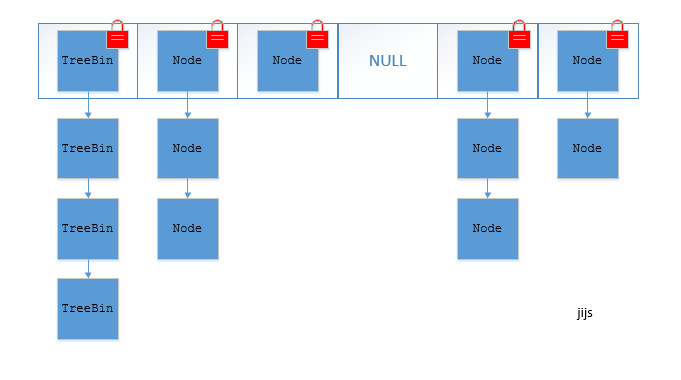
+## ConcurrentHashMap 和 Hashtable 的区别
+
+ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
+
+- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
+- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
+
+**两者的对比图:**
+
+图片来源:
+
+HashTable: [](https://camo.githubusercontent.com/b8e66016373bb109e923205857aeee9689baac9e/687474703a2f2f6d792d626c6f672d746f2d7573652e6f73732d636e2d6265696a696e672e616c6979756e63732e636f6d2f31382d382d32322f35303635363638312e6a7067)
+
+**JDK1.7的ConcurrentHashMap:** [](https://camo.githubusercontent.com/443af05b6be6ed09e50c78a1dca39bf75acb106d/687474703a2f2f6d792d626c6f672d746f2d7573652e6f73732d636e2d6265696a696e672e616c6979756e63732e636f6d2f31382d382d32322f33333132303438382e6a7067)**JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):** [](https://camo.githubusercontent.com/2d779bf515db75b5bf364c4f23c31268330a865e/687474703a2f2f6d792d626c6f672d746f2d7573652e6f73732d636e2d6265696a696e672e616c6979756e63732e636f6d2f31382d382d32322f39373733393232302e6a7067)
+
+## ConcurrentHashMap线程安全的具体实现方式/底层具体实现
+
+### JDK1.7(上面有示意图)
+
+首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
+
+**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
+
+Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
+
+```
+static class Segment extends ReentrantLock implements Serializable {
+}
+```
+
+一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
+
+### JDK1.8 (上面有示意图)
+
+ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))
+
+synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
+
+## comparable 和 Comparator的区别
+
+- comparable接口实际上是出自java.lang包 它有一个 `compareTo(Object obj)`方法用来排序
+- comparator接口实际上是出自 java.util 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
+
+一般我们需要对一个集合使用自定义排序时,我们就要重写`compareTo()`方法或`compare()`方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写`compareTo()`方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 `Collections.sort()`.
+
+### Comparator定制排序
+
+```java
+ ArrayList arrayList = new ArrayList();
+ arrayList.add(-1);
+ arrayList.add(3);
+ arrayList.add(3);
+ arrayList.add(-5);
+ arrayList.add(7);
+ arrayList.add(4);
+ arrayList.add(-9);
+ arrayList.add(-7);
+ System.out.println("原始数组:");
+ System.out.println(arrayList);
+ // void reverse(List list):反转
+ Collections.reverse(arrayList);
+ System.out.println("Collections.reverse(arrayList):");
+ System.out.println(arrayList);
+
+ // void sort(List list),按自然排序的升序排序
+ Collections.sort(arrayList);
+ System.out.println("Collections.sort(arrayList):");
+ System.out.println(arrayList);
+ // 定制排序的用法
+ Collections.sort(arrayList, new Comparator() {
+
+ @Override
+ public int compare(Integer o1, Integer o2) {
+ return o2.compareTo(o1);
+ }
+ });
+ System.out.println("定制排序后:");
+ System.out.println(arrayList);
+```
+
+Output:
+
+```
+原始数组:
+[-1, 3, 3, -5, 7, 4, -9, -7]
+Collections.reverse(arrayList):
+[-7, -9, 4, 7, -5, 3, 3, -1]
+Collections.sort(arrayList):
+[-9, -7, -5, -1, 3, 3, 4, 7]
+定制排序后:
+[7, 4, 3, 3, -1, -5, -7, -9]
+```
+
+### 重写compareTo方法实现按年龄来排序
+
+```java
+// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
+// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
+// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
+
+public class Person implements Comparable {
+ private String name;
+ private int age;
+
+ public Person(String name, int age) {
+ super();
+ this.name = name;
+ this.age = age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+
+ /**
+ * TODO重写compareTo方法实现按年龄来排序
+ */
+ @Override
+ public int compareTo(Person o) {
+ // TODO Auto-generated method stub
+ if (this.age > o.getAge()) {
+ return 1;
+ } else if (this.age < o.getAge()) {
+ return -1;
+ }
+ return age;
+ }
+}
+
+```
+
+```java
+ public static void main(String[] args) {
+ TreeMap pdata = new TreeMap();
+ pdata.put(new Person("张三", 30), "zhangsan");
+ pdata.put(new Person("李四", 20), "lisi");
+ pdata.put(new Person("王五", 10), "wangwu");
+ pdata.put(new Person("小红", 5), "xiaohong");
+ // 得到key的值的同时得到key所对应的值
+ Set keys = pdata.keySet();
+ for (Person key : keys) {
+ System.out.println(key.getAge() + "-" + key.getName());
+
+ }
+ }
+```
+
+Output:
+
+```
+5-小红
+10-王五
+20-李四
+30-张三
+```
+
+## 集合框架底层数据结构总结
+
+### Collection
+
+#### 1. List
+
+- **Arraylist:** Object数组
+- **Vector:** Object数组
+- **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环) 详细可阅读[JDK1.7-LinkedList循环链表优化](https://www.cnblogs.com/xingele0917/p/3696593.html)
+
+#### 2. Set
+
+- **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
+- **LinkedHashSet:** LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
+- **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树。)
+
+### Map
+
+- **HashMap:** JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
+- **LinkedHashMap:** LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
+- **Hashtable:** 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
+- **TreeMap:** 红黑树(自平衡的排序二叉树)
+
+## 如何选用集合?
+
+## 集合的选用
+
+主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap.当我们只需要存放元素值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。
\ No newline at end of file
diff --git a/docs/java/LinkedList.md b/docs/java/collection/LinkedList.md
similarity index 100%
rename from docs/java/LinkedList.md
rename to docs/java/collection/LinkedList.md
diff --git "a/docs/java/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md" "b/docs/java/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md"
deleted file mode 100644
index 16d7a41adea..00000000000
--- "a/docs/java/\350\277\231\345\207\240\351\201\223Java\351\233\206\345\220\210\346\241\206\346\236\266\351\235\242\350\257\225\351\242\230\345\207\240\344\271\216\345\277\205\351\227\256.md"
+++ /dev/null
@@ -1,273 +0,0 @@
-
-
-
-
-- [Arraylist 与 LinkedList 异同](#arraylist-与-linkedlist-异同)
- - [补充:数据结构基础之双向链表](#补充:数据结构基础之双向链表)
-- [ArrayList 与 Vector 区别](#arraylist-与-vector-区别)
-- [HashMap的底层实现](#hashmap的底层实现)
- - [JDK1.8之前](#jdk18之前)
- - [JDK1.8之后](#jdk18之后)
-- [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
-- [HashMap 的长度为什么是2的幂次方](#hashmap-的长度为什么是2的幂次方)
-- [HashMap 多线程操作导致死循环问题](#hashmap-多线程操作导致死循环问题)
-- [HashSet 和 HashMap 区别](#hashset-和-hashmap-区别)
-- [ConcurrentHashMap 和 Hashtable 的区别](#concurrenthashmap-和-hashtable-的区别)
-- [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](#concurrenthashmap线程安全的具体实现方式底层具体实现)
- - [JDK1.7(上面有示意图)](#jdk17(上面有示意图))
- - [JDK1.8 (上面有示意图)](#jdk18-(上面有示意图))
-- [集合框架底层数据结构总结](#集合框架底层数据结构总结)
- - [Collection](#collection)
- - [1. List](#1-list)
- - [2. Set](#2-set)
- - [Map](#map)
- - [推荐阅读:](#推荐阅读:)
-
-
-
-## Arraylist 与 LinkedList 异同
-
-- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别:); 详细可阅读[JDK1.7-LinkedList循环链表优化](https://www.cnblogs.com/xingele0917/p/3696593.html)
-- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
-- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
-- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
-- **6.补充内容:RandomAccess接口**
-
-```java
-public interface RandomAccess {
-}
-```
-
-查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
-
-在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
-
-```java
- public static
- int binarySearch(List> list, T key) {
- if (list instanceof RandomAccess || list.size()>>:无符号右移,忽略符号位,空位都以0补齐
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
- ```
-对比一下 JDK1.7的 HashMap 的 hash 方法源码.
-
-```java
-static int hash(int h) {
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
-
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
-}
-```
-
-相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
-
-所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
-
-
-
-
-
-### JDK1.8之后
-相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
-
-
-
->TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
-**推荐阅读:**
-
-- 《Java 8系列之重新认识HashMap》 :[https://zhuanlan.zhihu.com/p/21673805](https://zhuanlan.zhihu.com/p/21673805)
-
-## HashMap 和 Hashtable 的区别
-
-1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 `synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
-2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
-4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
-5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
-**HasMap 中带有初始容量的构造函数:**
-
-```java
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- this.loadFactor = loadFactor;
- this.threshold = tableSizeFor(initialCapacity);
- }
- public HashMap(int initialCapacity) {
- this(initialCapacity, DEFAULT_LOAD_FACTOR);
- }
-```
-
-下面这个方法保证了 HashMap 总是使用2的幂作为哈希表的大小。
-
-```java
- /**
- * Returns a power of two size for the given target capacity.
- */
- static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- }
-```
-
-## HashMap 的长度为什么是2的幂次方
-
-为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash` ”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
-
-**这个算法应该如何设计呢?**
-
-我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。**
-
-## HashMap 多线程操作导致死循环问题
-
-主要原因在于 并发下的Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
-
-详情请查看:
-
-
-## HashSet 和 HashMap 区别
-
-如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)
-
-
-
-## ConcurrentHashMap 和 Hashtable 的区别
-
-ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
-- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
-- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
-
-**两者的对比图:**
-
-图片来源:http://www.cnblogs.com/chengxiao/p/6842045.html
-
-HashTable:
-
-
-JDK1.7的ConcurrentHashMap:
-
-JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点
-Node: 链表节点):
-
-
-## ConcurrentHashMap线程安全的具体实现方式/底层具体实现
-
-### JDK1.7(上面有示意图)
-
-首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
-
-**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
-
-Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
-
-```java
-static class Segment extends ReentrantLock implements Serializable {
-}
-```
-
-一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
-
-### JDK1.8 (上面有示意图)
-
-ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))
-
-synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
-
-
-
-## 集合框架底层数据结构总结
-### Collection
-
-#### 1. List
- - **Arraylist:** Object数组
- - **Vector:** Object数组
- - **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
- 详细可阅读[JDK1.7-LinkedList循环链表优化](https://www.cnblogs.com/xingele0917/p/3696593.html)
-
-#### 2. Set
- - **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
- - **LinkedHashSet:** LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
- - **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树。)
-
-### Map
- - **HashMap:** JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
- - **LinkedHashMap:** LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
- - **Hashtable:** 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
- - **TreeMap:** 红黑树(自平衡的排序二叉树)
-
-
-
-
-### 推荐阅读:
-
-- [jdk1.8中ConcurrentHashMap的实现原理](https://blog.csdn.net/fjse51/article/details/55260493)
-- [HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你!](https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/)
-- [HASHMAP、HASHTABLE、CONCURRENTHASHMAP的原理与区别](http://www.yuanrengu.com/index.php/2017-01-17.html)
-- [ConcurrentHashMap实现原理及源码分析](https://www.cnblogs.com/chengxiao/p/6842045.html)
-- [java-并发-ConcurrentHashMap高并发机制-jdk1.8](https://blog.csdn.net/jianghuxiaojin/article/details/52006118#commentBox)
From 6d7b0ffb817409d6b80261f017f6f7f176b995c0 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:07:32 +0800
Subject: [PATCH 039/102] Fix link error
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 64e2a08fc89..f218e639aff 100644
--- a/README.md
+++ b/README.md
@@ -74,7 +74,7 @@
### 容器
-* [这几道Java集合框架面试题几乎必问](docs/java/这几道Java集合框架面试题几乎必问.md)
+* [常见面试题](docs/java/collection/Java集合框架常见面试题.md)
* [ArrayList 源码学习](docs/java/collection/ArrayList.md)
* [LinkedList 源码学习](docs/java/collection/LinkedList.md)
* [HashMap(JDK1.8)源码学习](docs/java/collection/HashMap.md)
From 8f8ffdac6f62bf015afd6be2b87cd7066359a381 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:15:43 +0800
Subject: [PATCH 040/102] Add content
---
README.md | 2 --
...345\237\272\347\241\200\347\237\245\350\257\206.md" | 10 ++++++++++
2 files changed, 10 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index f218e639aff..250642c6ad8 100644
--- a/README.md
+++ b/README.md
@@ -69,8 +69,6 @@
* [Java 基础知识回顾](docs/java/Java基础知识.md)
* [J2EE 基础知识回顾](docs/java/J2EE基础知识.md)
-* [Collections 工具类和 Arrays 工具类常见方法](docs/java/Basis/Arrays%2CCollectionsCommonMethods.md)
-* [Java常见关键字总结:static、final、this、super](docs/java/Basis/final、static、this、super.md)
### 容器
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 11b1e4e3908..9186c90d98c 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -50,6 +50,8 @@
- [35 Java 中 IO 流分为几种?BIO,NIO,AIO 有什么区别?](#35-java-中-io-流分为几种bionioaio-有什么区别)
- [java 中 IO 流分为几种?](#java-中-io-流分为几种)
- [BIO,NIO,AIO 有什么区别?](#bionioaio-有什么区别)
+- [36. 常见关键字总结:static,final,this,super](#36-常见关键字总结staticfinalthissuper)
+- [37. Collections 工具类和 Arrays 工具类常见方法总结](#37-collections-工具类和-arrays-工具类常见方法总结)
- [参考](#参考)
- [公众号](#公众号)
@@ -497,6 +499,14 @@ Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很
- **NIO (New I/O):** NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 `Socket` 和 `ServerSocket` 相对应的 `SocketChannel` 和 `ServerSocketChannel` 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
- **AIO (Asynchronous I/O):** AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
+## 36. 常见关键字总结:static,final,this,super
+
+详见笔主的这篇文章: [Java常见关键字总结:static,final,this,super](Basis/final、static、this、super.md)
+
+## 37. Collections 工具类和 Arrays 工具类常见方法总结
+
+详见笔主的这篇文章:[Collections 工具类和 Arrays 工具类常见方法](Basis/Arrays,CollectionsCommonMethods.md)
+
## 参考
- https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
From 68da51fd68842335a6a82ef955a17d6a08efee06 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:17:49 +0800
Subject: [PATCH 041/102] Update HomePage.md
---
docs/HomePage.md | 14 ++++----------
1 file changed, 4 insertions(+), 10 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index 2f9aeaab351..31b6fd3bf2d 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -21,19 +21,13 @@ Java后端技术交流群(限工作一年及以上,架构视频免费领取)
* [Java 基础知识回顾](./java/Java基础知识.md)
* [J2EE 基础知识回顾](./java/J2EE基础知识.md)
-* [Collections 工具类和 Arrays 工具类常见方法](./java/Basis/Arrays%2CCollectionsCommonMethods.md)
-* [Java常见关键字总结:static、final、this、super](./java/Basis/final、static、this、super.md)
### 容器
-* **常见问题总结:**
- * [这几道Java集合框架面试题几乎必问](./java/这几道Java集合框架面试题几乎必问.md)
- * [Java 集合框架常见面试题总结](./java/Java集合框架常见面试题总结.md)
-* **源码分析:**
- * [ArrayList 源码学习](./java/ArrayList.md)
- * [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](./java/ArrayList-Grow.md)
- * [LinkedList 源码学习](./java/LinkedList.md)
- * [HashMap(JDK1.8)源码学习](./java/HashMap.md)
+* [常见面试题](./java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](./java/collection/ArrayList.md)
+* [LinkedList 源码学习](./java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](./java/collection/HashMap.md)
### 并发
From 3d1de2031debe5d3ceba653605a29996e91cd07a Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:23:53 +0800
Subject: [PATCH 042/102] =?UTF-8?q?Update=20Java=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\237\272\347\241\200\347\237\245\350\257\206.md" | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 9186c90d98c..ffb55c77d57 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -501,11 +501,11 @@ Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很
## 36. 常见关键字总结:static,final,this,super
-详见笔主的这篇文章: [Java常见关键字总结:static,final,this,super](Basis/final、static、this、super.md)
+详见笔主的这篇文章: [Java常见关键字总结:static,final,this,super](
Date: Tue, 7 May 2019 20:25:11 +0800
Subject: [PATCH 043/102] Fix link error
---
.../JavaConcurrencyAdvancedCommonInterviewQuestions.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
index de97d2376f7..78a22674d39 100644
--- a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
+++ b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
@@ -144,7 +144,7 @@ JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](synchronized.md)
+关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比]()
### 1.5. 谈谈 synchronized和ReentrantLock 的区别
From d6138d09fa7d9f805fa3ff41eeb4e97434f8e892 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:31:28 +0800
Subject: [PATCH 044/102] =?UTF-8?q?Update=20Java=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\237\272\347\241\200\347\237\245\350\257\206.md" | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index ffb55c77d57..09175f2157c 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -501,11 +501,11 @@ Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很
## 36. 常见关键字总结:static,final,this,super
-详见笔主的这篇文章: [Java常见关键字总结:static,final,this,super](
## 37. Collections 工具类和 Arrays 工具类常见方法总结
-详见笔主的这篇文章:[Collections 工具类和 Arrays 工具类常见方法](https://gitee.com/SnailClimb/JavaGuide/blob/master/docs/java/Basis/Arrays,CollectionsCommonMethods.md)
+详见笔主的这篇文章:
## 参考
From bf56143fb77f4720553d84e0d7d836a1f419714f Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:34:09 +0800
Subject: [PATCH 045/102] Update
JavaConcurrencyAdvancedCommonInterviewQuestions.md
---
.../JavaConcurrencyAdvancedCommonInterviewQuestions.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
index 78a22674d39..fda84da3892 100644
--- a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
+++ b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
@@ -144,7 +144,7 @@ JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比]()
+关于这几种优化的详细信息可以查看笔主的这篇文章:
### 1.5. 谈谈 synchronized和ReentrantLock 的区别
From 5fc633356c707e5c8a51bb1731dd14fb6a8957fa Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 7 May 2019 20:36:24 +0800
Subject: [PATCH 046/102] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 250642c6ad8..c9c8f27a843 100644
--- a/README.md
+++ b/README.md
@@ -199,7 +199,7 @@
* [第一周(2018-8-7)](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
* [第二周(2018-8-13)](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
-* [第三周(2018-08-22)](docs/java/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第三周(2018-08-22)](docs/java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
* [第四周(2018-8-30).md](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
### 面经
From a7e5d5542be3732afa8cc90cb56efc1620176583 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 8 May 2019 10:00:57 +0800
Subject: [PATCH 047/102] =?UTF-8?q?Update=20JDK=E7=9B=91=E6=8E=A7=E5=92=8C?=
=?UTF-8?q?=E6=95=85=E9=9A=9C=E5=A4=84=E7=90=86=E5=B7=A5=E5=85=B7=E6=80=BB?=
=?UTF-8?q?=E7=BB=93.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...20\206\345\267\245\345\205\267\346\200\273\347\273\223.md" | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git "a/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md" "b/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md"
index 5f1e7e655e4..ec4a001f3cf 100644
--- "a/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md"
+++ "b/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md"
@@ -156,7 +156,7 @@ Server is ready.
**下面是一个线程死锁的代码。我们下面会通过 `jstack` 命令进行死锁检查,输出死锁信息,找到发生死锁的线程。**
-```
+```java
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
@@ -331,4 +331,4 @@ VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
\ No newline at end of file
+
From 361ecc4b4053f4b738ec55d665e786ea1b22c4c9 Mon Sep 17 00:00:00 2001
From: yanggy <50225852+yguangyin@users.noreply.github.com>
Date: Wed, 8 May 2019 14:16:12 +0800
Subject: [PATCH 048/102] =?UTF-8?q?=E5=88=A0=E9=99=A4=E9=87=8D=E5=A4=8D?=
=?UTF-8?q?=E2=80=9C=E4=BD=BF=E7=94=A8=E2=80=9D?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\237\272\347\241\200\347\237\245\350\257\206.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 09175f2157c..80bacaa776c 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -259,7 +259,7 @@ Java 程序在执行子类的构造方法之前,如果没有用 super() 来调
## 18. 成员变量与局部变量的区别有那些?
1. 从语法形式上看:成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
-2. 从变量在内存中的存储方式来看:如果成员变量是使用`static`修饰的,那么这个成员变量是属于类的,如果没有使用使用`static`修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
+2. 从变量在内存中的存储方式来看:如果成员变量是使用`static`修饰的,那么这个成员变量是属于类的,如果没有使用`static`修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
3. 从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
4. 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外被 final 修饰的成员变量也必须显示地赋值),而局部变量则不会自动赋值。
From ba443bcedd314f6f8e1d390a3c23e67d3b7ef2d2 Mon Sep 17 00:00:00 2001
From: Joe
Date: Wed, 8 May 2019 15:26:31 +0800
Subject: [PATCH 049/102] Update BIO-NIO-AIO.md
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
修改错别字
---
docs/java/BIO-NIO-AIO.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/java/BIO-NIO-AIO.md b/docs/java/BIO-NIO-AIO.md
index c5ec6dddd04..b1e101d0539 100644
--- a/docs/java/BIO-NIO-AIO.md
+++ b/docs/java/BIO-NIO-AIO.md
@@ -42,7 +42,7 @@
- **阻塞:** 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
- **非阻塞:** 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
-举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在哪里傻等着水开(**同步阻塞**)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(**同步非阻塞**)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(**异步非阻塞**)。
+举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(**同步阻塞**)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(**同步非阻塞**)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(**异步非阻塞**)。
## 1. BIO (Blocking I/O)
@@ -73,7 +73,7 @@ BIO通信(一请求一应答)模型图如下(图源网络,原出处不明)
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
-伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层任然是同步阻塞的BIO模型,因此无法从根本上解决问题。
+伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。
### 1.3 代码示例
From c64ea1788231c896331f89ed825349fd573b48ac Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 8 May 2019 21:59:29 +0800
Subject: [PATCH 050/102] Update Atomic.md
---
docs/java/Multithread/Atomic.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/docs/java/Multithread/Atomic.md b/docs/java/Multithread/Atomic.md
index 0c6a9dc041b..1afb5f56511 100644
--- a/docs/java/Multithread/Atomic.md
+++ b/docs/java/Multithread/Atomic.md
@@ -50,6 +50,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
- 描述: 第一个线程取到了变量 x 的值 A,然后巴拉巴拉干别的事,总之就是只拿到了变量 x 的值 A。这段时间内第二个线程也取到了变量 x 的值 A,然后把变量 x 的值改为 B,然后巴拉巴拉干别的事,最后又把变量 x 的值变为 A (相当于还原了)。在这之后第一个线程终于进行了变量 x 的操作,但是此时变量 x 的值还是 A,所以 compareAndSet 操作是成功。
- 例子描述(可能不太合适,但好理解): 年初,现金为零,然后通过正常劳动赚了三百万,之后正常消费了(比如买房子)三百万。年末,虽然现金零收入(可能变成其他形式了),但是赚了钱是事实,还是得交税的!
- 代码例子(以``` AtomicInteger ```为例)
+
```java
import java.util.concurrent.atomic.AtomicInteger;
@@ -110,7 +111,9 @@ public class AtomicIntegerDefectDemo {
}
}
```
+
输出内容如下:
+
```
Thread-0 ------ currentValue=1
Thread-1 ------ currentValue=1, finalValue=2, compareAndSet Result=true
From 3a1a9e2a78cef88b366e9688e042c243af653a71 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 8 May 2019 23:27:56 +0800
Subject: [PATCH 051/102] =?UTF-8?q?Update=20Java=E5=86=85=E5=AD=98?=
=?UTF-8?q?=E5=8C=BA=E5=9F=9F.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\206\205\345\255\230\345\214\272\345\237\237.md" | 2 ++
1 file changed, 2 insertions(+)
diff --git "a/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md" "b/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
index 1afa91c4eee..bfca94d6f62 100644
--- "a/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
+++ "b/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
@@ -35,6 +35,8 @@
# Java 内存区域详解
+如果没有特殊说明,都是针对的是 HotSpot 虚拟机。
+
## 写在前面 (常见面试题)
### 基本问题
From 6f4c5d45b43c1d9b52f523580527cae5d6f2822a Mon Sep 17 00:00:00 2001
From: Liu Guangming
Date: Thu, 9 May 2019 12:46:34 +0800
Subject: [PATCH 052/102] Update Java8Tutorial.md
---
docs/java/What's New in JDK8/Java8Tutorial.md | 18 +++++++++---------
1 file changed, 9 insertions(+), 9 deletions(-)
diff --git a/docs/java/What's New in JDK8/Java8Tutorial.md b/docs/java/What's New in JDK8/Java8Tutorial.md
index cee4d4e4f0a..0ba8b27f7cd 100644
--- a/docs/java/What's New in JDK8/Java8Tutorial.md
+++ b/docs/java/What's New in JDK8/Java8Tutorial.md
@@ -442,15 +442,15 @@ optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
```java
-List stringCollection = new ArrayList<>();
-stringCollection.add("ddd2");
-stringCollection.add("aaa2");
-stringCollection.add("bbb1");
-stringCollection.add("aaa1");
-stringCollection.add("bbb3");
-stringCollection.add("ccc");
-stringCollection.add("bbb2");
-stringCollection.add("ddd1");
+List stringList = new ArrayList<>();
+stringList.add("ddd2");
+stringList.add("aaa2");
+stringList.add("bbb1");
+stringList.add("aaa1");
+stringList.add("bbb3");
+stringList.add("ccc");
+stringList.add("bbb2");
+stringList.add("ddd1");
```
Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
From 76fcc1734523b8807b335fd1baa9042de2094525 Mon Sep 17 00:00:00 2001
From: Liu Guangming
Date: Thu, 9 May 2019 13:16:29 +0800
Subject: [PATCH 053/102] =?UTF-8?q?Update=20MySQL=E9=AB=98=E6=80=A7?=
=?UTF-8?q?=E8=83=BD=E4=BC=98=E5=8C=96=E8=A7=84=E8=8C=83=E5=BB=BA=E8=AE=AE?=
=?UTF-8?q?.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\214\226\350\247\204\350\214\203\345\273\272\350\256\256.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/database/MySQL\351\253\230\346\200\247\350\203\275\344\274\230\345\214\226\350\247\204\350\214\203\345\273\272\350\256\256.md" "b/docs/database/MySQL\351\253\230\346\200\247\350\203\275\344\274\230\345\214\226\350\247\204\350\214\203\345\273\272\350\256\256.md"
index dcfc2edd210..f079ad77593 100644
--- "a/docs/database/MySQL\351\253\230\346\200\247\350\203\275\344\274\230\345\214\226\350\247\204\350\214\203\345\273\272\350\256\256.md"
+++ "b/docs/database/MySQL\351\253\230\346\200\247\350\203\275\344\274\230\345\214\226\350\247\204\350\214\203\345\273\272\350\256\256.md"
@@ -311,7 +311,7 @@ select name,phone from customer where id = '111';
### 4. 数据库设计时,应该要对以后扩展进行考虑
-### 5. 程序连接不同的数据库使用不同的账号,进制跨库查询
+### 5. 程序连接不同的数据库使用不同的账号,禁止跨库查询
- 为数据库迁移和分库分表留出余地
- 降低业务耦合度
From cae1e93e0db1c17f9ed22036c7acdf7f9de460b5 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E6=8A=B1=E7=B4=A7=E6=88=91=E7=9A=84=E5=B0=8F=E9=B2=A4?=
=?UTF-8?q?=E9=B1=BC?=
Date: Thu, 9 May 2019 15:44:34 +0800
Subject: [PATCH 054/102] =?UTF-8?q?Update=20Redlock=E5=88=86=E5=B8=83?=
=?UTF-8?q?=E5=BC=8F=E9=94=81.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/database/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md" "b/docs/database/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md"
index b1742f2fbf9..86a15ff6faf 100644
--- "a/docs/database/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md"
+++ "b/docs/database/Redis/Redlock\345\210\206\345\270\203\345\274\217\351\224\201.md"
@@ -28,7 +28,7 @@ end
算法很易懂,起 5 个 master 节点,分布在不同的机房尽量保证可用性。为了获得锁,client 会进行如下操作:
-1. 得到当前的时间,微妙单位
+1. 得到当前的时间,微秒单位
2. 尝试顺序地在 5 个实例上申请锁,当然需要使用相同的 key 和 random value,这里一个 client 需要合理设置与 master 节点沟通的 timeout 大小,避免长时间和一个 fail 了的节点浪费时间
3. 当 client 在大于等于 3 个 master 上成功申请到锁的时候,且它会计算申请锁消耗了多少时间,这部分消耗的时间采用获得锁的当下时间减去第一步获得的时间戳得到,如果锁的持续时长(lock validity time)比流逝的时间多的话,那么锁就真正获取到了。
4. 如果锁申请到了,那么锁真正的 lock validity time 应该是 origin(lock validity time) - 申请锁期间流逝的时间
From dfcff9b1481beef2a92c95ee8a9edf8a7478c530 Mon Sep 17 00:00:00 2001
From: aptkid
Date: Thu, 9 May 2019 20:05:09 +0800
Subject: [PATCH 055/102] Update LinkedList.md
---
docs/java/collection/LinkedList.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/java/collection/LinkedList.md b/docs/java/collection/LinkedList.md
index 983c1fae0d0..d26bc752267 100644
--- a/docs/java/collection/LinkedList.md
+++ b/docs/java/collection/LinkedList.md
@@ -458,7 +458,7 @@ public class LinkedListDemo {
linkedList.add(3);
linkedList.removeFirstOccurrence(3); // 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表)
System.out.println("After removeFirstOccurrence(3):" + linkedList);
- linkedList.removeLastOccurrence(3); // 从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表)
+ linkedList.removeLastOccurrence(3); // 从此列表中移除最后一次出现的指定元素(从尾部到头部遍历列表)
System.out.println("After removeFirstOccurrence(3):" + linkedList);
/************************** 遍历操作 ************************/
From c6206288a62dc470abbd1ca700dd19b67101086f Mon Sep 17 00:00:00 2001
From: Liu Guangming
Date: Fri, 10 May 2019 11:50:48 +0800
Subject: [PATCH 056/102] =?UTF-8?q?Update=20J2EE=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
index ced017ab47b..c900eb8ff76 100644
--- "a/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -93,7 +93,7 @@ Form标签里的method的属性为get时调用doGet(),为post时调用doPost()
**转发是服务器行为,重定向是客户端行为。**
-**转发(Forword)**
+**转发(Forward)**
通过RequestDispatcher对象的forward(HttpServletRequest request,HttpServletResponse response)方法实现的。RequestDispatcher可以通过HttpServletRequest 的getRequestDispatcher()方法获得。例如下面的代码就是跳转到login_success.jsp页面。
```java
request.getRequestDispatcher("login_success.jsp").forward(request, response);
From a19dc12b0c2d081eae99fc5e4075697631348d86 Mon Sep 17 00:00:00 2001
From: Liu Guangming
Date: Fri, 10 May 2019 11:51:46 +0800
Subject: [PATCH 057/102] =?UTF-8?q?Update=201=E5=B9=B6=E5=8F=91=E7=BC=96?=
=?UTF-8?q?=E7=A8=8B=E5=9F=BA=E7=A1=80=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\250\213\345\237\272\347\241\200\347\237\245\350\257\206.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/Multithread/1\345\271\266\345\217\221\347\274\226\347\250\213\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Multithread/1\345\271\266\345\217\221\347\274\226\347\250\213\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 2e2c8c399f9..66c26fd7d01 100644
--- "a/docs/java/Multithread/1\345\271\266\345\217\221\347\274\226\347\250\213\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Multithread/1\345\271\266\345\217\221\347\274\226\347\250\213\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -57,7 +57,7 @@ public class MultiThread {
#### 1.3.1 图解进程和线程的关系
-下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下我的这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》](https://github.com/Snailclimb/JavaGuide/blob/master/Java 相关/可能是把 Java 内存区域讲的最清楚的一篇文章.md)
+下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下我的这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》]()

From 9babf88f2296979a5b6de0b05ce1cea59aaefe52 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Fri, 10 May 2019 13:35:43 +0800
Subject: [PATCH 058/102] Update HomePage.md
---
docs/HomePage.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index 31b6fd3bf2d..aaaf5acb85a 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -34,7 +34,6 @@ Java后端技术交流群(限工作一年及以上,架构视频免费领取)
* [Java 并发基础常见面试题总结](./java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
* [Java 并发进阶常见面试题总结](./java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
* [并发容器总结](./java/Multithread/并发容器总结.md)
-* [synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReentrantLock 的对比](./java/synchronized.md)
* [乐观锁与悲观锁](./essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
* [JUC 中的 Atomic 原子类总结](./java/Multithread/Atomic.md)
* [AQS 原理以及 AQS 同步组件总结](./java/Multithread/AQS.md)
@@ -152,7 +151,7 @@ Java后端技术交流群(限工作一年及以上,架构视频免费领取)
* [第一周(2018-8-7)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
* [第二周(2018-8-13)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
-* [第三周(2018-08-22)](./java/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第三周(2018-08-22)](./java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
* [第四周(2018-8-30).md](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
### 面经
@@ -182,6 +181,7 @@ Java后端技术交流群(限工作一年及以上,架构视频免费领取)
- [Java 项目月榜单](./github-trending/JavaGithubTrending.md)
+
***
## 待办
From 85ce52cf86ffec7d36a38d048ef56f645d7a3d8c Mon Sep 17 00:00:00 2001
From: shenghui <416834871@qq.com>
Date: Fri, 10 May 2019 17:47:48 +0800
Subject: [PATCH 059/102] =?UTF-8?q?Update=20=E8=AE=A1=E7=AE=97=E6=9C=BA?=
=?UTF-8?q?=E7=BD=91=E7=BB=9C.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index d8c74ef5bf4..1c694a5abb3 100644
--- "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -205,7 +205,7 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
**2) 出现差错情况(超时重传):**

-停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为 **自动重传请求 ARQ** 。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。**连续 ARQ 协议** 可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
+停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为 **自动重传请求 ARQ** 。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。**连续 ARQ 协议** 可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
**3) 确认丢失和确认迟到**
From 5a536d5de470f7a20b554787b8cbd44436682976 Mon Sep 17 00:00:00 2001
From: shenghui <416834871@qq.com>
Date: Fri, 10 May 2019 18:11:19 +0800
Subject: [PATCH 060/102] =?UTF-8?q?Update=20=E5=B9=B2=E8=B4=A7=EF=BC=9A?=
=?UTF-8?q?=E8=AE=A1=E7=AE=97=E6=9C=BA=E7=BD=91=E7=BB=9C=E7=9F=A5=E8=AF=86?=
=?UTF-8?q?=E6=80=BB=E7=BB=93.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
index 8e994dd7b14..2a2a4a8b693 100644
--- "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
+++ "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
@@ -52,7 +52,7 @@
大写字母I开头的Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用TCP/IP协议作为通信规则,其前身为ARPANET。Internet的推荐译名为因特网,现在一般流行称为互联网。
- 3,路由器是实现分组交换的关键构件,其任务是转发受到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后在进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组有称为包。分组是在互联网中传送的数据单元,正式由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
+ 3,路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由西组成边缘部分,其作用是提供连通性和交换。
From dfb83b7968007ac7781ced7414d67295d5b5da3d Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 11 May 2019 11:04:22 +0800
Subject: [PATCH 061/102] =?UTF-8?q?Update=20Java=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\237\272\347\241\200\347\237\245\350\257\206.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 80bacaa776c..ff51fbc1e02 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -242,7 +242,7 @@ Java 程序在执行子类的构造方法之前,如果没有用 super() 来调
## 16. import java和javax有什么区别?
-刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准API的一部分。
+刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准API的一部分。
所以,实际上java和javax没有区别。这都是一个名字。
From 544d22a2676c4ce5832a410309dddd333b6e0a25 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 11 May 2019 11:09:22 +0800
Subject: [PATCH 062/102] Update README.md
---
README.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/README.md b/README.md
index c9c8f27a843..a97c0504a87 100644
--- a/README.md
+++ b/README.md
@@ -317,6 +317,9 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
 +
+
+
+  +
### 公众号
From f7db5e7b52bc60fded72e0402aa2f936a1c7ac8a Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 12 May 2019 21:30:29 +0800
Subject: [PATCH 063/102] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index a97c0504a87..a8a85443b37 100644
--- a/README.md
+++ b/README.md
@@ -18,7 +18,7 @@
+
### 公众号
From f7db5e7b52bc60fded72e0402aa2f936a1c7ac8a Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 12 May 2019 21:30:29 +0800
Subject: [PATCH 063/102] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index a97c0504a87..a8a85443b37 100644
--- a/README.md
+++ b/README.md
@@ -18,7 +18,7 @@
-  +
+ 
From 15f18bdc68b9314deb087578773104ba05ebf826 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 12 May 2019 21:31:39 +0800
Subject: [PATCH 064/102] Update HomePage.md
---
docs/HomePage.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index aaaf5acb85a..d2250e65313 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -11,7 +11,7 @@ Java后端技术交流群(限工作一年及以上,架构视频免费领取)
Special Sponsors
-
+
From 627c51ef07dd957c856da44614e787b509fb2dbe Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E9=9D=B3=E9=98=B3?= <260893248@qq.com>
Date: Mon, 13 May 2019 18:45:04 +0800
Subject: [PATCH 065/102] =?UTF-8?q?=E4=BF=AE=E6=94=B9=E4=B8=80=E5=A4=84?=
=?UTF-8?q?=E6=8B=BC=E5=86=99=E9=94=99=E8=AF=AF?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
修改一处拼写错误
---
docs/java/What's New in JDK8/Java8Tutorial.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/java/What's New in JDK8/Java8Tutorial.md b/docs/java/What's New in JDK8/Java8Tutorial.md
index 0ba8b27f7cd..8bf59a6a686 100644
--- a/docs/java/What's New in JDK8/Java8Tutorial.md
+++ b/docs/java/What's New in JDK8/Java8Tutorial.md
@@ -918,7 +918,7 @@ System.out.println(hints2.length); // 2
-## Whete to go from here?
+## Where to go from here?
关于Java 8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK 1.8里还有很多很有用的东西,比如`Arrays.parallelSort`, `StampedLock`和`CompletableFuture`等等。
From d4baea65becaad485d5bd33de9412a02b3cab846 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 14 May 2019 18:36:00 +0800
Subject: [PATCH 066/102] Update HomePage.md
---
docs/HomePage.md | 2 --
1 file changed, 2 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index d2250e65313..820417b66fa 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -1,5 +1,3 @@
-Java后端技术交流群(限工作一年及以上,架构视频免费领取) :[](https://jq.qq.com/?_wv=1027&k=5QqyxIx)
-
点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
Java 学习/面试指南
From b594e29e9902cb0a153deb0e48abf1f1059f7a91 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 14 May 2019 22:56:14 +0800
Subject: [PATCH 067/102] Update README.md
---
README.md | 7 +++++--
1 file changed, 5 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index a8a85443b37..7bc5168099e 100644
--- a/README.md
+++ b/README.md
@@ -18,10 +18,14 @@
-
+
+
+
+ 
+
推荐一下我的另外一个正在维护的项目:[programmer-advancement](https://github.com/Snailclimb/programmer-advancement) (技术人员成长必备!)
推荐使用 在线阅读(访问速度慢的话,请使用 ),在线阅读内容本仓库同步一致。这种方式阅读的优势在于:有侧边栏阅读体验更好,Gitee pages 的访问速度相对来说也比较快。
@@ -280,7 +284,6 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
下面是笔主收集的一些对本仓库提过有价值的pr或者issue的朋友,人数较多,如果你也对本仓库提过不错的pr或者issue的话,你可以加我的微信与我联系。下面的排名不分先后!
-
 From a1c9195295b173518f2795003ce386eff4a17417 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 14 May 2019 23:01:25 +0800
Subject: [PATCH 068/102] Update README.md
---
README.md | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/README.md b/README.md
index 7bc5168099e..db3e2fb90d6 100644
--- a/README.md
+++ b/README.md
@@ -20,14 +20,13 @@
-
+
-推荐一下我的另外一个正在维护的项目:[programmer-advancement](https://github.com/Snailclimb/programmer-advancement) (技术人员成长必备!)
-
推荐使用 在线阅读(访问速度慢的话,请使用 ),在线阅读内容本仓库同步一致。这种方式阅读的优势在于:有侧边栏阅读体验更好,Gitee pages 的访问速度相对来说也比较快。
## 目录
From 8c0861076a5fe86b4b19ba8a36ec2b47bb628b24 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:08:09 +0800
Subject: [PATCH 069/102] Update README.md
---
README.md | 1 -
1 file changed, 1 deletion(-)
diff --git a/README.md b/README.md
index db3e2fb90d6..fe995647566 100644
--- a/README.md
+++ b/README.md
@@ -94,7 +94,6 @@
* [Java内存区域](docs/java/jvm/Java内存区域.md)
* [JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
* [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
-* [《深入理解Java虚拟机》第2版学习笔记](docs/java/Java虚拟机(jvm).md)
### I/O
From 7fe9aad6951e46c650a69ebf582dc1dafd49ac0e Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:10:40 +0800
Subject: [PATCH 070/102] =?UTF-8?q?Delete=20Java=E8=99=9A=E6=8B=9F?=
=?UTF-8?q?=E6=9C=BA=EF=BC=88jvm=EF=BC=89.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...346\234\272\357\274\210jvm\357\274\211.md" | 59 -------------------
1 file changed, 59 deletions(-)
delete mode 100644 "docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
diff --git "a/docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md" "b/docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
deleted file mode 100644
index 9be88bc89c3..00000000000
--- "a/docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
+++ /dev/null
@@ -1,59 +0,0 @@
-
-下面是按jvm虚拟机知识点分章节总结的一些jvm学习与面试相关的一些东西。一般作为Java程序员在面试的时候一般会问的大多就是**Java内存区域、虚拟机垃圾算法、虚拟垃圾收集器、JVM内存管理**这些问题了。这些内容参考周的《深入理解Java虚拟机》中第二章和第三章就足够了对应下面的[深入理解虚拟机之Java内存区域:](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483910%26idx%3D1%26sn%3D246f39051a85fc312577499691fba89f%26chksm%3Dfd985467caefdd71f9a7c275952be34484b14f9e092723c19bd4ef557c324169ed084f868bdb%23rd)和[深入理解虚拟机之垃圾回收](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483914%26idx%3D1%26sn%3D9aa157d4a1570962c39783cdeec7e539%26chksm%3Dfd98546bcaefdd7d9f61cd356e5584e56b64e234c3a403ed93cb6d4dde07a505e3000fd0c427%23rd)这两篇文章。
-
-
-> ### 常见面试题
-
-[深入理解虚拟机之Java内存区域](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484960&idx=1&sn=ff3739fe849030178346bef28a4556c3&chksm=cea249ebf9d5c0fdbde7c86155d0d7ac8925153742aff472bcb79e5e9d400534a855bad38375&token=1082669959&lang=zh_CN#rd)
-
-1. 介绍下Java内存区域(运行时数据区)。
-
-2. 对象的访问定位的两种方式。
-
-
-[深入理解虚拟机之垃圾回收](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484959&idx=1&sn=9ac740edba59981b7c89482043776280&chksm=cea249d4f9d5c0c21703382510a47d4bb387932bd814ac891fd214b92cead5d2cf0ee2dff797&token=1082669959&lang=zh_CN#rd)
-
-1. 如何判断对象是否死亡(两种方法)。
-
-2. 简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
-
-3. 垃圾收集有哪些算法,各自的特点?
-
-4. HotSpot为什么要分为新生代和老年代?
-
-5. 常见的垃圾回收器有那些?
-
-6. 介绍一下CMS,G1收集器。
-
-7. Minor Gc和Full GC 有什么不同呢?
-
-
-
- [虚拟机性能监控和故障处理工具](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484957&idx=1&sn=713ed6003d23ef883ded14cb43e9ebb7&chksm=cea249d6f9d5c0c0ce0854a03f0d02fcacc8a46e29c2fd4f085a375b00e1cd1b632937a9895e&token=1082669959&lang=zh_CN#rd)
-
-1. JVM调优的常见命令行工具有哪些?
-
- [深入理解虚拟机之类文件结构](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484956&idx=1&sn=05f46ccacacdbce7c43de594d3fe93db&chksm=cea249d7f9d5c0c1ef6d29b0fbbf0701acd28490deb0974ae71b4d23ae793bec0b0993a4c829&token=1082669959&lang=zh_CN#rd)
-
-1. 简单介绍一下Class类文件结构(常量池主要存放的是那两大常量?Class文件的继承关系是如何确定的?字段表、方法表、属性表主要包含那些信息?)
-
-[深入理解虚拟机之虚拟机字节码执行引擎](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484952&idx=1&sn=d0ec9443600dc5b2a81782b7ae0691d5&chksm=cea249d3f9d5c0c50642f1829fd6fe9e35d155bbbb6718611330c7c46c7158279275b533181e&token=1082669959&lang=zh_CN#rd)
-
-1. 简单说说类加载过程,里面执行了哪些操作?
-
-2. 对类加载器有了解吗?
-
-3. 什么是双亲委派模型?
-
-4. 双亲委派模型的工作过程以及使用它的好处。
-
-
-
-
-
-> ### 推荐阅读
-
- [《深入理解 Java 内存模型》读书笔记](http://www.54tianzhisheng.cn/2018/02/28/Java-Memory-Model/) (非常不错的文章)
- [全面理解Java内存模型(JMM)及volatile关键字 ](https://blog.csdn.net/javazejian/article/details/72772461)
-
-
From 1db5d974a7cb50b6eb902952d5dc221b2438099d Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:10:45 +0800
Subject: [PATCH 071/102] =?UTF-8?q?Create=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E8=BF=87=E7=A8=8B.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...40\350\275\275\350\277\207\347\250\213.md" | 70 +++++++++++++++++++
1 file changed, 70 insertions(+)
create mode 100644 "docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
new file mode 100644
index 00000000000..bf415396c63
--- /dev/null
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
@@ -0,0 +1,70 @@
+# 类加载过程
+
+Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+
+系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+
+
+
+
+
+
+## 加载
+
+类加载过程的第一步,主要完成下面3件事情:
+
+1. 通过全类名获取定义此类的二进制字节流
+2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
+3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
+
+虚拟机规范多上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
+
+**一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。**
+
+类加载器、双亲委派模型也是非常重要的知识点,这部分内容会在后面的文章中单独介绍到。
+
+加载阶段和连接阶段的部分内容是交叉进行的,加载阶段尚未结束,连接阶段可能就已经开始了。
+
+## 验证
+
+
+
+## 准备
+
+**准备阶段是正式为类变量分配内存并设置类变量初始值的阶段**,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
+
+1. 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
+2. 这里所设置的初始值"通常情况"下是数据类型默认的零值(如0、0L、null、false等),比如我们定义了`public static int value=111` ,那么 value 变量在准备阶段的初始值就是 0 而不是111(初始化阶段才会复制)。特殊情况:比如给 value 变量加上了 fianl 关键字`public static final int value=111` ,那么准备阶段 value 的值就被复制为 111。
+
+**基本数据类型的零值:**
+
+
+
+## 解析
+
+解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
+
+符号引用就是一组符号来描述目标,可以是任何字面量。**直接引用**就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方发表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
+
+综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
+
+## 初始化
+
+初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 ` ()`方法的过程。
+
+对于`()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
+
+对于初始化阶段,虚拟机严格规范了有且只有5中情况下,必须对类进行初始化:
+
+1. 当遇到 new 、 getstatic、putstatic或invokestatic 这4条直接码指令时,比如 new 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
+2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时 ,如果类没初始化,需要触发其初始化。
+3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
+4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
+5. 当使用 JDK1.7 的动态动态语言时,如果一个 MethodHandle 实例的最后解析结构为 REF_getStatic、REF_putStatic、REF_invokeStatic、的方法句柄,并且这个句柄没有初始化,则需要先触发器初始化。
+
+**参考**
+
+- 《深入理解Java虚拟机》
+- 《实战Java虚拟机》
+-
\ No newline at end of file
From a09c7e967e4eba6bb537128aa96df8159d361532 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:10:49 +0800
Subject: [PATCH 072/102] =?UTF-8?q?Create=20=E7=B1=BB=E6=96=87=E4=BB=B6?=
=?UTF-8?q?=E7=BB=93=E6=9E=84.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...07\344\273\266\347\273\223\346\236\204.md" | 195 ++++++++++++++++++
1 file changed, 195 insertions(+)
create mode 100644 "docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
new file mode 100644
index 00000000000..728576c172c
--- /dev/null
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -0,0 +1,195 @@
+# 类文件结构
+
+## 一 概述
+
+在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
+
+Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行在 Java 虚拟机之上。下图展示了不同的语言被不同的编译器编异常`.class`文件最终运行在 Java 虚拟机之上。`.class`文件的二进制格式可以使用 [WinHex](https://www.x-ways.net/winhex/) 查看。
+
+
+
+**可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。**
+
+## 二 Class 文件结构总结
+
+根据 Java 虚拟机规范,类文件由单个 ClassFile 结构组成:
+
+```java
+ClassFile {
+ u4 magic; //Class 文件的标志
+ u2 minor_version;//Class 的小版本号
+ u2 major_version;//Class 的大版本号
+ u2 constant_pool_count;//常量池的数量
+ cp_info constant_pool[constant_pool_count-1];//常量池
+ u2 access_flags;//Class 的访问标记
+ u2 this_class;//当前类
+ u2 super_class;//父类
+ u2 interfaces_count;//接口
+ u2 interfaces[interfaces_count];//一个类可以实现多个接口
+ u2 fields_count;//Class 文件的字段属性
+ field_info fields[fields_count];//一个类会可以有个字段
+ u2 methods_count;//Class 文件的方法数量
+ method_info methods[methods_count];//一个类可以有个多个方法
+ u2 attributes_count;//此类的属性表中的属性数
+ attribute_info attributes[attributes_count];//属性表集合
+}
+```
+
+下面详细介绍一下 Class 文件结构涉及到的一些组件。
+
+**Class文件字节码结构组织示意图** (之前在网上保存的,非常不错,原出处不明):
+
+
+
+### 2.1 魔数
+
+```java
+ u4 magic; //Class 文件的标志
+```
+
+每个 Class 文件的头四个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。
+
+程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
+
+### 2.2 Class 文件版本
+
+```java
+ u2 minor_version;//Class 的小版本号
+ u2 major_version;//Class 的大版本号
+```
+
+紧接着魔数的四个字节存储的是 Class 文件的版本号:第五和第六是**次版本号**,第七和第八是**主版本号**。
+
+高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
+
+### 2.3 常量池
+
+```java
+ u2 constant_pool_count;//常量池的数量
+ cp_info constant_pool[constant_pool_count-1];//常量池
+```
+
+紧接着主次版本号之后的是常量池,常量池的数量是 constant_pool_count-1(**常量池计数器是从1开始计数的,将第0项常量空出来是有特殊考虑的,索引值为0代表“不引用任何一个常量池项”**)。
+
+常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念。包括下面三类常量:
+
+- 类和接口的全限定名
+- 字段的名称和描述符
+- 方法的名称和描述符
+
+常量池中每一项常量都是一个表,这14种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
+
+| 类型 | 标志(tag) | 描述 |
+| :------------------------------: | :---------: | :--------------------: |
+| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
+| CONSTANT_Integer_info | 3 | 整形字面量 |
+| CONSTANT_Float_info | 4 | 浮点型字面量 |
+| CONSTANT_Long_info | 5 | 长整型字面量 |
+| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
+| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
+| CONSTANT_String_info | 8 | 字符串类型字面量 |
+| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
+| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
+| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
+| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
+| CONSTANT_MothodType_info | 16 | 标志方法类型 |
+| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
+| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
+
+`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
+
+### 2.4 访问标志
+
+在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 public 或者 abstract 类型,如果是类的话是否声明为 final 等等。
+
+类访问和属性修饰符:
+
+
+
+我们定义了一个 Employee 类
+
+```java
+package top.snailclimb.bean;
+public class Employee {
+ ...
+}
+```
+
+通过`javap -v class类名` 指令来看一下类的访问标志。
+
+
+
+### 2.5 当前类索引,父类索引与接口索引集合
+
+```java
+ u2 this_class;//当前类
+ u2 super_class;//父类
+ u2 interfaces_count;//接口
+ u2 interfaces[interfaces_count];//一个雷可以实现多个接口
+```
+
+**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
+
+**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按`implents`(如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
+
+### 2.6 字段表集合
+
+```java
+ u2 fields_count;//Class 文件的字段的个数
+ field_info fields[fields_count];//一个类会可以有个字段
+```
+
+字段表(field info)用于描述接口或类中声明的变量。字段包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。
+
+**field info(字段表) 的结构:**
+
+
+
+- **access_flags:** 字段的作用域(`public` ,`private`,`protected`修饰符),是实例变量还是类变量(`static`修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。
+- **name_index:** 对常量池的引用,表示的字段的名称;
+- **descriptor_index:** 对常量池的引用,表示字段和方法的描述符;
+- **attributes_count:** 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数;
+- **attributes[attributes_count]:** 存放具体属性具体内容。
+
+上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型这些都是无法固定的,只能引用常量池中常量来描述。
+
+**字段的 access_flags 的取值:**
+
+
+
+### 方法表集合
+
+```java
+ u2 methods_count;//Class 文件的方法的数量
+ method_info methods[methods_count];//一个类可以有个多个方法
+```
+
+methods_count 表示方法的数量,而 method_info 表示的方法表。
+
+Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。
+
+**method_info(方法表的) 结构:**
+
+
+
+**方法表的 access_flag 取值:**
+
+
+
+注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
+
+### 属性表集合
+
+```java
+ u2 attributes_count;//此类的属性表中的属性数
+ attribute_info attributes[attributes_count];//属性表集合
+```
+
+在 Class 文件,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息。与 Class 文件中其它的数据项目要求的顺序、长度和内容不同,属性表集合的限制稍微宽松一些,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写 入自己定义的属性信息,Java 虚拟机运行时会忽略掉它不认识的属性。
+
+## 参考
+
+-
+-
+-
+- 《实战 Java 虚拟机》
\ No newline at end of file
From e134b9582854c14a05a5e9e0b3d3132e2b1e07ff Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:12:23 +0800
Subject: [PATCH 073/102] Update README.md
---
README.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/README.md b/README.md
index fe995647566..b1ca7731d15 100644
--- a/README.md
+++ b/README.md
@@ -94,6 +94,9 @@
* [Java内存区域](docs/java/jvm/Java内存区域.md)
* [JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
* [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
+* [类文件结构](docs/java/jvm/类文件结构.md)
+* [类加载过程](docs/java/jvm/类加载过程.md)
+
### I/O
From 53eb931e973112b0979f36221d3e39c62ec412d4 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 21:06:17 +0800
Subject: [PATCH 074/102] =?UTF-8?q?Create=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E5=99=A8.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...73\345\212\240\350\275\275\345\231\250.md" | 112 ++++++++++++++++++
1 file changed, 112 insertions(+)
create mode 100644 "docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
new file mode 100644
index 00000000000..a2828e1a053
--- /dev/null
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -0,0 +1,112 @@
+## 回顾一下类加载过程
+
+类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
+
+所有的类都由类加载器加载,加载的作用就是将 .class文件加载到内存。
+
+## 类加载器总结
+
+JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`:
+
+1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/li`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
+2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
+3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
+
+## 双亲委派模型
+
+### 双亲委派模型介绍
+
+每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 **双亲委派模型** 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。**加载的时候,首先会把该请求委派该父类加载器的 `loadClass()` 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 `BootstrapClassLoader` 中。当父类加载器无法处理时,才由自己来处理。**当父类加载器为null时,会使用启动类加载器 `BootstrapClassLoader` 作为父类加载器。
+
+
+
+每个类加载都有一个父类加载器,我们通过下面的程序来验证。
+
+```java
+public class ClassLoaderDemo {
+ public static void main(String[] args) {
+ System.out.println("ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader());
+ System.out.println("The Parent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent());
+ System.out.println("The GrandParent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent().getParent());
+ }
+}
+```
+
+Output
+
+```
+ClassLodarDemo's ClassLoader is sun.misc.Launcher$AppClassLoader@18b4aac2
+The Parent of ClassLodarDemo's ClassLoader is sun.misc.Launcher$ExtClassLoader@1b6d3586
+The GrandParent of ClassLodarDemo's ClassLoader is null
+```
+
+`AppClassLoader`的父类加载器为`ExtClassLoader`
+`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `Bootstrap ClassLoader`** 。
+
+其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mather ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
+
+>The Java platform uses a delegation model for loading classes. **The basic idea is that every class loader has a "parent" class loader.** When loading a class, a class loader first "delegates" the search for the class to its parent class loader before attempting to find the class itself.
+
+### 双亲委派模型实现源码分析
+
+双亲委派模型的实现代码非常简单,逻辑非常清晰,都集中在 `java.lang.ClassLoader` 的 `loadClass()` 中,相关代码如下所示。
+
+```java
+private final ClassLoader parent;
+protected Class loadClass(String name, boolean resolve)
+ throws ClassNotFoundException
+ {
+ synchronized (getClassLoadingLock(name)) {
+ // 首先,检查请求的类是否已经被加载过
+ Class c = findLoadedClass(name);
+ if (c == null) {
+ long t0 = System.nanoTime();
+ try {
+ if (parent != null) {//父加载器不为空,调用父加载器loadClass()方法处理
+ c = parent.loadClass(name, false);
+ } else {//父加载器为空,使用启动类加载器 BootstrapClassLoader 加载
+ c = findBootstrapClassOrNull(name);
+ }
+ } catch (ClassNotFoundException e) {
+ //抛出异常说明父类加载器无法完成加载请求
+ }
+
+ if (c == null) {
+ long t1 = System.nanoTime();
+ //自己尝试加载
+ c = findClass(name);
+
+ // this is the defining class loader; record the stats
+ sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
+ sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
+ sun.misc.PerfCounter.getFindClasses().increment();
+ }
+ }
+ if (resolve) {
+ resolveClass(c);
+ }
+ return c;
+ }
+ }
+```
+
+### 双亲委派模型的好处
+
+双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
+
+### 如果我们不想要双亲委派模型怎么办?
+
+为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重载 `loadClass()` 即可。
+
+## 自定义类加载器
+
+除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
+
+## 推荐
+
+-
+-
+-
+
From 461938d0b362b4ab441071a13f243b921f66dcf0 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 21:08:54 +0800
Subject: [PATCH 075/102] Update README.md
---
README.md | 12 ++++++------
1 file changed, 6 insertions(+), 6 deletions(-)
diff --git a/README.md b/README.md
index b1ca7731d15..62bcd81207c 100644
--- a/README.md
+++ b/README.md
@@ -91,12 +91,12 @@
### JVM
-* [Java内存区域](docs/java/jvm/Java内存区域.md)
-* [JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
-* [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
-* [类文件结构](docs/java/jvm/类文件结构.md)
-* [类加载过程](docs/java/jvm/类加载过程.md)
-
+* [一 Java内存区域](docs/java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](docs/java/jvm/类文件结构.md)
+* [五 类加载过程](docs/java/jvm/类加载过程.md)
+* [六 类加载器](docs/java/jvm/类加载器.md)
### I/O
From 27c375c2018b2b4d5922886246a99d1b9557b59e Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 21:38:26 +0800
Subject: [PATCH 076/102] =?UTF-8?q?Update=20Java=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\237\272\347\241\200\347\237\245\350\257\206.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index ff51fbc1e02..05287387395 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -301,7 +301,7 @@ new运算符,new创建对象实例(对象实例在堆内存中),对象
**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
-- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
+- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
**举个例子:**
From ceff2be43f9447b7adbfd1075d06081bd5643759 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Thu, 16 May 2019 15:08:25 +0800
Subject: [PATCH 077/102] =?UTF-8?q?Update=20Spring=E5=AD=A6=E4=B9=A0?=
=?UTF-8?q?=E4=B8=8E=E9=9D=A2=E8=AF=95.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md" "b/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
index 78ff084cf59..7f4db10c16e 100644
--- "a/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
+++ "b/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
@@ -21,7 +21,7 @@
- [网易云课堂——58集精通java教程Spring框架开发](http://study.163.com/course/courseMain.htm?courseId=1004475015#/courseDetail?tab=1&35)
- [慕课网相关视频](https://www.imooc.com/)
-- **黑马视频和尚硅谷视频(非常推荐):** 微信公众号:“**JavaGui**”后台回复关键字 “**1**” 免费领取。
+- **黑马视频和尚硅谷视频(非常推荐):** 微信公众号:“**JavaGuide**”后台回复关键字 “**1**” 免费领取。
## 面试必备知识点
From c47196fb8f59c1c5ca6da1b85245432aa9f675bd Mon Sep 17 00:00:00 2001
From: WangKai
Date: Fri, 17 May 2019 11:35:00 +0800
Subject: [PATCH 078/102] =?UTF-8?q?=E4=BF=AE=E6=94=B9=E7=AC=94=E8=AF=AF?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
原文的 %JAVA_HOME%/li 应为 %JAVA_HOME%/lib
---
.../jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index a2828e1a053..f293d574c4b 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -10,7 +10,7 @@
JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`:
-1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/li`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
+1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/lib`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
From 2c4725d1f92642e341ecac8fa12db87a62166dd3 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 09:17:48 +0800
Subject: [PATCH 079/102] Add directory
---
...07\344\273\266\347\273\223\346\236\204.md" | 35 +++++++++++++++++--
1 file changed, 32 insertions(+), 3 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index 728576c172c..f8dda3a21db 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -1,3 +1,22 @@
+
+
+- [类文件结构](#类文件结构)
+ - [一 概述](#一-概述)
+ - [二 Class 文件结构总结](#二-class-文件结构总结)
+ - [2.1 魔数](#21-魔数)
+ - [2.2 Class 文件版本](#22-class-文件版本)
+ - [2.3 常量池](#23-常量池)
+ - [2.4 访问标志](#24-访问标志)
+ - [2.5 当前类索引,父类索引与接口索引集合](#25-当前类索引父类索引与接口索引集合)
+ - [2.6 字段表集合](#26-字段表集合)
+ - [2.7 方法表集合](#27-方法表集合)
+ - [2.8 属性表集合](#28-属性表集合)
+ - [参考](#参考)
+
+
+
+> 公众号JavaGuide 后台回复关键字“1”,免费获取Java工程师必备学习资源。
+
# 类文件结构
## 一 概述
@@ -157,7 +176,7 @@ public class Employee {

-### 方法表集合
+### 2.7 方法表集合
```java
u2 methods_count;//Class 文件的方法的数量
@@ -178,7 +197,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
-### 属性表集合
+### 2.8 属性表集合
```java
u2 attributes_count;//此类的属性表中的属性数
@@ -192,4 +211,14 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
-
-
-
-- 《实战 Java 虚拟机》
\ No newline at end of file
+- 《实战 Java 虚拟机》
+
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
From e32ab4783a7e72a83de50cfe4994dc6f38f68487 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 21:28:00 +0800
Subject: [PATCH 080/102] Add directory
---
...40\350\275\275\350\277\207\347\250\213.md" | 29 +++++++++++++++----
1 file changed, 24 insertions(+), 5 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
index bf415396c63..bbe86e7d37f 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
@@ -1,14 +1,23 @@
-# 类加载过程
+
-Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+- [类加载过程](#类加载过程)
+ - [加载](#加载)
+ - [验证](#验证)
+ - [准备](#准备)
+ - [解析](#解析)
+ - [初始化](#初始化)
-系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
+# 类加载过程
-
+Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
## 加载
@@ -67,4 +76,14 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
- 《深入理解Java虚拟机》
- 《实战Java虚拟机》
--
\ No newline at end of file
+-
+
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
From 32d7809f187433974445381f324667149511c4db Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 21:30:28 +0800
Subject: [PATCH 081/102] Add directory
---
...73\345\212\240\350\275\275\345\231\250.md" | 26 +++++++++++++++++++
1 file changed, 26 insertions(+)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index f293d574c4b..7dbaa108a21 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -1,3 +1,19 @@
+
+
+- [回顾一下类加载过程](#回顾一下类加载过程)
+- [类加载器总结](#类加载器总结)
+- [双亲委派模型](#双亲委派模型)
+ - [双亲委派模型介绍](#双亲委派模型介绍)
+ - [双亲委派模型实现源码分析](#双亲委派模型实现源码分析)
+ - [双亲委派模型的好处](#双亲委派模型的好处)
+ - [如果我们不想要双亲委派模型怎么办?](#如果我们不想要双亲委派模型怎么办)
+- [自定义类加载器](#自定义类加载器)
+- [推荐](#推荐)
+
+
+
+> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
+
## 回顾一下类加载过程
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
@@ -110,3 +126,13 @@ protected Class loadClass(String name, boolean resolve)
-
-
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
+
From 4fcb2988bbcce530fba669e11c151f773593a606 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 21:30:36 +0800
Subject: [PATCH 082/102] =?UTF-8?q?Update=20=E7=B1=BB=E6=96=87=E4=BB=B6?=
=?UTF-8?q?=E7=BB=93=E6=9E=84.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index f8dda3a21db..ecd322e4554 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -15,7 +15,7 @@
-> 公众号JavaGuide 后台回复关键字“1”,免费获取Java工程师必备学习资源。
+> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
# 类文件结构
From 72996ae5f1bd5399705f259b64eaaa6b7c185518 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:03:46 +0800
Subject: [PATCH 083/102] =?UTF-8?q?Update=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E5=99=A8.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index 7dbaa108a21..06273f1183c 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -112,7 +112,7 @@ protected Class loadClass(String name, boolean resolve)
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
-### 如果我们不想要双亲委派模型怎么办?
+### 如果我们不想用双亲委派模型怎么办?
为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重载 `loadClass()` 即可。
@@ -120,7 +120,7 @@ protected Class loadClass(String name, boolean resolve)
除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
-## 推荐
+## 推荐阅读
-
-
From 55c7661b0301e12596a36f14d54b674007dafa2f Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:04:24 +0800
Subject: [PATCH 084/102] =?UTF-8?q?Update=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E5=99=A8.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../\347\261\273\345\212\240\350\275\275\345\231\250.md" | 6 ++++--
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index a2828e1a053..b64488a3fce 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -2,6 +2,8 @@
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+
一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
所有的类都由类加载器加载,加载的作用就是将 .class文件加载到内存。
@@ -96,7 +98,7 @@ protected Class loadClass(String name, boolean resolve)
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
-### 如果我们不想要双亲委派模型怎么办?
+### 如果我们不想用双亲委派模型怎么办?
为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重载 `loadClass()` 即可。
@@ -104,7 +106,7 @@ protected Class loadClass(String name, boolean resolve)
除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
-## 推荐
+## 推荐阅读
-
-
From d8689a3f1019ee33724689c34fdffc494d43441a Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:04:32 +0800
Subject: [PATCH 085/102] =?UTF-8?q?Update=20=E7=B1=BB=E6=96=87=E4=BB=B6?=
=?UTF-8?q?=E7=BB=93=E6=9E=84.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index 728576c172c..c3063dee1a1 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -155,7 +155,7 @@ public class Employee {
**字段的 access_flags 的取值:**
-
+
### 方法表集合
From 2b2187891c0a9fb01f391b441f2866acd00ab349 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:07:09 +0800
Subject: [PATCH 086/102] =?UTF-8?q?Update=20=E8=AE=A1=E7=AE=97=E6=9C=BA?=
=?UTF-8?q?=E7=BD=91=E7=BB=9C.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...27\346\234\272\347\275\221\347\273\234.md" | 180 +++++++-----------
1 file changed, 69 insertions(+), 111 deletions(-)
diff --git "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index 1c694a5abb3..3db1787dff1 100644
--- "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -1,50 +1,5 @@
-
-
-- [一 OSI与TCP/IP各层的结构与功能,都有哪些协议](#一-osi与tcpip各层的结构与功能都有哪些协议)
- - [五层协议的体系结构](#五层协议的体系结构)
- - [1 应用层](#1-应用层)
- - [域名系统](#域名系统)
- - [HTTP协议](#http协议)
- - [2 运输层](#2-运输层)
- - [运输层主要使用以下两种协议](#运输层主要使用以下两种协议)
- - [UDP 的主要特点](#udp-的主要特点)
- - [TCP 的主要特点](#tcp-的主要特点)
- - [3 网络层](#3-网络层)
- - [4 数据链路层](#4-数据链路层)
- - [5 物理层](#5-物理层)
- - [总结一下](#总结一下)
-- [二 TCP 三次握手和四次挥手\(面试常客\)](#二-tcp-三次握手和四次挥手面试常客)
- - [为什么要三次握手](#为什么要三次握手)
- - [为什么要传回 SYN](#为什么要传回-syn)
- - [传了 SYN,为啥还要传 ACK](#传了-syn为啥还要传-ack)
- - [为什么要四次挥手](#为什么要四次挥手)
-- [三 TCP、UDP 协议的区别](#三-tcp、udp-协议的区别)
-- [四 TCP 协议如何保证可靠传输](#四-tcp-协议如何保证可靠传输)
- - [停止等待协议](#停止等待协议)
- - [自动重传请求 ARQ 协议](#自动重传请求-arq-协议)
- - [连续ARQ协议](#连续arq协议)
- - [滑动窗口](#滑动窗口)
- - [流量控制](#流量控制)
- - [拥塞控制](#拥塞控制)
-- [五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)](#五-在浏览器中输入url地址---显示主页的过程(面试常客))
-- [六 状态码](#六-状态码)
-- [七 各种协议与HTTP协议之间的关系](#七-各种协议与http协议之间的关系)
-- [八 HTTP长连接、短连接](#八-http长连接、短连接)
-- [写在最后](#写在最后)
- - [计算机网络常见问题回顾](#计算机网络常见问题回顾)
- - [建议](#建议)
-
-
-
-
-相对与上一个版本的计算机网路面试知识总结,这个版本增加了 “TCP协议如何保证可靠传输”包括超时重传、停止等待协议、滑动窗口、流量控制、拥塞控制等内容并且对一些已有内容做了补充。
-
-
-## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议
-
-
-### 五层协议的体系结构
+## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议?
学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
@@ -52,43 +7,31 @@
结合互联网的情况,自上而下地,非常简要的介绍一下各层的作用。
-### 1 应用层
+### 1.1 应用层
**应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。**应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如**域名系统DNS**,支持万维网应用的 **HTTP协议**,支持电子邮件的 **SMTP协议**等等。我们把应用层交互的数据单元称为报文。
-#### 域名系统
+**域名系统**
> 域名系统(Domain Name System缩写 DNS,Domain Name被译为域名)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。(百度百科)例如:一个公司的 Web 网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM 公司的域名是 www.ibm.com、Oracle 公司的域名是 www.oracle.com、Cisco公司的域名是 www.cisco.com 等。
-#### HTTP协议
+**HTTP协议**
+
> 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW(万维网) 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。(百度百科)
-### 2 运输层
+### 1.2 运输层
**运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务**。应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。
-#### 运输层主要使用以下两种协议
+**运输层主要使用以下两种协议:**
1. **传输控制协议 TCP**(Transmission Control Protocol)--提供**面向连接**的,**可靠的**数据传输服务。
2. **用户数据协议 UDP**(User Datagram Protocol)--提供**无连接**的,尽最大努力的数据传输服务(**不保证数据传输的可靠性**)。
-#### UDP 的主要特点
-1. UDP 是无连接的;
-2. UDP 使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态(这里面有许多参数);
-3. UDP 是面向报文的;
-4. UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 直播,实时视频会议等);
-5. UDP 支持一对一、一对多、多对一和多对多的交互通信;
-6. UDP 的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
-
-#### TCP 的主要特点
-1. TCP 是面向连接的。(就好像打电话一样,通话前需要先拨号建立连接,通话结束后要挂机释放连接);
-2. 每一条 TCP 连接只能有两个端点,每一条TCP连接只能是点对点的(一对一);
-3. TCP 提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达;
-4. TCP 提供全双工通信。TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据;
-5. 面向字节流。TCP 中的“流”(Stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
+**TCP 与 UDP 的对比见问题三。**
-### 3 网络层
+### 1.3 网络层
**在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 **IP 协议**,因此分组也叫 **IP 数据报** ,简称 **数据报**。
@@ -99,19 +42,19 @@
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
-### 4 数据链路层
+### 1.4 数据链路层
**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装程帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。
控制信息还使接收端能够检测到所收到的帧中有误差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
-### 5 物理层
+### 1.5 物理层
在物理层上所传送的数据单位是比特。
**物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。** 使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
在互联网使用的各种协中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的TCP/IP并不一定单指TCP和IP这两个具体的协议,而往往表示互联网所使用的整个TCP/IP协议族。
-### 总结一下
+### 1.6 总结一下
上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下。图片来源:https://blog.csdn.net/yaopeng_2005/article/details/7064869

@@ -120,9 +63,9 @@
为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。
-**漫画图解:**
+### 2.1 TCP 三次握手漫画图解
-图片来源:《图解HTTP》
+如下图所示,下面的两个机器人通过3次握手确定了对方能正确接收和发送消息(图片来源:《图解HTTP》)。

**简单示意图:**
@@ -132,7 +75,7 @@
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
-### 为什么要三次握手
+### 2.2 为什么要三次握手
**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
@@ -144,13 +87,13 @@
所以三次握手就能确认双发收发功能都正常,缺一不可。
-### 为什么要传回 SYN
+### 2.3 为什么要传回 SYN
接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
-### 传了 SYN,为啥还要传 ACK
+### 2.4 传了 SYN,为啥还要传 ACK
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
@@ -164,7 +107,7 @@
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-### 为什么要四次挥手
+### 2.5 为什么要四次挥手
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
@@ -172,7 +115,7 @@
上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891)
-## 三 TCP、UDP 协议的区别
+## 三 TCP,UDP 协议的区别

UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
@@ -187,15 +130,21 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
4. TCP 的接收端会丢弃重复的数据。
5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
-7. **停止等待协议** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+7. **ARQ协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
+### 4.1 ARQ协议
+**自动重传请求**(Automatic Repeat-reQuest,ARQ)是OSI模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认帧,它通常会重新发送。ARQ包括停止等待ARQ协议和连续ARQ协议。
-### 停止等待协议
-- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组;
+#### 停止等待ARQ协议
+- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组;
- 在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认;
+**优点:** 简单
+
+**缺点:** 信道利用率低,等待时间长
+
**1) 无差错情况:**
@@ -221,34 +170,19 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
1. A收到重复的确认后,直接丢弃。
2. B收到重复的M1后,也直接丢弃重复的M1。
-### 自动重传请求 ARQ 协议
-停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ。
-
-**优点:** 简单
-
-**缺点:** 信道利用率低
-
-### 连续ARQ协议
+#### 连续ARQ协议
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
-
-**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-### 滑动窗口
-
-- TCP 利用滑动窗口实现流量控制的机制。
-- 滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包,谁也发不了数据,所以就有了滑动窗口机制来解决此问题。
-- TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个 1 字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。
+**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-### 流量控制
+### 4.2 滑动窗口和流量控制
-- TCP 利用滑动窗口实现流量控制。
-- 流量控制是为了控制发送方发送速率,保证接收方来得及接收。
-- 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+**TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。** 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
-### 拥塞控制
+### 4.3 拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
@@ -265,7 +199,7 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
-## 五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)
+## 五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)
百度好像最喜欢问这个问题。
> 打开一个网页,整个过程会使用哪些协议
@@ -301,7 +235,7 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**

-## 八 HTTP长连接、短连接
+## 八 HTTP长连接,短连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
@@ -317,26 +251,50 @@ Connection:keep-alive
—— [《HTTP长连接、短连接究竟是什么?》](https://www.cnblogs.com/gotodsp/p/6366163.html)
+## 九 HTTP是不保存状态的协议,如何保存用户状态?
-## 写在最后
-### 计算机网络常见问题回顾
+HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个Session)。
-- ①TCP三次握手和四次挥手、
-- ②在浏览器中输入url地址->>显示主页的过程
-- ③HTTP和HTTPS的区别
-- ④TCP、UDP协议的区别
-- ⑤常见的状态码。
+在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库redis保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
-### 建议
-非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
+**Cookie 被禁用怎么办?**
+最常用的就是利用 URL 重写把 Session ID 直接附加在URL路径的后面。
+
+
+## 十 Cookie的作用是什么?和Session有什么区别?
+
+Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
+
+ **Cookie 一般用来保存用户信息** 比如①我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;②一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
+
+Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
+
+Cookie 存储在客户端中,而Session存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
+
+## 十一 HTTP 1.0和HTTP 1.1的主要区别是什么?
+
+> 这部分回答引用这篇文章 的一些内容。
+
+HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
+
+1. **长连接** : **在HTTP/1.0中,默认使用的是短连接**,也就是说每次请求都要重新建立一次连接。HTTP 是基于TCP/IP协议的,每一次建立或者断开连接都需要三次握手四次挥手的开销,如果每次请求都要这样的话,开销会比较大。因此最好能维持一个长连接,可以用个长连接来发多个请求。**HTTP 1.1起,默认使用长连接** ,默认开启Connection: keep-alive。 **HTTP/1.1的持续连接有非流水线方式和流水线方式** 。流水线方式是客户在收到HTTP的响应报文之前就能接着发送新的请求报文。与之相对应的非流水线方式是客户在收到前一个响应后才能发送下一个请求。
+1. **错误状态响应码** :在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
+1. **缓存处理** :在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
+1. **带宽优化及网络连接的使用** :HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+
+
+
+## 建议
+非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
-### 参考
+## 参考
- [https://blog.csdn.net/qq_16209077/article/details/52718250](https://blog.csdn.net/qq_16209077/article/details/52718250)
- [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
- [https://blog.csdn.net/turn__back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
+-
From 1c2735839a6c1058e0e3d0908a6deb5e8dc6ed36 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:07:15 +0800
Subject: [PATCH 087/102] =?UTF-8?q?Update=20J2EE=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...345\237\272\347\241\200\347\237\245\350\257\206.md" | 10 ++++------
1 file changed, 4 insertions(+), 6 deletions(-)
diff --git "a/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
index c900eb8ff76..3bb362d36e3 100644
--- "a/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -294,12 +294,10 @@ if(cookies !=null){
在所有会话跟踪技术中,HttpSession对象是最强大也是功能最多的。当一个用户第一次访问某个网站时会自动创建 HttpSession,每个用户可以访问他自己的HttpSession。可以通过HttpServletRequest对象的getSession方 法获得HttpSession,通过HttpSession的setAttribute方法可以将一个值放在HttpSession中,通过调用 HttpSession对象的getAttribute方法,同时传入属性名就可以获取保存在HttpSession中的对象。与上面三种方式不同的 是,HttpSession放在服务器的内存中,因此不要将过大的对象放在里面,即使目前的Servlet容器可以在内存将满时将HttpSession 中的对象移到其他存储设备中,但是这样势必影响性能。添加到HttpSession中的值可以是任意Java对象,这个对象最好实现了 Serializable接口,这样Servlet容器在必要的时候可以将其序列化到文件中,否则在序列化时就会出现异常。
## Cookie和Session的的区别
-1. 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
-2. 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
-3. Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
+Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
-参考:
+ **Cookie 一般用来保存用户信息** 比如①我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;②一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
-https://www.zhihu.com/question/19786827/answer/28752144
+Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
-《javaweb整合开发王者归来》P158 Cookie和Session的比较
+Cookie 存储在客户端中,而Session存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
\ No newline at end of file
From c7a02b3c89e558a60aaaecdae796530c5f731c33 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:11:46 +0800
Subject: [PATCH 088/102] Add directory
---
...27\346\234\272\347\275\221\347\273\234.md" | 46 +++++++++++++------
1 file changed, 33 insertions(+), 13 deletions(-)
diff --git "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index 3db1787dff1..940ac64b951 100644
--- "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -1,3 +1,36 @@
+
+
+- [一 OSI与TCP/IP各层的结构与功能,都有哪些协议?](#一-osi与tcpip各层的结构与功能都有哪些协议)
+ - [1.1 应用层](#11-应用层)
+ - [1.2 运输层](#12-运输层)
+ - [1.3 网络层](#13-网络层)
+ - [1.4 数据链路层](#14-数据链路层)
+ - [1.5 物理层](#15-物理层)
+ - [1.6 总结一下](#16-总结一下)
+- [二 TCP 三次握手和四次挥手(面试常客)](#二-tcp-三次握手和四次挥手面试常客)
+ - [2.1 TCP 三次握手漫画图解](#21-tcp-三次握手漫画图解)
+ - [2.2 为什么要三次握手](#22-为什么要三次握手)
+ - [2.3 为什么要传回 SYN](#23-为什么要传回-syn)
+ - [2.4 传了 SYN,为啥还要传 ACK](#24-传了-syn为啥还要传-ack)
+ - [2.5 为什么要四次挥手](#25-为什么要四次挥手)
+- [三 TCP,UDP 协议的区别](#三-tcpudp-协议的区别)
+- [四 TCP 协议如何保证可靠传输](#四-tcp-协议如何保证可靠传输)
+ - [4.1 ARQ协议](#41-arq协议)
+ - [停止等待ARQ协议](#停止等待arq协议)
+ - [连续ARQ协议](#连续arq协议)
+ - [4.2 滑动窗口和流量控制](#42-滑动窗口和流量控制)
+ - [4.3 拥塞控制](#43-拥塞控制)
+- [五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)](#五--在浏览器中输入url地址---显示主页的过程面试常客)
+- [六 状态码](#六-状态码)
+- [七 各种协议与HTTP协议之间的关系](#七-各种协议与http协议之间的关系)
+- [八 HTTP长连接,短连接](#八--http长连接短连接)
+- [九 HTTP是不保存状态的协议,如何保存用户状态?](#九-http是不保存状态的协议如何保存用户状态)
+- [十 Cookie的作用是什么?和Session有什么区别?](#十-cookie的作用是什么和session有什么区别)
+- [十一 HTTP 1.0和HTTP 1.1的主要区别是什么?](#十一-http-10和http-11的主要区别是什么)
+- [建议](#建议)
+- [参考](#参考)
+
+
## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议?
@@ -37,7 +70,6 @@
这里要注意:**不要把运输层的“用户数据报 UDP ”和网络层的“ IP 数据报”弄混**。另外,无论是哪一层的数据单元,都可笼统地用“分组”来表示。
-
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
@@ -106,7 +138,6 @@
- 服务器-关闭与客户端的连接,发送一个FIN给客户端
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-
### 2.5 为什么要四次挥手
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
@@ -220,9 +251,6 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
- [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700)
-
-
-
## 六 状态码

@@ -284,8 +312,6 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
1. **缓存处理** :在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
1. **带宽优化及网络连接的使用** :HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
-
## 建议
非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
@@ -295,9 +321,3 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
- [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
- [https://blog.csdn.net/turn__back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
-
-
-
-
-
-
-
From 47f51a7dedee100f3905ab7c4954ff8c968ad45c Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:13:29 +0800
Subject: [PATCH 089/102] Update HomePage.md
---
docs/HomePage.md | 18 ++++++------------
1 file changed, 6 insertions(+), 12 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index 820417b66fa..6f87b4408f3 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -5,13 +5,6 @@
From a1c9195295b173518f2795003ce386eff4a17417 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 14 May 2019 23:01:25 +0800
Subject: [PATCH 068/102] Update README.md
---
README.md | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git a/README.md b/README.md
index 7bc5168099e..db3e2fb90d6 100644
--- a/README.md
+++ b/README.md
@@ -20,14 +20,13 @@
-
+
-推荐一下我的另外一个正在维护的项目:[programmer-advancement](https://github.com/Snailclimb/programmer-advancement) (技术人员成长必备!)
-
推荐使用 在线阅读(访问速度慢的话,请使用 ),在线阅读内容本仓库同步一致。这种方式阅读的优势在于:有侧边栏阅读体验更好,Gitee pages 的访问速度相对来说也比较快。
## 目录
From 8c0861076a5fe86b4b19ba8a36ec2b47bb628b24 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:08:09 +0800
Subject: [PATCH 069/102] Update README.md
---
README.md | 1 -
1 file changed, 1 deletion(-)
diff --git a/README.md b/README.md
index db3e2fb90d6..fe995647566 100644
--- a/README.md
+++ b/README.md
@@ -94,7 +94,6 @@
* [Java内存区域](docs/java/jvm/Java内存区域.md)
* [JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
* [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
-* [《深入理解Java虚拟机》第2版学习笔记](docs/java/Java虚拟机(jvm).md)
### I/O
From 7fe9aad6951e46c650a69ebf582dc1dafd49ac0e Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:10:40 +0800
Subject: [PATCH 070/102] =?UTF-8?q?Delete=20Java=E8=99=9A=E6=8B=9F?=
=?UTF-8?q?=E6=9C=BA=EF=BC=88jvm=EF=BC=89.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...346\234\272\357\274\210jvm\357\274\211.md" | 59 -------------------
1 file changed, 59 deletions(-)
delete mode 100644 "docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
diff --git "a/docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md" "b/docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
deleted file mode 100644
index 9be88bc89c3..00000000000
--- "a/docs/java/Java\350\231\232\346\213\237\346\234\272\357\274\210jvm\357\274\211.md"
+++ /dev/null
@@ -1,59 +0,0 @@
-
-下面是按jvm虚拟机知识点分章节总结的一些jvm学习与面试相关的一些东西。一般作为Java程序员在面试的时候一般会问的大多就是**Java内存区域、虚拟机垃圾算法、虚拟垃圾收集器、JVM内存管理**这些问题了。这些内容参考周的《深入理解Java虚拟机》中第二章和第三章就足够了对应下面的[深入理解虚拟机之Java内存区域:](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483910%26idx%3D1%26sn%3D246f39051a85fc312577499691fba89f%26chksm%3Dfd985467caefdd71f9a7c275952be34484b14f9e092723c19bd4ef557c324169ed084f868bdb%23rd)和[深入理解虚拟机之垃圾回收](https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzU4NDQ4MzU5OA%3D%3D%26mid%3D2247483914%26idx%3D1%26sn%3D9aa157d4a1570962c39783cdeec7e539%26chksm%3Dfd98546bcaefdd7d9f61cd356e5584e56b64e234c3a403ed93cb6d4dde07a505e3000fd0c427%23rd)这两篇文章。
-
-
-> ### 常见面试题
-
-[深入理解虚拟机之Java内存区域](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484960&idx=1&sn=ff3739fe849030178346bef28a4556c3&chksm=cea249ebf9d5c0fdbde7c86155d0d7ac8925153742aff472bcb79e5e9d400534a855bad38375&token=1082669959&lang=zh_CN#rd)
-
-1. 介绍下Java内存区域(运行时数据区)。
-
-2. 对象的访问定位的两种方式。
-
-
-[深入理解虚拟机之垃圾回收](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484959&idx=1&sn=9ac740edba59981b7c89482043776280&chksm=cea249d4f9d5c0c21703382510a47d4bb387932bd814ac891fd214b92cead5d2cf0ee2dff797&token=1082669959&lang=zh_CN#rd)
-
-1. 如何判断对象是否死亡(两种方法)。
-
-2. 简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
-
-3. 垃圾收集有哪些算法,各自的特点?
-
-4. HotSpot为什么要分为新生代和老年代?
-
-5. 常见的垃圾回收器有那些?
-
-6. 介绍一下CMS,G1收集器。
-
-7. Minor Gc和Full GC 有什么不同呢?
-
-
-
- [虚拟机性能监控和故障处理工具](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484957&idx=1&sn=713ed6003d23ef883ded14cb43e9ebb7&chksm=cea249d6f9d5c0c0ce0854a03f0d02fcacc8a46e29c2fd4f085a375b00e1cd1b632937a9895e&token=1082669959&lang=zh_CN#rd)
-
-1. JVM调优的常见命令行工具有哪些?
-
- [深入理解虚拟机之类文件结构](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484956&idx=1&sn=05f46ccacacdbce7c43de594d3fe93db&chksm=cea249d7f9d5c0c1ef6d29b0fbbf0701acd28490deb0974ae71b4d23ae793bec0b0993a4c829&token=1082669959&lang=zh_CN#rd)
-
-1. 简单介绍一下Class类文件结构(常量池主要存放的是那两大常量?Class文件的继承关系是如何确定的?字段表、方法表、属性表主要包含那些信息?)
-
-[深入理解虚拟机之虚拟机字节码执行引擎](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484952&idx=1&sn=d0ec9443600dc5b2a81782b7ae0691d5&chksm=cea249d3f9d5c0c50642f1829fd6fe9e35d155bbbb6718611330c7c46c7158279275b533181e&token=1082669959&lang=zh_CN#rd)
-
-1. 简单说说类加载过程,里面执行了哪些操作?
-
-2. 对类加载器有了解吗?
-
-3. 什么是双亲委派模型?
-
-4. 双亲委派模型的工作过程以及使用它的好处。
-
-
-
-
-
-> ### 推荐阅读
-
- [《深入理解 Java 内存模型》读书笔记](http://www.54tianzhisheng.cn/2018/02/28/Java-Memory-Model/) (非常不错的文章)
- [全面理解Java内存模型(JMM)及volatile关键字 ](https://blog.csdn.net/javazejian/article/details/72772461)
-
-
From 1db5d974a7cb50b6eb902952d5dc221b2438099d Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:10:45 +0800
Subject: [PATCH 071/102] =?UTF-8?q?Create=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E8=BF=87=E7=A8=8B.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...40\350\275\275\350\277\207\347\250\213.md" | 70 +++++++++++++++++++
1 file changed, 70 insertions(+)
create mode 100644 "docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
new file mode 100644
index 00000000000..bf415396c63
--- /dev/null
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
@@ -0,0 +1,70 @@
+# 类加载过程
+
+Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+
+系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+
+
+
+
+
+
+## 加载
+
+类加载过程的第一步,主要完成下面3件事情:
+
+1. 通过全类名获取定义此类的二进制字节流
+2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
+3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
+
+虚拟机规范多上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
+
+**一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。**
+
+类加载器、双亲委派模型也是非常重要的知识点,这部分内容会在后面的文章中单独介绍到。
+
+加载阶段和连接阶段的部分内容是交叉进行的,加载阶段尚未结束,连接阶段可能就已经开始了。
+
+## 验证
+
+
+
+## 准备
+
+**准备阶段是正式为类变量分配内存并设置类变量初始值的阶段**,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
+
+1. 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
+2. 这里所设置的初始值"通常情况"下是数据类型默认的零值(如0、0L、null、false等),比如我们定义了`public static int value=111` ,那么 value 变量在准备阶段的初始值就是 0 而不是111(初始化阶段才会复制)。特殊情况:比如给 value 变量加上了 fianl 关键字`public static final int value=111` ,那么准备阶段 value 的值就被复制为 111。
+
+**基本数据类型的零值:**
+
+
+
+## 解析
+
+解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
+
+符号引用就是一组符号来描述目标,可以是任何字面量。**直接引用**就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方发表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
+
+综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
+
+## 初始化
+
+初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 ` ()`方法的过程。
+
+对于`()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
+
+对于初始化阶段,虚拟机严格规范了有且只有5中情况下,必须对类进行初始化:
+
+1. 当遇到 new 、 getstatic、putstatic或invokestatic 这4条直接码指令时,比如 new 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
+2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时 ,如果类没初始化,需要触发其初始化。
+3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
+4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
+5. 当使用 JDK1.7 的动态动态语言时,如果一个 MethodHandle 实例的最后解析结构为 REF_getStatic、REF_putStatic、REF_invokeStatic、的方法句柄,并且这个句柄没有初始化,则需要先触发器初始化。
+
+**参考**
+
+- 《深入理解Java虚拟机》
+- 《实战Java虚拟机》
+-
\ No newline at end of file
From a09c7e967e4eba6bb537128aa96df8159d361532 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:10:49 +0800
Subject: [PATCH 072/102] =?UTF-8?q?Create=20=E7=B1=BB=E6=96=87=E4=BB=B6?=
=?UTF-8?q?=E7=BB=93=E6=9E=84.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...07\344\273\266\347\273\223\346\236\204.md" | 195 ++++++++++++++++++
1 file changed, 195 insertions(+)
create mode 100644 "docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
new file mode 100644
index 00000000000..728576c172c
--- /dev/null
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -0,0 +1,195 @@
+# 类文件结构
+
+## 一 概述
+
+在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
+
+Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行在 Java 虚拟机之上。下图展示了不同的语言被不同的编译器编异常`.class`文件最终运行在 Java 虚拟机之上。`.class`文件的二进制格式可以使用 [WinHex](https://www.x-ways.net/winhex/) 查看。
+
+
+
+**可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。**
+
+## 二 Class 文件结构总结
+
+根据 Java 虚拟机规范,类文件由单个 ClassFile 结构组成:
+
+```java
+ClassFile {
+ u4 magic; //Class 文件的标志
+ u2 minor_version;//Class 的小版本号
+ u2 major_version;//Class 的大版本号
+ u2 constant_pool_count;//常量池的数量
+ cp_info constant_pool[constant_pool_count-1];//常量池
+ u2 access_flags;//Class 的访问标记
+ u2 this_class;//当前类
+ u2 super_class;//父类
+ u2 interfaces_count;//接口
+ u2 interfaces[interfaces_count];//一个类可以实现多个接口
+ u2 fields_count;//Class 文件的字段属性
+ field_info fields[fields_count];//一个类会可以有个字段
+ u2 methods_count;//Class 文件的方法数量
+ method_info methods[methods_count];//一个类可以有个多个方法
+ u2 attributes_count;//此类的属性表中的属性数
+ attribute_info attributes[attributes_count];//属性表集合
+}
+```
+
+下面详细介绍一下 Class 文件结构涉及到的一些组件。
+
+**Class文件字节码结构组织示意图** (之前在网上保存的,非常不错,原出处不明):
+
+
+
+### 2.1 魔数
+
+```java
+ u4 magic; //Class 文件的标志
+```
+
+每个 Class 文件的头四个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。
+
+程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
+
+### 2.2 Class 文件版本
+
+```java
+ u2 minor_version;//Class 的小版本号
+ u2 major_version;//Class 的大版本号
+```
+
+紧接着魔数的四个字节存储的是 Class 文件的版本号:第五和第六是**次版本号**,第七和第八是**主版本号**。
+
+高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
+
+### 2.3 常量池
+
+```java
+ u2 constant_pool_count;//常量池的数量
+ cp_info constant_pool[constant_pool_count-1];//常量池
+```
+
+紧接着主次版本号之后的是常量池,常量池的数量是 constant_pool_count-1(**常量池计数器是从1开始计数的,将第0项常量空出来是有特殊考虑的,索引值为0代表“不引用任何一个常量池项”**)。
+
+常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念。包括下面三类常量:
+
+- 类和接口的全限定名
+- 字段的名称和描述符
+- 方法的名称和描述符
+
+常量池中每一项常量都是一个表,这14种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
+
+| 类型 | 标志(tag) | 描述 |
+| :------------------------------: | :---------: | :--------------------: |
+| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
+| CONSTANT_Integer_info | 3 | 整形字面量 |
+| CONSTANT_Float_info | 4 | 浮点型字面量 |
+| CONSTANT_Long_info | 5 | 长整型字面量 |
+| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
+| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
+| CONSTANT_String_info | 8 | 字符串类型字面量 |
+| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
+| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
+| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
+| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
+| CONSTANT_MothodType_info | 16 | 标志方法类型 |
+| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
+| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
+
+`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
+
+### 2.4 访问标志
+
+在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 public 或者 abstract 类型,如果是类的话是否声明为 final 等等。
+
+类访问和属性修饰符:
+
+
+
+我们定义了一个 Employee 类
+
+```java
+package top.snailclimb.bean;
+public class Employee {
+ ...
+}
+```
+
+通过`javap -v class类名` 指令来看一下类的访问标志。
+
+
+
+### 2.5 当前类索引,父类索引与接口索引集合
+
+```java
+ u2 this_class;//当前类
+ u2 super_class;//父类
+ u2 interfaces_count;//接口
+ u2 interfaces[interfaces_count];//一个雷可以实现多个接口
+```
+
+**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
+
+**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按`implents`(如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
+
+### 2.6 字段表集合
+
+```java
+ u2 fields_count;//Class 文件的字段的个数
+ field_info fields[fields_count];//一个类会可以有个字段
+```
+
+字段表(field info)用于描述接口或类中声明的变量。字段包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。
+
+**field info(字段表) 的结构:**
+
+
+
+- **access_flags:** 字段的作用域(`public` ,`private`,`protected`修饰符),是实例变量还是类变量(`static`修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。
+- **name_index:** 对常量池的引用,表示的字段的名称;
+- **descriptor_index:** 对常量池的引用,表示字段和方法的描述符;
+- **attributes_count:** 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数;
+- **attributes[attributes_count]:** 存放具体属性具体内容。
+
+上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型这些都是无法固定的,只能引用常量池中常量来描述。
+
+**字段的 access_flags 的取值:**
+
+
+
+### 方法表集合
+
+```java
+ u2 methods_count;//Class 文件的方法的数量
+ method_info methods[methods_count];//一个类可以有个多个方法
+```
+
+methods_count 表示方法的数量,而 method_info 表示的方法表。
+
+Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。
+
+**method_info(方法表的) 结构:**
+
+
+
+**方法表的 access_flag 取值:**
+
+
+
+注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
+
+### 属性表集合
+
+```java
+ u2 attributes_count;//此类的属性表中的属性数
+ attribute_info attributes[attributes_count];//属性表集合
+```
+
+在 Class 文件,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息。与 Class 文件中其它的数据项目要求的顺序、长度和内容不同,属性表集合的限制稍微宽松一些,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写 入自己定义的属性信息,Java 虚拟机运行时会忽略掉它不认识的属性。
+
+## 参考
+
+-
+-
+-
+- 《实战 Java 虚拟机》
\ No newline at end of file
From e134b9582854c14a05a5e9e0b3d3132e2b1e07ff Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 20:12:23 +0800
Subject: [PATCH 073/102] Update README.md
---
README.md | 3 +++
1 file changed, 3 insertions(+)
diff --git a/README.md b/README.md
index fe995647566..b1ca7731d15 100644
--- a/README.md
+++ b/README.md
@@ -94,6 +94,9 @@
* [Java内存区域](docs/java/jvm/Java内存区域.md)
* [JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
* [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
+* [类文件结构](docs/java/jvm/类文件结构.md)
+* [类加载过程](docs/java/jvm/类加载过程.md)
+
### I/O
From 53eb931e973112b0979f36221d3e39c62ec412d4 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 21:06:17 +0800
Subject: [PATCH 074/102] =?UTF-8?q?Create=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E5=99=A8.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...73\345\212\240\350\275\275\345\231\250.md" | 112 ++++++++++++++++++
1 file changed, 112 insertions(+)
create mode 100644 "docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
new file mode 100644
index 00000000000..a2828e1a053
--- /dev/null
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -0,0 +1,112 @@
+## 回顾一下类加载过程
+
+类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
+
+所有的类都由类加载器加载,加载的作用就是将 .class文件加载到内存。
+
+## 类加载器总结
+
+JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`:
+
+1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/li`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
+2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
+3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
+
+## 双亲委派模型
+
+### 双亲委派模型介绍
+
+每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 **双亲委派模型** 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。**加载的时候,首先会把该请求委派该父类加载器的 `loadClass()` 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 `BootstrapClassLoader` 中。当父类加载器无法处理时,才由自己来处理。**当父类加载器为null时,会使用启动类加载器 `BootstrapClassLoader` 作为父类加载器。
+
+
+
+每个类加载都有一个父类加载器,我们通过下面的程序来验证。
+
+```java
+public class ClassLoaderDemo {
+ public static void main(String[] args) {
+ System.out.println("ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader());
+ System.out.println("The Parent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent());
+ System.out.println("The GrandParent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent().getParent());
+ }
+}
+```
+
+Output
+
+```
+ClassLodarDemo's ClassLoader is sun.misc.Launcher$AppClassLoader@18b4aac2
+The Parent of ClassLodarDemo's ClassLoader is sun.misc.Launcher$ExtClassLoader@1b6d3586
+The GrandParent of ClassLodarDemo's ClassLoader is null
+```
+
+`AppClassLoader`的父类加载器为`ExtClassLoader`
+`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `Bootstrap ClassLoader`** 。
+
+其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mather ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
+
+>The Java platform uses a delegation model for loading classes. **The basic idea is that every class loader has a "parent" class loader.** When loading a class, a class loader first "delegates" the search for the class to its parent class loader before attempting to find the class itself.
+
+### 双亲委派模型实现源码分析
+
+双亲委派模型的实现代码非常简单,逻辑非常清晰,都集中在 `java.lang.ClassLoader` 的 `loadClass()` 中,相关代码如下所示。
+
+```java
+private final ClassLoader parent;
+protected Class loadClass(String name, boolean resolve)
+ throws ClassNotFoundException
+ {
+ synchronized (getClassLoadingLock(name)) {
+ // 首先,检查请求的类是否已经被加载过
+ Class c = findLoadedClass(name);
+ if (c == null) {
+ long t0 = System.nanoTime();
+ try {
+ if (parent != null) {//父加载器不为空,调用父加载器loadClass()方法处理
+ c = parent.loadClass(name, false);
+ } else {//父加载器为空,使用启动类加载器 BootstrapClassLoader 加载
+ c = findBootstrapClassOrNull(name);
+ }
+ } catch (ClassNotFoundException e) {
+ //抛出异常说明父类加载器无法完成加载请求
+ }
+
+ if (c == null) {
+ long t1 = System.nanoTime();
+ //自己尝试加载
+ c = findClass(name);
+
+ // this is the defining class loader; record the stats
+ sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
+ sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
+ sun.misc.PerfCounter.getFindClasses().increment();
+ }
+ }
+ if (resolve) {
+ resolveClass(c);
+ }
+ return c;
+ }
+ }
+```
+
+### 双亲委派模型的好处
+
+双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
+
+### 如果我们不想要双亲委派模型怎么办?
+
+为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重载 `loadClass()` 即可。
+
+## 自定义类加载器
+
+除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
+
+## 推荐
+
+-
+-
+-
+
From 461938d0b362b4ab441071a13f243b921f66dcf0 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 21:08:54 +0800
Subject: [PATCH 075/102] Update README.md
---
README.md | 12 ++++++------
1 file changed, 6 insertions(+), 6 deletions(-)
diff --git a/README.md b/README.md
index b1ca7731d15..62bcd81207c 100644
--- a/README.md
+++ b/README.md
@@ -91,12 +91,12 @@
### JVM
-* [Java内存区域](docs/java/jvm/Java内存区域.md)
-* [JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
-* [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
-* [类文件结构](docs/java/jvm/类文件结构.md)
-* [类加载过程](docs/java/jvm/类加载过程.md)
-
+* [一 Java内存区域](docs/java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](docs/java/jvm/类文件结构.md)
+* [五 类加载过程](docs/java/jvm/类加载过程.md)
+* [六 类加载器](docs/java/jvm/类加载器.md)
### I/O
From 27c375c2018b2b4d5922886246a99d1b9557b59e Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Wed, 15 May 2019 21:38:26 +0800
Subject: [PATCH 076/102] =?UTF-8?q?Update=20Java=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../Java\345\237\272\347\241\200\347\237\245\350\257\206.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
index ff51fbc1e02..05287387395 100644
--- "a/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/Java\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -301,7 +301,7 @@ new运算符,new创建对象实例(对象实例在堆内存中),对象
**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
-- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
+- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
**举个例子:**
From ceff2be43f9447b7adbfd1075d06081bd5643759 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Thu, 16 May 2019 15:08:25 +0800
Subject: [PATCH 077/102] =?UTF-8?q?Update=20Spring=E5=AD=A6=E4=B9=A0?=
=?UTF-8?q?=E4=B8=8E=E9=9D=A2=E8=AF=95.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md" "b/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
index 78ff084cf59..7f4db10c16e 100644
--- "a/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
+++ "b/docs/system-design/framework/Spring\345\255\246\344\271\240\344\270\216\351\235\242\350\257\225.md"
@@ -21,7 +21,7 @@
- [网易云课堂——58集精通java教程Spring框架开发](http://study.163.com/course/courseMain.htm?courseId=1004475015#/courseDetail?tab=1&35)
- [慕课网相关视频](https://www.imooc.com/)
-- **黑马视频和尚硅谷视频(非常推荐):** 微信公众号:“**JavaGui**”后台回复关键字 “**1**” 免费领取。
+- **黑马视频和尚硅谷视频(非常推荐):** 微信公众号:“**JavaGuide**”后台回复关键字 “**1**” 免费领取。
## 面试必备知识点
From c47196fb8f59c1c5ca6da1b85245432aa9f675bd Mon Sep 17 00:00:00 2001
From: WangKai
Date: Fri, 17 May 2019 11:35:00 +0800
Subject: [PATCH 078/102] =?UTF-8?q?=E4=BF=AE=E6=94=B9=E7=AC=94=E8=AF=AF?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
原文的 %JAVA_HOME%/li 应为 %JAVA_HOME%/lib
---
.../jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index a2828e1a053..f293d574c4b 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -10,7 +10,7 @@
JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`:
-1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/li`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
+1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/lib`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
From 2c4725d1f92642e341ecac8fa12db87a62166dd3 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 09:17:48 +0800
Subject: [PATCH 079/102] Add directory
---
...07\344\273\266\347\273\223\346\236\204.md" | 35 +++++++++++++++++--
1 file changed, 32 insertions(+), 3 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index 728576c172c..f8dda3a21db 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -1,3 +1,22 @@
+
+
+- [类文件结构](#类文件结构)
+ - [一 概述](#一-概述)
+ - [二 Class 文件结构总结](#二-class-文件结构总结)
+ - [2.1 魔数](#21-魔数)
+ - [2.2 Class 文件版本](#22-class-文件版本)
+ - [2.3 常量池](#23-常量池)
+ - [2.4 访问标志](#24-访问标志)
+ - [2.5 当前类索引,父类索引与接口索引集合](#25-当前类索引父类索引与接口索引集合)
+ - [2.6 字段表集合](#26-字段表集合)
+ - [2.7 方法表集合](#27-方法表集合)
+ - [2.8 属性表集合](#28-属性表集合)
+ - [参考](#参考)
+
+
+
+> 公众号JavaGuide 后台回复关键字“1”,免费获取Java工程师必备学习资源。
+
# 类文件结构
## 一 概述
@@ -157,7 +176,7 @@ public class Employee {

-### 方法表集合
+### 2.7 方法表集合
```java
u2 methods_count;//Class 文件的方法的数量
@@ -178,7 +197,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
-### 属性表集合
+### 2.8 属性表集合
```java
u2 attributes_count;//此类的属性表中的属性数
@@ -192,4 +211,14 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
-
-
-
-- 《实战 Java 虚拟机》
\ No newline at end of file
+- 《实战 Java 虚拟机》
+
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
From e32ab4783a7e72a83de50cfe4994dc6f38f68487 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 21:28:00 +0800
Subject: [PATCH 080/102] Add directory
---
...40\350\275\275\350\277\207\347\250\213.md" | 29 +++++++++++++++----
1 file changed, 24 insertions(+), 5 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
index bf415396c63..bbe86e7d37f 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
@@ -1,14 +1,23 @@
-# 类加载过程
+
-Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+- [类加载过程](#类加载过程)
+ - [加载](#加载)
+ - [验证](#验证)
+ - [准备](#准备)
+ - [解析](#解析)
+ - [初始化](#初始化)
-系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
+# 类加载过程
-
+Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
+系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
## 加载
@@ -67,4 +76,14 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
- 《深入理解Java虚拟机》
- 《实战Java虚拟机》
--
\ No newline at end of file
+-
+
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
From 32d7809f187433974445381f324667149511c4db Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 21:30:28 +0800
Subject: [PATCH 081/102] Add directory
---
...73\345\212\240\350\275\275\345\231\250.md" | 26 +++++++++++++++++++
1 file changed, 26 insertions(+)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index f293d574c4b..7dbaa108a21 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -1,3 +1,19 @@
+
+
+- [回顾一下类加载过程](#回顾一下类加载过程)
+- [类加载器总结](#类加载器总结)
+- [双亲委派模型](#双亲委派模型)
+ - [双亲委派模型介绍](#双亲委派模型介绍)
+ - [双亲委派模型实现源码分析](#双亲委派模型实现源码分析)
+ - [双亲委派模型的好处](#双亲委派模型的好处)
+ - [如果我们不想要双亲委派模型怎么办?](#如果我们不想要双亲委派模型怎么办)
+- [自定义类加载器](#自定义类加载器)
+- [推荐](#推荐)
+
+
+
+> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
+
## 回顾一下类加载过程
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
@@ -110,3 +126,13 @@ protected Class loadClass(String name, boolean resolve)
-
-
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
+
+
+
From 4fcb2988bbcce530fba669e11c151f773593a606 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sat, 18 May 2019 21:30:36 +0800
Subject: [PATCH 082/102] =?UTF-8?q?Update=20=E7=B1=BB=E6=96=87=E4=BB=B6?=
=?UTF-8?q?=E7=BB=93=E6=9E=84.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index f8dda3a21db..ecd322e4554 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -15,7 +15,7 @@
-> 公众号JavaGuide 后台回复关键字“1”,免费获取Java工程师必备学习资源。
+> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
# 类文件结构
From 72996ae5f1bd5399705f259b64eaaa6b7c185518 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:03:46 +0800
Subject: [PATCH 083/102] =?UTF-8?q?Update=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E5=99=A8.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index 7dbaa108a21..06273f1183c 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -112,7 +112,7 @@ protected Class loadClass(String name, boolean resolve)
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
-### 如果我们不想要双亲委派模型怎么办?
+### 如果我们不想用双亲委派模型怎么办?
为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重载 `loadClass()` 即可。
@@ -120,7 +120,7 @@ protected Class loadClass(String name, boolean resolve)
除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
-## 推荐
+## 推荐阅读
-
-
From 55c7661b0301e12596a36f14d54b674007dafa2f Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:04:24 +0800
Subject: [PATCH 084/102] =?UTF-8?q?Update=20=E7=B1=BB=E5=8A=A0=E8=BD=BD?=
=?UTF-8?q?=E5=99=A8.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../\347\261\273\345\212\240\350\275\275\345\231\250.md" | 6 ++++--
1 file changed, 4 insertions(+), 2 deletions(-)
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index a2828e1a053..b64488a3fce 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -2,6 +2,8 @@
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
+
+
一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
所有的类都由类加载器加载,加载的作用就是将 .class文件加载到内存。
@@ -96,7 +98,7 @@ protected Class loadClass(String name, boolean resolve)
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
-### 如果我们不想要双亲委派模型怎么办?
+### 如果我们不想用双亲委派模型怎么办?
为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重载 `loadClass()` 即可。
@@ -104,7 +106,7 @@ protected Class loadClass(String name, boolean resolve)
除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
-## 推荐
+## 推荐阅读
-
-
From d8689a3f1019ee33724689c34fdffc494d43441a Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:04:32 +0800
Subject: [PATCH 085/102] =?UTF-8?q?Update=20=E7=B1=BB=E6=96=87=E4=BB=B6?=
=?UTF-8?q?=E7=BB=93=E6=9E=84.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index 728576c172c..c3063dee1a1 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -155,7 +155,7 @@ public class Employee {
**字段的 access_flags 的取值:**
-
+
### 方法表集合
From 2b2187891c0a9fb01f391b441f2866acd00ab349 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:07:09 +0800
Subject: [PATCH 086/102] =?UTF-8?q?Update=20=E8=AE=A1=E7=AE=97=E6=9C=BA?=
=?UTF-8?q?=E7=BD=91=E7=BB=9C.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...27\346\234\272\347\275\221\347\273\234.md" | 180 +++++++-----------
1 file changed, 69 insertions(+), 111 deletions(-)
diff --git "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index 1c694a5abb3..3db1787dff1 100644
--- "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -1,50 +1,5 @@
-
-
-- [一 OSI与TCP/IP各层的结构与功能,都有哪些协议](#一-osi与tcpip各层的结构与功能都有哪些协议)
- - [五层协议的体系结构](#五层协议的体系结构)
- - [1 应用层](#1-应用层)
- - [域名系统](#域名系统)
- - [HTTP协议](#http协议)
- - [2 运输层](#2-运输层)
- - [运输层主要使用以下两种协议](#运输层主要使用以下两种协议)
- - [UDP 的主要特点](#udp-的主要特点)
- - [TCP 的主要特点](#tcp-的主要特点)
- - [3 网络层](#3-网络层)
- - [4 数据链路层](#4-数据链路层)
- - [5 物理层](#5-物理层)
- - [总结一下](#总结一下)
-- [二 TCP 三次握手和四次挥手\(面试常客\)](#二-tcp-三次握手和四次挥手面试常客)
- - [为什么要三次握手](#为什么要三次握手)
- - [为什么要传回 SYN](#为什么要传回-syn)
- - [传了 SYN,为啥还要传 ACK](#传了-syn为啥还要传-ack)
- - [为什么要四次挥手](#为什么要四次挥手)
-- [三 TCP、UDP 协议的区别](#三-tcp、udp-协议的区别)
-- [四 TCP 协议如何保证可靠传输](#四-tcp-协议如何保证可靠传输)
- - [停止等待协议](#停止等待协议)
- - [自动重传请求 ARQ 协议](#自动重传请求-arq-协议)
- - [连续ARQ协议](#连续arq协议)
- - [滑动窗口](#滑动窗口)
- - [流量控制](#流量控制)
- - [拥塞控制](#拥塞控制)
-- [五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)](#五-在浏览器中输入url地址---显示主页的过程(面试常客))
-- [六 状态码](#六-状态码)
-- [七 各种协议与HTTP协议之间的关系](#七-各种协议与http协议之间的关系)
-- [八 HTTP长连接、短连接](#八-http长连接、短连接)
-- [写在最后](#写在最后)
- - [计算机网络常见问题回顾](#计算机网络常见问题回顾)
- - [建议](#建议)
-
-
-
-
-相对与上一个版本的计算机网路面试知识总结,这个版本增加了 “TCP协议如何保证可靠传输”包括超时重传、停止等待协议、滑动窗口、流量控制、拥塞控制等内容并且对一些已有内容做了补充。
-
-
-## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议
-
-
-### 五层协议的体系结构
+## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议?
学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
@@ -52,43 +7,31 @@
结合互联网的情况,自上而下地,非常简要的介绍一下各层的作用。
-### 1 应用层
+### 1.1 应用层
**应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。**应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如**域名系统DNS**,支持万维网应用的 **HTTP协议**,支持电子邮件的 **SMTP协议**等等。我们把应用层交互的数据单元称为报文。
-#### 域名系统
+**域名系统**
> 域名系统(Domain Name System缩写 DNS,Domain Name被译为域名)是因特网的一项核心服务,它作为可以将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。(百度百科)例如:一个公司的 Web 网站可看作是它在网上的门户,而域名就相当于其门牌地址,通常域名都使用该公司的名称或简称。例如上面提到的微软公司的域名,类似的还有:IBM 公司的域名是 www.ibm.com、Oracle 公司的域名是 www.oracle.com、Cisco公司的域名是 www.cisco.com 等。
-#### HTTP协议
+**HTTP协议**
+
> 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW(万维网) 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。(百度百科)
-### 2 运输层
+### 1.2 运输层
**运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务**。应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。
-#### 运输层主要使用以下两种协议
+**运输层主要使用以下两种协议:**
1. **传输控制协议 TCP**(Transmission Control Protocol)--提供**面向连接**的,**可靠的**数据传输服务。
2. **用户数据协议 UDP**(User Datagram Protocol)--提供**无连接**的,尽最大努力的数据传输服务(**不保证数据传输的可靠性**)。
-#### UDP 的主要特点
-1. UDP 是无连接的;
-2. UDP 使用尽最大努力交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态(这里面有许多参数);
-3. UDP 是面向报文的;
-4. UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 直播,实时视频会议等);
-5. UDP 支持一对一、一对多、多对一和多对多的交互通信;
-6. UDP 的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
-
-#### TCP 的主要特点
-1. TCP 是面向连接的。(就好像打电话一样,通话前需要先拨号建立连接,通话结束后要挂机释放连接);
-2. 每一条 TCP 连接只能有两个端点,每一条TCP连接只能是点对点的(一对一);
-3. TCP 提供可靠交付的服务。通过TCP连接传送的数据,无差错、不丢失、不重复、并且按序到达;
-4. TCP 提供全双工通信。TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接收缓存,用来临时存放双方通信的数据;
-5. 面向字节流。TCP 中的“流”(Stream)指的是流入进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序交下来的数据仅仅看成是一连串的无结构的字节流。
+**TCP 与 UDP 的对比见问题三。**
-### 3 网络层
+### 1.3 网络层
**在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 **IP 协议**,因此分组也叫 **IP 数据报** ,简称 **数据报**。
@@ -99,19 +42,19 @@
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
-### 4 数据链路层
+### 1.4 数据链路层
**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装程帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。
控制信息还使接收端能够检测到所收到的帧中有误差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
-### 5 物理层
+### 1.5 物理层
在物理层上所传送的数据单位是比特。
**物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。** 使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
在互联网使用的各种协中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的TCP/IP并不一定单指TCP和IP这两个具体的协议,而往往表示互联网所使用的整个TCP/IP协议族。
-### 总结一下
+### 1.6 总结一下
上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下。图片来源:https://blog.csdn.net/yaopeng_2005/article/details/7064869

@@ -120,9 +63,9 @@
为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。
-**漫画图解:**
+### 2.1 TCP 三次握手漫画图解
-图片来源:《图解HTTP》
+如下图所示,下面的两个机器人通过3次握手确定了对方能正确接收和发送消息(图片来源:《图解HTTP》)。

**简单示意图:**
@@ -132,7 +75,7 @@
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
-### 为什么要三次握手
+### 2.2 为什么要三次握手
**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
@@ -144,13 +87,13 @@
所以三次握手就能确认双发收发功能都正常,缺一不可。
-### 为什么要传回 SYN
+### 2.3 为什么要传回 SYN
接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
-### 传了 SYN,为啥还要传 ACK
+### 2.4 传了 SYN,为啥还要传 ACK
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
@@ -164,7 +107,7 @@
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-### 为什么要四次挥手
+### 2.5 为什么要四次挥手
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
@@ -172,7 +115,7 @@
上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891)
-## 三 TCP、UDP 协议的区别
+## 三 TCP,UDP 协议的区别

UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
@@ -187,15 +130,21 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
4. TCP 的接收端会丢弃重复的数据。
5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
-7. **停止等待协议** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+7. **ARQ协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
+### 4.1 ARQ协议
+**自动重传请求**(Automatic Repeat-reQuest,ARQ)是OSI模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认帧,它通常会重新发送。ARQ包括停止等待ARQ协议和连续ARQ协议。
-### 停止等待协议
-- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组;
+#### 停止等待ARQ协议
+- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组;
- 在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认;
+**优点:** 简单
+
+**缺点:** 信道利用率低,等待时间长
+
**1) 无差错情况:**
@@ -221,34 +170,19 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
1. A收到重复的确认后,直接丢弃。
2. B收到重复的M1后,也直接丢弃重复的M1。
-### 自动重传请求 ARQ 协议
-停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ。
-
-**优点:** 简单
-
-**缺点:** 信道利用率低
-
-### 连续ARQ协议
+#### 连续ARQ协议
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
-
-**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-### 滑动窗口
-
-- TCP 利用滑动窗口实现流量控制的机制。
-- 滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包,谁也发不了数据,所以就有了滑动窗口机制来解决此问题。
-- TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个 1 字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。
+**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
-### 流量控制
+### 4.2 滑动窗口和流量控制
-- TCP 利用滑动窗口实现流量控制。
-- 流量控制是为了控制发送方发送速率,保证接收方来得及接收。
-- 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+**TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。** 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
-### 拥塞控制
+### 4.3 拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
@@ -265,7 +199,7 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
-## 五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)
+## 五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)
百度好像最喜欢问这个问题。
> 打开一个网页,整个过程会使用哪些协议
@@ -301,7 +235,7 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**

-## 八 HTTP长连接、短连接
+## 八 HTTP长连接,短连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
@@ -317,26 +251,50 @@ Connection:keep-alive
—— [《HTTP长连接、短连接究竟是什么?》](https://www.cnblogs.com/gotodsp/p/6366163.html)
+## 九 HTTP是不保存状态的协议,如何保存用户状态?
-## 写在最后
-### 计算机网络常见问题回顾
+HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个Session)。
-- ①TCP三次握手和四次挥手、
-- ②在浏览器中输入url地址->>显示主页的过程
-- ③HTTP和HTTPS的区别
-- ④TCP、UDP协议的区别
-- ⑤常见的状态码。
+在服务端保存 Session 的方法很多,最常用的就是内存和数据库(比如是使用内存数据库redis保存)。既然 Session 存放在服务器端,那么我们如何实现 Session 跟踪呢?大部分情况下,我们都是通过在 Cookie 中附加一个 Session ID 来方式来跟踪。
-### 建议
-非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
+**Cookie 被禁用怎么办?**
+最常用的就是利用 URL 重写把 Session ID 直接附加在URL路径的后面。
+
+
+## 十 Cookie的作用是什么?和Session有什么区别?
+
+Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
+
+ **Cookie 一般用来保存用户信息** 比如①我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;②一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
+
+Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
+
+Cookie 存储在客户端中,而Session存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
+
+## 十一 HTTP 1.0和HTTP 1.1的主要区别是什么?
+
+> 这部分回答引用这篇文章 的一些内容。
+
+HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
+
+1. **长连接** : **在HTTP/1.0中,默认使用的是短连接**,也就是说每次请求都要重新建立一次连接。HTTP 是基于TCP/IP协议的,每一次建立或者断开连接都需要三次握手四次挥手的开销,如果每次请求都要这样的话,开销会比较大。因此最好能维持一个长连接,可以用个长连接来发多个请求。**HTTP 1.1起,默认使用长连接** ,默认开启Connection: keep-alive。 **HTTP/1.1的持续连接有非流水线方式和流水线方式** 。流水线方式是客户在收到HTTP的响应报文之前就能接着发送新的请求报文。与之相对应的非流水线方式是客户在收到前一个响应后才能发送下一个请求。
+1. **错误状态响应码** :在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
+1. **缓存处理** :在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
+1. **带宽优化及网络连接的使用** :HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+
+
+
+## 建议
+非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
-### 参考
+## 参考
- [https://blog.csdn.net/qq_16209077/article/details/52718250](https://blog.csdn.net/qq_16209077/article/details/52718250)
- [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
- [https://blog.csdn.net/turn__back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
+-
From 1c2735839a6c1058e0e3d0908a6deb5e8dc6ed36 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:07:15 +0800
Subject: [PATCH 087/102] =?UTF-8?q?Update=20J2EE=E5=9F=BA=E7=A1=80?=
=?UTF-8?q?=E7=9F=A5=E8=AF=86.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...345\237\272\347\241\200\347\237\245\350\257\206.md" | 10 ++++------
1 file changed, 4 insertions(+), 6 deletions(-)
diff --git "a/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
index c900eb8ff76..3bb362d36e3 100644
--- "a/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/java/J2EE\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -294,12 +294,10 @@ if(cookies !=null){
在所有会话跟踪技术中,HttpSession对象是最强大也是功能最多的。当一个用户第一次访问某个网站时会自动创建 HttpSession,每个用户可以访问他自己的HttpSession。可以通过HttpServletRequest对象的getSession方 法获得HttpSession,通过HttpSession的setAttribute方法可以将一个值放在HttpSession中,通过调用 HttpSession对象的getAttribute方法,同时传入属性名就可以获取保存在HttpSession中的对象。与上面三种方式不同的 是,HttpSession放在服务器的内存中,因此不要将过大的对象放在里面,即使目前的Servlet容器可以在内存将满时将HttpSession 中的对象移到其他存储设备中,但是这样势必影响性能。添加到HttpSession中的值可以是任意Java对象,这个对象最好实现了 Serializable接口,这样Servlet容器在必要的时候可以将其序列化到文件中,否则在序列化时就会出现异常。
## Cookie和Session的的区别
-1. 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
-2. 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
-3. Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
+Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
-参考:
+ **Cookie 一般用来保存用户信息** 比如①我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了;②一般的网站都会有保持登录也就是说下次你再访问网站的时候就不需要重新登录了,这是因为用户登录的时候我们可以存放了一个 Token 在 Cookie 中,下次登录的时候只需要根据 Token 值来查找用户即可(为了安全考虑,重新登录一般要将 Token 重写);③登录一次网站后访问网站其他页面不需要重新登录。**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
-https://www.zhihu.com/question/19786827/answer/28752144
+Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。
-《javaweb整合开发王者归来》P158 Cookie和Session的比较
+Cookie 存储在客户端中,而Session存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
\ No newline at end of file
From c7a02b3c89e558a60aaaecdae796530c5f731c33 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:11:46 +0800
Subject: [PATCH 088/102] Add directory
---
...27\346\234\272\347\275\221\347\273\234.md" | 46 +++++++++++++------
1 file changed, 33 insertions(+), 13 deletions(-)
diff --git "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index 3db1787dff1..940ac64b951 100644
--- "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -1,3 +1,36 @@
+
+
+- [一 OSI与TCP/IP各层的结构与功能,都有哪些协议?](#一-osi与tcpip各层的结构与功能都有哪些协议)
+ - [1.1 应用层](#11-应用层)
+ - [1.2 运输层](#12-运输层)
+ - [1.3 网络层](#13-网络层)
+ - [1.4 数据链路层](#14-数据链路层)
+ - [1.5 物理层](#15-物理层)
+ - [1.6 总结一下](#16-总结一下)
+- [二 TCP 三次握手和四次挥手(面试常客)](#二-tcp-三次握手和四次挥手面试常客)
+ - [2.1 TCP 三次握手漫画图解](#21-tcp-三次握手漫画图解)
+ - [2.2 为什么要三次握手](#22-为什么要三次握手)
+ - [2.3 为什么要传回 SYN](#23-为什么要传回-syn)
+ - [2.4 传了 SYN,为啥还要传 ACK](#24-传了-syn为啥还要传-ack)
+ - [2.5 为什么要四次挥手](#25-为什么要四次挥手)
+- [三 TCP,UDP 协议的区别](#三-tcpudp-协议的区别)
+- [四 TCP 协议如何保证可靠传输](#四-tcp-协议如何保证可靠传输)
+ - [4.1 ARQ协议](#41-arq协议)
+ - [停止等待ARQ协议](#停止等待arq协议)
+ - [连续ARQ协议](#连续arq协议)
+ - [4.2 滑动窗口和流量控制](#42-滑动窗口和流量控制)
+ - [4.3 拥塞控制](#43-拥塞控制)
+- [五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)](#五--在浏览器中输入url地址---显示主页的过程面试常客)
+- [六 状态码](#六-状态码)
+- [七 各种协议与HTTP协议之间的关系](#七-各种协议与http协议之间的关系)
+- [八 HTTP长连接,短连接](#八--http长连接短连接)
+- [九 HTTP是不保存状态的协议,如何保存用户状态?](#九-http是不保存状态的协议如何保存用户状态)
+- [十 Cookie的作用是什么?和Session有什么区别?](#十-cookie的作用是什么和session有什么区别)
+- [十一 HTTP 1.0和HTTP 1.1的主要区别是什么?](#十一-http-10和http-11的主要区别是什么)
+- [建议](#建议)
+- [参考](#参考)
+
+
## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议?
@@ -37,7 +70,6 @@
这里要注意:**不要把运输层的“用户数据报 UDP ”和网络层的“ IP 数据报”弄混**。另外,无论是哪一层的数据单元,都可笼统地用“分组”来表示。
-
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
@@ -106,7 +138,6 @@
- 服务器-关闭与客户端的连接,发送一个FIN给客户端
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-
### 2.5 为什么要四次挥手
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
@@ -220,9 +251,6 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
- [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700)
-
-
-
## 六 状态码

@@ -284,8 +312,6 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
1. **缓存处理** :在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
1. **带宽优化及网络连接的使用** :HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
-
## 建议
非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
@@ -295,9 +321,3 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
- [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
- [https://blog.csdn.net/turn__back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
-
-
-
-
-
-
-
From 47f51a7dedee100f3905ab7c4954ff8c968ad45c Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 11:13:29 +0800
Subject: [PATCH 089/102] Update HomePage.md
---
docs/HomePage.md | 18 ++++++------------
1 file changed, 6 insertions(+), 12 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index 820417b66fa..6f87b4408f3 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -5,13 +5,6 @@
 -
-
-
-Special Sponsors
-
-
-
-
-
## Java
@@ -38,10 +31,12 @@
### JVM
-* [Java内存区域](./java/jvm/Java内存区域.md)
-* [JVM垃圾回收](./java/jvm/JVM垃圾回收.md)
-* [JDK 监控和故障处理工具](./java/jvm/JDK监控和故障处理工具总结.md)
-* [《深入理解Java虚拟机》第2版学习笔记](./java/Java虚拟机(jvm).md)
+* [一 Java内存区域](./java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](./java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](./java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](./java/jvm/类文件结构.md)
+* [五 类加载过程](./java/jvm/类加载过程.md)
+* [六 类加载器](./java/jvm/类加载器.md)
### I/O
@@ -179,7 +174,6 @@
- [Java 项目月榜单](./github-trending/JavaGithubTrending.md)
-
***
## 待办
From aa8358d4a27d4e7bd93379a065811baa53b0c9e9 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Sun, 19 May 2019 16:00:45 +0800
Subject: [PATCH 090/102] =?UTF-8?q?Update=20=E8=AE=A1=E7=AE=97=E6=9C=BA?=
=?UTF-8?q?=E7=BD=91=E7=BB=9C.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...\227\346\234\272\347\275\221\347\273\234.md" | 17 +++++++++++++++++
1 file changed, 17 insertions(+)
diff --git "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index 940ac64b951..2d076d62b1d 100644
--- "a/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/docs/network/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -27,6 +27,8 @@
- [九 HTTP是不保存状态的协议,如何保存用户状态?](#九-http是不保存状态的协议如何保存用户状态)
- [十 Cookie的作用是什么?和Session有什么区别?](#十-cookie的作用是什么和session有什么区别)
- [十一 HTTP 1.0和HTTP 1.1的主要区别是什么?](#十一-http-10和http-11的主要区别是什么)
+- [十二 URI和URL的区别是什么?](#十二-uri和url的区别是什么)
+- [十三 HTTP 和 HTTPS 的区别?](#十三-http-和-https-的区别)
- [建议](#建议)
- [参考](#参考)
@@ -312,7 +314,22 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
1. **缓存处理** :在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
1. **带宽优化及网络连接的使用** :HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+## 十二 URI和URL的区别是什么?
+
+- URI(Uniform Resource Identifier) 是同一资源标志符,可以唯一标识一个资源。
+- URL(Uniform Resource Location) 是同一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+
+URI的作用像身份证号一样,URL的作用更像家庭住址一样。URL是一种具体的URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
+
+## 十三 HTTP 和 HTTPS 的区别?
+
+1. **端口** :HTTP的URL由“http://”起始且默认使用端口80,而HTTPS的URL由“https://”起始且默认使用端口443。
+2. **安全性和资源消耗:** HTTP协议运行在TCP之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS是运行在SSL/TLS之上的HTTP协议,SSL/TLS 运行在TCP之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS高,但是 HTTPS 比HTTP耗费更多服务器资源。
+ - 对称加密:密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES等;
+ - 非对称加密:密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。
+
## 建议
+
非常推荐大家看一下 《图解HTTP》 这本书,这本书页数不多,但是内容很是充实,不管是用来系统的掌握网络方面的一些知识还是说纯粹为了应付面试都有很大帮助。下面的一些文章只是参考。大二学习这门课程的时候,我们使用的教材是 《计算机网络第七版》(谢希仁编著),不推荐大家看这本教材,书非常厚而且知识偏理论,不确定大家能不能心平气和的读完。
## 参考
From 7b4da80022fe77ee6130b1b5e9d74d3008aebc29 Mon Sep 17 00:00:00 2001
From: Kugin
Date: Sun, 19 May 2019 18:44:40 +0800
Subject: [PATCH 091/102] =?UTF-8?q?fix:=20=E8=A7=A3=E9=87=8A=E5=99=A8?=
=?UTF-8?q?=E6=A8=A1=E5=BC=8F=E4=B8=8E=E4=B8=AD=E4=BB=8B=E8=80=85=E6=A8=A1?=
=?UTF-8?q?=E5=BC=8F=E6=96=87=E7=AB=A0=E9=93=BE=E6=8E=A5=E9=94=99=E4=BD=8D?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../\350\256\276\350\256\241\346\250\241\345\274\217.md" | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git "a/docs/system-design/\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/docs/system-design/\350\256\276\350\256\241\346\250\241\345\274\217.md"
index e3e95860529..01f8b339143 100644
--- "a/docs/system-design/\350\256\276\350\256\241\346\250\241\345\274\217.md"
+++ "b/docs/system-design/\350\256\276\350\256\241\346\250\241\345\274\217.md"
@@ -67,9 +67,9 @@
- [Java设计模式之责任链模式、职责链模式](https://blog.csdn.net/jason0539/article/details/45091639)
- [责任链模式实现的三种方式](https://www.cnblogs.com/lizo/p/7503862.html)
- **命令模式:** 在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,我们只需在程序运行时指定具体的请求接收者即可,此时,可以使用命令模式来进行设计,使得请求发送者与请求接收者消除彼此之间的耦合,让对象之间的调用关系更加灵活。命令模式可以对发送者和接收者完全解耦,发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不必知道如何完成请求。这就是命令模式的模式动机。
-- **解释器模式:**
+- **解释器模式:**
- **迭代器模式:**
-- **中介者模式:**
+- **中介者模式:**
- **备忘录模式:**
- **观察者模式:**
- **状态模式:**
From 867fcd49115b748628fa4da9aa62ca141eff338d Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:00:41 +0800
Subject: [PATCH 092/102] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 62bcd81207c..6de34b75708 100644
--- a/README.md
+++ b/README.md
@@ -51,7 +51,7 @@
- [系统设计](#系统设计)
- [设计模式](#设计模式)
- [常用框架](#常用框架)
- - [数据通信](#数据通信)
+ - [数据通信(消息队列、Dubbo)](#数据通信)
- [网站架构](#网站架构)
- [面试指南](#面试指南)
- [备战面试](#备战面试)
From 95026a926daeeaf1612e90de0318e9ce18462b8e Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:10:15 +0800
Subject: [PATCH 093/102] =?UTF-8?q?Delete=20RocketMQ=E7=9A=84=E5=87=A0?=
=?UTF-8?q?=E4=B8=AA=E7=AE=80=E5=8D=95=E9=97=AE=E9=A2=98=E4=B8=8E=E7=AD=94?=
=?UTF-8?q?=E6=A1=88.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...30\344\270\216\347\255\224\346\241\210.md" | 208 ------------------
1 file changed, 208 deletions(-)
delete mode 100644 "docs/mq/rocketmq/RocketMQ\347\232\204\345\207\240\344\270\252\347\256\200\345\215\225\351\227\256\351\242\230\344\270\216\347\255\224\346\241\210.md"
diff --git "a/docs/mq/rocketmq/RocketMQ\347\232\204\345\207\240\344\270\252\347\256\200\345\215\225\351\227\256\351\242\230\344\270\216\347\255\224\346\241\210.md" "b/docs/mq/rocketmq/RocketMQ\347\232\204\345\207\240\344\270\252\347\256\200\345\215\225\351\227\256\351\242\230\344\270\216\347\255\224\346\241\210.md"
deleted file mode 100644
index c80b144a917..00000000000
--- "a/docs/mq/rocketmq/RocketMQ\347\232\204\345\207\240\344\270\252\347\256\200\345\215\225\351\227\256\351\242\230\344\270\216\347\255\224\346\241\210.md"
+++ /dev/null
@@ -1,208 +0,0 @@
-
-
-- [1 单机版消息中心](#1-%E5%8D%95%E6%9C%BA%E7%89%88%E6%B6%88%E6%81%AF%E4%B8%AD%E5%BF%83)
-- [2 分布式消息中心](#2-%E5%88%86%E5%B8%83%E5%BC%8F%E6%B6%88%E6%81%AF%E4%B8%AD%E5%BF%83)
- - [2.1 问题与解决](#21-%E9%97%AE%E9%A2%98%E4%B8%8E%E8%A7%A3%E5%86%B3)
- - [2.1.1 消息丢失的问题](#211-%E6%B6%88%E6%81%AF%E4%B8%A2%E5%A4%B1%E7%9A%84%E9%97%AE%E9%A2%98)
- - [2.1.2 同步落盘怎么才能快](#212-%E5%90%8C%E6%AD%A5%E8%90%BD%E7%9B%98%E6%80%8E%E4%B9%88%E6%89%8D%E8%83%BD%E5%BF%AB)
- - [2.1.3 消息堆积的问题](#213-%E6%B6%88%E6%81%AF%E5%A0%86%E7%A7%AF%E7%9A%84%E9%97%AE%E9%A2%98)
- - [2.1.4 定时消息的实现](#214-%E5%AE%9A%E6%97%B6%E6%B6%88%E6%81%AF%E7%9A%84%E5%AE%9E%E7%8E%B0)
- - [2.1.5 顺序消息的实现](#215-%E9%A1%BA%E5%BA%8F%E6%B6%88%E6%81%AF%E7%9A%84%E5%AE%9E%E7%8E%B0)
- - [2.1.6 分布式消息的实现](#216-%E5%88%86%E5%B8%83%E5%BC%8F%E6%B6%88%E6%81%AF%E7%9A%84%E5%AE%9E%E7%8E%B0)
- - [2.1.7 消息的 push 实现](#217-%E6%B6%88%E6%81%AF%E7%9A%84-push-%E5%AE%9E%E7%8E%B0)
- - [2.1.8 消息重复发送的避免](#218-%E6%B6%88%E6%81%AF%E9%87%8D%E5%A4%8D%E5%8F%91%E9%80%81%E7%9A%84%E9%81%BF%E5%85%8D)
- - [2.1.9 广播消费与集群消费](#219-%E5%B9%BF%E6%92%AD%E6%B6%88%E8%B4%B9%E4%B8%8E%E9%9B%86%E7%BE%A4%E6%B6%88%E8%B4%B9)
- - [2.1.10 RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?](#2110-rocketmq-%E4%B8%8D%E4%BD%BF%E7%94%A8-zookeeper-%E4%BD%9C%E4%B8%BA%E6%B3%A8%E5%86%8C%E4%B8%AD%E5%BF%83%E7%9A%84%E5%8E%9F%E5%9B%A0%E4%BB%A5%E5%8F%8A%E8%87%AA%E5%88%B6%E7%9A%84-nameserver-%E4%BC%98%E7%BC%BA%E7%82%B9)
- - [2.1.11 其它](#2111-%E5%85%B6%E5%AE%83)
-- [3 参考](#3-%E5%8F%82%E8%80%83)
-
-
-
-# 1 单机版消息中心
-
-一个消息中心,最基本的需要支持多生产者、多消费者,例如下:
-
-```java
-class Scratch {
-
- public static void main(String[] args) {
- // 实际中会有 nameserver 服务来找到 broker 具体位置以及 broker 主从信息
- Broker broker = new Broker();
- Producer producer1 = new Producer();
- producer1.connectBroker(broker);
- Producer producer2 = new Producer();
- producer2.connectBroker(broker);
-
- Consumer consumer1 = new Consumer();
- consumer1.connectBroker(broker);
- Consumer consumer2 = new Consumer();
- consumer2.connectBroker(broker);
-
- for (int i = 0; i < 2; i++) {
- producer1.asyncSendMsg("producer1 send msg" + i);
- producer2.asyncSendMsg("producer2 send msg" + i);
- }
- System.out.println("broker has msg:" + broker.getAllMagByDisk());
-
- for (int i = 0; i < 1; i++) {
- System.out.println("consumer1 consume msg:" + consumer1.syncPullMsg());
- }
- for (int i = 0; i < 3; i++) {
- System.out.println("consumer2 consume msg:" + consumer2.syncPullMsg());
- }
- }
-
-}
-
-class Producer {
-
- private Broker broker;
-
- public void connectBroker(Broker broker) {
- this.broker = broker;
- }
-
- public void asyncSendMsg(String msg) {
- if (broker == null) {
- throw new RuntimeException("please connect broker first");
- }
- new Thread(() -> {
- broker.sendMsg(msg);
- }).start();
- }
-}
-
-class Consumer {
- private Broker broker;
-
- public void connectBroker(Broker broker) {
- this.broker = broker;
- }
-
- public String syncPullMsg() {
- return broker.getMsg();
- }
-
-}
-
-class Broker {
-
- // 对应 RocketMQ 中 MessageQueue,默认情况下 1 个 Topic 包含 4 个 MessageQueue
- private LinkedBlockingQueue messageQueue = new LinkedBlockingQueue(Integer.MAX_VALUE);
-
- // 实际发送消息到 broker 服务器使用 Netty 发送
- public void sendMsg(String msg) {
- try {
- messageQueue.put(msg);
- // 实际会同步或异步落盘,异步落盘使用的定时任务定时扫描落盘
- } catch (InterruptedException e) {
-
- }
- }
-
- public String getMsg() {
- try {
- return messageQueue.take();
- } catch (InterruptedException e) {
-
- }
- return null;
- }
-
- public String getAllMagByDisk() {
- StringBuilder sb = new StringBuilder("\n");
- messageQueue.iterator().forEachRemaining((msg) -> {
- sb.append(msg + "\n");
- });
- return sb.toString();
- }
-}
-```
-
-问题:
-1. 没有实现真正执行消息存储落盘
-2. 没有实现 NameServer 去作为注册中心,定位服务
-3. 使用 LinkedBlockingQueue 作为消息队列,注意,参数是无限大,在真正 RocketMQ 也是如此是无限大,理论上不会出现对进来的数据进行抛弃,但是会有内存泄漏问题(阿里巴巴开发手册也因为这个问题,建议我们使用自制线程池)
-4. 没有使用多个队列(即多个 LinkedBlockingQueue),RocketMQ 的顺序消息是通过生产者和消费者同时使用同一个 MessageQueue 来实现,但是如果我们只有一个 MessageQueue,那我们天然就支持顺序消息
-5. 没有使用 MappedByteBuffer 来实现文件映射从而使消息数据落盘非常的快(实际 RocketMQ 使用的是 FileChannel+DirectBuffer)
-
-# 2 分布式消息中心
-
-## 2.1 问题与解决
-
-### 2.1.1 消息丢失的问题
-
-1. 当你系统需要保证百分百消息不丢失,你可以使用生产者每发送一个消息,Broker 同步返回一个消息发送成功的反馈消息
-2. 即每发送一个消息,同步落盘后才返回生产者消息发送成功,这样只要生产者得到了消息发送生成的返回,事后除了硬盘损坏,都可以保证不会消息丢失
-3. 但是这同时引入了一个问题,同步落盘怎么才能快?
-
-### 2.1.2 同步落盘怎么才能快
-
-1. 使用 FileChannel + DirectBuffer 池,使用堆外内存,加快内存拷贝
-2. 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询index 文件来定位,从而减少文件IO随机读写的性能损耗
-
-### 2.1.3 消息堆积的问题
-
-1. 后台定时任务每隔72小时,删除旧的没有使用过的消息信息
-2. 根据不同的业务实现不同的丢弃任务,具体参考线程池的 AbortPolicy,例如FIFO/LRU等(RocketMQ没有此策略)
-3. 消息定时转移,或者对某些重要的 TAG 型(支付型)消息真正落库
-
-### 2.1.4 定时消息的实现
-
-1. 实际 RocketMQ 没有实现任意精度的定时消息,它只支持某些特定的时间精度的定时消息
-2. 实现定时消息的原理是:创建特定时间精度的 MessageQueue,例如生产者需要定时1s之后被消费者消费,你只需要将此消息发送到特定的 Topic,例如:MessageQueue-1 表示这个 MessageQueue 里面的消息都会延迟一秒被消费,然后 Broker 会在 1s 后发送到消费者消费此消息,使用 newSingleThreadScheduledExecutor 实现
-
-### 2.1.5 顺序消息的实现
-
-与定时消息同原理,生产者生产消息时指定特定的 MessageQueue ,消费者消费消息时,消费特定的 MessageQueue,其实单机版的消息中心在一个 MessageQueue 就天然支持了顺序消息
-
-### 2.1.6 分布式消息的实现
-
-1. 需要前置知识:2PC
-2. RocketMQ4.3 起支持,原理为2PC,即两阶段提交,prepared->commit/rollback
-3. 生产者发送事务消息,假设该事务消息 Topic 为 Topic1-Trans,Broker 得到后首先更改该消息的 Topic 为 Topic1-Prepared,该 Topic1-Prepared 对消费者不可见。然后定时回调生产者的本地事务A执行状态,根据本地事务A执行状态,来是否将该消息修改为 Topic1-Commit 或 Topic1-Rollback,消费者就可以正常找到该事务消息或者不执行等
-
->注意,就算是事务消息最后回滚了也不会物理删除,只会逻辑删除该消息
-
-### 2.1.7 消息的 push 实现
-
-1. 注意,RocketMQ 已经说了自己会有低延迟问题,其中就包括这个消息的 push 延迟问题
-2. 因为这并不是真正的将消息主动的推送到消费者,而是 Broker 定时任务每5s将消息推送到消费者
-
-### 2.1.8 消息重复发送的避免
-
-1. RocketMQ 会出现消息重复发送的问题,因为在网络延迟的情况下,这种问题不可避免的发生,如果非要实现消息不可重复发送,那基本太难,因为网络环境无法预知,还会使程序复杂度加大,因此默认允许消息重复发送
-2. RocketMQ 让使用者在消费者端去解决该问题,即需要消费者端在消费消息时支持幂等性的去消费消息
-3. 最简单的解决方案是每条消费记录有个消费状态字段,根据这个消费状态字段来是否消费或者使用一个集中式的表,来存储所有消息的消费状态,从而避免重复消费
-4. 具体实现可以查询关于消息幂等消费的解决方案
-
-### 2.1.9 广播消费与集群消费
-
-1. 消息消费区别:广播消费,订阅该 Topic 的消息者们都会消费**每个**消息。集群消费,订阅该 Topic 的消息者们只会有一个去消费**某个**消息
-2. 消息落盘区别:具体表现在消息消费进度的保存上。广播消费,由于每个消费者都独立的去消费每个消息,因此每个消费者各自保存自己的消息消费进度。而集群消费下,订阅了某个 Topic,而旗下又有多个 MessageQueue,每个消费者都可能会去消费不同的 MessageQueue,因此总体的消费进度保存在 Broker 上集中的管理
-
-### 2.1.10 RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?
-
-1. ZooKeeper 作为支持顺序一致性的中间件,在某些情况下,它为了满足一致性,会丢失一定时间内的可用性,RocketMQ 需要注册中心只是为了发现组件地址,在某些情况下,RocketMQ 的注册中心可以出现数据不一致性,这同时也是 NameServer 的缺点,因为 NameServer 集群间互不通信,它们之间的注册信息可能会不一致
-2. 另外,当有新的服务器加入时,NameServer 并不会立马通知到 Produer,而是由 Produer 定时去请求 NameServer 获取最新的 Broker/Consumer 信息(这种情况是通过 Producer 发送消息时,负载均衡解决)
-
-### 2.1.11 其它
-
-![][1]
-
-加分项咯
-1. 包括组件通信间使用 Netty 的自定义协议
-2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
-3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时就使用过滤服务器进行过滤)
-4. Broker 同步双写和异步双写中 Master 和 Slave 的交互
-
-# 3 参考
-
-1. 《RocketMQ技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
-2. 关于 RocketMQ 对 MappedByteBuffer 的一点优化:https://lishoubo.github.io/2017/09/27/MappedByteBuffer%E7%9A%84%E4%B8%80%E7%82%B9%E4%BC%98%E5%8C%96/
-3. 阿里中间件团队博客-十分钟入门RocketMQ:http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/
-4. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
-5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
-6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
-
-[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/RocketMQ%E6%B5%81%E7%A8%8B.png
\ No newline at end of file
From 5e06078d4bc762880ebfc0fad079ca1a2bd911b3 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:11:24 +0800
Subject: [PATCH 094/102] Update README.md
---
README.md | 9 +++++----
1 file changed, 5 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index 6de34b75708..5b120d6fb15 100644
--- a/README.md
+++ b/README.md
@@ -51,7 +51,7 @@
- [系统设计](#系统设计)
- [设计模式](#设计模式)
- [常用框架](#常用框架)
- - [数据通信(消息队列、Dubbo)](#数据通信)
+ - [数据通信](#数据通信)
- [网站架构](#网站架构)
- [面试指南](#面试指南)
- [备战面试](#备战面试)
@@ -178,10 +178,11 @@
### 数据通信
-- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/数据通信(RESTful、RPC、消息队列).md)
-- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/Dubbo.md)
- [消息队列总结](docs/system-design/data-communication/message-queue.md)
-- [RabbitMQ 的重要概念以及安装](docs/system-design/data-communication/rabbitmq.md)
+- [RabbitMQ 入门](docs/system-design/data-communication/RabbitMQ.md)
+- [RocketMQ的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
### 网站架构
From e83d2b75a3b12d049a3ef03b22588e8d7ebe7034 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:12:12 +0800
Subject: [PATCH 095/102] Update README.md
---
README.md | 7 ++++---
1 file changed, 4 insertions(+), 3 deletions(-)
diff --git a/README.md b/README.md
index 62bcd81207c..5b120d6fb15 100644
--- a/README.md
+++ b/README.md
@@ -178,10 +178,11 @@
### 数据通信
-- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/数据通信(RESTful、RPC、消息队列).md)
-- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/Dubbo.md)
- [消息队列总结](docs/system-design/data-communication/message-queue.md)
-- [RabbitMQ 的重要概念以及安装](docs/system-design/data-communication/rabbitmq.md)
+- [RabbitMQ 入门](docs/system-design/data-communication/RabbitMQ.md)
+- [RocketMQ的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
### 网站架构
From 4e6177d5f7db60ae4d2eec571ccf7c418408ee23 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:13:47 +0800
Subject: [PATCH 096/102] Update README.md
---
README.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 5b120d6fb15..b1728c91b3f 100644
--- a/README.md
+++ b/README.md
@@ -51,7 +51,7 @@
- [系统设计](#系统设计)
- [设计模式](#设计模式)
- [常用框架](#常用框架)
- - [数据通信](#数据通信)
+ - [数据通信(消息队列、Dubbo)](#数据通信)
- [网站架构](#网站架构)
- [面试指南](#面试指南)
- [备战面试](#备战面试)
From f90fba5684c3caa20ea8f9560feeb47e93466fd8 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:13:52 +0800
Subject: [PATCH 097/102] =?UTF-8?q?Delete=20=E6=95=B0=E6=8D=AE=E9=80=9A?=
=?UTF-8?q?=E4=BF=A1(RESTful=E3=80=81RPC=E3=80=81=E6=B6=88=E6=81=AF?=
=?UTF-8?q?=E9=98=9F=E5=88=97).md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...0\346\201\257\351\230\237\345\210\227).md" | 100 ------------------
1 file changed, 100 deletions(-)
delete mode 100644 "docs/system-design/data-communication/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md"
diff --git "a/docs/system-design/data-communication/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md" "b/docs/system-design/data-communication/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md"
deleted file mode 100644
index 7840d844d73..00000000000
--- "a/docs/system-design/data-communication/\346\225\260\346\215\256\351\200\232\344\277\241(RESTful\343\200\201RPC\343\200\201\346\266\210\346\201\257\351\230\237\345\210\227).md"
+++ /dev/null
@@ -1,100 +0,0 @@
-> ## RPC
-
-**RPC(Remote Procedure Call)—远程过程调用** ,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发分布式程序就像开发本地程序一样简单。
-
-**RPC采用客户端(服务调用方)/服务器端(服务提供方)模式,** 都运行在自己的JVM中。客户端只需要引入要使用的接口,接口的实现和运行都在服务器端。RPC主要依赖的技术包括序列化、反序列化和数据传输协议,这是一种定义与实现相分离的设计。
-
-**目前Java使用比较多的RPC方案主要有RMI(JDK自带)、Hessian、Dubbo以及Thrift等。**
-
-**注意: RPC主要指内部服务之间的调用,RESTful也可以用于内部服务之间的调用,但其主要用途还在于外部系统提供服务,因此没有将其包含在本知识点内。**
-
-### 常见RPC框架:
-
-- **RMI(JDK自带):** JDK自带的RPC
-
- 详细内容可以参考:[从懵逼到恍然大悟之Java中RMI的使用](https://blog.csdn.net/lmy86263/article/details/72594760)
-
-- **Dubbo:** Dubbo是 阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
-
- 详细内容可以参考:
-
- - [ 高性能优秀的服务框架-dubbo介绍](https://blog.csdn.net/qq_34337272/article/details/79862899)
-
- - [Dubbo是什么?能做什么?](https://blog.csdn.net/houshaolin/article/details/76408399)
-
-
-- **Hessian:** Hessian是一个轻量级的remotingonhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
-
- 详细内容可以参考: [Hessian的使用以及理解](https://blog.csdn.net/sunwei_pyw/article/details/74002351)
-
-- **Thrift:** Apache Thrift是Facebook开源的跨语言的RPC通信框架,目前已经捐献给Apache基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于thrift研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
-
-
- 详细内容可以参考: [【Java】分布式RPC通信框架Apache Thrift 使用总结](https://www.cnblogs.com/zeze/p/8628585.html)
-
-### 如何进行选择:
-
-- **是否允许代码侵入:** 即需要依赖相应的代码生成器生成代码,比如Thrift。
-- **是否需要长连接获取高性能:** 如果对于性能需求较高的haul,那么可以果断选择基于TCP的Thrift、Dubbo。
-- **是否需要跨越网段、跨越防火墙:** 这种情况一般选择基于HTTP协议的Hessian和Thrift的HTTP Transport。
-
-此外,Google推出的基于HTTP2.0的gRPC框架也开始得到应用,其序列化协议基于Protobuf,网络框架使用的是Netty4,但是其需要生成代码,可扩展性也比较差。
-
-> ## 消息中间件
-
-**消息中间件,也可以叫做中央消息队列或者是消息队列(区别于本地消息队列,本地消息队列指的是JVM内的队列实现)**,是一种独立的队列系统,消息中间件经常用来解决内部服务之间的 **异步调用问题** 。请求服务方把请求队列放到队列中即可返回,然后等待服务提供方去队列中获取请求进行处理,之后通过回调等机制把结果返回给请求服务方。
-
-异步调用只是消息中间件一个非常常见的应用场景。此外,常用的消息队列应用场景还偷如下几个:
-- **解耦 :** 一个业务的非核心流程需要依赖其他系统,但结果并不重要,有通知即可。
-- **最终一致性 :** 指的是两个系统的状态保持一致,可以有一定的延迟,只要最终达到一致性即可。经常用在解决分布式事务上。
-- **广播 :** 消息队列最基本的功能。生产者只负责生产消息,订阅者接收消息。
-- **错峰和流控**
-
-
-具体可以参考:
-
-[《消息队列深入解析》](https://blog.csdn.net/qq_34337272/article/details/80029918)
-
-当前使用较多的消息队列有ActiveMQ(性能差,不推荐使用)、RabbitMQ、RocketMQ、Kafka等等,我们之前提到的redis数据库也可以实现消息队列,不过不推荐,redis本身设计就不是用来做消息队列的。
-
-- **ActiveMQ:** ActiveMQ是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的JMSProvider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
-
- 具体可以参考:
-
- [《消息队列ActiveMQ的使用详解》](https://blog.csdn.net/qq_34337272/article/details/80031702)
-
-- **RabbitMQ:** RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗
- > AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
-
-
- 具体可以参考:
-
- [《消息队列之 RabbitMQ》](https://www.jianshu.com/p/79ca08116d57)
-
-- **RocketMQ:**
-
- 具体可以参考:
-
- [《RocketMQ 实战之快速入门》](https://www.jianshu.com/p/824066d70da8)
-
- [《十分钟入门RocketMQ》](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/) (阿里中间件团队博客)
-
-
-- **Kafka**:Kafka是一个分布式的、可分区的、可复制的、基于发布/订阅的消息系统(现在官方的描述是“一个分布式流平台”),Kafka主要用于大数据领域,当然在分布式系统中也有应用。目前市面上流行的消息队列RocketMQ就是阿里借鉴Kafka的原理、用Java开发而得。
-
- 具体可以参考:
-
- [《Kafka应用场景》](http://book.51cto.com/art/201801/565244.htm)
-
- [《初谈Kafka》](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484106&idx=1&sn=aa1999895d009d91eb3692a3e6429d18&chksm=fd9854abcaefddbd1101ca5dc2c7c783d7171320d6300d9b2d8e68b7ef8abd2b02ea03e03600#rd)
-
-**推荐阅读:**
-
-[《Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别》](https://mp.weixin.qq.com/s?__biz=MzU5OTMyODAyNg==&mid=2247484721&idx=1&sn=11e4e29886e581dd328311d308ccc068&chksm=feb7d144c9c058529465b02a4e26a25ef76b60be8984ace9e4a0f5d3d98ca52e014ecb73b061&scene=21#wechat_redirect)
-
-
-
-
-
-
-
From 5880c393c1619f09e41ff8e70de4bf9734e4ceef Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:13:57 +0800
Subject: [PATCH 098/102] Create summary.md
---
.../data-communication/summary.md | 100 ++++++++++++++++++
1 file changed, 100 insertions(+)
create mode 100644 docs/system-design/data-communication/summary.md
diff --git a/docs/system-design/data-communication/summary.md b/docs/system-design/data-communication/summary.md
new file mode 100644
index 00000000000..7840d844d73
--- /dev/null
+++ b/docs/system-design/data-communication/summary.md
@@ -0,0 +1,100 @@
+> ## RPC
+
+**RPC(Remote Procedure Call)—远程过程调用** ,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发分布式程序就像开发本地程序一样简单。
+
+**RPC采用客户端(服务调用方)/服务器端(服务提供方)模式,** 都运行在自己的JVM中。客户端只需要引入要使用的接口,接口的实现和运行都在服务器端。RPC主要依赖的技术包括序列化、反序列化和数据传输协议,这是一种定义与实现相分离的设计。
+
+**目前Java使用比较多的RPC方案主要有RMI(JDK自带)、Hessian、Dubbo以及Thrift等。**
+
+**注意: RPC主要指内部服务之间的调用,RESTful也可以用于内部服务之间的调用,但其主要用途还在于外部系统提供服务,因此没有将其包含在本知识点内。**
+
+### 常见RPC框架:
+
+- **RMI(JDK自带):** JDK自带的RPC
+
+ 详细内容可以参考:[从懵逼到恍然大悟之Java中RMI的使用](https://blog.csdn.net/lmy86263/article/details/72594760)
+
+- **Dubbo:** Dubbo是 阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
+
+ 详细内容可以参考:
+
+ - [ 高性能优秀的服务框架-dubbo介绍](https://blog.csdn.net/qq_34337272/article/details/79862899)
+
+ - [Dubbo是什么?能做什么?](https://blog.csdn.net/houshaolin/article/details/76408399)
+
+
+- **Hessian:** Hessian是一个轻量级的remotingonhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
+
+ 详细内容可以参考: [Hessian的使用以及理解](https://blog.csdn.net/sunwei_pyw/article/details/74002351)
+
+- **Thrift:** Apache Thrift是Facebook开源的跨语言的RPC通信框架,目前已经捐献给Apache基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于thrift研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
+
+
+ 详细内容可以参考: [【Java】分布式RPC通信框架Apache Thrift 使用总结](https://www.cnblogs.com/zeze/p/8628585.html)
+
+### 如何进行选择:
+
+- **是否允许代码侵入:** 即需要依赖相应的代码生成器生成代码,比如Thrift。
+- **是否需要长连接获取高性能:** 如果对于性能需求较高的haul,那么可以果断选择基于TCP的Thrift、Dubbo。
+- **是否需要跨越网段、跨越防火墙:** 这种情况一般选择基于HTTP协议的Hessian和Thrift的HTTP Transport。
+
+此外,Google推出的基于HTTP2.0的gRPC框架也开始得到应用,其序列化协议基于Protobuf,网络框架使用的是Netty4,但是其需要生成代码,可扩展性也比较差。
+
+> ## 消息中间件
+
+**消息中间件,也可以叫做中央消息队列或者是消息队列(区别于本地消息队列,本地消息队列指的是JVM内的队列实现)**,是一种独立的队列系统,消息中间件经常用来解决内部服务之间的 **异步调用问题** 。请求服务方把请求队列放到队列中即可返回,然后等待服务提供方去队列中获取请求进行处理,之后通过回调等机制把结果返回给请求服务方。
+
+异步调用只是消息中间件一个非常常见的应用场景。此外,常用的消息队列应用场景还偷如下几个:
+- **解耦 :** 一个业务的非核心流程需要依赖其他系统,但结果并不重要,有通知即可。
+- **最终一致性 :** 指的是两个系统的状态保持一致,可以有一定的延迟,只要最终达到一致性即可。经常用在解决分布式事务上。
+- **广播 :** 消息队列最基本的功能。生产者只负责生产消息,订阅者接收消息。
+- **错峰和流控**
+
+
+具体可以参考:
+
+[《消息队列深入解析》](https://blog.csdn.net/qq_34337272/article/details/80029918)
+
+当前使用较多的消息队列有ActiveMQ(性能差,不推荐使用)、RabbitMQ、RocketMQ、Kafka等等,我们之前提到的redis数据库也可以实现消息队列,不过不推荐,redis本身设计就不是用来做消息队列的。
+
+- **ActiveMQ:** ActiveMQ是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的JMSProvider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
+
+ 具体可以参考:
+
+ [《消息队列ActiveMQ的使用详解》](https://blog.csdn.net/qq_34337272/article/details/80031702)
+
+- **RabbitMQ:** RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗
+ > AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
+
+
+ 具体可以参考:
+
+ [《消息队列之 RabbitMQ》](https://www.jianshu.com/p/79ca08116d57)
+
+- **RocketMQ:**
+
+ 具体可以参考:
+
+ [《RocketMQ 实战之快速入门》](https://www.jianshu.com/p/824066d70da8)
+
+ [《十分钟入门RocketMQ》](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/) (阿里中间件团队博客)
+
+
+- **Kafka**:Kafka是一个分布式的、可分区的、可复制的、基于发布/订阅的消息系统(现在官方的描述是“一个分布式流平台”),Kafka主要用于大数据领域,当然在分布式系统中也有应用。目前市面上流行的消息队列RocketMQ就是阿里借鉴Kafka的原理、用Java开发而得。
+
+ 具体可以参考:
+
+ [《Kafka应用场景》](http://book.51cto.com/art/201801/565244.htm)
+
+ [《初谈Kafka》](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484106&idx=1&sn=aa1999895d009d91eb3692a3e6429d18&chksm=fd9854abcaefddbd1101ca5dc2c7c783d7171320d6300d9b2d8e68b7ef8abd2b02ea03e03600#rd)
+
+**推荐阅读:**
+
+[《Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别》](https://mp.weixin.qq.com/s?__biz=MzU5OTMyODAyNg==&mid=2247484721&idx=1&sn=11e4e29886e581dd328311d308ccc068&chksm=feb7d144c9c058529465b02a4e26a25ef76b60be8984ace9e4a0f5d3d98ca52e014ecb73b061&scene=21#wechat_redirect)
+
+
+
+
+
+
+
From c726fc3add78b03b223e0b5530da0612af543274 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:14:02 +0800
Subject: [PATCH 099/102] Create RocketMQ-Questions.md
---
.../data-communication/RocketMQ-Questions.md | 208 ++++++++++++++++++
1 file changed, 208 insertions(+)
create mode 100644 docs/system-design/data-communication/RocketMQ-Questions.md
diff --git a/docs/system-design/data-communication/RocketMQ-Questions.md b/docs/system-design/data-communication/RocketMQ-Questions.md
new file mode 100644
index 00000000000..c80b144a917
--- /dev/null
+++ b/docs/system-design/data-communication/RocketMQ-Questions.md
@@ -0,0 +1,208 @@
+
+
+- [1 单机版消息中心](#1-%E5%8D%95%E6%9C%BA%E7%89%88%E6%B6%88%E6%81%AF%E4%B8%AD%E5%BF%83)
+- [2 分布式消息中心](#2-%E5%88%86%E5%B8%83%E5%BC%8F%E6%B6%88%E6%81%AF%E4%B8%AD%E5%BF%83)
+ - [2.1 问题与解决](#21-%E9%97%AE%E9%A2%98%E4%B8%8E%E8%A7%A3%E5%86%B3)
+ - [2.1.1 消息丢失的问题](#211-%E6%B6%88%E6%81%AF%E4%B8%A2%E5%A4%B1%E7%9A%84%E9%97%AE%E9%A2%98)
+ - [2.1.2 同步落盘怎么才能快](#212-%E5%90%8C%E6%AD%A5%E8%90%BD%E7%9B%98%E6%80%8E%E4%B9%88%E6%89%8D%E8%83%BD%E5%BF%AB)
+ - [2.1.3 消息堆积的问题](#213-%E6%B6%88%E6%81%AF%E5%A0%86%E7%A7%AF%E7%9A%84%E9%97%AE%E9%A2%98)
+ - [2.1.4 定时消息的实现](#214-%E5%AE%9A%E6%97%B6%E6%B6%88%E6%81%AF%E7%9A%84%E5%AE%9E%E7%8E%B0)
+ - [2.1.5 顺序消息的实现](#215-%E9%A1%BA%E5%BA%8F%E6%B6%88%E6%81%AF%E7%9A%84%E5%AE%9E%E7%8E%B0)
+ - [2.1.6 分布式消息的实现](#216-%E5%88%86%E5%B8%83%E5%BC%8F%E6%B6%88%E6%81%AF%E7%9A%84%E5%AE%9E%E7%8E%B0)
+ - [2.1.7 消息的 push 实现](#217-%E6%B6%88%E6%81%AF%E7%9A%84-push-%E5%AE%9E%E7%8E%B0)
+ - [2.1.8 消息重复发送的避免](#218-%E6%B6%88%E6%81%AF%E9%87%8D%E5%A4%8D%E5%8F%91%E9%80%81%E7%9A%84%E9%81%BF%E5%85%8D)
+ - [2.1.9 广播消费与集群消费](#219-%E5%B9%BF%E6%92%AD%E6%B6%88%E8%B4%B9%E4%B8%8E%E9%9B%86%E7%BE%A4%E6%B6%88%E8%B4%B9)
+ - [2.1.10 RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?](#2110-rocketmq-%E4%B8%8D%E4%BD%BF%E7%94%A8-zookeeper-%E4%BD%9C%E4%B8%BA%E6%B3%A8%E5%86%8C%E4%B8%AD%E5%BF%83%E7%9A%84%E5%8E%9F%E5%9B%A0%E4%BB%A5%E5%8F%8A%E8%87%AA%E5%88%B6%E7%9A%84-nameserver-%E4%BC%98%E7%BC%BA%E7%82%B9)
+ - [2.1.11 其它](#2111-%E5%85%B6%E5%AE%83)
+- [3 参考](#3-%E5%8F%82%E8%80%83)
+
+
+
+# 1 单机版消息中心
+
+一个消息中心,最基本的需要支持多生产者、多消费者,例如下:
+
+```java
+class Scratch {
+
+ public static void main(String[] args) {
+ // 实际中会有 nameserver 服务来找到 broker 具体位置以及 broker 主从信息
+ Broker broker = new Broker();
+ Producer producer1 = new Producer();
+ producer1.connectBroker(broker);
+ Producer producer2 = new Producer();
+ producer2.connectBroker(broker);
+
+ Consumer consumer1 = new Consumer();
+ consumer1.connectBroker(broker);
+ Consumer consumer2 = new Consumer();
+ consumer2.connectBroker(broker);
+
+ for (int i = 0; i < 2; i++) {
+ producer1.asyncSendMsg("producer1 send msg" + i);
+ producer2.asyncSendMsg("producer2 send msg" + i);
+ }
+ System.out.println("broker has msg:" + broker.getAllMagByDisk());
+
+ for (int i = 0; i < 1; i++) {
+ System.out.println("consumer1 consume msg:" + consumer1.syncPullMsg());
+ }
+ for (int i = 0; i < 3; i++) {
+ System.out.println("consumer2 consume msg:" + consumer2.syncPullMsg());
+ }
+ }
+
+}
+
+class Producer {
+
+ private Broker broker;
+
+ public void connectBroker(Broker broker) {
+ this.broker = broker;
+ }
+
+ public void asyncSendMsg(String msg) {
+ if (broker == null) {
+ throw new RuntimeException("please connect broker first");
+ }
+ new Thread(() -> {
+ broker.sendMsg(msg);
+ }).start();
+ }
+}
+
+class Consumer {
+ private Broker broker;
+
+ public void connectBroker(Broker broker) {
+ this.broker = broker;
+ }
+
+ public String syncPullMsg() {
+ return broker.getMsg();
+ }
+
+}
+
+class Broker {
+
+ // 对应 RocketMQ 中 MessageQueue,默认情况下 1 个 Topic 包含 4 个 MessageQueue
+ private LinkedBlockingQueue messageQueue = new LinkedBlockingQueue(Integer.MAX_VALUE);
+
+ // 实际发送消息到 broker 服务器使用 Netty 发送
+ public void sendMsg(String msg) {
+ try {
+ messageQueue.put(msg);
+ // 实际会同步或异步落盘,异步落盘使用的定时任务定时扫描落盘
+ } catch (InterruptedException e) {
+
+ }
+ }
+
+ public String getMsg() {
+ try {
+ return messageQueue.take();
+ } catch (InterruptedException e) {
+
+ }
+ return null;
+ }
+
+ public String getAllMagByDisk() {
+ StringBuilder sb = new StringBuilder("\n");
+ messageQueue.iterator().forEachRemaining((msg) -> {
+ sb.append(msg + "\n");
+ });
+ return sb.toString();
+ }
+}
+```
+
+问题:
+1. 没有实现真正执行消息存储落盘
+2. 没有实现 NameServer 去作为注册中心,定位服务
+3. 使用 LinkedBlockingQueue 作为消息队列,注意,参数是无限大,在真正 RocketMQ 也是如此是无限大,理论上不会出现对进来的数据进行抛弃,但是会有内存泄漏问题(阿里巴巴开发手册也因为这个问题,建议我们使用自制线程池)
+4. 没有使用多个队列(即多个 LinkedBlockingQueue),RocketMQ 的顺序消息是通过生产者和消费者同时使用同一个 MessageQueue 来实现,但是如果我们只有一个 MessageQueue,那我们天然就支持顺序消息
+5. 没有使用 MappedByteBuffer 来实现文件映射从而使消息数据落盘非常的快(实际 RocketMQ 使用的是 FileChannel+DirectBuffer)
+
+# 2 分布式消息中心
+
+## 2.1 问题与解决
+
+### 2.1.1 消息丢失的问题
+
+1. 当你系统需要保证百分百消息不丢失,你可以使用生产者每发送一个消息,Broker 同步返回一个消息发送成功的反馈消息
+2. 即每发送一个消息,同步落盘后才返回生产者消息发送成功,这样只要生产者得到了消息发送生成的返回,事后除了硬盘损坏,都可以保证不会消息丢失
+3. 但是这同时引入了一个问题,同步落盘怎么才能快?
+
+### 2.1.2 同步落盘怎么才能快
+
+1. 使用 FileChannel + DirectBuffer 池,使用堆外内存,加快内存拷贝
+2. 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询index 文件来定位,从而减少文件IO随机读写的性能损耗
+
+### 2.1.3 消息堆积的问题
+
+1. 后台定时任务每隔72小时,删除旧的没有使用过的消息信息
+2. 根据不同的业务实现不同的丢弃任务,具体参考线程池的 AbortPolicy,例如FIFO/LRU等(RocketMQ没有此策略)
+3. 消息定时转移,或者对某些重要的 TAG 型(支付型)消息真正落库
+
+### 2.1.4 定时消息的实现
+
+1. 实际 RocketMQ 没有实现任意精度的定时消息,它只支持某些特定的时间精度的定时消息
+2. 实现定时消息的原理是:创建特定时间精度的 MessageQueue,例如生产者需要定时1s之后被消费者消费,你只需要将此消息发送到特定的 Topic,例如:MessageQueue-1 表示这个 MessageQueue 里面的消息都会延迟一秒被消费,然后 Broker 会在 1s 后发送到消费者消费此消息,使用 newSingleThreadScheduledExecutor 实现
+
+### 2.1.5 顺序消息的实现
+
+与定时消息同原理,生产者生产消息时指定特定的 MessageQueue ,消费者消费消息时,消费特定的 MessageQueue,其实单机版的消息中心在一个 MessageQueue 就天然支持了顺序消息
+
+### 2.1.6 分布式消息的实现
+
+1. 需要前置知识:2PC
+2. RocketMQ4.3 起支持,原理为2PC,即两阶段提交,prepared->commit/rollback
+3. 生产者发送事务消息,假设该事务消息 Topic 为 Topic1-Trans,Broker 得到后首先更改该消息的 Topic 为 Topic1-Prepared,该 Topic1-Prepared 对消费者不可见。然后定时回调生产者的本地事务A执行状态,根据本地事务A执行状态,来是否将该消息修改为 Topic1-Commit 或 Topic1-Rollback,消费者就可以正常找到该事务消息或者不执行等
+
+>注意,就算是事务消息最后回滚了也不会物理删除,只会逻辑删除该消息
+
+### 2.1.7 消息的 push 实现
+
+1. 注意,RocketMQ 已经说了自己会有低延迟问题,其中就包括这个消息的 push 延迟问题
+2. 因为这并不是真正的将消息主动的推送到消费者,而是 Broker 定时任务每5s将消息推送到消费者
+
+### 2.1.8 消息重复发送的避免
+
+1. RocketMQ 会出现消息重复发送的问题,因为在网络延迟的情况下,这种问题不可避免的发生,如果非要实现消息不可重复发送,那基本太难,因为网络环境无法预知,还会使程序复杂度加大,因此默认允许消息重复发送
+2. RocketMQ 让使用者在消费者端去解决该问题,即需要消费者端在消费消息时支持幂等性的去消费消息
+3. 最简单的解决方案是每条消费记录有个消费状态字段,根据这个消费状态字段来是否消费或者使用一个集中式的表,来存储所有消息的消费状态,从而避免重复消费
+4. 具体实现可以查询关于消息幂等消费的解决方案
+
+### 2.1.9 广播消费与集群消费
+
+1. 消息消费区别:广播消费,订阅该 Topic 的消息者们都会消费**每个**消息。集群消费,订阅该 Topic 的消息者们只会有一个去消费**某个**消息
+2. 消息落盘区别:具体表现在消息消费进度的保存上。广播消费,由于每个消费者都独立的去消费每个消息,因此每个消费者各自保存自己的消息消费进度。而集群消费下,订阅了某个 Topic,而旗下又有多个 MessageQueue,每个消费者都可能会去消费不同的 MessageQueue,因此总体的消费进度保存在 Broker 上集中的管理
+
+### 2.1.10 RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?
+
+1. ZooKeeper 作为支持顺序一致性的中间件,在某些情况下,它为了满足一致性,会丢失一定时间内的可用性,RocketMQ 需要注册中心只是为了发现组件地址,在某些情况下,RocketMQ 的注册中心可以出现数据不一致性,这同时也是 NameServer 的缺点,因为 NameServer 集群间互不通信,它们之间的注册信息可能会不一致
+2. 另外,当有新的服务器加入时,NameServer 并不会立马通知到 Produer,而是由 Produer 定时去请求 NameServer 获取最新的 Broker/Consumer 信息(这种情况是通过 Producer 发送消息时,负载均衡解决)
+
+### 2.1.11 其它
+
+![][1]
+
+加分项咯
+1. 包括组件通信间使用 Netty 的自定义协议
+2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
+3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时就使用过滤服务器进行过滤)
+4. Broker 同步双写和异步双写中 Master 和 Slave 的交互
+
+# 3 参考
+
+1. 《RocketMQ技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
+2. 关于 RocketMQ 对 MappedByteBuffer 的一点优化:https://lishoubo.github.io/2017/09/27/MappedByteBuffer%E7%9A%84%E4%B8%80%E7%82%B9%E4%BC%98%E5%8C%96/
+3. 阿里中间件团队博客-十分钟入门RocketMQ:http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/
+4. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
+5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
+6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
+
+[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/RocketMQ%E6%B5%81%E7%A8%8B.png
\ No newline at end of file
From 9d4bf77fe8373e4135b75db7d085339fbda18f52 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:14:06 +0800
Subject: [PATCH 100/102] Update HomePage.md
---
docs/HomePage.md | 151 ++++++++++++++++++++++++-----------------------
1 file changed, 76 insertions(+), 75 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index 6f87b4408f3..e4463d8d349 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -10,169 +10,170 @@
### 基础
-* [Java 基础知识回顾](./java/Java基础知识.md)
-* [J2EE 基础知识回顾](./java/J2EE基础知识.md)
+* [Java 基础知识回顾](docs/java/Java基础知识.md)
+* [J2EE 基础知识回顾](docs/java/J2EE基础知识.md)
### 容器
-* [常见面试题](./java/collection/Java集合框架常见面试题.md)
-* [ArrayList 源码学习](./java/collection/ArrayList.md)
-* [LinkedList 源码学习](./java/collection/LinkedList.md)
-* [HashMap(JDK1.8)源码学习](./java/collection/HashMap.md)
+* [常见面试题](docs/java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](docs/java/collection/ArrayList.md)
+* [LinkedList 源码学习](docs/java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](docs/java/collection/HashMap.md)
### 并发
-* [Java 并发基础常见面试题总结](./java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
-* [Java 并发进阶常见面试题总结](./java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
-* [并发容器总结](./java/Multithread/并发容器总结.md)
-* [乐观锁与悲观锁](./essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
-* [JUC 中的 Atomic 原子类总结](./java/Multithread/Atomic.md)
-* [AQS 原理以及 AQS 同步组件总结](./java/Multithread/AQS.md)
+* [Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](docs/java/Multithread/并发容器总结.md)
+* [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
### JVM
-* [一 Java内存区域](./java/jvm/Java内存区域.md)
-* [二 JVM垃圾回收](./java/jvm/JVM垃圾回收.md)
-* [三 JDK 监控和故障处理工具](./java/jvm/JDK监控和故障处理工具总结.md)
-* [四 类文件结构](./java/jvm/类文件结构.md)
-* [五 类加载过程](./java/jvm/类加载过程.md)
-* [六 类加载器](./java/jvm/类加载器.md)
+* [一 Java内存区域](docs/java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](docs/java/jvm/类文件结构.md)
+* [五 类加载过程](docs/java/jvm/类加载过程.md)
+* [六 类加载器](docs/java/jvm/类加载器.md)
### I/O
-* [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
-* [Java IO 与 NIO系列文章](./java/Java%20IO与NIO.md)
+* [BIO,NIO,AIO 总结 ](docs/java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](docs/java/Java%20IO与NIO.md)
### Java 8
-* [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
-* [Java 8 学习资源推荐](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+* [Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)
### 编程规范
-- [Java 编程规范](./java/Java编程规范.md)
+- [Java 编程规范](docs/java/Java编程规范.md)
## 网络
-* [计算机网络常见面试题](./network/计算机网络.md)
-* [计算机网络基础知识总结](./network/干货:计算机网络知识总结.md)
-* [HTTPS中的TLS](./network/HTTPS中的TLS.md)
+* [计算机网络常见面试题](docs/network/计算机网络.md)
+* [计算机网络基础知识总结](docs/network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](docs/network/HTTPS中的TLS.md)
## 操作系统
### Linux相关
-* [后端程序员必备的 Linux 基础知识](./operating-system/后端程序员必备的Linux基础知识.md)
-* [Shell 编程入门](./operating-system/Shell.md)
+* [后端程序员必备的 Linux 基础知识](docs/operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](docs/operating-system/Shell.md)
## 数据结构与算法
### 数据结构
-- [数据结构知识学习与面试](./dataStructures-algorithms/数据结构.md)
+- [数据结构知识学习与面试](docs/dataStructures-algorithms/数据结构.md)
### 算法
-- [算法学习资源推荐](./dataStructures-algorithms/算法学习资源推荐.md)
-- [几道常见的子符串算法题总结 ](./dataStructures-algorithms/几道常见的子符串算法题.md)
-- [几道常见的链表算法题总结 ](./dataStructures-algorithms/几道常见的链表算法题.md)
-- [剑指offer部分编程题](./dataStructures-algorithms/剑指offer部分编程题.md)
-- [公司真题](./dataStructures-algorithms/公司真题.md)
-- [回溯算法经典案例之N皇后问题](./dataStructures-algorithms/Backtracking-NQueens.md)
+- [算法学习资源推荐](docs/dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的子符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](docs/dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](docs/dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](docs/dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](docs/dataStructures-algorithms/Backtracking-NQueens.md)
## 数据库
### MySQL
-* [MySQL 学习与面试](./database/MySQL.md)
-* [一千行MySQL学习笔记](./database/一千行MySQL命令.md)
-* [MySQL高性能优化规范建议](./database/MySQL高性能优化规范建议.md)
-* [搞定数据库索引就是这么简单](./database/MySQL%20Index.md)
-* [事务隔离级别(图文详解)](./database/事务隔离级别(图文详解).md)
-* [一条SQL语句在MySQL中如何执行的](./database/一条sql语句在mysql中如何执行的.md)
+* [MySQL 学习与面试](docs/database/MySQL.md)
+* [一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
+* [搞定数据库索引就是这么简单](docs/database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](docs/database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
### Redis
-* [Redis 总结](./database/Redis/Redis.md)
-* [Redlock分布式锁](./database/Redis/Redlock分布式锁.md)
-* [如何做可靠的分布式锁,Redlock真的可行么](./database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+* [Redis 总结](docs/database/Redis/Redis.md)
+* [Redlock分布式锁](docs/database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](docs/database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
## 系统设计
### 设计模式
-- [设计模式系列文章](./system-design/设计模式.md)
+- [设计模式系列文章](docs/system-design/设计模式.md)
### 常用框架
#### Spring
-- [Spring 学习与面试](./system-design/framework/Spring学习与面试.md)
-- [Spring中bean的作用域与生命周期](./system-design/framework/SpringBean.md)
-- [SpringMVC 工作原理详解](./system-design/framework/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
+- [Spring 学习与面试](docs/system-design/framework/Spring学习与面试.md)
+- [Spring中bean的作用域与生命周期](docs/system-design/framework/SpringBean.md)
+- [SpringMVC 工作原理详解](docs/system-design/framework/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
#### ZooKeeper
-- [ZooKeeper 相关概念总结](./system-design/framework/ZooKeeper.md)
-- [ZooKeeper 数据模型和常见命令](./system-design/framework/ZooKeeper数据模型和常见命令.md)
+- [ZooKeeper 相关概念总结](docs/system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](docs/system-design/framework/ZooKeeper数据模型和常见命令.md)
### 数据通信
-- [数据通信(RESTful、RPC、消息队列)相关知识点总结](./system-design/data-communication/数据通信(RESTful、RPC、消息队列).md)
-- [Dubbo 总结:关于 Dubbo 的重要知识点](./system-design/data-communication/dubbo.md)
-- [消息队列总结](./system-design/data-communication/message-queue.md)
-- [RabbitMQ 的重要概念以及安装](./system-design/data-communication/rabbitmq.md)
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/Dubbo.md)
+- [消息队列总结](docs/system-design/data-communication/message-queue.md)
+- [RabbitMQ 入门](docs/system-design/data-communication/RabbitMQ.md)
+- [RocketMQ的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
### 网站架构
-- [一文读懂分布式应该学什么](./system-design/website-architecture/分布式.md)
-- [8 张图读懂大型网站技术架构](./system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
-- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](./system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+- [一文读懂分布式应该学什么](docs/system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](docs/system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](docs/system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
## 面试指南
### 备战面试
-* [【备战面试1】程序员的简历就该这样写](./essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
-* [【备战面试2】初出茅庐的程序员该如何准备面试?](./essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
-* [【备战面试3】7个大部分程序员在面试前很关心的问题](./essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
-* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](./essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
-* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](./essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
-* [【备战面试6】美团面试常见问题总结(附详解答案)](./essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+* [【备战面试1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
### 常见面试题总结
-* [第一周(2018-8-7)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
-* [第二周(2018-8-13)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
-* [第三周(2018-08-22)](./java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
-* [第四周(2018-8-30).md](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+* [第一周(2018-8-7)](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](docs/java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
### 面经
-- [5面阿里,终获offer(2018年秋招)](./essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
-- [蚂蚁金服2019实习生面经总结(已拿口头offer)](./essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
-- [2019年蚂蚁金服、头条、拼多多的面试总结](./essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+- [5面阿里,终获offer(2018年秋招)](docs/essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
## 工具
### Git
-* [Git入门](./tools/Git.md)
+* [Git入门](docs/tools/Git.md)
### Docker
-* [Docker 入门](./tools/Docker.md)
-* [一文搞懂 Docker 镜像的常用操作!](./tools/Docker-Image.md)
+* [Docker 入门](docs/tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
## 资料
### 书单
-- [Java程序员必备书单](./data/java-recommended-books.md)
+- [Java程序员必备书单](docs/data/java-recommended-books.md)
### Github榜单
-- [Java 项目月榜单](./github-trending/JavaGithubTrending.md)
+- [Java 项目月榜单](docs/github-trending/JavaGithubTrending.md)
***
From 34e625b75ded5008c9f734fae5e658b813caeeb4 Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Mon, 20 May 2019 17:17:23 +0800
Subject: [PATCH 101/102] Update RocketMQ-Questions.md
---
docs/system-design/data-communication/RocketMQ-Questions.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/docs/system-design/data-communication/RocketMQ-Questions.md b/docs/system-design/data-communication/RocketMQ-Questions.md
index c80b144a917..81b701aca87 100644
--- a/docs/system-design/data-communication/RocketMQ-Questions.md
+++ b/docs/system-design/data-communication/RocketMQ-Questions.md
@@ -1,3 +1,4 @@
+本文来自读者 [PR](https://github.com/Snailclimb/JavaGuide/pull/291)。
- [1 单机版消息中心](#1-%E5%8D%95%E6%9C%BA%E7%89%88%E6%B6%88%E6%81%AF%E4%B8%AD%E5%BF%83)
@@ -205,4 +206,4 @@ class Broker {
5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
-[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/RocketMQ%E6%B5%81%E7%A8%8B.png
\ No newline at end of file
+[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/RocketMQ%E6%B5%81%E7%A8%8B.png
From 4b581d01f642efafe918c9e541a4ce8084898deb Mon Sep 17 00:00:00 2001
From: SnailClimb
Date: Tue, 21 May 2019 10:51:43 +0800
Subject: [PATCH 102/102] Update HomePage.md
---
docs/HomePage.md | 152 +++++++++++++++++++++++------------------------
1 file changed, 76 insertions(+), 76 deletions(-)
diff --git a/docs/HomePage.md b/docs/HomePage.md
index e4463d8d349..fcfb25f83c1 100644
--- a/docs/HomePage.md
+++ b/docs/HomePage.md
@@ -10,170 +10,170 @@
### 基础
-* [Java 基础知识回顾](docs/java/Java基础知识.md)
-* [J2EE 基础知识回顾](docs/java/J2EE基础知识.md)
+* [Java 基础知识回顾](./java/Java基础知识.md)
+* [J2EE 基础知识回顾](./java/J2EE基础知识.md)
### 容器
-* [常见面试题](docs/java/collection/Java集合框架常见面试题.md)
-* [ArrayList 源码学习](docs/java/collection/ArrayList.md)
-* [LinkedList 源码学习](docs/java/collection/LinkedList.md)
-* [HashMap(JDK1.8)源码学习](docs/java/collection/HashMap.md)
+* [常见面试题](./java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](./java/collection/ArrayList.md)
+* [LinkedList 源码学习](./java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](./java/collection/HashMap.md)
### 并发
-* [Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
-* [Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
-* [并发容器总结](docs/java/Multithread/并发容器总结.md)
-* [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
-* [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
-* [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
+* [Java 并发基础常见面试题总结](./java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](./java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](./java/Multithread/并发容器总结.md)
+* [乐观锁与悲观锁](./essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](./java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](./java/Multithread/AQS.md)
### JVM
-* [一 Java内存区域](docs/java/jvm/Java内存区域.md)
-* [二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
-* [三 JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
-* [四 类文件结构](docs/java/jvm/类文件结构.md)
-* [五 类加载过程](docs/java/jvm/类加载过程.md)
-* [六 类加载器](docs/java/jvm/类加载器.md)
+* [一 Java内存区域](./java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](./java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](./java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](./java/jvm/类文件结构.md)
+* [五 类加载过程](./java/jvm/类加载过程.md)
+* [六 类加载器](./java/jvm/类加载器.md)
### I/O
-* [BIO,NIO,AIO 总结 ](docs/java/BIO-NIO-AIO.md)
-* [Java IO 与 NIO系列文章](docs/java/Java%20IO与NIO.md)
+* [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](./java/Java%20IO与NIO.md)
### Java 8
-* [Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)
-* [Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+* [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
### 编程规范
-- [Java 编程规范](docs/java/Java编程规范.md)
+- [Java 编程规范](./java/Java编程规范.md)
## 网络
-* [计算机网络常见面试题](docs/network/计算机网络.md)
-* [计算机网络基础知识总结](docs/network/干货:计算机网络知识总结.md)
-* [HTTPS中的TLS](docs/network/HTTPS中的TLS.md)
+* [计算机网络常见面试题](./network/计算机网络.md)
+* [计算机网络基础知识总结](./network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](./network/HTTPS中的TLS.md)
## 操作系统
### Linux相关
-* [后端程序员必备的 Linux 基础知识](docs/operating-system/后端程序员必备的Linux基础知识.md)
-* [Shell 编程入门](docs/operating-system/Shell.md)
+* [后端程序员必备的 Linux 基础知识](./operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](./operating-system/Shell.md)
## 数据结构与算法
### 数据结构
-- [数据结构知识学习与面试](docs/dataStructures-algorithms/数据结构.md)
+- [数据结构知识学习与面试](./dataStructures-algorithms/数据结构.md)
### 算法
-- [算法学习资源推荐](docs/dataStructures-algorithms/算法学习资源推荐.md)
-- [几道常见的子符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
-- [几道常见的链表算法题总结 ](docs/dataStructures-algorithms/几道常见的链表算法题.md)
-- [剑指offer部分编程题](docs/dataStructures-algorithms/剑指offer部分编程题.md)
-- [公司真题](docs/dataStructures-algorithms/公司真题.md)
-- [回溯算法经典案例之N皇后问题](docs/dataStructures-algorithms/Backtracking-NQueens.md)
+- [算法学习资源推荐](./dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的子符串算法题总结 ](./dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](./dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](./dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](./dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](./dataStructures-algorithms/Backtracking-NQueens.md)
## 数据库
### MySQL
-* [MySQL 学习与面试](docs/database/MySQL.md)
-* [一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)
-* [MySQL高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
-* [搞定数据库索引就是这么简单](docs/database/MySQL%20Index.md)
-* [事务隔离级别(图文详解)](docs/database/事务隔离级别(图文详解).md)
-* [一条SQL语句在MySQL中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
+* [MySQL 学习与面试](./database/MySQL.md)
+* [一千行MySQL学习笔记](./database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](./database/MySQL高性能优化规范建议.md)
+* [搞定数据库索引就是这么简单](./database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](./database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](./database/一条sql语句在mysql中如何执行的.md)
### Redis
-* [Redis 总结](docs/database/Redis/Redis.md)
-* [Redlock分布式锁](docs/database/Redis/Redlock分布式锁.md)
-* [如何做可靠的分布式锁,Redlock真的可行么](docs/database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+* [Redis 总结](./database/Redis/Redis.md)
+* [Redlock分布式锁](./database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](./database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
## 系统设计
### 设计模式
-- [设计模式系列文章](docs/system-design/设计模式.md)
+- [设计模式系列文章](./system-design/设计模式.md)
### 常用框架
#### Spring
-- [Spring 学习与面试](docs/system-design/framework/Spring学习与面试.md)
-- [Spring中bean的作用域与生命周期](docs/system-design/framework/SpringBean.md)
-- [SpringMVC 工作原理详解](docs/system-design/framework/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
+- [Spring 学习与面试](./system-design/framework/Spring学习与面试.md)
+- [Spring中bean的作用域与生命周期](./system-design/framework/SpringBean.md)
+- [SpringMVC 工作原理详解](./system-design/framework/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
#### ZooKeeper
-- [ZooKeeper 相关概念总结](docs/system-design/framework/ZooKeeper.md)
-- [ZooKeeper 数据模型和常见命令](docs/system-design/framework/ZooKeeper数据模型和常见命令.md)
+- [ZooKeeper 相关概念总结](./system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](./system-design/framework/ZooKeeper数据模型和常见命令.md)
### 数据通信
-- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
-- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/Dubbo.md)
-- [消息队列总结](docs/system-design/data-communication/message-queue.md)
-- [RabbitMQ 入门](docs/system-design/data-communication/RabbitMQ.md)
-- [RocketMQ的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](./system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](./system-design/data-communication/Dubbo.md)
+- [消息队列总结](./system-design/data-communication/message-queue.md)
+- [RabbitMQ 入门](./system-design/data-communication/RabbitMQ.md)
+- [RocketMQ的几个简单问题与答案](./system-design/data-communication/RocketMQ-Questions.md)
### 网站架构
-- [一文读懂分布式应该学什么](docs/system-design/website-architecture/分布式.md)
-- [8 张图读懂大型网站技术架构](docs/system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
-- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](docs/system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+- [一文读懂分布式应该学什么](./system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](./system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](./system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
## 面试指南
### 备战面试
-* [【备战面试1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
-* [【备战面试2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
-* [【备战面试3】7个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
-* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
-* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
-* [【备战面试6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+* [【备战面试1】程序员的简历就该这样写](./essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](./essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](./essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](./essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](./essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](./essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
### 常见面试题总结
-* [第一周(2018-8-7)](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
-* [第二周(2018-8-13)](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
-* [第三周(2018-08-22)](docs/java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
-* [第四周(2018-8-30).md](docs/essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+* [第一周(2018-8-7)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](./java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
### 面经
-- [5面阿里,终获offer(2018年秋招)](docs/essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
-- [蚂蚁金服2019实习生面经总结(已拿口头offer)](docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
-- [2019年蚂蚁金服、头条、拼多多的面试总结](docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+- [5面阿里,终获offer(2018年秋招)](./essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](./essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](./essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
## 工具
### Git
-* [Git入门](docs/tools/Git.md)
+* [Git入门](./tools/Git.md)
### Docker
-* [Docker 入门](docs/tools/Docker.md)
-* [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
+* [Docker 入门](./tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](./tools/Docker-Image.md)
## 资料
### 书单
-- [Java程序员必备书单](docs/data/java-recommended-books.md)
+- [Java程序员必备书单](./data/java-recommended-books.md)
### Github榜单
-- [Java 项目月榜单](docs/github-trending/JavaGithubTrending.md)
+- [Java 项目月榜单](./github-trending/JavaGithubTrending.md)
***
 +
+
 +
+
 +
+
 ### 3.2 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
-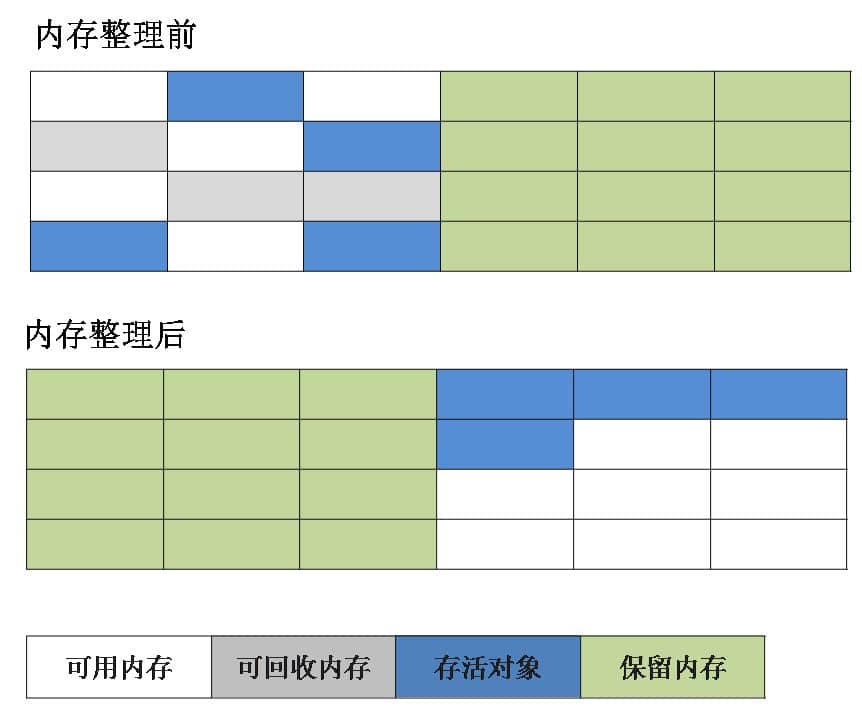
+
### 3.2 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
-
+ ### 3.3 标记-整理算法
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
-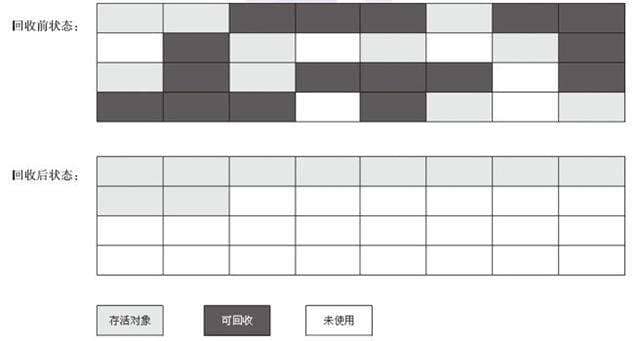
+
### 3.4 分代收集算法
-当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
+当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
-**延伸面试问题:** HotSpot为什么要分为新生代和老年代?
+**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
根据上面的对分代收集算法的介绍回答。
## 4 垃圾收集器
-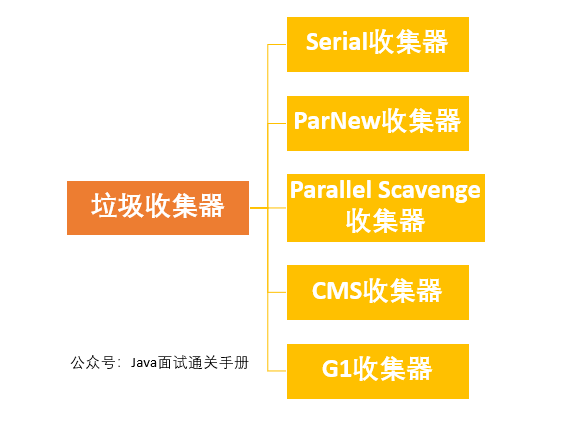
+
**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
-虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为知道现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的HotSpot虚拟机就不会实现那么多不同的垃圾收集器了。
+虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为知道现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
-### 4.1 Serial收集器
+### 4.1 Serial 收集器
Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
**新生代采用复制算法,老年代采用标记-整理算法。**
-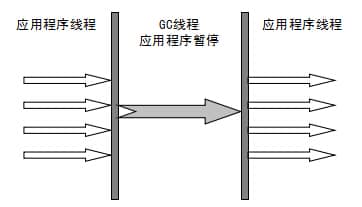
+
-虚拟机的设计者们当然知道Stop The World带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
+虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
-但是Serial收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial收集器对于运行在Client模式下的虚拟机来说是个不错的选择。
+但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
-### 4.2 ParNew收集器
-**ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和Serial收集器完全一样。**
+### 4.2 ParNew 收集器
+**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
**新生代采用复制算法,老年代采用标记-整理算法。**
-
+
-它是许多运行在Server模式下的虚拟机的首要选择,除了Serial收集器外,只有它能与CMS收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
+它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
**并行和并发概念补充:**
- **并行(Parallel)** :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
-- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个CPU上。
+- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
-### 4.3 Parallel Scavenge收集器
+### 4.3 Parallel Scavenge 收集器
-Parallel Scavenge 收集器类似于ParNew 收集器。 **那么它有什么特别之处呢?**
+Parallel Scavenge 收集器类似于 ParNew 收集器。 **那么它有什么特别之处呢?**
```
-XX:+UseParallelGC
- 使用Parallel收集器+ 老年代串行
+ 使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC
- 使用Parallel收集器+ 老年代并行
+ 使用 Parallel 收集器+ 老年代并行
```
-**Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。** Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
**新生代采用复制算法,老年代采用标记-整理算法。**
-
+
-### 4.4.Serial Old收集器
-**Serial收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在JDK1.5以及以前的版本中与Parallel Scavenge收集器搭配使用,另一种用途是作为CMS收集器的后备方案。
+### 4.4.Serial Old 收集器
+**Serial 收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
-### 4.5 Parallel Old收集器
- **Parallel Scavenge收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及CPU资源的场合,都可以优先考虑 Parallel Scavenge收集器和Parallel Old收集器。
+### 4.5 Parallel Old 收集器
+ **Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
-### 4.6 CMS收集器
+### 4.6 CMS 收集器
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
-**CMS(Concurrent Mark Sweep)收集器是HotSpot虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
+**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
-从名字中的**Mark Sweep**这两个词可以看出,CMS收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
+从名字中的**Mark Sweep**这两个词可以看出,CMS 收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
-- **初始标记:** 暂停所有的其他线程,并记录下直接与root相连的对象,速度很快 ;
-- **并发标记:** 同时开启GC和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以GC线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
+- **初始标记:** 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
+- **并发标记:** 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- **重新标记:** 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
-- **并发清除:** 开启用户线程,同时GC线程开始对为标记的区域做清扫。
+- **并发清除:** 开启用户线程,同时 GC 线程开始对为标记的区域做清扫。
-
+
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
-- **对CPU资源敏感;**
+- **对 CPU 资源敏感;**
- **无法处理浮动垃圾;**
- **它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
-### 4.7 G1收集器
+### 4.7 G1 收集器
-**G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征.**
+**G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.**
-被视为JDK1.7中HotSpot虚拟机的一个重要进化特征。它具备一下特点:
+被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
-- **并行与并发**:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短Stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
-- **分代收集**:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
-- **空间整合**:与CMS的“标记--清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
-- **可预测的停顿**:这是G1相对于CMS的另一个大优势,降低停顿时间是G1 和 CMS 共同的关注点,但G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内。
+- **并行与并发**:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
+- **分代收集**:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
+- **空间整合**:与 CMS 的“标记--清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
+- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
-G1收集器的运作大致分为以下几个步骤:
+G1 收集器的运作大致分为以下几个步骤:
- **初始标记**
- **并发标记**
@@ -355,14 +386,13 @@ G1收集器的运作大致分为以下几个步骤:
- **筛选回收**
-**G1收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的Region(这也就是它的名字Garbage-First的由来)**。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了GF收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
-
-
+**G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)**。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 GF 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
## 参考
-- 《深入理解Java虚拟机:JVM高级特性与最佳实践(第二版》
+- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
- https://my.oschina.net/hosee/blog/644618
+-
### 3.3 标记-整理算法
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
-
+
### 3.4 分代收集算法
-当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
+当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
-**延伸面试问题:** HotSpot为什么要分为新生代和老年代?
+**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
根据上面的对分代收集算法的介绍回答。
## 4 垃圾收集器
-
+
**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
-虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为知道现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的HotSpot虚拟机就不会实现那么多不同的垃圾收集器了。
+虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为知道现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
-### 4.1 Serial收集器
+### 4.1 Serial 收集器
Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
**新生代采用复制算法,老年代采用标记-整理算法。**
-
+
-虚拟机的设计者们当然知道Stop The World带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
+虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
-但是Serial收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial收集器对于运行在Client模式下的虚拟机来说是个不错的选择。
+但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
-### 4.2 ParNew收集器
-**ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和Serial收集器完全一样。**
+### 4.2 ParNew 收集器
+**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
**新生代采用复制算法,老年代采用标记-整理算法。**
-
+
-它是许多运行在Server模式下的虚拟机的首要选择,除了Serial收集器外,只有它能与CMS收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
+它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
**并行和并发概念补充:**
- **并行(Parallel)** :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
-- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个CPU上。
+- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
-### 4.3 Parallel Scavenge收集器
+### 4.3 Parallel Scavenge 收集器
-Parallel Scavenge 收集器类似于ParNew 收集器。 **那么它有什么特别之处呢?**
+Parallel Scavenge 收集器类似于 ParNew 收集器。 **那么它有什么特别之处呢?**
```
-XX:+UseParallelGC
- 使用Parallel收集器+ 老年代串行
+ 使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC
- 使用Parallel收集器+ 老年代并行
+ 使用 Parallel 收集器+ 老年代并行
```
-**Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。** Parallel Scavenge收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
**新生代采用复制算法,老年代采用标记-整理算法。**
-
+
-### 4.4.Serial Old收集器
-**Serial收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在JDK1.5以及以前的版本中与Parallel Scavenge收集器搭配使用,另一种用途是作为CMS收集器的后备方案。
+### 4.4.Serial Old 收集器
+**Serial 收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
-### 4.5 Parallel Old收集器
- **Parallel Scavenge收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及CPU资源的场合,都可以优先考虑 Parallel Scavenge收集器和Parallel Old收集器。
+### 4.5 Parallel Old 收集器
+ **Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
-### 4.6 CMS收集器
+### 4.6 CMS 收集器
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
-**CMS(Concurrent Mark Sweep)收集器是HotSpot虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
+**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
-从名字中的**Mark Sweep**这两个词可以看出,CMS收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
+从名字中的**Mark Sweep**这两个词可以看出,CMS 收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
-- **初始标记:** 暂停所有的其他线程,并记录下直接与root相连的对象,速度很快 ;
-- **并发标记:** 同时开启GC和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以GC线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
+- **初始标记:** 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
+- **并发标记:** 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- **重新标记:** 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
-- **并发清除:** 开启用户线程,同时GC线程开始对为标记的区域做清扫。
+- **并发清除:** 开启用户线程,同时 GC 线程开始对为标记的区域做清扫。
-
+
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
-- **对CPU资源敏感;**
+- **对 CPU 资源敏感;**
- **无法处理浮动垃圾;**
- **它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
-### 4.7 G1收集器
+### 4.7 G1 收集器
-**G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征.**
+**G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.**
-被视为JDK1.7中HotSpot虚拟机的一个重要进化特征。它具备一下特点:
+被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
-- **并行与并发**:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短Stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
-- **分代收集**:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。
-- **空间整合**:与CMS的“标记--清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
-- **可预测的停顿**:这是G1相对于CMS的另一个大优势,降低停顿时间是G1 和 CMS 共同的关注点,但G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内。
+- **并行与并发**:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
+- **分代收集**:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
+- **空间整合**:与 CMS 的“标记--清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
+- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
-G1收集器的运作大致分为以下几个步骤:
+G1 收集器的运作大致分为以下几个步骤:
- **初始标记**
- **并发标记**
@@ -355,14 +386,13 @@ G1收集器的运作大致分为以下几个步骤:
- **筛选回收**
-**G1收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的Region(这也就是它的名字Garbage-First的由来)**。这种使用Region划分内存空间以及有优先级的区域回收方式,保证了GF收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
-
-
+**G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)**。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 GF 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
## 参考
-- 《深入理解Java虚拟机:JVM高级特性与最佳实践(第二版》
+- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
- https://my.oschina.net/hosee/blog/644618
+-