---
title: Spring和Spring Boot常见面试题总结
category: 系统设计
tag:
- 常见框架
head:
- - meta
- name: keywords
content: Spring面试题,Spring Boot面试题,Spring IoC,依赖注入,Spring AOP,Spring MVC 工作原理,Spring 事务传播行为,Spring 循环依赖,Spring Bean 生命周期,Spring Security 权限控制,Java 面试指南,JavaGuide
- - meta
- name: description
content: 本文系统梳理 Spring 和 Spring Boot 常见面试题与高频知识点,包括 IoC 与依赖注入原理、Bean 的作用域与生命周期、AOP 核心概念及通知类型、Spring MVC 核心组件和请求处理流程、事务传播行为与隔离级别、循环依赖及三级缓存、@Transactional 回滚规则、Spring Security 权限控制与密码加密、Spring Boot 自动配置和配置文件加载优先级等,适合作为 Java 后端面试突击与复习笔记。
---
------

------
## 前言
由于很多读者都有突击面试的需求,所以我在几年前就弄了 **JavaGuide 面试突击版本**(JavaGuide 内容精简版,只保留重点),并持续完善跟进。对于喜欢纸质阅读的朋友来说,也可以打印出来,整体阅读体验非常高!
除了只保留最常问的面试题之外,我还进一步对重点中的重点进行了⭐️标注。并且,有亮色(白天)和暗色(夜间)两个主题选择,需要打印出来的朋友记得选择亮色版本。
对于时间比较充裕的朋友,我个人还是更推荐 [JavaGuide](https://javaguide.cn/) 网站系统学习,内容更全面,更深入。
JavaGuide 已经持续维护 6 年多了,累计提交了接近 **6000** commit ,共有 **570+** 多位贡献者共同参与维护和完善。用心做原创优质内容,如果觉得有帮助的话,欢迎点赞分享!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
对于需要更进一步面试辅导服务的读者,欢迎加入 **[JavaGuide 官方知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)**(技术专栏/一对一提问/简历修改/求职指南/面试打卡),绝对物超所值!
面试突击最新版本可以在我的公众号回复“**PDF**”获取([JavaGuide 官方知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)会提前同步最新版,针对球友的一个小福利)。

这部分内容摘自 [JavaGuide](https://javaguide.cn/) 下面几篇文章中的重点:
- [Spring 常见面试题总结](https://javaguide.cn/system-design/framework/spring/spring-knowledge-and-questions-summary.html)(Spring 基础、IoC、AOP、MVC、事务、循环依赖等)
- [SpringBoot 常见面试题总结](https://javaguide.cn/system-design/framework/spring/springboot-knowledge-and-questions-summary.html)
- [Spring&SpringBoot常用注解总结](https://javaguide.cn/system-design/framework/spring/spring-common-annotations.html)
- [IoC & AOP详解(快速搞懂)](https://javaguide.cn/system-design/framework/spring/ioc-and-aop.html)
- [Spring 事务详解](https://javaguide.cn/system-design/framework/spring/spring-transaction.html)
- [Spring 中的设计模式详解](https://javaguide.cn/system-design/framework/spring/spring-design-patterns-summary.html)
- [SpringBoot 自动装配原理详解](https://javaguide.cn/system-design/framework/spring/spring-boot-auto-assembly-principles.html)
- [Async 注解原理分析](https://javaguide.cn/system-design/framework/spring/async.html)
## Spring IoC
### ⭐️什么是 IoC?
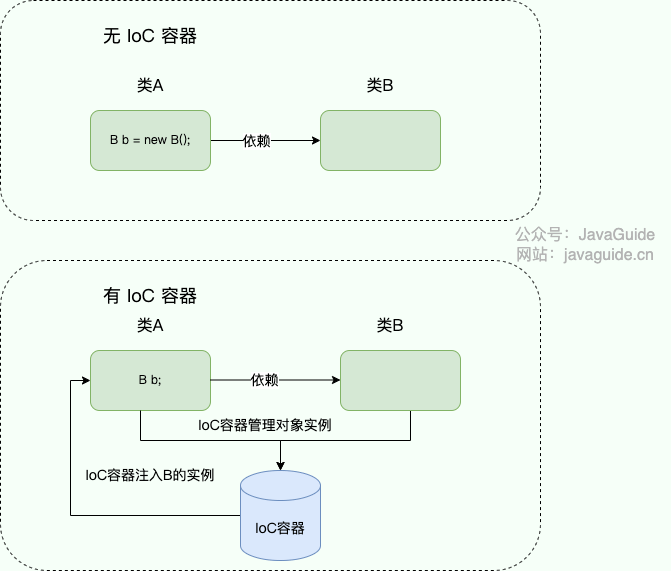
IoC (Inversion of Control )即控制反转/反转控制。它是一种思想不是一个技术实现。描述的是:Java 开发领域对象的创建以及管理的问题。
例如:现有类 A 依赖于类 B
- **传统的开发方式** :往往是在类 A 中手动通过 new 关键字来 new 一个 B 的对象出来
- **使用 IoC 思想的开发方式** :不通过 new 关键字来创建对象,而是通过 IoC 容器(Spring 框架) 来帮助我们实例化对象。我们需要哪个对象,直接从 IoC 容器里面去取即可。
从以上两种开发方式的对比来看:我们 “丧失了一个权力” (创建、管理对象的权力),从而也得到了一个好处(不用再考虑对象的创建、管理等一系列的事情)
**为什么叫控制反转?**
- **控制** :指的是对象创建(实例化、管理)的权力
- **反转** :控制权交给外部环境(IoC 容器)
### ⭐️IoC 解决了什么问题?
IoC 的思想就是两方之间不互相依赖,由第三方容器来管理相关资源。这样有什么好处呢?
1. 对象之间的耦合度或者说依赖程度降低;
2. 资源变的容易管理;比如你用 Spring 容器提供的话很容易就可以实现一个单例。
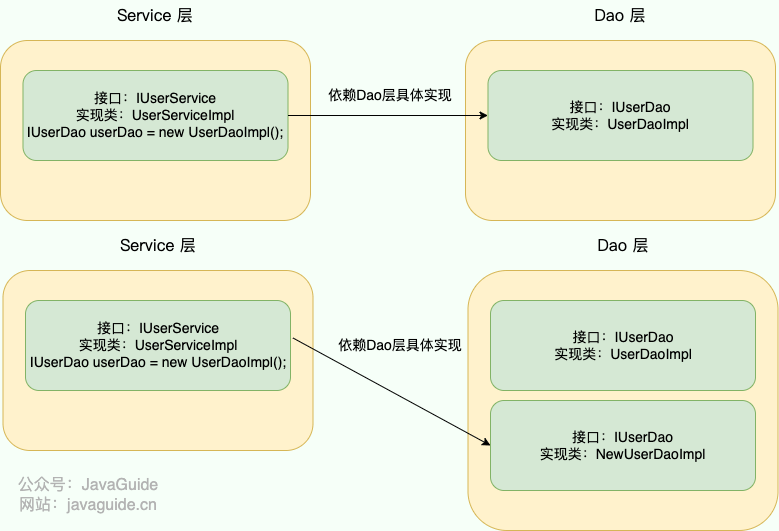
例如:现有一个针对 User 的操作,利用 Service 和 Dao 两层结构进行开发
在没有使用 IoC 思想的情况下,Service 层想要使用 Dao 层的具体实现的话,需要通过 new 关键字在`UserServiceImpl` 中手动 new 出 `IUserDao` 的具体实现类 `UserDaoImpl`(不能直接 new 接口类)。
很完美,这种方式也是可以实现的,但是我们想象一下如下场景:
开发过程中突然接到一个新的需求,针对`IUserDao` 接口开发出另一个具体实现类。因为 Server 层依赖了`IUserDao`的具体实现,所以我们需要修改`UserServiceImpl`中 new 的对象。如果只有一个类引用了`IUserDao`的具体实现,可能觉得还好,修改起来也不是很费力气,但是如果有许许多多的地方都引用了`IUserDao`的具体实现的话,一旦需要更换`IUserDao` 的实现方式,那修改起来将会非常的头疼。
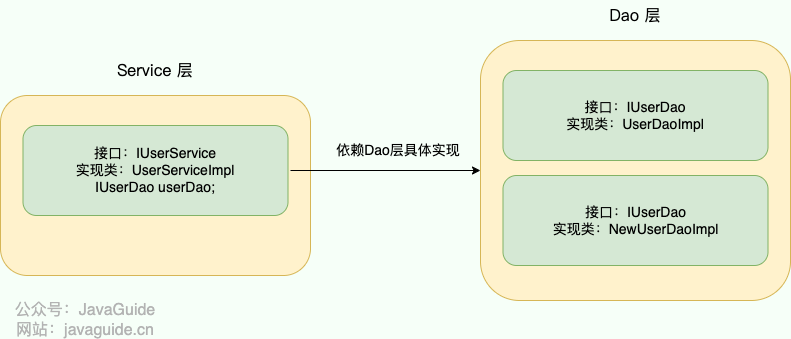
使用 IoC 的思想,我们将对象的控制权(创建、管理)交由 IoC 容器去管理,我们在使用的时候直接向 IoC 容器 “要” 就可以了
### 什么是 Spring Bean?
简单来说,Bean 代指的就是那些被 IoC 容器所管理的对象。
我们需要告诉 IoC 容器帮助我们管理哪些对象,这个是通过配置元数据来定义的。配置元数据可以是 XML 文件、注解或者 Java 配置类。
```xml
```
下图简单地展示了 IoC 容器如何使用配置元数据来管理对象。
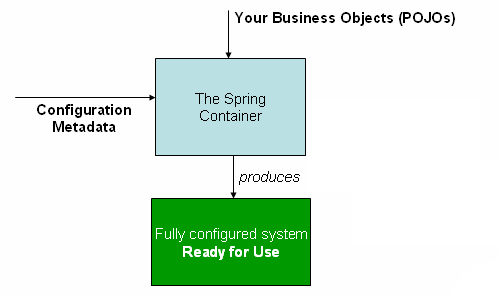
`org.springframework.beans`和 `org.springframework.context` 这两个包是 IoC 实现的基础,如果想要研究 IoC 相关的源码的话,可以去看看
### 将一个类声明为 Bean 的注解有哪些?
- `@Component`:通用的注解,可标注任意类为 `Spring` 组件。如果一个 Bean 不知道属于哪个层,可以使用`@Component` 注解标注。
- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。
- `@Controller` : 对应 Spring MVC 控制层,主要用于接受用户请求并调用 `Service` 层返回数据给前端页面。
### @Component 和 @Bean 的区别是什么?
- `@Component` 注解作用于类,而`@Bean`注解作用于方法。
- `@Component`通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用 `@ComponentScan` 注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。`@Bean` 注解通常是我们在标有该注解的方法中定义产生这个 bean,`@Bean`告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。
- `@Bean` 注解比 `@Component` 注解的自定义性更强,而且很多地方我们只能通过 `@Bean` 注解来注册 bean。比如当我们引用第三方库中的类需要装配到 `Spring`容器时,则只能通过 `@Bean`来实现。
`@Bean`注解使用示例:
```java
@Configuration
public class AppConfig {
@Bean
public TransferService transferService() {
return new TransferServiceImpl();
}
}
```
上面的代码相当于下面的 xml 配置
```xml
```
下面这个例子是通过 `@Component` 无法实现的。
```java
@Bean
public OneService getService(status) {
case (status) {
when 1:
return new serviceImpl1();
when 2:
return new serviceImpl2();
when 3:
return new serviceImpl3();
}
}
```
### 注入 Bean 的注解有哪些?
Spring 内置的 `@Autowired` 以及 JDK 内置的 `@Resource` 和 `@Inject` 都可以用于注入 Bean。
| Annotation | Package | Source |
| ------------ | ---------------------------------- | ------------ |
| `@Autowired` | `org.springframework.bean.factory` | Spring 2.5+ |
| `@Resource` | `javax.annotation` | Java JSR-250 |
| `@Inject` | `javax.inject` | Java JSR-330 |
`@Autowired` 和`@Resource`使用的比较多一些。
### ⭐️@Autowired 和 @Resource 的区别是什么?
`@Autowired` 是 Spring 内置的注解,默认注入逻辑为**先按类型(byType)匹配,若存在多个同类型 Bean,则再尝试按名称(byName)筛选**。
具体来说:
1. 优先根据接口 / 类的类型在 Spring 容器中查找匹配的 Bean。若只找到一个符合类型的 Bean,直接注入,无需考虑名称;
2. 若找到多个同类型的 Bean(例如一个接口有多个实现类),则会尝试通过**属性名或参数名**与 Bean 的名称进行匹配(默认 Bean 名称为类名首字母小写,除非通过 `@Bean(name = "...")` 或 `@Component("...")` 显式指定)。
当一个接口存在多个实现类时:
- 若属性名与某个 Bean 的名称一致,则注入该 Bean;
- 若属性名与所有 Bean 名称都不匹配,会抛出 `NoUniqueBeanDefinitionException`,此时需要通过 `@Qualifier` 显式指定要注入的 Bean 名称。
举例说明:
```java
// SmsService 接口有两个实现类:SmsServiceImpl1、SmsServiceImpl2(均被 Spring 管理)
// 报错:byType 匹配到多个 Bean,且属性名 "smsService" 与两个实现类的默认名称(smsServiceImpl1、smsServiceImpl2)都不匹配
@Autowired
private SmsService smsService;
// 正确:属性名 "smsServiceImpl1" 与实现类 SmsServiceImpl1 的默认名称匹配
@Autowired
private SmsService smsServiceImpl1;
// 正确:通过 @Qualifier 显式指定 Bean 名称 "smsServiceImpl1"
@Autowired
@Qualifier(value = "smsServiceImpl1")
private SmsService smsService;
```
实际开发实践中,我们还是建议通过 `@Qualifier` 注解来显式指定名称而不是依赖变量的名称。
`@Resource`属于 JDK 提供的注解,默认注入逻辑为**先按名称(byName)匹配,若存在多个同类型 Bean,则再尝试按类型(byType)筛选**。
`@Resource` 有两个比较重要且日常开发常用的属性:`name`(名称)、`type`(类型)。
```java
public @interface Resource {
String name() default "";
Class type() default Object.class;
}
```
如果仅指定 `name` 属性则注入方式为`byName`,如果仅指定`type`属性则注入方式为`byType`,如果同时指定`name` 和`type`属性(不建议这么做)则注入方式为`byType`+`byName`。
```java
// 报错,byName 和 byType 都无法匹配到 bean
@Resource
private SmsService smsService;
// 正确注入 SmsServiceImpl1 对象对应的 bean
@Resource
private SmsService smsServiceImpl1;
// 正确注入 SmsServiceImpl1 对象对应的 bean(比较推荐这种方式)
@Resource(name = "smsServiceImpl1")
private SmsService smsService;
```
**简单总结一下**:
- `@Autowired` 是 Spring 提供的注解,`@Resource` 是 JDK 提供的注解。
- `Autowired` 默认的注入方式为`byType`(根据类型进行匹配),`@Resource`默认注入方式为 `byName`(根据名称进行匹配)。
- 当一个接口存在多个实现类的情况下,`@Autowired` 和`@Resource`都需要通过名称才能正确匹配到对应的 Bean。`Autowired` 可以通过 `@Qualifier` 注解来显式指定名称,`@Resource`可以通过 `name` 属性来显式指定名称。
- `@Autowired` 支持在构造函数、方法、字段和参数上使用。`@Resource` 主要用于字段和方法上的注入,不支持在构造函数或参数上使用。
考虑到 `@Resource` 的语义更清晰(名称优先),并且是 Java 标准,能减少对 Spring 框架的强耦合,我们通常**更推荐使用 `@Resource`**,尤其是在需要按名称注入的场景下。而 `@Autowired` 配合构造器注入,在实现依赖注入的不可变性和强制性方面有优势,也是一种非常好的实践。
### 注入 Bean 的方式有哪些?
依赖注入 (Dependency Injection, DI) 的常见方式:
1. 构造函数注入:通过类的构造函数来注入依赖项。
1. Setter 注入:通过类的 Setter 方法来注入依赖项。
1. Field(字段) 注入:直接在类的字段上使用注解(如 `@Autowired` 或 `@Resource`)来注入依赖项。
构造函数注入示例:
```java
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
//...
}
```
Setter 注入示例:
```java
@Service
public class UserService {
private UserRepository userRepository;
// 在 Spring 4.3 及以后的版本,特定情况下 @Autowired 可以省略不写
@Autowired
public void setUserRepository(UserRepository userRepository) {
this.userRepository = userRepository;
}
//...
}
```
Field 注入示例:
```java
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
//...
}
```
### ⭐️构造函数注入还是 Setter 注入?
Spring 官方有对这个问题的回答:。
我这里主要提取总结完善一下 Spring 官方的建议。
**Spring 官方推荐构造函数注入**,这种注入方式的优势如下:
1. 依赖完整性:确保所有必需依赖在对象创建时就被注入,避免了空指针异常的风险。
2. 不可变性:有助于创建不可变对象,提高了线程安全性。
3. 初始化保证:组件在使用前已完全初始化,减少了潜在的错误。
4. 测试便利性:在单元测试中,可以直接通过构造函数传入模拟的依赖项,而不必依赖 Spring 容器进行注入。
构造函数注入适合处理**必需的依赖项**,而 **Setter 注入** 则更适合**可选的依赖项**,这些依赖项可以有默认值或在对象生命周期中动态设置。虽然 `@Autowired` 可以用于 Setter 方法来处理必需的依赖项,但构造函数注入仍然是更好的选择。
在某些情况下(例如第三方类不提供 Setter 方法),构造函数注入可能是**唯一的选择**。
### ⭐️Bean 的作用域有哪些?
Spring 中 Bean 的作用域通常有下面几种:
- **singleton** : IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
- **prototype** : 每次获取都会创建一个新的 bean 实例。也就是说,连续 `getBean()` 两次,得到的是不同的 Bean 实例。
- **request** (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
- **session** (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
- **application/global-session** (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
- **websocket** (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
**如何配置 bean 的作用域呢?**
xml 方式:
```xml
```
注解方式:
```java
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
```
### ⭐️Bean 是线程安全的吗?
Spring 框架中的 Bean 是否线程安全,取决于其作用域和状态。
我们这里以最常用的两种作用域 prototype 和 singleton 为例介绍。几乎所有场景的 Bean 作用域都是使用默认的 singleton ,重点关注 singleton 作用域即可。
prototype 作用域下,每次获取都会创建一个新的 bean 实例,不存在资源竞争问题,所以不存在线程安全问题。singleton 作用域下,IoC 容器中只有唯一的 bean 实例,可能会存在资源竞争问题(取决于 Bean 是否有状态)。如果这个 bean 是有状态的话,那就存在线程安全问题(有状态 Bean 是指包含可变的成员变量的对象)。
有状态 Bean 示例:
```java
// 定义了一个购物车类,其中包含一个保存用户的购物车里商品的 List
@Component
public class ShoppingCart {
private List items = new ArrayList<>();
public void addItem(String item) {
items.add(item);
}
public List getItems() {
return items;
}
}
```
不过,大部分 Bean 实际都是无状态(没有定义可变的成员变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
无状态 Bean 示例:
```java
// 定义了一个用户服务,它仅包含业务逻辑而不保存任何状态。
@Component
public class UserService {
public User findUserById(Long id) {
//...
}
//...
}
```
对于有状态单例 Bean 的线程安全问题,常见的三种解决办法是:
1. **避免可变成员变量**: 尽量设计 Bean 为无状态。
2. **使用`ThreadLocal`**: 将可变成员变量保存在 `ThreadLocal` 中,确保线程独立。
3. **使用同步机制**: 利用 `synchronized` 或 `ReentrantLock` 来进行同步控制,确保线程安全。
这里以 `ThreadLocal`为例,演示一下`ThreadLocal` 保存用户登录信息的场景:
```java
public class UserThreadLocal {
private UserThreadLocal() {}
private static final ThreadLocal LOCAL = ThreadLocal.withInitial(() -> null);
public static void put(SysUser sysUser) {
LOCAL.set(sysUser);
}
public static SysUser get() {
return LOCAL.get();
}
public static void remove() {
LOCAL.remove();
}
}
```
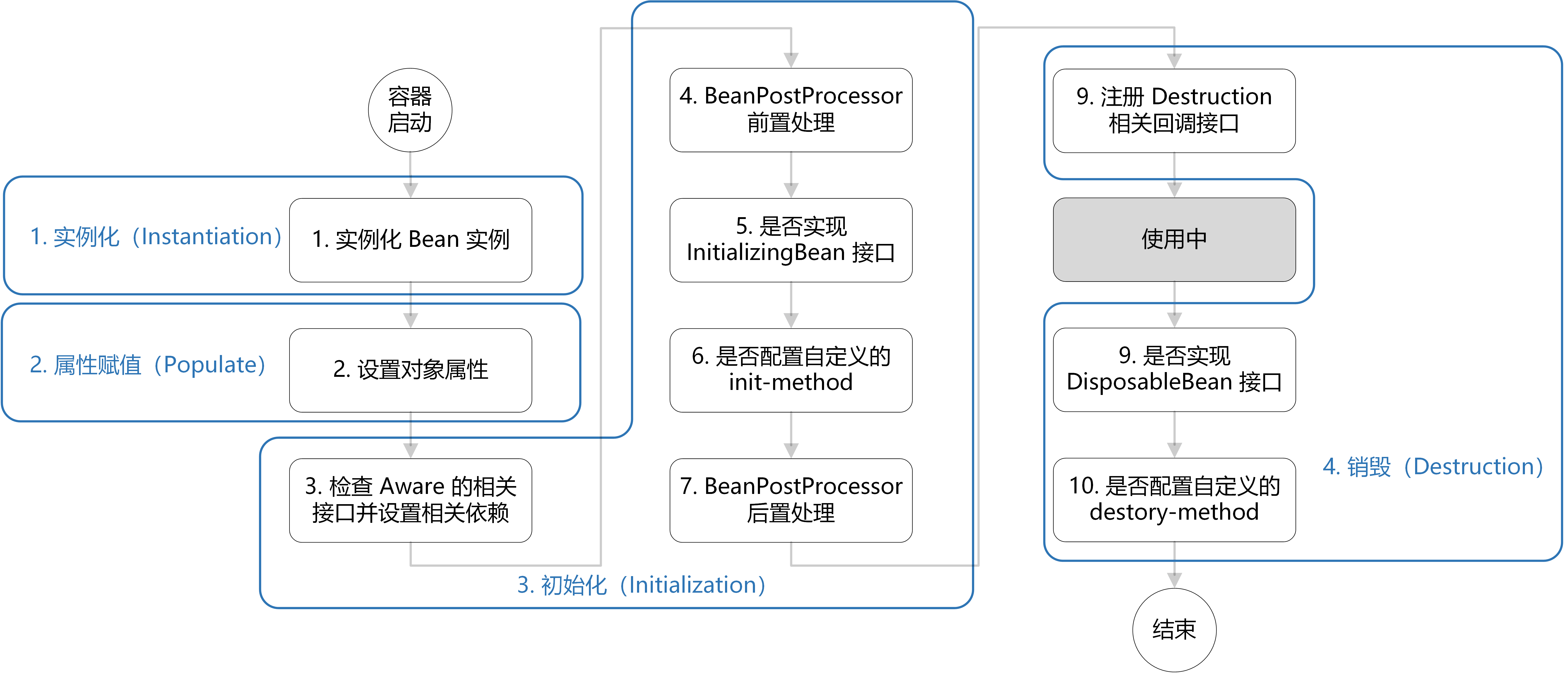
### ⭐️Bean 的生命周期了解么?
1. **创建 Bean 的实例**:Bean 容器首先会找到配置文件中的 Bean 定义,然后使用 Java 反射 API 来创建 Bean 的实例。
2. **Bean 属性赋值/填充**:为 Bean 设置相关属性和依赖,例如`@Autowired` 等注解注入的对象、`@Value` 注入的值、`setter`方法或构造函数注入依赖和值、`@Resource`注入的各种资源。
3. **Bean 初始化**:
- 如果 Bean 实现了 `BeanNameAware` 接口,调用 `setBeanName()`方法,传入 Bean 的名字。
- 如果 Bean 实现了 `BeanClassLoaderAware` 接口,调用 `setBeanClassLoader()`方法,传入 `ClassLoader`对象的实例。
- 如果 Bean 实现了 `BeanFactoryAware` 接口,调用 `setBeanFactory()`方法,传入 `BeanFactory`对象的实例。
- 与上面的类似,如果实现了其他 `*.Aware`接口,就调用相应的方法。
- 如果有和加载这个 Bean 的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessBeforeInitialization()` 方法
- 如果 Bean 实现了`InitializingBean`接口,执行`afterPropertiesSet()`方法。
- 如果 Bean 在配置文件中的定义包含 `init-method` 属性,执行指定的方法。
- 如果有和加载这个 Bean 的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessAfterInitialization()` 方法。
4. **销毁 Bean**:销毁并不是说要立马把 Bean 给销毁掉,而是把 Bean 的销毁方法先记录下来,将来需要销毁 Bean 或者销毁容器的时候,就调用这些方法去释放 Bean 所持有的资源。
- 如果 Bean 实现了 `DisposableBean` 接口,执行 `destroy()` 方法。
- 如果 Bean 在配置文件中的定义包含 `destroy-method` 属性,执行指定的 Bean 销毁方法。或者,也可以直接通过`@PreDestroy` 注解标记 Bean 销毁之前执行的方法。
`AbstractAutowireCapableBeanFactory` 的 `doCreateBean()` 方法中能看到依次执行了这 4 个阶段:
```java
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 1. 创建 Bean 的实例
BeanWrapper instanceWrapper = null;
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object exposedObject = bean;
try {
// 2. Bean 属性赋值/填充
populateBean(beanName, mbd, instanceWrapper);
// 3. Bean 初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
// 4. 销毁 Bean-注册回调接口
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
return exposedObject;
}
```
`Aware` 接口能让 Bean 能拿到 Spring 容器资源。
Spring 中提供的 `Aware` 接口主要有:
1. `BeanNameAware`:注入当前 bean 对应 beanName;
2. `BeanClassLoaderAware`:注入加载当前 bean 的 ClassLoader;
3. `BeanFactoryAware`:注入当前 `BeanFactory` 容器的引用。
`BeanPostProcessor` 接口是 Spring 为修改 Bean 提供的强大扩展点。
```java
public interface BeanPostProcessor {
// 初始化前置处理
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
// 初始化后置处理
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
```
- `postProcessBeforeInitialization`:Bean 实例化、属性注入完成后,`InitializingBean#afterPropertiesSet`方法以及自定义的 `init-method` 方法之前执行;
- `postProcessAfterInitialization`:类似于上面,不过是在 `InitializingBean#afterPropertiesSet`方法以及自定义的 `init-method` 方法之后执行。
`InitializingBean` 和 `init-method` 是 Spring 为 Bean 初始化提供的扩展点。
```java
public interface InitializingBean {
// 初始化逻辑
void afterPropertiesSet() throws Exception;
}
```
指定 `init-method` 方法,指定初始化方法:
```xml
```
**如何记忆呢?**
1. 整体上可以简单分为四步:实例化 —> 属性赋值 —> 初始化 —> 销毁。
2. 初始化这一步涉及到的步骤比较多,包含 `Aware` 接口的依赖注入、`BeanPostProcessor` 在初始化前后的处理以及 `InitializingBean` 和 `init-method` 的初始化操作。
3. 销毁这一步会注册相关销毁回调接口,最后通过`DisposableBean` 和 `destory-method` 进行销毁。
最后,再分享一张清晰的图解(图源:[如何记忆 Spring Bean 的生命周期](https://chaycao.github.io/2020/02/15/如何记忆Spring-Bean的生命周期.html))。
## Spring AOP
### ⭐️谈谈自己对于 AOP 的了解
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 **JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
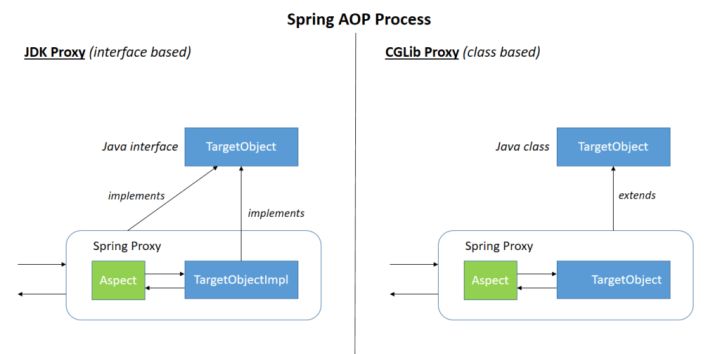
当然你也可以使用 **AspectJ** !Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
AOP 切面编程涉及到的一些专业术语:
| 术语 | 含义 |
| :---------------- | :----------------------------------------------------------: |
| 目标(Target) | 被通知的对象 |
| 代理(Proxy) | 向目标对象应用通知之后创建的代理对象 |
| 连接点(JoinPoint) | 目标对象的所属类中,定义的所有方法均为连接点 |
| 切入点(Pointcut) | 被切面拦截 / 增强的连接点(切入点一定是连接点,连接点不一定是切入点) |
| 通知(Advice) | 增强的逻辑 / 代码,也即拦截到目标对象的连接点之后要做的事情 |
| 切面(Aspect) | 切入点(Pointcut)+通知(Advice) |
| Weaving(织入) | 将通知应用到目标对象,进而生成代理对象的过程动作 |
### ⭐️Spring AOP 和 AspectJ AOP 有什么区别?
| 特性 | Spring AOP | AspectJ |
| -------------- | -------------------------------------------------------- | ------------------------------------------ |
| **增强方式** | 运行时增强(基于动态代理) | 编译时增强、类加载时增强(直接操作字节码) |
| **切入点支持** | 方法级(Spring Bean 范围内,不支持 final 和 staic 方法) | 方法级、字段、构造器、静态方法等 |
| **性能** | 运行时依赖代理,有一定开销,切面多时性能较低 | 运行时无代理开销,性能更高 |
| **复杂性** | 简单,易用,适合大多数场景 | 功能强大,但相对复杂 |
| **使用场景** | Spring 应用下比较简单的 AOP 需求 | 高性能、高复杂度的 AOP 需求 |
**如何选择?**
- **功能考量**:AspectJ 支持更复杂的 AOP 场景,Spring AOP 更简单易用。如果你需要增强 `final` 方法、静态方法、字段访问、构造器调用等,或者需要在非 Spring 管理的对象上应用增强逻辑,AspectJ 是唯一的选择。
- **性能考量**:切面数量较少时两者性能差异不大,但切面较多时 AspectJ 性能更优。
**一句话总结**:简单场景优先使用 Spring AOP;复杂场景或高性能需求时,选择 AspectJ。
### ⭐️AOP 常见的通知类型有哪些?
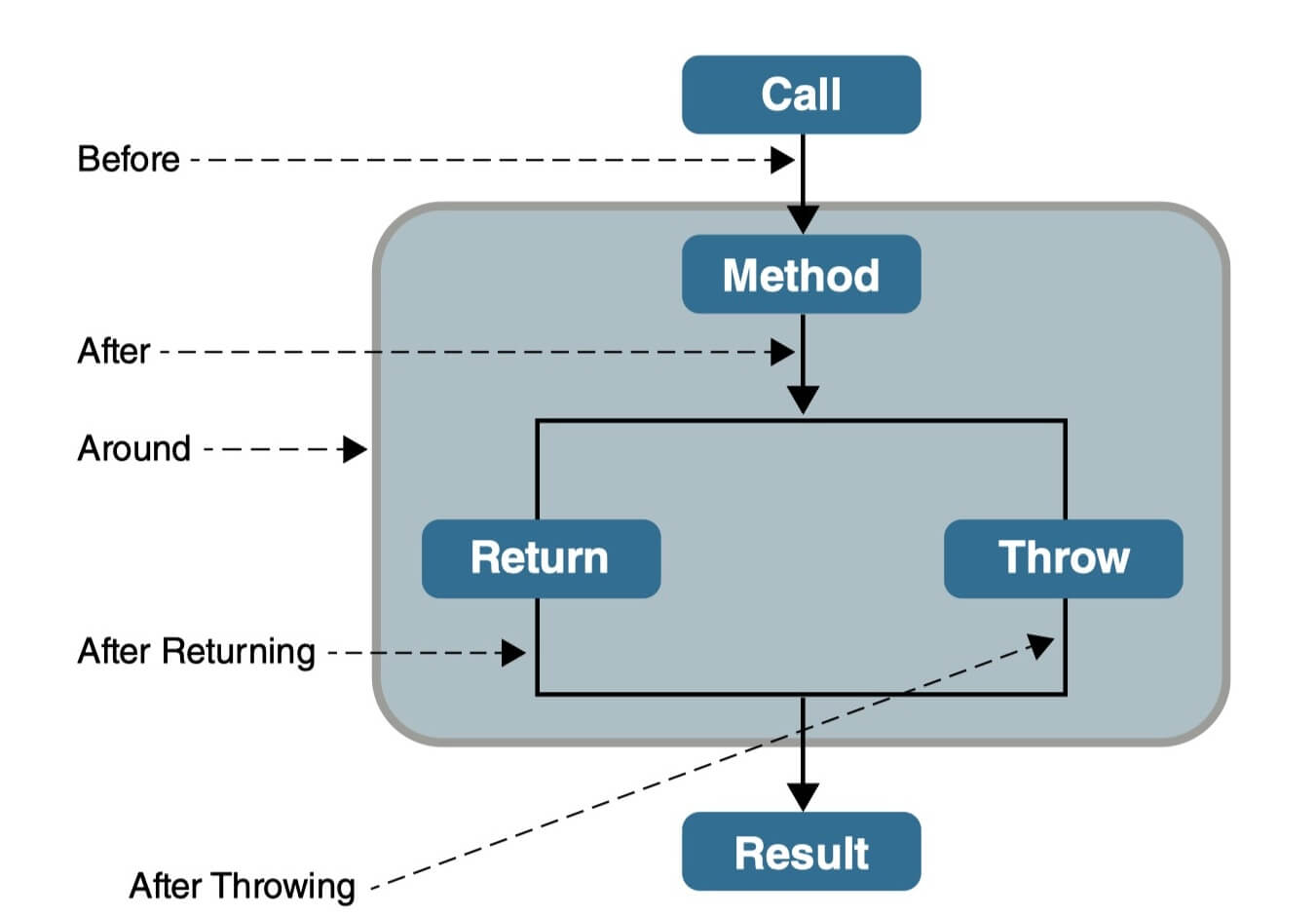
- **Before**(前置通知):目标对象的方法调用之前触发
- **After** (后置通知):目标对象的方法调用之后触发
- **AfterReturning**(返回通知):目标对象的方法调用完成,在返回结果值之后触发
- **AfterThrowing**(异常通知):目标对象的方法运行中抛出 / 触发异常后触发。AfterReturning 和 AfterThrowing 两者互斥。如果方法调用成功无异常,则会有返回值;如果方法抛出了异常,则不会有返回值。
- **Around** (环绕通知):编程式控制目标对象的方法调用。环绕通知是所有通知类型中可操作范围最大的一种,因为它可以直接拿到目标对象,以及要执行的方法,所以环绕通知可以任意的在目标对象的方法调用前后搞事,甚至不调用目标对象的方法
### 多个切面的执行顺序如何控制?
1、通常使用`@Order` 注解直接定义切面顺序
```java
// 值越小优先级越高
@Order(3)
@Component
@Aspect
public class LoggingAspect implements Ordered {
```
**2、实现`Ordered` 接口重写 `getOrder` 方法。**
```java
@Component
@Aspect
public class LoggingAspect implements Ordered {
// ....
@Override
public int getOrder() {
// 返回值越小优先级越高
return 1;
}
}
```
## Spring MVC
### 说说自己对于 Spring MVC 了解?
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。

网上有很多人说 MVC 不是设计模式,只是软件设计规范,我个人更倾向于 MVC 同样是众多设计模式中的一种。**[java-design-patterns](https://github.com/iluwatar/java-design-patterns)** 项目中就有关于 MVC 的相关介绍。
想要真正理解 Spring MVC,我们先来看看 Model 1 和 Model 2 这两个没有 Spring MVC 的时代。
**Model 1 时代**
很多学 Java 后端比较晚的朋友可能并没有接触过 Model 1 时代下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。
这个模式下 JSP 即是控制层(Controller)又是表现层(View)。显而易见,这种模式存在很多问题。比如控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;再比如前端和后端相互依赖,难以进行测试维护并且开发效率极低。
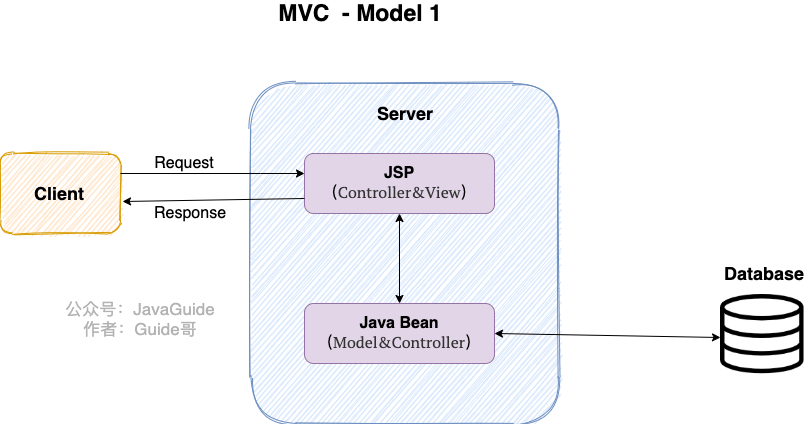
**Model 2 时代**
学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+ JSP(View)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。
- Model:系统涉及的数据,也就是 dao 和 bean。
- View:展示模型中的数据,只是用来展示。
- Controller:接受用户请求,并将请求发送至 Model,最后返回数据给 JSP 并展示给用户
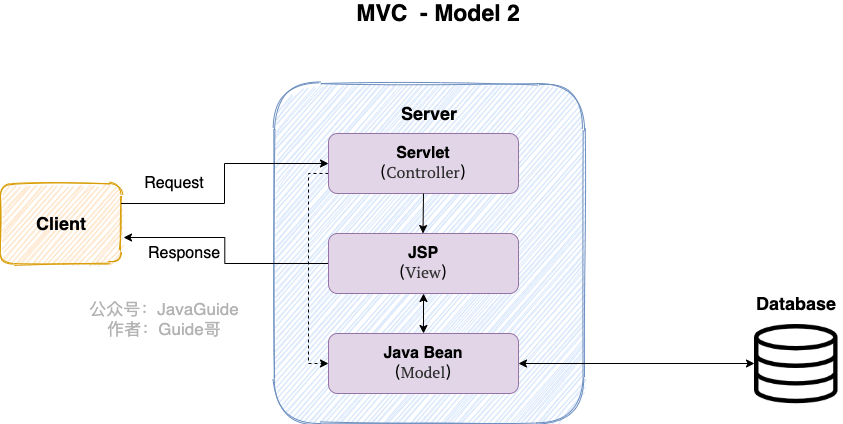
Model2 模式下还存在很多问题,Model2 的抽象和封装程度还远远不够,使用 Model2 进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和复用性。
于是,很多 JavaWeb 开发相关的 MVC 框架应运而生比如 Struts2,但是 Struts2 比较笨重。
**Spring MVC 时代**
随着 Spring 轻量级开发框架的流行,Spring 生态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相比于 Struts2 , Spring MVC 使用更加简单和方便,开发效率更高,并且 Spring MVC 运行速度更快。
MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring MVC 可以帮助我们进行更简洁的 Web 层的开发,并且它天生与 Spring 框架集成。Spring MVC 下我们一般把后端项目分为 Service 层(处理业务)、Dao 层(数据库操作)、Entity 层(实体类)、Controller 层(控制层,返回数据给前台页面)。
### Spring MVC 的核心组件有哪些?
记住了下面这些组件,也就记住了 SpringMVC 的工作原理。
- **`DispatcherServlet`**:**核心的中央处理器**,负责接收请求、分发,并给予客户端响应。
- **`HandlerMapping`**:**处理器映射器**,根据 URL 去匹配查找能处理的 `Handler` ,并会将请求涉及到的拦截器和 `Handler` 一起封装。
- **`HandlerAdapter`**:**处理器适配器**,根据 `HandlerMapping` 找到的 `Handler` ,适配执行对应的 `Handler`;
- **`Handler`**:**请求处理器**,处理实际请求的处理器。
- **`ViewResolver`**:**视图解析器**,根据 `Handler` 返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给 `DispatcherServlet` 响应客户端
### ⭐️SpringMVC 工作原理了解吗?
**Spring MVC 原理如下图所示:**
> SpringMVC 工作原理的图解我没有自己画,直接图省事在网上找了一个非常清晰直观的,原出处不明。

**流程说明(重要):**
1. 客户端(浏览器)发送请求, `DispatcherServlet`拦截请求。
2. `DispatcherServlet` 根据请求信息调用 `HandlerMapping` 。`HandlerMapping` 根据 URL 去匹配查找能处理的 `Handler`(也就是我们平常说的 `Controller` 控制器) ,并会将请求涉及到的拦截器和 `Handler` 一起封装。
3. `DispatcherServlet` 调用 `HandlerAdapter`适配器执行 `Handler` 。
4. `Handler` 完成对用户请求的处理后,会返回一个 `ModelAndView` 对象给`DispatcherServlet`,`ModelAndView` 顾名思义,包含了数据模型以及相应的视图的信息。`Model` 是返回的数据对象,`View` 是个逻辑上的 `View`。
5. `ViewResolver` 会根据逻辑 `View` 查找实际的 `View`。
6. `DispaterServlet` 把返回的 `Model` 传给 `View`(视图渲染)。
7. 把 `View` 返回给请求者(浏览器)
上述流程是传统开发模式(JSP,Thymeleaf 等)的工作原理。然而现在主流的开发方式是前后端分离,这种情况下 Spring MVC 的 `View` 概念发生了一些变化。由于 `View` 通常由前端框架(Vue, React 等)来处理,后端不再负责渲染页面,而是只负责提供数据,因此:
- 前后端分离时,后端通常不再返回具体的视图,而是返回**纯数据**(通常是 JSON 格式),由前端负责渲染和展示。
- `View` 的部分在前后端分离的场景下往往不需要设置,Spring MVC 的控制器方法只需要返回数据,不再返回 `ModelAndView`,而是直接返回数据,Spring 会自动将其转换为 JSON 格式。相应的,`ViewResolver` 也将不再被使用。
怎么做到呢?
- 使用 `@RestController` 注解代替传统的 `@Controller` 注解,这样所有方法默认会返回 JSON 格式的数据,而不是试图解析视图。
- 如果你使用的是 `@Controller`,可以结合 `@ResponseBody` 注解来返回 JSON。
### 统一异常处理怎么做?
推荐使用注解的方式统一异常处理,具体会使用到 `@ControllerAdvice` + `@ExceptionHandler` 这两个注解 。
```java
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
@ExceptionHandler(BaseException.class)
public ResponseEntity handleAppException(BaseException ex, HttpServletRequest request) {
//......
}
@ExceptionHandler(value = ResourceNotFoundException.class)
public ResponseEntity handleResourceNotFoundException(ResourceNotFoundException ex, HttpServletRequest request) {
//......
}
}
```
这种异常处理方式下,会给所有或者指定的 `Controller` 织入异常处理的逻辑(AOP),当 `Controller` 中的方法抛出异常的时候,由被`@ExceptionHandler` 注解修饰的方法进行处理。
`ExceptionHandlerMethodResolver` 中 `getMappedMethod` 方法决定了异常具体被哪个被 `@ExceptionHandler` 注解修饰的方法处理异常。
```java
@Nullable
private Method getMappedMethod(Class exceptionType) {
List> matches = new ArrayList<>();
//找到可以处理的所有异常信息。mappedMethods 中存放了异常和处理异常的方法的对应关系
for (Class mappedException : this.mappedMethods.keySet()) {
if (mappedException.isAssignableFrom(exceptionType)) {
matches.add(mappedException);
}
}
// 不为空说明有方法处理异常
if (!matches.isEmpty()) {
// 按照匹配程度从小到大排序
matches.sort(new ExceptionDepthComparator(exceptionType));
// 返回处理异常的方法
return this.mappedMethods.get(matches.get(0));
}
else {
return null;
}
}
```
从源代码看出:**`getMappedMethod()`会首先找到可以匹配处理异常的所有方法信息,然后对其进行从小到大的排序,最后取最小的那一个匹配的方法(即匹配度最高的那个)。**
## Spring 框架中用到了哪些设计模式?
> 关于下面这些设计模式的详细介绍,可以看我写的 [Spring 中的设计模式详解](https://javaguide.cn/system-design/framework/spring/spring-design-patterns-summary.html) 这篇文章。
- **工厂设计模式** : Spring 使用工厂模式通过 `BeanFactory`、`ApplicationContext` 创建 bean 对象。
- **代理设计模式** : Spring AOP 功能的实现。
- **单例设计模式** : Spring 中的 Bean 默认都是单例的。
- **模板方法模式** : Spring 中 `jdbcTemplate`、`hibernateTemplate` 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
- **适配器模式** : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
- ……
## ⭐️Spring 的循环依赖
### Spring 循环依赖了解吗,怎么解决?
循环依赖是指 Bean 对象循环引用,是两个或多个 Bean 之间相互持有对方的引用,例如 CircularDependencyA → CircularDependencyB → CircularDependencyA。
```java
@Component
public class CircularDependencyA {
@Autowired
private CircularDependencyB circB;
}
@Component
public class CircularDependencyB {
@Autowired
private CircularDependencyA circA;
}
```
单个对象的自我依赖也会出现循环依赖,但这种概率极低,属于是代码编写错误。
```java
@Component
public class CircularDependencyA {
@Autowired
private CircularDependencyA circA;
}
```
Spring 框架通过使用三级缓存来解决这个问题,确保即使在循环依赖的情况下也能正确创建 Bean。
Spring 中的三级缓存其实就是三个 Map,如下:
```java
// 一级缓存
/** Cache of singleton objects: bean name to bean instance. */
private final Map singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存
/** Cache of early singleton objects: bean name to bean instance. */
private final Map earlySingletonObjects = new HashMap<>(16);
// 三级缓存
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map> singletonFactories = new HashMap<>(16);
```
简单来说,Spring 的三级缓存包括:
1. **一级缓存(singletonObjects)**:存放最终形态的 Bean(已经实例化、属性填充、初始化),单例池,为“Spring 的单例属性”⽽⽣。一般情况我们获取 Bean 都是从这里获取的,但是并不是所有的 Bean 都在单例池里面,例如原型 Bean 就不在里面。
2. **二级缓存(earlySingletonObjects)**:存放过渡 Bean(半成品,尚未属性填充),也就是三级缓存中`ObjectFactory`产生的对象,与三级缓存配合使用的,可以防止 AOP 的情况下,每次调用`ObjectFactory#getObject()`都是会产生新的代理对象的。
3. **三级缓存(singletonFactories)**:存放`ObjectFactory`,`ObjectFactory`的`getObject()`方法(最终调用的是`getEarlyBeanReference()`方法)可以生成原始 Bean 对象或者代理对象(如果 Bean 被 AOP 切面代理)。三级缓存只会对单例 Bean 生效。
接下来说一下 Spring 创建 Bean 的流程:
1. 先去 **一级缓存 `singletonObjects`** 中获取,存在就返回;
2. 如果不存在或者对象正在创建中,于是去 **二级缓存 `earlySingletonObjects`** 中获取;
3. 如果还没有获取到,就去 **三级缓存 `singletonFactories`** 中获取,通过执行 `ObjectFacotry` 的 `getObject()` 就可以获取该对象,获取成功之后,从三级缓存移除,并将该对象加入到二级缓存中。
在三级缓存中存储的是 `ObjectFacoty` :
```java
public interface ObjectFactory {
T getObject() throws BeansException;
}
```
Spring 在创建 Bean 的时候,如果允许循环依赖的话,Spring 就会将刚刚实例化完成,但是属性还没有初始化完的 Bean 对象给提前暴露出去,这里通过 `addSingletonFactory` 方法,向三级缓存中添加一个 `ObjectFactory` 对象:
```java
// AbstractAutowireCapableBeanFactory # doCreateBean #
public abstract class AbstractAutowireCapableBeanFactory ... {
protected Object doCreateBean(...) {
//...
// 支撑循环依赖:将 ()->getEarlyBeanReference 作为一个 ObjectFactory 对象的 getObject() 方法加入到三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
}
```
那么上边在说 Spring 创建 Bean 的流程时说了,如果一级缓存、二级缓存都取不到对象时,会去三级缓存中通过 `ObjectFactory` 的 `getObject` 方法获取对象。
```java
class A {
// 使用了 B
private B b;
}
class B {
// 使用了 A
private A a;
}
```
以上面的循环依赖代码为例,整个解决循环依赖的流程如下:
- 当 Spring 创建 A 之后,发现 A 依赖了 B ,又去创建 B,B 依赖了 A ,又去创建 A;
- 在 B 创建 A 的时候,那么此时 A 就发生了循环依赖,由于 A 此时还没有初始化完成,因此在 **一二级缓存** 中肯定没有 A;
- 那么此时就去三级缓存中调用 `getObject()` 方法去获取 A 的 **前期暴露的对象** ,也就是调用上边加入的 `getEarlyBeanReference()` 方法,生成一个 A 的 **前期暴露对象**;
- 然后就将这个 `ObjectFactory` 从三级缓存中移除,并且将前期暴露对象放入到二级缓存中,那么 B 就将这个前期暴露对象注入到依赖,来支持循环依赖。
**只用两级缓存够吗?** 在没有 AOP 的情况下,确实可以只使用一级和二级缓存来解决循环依赖问题。但是,当涉及到 AOP 时,三级缓存就显得非常重要了,因为它确保了即使在 Bean 的创建过程中有多次对早期引用的请求,也始终只返回同一个代理对象,从而避免了同一个 Bean 有多个代理对象的问题。
**最后总结一下 Spring 如何解决三级缓存**:
在三级缓存这一块,主要记一下 Spring 是如何支持循环依赖的即可,也就是如果发生循环依赖的话,就去 **三级缓存 `singletonFactories`** 中拿到三级缓存中存储的 `ObjectFactory` 并调用它的 `getObject()` 方法来获取这个循环依赖对象的前期暴露对象(虽然还没初始化完成,但是可以拿到该对象在堆中的存储地址了),并且将这个前期暴露对象放到二级缓存中,这样在循环依赖时,就不会重复初始化了!
不过,这种机制也有一些缺点,比如增加了内存开销(需要维护三级缓存,也就是三个 Map),降低了性能(需要进行多次检查和转换)。并且,还有少部分情况是不支持循环依赖的,比如非单例的 bean 和`@Async`注解的 bean 无法支持循环依赖。
### @Lazy 能解决循环依赖吗?
`@Lazy` 用来标识类是否需要懒加载/延迟加载,可以作用在类上、方法上、构造器上、方法参数上、成员变量中。
Spring Boot 2.2 新增了**全局懒加载属性**,开启后全局 bean 被设置为懒加载,需要时再去创建。
配置文件配置全局懒加载:
```properties
#默认false
spring.main.lazy-initialization=true
```
编码的方式设置全局懒加载:
```java
SpringApplication springApplication=new SpringApplication(Start.class);
springApplication.setLazyInitialization(false);
springApplication.run(args);
```
如非必要,尽量不要用全局懒加载。全局懒加载会让 Bean 第一次使用的时候加载会变慢,并且它会延迟应用程序问题的发现(当 Bean 被初始化时,问题才会出现)。
如果一个 Bean 没有被标记为懒加载,那么它会在 Spring IoC 容器启动的过程中被创建和初始化。如果一个 Bean 被标记为懒加载,那么它不会在 Spring IoC 容器启动时立即实例化,而是在第一次被请求时才创建。这可以帮助减少应用启动时的初始化时间,也可以用来解决循环依赖问题。
循环依赖问题是如何通过`@Lazy` 解决的呢?这里举一个例子,比如说有两个 Bean,A 和 B,他们之间发生了循环依赖,那么 A 的构造器上添加 `@Lazy` 注解之后(延迟 Bean B 的实例化),加载的流程如下:
- 首先 Spring 会去创建 A 的 Bean,创建时需要注入 B 的属性;
- 由于在 A 上标注了 `@Lazy` 注解,因此 Spring 会去创建一个 B 的代理对象,将这个代理对象注入到 A 中的 B 属性;
- 之后开始执行 B 的实例化、初始化,在注入 B 中的 A 属性时,此时 A 已经创建完毕了,就可以将 A 给注入进去。
从上面的加载流程可以看出: `@Lazy` 解决循环依赖的关键点在于代理对象的使用。
- **没有 `@Lazy` 的情况下**:在 Spring 容器初始化 `A` 时会立即尝试创建 `B`,而在创建 `B` 的过程中又会尝试创建 `A`,最终导致循环依赖(即无限递归,最终抛出异常)。
- **使用 `@Lazy` 的情况下**:Spring 不会立即创建 `B`,而是会注入一个 `B` 的代理对象。由于此时 `B` 仍未被真正初始化,`A` 的初始化可以顺利完成。等到 `A` 实例实际调用 `B` 的方法时,代理对象才会触发 `B` 的真正初始化。
`@Lazy` 能够在一定程度上打破循环依赖链,允许 Spring 容器顺利地完成 Bean 的创建和注入。但这并不是一个根本性的解决方案,尤其是在构造函数注入、复杂的多级依赖等场景中,`@Lazy` 无法有效地解决问题。因此,最佳实践仍然是尽量避免设计上的循环依赖。
### SpringBoot 允许循环依赖发生么?
SpringBoot 2.6.x 以前是默认允许循环依赖的,也就是说你的代码出现了循环依赖问题,一般情况下也不会报错。SpringBoot 2.6.x 以后官方不再推荐编写存在循环依赖的代码,建议开发者自己写代码的时候去减少不必要的互相依赖。这其实也是我们最应该去做的,循环依赖本身就是一种设计缺陷,我们不应该过度依赖 Spring 而忽视了编码的规范和质量,说不定未来某个 SpringBoot 版本就彻底禁止循环依赖的代码了。
SpringBoot 2.6.x 以后,如果你不想重构循环依赖的代码的话,也可以采用下面这些方法:
- 在全局配置文件中设置允许循环依赖存在:`spring.main.allow-circular-references=true`。最简单粗暴的方式,不太推荐。
- 在导致循环依赖的 Bean 上添加 `@Lazy` 注解,这是一种比较推荐的方式。`@Lazy` 用来标识类是否需要懒加载/延迟加载,可以作用在类上、方法上、构造器上、方法参数上、成员变量中。
- ……
## ⭐️Spring 事务
关于 Spring 事务的详细介绍,可以看我写的 [Spring 事务详解](https://javaguide.cn/system-design/framework/spring/spring-transaction.html) 这篇文章。
### Spring 管理事务的方式有几种?
- **编程式事务**:在代码中硬编码(在分布式系统中推荐使用) : 通过 `TransactionTemplate`或者 `TransactionManager` 手动管理事务,事务范围过大会出现事务未提交导致超时,因此事务要比锁的粒度更小。
- **声明式事务**:在 XML 配置文件中配置或者直接基于注解(单体应用或者简单业务系统推荐使用) : 实际是通过 AOP 实现(基于`@Transactional` 的全注解方式使用最多)
### Spring 事务中哪几种事务传播行为?
**事务传播行为是为了解决业务层方法之间互相调用的事务问题**。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
正确的事务传播行为可能的值如下:
**1.`TransactionDefinition.PROPAGATION_REQUIRED`**
使用的最多的一个事务传播行为,我们平时经常使用的`@Transactional`注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
**`2.TransactionDefinition.PROPAGATION_REQUIRES_NEW`**
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,`Propagation.REQUIRES_NEW`修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
**3.`TransactionDefinition.PROPAGATION_NESTED`**
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于`TransactionDefinition.PROPAGATION_REQUIRED`。
**4.`TransactionDefinition.PROPAGATION_MANDATORY`**
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
这个使用的很少。
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚:
- **`TransactionDefinition.PROPAGATION_SUPPORTS`**: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- **`TransactionDefinition.PROPAGATION_NOT_SUPPORTED`**: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- **`TransactionDefinition.PROPAGATION_NEVER`**: 以非事务方式运行,如果当前存在事务,则抛出异常。
### Spring 事务中的隔离级别有哪几种?
和事务传播行为这块一样,为了方便使用,Spring 也相应地定义了一个枚举类:`Isolation`
```java
public enum Isolation {
DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
private final int value;
Isolation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
```
下面我依次对每一种事务隔离级别进行介绍:
- **`TransactionDefinition.ISOLATION_DEFAULT`** :使用后端数据库默认的隔离级别,MySQL 默认采用的 `REPEATABLE_READ` 隔离级别 Oracle 默认采用的 `READ_COMMITTED` 隔离级别.
- **`TransactionDefinition.ISOLATION_READ_UNCOMMITTED`** :最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
- **`TransactionDefinition.ISOLATION_READ_COMMITTED`** : 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
- **`TransactionDefinition.ISOLATION_REPEATABLE_READ`** : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
- **`TransactionDefinition.ISOLATION_SERIALIZABLE`** : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
### @Transactional(rollbackFor = Exception.class)注解了解吗?
`Exception` 分为运行时异常 `RuntimeException` 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
当 `@Transactional` 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。
`@Transactional` 注解默认回滚策略是只有在遇到`RuntimeException`(运行时异常) 或者 `Error` 时才会回滚事务,而不会回滚 `Checked Exception`(受检查异常)。这是因为 Spring 认为`RuntimeException`和 Error 是不可预期的错误,而受检异常是可预期的错误,可以通过业务逻辑来处理。

如果想要修改默认的回滚策略,可以使用 `@Transactional` 注解的 `rollbackFor` 和 `noRollbackFor` 属性来指定哪些异常需要回滚,哪些异常不需要回滚。例如,如果想要让所有的异常都回滚事务,可以使用如下的注解:
```java
@Transactional(rollbackFor = Exception.class)
public void someMethod() {
// some business logic
}
```
如果想要让某些特定的异常不回滚事务,可以使用如下的注解:
```java
@Transactional(noRollbackFor = CustomException.class)
public void someMethod() {
// some business logic
}
```
## Spring Security
Spring Security 重要的是实战,这里仅对小部分知识点进行总结。
### 有哪些控制请求访问权限的方法?
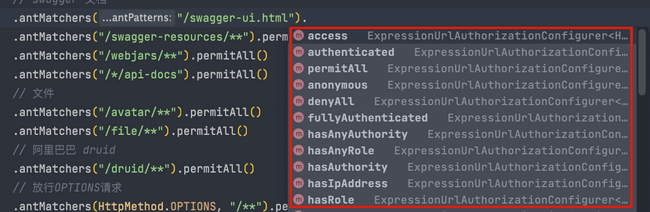
- `permitAll()`:无条件允许任何形式访问,不管你登录还是没有登录。
- `anonymous()`:允许匿名访问,也就是没有登录才可以访问。
- `denyAll()`:无条件决绝任何形式的访问。
- `authenticated()`:只允许已认证的用户访问。
- `fullyAuthenticated()`:只允许已经登录或者通过 remember-me 登录的用户访问。
- `hasRole(String)` : 只允许指定的角色访问。
- `hasAnyRole(String)` : 指定一个或者多个角色,满足其一的用户即可访问。
- `hasAuthority(String)`:只允许具有指定权限的用户访问
- `hasAnyAuthority(String)`:指定一个或者多个权限,满足其一的用户即可访问。
- `hasIpAddress(String)` : 只允许指定 ip 的用户访问。
### hasRole 和 hasAuthority 有区别吗?
可以看看松哥的这篇文章:[Spring Security 中的 hasRole 和 hasAuthority 有区别吗?](https://mp.weixin.qq.com/s/GTNOa2k9_n_H0w24upClRw),介绍的比较详细。
### ⭐️如何对密码进行加密?
如果我们需要保存密码这类敏感数据到数据库的话,需要先加密再保存。
Spring Security 提供了多种加密算法的实现,开箱即用,非常方便。这些加密算法实现类的接口是 `PasswordEncoder` ,如果你想要自己实现一个加密算法的话,也需要实现 `PasswordEncoder` 接口。
`PasswordEncoder` 接口一共也就 3 个必须实现的方法。
```java
public interface PasswordEncoder {
// 加密也就是对原始密码进行编码
String encode(CharSequence var1);
// 比对原始密码和数据库中保存的密码
boolean matches(CharSequence var1, String var2);
// 判断加密密码是否需要再次进行加密,默认返回 false
default boolean upgradeEncoding(String encodedPassword) {
return false;
}
}
```
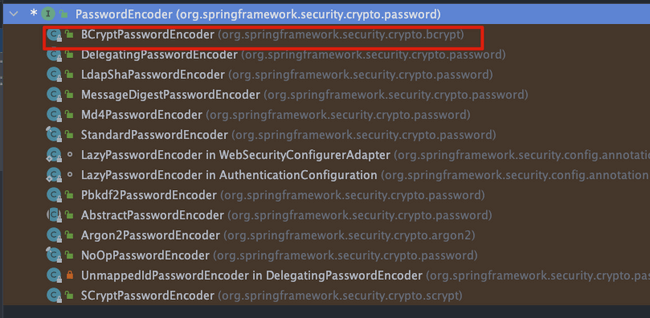
官方推荐使用基于 bcrypt 强哈希函数的加密算法实现类。
### 如何优雅更换系统使用的加密算法?
如果我们在开发过程中,突然发现现有的加密算法无法满足我们的需求,需要更换成另外一个加密算法,这个时候应该怎么办呢?
推荐的做法是通过 `DelegatingPasswordEncoder` 兼容多种不同的密码加密方案,以适应不同的业务需求。
从名字也能看出来,`DelegatingPasswordEncoder` 其实就是一个代理类,并非是一种全新的加密算法,它做的事情就是代理上面提到的加密算法实现类。在 Spring Security 5.0 之后,默认就是基于 `DelegatingPasswordEncoder` 进行密码加密的。
## SpringBoot
### ⭐️Spring,Spring MVC,Spring Boot 之间什么关系?
很多人对 Spring,Spring MVC,Spring Boot 这三者傻傻分不清楚!这里简单介绍一下这三者,其实很简单,没有什么高深的东西。
Spring 包含了多个功能模块(上面刚刚提到过),其中最重要的是 Spring-Core(主要提供 IoC 依赖注入功能的支持) 模块, Spring 中的其他模块(比如 Spring MVC)的功能实现基本都需要依赖于该模块。
下图对应的是 Spring4.x 版本。目前最新的 5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。

Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。

使用 Spring 进行开发各种配置过于麻烦比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置。于是,Spring Boot 诞生了!
Spring 旨在简化 J2EE 企业应用程序开发。Spring Boot 旨在简化 Spring 开发(减少配置文件,开箱即用!)。
Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程序,你还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 帮你简化了 Spring MVC 的很多配置,真正做到开箱即用!
### ⭐️Spring Boot 支持哪些内嵌 Servlet 容器?如何选择?
Spring Boot 提供了三种内嵌 Web 容器,分别为 **Tomcat**、**Jetty** 和 **Undertow** 。
当你在项目中引入 `spring-boot-starter-web` 这个起步依赖时,Spring Boot 默认会包含并启用 Tomcat 作为内嵌 Servlet 容器。
如果你想使用 Jetty 或 Undertow,需要在构建文件(如 Maven 的 `pom.xml`或 Gradle 的 `build.gradle`)中,从 `spring-boot-starter-web` 中排除默认的 Tomcat 依赖 (`spring-boot-starter-tomcat`),添加你想使用的容器对应的 Starter 依赖(例如 `spring-boot-starter-jetty` 或 `spring-boot-starter-undertow`)。
```xml
org.springframework.boot
spring-boot-starter-web
spring-boot-starter-tomcat
org.springframework.boot
spring-boot-starter-jetty
org.springframework.boot
```
在 Spring Boot 项目中,我们可以根据具体应用场景和性能需求,灵活地选择不同的嵌入式 Servlet 容器来提供 HTTP 服务:
1. **Tomcat**:适用于大多数常规 Web 应用程序和 RESTful 服务,易于使用和配置,但在高并发场景下确实可能不如 Undertow 表现出色。
2. **Undertow**:Undertow 具有极低的启动时间和资源占用,支持非阻塞 IO(NIO),在高并发场景下表现出色,性能优于 Tomcat。
3. **Jetty**:如果应用程序涉及即时通信、聊天系统或其他需要保持长连接的场景,Jetty 是一个更好的选择。它在处理长连接和 WebSocket 时表现优越。另外。Jetty 在性能和内存使用方面通常优于 Tomcat,虽然在极端高并发场景中可能略逊于 Undertow。
**⚠️** **注意** :
Spring Boot 4.0 完全移除了对 Undertow 的内嵌支持——不仅删掉了 **spring-boot-starter-undertow**,也不再提供任何 Undertow 相关的自动配置。移除的根本原因是:Spring Boot 4.0 基线升级到 Servlet 6.1(也就是说必须支持 Servlet 6.1 才能留在 starter 列表里),而截至 2025-10 官方发布说明时,Undertow 尚未兼容该版本。
### Spring Boot 默认使用的日志框架是什么?
Spring Boot 默认选用 SLF4J (Simple Logging Facade for Java) 作为其日志门面 (Facade) / 日志抽象层,并搭配 Logback 作为默认的具体日志实现库 (Implementation)。
### ⭐️Spring Boot 的自动配置是如何实现的?
Spring Boot 的自动配置机制是通过 `@SpringBootApplication` 注解启动的,这个注解本质上是几个关键注解的组合。我们可以将 `@SpringBootApplication` 看作是 `@Configuration`、`@EnableAutoConfiguration` 和 `@ComponentScan` 注解的集合。
- **`@EnableAutoConfiguration`**: 启用 Spring Boot 的自动配置机制。它是自动配置的核心,允许 Spring Boot 根据项目的依赖和配置自动配置 Spring 应用的各个部分。
- **`@ComponentScan`**: 启用组件扫描,扫描被 `@Component`(以及 `@Service`、`@Controller` 等)注解的类,并将这些类注册为 Spring 容器中的 Bean。默认情况下,它会扫描该类所在包及其子包下的所有类。
- **`@Configuration`**: 允许在上下文中注册额外的 Bean 或导入其他配置类。它相当于一个具有 `@Bean` 方法的 Spring 配置类。
`@EnableAutoConfiguration`是启动自动配置的关键,源码如下(建议自己打断点调试,走一遍基本的流程):
```java
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.context.annotation.Import;
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class[] exclude() default {};
String[] excludeName() default {};
}
```
这个注解通过 `@Import` 导入了 `AutoConfigurationImportSelector` 类,而 `AutoConfigurationImportSelector` 是自动配置的核心类之一。`@Import` 注解的作用是将指定的配置类或 Bean 导入到当前的配置类中。
`AutoConfigurationImportSelector` 类的 `getCandidateConfigurations` 方法会加载所有可用的自动配置类,并将这些类的信息以 `List` 的形式返回。这些配置类会被 Spring 容器管理为 Bean,从而实现自动配置。
```java
protected List getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
```
这里使用了 `SpringFactoriesLoader` 来加载位于 `META-INF/spring.factories` 文件中的自动配置类。这些配置类会根据应用的具体条件(例如类路径中的依赖)自动配置相应的组件。
**自动配置信息有了,那么自动配置还差什么呢?**
`@Conditional` 注解!在自动配置类中,Spring Boot 使用了一系列条件注解(如 `@Conditional`、`@ConditionalOnClass`、`@ConditionalOnBean` 等)来判断某些配置是否应该生效。这些注解是 `@Conditional` 注解的扩展,用于在特定条件满足时才启用相应的配置。
例如,在 Spring Security 的自动配置中,有一个名为 `SecurityAutoConfiguration` 的自动配置类,它导入了 `WebSecurityEnablerConfiguration` 类。
`WebSecurityEnablerConfiguration` 类的源码如下:
```java
@Configuration
@ConditionalOnBean(WebSecurityConfigurerAdapter.class)
@ConditionalOnMissingBean(name = BeanIds.SPRING_SECURITY_FILTER_CHAIN)
@ConditionalOnWebApplication(type = ConditionalOnWebApplication.Type.SERVLET)
@EnableWebSecurity
public class WebSecurityEnablerConfiguration {
}
```
`WebSecurityEnablerConfiguration`类中使用`@ConditionalOnBean`指定了容器中必须还有`WebSecurityConfigurerAdapter` 类或其实现类。所以,一般情况下 Spring Security 配置类都会去实现 `WebSecurityConfigurerAdapter`,这样自动将配置就完成了。
最后,简单总结一下:Spring Boot 的自动配置机制通过 `@EnableAutoConfiguration` 启动。该注解利用 `@Import` 注解导入了 `AutoConfigurationImportSelector` 类,而 `AutoConfigurationImportSelector` 类则负责加载并管理所有的自动配置类。这些自动配置类通常在`META-INF/spring.factories` 文件中声明,并根据项目的依赖和配置条件,通过条件注解(如 `@ConditionalOnClass`、`@ConditionalOnBean` 等)判断是否应该生效。
⭐自动配置是详细的源码解读可以参考 [JavaGuide](https://javaguide.cn/) 上这篇文章:[SpringBoot 自动装配原理详解](https://javaguide.cn/system-design/framework/spring/spring-boot-auto-assembly-principles.html)。
### Spring Boot 如何加载配置文件?如果两种配置文件同时存在,会怎样处理?
Spring Boot 会自动从类路径的根目录(通常是项目的 `src/main/resources/` 目录)下查找并加载名为 `application.properties` 或 `application.yml` (包括 `.yaml` 扩展名) 的文件。
如果在同一目录下同时存在 `application.properties` 和 `application.yml` 文件,`application.properties` 文件中的配置项优先级更高,会覆盖 `application.yml` 中相同的配置项。为了避免配置冲突和混淆,建议在一个项目中只使用一种格式。
如果开发者没有提供任何 `application.properties` 或 `application.yml` 文件,或者文件中没有定义某个特定的配置项,Spring Boot 将会使用其内置的默认配置值(如果该配置项有默认值的话)。
### Spring Boot 加载配置文件的优先级了解么?
Spring Boot 加载配置文件的优先级设计得非常灵活,主要是为了方便我们在不同环境(开发、测试、生产)下覆盖或指定配置。它的原则是:**后加载的覆盖先加载的,而且离用户(或部署环境)越近的优先级越高**。
**加载顺序如下**:
1. 当前项目根目录下 `config/` 子目录的配置文件 (`./config/application.yml` 或 `./config/application.properties`):优先级最高,通常放在运行 Jar 包同级的 `config` 目录里。
2. 当前项目根目录下的配置文件 (`./application.yml` 或 `./application.properties`): 直接放在运行 Jar 包同级目录里,优先级次之。
3. 类路径内 `config/` 子目录的配置文件 (`classpath:/config/application.yml` 或 `classpath:/config/application.properties`): 对应项目中的 `src/main/resources/config/` 下的文件,优先级再次之。
4. 类路径下的配置文件 (`classpath:/application.yml` 或 `classpath:/application.properties`): 对应项目中的 `src/main/resources/` 根目录下的文件,在这些位置里优先级最低。
总结:Jar 包外 `config/` > Jar 包外根目录 > Jar 包内 `config/`> Jar 包内根目录。
 **简单记忆规则**:
- **包外 > 包内**(方便部署时覆盖配置)。
- **`config/` 目录 > 根目录**(无论包内还是包外,`config` 目录里的配置优先级更高)。
如果某个 Profile 文件(如 `application-dev.yml`)被激活(通过 `spring.profiles.active=dev` 指定),那么,**在同一个目录下**,Profile 文件的优先级高于通用文件。例如:
- `src/main/resources/application-dev.yml` 的配置会覆盖 `src/main/resources/application.yml` 中的同名配置。
- 同样地,Jar 包外的 `config/application-dev.yml` 会覆盖 `config/application.yml`。
通过这样的灵活设计,Spring Boot 能很好地适应各种环境的配置需求,同时确保配置文件的覆盖和管理清晰有序。
### ⭐️更多 SpringBoot 面试题
更多 **Spring Boot** 相关的面试题欢迎加入我的知识星球,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
很多 Spring Boot 重要的新特性都已经同步到了这篇文章中,质量很高,保证内容与时俱进!
**简单记忆规则**:
- **包外 > 包内**(方便部署时覆盖配置)。
- **`config/` 目录 > 根目录**(无论包内还是包外,`config` 目录里的配置优先级更高)。
如果某个 Profile 文件(如 `application-dev.yml`)被激活(通过 `spring.profiles.active=dev` 指定),那么,**在同一个目录下**,Profile 文件的优先级高于通用文件。例如:
- `src/main/resources/application-dev.yml` 的配置会覆盖 `src/main/resources/application.yml` 中的同名配置。
- 同样地,Jar 包外的 `config/application-dev.yml` 会覆盖 `config/application.yml`。
通过这样的灵活设计,Spring Boot 能很好地适应各种环境的配置需求,同时确保配置文件的覆盖和管理清晰有序。
### ⭐️更多 SpringBoot 面试题
更多 **Spring Boot** 相关的面试题欢迎加入我的知识星球,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
很多 Spring Boot 重要的新特性都已经同步到了这篇文章中,质量很高,保证内容与时俱进!
