diff --git a/README.md b/README.md
index 96a459b6da8..10081046d97 100644
--- a/README.md
+++ b/README.md
@@ -290,7 +290,10 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
 -
+
+
-
+
+  +
+
+
+

 @@ -339,4 +342,4 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
\ No newline at end of file
+
diff --git "a/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md" "b/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
index cd2a3e31e2b..8489082b2f3 100644
--- "a/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
+++ "b/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
@@ -135,17 +135,21 @@ public class Main {
}
- private static boolean checkStrs(String[] strs) {
- if (strs != null) {
- // 遍历strs检查元素值
- for (int i = 0; i < strs.length; i++) {
- if (strs[i] == null || strs[i].length() == 0) {
- return false;
- }
- }
- }
- return true;
- }
+ private static boolean chechStrs(String[] strs) {
+ boolean flag = false;
+ if (strs != null) {
+ // 遍历strs检查元素值
+ for (int i = 0; i < strs.length; i++) {
+ if (strs[i] != null && strs[i].length() != 0) {
+ flag = true;
+ } else {
+ flag = false;
+ break;
+ }
+ }
+ }
+ return flag;
+ }
// 测试
public static void main(String[] args) {
diff --git "a/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md" "b/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md"
index f3696d2cd38..2632a9e2183 100644
--- "a/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md"
+++ "b/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md"
@@ -83,8 +83,8 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
### ArrayList 和 LinkedList 源码学习
-- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/ArrayList.md)
-- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/LinkedList.md)
+- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList.md)
+- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/LinkedList.md)
### 推荐阅读
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index ba5a5fa94b2..d8d31ada3b1 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -36,9 +36,13 @@
## 文字教程推荐
-[MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
+- [Github-MySQL入门教程(MySQL tutorial book)](https://github.com/jaywcjlove/mysql-tutorial) (从零开始学习MySQL,主要是面向MySQL数据库管理系统初学者)
+- [官方教程](https://dev.mysql.com/doc/refman/5.7/)
+- [MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
-[MySQL教程(易百教程)](https://www.yiibai.com/MySQL/)
+## 相关资源推荐
+
+- [中国5级行政区域mysql库](https://github.com/kakuilan/china_area_mysql)
## 视频教程推荐
@@ -95,7 +99,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
**两者的对比:**
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
5. ......
@@ -104,7 +108,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
> 不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
-一般情况下我们选择 InnoDB 都是没有问题的,但是某事情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
+一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
### 字符集及校对规则
@@ -160,14 +164,14 @@ select sql_no_cache count(*) from usr;
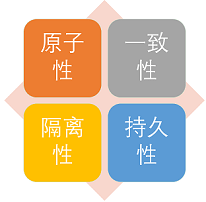
-1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **一致性:** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
-3. **隔离性:** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
-4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
### 并发事务带来哪些问题?
-在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
diff --git a/docs/database/Redis/Redis.md b/docs/database/Redis/Redis.md
index 559e0a5aae3..52efa5ad02c 100644
--- a/docs/database/Redis/Redis.md
+++ b/docs/database/Redis/Redis.md
@@ -54,6 +54,21 @@
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
+### redis 的线程模型
+
+> 参考地址:https://www.javazhiyin.com/22943.html
+
+redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
+
+文件事件处理器的结构包含 4 个部分:
+
+- 多个 socket
+- IO 多路复用程序
+- 文件事件分派器
+- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
+
+多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
+
### redis 和 memcached 的区别
diff --git "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
index 84a8631ab6f..eb4a501f008 100644
--- "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
+++ "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
@@ -38,7 +38,7 @@
#### 分组(packet ):
因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
#### 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查气首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
+ 路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
#### 带宽(bandwidth):
在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
#### 吞吐量(throughput ):
@@ -193,7 +193,7 @@
12,以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。
-13,使用集线器可以在物理层扩展以太网(扩展后的以太网任然是一个网络)
+13,使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)
### (3),最重要的知识点
#### ① 数据链路层的点对点信道和广播信道的特点,以及这两种信道所使用的协议(PPP协议以及CSMA/CD协议)的特点
#### ② 数据链路层的三个基本问题:**封装成帧**,**透明传输**,**差错检测**
diff --git a/docs/operating-system/Shell.md b/docs/operating-system/Shell.md
index 7ed6aad498f..e58f5c409e4 100644
--- a/docs/operating-system/Shell.md
+++ b/docs/operating-system/Shell.md
@@ -260,7 +260,7 @@ echo $length #输出:5
echo $length2 #输出:5
# 输出数组第三个元素
echo ${array[2]} #输出:3
-unset array[1]# 删除下表为1的元素也就是删除第二个元素
+unset array[1]# 删除下标为1的元素也就是删除第二个元素
for i in ${array[@]};do echo $i ;done # 遍历数组,输出: 1 3 4 5
unset arr_number; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
@@ -283,7 +283,7 @@ for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没
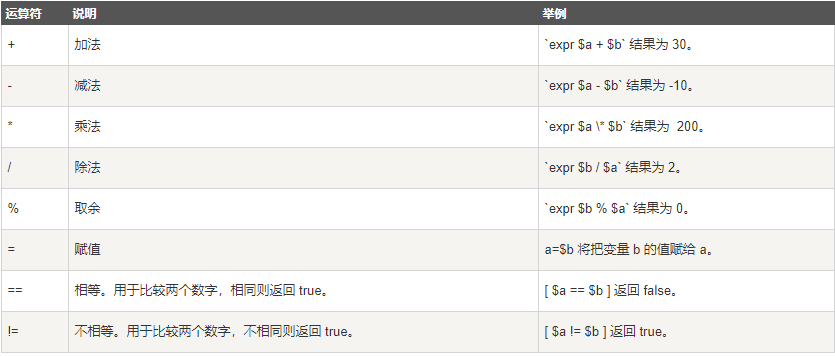
-我以加法运算符做一个简单的示例:
+我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
```shell
#!/bin/bash
diff --git "a/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 4272501eca7..199bfc9b35a 100644
--- "a/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -32,7 +32,7 @@
### 1.1 操作系统简介
-我通过以下四点介绍什么操作系统:
+我通过以下四点介绍什么是操作系统:
- **操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;**
- **操作系统本质上是运行在计算机上的软件程序 ;**
@@ -193,7 +193,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
f:指定文件名
-比如:加入test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
+比如:假如test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
**2)解压压缩包:**
diff --git a/docs/system-design/data-communication/rabbitmq.md b/docs/system-design/data-communication/rabbitmq.md
index 825f71239c6..28407cce610 100644
--- a/docs/system-design/data-communication/rabbitmq.md
+++ b/docs/system-design/data-communication/rabbitmq.md
@@ -123,7 +123,7 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
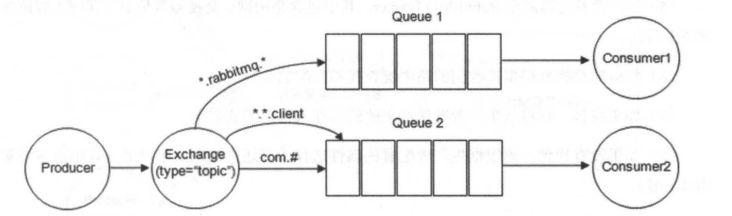
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
-- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“.”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
+- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
@@ -177,7 +177,7 @@ erlang 官网下载:[http://www.erlang.org/downloads](http://www.erlang.org/do
```shell
[root@SnailClimb local]#yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
-```
+```
**5 进入erlang 安装包解压文件对 erlang 进行安装环境的配置**
diff --git a/docs/system-design/framework/spring/SpringInterviewQuestions.md b/docs/system-design/framework/spring/SpringInterviewQuestions.md
index 9295681bfaa..3f97330b012 100644
--- a/docs/system-design/framework/spring/SpringInterviewQuestions.md
+++ b/docs/system-design/framework/spring/SpringInterviewQuestions.md
@@ -43,8 +43,8 @@ Spring 官网列出的 Spring 的 6 个特征:

- **Spring Core:** 基础,可以说 Spring 其他所有的功能都需要依赖于该类库。主要提供 IoC 依赖注入功能。
-- **Spring Aspects ** : 该模块为与AspectJ的集成提供支持。
-- **Spring AOP** :提供了面向方面的编程实现。
+- **Spring Aspects** : 该模块为与AspectJ的集成提供支持。
+- **Spring AOP** :提供了面向切面的编程实现。
- **Spring JDBC** : Java数据库连接。
- **Spring JMS** :Java消息服务。
- **Spring ORM** : 用于支持Hibernate等ORM工具。
@@ -227,7 +227,7 @@ public OneService getService(status) {
我们一般使用 `@Autowired` 注解自动装配 bean,要想把类标识成可用于 `@Autowired` 注解自动装配的 bean 的类,采用以下注解可实现:
-- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于拿个层,可以使用`@Component` 注解标注。
+- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于哪个层,可以使用`@Component` 注解标注。
- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao层。
- `@Controller` : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
diff --git a/docs/tools/Git.md b/docs/tools/Git.md
index e58f13b63aa..37e1f4465c7 100644
--- a/docs/tools/Git.md
+++ b/docs/tools/Git.md
@@ -112,7 +112,7 @@ Git 有三种状态,你的文件可能处于其中之一:
2. **已修改(modified)**:已修改表示修改了文件,但还没保存到数据库中。
3. **已暂存(staged)**:表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
-由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directoty) **、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
+由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directoty)**、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
@@ -339,4 +342,4 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
\ No newline at end of file
+
diff --git "a/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md" "b/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
index cd2a3e31e2b..8489082b2f3 100644
--- "a/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
+++ "b/docs/dataStructures-algorithms/\345\207\240\351\201\223\345\270\270\350\247\201\347\232\204\345\255\220\347\254\246\344\270\262\347\256\227\346\263\225\351\242\230.md"
@@ -135,17 +135,21 @@ public class Main {
}
- private static boolean checkStrs(String[] strs) {
- if (strs != null) {
- // 遍历strs检查元素值
- for (int i = 0; i < strs.length; i++) {
- if (strs[i] == null || strs[i].length() == 0) {
- return false;
- }
- }
- }
- return true;
- }
+ private static boolean chechStrs(String[] strs) {
+ boolean flag = false;
+ if (strs != null) {
+ // 遍历strs检查元素值
+ for (int i = 0; i < strs.length; i++) {
+ if (strs[i] != null && strs[i].length() != 0) {
+ flag = true;
+ } else {
+ flag = false;
+ break;
+ }
+ }
+ }
+ return flag;
+ }
// 测试
public static void main(String[] args) {
diff --git "a/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md" "b/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md"
index f3696d2cd38..2632a9e2183 100644
--- "a/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md"
+++ "b/docs/dataStructures-algorithms/\346\225\260\346\215\256\347\273\223\346\236\204.md"
@@ -83,8 +83,8 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
### ArrayList 和 LinkedList 源码学习
-- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/ArrayList.md)
-- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/LinkedList.md)
+- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList.md)
+- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/LinkedList.md)
### 推荐阅读
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index ba5a5fa94b2..d8d31ada3b1 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -36,9 +36,13 @@
## 文字教程推荐
-[MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
+- [Github-MySQL入门教程(MySQL tutorial book)](https://github.com/jaywcjlove/mysql-tutorial) (从零开始学习MySQL,主要是面向MySQL数据库管理系统初学者)
+- [官方教程](https://dev.mysql.com/doc/refman/5.7/)
+- [MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
-[MySQL教程(易百教程)](https://www.yiibai.com/MySQL/)
+## 相关资源推荐
+
+- [中国5级行政区域mysql库](https://github.com/kakuilan/china_area_mysql)
## 视频教程推荐
@@ -95,7 +99,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
**两者的对比:**
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
5. ......
@@ -104,7 +108,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
> 不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
-一般情况下我们选择 InnoDB 都是没有问题的,但是某事情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
+一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
### 字符集及校对规则
@@ -160,14 +164,14 @@ select sql_no_cache count(*) from usr;

-1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **一致性:** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
-3. **隔离性:** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
-4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
### 并发事务带来哪些问题?
-在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
diff --git a/docs/database/Redis/Redis.md b/docs/database/Redis/Redis.md
index 559e0a5aae3..52efa5ad02c 100644
--- a/docs/database/Redis/Redis.md
+++ b/docs/database/Redis/Redis.md
@@ -54,6 +54,21 @@
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
+### redis 的线程模型
+
+> 参考地址:https://www.javazhiyin.com/22943.html
+
+redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
+
+文件事件处理器的结构包含 4 个部分:
+
+- 多个 socket
+- IO 多路复用程序
+- 文件事件分派器
+- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
+
+多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
+
### redis 和 memcached 的区别
diff --git "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
index 84a8631ab6f..eb4a501f008 100644
--- "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
+++ "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
@@ -38,7 +38,7 @@
#### 分组(packet ):
因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
#### 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查气首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
+ 路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
#### 带宽(bandwidth):
在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
#### 吞吐量(throughput ):
@@ -193,7 +193,7 @@
12,以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。
-13,使用集线器可以在物理层扩展以太网(扩展后的以太网任然是一个网络)
+13,使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)
### (3),最重要的知识点
#### ① 数据链路层的点对点信道和广播信道的特点,以及这两种信道所使用的协议(PPP协议以及CSMA/CD协议)的特点
#### ② 数据链路层的三个基本问题:**封装成帧**,**透明传输**,**差错检测**
diff --git a/docs/operating-system/Shell.md b/docs/operating-system/Shell.md
index 7ed6aad498f..e58f5c409e4 100644
--- a/docs/operating-system/Shell.md
+++ b/docs/operating-system/Shell.md
@@ -260,7 +260,7 @@ echo $length #输出:5
echo $length2 #输出:5
# 输出数组第三个元素
echo ${array[2]} #输出:3
-unset array[1]# 删除下表为1的元素也就是删除第二个元素
+unset array[1]# 删除下标为1的元素也就是删除第二个元素
for i in ${array[@]};do echo $i ;done # 遍历数组,输出: 1 3 4 5
unset arr_number; # 删除数组中的所有元素
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
@@ -283,7 +283,7 @@ for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没

-我以加法运算符做一个简单的示例:
+我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
```shell
#!/bin/bash
diff --git "a/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md" "b/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
index 4272501eca7..199bfc9b35a 100644
--- "a/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
+++ "b/docs/operating-system/\345\220\216\347\253\257\347\250\213\345\272\217\345\221\230\345\277\205\345\244\207\347\232\204Linux\345\237\272\347\241\200\347\237\245\350\257\206.md"
@@ -32,7 +32,7 @@
### 1.1 操作系统简介
-我通过以下四点介绍什么操作系统:
+我通过以下四点介绍什么是操作系统:
- **操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;**
- **操作系统本质上是运行在计算机上的软件程序 ;**
@@ -193,7 +193,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
f:指定文件名
-比如:加入test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
+比如:假如test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
**2)解压压缩包:**
diff --git a/docs/system-design/data-communication/rabbitmq.md b/docs/system-design/data-communication/rabbitmq.md
index 825f71239c6..28407cce610 100644
--- a/docs/system-design/data-communication/rabbitmq.md
+++ b/docs/system-design/data-communication/rabbitmq.md
@@ -123,7 +123,7 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
-- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“.”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
+- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。

@@ -177,7 +177,7 @@ erlang 官网下载:[http://www.erlang.org/downloads](http://www.erlang.org/do
```shell
[root@SnailClimb local]#yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
-```
+```
**5 进入erlang 安装包解压文件对 erlang 进行安装环境的配置**
diff --git a/docs/system-design/framework/spring/SpringInterviewQuestions.md b/docs/system-design/framework/spring/SpringInterviewQuestions.md
index 9295681bfaa..3f97330b012 100644
--- a/docs/system-design/framework/spring/SpringInterviewQuestions.md
+++ b/docs/system-design/framework/spring/SpringInterviewQuestions.md
@@ -43,8 +43,8 @@ Spring 官网列出的 Spring 的 6 个特征:

- **Spring Core:** 基础,可以说 Spring 其他所有的功能都需要依赖于该类库。主要提供 IoC 依赖注入功能。
-- **Spring Aspects ** : 该模块为与AspectJ的集成提供支持。
-- **Spring AOP** :提供了面向方面的编程实现。
+- **Spring Aspects** : 该模块为与AspectJ的集成提供支持。
+- **Spring AOP** :提供了面向切面的编程实现。
- **Spring JDBC** : Java数据库连接。
- **Spring JMS** :Java消息服务。
- **Spring ORM** : 用于支持Hibernate等ORM工具。
@@ -227,7 +227,7 @@ public OneService getService(status) {
我们一般使用 `@Autowired` 注解自动装配 bean,要想把类标识成可用于 `@Autowired` 注解自动装配的 bean 的类,采用以下注解可实现:
-- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于拿个层,可以使用`@Component` 注解标注。
+- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于哪个层,可以使用`@Component` 注解标注。
- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao层。
- `@Controller` : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
diff --git a/docs/tools/Git.md b/docs/tools/Git.md
index e58f13b63aa..37e1f4465c7 100644
--- a/docs/tools/Git.md
+++ b/docs/tools/Git.md
@@ -112,7 +112,7 @@ Git 有三种状态,你的文件可能处于其中之一:
2. **已修改(modified)**:已修改表示修改了文件,但还没保存到数据库中。
3. **已暂存(staged)**:表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
-由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directoty) **、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
+由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directoty)**、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
