p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
```
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树。
### ⭐️HashMap 的长度为什么是 2 的幂次方
为了让 `HashMap` 存取高效并减少碰撞,我们需要确保数据尽量均匀分布。哈希值在 Java 中通常使用 `int` 表示,其范围是 `-2147483648 ~ 2147483647`前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但是,问题是一个 40 亿长度的数组,内存是放不下的。所以,这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。
**这个算法应该如何设计呢?**
我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了:“**取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作**(也就是说 `hash%length==hash&(length-1)` 的前提是 length 是 2 的 n 次方)。” 并且,**采用二进制位操作 & 相对于 % 能够提高运算效率**。
除了上面所说的位运算比取余效率高之外,我觉得更重要的一个原因是:**长度是 2 的幂次方,可以让 `HashMap` 在扩容的时候更均匀**。例如:
- length = 8 时,length - 1 = 7 的二进制位`0111`
- length = 16 时,length - 1 = 15 的二进制位`1111`
这时候原本存在 `HashMap` 中的元素计算新的数组位置时 `hash&(length-1)`,取决 hash 的第四个二进制位(从右数),会出现两种情况:
1. 第四个二进制位为 0,数组位置不变,也就是说当前元素在新数组和旧数组的位置相同。
2. 第四个二进制位为 1,数组位置在新数组扩容之后的那一部分。
这里列举一个例子:
```plain
假设有一个元素的哈希值为 10101100
旧数组元素位置计算:
hash = 10101100
length - 1 = 00000111
& -----------------
index = 00000100 (4)
新数组元素位置计算:
hash = 10101100
length - 1 = 00001111
& -----------------
index = 00001100 (12)
看第四位(从右数):
1.高位为 0:位置不变。
2.高位为 1:移动到新位置(原索引位置+原容量)。
```
⚠️注意:这里列举的场景看的是第四个二进制位,更准确点来说看的是高位(从右数),例如 `length = 32` 时,`length - 1 = 31`,二进制为 `11111`,这里看的就是第五个二进制位。
也就是说扩容之后,在旧数组元素 hash 值比较均匀(至于 hash 值均不均匀,取决于前面讲的对象的 `hashcode()` 方法和扰动函数)的情况下,新数组元素也会被分配的比较均匀,最好的情况是会有一半在新数组的前半部分,一半在新数组后半部分。
这样也使得扩容机制变得简单和高效,扩容后只需检查哈希值高位的变化来决定元素的新位置,要么位置不变(高位为 0),要么就是移动到新位置(高位为 1,原索引位置+原容量)。
最后,简单总结一下 `HashMap` 的长度是 2 的幂次方的原因:
1. 位运算效率更高:位运算(&)比取余运算(%)更高效。当长度为 2 的幂次方时,`hash % length` 等价于 `hash & (length - 1)`。
2. 可以更好地保证哈希值的均匀分布:扩容之后,在旧数组元素 hash 值比较均匀的情况下,新数组元素也会被分配的比较均匀,最好的情况是会有一半在新数组的前半部分,一半在新数组后半部分。
3. 扩容机制变得简单和高效:扩容后只需检查哈希值高位的变化来决定元素的新位置,要么位置不变(高位为 0),要么就是移动到新位置(高位为 1,原索引位置+原容量)。
### ⭐️HashMap 多线程操作导致死循环问题
JDK1.7 及之前版本的 `HashMap` 在多线程环境下扩容操作可能存在死循环问题,这是由于当一个桶位中有多个元素需要进行扩容时,多个线程同时对链表进行操作,头插法可能会导致链表中的节点指向错误的位置,从而形成一个环形链表,进而使得查询元素的操作陷入死循环无法结束。
为了解决这个问题,JDK1.8 版本的 HashMap 采用了尾插法而不是头插法来避免链表倒置,使得插入的节点永远都是放在链表的末尾,避免了链表中的环形结构。但是还是不建议在多线程下使用 `HashMap`,因为多线程下使用 `HashMap` 还是会存在数据覆盖的问题。并发环境下,推荐使用 `ConcurrentHashMap` 。
一般面试中这样介绍就差不多,不需要记各种细节,个人觉得也没必要记。如果想要详细了解 `HashMap` 扩容导致死循环问题,可以看看耗子叔的这篇文章:[Java HashMap 的死循环](https://coolshell.cn/articles/9606.html)。
### ⭐️HashMap 为什么线程不安全?
JDK1.7 及之前版本,在多线程环境下,`HashMap` 扩容时会造成死循环和数据丢失的问题。
数据丢失这个在 JDK1.7 和 JDK 1.8 中都存在,这里以 JDK 1.8 为例进行介绍。
JDK 1.8 后,在 `HashMap` 中,多个键值对可能会被分配到同一个桶(bucket),并以链表或红黑树的形式存储。多个线程对 `HashMap` 的 `put` 操作会导致线程不安全,具体来说会有数据覆盖的风险。
举个例子:
- 两个线程 1,2 同时进行 put 操作,并且发生了哈希冲突(hash 函数计算出的插入下标是相同的)。
- 不同的线程可能在不同的时间片获得 CPU 执行的机会,当前线程 1 执行完哈希冲突判断后,由于时间片耗尽挂起。线程 2 先完成了插入操作。
- 随后,线程 1 获得时间片,由于之前已经进行过 hash 碰撞的判断,所有此时会直接进行插入,这就导致线程 2 插入的数据被线程 1 覆盖了。
```java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// ...
// 判断是否出现 hash 碰撞
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
// ...
}
```
还有一种情况是这两个线程同时 `put` 操作导致 `size` 的值不正确,进而导致数据覆盖的问题:
1. 线程 1 执行 `if(++size > threshold)` 判断时,假设获得 `size` 的值为 10,由于时间片耗尽挂起。
2. 线程 2 也执行 `if(++size > threshold)` 判断,获得 `size` 的值也为 10,并将元素插入到该桶位中,并将 `size` 的值更新为 11。
3. 随后,线程 1 获得时间片,它也将元素放入桶位中,并将 size 的值更新为 11。
4. 线程 1、2 都执行了一次 `put` 操作,但是 `size` 的值只增加了 1,也就导致实际上只有一个元素被添加到了 `HashMap` 中。
```java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// ...
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
```
### HashMap 常见的遍历方式?
[HashMap 的 7 种遍历方式与性能分析!](https://mp.weixin.qq.com/s/zQBN3UvJDhRTKP6SzcZFKw)
**🐛 修正(参见:[issue#1411](https://github.com/Snailclimb/JavaGuide/issues/1411))**:
这篇文章对于 parallelStream 遍历方式的性能分析有误,先说结论:**存在阻塞时 parallelStream 性能最高, 非阻塞时 parallelStream 性能最低** 。
当遍历不存在阻塞时, parallelStream 的性能是最低的:
```plain
Benchmark Mode Cnt Score Error Units
Test.entrySet avgt 5 288.651 ± 10.536 ns/op
Test.keySet avgt 5 584.594 ± 21.431 ns/op
Test.lambda avgt 5 221.791 ± 10.198 ns/op
Test.parallelStream avgt 5 6919.163 ± 1116.139 ns/op
```
加入阻塞代码`Thread.sleep(10)`后, parallelStream 的性能才是最高的:
```plain
Benchmark Mode Cnt Score Error Units
Test.entrySet avgt 5 1554828440.000 ± 23657748.653 ns/op
Test.keySet avgt 5 1550612500.000 ± 6474562.858 ns/op
Test.lambda avgt 5 1551065180.000 ± 19164407.426 ns/op
Test.parallelStream avgt 5 186345456.667 ± 3210435.590 ns/op
```
### ⭐️ConcurrentHashMap 和 Hashtable 的区别
`ConcurrentHashMap` 和 `Hashtable` 的区别主要体现在实现线程安全的方式上不同。
- **底层数据结构:** JDK1.7 的 `ConcurrentHashMap` 底层采用 **分段的数组+链表** 实现,在 JDK1.8 中采用的数据结构跟 `HashMap` 的结构一样,数组+链表/红黑二叉树。`Hashtable` 和 JDK1.8 之前的 `HashMap` 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- **实现线程安全的方式(重要):**
- 在 JDK1.7 的时候,`ConcurrentHashMap` 对整个桶数组进行了分割分段(`Segment`,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
- 到了 JDK1.8 的时候,`ConcurrentHashMap` 已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 `synchronized` 锁做了很多优化) 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
- **`Hashtable`(同一把锁)** :使用 `synchronized` 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
下面,我们再来看看两者底层数据结构的对比图。
**Hashtable** :
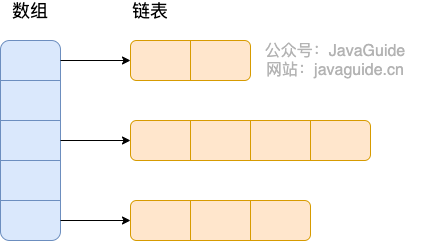
https://www.cnblogs.com/chengxiao/p/6842045.html>
**JDK1.7 的 ConcurrentHashMap**:
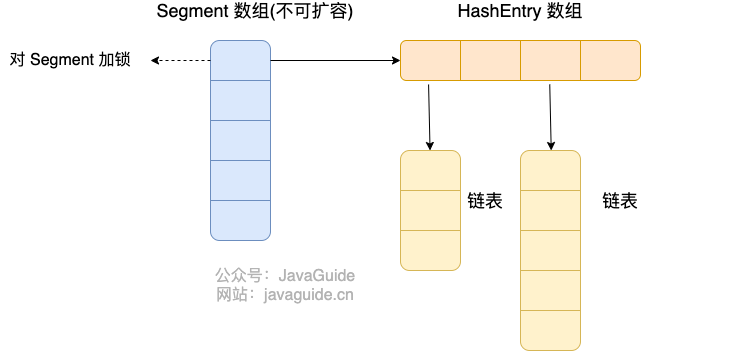
`ConcurrentHashMap` 是由 `Segment` 数组结构和 `HashEntry` 数组结构组成。
`Segment` 数组中的每个元素包含一个 `HashEntry` 数组,每个 `HashEntry` 数组属于链表结构。
**JDK1.8 的 ConcurrentHashMap**:
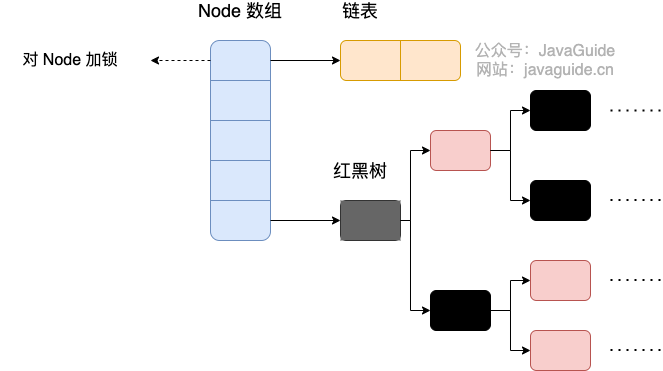
JDK1.8 的 `ConcurrentHashMap` 不再是 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。不过,Node 只能用于链表的情况,红黑树的情况需要使用 **`TreeNode`**。当冲突链表达到一定长度时,链表会转换成红黑树。
`TreeNode`是存储红黑树节点,被`TreeBin`包装。`TreeBin`通过`root`属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在 `ConcurrentHashMap` 中`TreeBin`通过`waiter`属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
```java
static final class TreeBin extends Node {
TreeNode root;
volatile TreeNode first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
...
}
```
### ⭐️ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
#### JDK1.8 之前

首先将数据分为一段一段(这个“段”就是 `Segment`)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
**`ConcurrentHashMap` 是由 `Segment` 数组结构和 `HashEntry` 数组结构组成**。
`Segment` 继承了 `ReentrantLock`,所以 `Segment` 是一种可重入锁,扮演锁的角色。`HashEntry` 用于存储键值对数据。
```java
static class Segment extends ReentrantLock implements Serializable {
}
```
一个 `ConcurrentHashMap` 里包含一个 `Segment` 数组,`Segment` 的个数一旦**初始化就不能改变**。 `Segment` 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
`Segment` 的结构和 `HashMap` 类似,是一种数组和链表结构,一个 `Segment` 包含一个 `HashEntry` 数组,每个 `HashEntry` 是一个链表结构的元素,每个 `Segment` 守护着一个 `HashEntry` 数组里的元素,当对 `HashEntry` 数组的数据进行修改时,必须首先获得对应的 `Segment` 的锁。也就是说,对同一 `Segment` 的并发写入会被阻塞,不同 `Segment` 的写入是可以并发执行的。
#### JDK1.8 之后

Java 8 几乎完全重写了 `ConcurrentHashMap`,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
`ConcurrentHashMap` 取消了 `Segment` 分段锁,采用 `Node + CAS + synchronized` 来保证并发安全。数据结构跟 `HashMap` 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,`synchronized` 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
### ⭐️JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
- **线程安全实现方式**:JDK 1.7 采用 `Segment` 分段锁来保证安全, `Segment` 是继承自 `ReentrantLock`。JDK1.8 放弃了 `Segment` 分段锁的设计,采用 `Node + CAS + synchronized` 保证线程安全,锁粒度更细,`synchronized` 只锁定当前链表或红黑二叉树的首节点。
- **Hash 碰撞解决方法** : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
- **并发度**:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
### ConcurrentHashMap 为什么 key 和 value 不能为 null?
`ConcurrentHashMap` 的 key 和 value 不能为 null 主要是为了避免二义性。null 是一个特殊的值,表示没有对象或没有引用。如果你用 null 作为键,那么你就无法区分这个键是否存在于 `ConcurrentHashMap` 中,还是根本没有这个键。同样,如果你用 null 作为值,那么你就无法区分这个值是否是真正存储在 `ConcurrentHashMap` 中的,还是因为找不到对应的键而返回的。
拿 get 方法取值来说,返回的结果为 null 存在两种情况:
- 值没有在集合中 ;
- 值本身就是 null。
这也就是二义性的由来。
具体可以参考 [ConcurrentHashMap 源码分析](https://javaguide.cn/java/collection/concurrent-hash-map-source-code.html) 。
多线程环境下,存在一个线程操作该 `ConcurrentHashMap` 时,其他的线程将该 `ConcurrentHashMap` 修改的情况,所以无法通过 `containsKey(key)` 来判断否存在这个键值对,也就没办法解决二义性问题了。
与此形成对比的是,`HashMap` 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。如果传入 null 作为参数,就会返回 hash 值为 0 的位置的值。单线程环境下,不存在一个线程操作该 HashMap 时,其他的线程将该 `HashMap` 修改的情况,所以可以通过 `contains(key)`来做判断是否存在这个键值对,从而做相应的处理,也就不存在二义性问题。
也就是说,多线程下无法正确判定键值对是否存在(存在其他线程修改的情况),单线程是可以的(不存在其他线程修改的情况)。
如果你确实需要在 ConcurrentHashMap 中使用 null 的话,可以使用一个特殊的静态空对象来代替 null。
```java
public static final Object NULL = new Object();
```
最后,再分享一下 `ConcurrentHashMap` 作者本人 (Doug Lea)对于这个问题的回答:
> The main reason that nulls aren't allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can't be accommodated. The main one is that if `map.get(key)` returns `null`, you can't detect whether the key explicitly maps to `null` vs the key isn't mapped. In a non-concurrent map, you can check this via `map.contains(key)`, but in a concurrent one, the map might have changed between calls.
翻译过来之后的,大致意思还是单线程下可以容忍歧义,而多线程下无法容忍。
### ⭐️ConcurrentHashMap 能保证复合操作的原子性吗?
`ConcurrentHashMap` 是线程安全的,意味着它可以保证多个线程同时对它进行读写操作时,不会出现数据不一致的情况,也不会导致 JDK1.7 及之前版本的 `HashMap` 多线程操作导致死循环问题。但是,这并不意味着它可以保证所有的复合操作都是原子性的,一定不要搞混了!
复合操作是指由多个基本操作(如`put`、`get`、`remove`、`containsKey`等)组成的操作,例如先判断某个键是否存在`containsKey(key)`,然后根据结果进行插入或更新`put(key, value)`。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
例如,有两个线程 A 和 B 同时对 `ConcurrentHashMap` 进行复合操作,如下:
```java
// 线程 A
if (!map.containsKey(key)) {
map.put(key, value);
}
// 线程 B
if (!map.containsKey(key)) {
map.put(key, anotherValue);
}
```
如果线程 A 和 B 的执行顺序是这样:
1. 线程 A 判断 map 中不存在 key
2. 线程 B 判断 map 中不存在 key
3. 线程 B 将 (key, anotherValue) 插入 map
4. 线程 A 将 (key, value) 插入 map
那么最终的结果是 (key, value),而不是预期的 (key, anotherValue)。这就是复合操作的非原子性导致的问题。
**那如何保证 `ConcurrentHashMap` 复合操作的原子性呢?**
`ConcurrentHashMap` 提供了一些原子性的复合操作,如 `putIfAbsent`、`compute`、`computeIfAbsent` 、`computeIfPresent`、`merge`等。这些方法都可以接受一个函数作为参数,根据给定的 key 和 value 来计算一个新的 value,并且将其更新到 map 中。
上面的代码可以改写为:
```java
// 线程 A
map.putIfAbsent(key, value);
// 线程 B
map.putIfAbsent(key, anotherValue);
```
或者:
```java
// 线程 A
map.computeIfAbsent(key, k -> value);
// 线程 B
map.computeIfAbsent(key, k -> anotherValue);
```
很多同学可能会说了,这种情况也能加锁同步呀!确实可以,但不建议使用加锁的同步机制,违背了使用 `ConcurrentHashMap` 的初衷。在使用 `ConcurrentHashMap` 的时候,尽量使用这些原子性的复合操作方法来保证原子性。
