> T min(T[] values) {
- if (values == null || values.length == 0) return null;
- T min = values[0];
- for (int i = 1; i < values.length; i++) {
- if (min.compareTo(values[i]) > 0) min = values[i];
- }
- return min;
-}
-```
-
-测试:
-
-```java
-int minInteger = min(new Integer[]{1, 2, 3});//result:1
-double minDouble = min(new Double[]{1.2, 2.2, -1d});//result:-1d
-String typeError = min(new String[]{"1","3"});//报错
-```
-### 0.0.2. 使用数组实现栈
-
-**自己实现一个栈,要求这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。**
-
-提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用`Arrays.copyOf()`进行扩容;
-
-```java
-public class MyStack {
- private int[] storage;//存放栈中元素的数组
- private int capacity;//栈的容量
- private int count;//栈中元素数量
- private static final int GROW_FACTOR = 2;
-
- //不带初始容量的构造方法。默认容量为8
- public MyStack() {
- this.capacity = 8;
- this.storage=new int[8];
- this.count = 0;
- }
-
- //带初始容量的构造方法
- public MyStack(int initialCapacity) {
- if (initialCapacity < 1)
- throw new IllegalArgumentException("Capacity too small.");
-
- this.capacity = initialCapacity;
- this.storage = new int[initialCapacity];
- this.count = 0;
- }
-
- //入栈
- public void push(int value) {
- if (count == capacity) {
- ensureCapacity();
- }
- storage[count++] = value;
- }
-
- //确保容量大小
- private void ensureCapacity() {
- int newCapacity = capacity * GROW_FACTOR;
- storage = Arrays.copyOf(storage, newCapacity);
- capacity = newCapacity;
- }
-
- //返回栈顶元素并出栈
- private int pop() {
- if (count == 0)
- throw new IllegalArgumentException("Stack is empty.");
- count--;
- return storage[count];
- }
-
- //返回栈顶元素不出栈
- private int peek() {
- if (count == 0){
- throw new IllegalArgumentException("Stack is empty.");
- }else {
- return storage[count-1];
- }
- }
-
- //判断栈是否为空
- private boolean isEmpty() {
- return count == 0;
- }
-
- //返回栈中元素的个数
- private int size() {
- return count;
- }
-
-}
-
-```
-
-验证
-
-```java
-MyStack myStack = new MyStack(3);
-myStack.push(1);
-myStack.push(2);
-myStack.push(3);
-myStack.push(4);
-myStack.push(5);
-myStack.push(6);
-myStack.push(7);
-myStack.push(8);
-System.out.println(myStack.peek());//8
-System.out.println(myStack.size());//8
-for (int i = 0; i < 8; i++) {
- System.out.println(myStack.pop());
-}
-System.out.println(myStack.isEmpty());//true
-myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
-```
-
-
-
diff --git a/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md b/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md
deleted file mode 100644
index 7c367e11bd0..00000000000
--- a/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md
+++ /dev/null
@@ -1,441 +0,0 @@
-
-
-- [1. LRU 缓存介绍](#1-lru-%e7%bc%93%e5%ad%98%e4%bb%8b%e7%bb%8d)
-- [2. ConcurrentLinkedQueue简单介绍](#2-concurrentlinkedqueue%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
-- [3. ReadWriteLock简单介绍](#3-readwritelock%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
-- [4. ScheduledExecutorService 简单介绍](#4-scheduledexecutorservice-%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
-- [5. 徒手撸一个线程安全的 LRU 缓存](#5-%e5%be%92%e6%89%8b%e6%92%b8%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
- - [5.1. 实现方法](#51-%e5%ae%9e%e7%8e%b0%e6%96%b9%e6%b3%95)
- - [5.2. 原理](#52-%e5%8e%9f%e7%90%86)
- - [5.3. put方法具体流程分析](#53-put%e6%96%b9%e6%b3%95%e5%85%b7%e4%bd%93%e6%b5%81%e7%a8%8b%e5%88%86%e6%9e%90)
- - [5.4. 源码](#54-%e6%ba%90%e7%a0%81)
-- [6. 实现一个线程安全并且带有过期时间的 LRU 缓存](#6-%e5%ae%9e%e7%8e%b0%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e5%b9%b6%e4%b8%94%e5%b8%a6%e6%9c%89%e8%bf%87%e6%9c%9f%e6%97%b6%e9%97%b4%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
-
-
-
-最近被读者问到“不用LinkedHashMap的话,如何实现一个线程安全的 LRU 缓存?网上的代码太杂太乱,Guide哥哥能不能帮忙写一个?”。
-
-*划重点,手写一个 LRU 缓存在面试中还是挺常见的!*
-
-很多人就会问了:“网上已经有这么多现成的缓存了!为什么面试官还要我们自己实现一个呢?” 。咳咳咳,当然是为了面试需要。哈哈!开个玩笑,我个人觉得更多地是为了学习吧!今天Guide哥教大家:
-
-1. 实现一个线程安全的 LRU 缓存
-2. 实现一个线程安全并且带有过期时间的 LRU 缓存
-
-考虑到了线程安全性我们使用了 `ConcurrentHashMap` 、`ConcurrentLinkedQueue` 这两个线程安全的集合。另外,还用到 `ReadWriteLock`(读写锁)。为了实现带有过期时间的缓存,我们用到了 `ScheduledExecutorService`来做定时任务执行。
-
-如果有任何不对或者需要完善的地方,请帮忙指出!
-
-### 1. LRU 缓存介绍
-
-**LRU (Least Recently Used,最近最少使用)是一种缓存淘汰策略。**
-
-LRU缓存指的是当缓存大小已达到最大分配容量的时候,如果再要去缓存新的对象数据的话,就需要将缓存中最近访问最少的对象删除掉以便给新来的数据腾出空间。
-
-### 2. ConcurrentLinkedQueue简单介绍
-
-**ConcurrentLinkedQueue是一个基于单向链表的无界无锁线程安全的队列,适合在高并发环境下使用,效率比较高。** 我们在使用的时候,可以就把它理解为我们经常接触的数据结构——队列,不过是增加了多线程下的安全性保证罢了。**和普通队列一样,它也是按照先进先出(FIFO)的规则对接点进行排序。** 另外,队列元素中不可以放置null元素。
-
-`ConcurrentLinkedQueue` 整个继承关系如下图所示:
-
-
-
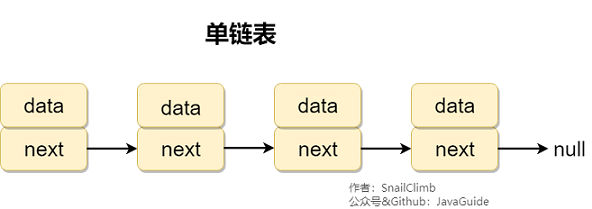
-`ConcurrentLinkedQueue中`最主要的两个方法是:`offer(value)`和`poll()`,分别实现队列的两个重要的操作:入队和出队(`offer(value)`等价于 `add(value)`)。
-
-我们添加一个元素到队列的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。
-
-
-
-利用`ConcurrentLinkedQueue`队列先进先出的特性,每当我们 `put`/`get`(缓存被使用)元素的时候,我们就将这个元素存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。
-
-### 3. ReadWriteLock简单介绍
-
-`ReadWriteLock` 是一个接口,位于`java.util.concurrent.locks`包下,里面只有两个方法分别返回读锁和写锁:
-
-```java
-public interface ReadWriteLock {
- /**
- * 返回读锁
- */
- Lock readLock();
-
- /**
- * 返回写锁
- */
- Lock writeLock();
-}
-```
-
-`ReentrantReadWriteLock` 是`ReadWriteLock`接口的具体实现类。
-
-**读写锁还是比较适合缓存这种读多写少的场景。读写锁可以保证多个线程和同时读取,但是只有一个线程可以写入。**
-
-读写锁的特点是:写锁和写锁互斥,读锁和写锁互斥,读锁之间不互斥。也就说:同一时刻只能有一个线程写,但是可以有多个线程
-读。读写之间是互斥的,两者不能同时发生(当进行写操作时,同一时刻其他线程的读操作会被阻塞;当进行读操作时,同一时刻所有线程的写操作会被阻塞)。
-
-另外,**同一个线程持有写锁时是可以申请读锁,但是持有读锁的情况下不可以申请写锁。**
-
-### 4. ScheduledExecutorService 简单介绍
-
-`ScheduledExecutorService` 是一个接口,`ScheduledThreadPoolExecutor` 是其主要实现类。
-
-
-
-**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目用到的比较少,因为有其他方案选择比如`quartz`。但是,在一些需求比较简单的场景下还是非常有用的!
-
-**`ScheduledThreadPoolExecutor` 使用的任务队列 `DelayQueue` 封装了一个 `PriorityQueue`,`PriorityQueue` 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行,如果执行所需时间相同则先提交的任务将被先执行。**
-
-### 5. 徒手撸一个线程安全的 LRU 缓存
-
-#### 5.1. 实现方法
-
- `ConcurrentHashMap` + `ConcurrentLinkedQueue` +`ReadWriteLock`
-
-#### 5.2. 原理
-
-`ConcurrentHashMap` 是线程安全的Map,我们可以利用它缓存 key,value形式的数据。`ConcurrentLinkedQueue`是一个线程安全的基于链表的队列(先进先出),我们可以用它来维护 key 。每当我们put/get(缓存被使用)元素的时候,我们就将这个元素对应的 key 存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。当我们的缓存容量不够的时候,我们直接移除队列头部对应的key以及这个key对应的缓存即可!
-
-另外,我们用到了`ReadWriteLock`(读写锁)来保证线程安全。
-
-#### 5.3. put方法具体流程分析
-
-为了方便大家理解,我将代码中比较重要的 `put(key,value)`方法的原理图画了出来,如下图所示:
-
-
-
-
-
-#### 5.4. 源码
-
-```java
-/**
- * @author shuang.kou
- *
- * 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock实现线程安全的 LRU 缓存
- * 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
- */
-public class MyLruCache {
-
- /**
- * 缓存的最大容量
- */
- private final int maxCapacity;
-
- private ConcurrentHashMap cacheMap;
- private ConcurrentLinkedQueue keys;
- /**
- * 读写锁
- */
- private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- private Lock writeLock = readWriteLock.writeLock();
- private Lock readLock = readWriteLock.readLock();
-
- public MyLruCache(int maxCapacity) {
- if (maxCapacity < 0) {
- throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
- }
- this.maxCapacity = maxCapacity;
- cacheMap = new ConcurrentHashMap<>(maxCapacity);
- keys = new ConcurrentLinkedQueue<>();
- }
-
- public V put(K key, V value) {
- // 加写锁
- writeLock.lock();
- try {
- //1.key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- moveToTailOfQueue(key);
- cacheMap.put(key, value);
- return value;
- }
- //2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
- if (cacheMap.size() == maxCapacity) {
- System.out.println("maxCapacity of cache reached");
- removeOldestKey();
- }
- //3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
- keys.add(key);
- cacheMap.put(key, value);
- return value;
- } finally {
- writeLock.unlock();
- }
- }
-
- public V get(K key) {
- //加读锁
- readLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在的话就将key移动到队列的尾部
- moveToTailOfQueue(key);
- return cacheMap.get(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- readLock.unlock();
- }
- }
-
- public V remove(K key) {
- writeLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在移除队列和Map中对应的Key
- keys.remove(key);
- return cacheMap.remove(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- writeLock.unlock();
- }
- }
-
- /**
- * 将元素添加到队列的尾部(put/get的时候执行)
- */
- private void moveToTailOfQueue(K key) {
- keys.remove(key);
- keys.add(key);
- }
-
- /**
- * 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
- */
- private void removeOldestKey() {
- K oldestKey = keys.poll();
- if (oldestKey != null) {
- cacheMap.remove(oldestKey);
- }
- }
-
- public int size() {
- return cacheMap.size();
- }
-
-}
-```
-
-**非并发环境测试:**
-
-```java
-MyLruCache myLruCache = new MyLruCache<>(3);
-myLruCache.put(1, "Java");
-System.out.println(myLruCache.get(1));// Java
-myLruCache.remove(1);
-System.out.println(myLruCache.get(1));// null
-myLruCache.put(2, "C++");
-myLruCache.put(3, "Python");
-System.out.println(myLruCache.get(2));//C++
-myLruCache.put(4, "C");
-myLruCache.put(5, "PHP");
-System.out.println(myLruCache.get(2));// C++
-```
-
-**并发环境测试:**
-
-我们初始化了一个固定容量为 10 的线程池和count为10的`CountDownLatch`。我们将1000000次操作分10次添加到线程池,然后我们等待线程池执行完成这10次操作。
-
-
-```java
-int threadNum = 10;
-int batchSize = 100000;
-//init cache
-MyLruCache myLruCache = new MyLruCache<>(batchSize * 10);
-//init thread pool with 10 threads
-ExecutorService fixedThreadPool = Executors.newFixedThreadPool(threadNum);
-//init CountDownLatch with 10 count
-CountDownLatch latch = new CountDownLatch(threadNum);
-AtomicInteger atomicInteger = new AtomicInteger(0);
-long startTime = System.currentTimeMillis();
-for (int t = 0; t < threadNum; t++) {
- fixedThreadPool.submit(() -> {
- for (int i = 0; i < batchSize; i++) {
- int value = atomicInteger.incrementAndGet();
- myLruCache.put("id" + value, value);
- }
- latch.countDown();
- });
-}
-//wait for 10 threads to complete the task
-latch.await();
-fixedThreadPool.shutdown();
-System.out.println("Cache size:" + myLruCache.size());//Cache size:1000000
-long endTime = System.currentTimeMillis();
-long duration = endTime - startTime;
-System.out.println(String.format("Time cost:%dms", duration));//Time cost:511ms
-```
-
-### 6. 实现一个线程安全并且带有过期时间的 LRU 缓存
-
-实际上就是在我们上面时间的LRU缓存的基础上加上一个定时任务去删除缓存,单纯利用 JDK 提供的类,我们实现定时任务的方式有很多种:
-
-1. `Timer` :不被推荐,多线程会存在问题。
-2. `ScheduledExecutorService` :定时器线程池,可以用来替代 `Timer`
-3. `DelayQueue` :延时队列
-4. `quartz` :一个很火的开源任务调度框架,很多其他框架都是基于 `quartz` 开发的,比如当当网的`elastic-job `就是基于`quartz`二次开发之后的分布式调度解决方案
-5. ......
-
-最终我们选择了 `ScheduledExecutorService`,主要原因是它易用(基于`DelayQueue`做了很多封装)并且基本能满足我们的大部分需求。
-
-我们在我们上面实现的线程安全的 LRU 缓存基础上,简单稍作修改即可!我们增加了一个方法:
-
-```java
-private void removeAfterExpireTime(K key, long expireTime) {
- scheduledExecutorService.schedule(() -> {
- //过期后清除该键值对
- cacheMap.remove(key);
- keys.remove(key);
- }, expireTime, TimeUnit.MILLISECONDS);
-}
-```
-我们put元素的时候,如果通过这个方法就能直接设置过期时间。
-
-
-**完整源码如下:**
-
-```java
-/**
- * @author shuang.kou
- *
- * 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock+ScheduledExecutorService实现线程安全的 LRU 缓存
- * 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
- */
-public class MyLruCacheWithExpireTime {
-
- /**
- * 缓存的最大容量
- */
- private final int maxCapacity;
-
- private ConcurrentHashMap cacheMap;
- private ConcurrentLinkedQueue keys;
- /**
- * 读写锁
- */
- private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- private Lock writeLock = readWriteLock.writeLock();
- private Lock readLock = readWriteLock.readLock();
-
- private ScheduledExecutorService scheduledExecutorService;
-
- public MyLruCacheWithExpireTime(int maxCapacity) {
- if (maxCapacity < 0) {
- throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
- }
- this.maxCapacity = maxCapacity;
- cacheMap = new ConcurrentHashMap<>(maxCapacity);
- keys = new ConcurrentLinkedQueue<>();
- scheduledExecutorService = Executors.newScheduledThreadPool(3);
- }
-
- public V put(K key, V value, long expireTime) {
- // 加写锁
- writeLock.lock();
- try {
- //1.key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- moveToTailOfQueue(key);
- cacheMap.put(key, value);
- return value;
- }
- //2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
- if (cacheMap.size() == maxCapacity) {
- System.out.println("maxCapacity of cache reached");
- removeOldestKey();
- }
- //3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
- keys.add(key);
- cacheMap.put(key, value);
- if (expireTime > 0) {
- removeAfterExpireTime(key, expireTime);
- }
- return value;
- } finally {
- writeLock.unlock();
- }
- }
-
- public V get(K key) {
- //加读锁
- readLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在的话就将key移动到队列的尾部
- moveToTailOfQueue(key);
- return cacheMap.get(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- readLock.unlock();
- }
- }
-
- public V remove(K key) {
- writeLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在移除队列和Map中对应的Key
- keys.remove(key);
- return cacheMap.remove(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- writeLock.unlock();
- }
- }
-
- /**
- * 将元素添加到队列的尾部(put/get的时候执行)
- */
- private void moveToTailOfQueue(K key) {
- keys.remove(key);
- keys.add(key);
- }
-
- /**
- * 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
- */
- private void removeOldestKey() {
- K oldestKey = keys.poll();
- if (oldestKey != null) {
- cacheMap.remove(oldestKey);
- }
- }
-
- private void removeAfterExpireTime(K key, long expireTime) {
- scheduledExecutorService.schedule(() -> {
- //过期后清除该键值对
- cacheMap.remove(key);
- keys.remove(key);
- }, expireTime, TimeUnit.MILLISECONDS);
- }
-
- public int size() {
- return cacheMap.size();
- }
-
-}
-
-```
-
-**测试效果:**
-
-```java
-MyLruCacheWithExpireTime myLruCache = new MyLruCacheWithExpireTime<>(3);
-myLruCache.put(1,"Java",3000);
-myLruCache.put(2,"C++",3000);
-myLruCache.put(3,"Python",1500);
-System.out.println(myLruCache.size());//3
-Thread.sleep(2000);
-System.out.println(myLruCache.size());//2
-```
diff --git "a/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md" "b/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md"
index d5cb29de7a9..c8263de02e2 100644
--- "a/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md"
+++ "b/docs/java/jvm/JDK\347\233\221\346\216\247\345\222\214\346\225\205\351\232\234\345\244\204\347\220\206\345\267\245\345\205\267\346\200\273\347\273\223.md"
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [JDK 监控和故障处理工具总结](#jdk-监控和故障处理工具总结)
@@ -325,13 +323,3 @@ VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java
-
-
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md" "b/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
index 655266a7814..b979285a59d 100644
--- "a/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
+++ "b/docs/java/jvm/JVM\345\236\203\345\234\276\345\233\236\346\224\266.md"
@@ -1,39 +1,45 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
+
+
+
+
- [JVM 垃圾回收](#jvm-垃圾回收)
- - [写在前面](#写在前面)
- - [本节常见面试题](#本节常见面试题)
- - [本文导火索](#本文导火索)
- - [1 揭开 JVM 内存分配与回收的神秘面纱](#1--揭开-jvm-内存分配与回收的神秘面纱)
- - [1.1 对象优先在 eden 区分配](#11-对象优先在-eden-区分配)
- - [1.2 大对象直接进入老年代](#12-大对象直接进入老年代)
- - [1.3 长期存活的对象将进入老年代](#13-长期存活的对象将进入老年代)
- - [1.4 动态对象年龄判定](#14-动态对象年龄判定)
- - [2 对象已经死亡?](#2-对象已经死亡)
- - [2.1 引用计数法](#21-引用计数法)
- - [2.2 可达性分析算法](#22-可达性分析算法)
- - [2.3 再谈引用](#23-再谈引用)
- - [2.4 不可达的对象并非“非死不可”](#24-不可达的对象并非非死不可)
- - [2.5 如何判断一个常量是废弃常量](#25-如何判断一个常量是废弃常量)
- - [2.6 如何判断一个类是无用的类](#26-如何判断一个类是无用的类)
- - [3 垃圾收集算法](#3-垃圾收集算法)
- - [3.1 标记-清除算法](#31-标记-清除算法)
- - [3.2 复制算法](#32-复制算法)
- - [3.3 标记-整理算法](#33-标记-整理算法)
- - [3.4 分代收集算法](#34-分代收集算法)
- - [4 垃圾收集器](#4-垃圾收集器)
- - [4.1 Serial 收集器](#41-serial-收集器)
- - [4.2 ParNew 收集器](#42-parnew-收集器)
- - [4.3 Parallel Scavenge 收集器](#43-parallel-scavenge-收集器)
- - [4.4.Serial Old 收集器](#44serial-old-收集器)
- - [4.5 Parallel Old 收集器](#45-parallel-old-收集器)
- - [4.6 CMS 收集器](#46-cms-收集器)
- - [4.7 G1 收集器](#47-g1-收集器)
- - [参考](#参考)
-
-
+ - [写在前面](#写在前面)
+ - [本节常见面试题](#本节常见面试题)
+ - [本文导火索](#本文导火索)
+ - [1 揭开 JVM 内存分配与回收的神秘面纱](#1-揭开-jvm-内存分配与回收的神秘面纱)
+ - [1.1 对象优先在 eden 区分配](#11-对象优先在-eden-区分配)
+ - [1.2 大对象直接进入老年代](#12-大对象直接进入老年代)
+ - [1.3 长期存活的对象将进入老年代](#13-长期存活的对象将进入老年代)
+ - [1.4 动态对象年龄判定](#14-动态对象年龄判定)
+ - [1.5 主要进行 gc 的区域](#15-主要进行-gc-的区域)
+ - [2 对象已经死亡?](#2-对象已经死亡)
+ - [2.1 引用计数法](#21-引用计数法)
+ - [2.2 可达性分析算法](#22-可达性分析算法)
+ - [2.3 再谈引用](#23-再谈引用)
+ - [2.4 不可达的对象并非“非死不可”](#24-不可达的对象并非非死不可)
+ - [2.5 如何判断一个常量是废弃常量?](#25-如何判断一个常量是废弃常量)
+ - [2.6 如何判断一个类是无用的类](#26-如何判断一个类是无用的类)
+ - [3 垃圾收集算法](#3-垃圾收集算法)
+ - [3.1 标记-清除算法](#31-标记-清除算法)
+ - [3.2 复制算法](#32-复制算法)
+ - [3.3 标记-整理算法](#33-标记-整理算法)
+ - [3.4 分代收集算法](#34-分代收集算法)
+ - [4 垃圾收集器](#4-垃圾收集器)
+ - [4.1 Serial 收集器](#41-serial-收集器)
+ - [4.2 ParNew 收集器](#42-parnew-收集器)
+ - [4.3 Parallel Scavenge 收集器](#43-parallel-scavenge-收集器)
+ - [4.4.Serial Old 收集器](#44serial-old-收集器)
+ - [4.5 Parallel Old 收集器](#45-parallel-old-收集器)
+ - [4.6 CMS 收集器](#46-cms-收集器)
+ - [4.7 G1 收集器](#47-g1-收集器)
+ - [4.8 ZGC 收集器](#48-zgc-收集器)
+ - [参考](#参考)
+
+
+
+
# JVM 垃圾回收
## 写在前面
@@ -58,7 +64,7 @@
当需要排查各种内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
-## 1 揭开 JVM 内存分配与回收的神秘面纱
+## 1 揭开 JVM 内存分配与回收的神秘面纱
Java 的自动内存管理主要是针对对象内存的回收和对象内存的分配。同时,Java 自动内存管理最核心的功能是 **堆** 内存中对象的分配与回收。
@@ -70,9 +76,9 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
上图所示的 Eden 区、From Survivor0("From") 区、To Survivor1("To") 区都属于新生代,Old Memory 区属于老年代。
-大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
+大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
-> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值”。
+> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
>
> **动态年龄计算的代码如下**
>
@@ -90,12 +96,10 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> }
->
-> ```
>
->
+> ```
-经过这次GC后,Eden区和"From"区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次GC前的“From”,新的"From"就是上次GC前的"To"。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到老年代中。
+经过这次 GC 后,Eden 区和"From"区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次 GC 前的“From”,新的"From"就是上次 GC 前的"To"。不管怎样,都会保证名为 To 的 Survivor 区域是空的。Minor GC 会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到老年代中。

@@ -105,13 +109,6 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
大多数情况下,对象在新生代中 eden 区分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.下面我们来进行实际测试以下。
-在测试之前我们先来看看 **Minor GC 和 Full GC 有什么不同呢?**
-
-- **新生代 GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
-- **老年代 GC(Major GC/Full GC)**:指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
-
-> [issue#664 ](https://github.com/Snailclimb/JavaGuide/issues/664) :**[guang19](https://github.com/guang19)** 补充:个人在网上查阅相关资料的时候发现如题所说的观点。有的文章说 Major GC 与 Full GC 一样是属于对老年代的GC,也有的文章说 Major GC 是对整个堆区的GC,所以这点需要各位同学自行分辨 Major GC 语义。见: [知乎讨论](https://www.zhihu.com/question/41922036)
-
**测试:**
```java
@@ -124,6 +121,7 @@ public class GCTest {
}
}
```
+
通过以下方式运行:

@@ -139,6 +137,7 @@ public class GCTest {
```java
allocation2 = new byte[900*1024];
```
+
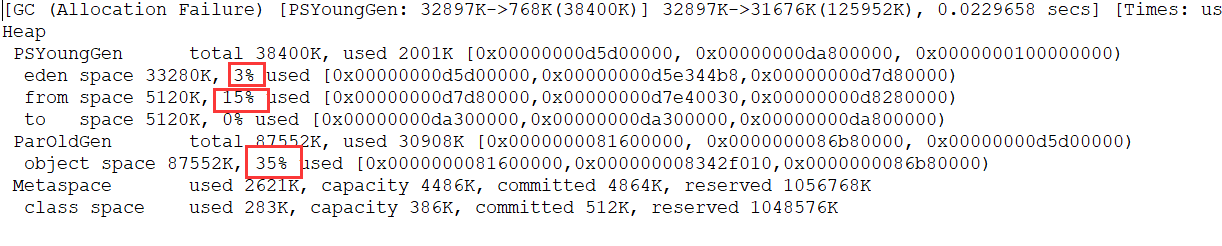
**简单解释一下为什么会出现这种情况:** 因为给 allocation2 分配内存的时候 eden 区内存几乎已经被分配完了,我们刚刚讲了当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.GC 期间虚拟机又发现 allocation1 无法存入 Survivor 空间,所以只好通过 **分配担保机制** 把新生代的对象提前转移到老年代中去,老年代上的空间足够存放 allocation1,所以不会出现 Full GC。执行 Minor GC 后,后面分配的对象如果能够存在 eden 区的话,还是会在 eden 区分配内存。可以执行如下代码验证:
@@ -158,8 +157,8 @@ public class GCTest {
```
-
### 1.2 大对象直接进入老年代
+
大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
**为什么要这样呢?**
@@ -167,16 +166,16 @@ public class GCTest {
为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
### 1.3 长期存活的对象将进入老年代
+
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这一点,虚拟机给每个对象一个对象年龄(Age)计数器。
如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并将对象年龄设为 1.对象在 Survivor 中每熬过一次 MinorGC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
### 1.4 动态对象年龄判定
+大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
-大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
-
-> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值”。
+> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
>
> **动态年龄计算的代码如下**
>
@@ -194,14 +193,35 @@ public class GCTest {
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> }
->
+>
> ```
>
-> 额外补充说明([issue672](https://github.com/Snailclimb/JavaGuide/issues/672)):**关于默认的晋升年龄是15,这个说法的来源大部分都是《深入理解Java虚拟机》这本书。**
-> 如果你去Oracle的官网阅读[相关的虚拟机参数](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html),你会发现`-XX:MaxTenuringThreshold=threshold`这里有个说明
+> 额外补充说明([issue672](https://github.com/Snailclimb/JavaGuide/issues/672)):**关于默认的晋升年龄是 15,这个说法的来源大部分都是《深入理解 Java 虚拟机》这本书。**
+> 如果你去 Oracle 的官网阅读[相关的虚拟机参数](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html),你会发现`-XX:MaxTenuringThreshold=threshold`这里有个说明
>
-> **Sets the maximum tenuring threshold for use in adaptive GC sizing. The largest value is 15. The default value is 15 for the parallel (throughput) collector, and 6 for the CMS collector.默认晋升年龄并不都是15,这个是要区分垃圾收集器的,CMS就是6.**
+> **Sets the maximum tenuring threshold for use in adaptive GC sizing. The largest value is 15. The default value is 15 for the parallel (throughput) collector, and 6 for the CMS collector.默认晋升年龄并不都是 15,这个是要区分垃圾收集器的,CMS 就是 6.**
+
+### 1.5 主要进行 gc 的区域
+
+周志明先生在《深入理解 Java 虚拟机》第二版中 P92 如是写道:
+> ~~_“老年代 GC(Major GC/Full GC),指发生在老年代的 GC……”_~~
+
+上面的说法已经在《深入理解 Java 虚拟机》第三版中被改正过来了。感谢 R 大的回答:
+
+
+
+**总结:**
+
+针对 HotSpot VM 的实现,它里面的 GC 其实准确分类只有两大种:
+
+部分收集 (Partial GC):
+
+- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
+- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
+- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
+
+整堆收集 (Full GC):收集整个 Java 堆和方法区。
## 2 对象已经死亡?
@@ -230,19 +250,18 @@ public class ReferenceCountingGc {
}
```
-
-
### 2.2 可达性分析算法
这个算法的基本思想就是通过一系列的称为 **“GC Roots”** 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。

-可作为GC Roots的对象包括下面几种:
-* 虚拟机栈(栈帧中的本地变量表)中引用的对象
-* 本地方法栈(Native方法)中引用的对象
-* 方法区中类静态属性引用的对象
-* 方法区中常量引用的对象
+可作为 GC Roots 的对象包括下面几种:
+
+- 虚拟机栈(栈帧中的本地变量表)中引用的对象
+- 本地方法栈(Native 方法)中引用的对象
+- 方法区中类静态属性引用的对象
+- 方法区中常量引用的对象
### 2.3 再谈引用
@@ -264,7 +283,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
**3.弱引用(WeakReference)**
-如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
+如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
@@ -274,7 +293,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
**虚引用主要用来跟踪对象被垃圾回收的活动**。
-**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
+**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
@@ -288,7 +307,15 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
-假如在常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池。
+~~**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**~~
+
+> 修正([issue747](https://github.com/Snailclimb/JavaGuide/issues/747),[reference](https://blog.csdn.net/q5706503/article/details/84640762)):
+>
+> 1. **JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时 hotspot 虚拟机对方法区的实现为永久代**
+> 2. **JDK1.7 字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是 hotspot 中的永久代** 。
+> 3. **JDK1.8 hotspot 移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)**
+
+假如在字符串常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池了。
### 2.6 如何判断一个类是无用的类
@@ -297,12 +324,11 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 **“无用的类”** :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
-- 加载该类的 ClassLoader 已经被回收。
-- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
+- 加载该类的 `ClassLoader` 已经被回收。
+- 该类对应的 `java.lang.Class` 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
-
## 3 垃圾收集算法

@@ -320,7 +346,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
- +
### 3.3 标记-整理算法
@@ -346,11 +372,12 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
-
### 4.1 Serial 收集器
-Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
- **新生代采用复制算法,老年代采用标记-整理算法。**
+Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
+
+**新生代采用复制算法,老年代采用标记-整理算法。**
+

虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
@@ -358,9 +385,11 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
### 4.2 ParNew 收集器
+
**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
- **新生代采用复制算法,老年代采用标记-整理算法。**
+**新生代采用复制算法,老年代采用标记-整理算法。**
+

它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
@@ -371,13 +400,12 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
-
### 4.3 Parallel Scavenge 收集器
-Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和ParNew都一样。 **那么它有什么特别之处呢?**
+Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 **那么它有什么特别之处呢?**
```
--XX:+UseParallelGC
+-XX:+UseParallelGC
使用 Parallel 收集器+ 老年代串行
@@ -387,17 +415,32 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
```
-**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
+
+**新生代采用复制算法,老年代采用标记-整理算法。**
- **新生代采用复制算法,老年代采用标记-整理算法。**

+**这是 JDK1.8 默认收集器**
+
+使用 java -XX:+PrintCommandLineFlags -version 命令查看
+
+```
+-XX:InitialHeapSize=262921408 -XX:MaxHeapSize=4206742528 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
+java version "1.8.0_211"
+Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
+Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
+```
+
+JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old,如果指定了-XX:+UseParallelGC 参数,则默认指定了-XX:+UseParallelOldGC,可以使用-XX:-UseParallelOldGC 来禁用该功能
### 4.4.Serial Old 收集器
+
**Serial 收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
### 4.5 Parallel Old 收集器
- **Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
+
+**Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
### 4.6 CMS 收集器
@@ -422,7 +465,6 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
### 4.7 G1 收集器
-
**G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.**
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
@@ -432,7 +474,6 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
- **空间整合**:与 CMS 的“标记--清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
-
G1 收集器的运作大致分为以下几个步骤:
- **初始标记**
@@ -440,32 +481,18 @@ G1 收集器的运作大致分为以下几个步骤:
- **最终标记**
- **筛选回收**
-
**G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)**。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
-## 参考
-
-- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
-- https://my.oschina.net/hosee/blog/644618
--
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
-
-
-
-
-
+### 4.8 ZGC 收集器
+与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
+在 ZGC 中出现 Stop The World 的情况会更少!
+详情可以看 : [《新一代垃圾回收器 ZGC 的探索与实践》](https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html)
+## 参考
+- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
+- https://my.oschina.net/hosee/blog/644618
+-
diff --git "a/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md" "b/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
index 0cae9f0a7f8..1909ad3bbf4 100644
--- "a/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
+++ "b/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [Java 内存区域详解](#java-内存区域详解)
@@ -125,7 +123,7 @@ Java 方法有两种返回方式:
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
-方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。
+方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 `StackOverFlowError` 和 `OutOfMemoryError` 两种错误。
### 2.4 堆
@@ -306,14 +304,16 @@ JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**
### 3.3 对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
-1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
+1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
- 
+ 
2. **直接指针:** 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。

+
+
**这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。**
@@ -413,7 +413,7 @@ private static class CharacterCache {
}
```
-两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。**
+两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
```java
Integer i1 = 33;
@@ -492,13 +492,3 @@ i4=i5+i6 true
-
-
- 深入解析String#intern
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md" "b/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md"
index 91c1da9a7cb..db8ee340ca0 100644
--- "a/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md"
+++ "b/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md"
@@ -8,7 +8,7 @@
JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,一种规范。通过在实际的计算机上仿真模拟各类计算机功能实现···
-好,其实抛开这么专业的句子不说,就知道JVM其实就类似于一台小电脑运行在windows或者linux这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,可操作系统可以帮我们完成和硬件进行交互的工作。
+好,其实抛开这么专业的句子不说,就知道JVM其实就类似于一台小电脑运行在windows或者linux这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,而操作系统可以帮我们完成和硬件进行交互的工作。
### 1.1 Java文件是如何被运行的
@@ -101,10 +101,10 @@ GC将无用对象从内存中卸载
加载一个Class类的顺序也是有优先级的,类加载器从最底层开始往上的顺序是这样的
1. BootStrap ClassLoader:rt.jar
-2. Extention ClassLoader: 加载扩展的jar包
+2. Extension ClassLoader: 加载扩展的jar包
3. App ClassLoader:指定的classpath下面的jar包
4. Custom ClassLoader:自定义的类加载器
-
+
### 2.3 双亲委派机制
当一个类收到了加载请求时,它是不会先自己去尝试加载的,而是委派给父类去完成,比如我现在要new一个Person,这个Person是我们自定义的类,如果我们要加载它,就会先委派App ClassLoader,只有当父类加载器都反馈自己无法完成这个请求(也就是父类加载器都没有找到加载所需的Class)时,子类加载器才会自行尝试加载
@@ -131,7 +131,7 @@ GC将无用对象从内存中卸载
### 3.2 方法区
-方法区主要的作用技术存放类的元数据信息,常量和静态变量···等。当它存储的信息过大时,会在无法满足内存分配时报错。
+方法区主要的作用是存放类的元数据信息,常量和静态变量···等。当它存储的信息过大时,会在无法满足内存分配时报错。
### 3.3 虚拟机栈和虚拟机堆
@@ -190,7 +190,7 @@ JVM内存会划分为堆内存和非堆内存,堆内存中也会划分为**年
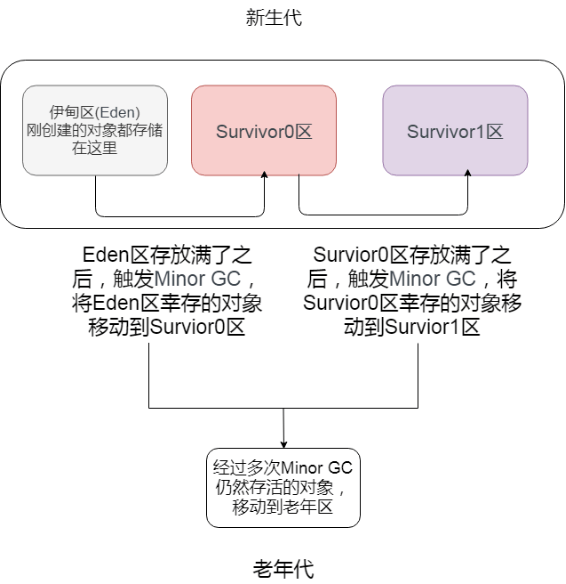
当Eden空间满了之后,会触发一个叫做Minor GC(就是一个发生在年轻代的GC)的操作,存活下来的对象移动到Survivor0区。Survivor0区满后触发 Minor GC,就会将存活对象移动到Survivor1区,此时还会把from和to两个指针交换,这样保证了一段时间内总有一个survivor区为空且to所指向的survivor区为空。经过多次的 Minor GC后仍然存活的对象(**这里的存活判断是15次,对应到虚拟机参数为 -XX:MaxTenuringThreshold 。为什么是15,因为HotSpot会在对象投中的标记字段里记录年龄,分配到的空间仅有4位,所以最多只能记录到15**)会移动到老年代。老年代是存储长期存活的对象的,占满时就会触发我们最常听说的Full GC,期间会停止所有线程等待GC的完成。所以对于响应要求高的应用应该尽量去减少发生Full GC从而避免响应超时的问题。
-而且当老年区执行了full gc之后仍然无法进行对象保存的操作,就会产生OOM,这时候就是虚拟机中的堆内存不足,原因可能会是堆内存设置的大小过小,这个可以通过参数-Xms、-Xms来调整。也可能是代码中创建的对象大且多,而且它们一直在被引用从而长时间垃圾收集无法收集它们。
+而且当老年区执行了full gc之后仍然无法进行对象保存的操作,就会产生OOM,这时候就是虚拟机中的堆内存不足,原因可能会是堆内存设置的大小过小,这个可以通过参数-Xms、-Xmx来调整。也可能是代码中创建的对象大且多,而且它们一直在被引用从而长时间垃圾收集无法收集它们。
@@ -297,7 +297,7 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | |
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 |
-| -Xss | 每个线程的堆栈大小 | | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长)和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了
+| -Xss | 每个线程的堆栈大小 | | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.根据应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长)和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | |-XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | |设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
| -XX:+DisableExplicitGC | 关闭System.gc() | |这个参数需要严格的测试
@@ -319,7 +319,7 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。简单点来说,你不停地往堆内存里面丢数据,等它剩余大小小于40%了,JVM就会动态申请内存空间不过会小于-Xmx,如果剩余大小大于70%,又会动态缩小不过不会小于–Xms。就这么简单
-开发过程中,通常会将 -Xms 与 -Xmx两个参数的配置相同的值,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源。
+开发过程中,通常会将 -Xms 与 -Xmx两个参数配置成相同的值,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源。
我们执行下面的代码
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png"
new file mode 100644
index 00000000000..88b494732af
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png"
index 145bd405c21..f954d8a7375 100644
Binary files "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" differ
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index 1d0a826f152..37394a92444 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [回顾一下类加载过程](#回顾一下类加载过程)
@@ -134,13 +132,5 @@ protected Class loadClass(String name, boolean resolve)
-
-
-### 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
index 9330c58166a..41ee988043a 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
@@ -1,7 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
-
- [类的生命周期](#类的生命周期)
@@ -39,7 +35,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
-虚拟机规范多上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
+虚拟机规范上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
**一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。**
@@ -72,7 +68,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
### 初始化
-初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 ` ()`方法的过程。
+初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行初始化方法 ` ()`方法的过程。
对于`()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
@@ -104,7 +100,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
所以,在JVM生命周期类,由jvm自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
-只要想通一点就好了,jdk自带的BootstrapClassLoader,PlatformClassLoader,AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
+只要想通一点就好了,jdk自带的BootstrapClassLoader,ExtClassLoader,AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
**参考**
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index fe282352150..852b4c4dd8f 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -46,7 +46,7 @@ ClassFile {
u2 interfaces_count;//接口
u2 interfaces[interfaces_count];//一个类可以实现多个接口
u2 fields_count;//Class 文件的字段属性
- field_info fields[fields_count];//一个类会可以有个字段
+ field_info fields[fields_count];//一个类会可以有多个字段
u2 methods_count;//Class 文件的方法数量
method_info methods[methods_count];//一个类可以有个多个方法
u2 attributes_count;//此类的属性表中的属性数
@@ -149,7 +149,7 @@ public class Employee {
**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
-**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按`implents`(如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
+**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
### 2.6 字段表集合
@@ -172,9 +172,9 @@ public class Employee {
上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型这些都是无法固定的,只能引用常量池中常量来描述。
-**字段的 access_flags 的取值:**
+**字段的 access_flag 的取值:**
-
+
### 2.7 方法表集合
@@ -183,7 +183,7 @@ public class Employee {
method_info methods[methods_count];//一个类可以有个多个方法
```
-methods_count 表示方法的数量,而 method_info 表示的方法表。
+methods_count 表示方法的数量,而 method_info 表示方法表。
Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。
@@ -193,7 +193,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
**方法表的 access_flag 取值:**
-
+
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
@@ -212,13 +212,3 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
-
-
- 《实战 Java 虚拟机》
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
similarity index 93%
rename from docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
rename to "docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index c987d1497d1..76a3a9768fa 100644
--- a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -84,7 +84,7 @@ public class MultiThread {
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
-**总结:** 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
+**总结:** **线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。**
下面是该知识点的扩展内容!
@@ -279,18 +279,18 @@ Process finished with exit code 0
## 9. 说说 sleep() 方法和 wait() 方法区别和共同点?
-- 两者最主要的区别在于:**sleep 方法没有释放锁,而 wait 方法释放了锁** 。
+- 两者最主要的区别在于:**`sleep()` 方法没有释放锁,而 `wait()` 方法释放了锁** 。
- 两者都可以暂停线程的执行。
-- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
-- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。
+- `wait()` 通常被用于线程间交互/通信,`sleep() `通常被用于暂停执行。
+- `wait()` 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 `notify() `或者 `notifyAll()` 方法。`sleep() `方法执行完成后,线程会自动苏醒。或者可以使用 `wait(long timeout)` 超时后线程会自动苏醒。
## 10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
-new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
+new 一个 Thread,线程进入了新建状态。调用 `start()`方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 `start()` 会执行线程的相应准备工作,然后自动执行 ` run() ` 方法的内容,这是真正的多线程工作。 但是,直接执行 `run()` 方法,会把 `run()` 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
-**总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。**
+**总结: 调用 `start()` 方法方可启动线程并使线程进入就绪状态,直接执行 `run()` 方法的话不会以多线程的方式执行。**
## 公众号
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..7097b672686
--- /dev/null
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,1119 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
+
+
+
+
+
+
+- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
+ - [1.synchronized 关键字](#1synchronized-关键字)
+ - [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
+ - [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
+ - [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
+ - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
+ - [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
+ - [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
+ - [1.3.3.总结](#133总结)
+ - [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
+ - [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
+ - [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
+ - [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
+ - [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
+ - [2. volatile 关键字](#2-volatile-关键字)
+ - [2.1. CPU 缓存模型](#21-cpu-缓存模型)
+ - [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
+ - [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
+ - [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
+ - [3. ThreadLocal](#3-threadlocal)
+ - [3.1. ThreadLocal 简介](#31-threadlocal-简介)
+ - [3.2. ThreadLocal 示例](#32-threadlocal-示例)
+ - [3.3. ThreadLocal 原理](#33-threadlocal-原理)
+ - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
+ - [4. 线程池](#4-线程池)
+ - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
+ - [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
+ - [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
+ - [4.4. 如何创建线程池](#44-如何创建线程池)
+ - [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
+ - [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
+ - [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
+ - [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
+ - [4.7 线程池原理分析](#47-线程池原理分析)
+ - [5. Atomic 原子类](#5-atomic-原子类)
+ - [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
+ - [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
+ - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
+ - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
+ - [6. AQS](#6-aqs)
+ - [6.1. AQS 介绍](#61-aqs-介绍)
+ - [6.2. AQS 原理分析](#62-aqs-原理分析)
+ - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
+ - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
+ - [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
+ - [6.3. AQS 组件总结](#63-aqs-组件总结)
+ - [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
+ - [7 Reference](#7-reference)
+ - [公众号](#公众号)
+
+
+
+
+# Java 并发进阶常见面试题总结
+
+## 1.synchronized 关键字
+
+
+
+### 1.1.说一说自己对于 synchronized 关键字的了解
+
+**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
+
+另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
+
+**为什么呢?**
+
+因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
+
+庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 `synchronized` 较大优化,所以现在的 `synchronized` 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
+
+所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 `synchronized` 关键字。
+
+### 1.2. 说说自己是怎么使用 synchronized 关键字
+
+**synchronized 关键字最主要的三种使用方式:**
+
+**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+
+```java
+synchronized void method() {
+ //业务代码
+}
+```
+
+**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
+
+```java
+synchronized void staic method() {
+ //业务代码
+}
+```
+
+**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
+
+```java
+synchronized(this) {
+ //业务代码
+}
+```
+
+**总结:**
+
+- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
+- `synchronized` 关键字加到实例方法上是给对象实例上锁。
+- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
+
+下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
+
+面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
+
+**双重校验锁实现对象单例(线程安全)**
+
+```java
+public class Singleton {
+
+ private volatile static Singleton uniqueInstance;
+
+ private Singleton() {
+ }
+
+ public static Singleton getUniqueInstance() {
+ //先判断对象是否已经实例过,没有实例化过才进入加锁代码
+ if (uniqueInstance == null) {
+ //类对象加锁
+ synchronized (Singleton.class) {
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ }
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
+
+`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
+
+1. 为 `uniqueInstance` 分配内存空间
+2. 初始化 `uniqueInstance`
+3. 将 `uniqueInstance` 指向分配的内存地址
+
+但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
+
+使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+
+### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
+
+先说结论:**构造方法不能使用 synchronized 关键字修饰。**
+
+构造方法本身就属于线程安全的,不存在同步的构造方法一说。
+
+### 1.3. 讲一下 synchronized 关键字的底层原理
+
+**synchronized 关键字底层原理属于 JVM 层面。**
+
+#### 1.3.1. synchronized 同步语句块的情况
+
+```java
+public class SynchronizedDemo {
+ public void method() {
+ synchronized (this) {
+ System.out.println("synchronized 代码块");
+ }
+ }
+}
+
+```
+
+通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
+
+
+
+从上面我们可以看出:
+
+**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
+
+当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
+
+> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
+>
+> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
+
+在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
+
+在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
+
+#### 1.3.2. `synchronized` 修饰方法的的情况
+
+```java
+public class SynchronizedDemo2 {
+ public synchronized void method() {
+ System.out.println("synchronized 方法");
+ }
+}
+
+```
+
+
+
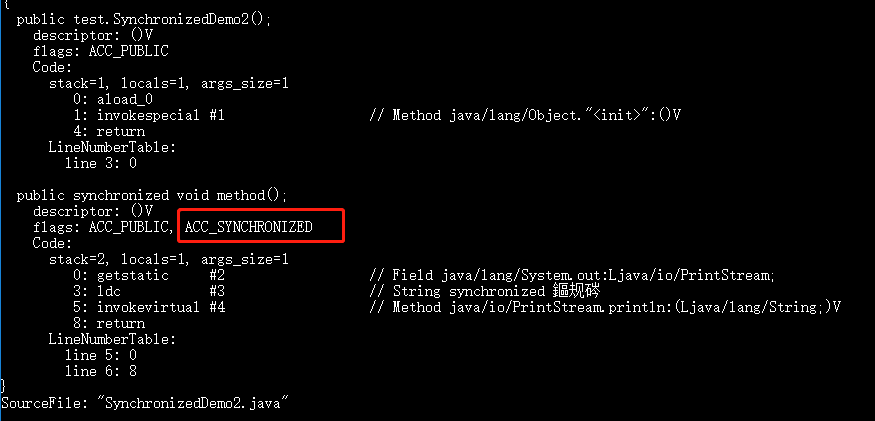
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
+
+#### 1.3.3.总结
+
+`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
+
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
+
+**不过两者的本质都是对对象监视器 monitor 的获取。**
+
+### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
+
+JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
+
+锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
+
+关于这几种优化的详细信息可以查看下面这几篇文章:
+
+- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
+- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
+
+### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
+
+#### 1.5.1. 两者都是可重入锁
+
+**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
+
+#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
+
+`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
+
+#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
+
+相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
+
+- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
+- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
+- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
+
+> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
+
+**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
+
+## 2. volatile 关键字
+
+我们先要从 **CPU 缓存模型** 说起!
+
+### 2.1. CPU 缓存模型
+
+**为什么要弄一个 CPU 高速缓存呢?**
+
+类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
+
+我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
+
+总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
+
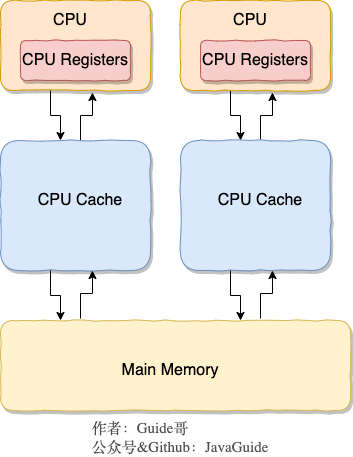
+为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
+
+
+
+**CPU Cache 的工作方式:**
+
+先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
+
+**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
+
+### 2.2. 讲一下 JMM(Java 内存模型)
+
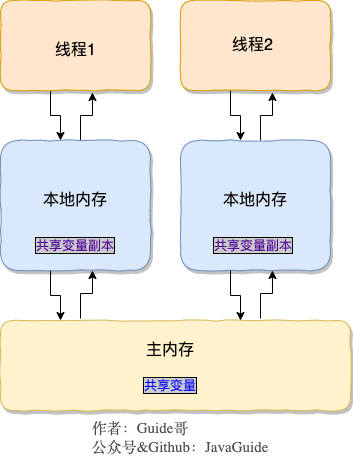
+在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
+
+
+
+要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
+
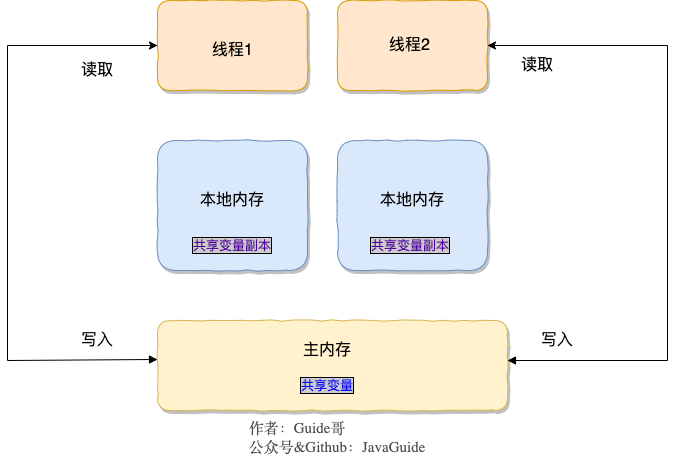
+所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
+
+
+
+### 2.3. 并发编程的三个重要特性
+
+1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
+2. **可见性** :当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
+3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
+
+### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
+
+`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
+
+- **`volatile` 关键字**是线程同步的**轻量级实现**,所以**`volatile `性能肯定比` synchronized `关键字要好**。但是**`volatile` 关键字只能用于变量而 `synchronized` 关键字可以修饰方法以及代码块**。
+- **`volatile` 关键字能保证数据的可见性,但不能保证数据的原子性。`synchronized` 关键字两者都能保证。**
+- **`volatile`关键字主要用于解决变量在多个线程之间的可见性,而 `synchronized` 关键字解决的是多个线程之间访问资源的同步性。**
+
+## 3. ThreadLocal
+
+### 3.1. ThreadLocal 简介
+
+通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
+
+**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
+
+再举个简单的例子:
+
+比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
+
+### 3.2. ThreadLocal 示例
+
+相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
+
+```java
+import java.text.SimpleDateFormat;
+import java.util.Random;
+
+public class ThreadLocalExample implements Runnable{
+
+ // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
+ private static final ThreadLocal formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
+
+ public static void main(String[] args) throws InterruptedException {
+ ThreadLocalExample obj = new ThreadLocalExample();
+ for(int i=0 ; i<10; i++){
+ Thread t = new Thread(obj, ""+i);
+ Thread.sleep(new Random().nextInt(1000));
+ t.start();
+ }
+ }
+
+ @Override
+ public void run() {
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
+ try {
+ Thread.sleep(new Random().nextInt(1000));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ //formatter pattern is changed here by thread, but it won't reflect to other threads
+ formatter.set(new SimpleDateFormat());
+
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
+ }
+
+}
+
+```
+
+Output:
+
+```
+Thread Name= 0 default Formatter = yyyyMMdd HHmm
+Thread Name= 0 formatter = yy-M-d ah:mm
+Thread Name= 1 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 default Formatter = yyyyMMdd HHmm
+Thread Name= 1 formatter = yy-M-d ah:mm
+Thread Name= 3 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 formatter = yy-M-d ah:mm
+Thread Name= 4 default Formatter = yyyyMMdd HHmm
+Thread Name= 3 formatter = yy-M-d ah:mm
+Thread Name= 4 formatter = yy-M-d ah:mm
+Thread Name= 5 default Formatter = yyyyMMdd HHmm
+Thread Name= 5 formatter = yy-M-d ah:mm
+Thread Name= 6 default Formatter = yyyyMMdd HHmm
+Thread Name= 6 formatter = yy-M-d ah:mm
+Thread Name= 7 default Formatter = yyyyMMdd HHmm
+Thread Name= 7 formatter = yy-M-d ah:mm
+Thread Name= 8 default Formatter = yyyyMMdd HHmm
+Thread Name= 9 default Formatter = yyyyMMdd HHmm
+Thread Name= 8 formatter = yy-M-d ah:mm
+Thread Name= 9 formatter = yy-M-d ah:mm
+```
+
+从输出中可以看出,Thread-0 已经改变了 formatter 的值,但仍然是 thread-2 默认格式化程序与初始化值相同,其他线程也一样。
+
+上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
+
+```java
+ private static final ThreadLocal formatter = new ThreadLocal(){
+ @Override
+ protected SimpleDateFormat initialValue()
+ {
+ return new SimpleDateFormat("yyyyMMdd HHmm");
+ }
+ };
+```
+
+### 3.3. ThreadLocal 原理
+
+从 `Thread`类源代码入手。
+
+```java
+public class Thread implements Runnable {
+ ......
+//与此线程有关的ThreadLocal值。由ThreadLocal类维护
+ThreadLocal.ThreadLocalMap threadLocals = null;
+
+//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
+ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
+ ......
+}
+```
+
+从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是 null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set()`方法。
+
+`ThreadLocal`类的`set()`方法
+
+```java
+ public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+ }
+ ThreadLocalMap getMap(Thread t) {
+ return t.threadLocals;
+ }
+```
+
+通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
+
+**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为 key ,Object 对象为 value 的键值对。**
+
+```java
+ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
+ ......
+}
+```
+
+比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
+
+
+
+`ThreadLocalMap`是`ThreadLocal`的静态内部类。
+
+
+
+### 3.4. ThreadLocal 内存泄露问题
+
+`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
+
+```java
+ static class Entry extends WeakReference> {
+ /** The value associated with this ThreadLocal. */
+ Object value;
+
+ Entry(ThreadLocal k, Object v) {
+ super(k);
+ value = v;
+ }
+ }
+```
+
+**弱引用介绍:**
+
+> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
+>
+> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
+
+## 4. 线程池
+
+### 4.1. 为什么要用线程池?
+
+> **池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
+
+**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
+
+这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
+
+- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
+- **提高响应速度**。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
+- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
+
+### 4.2. 实现 Runnable 接口和 Callable 接口的区别
+
+`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
+
+工具类 `Executors` 可以实现 `Runnable` 对象和 `Callable` 对象之间的相互转换。(`Executors.callable(Runnable task`)或 `Executors.callable(Runnable task,Object resule)`)。
+
+`Runnable.java`
+
+```java
+@FunctionalInterface
+public interface Runnable {
+ /**
+ * 被线程执行,没有返回值也无法抛出异常
+ */
+ public abstract void run();
+}
+```
+
+`Callable.java`
+
+```java
+@FunctionalInterface
+public interface Callable {
+ /**
+ * 计算结果,或在无法这样做时抛出异常。
+ * @return 计算得出的结果
+ * @throws 如果无法计算结果,则抛出异常
+ */
+ V call() throws Exception;
+}
+```
+
+### 4.3. 执行 execute()方法和 submit()方法的区别是什么呢?
+
+1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
+2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
+
+我们以**`AbstractExecutorService`**接口中的一个 `submit` 方法为例子来看看源代码:
+
+```java
+ public Future submit(Runnable task) {
+ if (task == null) throw new NullPointerException();
+ RunnableFuture ftask = newTaskFor(task, null);
+ execute(ftask);
+ return ftask;
+ }
+```
+
+上面方法调用的 `newTaskFor` 方法返回了一个 `FutureTask` 对象。
+
+```java
+ protected RunnableFuture newTaskFor(Runnable runnable, T value) {
+ return new FutureTask(runnable, value);
+ }
+```
+
+我们再来看看`execute()`方法:
+
+```java
+ public void execute(Runnable command) {
+ ...
+ }
+```
+
+### 4.4. 如何创建线程池
+
+《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
+
+> Executors 返回线程池对象的弊端如下:
+>
+> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致 OOM。
+> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
+
+**方式一:通过构造方法实现**
+
+**方式二:通过 Executor 框架的工具类 Executors 来实现**
+我们可以创建三种类型的 ThreadPoolExecutor:
+
+- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
+- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
+- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
+
+对应 Executors 工具类中的方法如图所示:
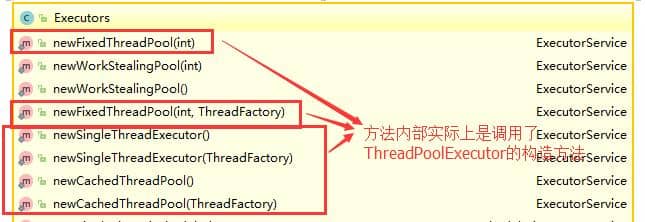
+
+
+### 4.5 ThreadPoolExecutor 类分析
+
+`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
+
+```java
+ /**
+ * 用给定的初始参数创建一个新的ThreadPoolExecutor。
+ */
+ public ThreadPoolExecutor(int corePoolSize,
+ int maximumPoolSize,
+ long keepAliveTime,
+ TimeUnit unit,
+ BlockingQueue workQueue,
+ ThreadFactory threadFactory,
+ RejectedExecutionHandler handler) {
+ if (corePoolSize < 0 ||
+ maximumPoolSize <= 0 ||
+ maximumPoolSize < corePoolSize ||
+ keepAliveTime < 0)
+ throw new IllegalArgumentException();
+ if (workQueue == null || threadFactory == null || handler == null)
+ throw new NullPointerException();
+ this.corePoolSize = corePoolSize;
+ this.maximumPoolSize = maximumPoolSize;
+ this.workQueue = workQueue;
+ this.keepAliveTime = unit.toNanos(keepAliveTime);
+ this.threadFactory = threadFactory;
+ this.handler = handler;
+ }
+```
+
+**下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。**
+
+#### 4.5.1 `ThreadPoolExecutor`构造函数重要参数分析
+
+**`ThreadPoolExecutor` 3 个最重要的参数:**
+
+- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
+- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
+
+`ThreadPoolExecutor`其他常见参数:
+
+1. **`keepAliveTime`**:当线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁;
+2. **`unit`** : `keepAliveTime` 参数的时间单位。
+3. **`threadFactory`** :executor 创建新线程的时候会用到。
+4. **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
+
+#### 4.5.2 `ThreadPoolExecutor` 饱和策略
+
+**`ThreadPoolExecutor` 饱和策略定义:**
+
+如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
+
+- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
+- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
+- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
+
+举个例子: Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)
+
+### 4.6 一个简单的线程池 Demo
+
+为了让大家更清楚上面的面试题中的一些概念,我写了一个简单的线程池 Demo。
+
+首先创建一个 `Runnable` 接口的实现类(当然也可以是 `Callable` 接口,我们上面也说了两者的区别。)
+
+`MyRunnable.java`
+
+```java
+import java.util.Date;
+
+/**
+ * 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
+ * @author shuang.kou
+ */
+public class MyRunnable implements Runnable {
+
+ private String command;
+
+ public MyRunnable(String s) {
+ this.command = s;
+ }
+
+ @Override
+ public void run() {
+ System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
+ processCommand();
+ System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
+ }
+
+ private void processCommand() {
+ try {
+ Thread.sleep(5000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+
+ @Override
+ public String toString() {
+ return this.command;
+ }
+}
+
+```
+
+编写测试程序,我们这里以阿里巴巴推荐的使用 `ThreadPoolExecutor` 构造函数自定义参数的方式来创建线程池。
+
+`ThreadPoolExecutorDemo.java`
+
+```java
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+
+public class ThreadPoolExecutorDemo {
+
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ for (int i = 0; i < 10; i++) {
+ //创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
+ Runnable worker = new MyRunnable("" + i);
+ //执行Runnable
+ executor.execute(worker);
+ }
+ //终止线程池
+ executor.shutdown();
+ while (!executor.isTerminated()) {
+ }
+ System.out.println("Finished all threads");
+ }
+}
+
+```
+
+可以看到我们上面的代码指定了:
+
+1. `corePoolSize`: 核心线程数为 5。
+2. `maximumPoolSize` :最大线程数 10
+3. `keepAliveTime` : 等待时间为 1L。
+4. `unit`: 等待时间的单位为 TimeUnit.SECONDS。
+5. `workQueue`:任务队列为 `ArrayBlockingQueue`,并且容量为 100;
+6. `handler`:饱和策略为 `CallerRunsPolicy`。
+
+**Output:**
+
+```
+pool-1-thread-2 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-5 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-4 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-1 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-3 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-5 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-3 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-2 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-4 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-1 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-2 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-1 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-4 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-3 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-5 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-2 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-3 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-4 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-5 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
+
+```
+
+### 4.7 线程池原理分析
+
+承接 4.6 节,我们通过代码输出结果可以看出:**线程池每次会同时执行 5 个任务,这 5 个任务执行完之后,剩余的 5 个任务才会被执行。** 大家可以先通过上面讲解的内容,分析一下到底是咋回事?(自己独立思考一会)
+
+现在,我们就分析上面的输出内容来简单分析一下线程池原理。
+
+**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。**在 4.6 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
+
+```java
+ // 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
+ private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
+
+ private static int workerCountOf(int c) {
+ return c & CAPACITY;
+ }
+
+ private final BlockingQueue workQueue;
+
+ public void execute(Runnable command) {
+ // 如果任务为null,则抛出异常。
+ if (command == null)
+ throw new NullPointerException();
+ // ctl 中保存的线程池当前的一些状态信息
+ int c = ctl.get();
+
+ // 下面会涉及到 3 步 操作
+ // 1.首先判断当前线程池中之行的任务数量是否小于 corePoolSize
+ // 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ if (workerCountOf(c) < corePoolSize) {
+ if (addWorker(command, true))
+ return;
+ c = ctl.get();
+ }
+ // 2.如果当前之行的任务数量大于等于 corePoolSize 的时候就会走到这里
+ // 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去
+ if (isRunning(c) && workQueue.offer(command)) {
+ int recheck = ctl.get();
+ // 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
+ if (!isRunning(recheck) && remove(command))
+ reject(command);
+ // 如果当前线程池为空就新创建一个线程并执行。
+ else if (workerCountOf(recheck) == 0)
+ addWorker(null, false);
+ }
+ //3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ //如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
+ else if (!addWorker(command, false))
+ reject(command);
+ }
+```
+
+通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
+
+
+
+现在,让我们在回到 4.6 节我们写的 Demo, 现在应该是不是很容易就可以搞懂它的原理了呢?
+
+没搞懂的话,也没关系,可以看看我的分析:
+
+> 我们在代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的 5 个任务会被放到等待队列中去。当前的 5 个任务之行完成后,才会之行剩下的 5 个任务。
+
+## 5. Atomic 原子类
+
+### 5.1. 介绍一下 Atomic 原子类
+
+`Atomic` 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
+
+所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
+
+并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
+
+
+
+### 5.2. JUC 包中的原子类是哪 4 类?
+
+**基本类型**
+
+使用原子的方式更新基本类型
+
+- `AtomicInteger`:整形原子类
+- `AtomicLong`:长整型原子类
+- `AtomicBoolean`:布尔型原子类
+
+**数组类型**
+
+使用原子的方式更新数组里的某个元素
+
+- `AtomicIntegerArray`:整形数组原子类
+- `AtomicLongArray`:长整形数组原子类
+- `AtomicReferenceArray`:引用类型数组原子类
+
+**引用类型**
+
+- `AtomicReference`:引用类型原子类
+- `AtomicStampedReference`:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- `AtomicMarkableReference` :原子更新带有标记位的引用类型
+
+**对象的属性修改类型**
+
+- `AtomicIntegerFieldUpdater`:原子更新整形字段的更新器
+- `AtomicLongFieldUpdater`:原子更新长整形字段的更新器
+- `AtomicReferenceFieldUpdater`:原子更新引用类型字段的更新器
+
+### 5.3. 讲讲 AtomicInteger 的使用
+
+**AtomicInteger 类常用方法**
+
+```java
+public final int get() //获取当前的值
+public final int getAndSet(int newValue)//获取当前的值,并设置新的值
+public final int getAndIncrement()//获取当前的值,并自增
+public final int getAndDecrement() //获取当前的值,并自减
+public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
+boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
+public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
+```
+
+**AtomicInteger 类的使用示例**
+
+使用 AtomicInteger 之后,不用对 increment() 方法加锁也可以保证线程安全。
+
+```java
+class AtomicIntegerTest {
+ private AtomicInteger count = new AtomicInteger();
+ //使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
+ public void increment() {
+ count.incrementAndGet();
+ }
+
+ public int getCount() {
+ return count.get();
+ }
+}
+
+```
+
+### 5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理
+
+AtomicInteger 线程安全原理简单分析
+
+AtomicInteger 类的部分源码:
+
+```java
+ // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
+ private static final Unsafe unsafe = Unsafe.getUnsafe();
+ private static final long valueOffset;
+
+ static {
+ try {
+ valueOffset = unsafe.objectFieldOffset
+ (AtomicInteger.class.getDeclaredField("value"));
+ } catch (Exception ex) { throw new Error(ex); }
+ }
+
+ private volatile int value;
+```
+
+AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
+
+CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
+
+关于 Atomic 原子类这部分更多内容可以查看我的这篇文章:并发编程面试必备:[JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s/joa-yOiTrYF67bElj8xqvg)
+
+## 6. AQS
+
+### 6.1. AQS 介绍
+
+AQS 的全称为(`AbstractQueuedSynchronizer`),这个类在` java.util.concurrent.locks `包下面。
+
+
+
+AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 `ReentrantLock`,`Semaphore`,其他的诸如 `ReentrantReadWriteLock`,`SynchronousQueue`,`FutureTask` 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
+
+### 6.2. AQS 原理分析
+
+AQS 原理这部分参考了部分博客,在 5.2 节末尾放了链接。
+
+> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于 AQS 原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
+
+下面大部分内容其实在 AQS 类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
+
+#### 6.2.1. AQS 原理概览
+
+**AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
+
+> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
+
+看个 AQS(AbstractQueuedSynchronizer)原理图:
+
+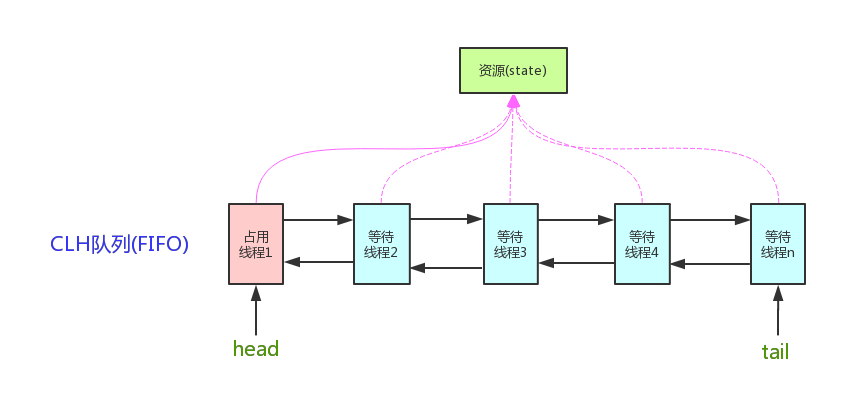
+
+AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
+
+```java
+private volatile int state;//共享变量,使用volatile修饰保证线程可见性
+```
+
+状态信息通过 protected 类型的 getState,setState,compareAndSetState 进行操作
+
+```java
+
+//返回同步状态的当前值
+protected final int getState() {
+ return state;
+}
+ // 设置同步状态的值
+protected final void setState(int newState) {
+ state = newState;
+}
+//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
+protected final boolean compareAndSetState(int expect, int update) {
+ return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
+}
+```
+
+#### 6.2.2. AQS 对资源的共享方式
+
+**AQS 定义两种资源共享方式**
+
+- **Exclusive**(独占):只有一个线程能执行,如 `ReentrantLock`。又可分为公平锁和非公平锁:
+ - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
+ - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
+- **Share**(共享):多个线程可同时执行,如` CountDownLatch`、`Semaphore`、`CountDownLatch`、 `CyclicBarrier`、`ReadWriteLock` 我们都会在后面讲到。
+
+`ReentrantReadWriteLock` 可以看成是组合式,因为 `ReentrantReadWriteLock` 也就是读写锁允许多个线程同时对某一资源进行读。
+
+不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
+
+#### 6.2.3. AQS 底层使用了模板方法模式
+
+同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
+
+1. 使用者继承 `AbstractQueuedSynchronizer` 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
+2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
+
+这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
+
+**AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:**
+
+```java
+isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
+tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
+tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
+tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
+tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
+
+```
+
+默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
+
+以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
+
+再以 `CountDownLatch` 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后` countDown()` 一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 `await()` 函数返回,继续后余动作。
+
+一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
+
+推荐两篇 AQS 原理和相关源码分析的文章:
+
+- http://www.cnblogs.com/waterystone/p/4920797.html
+- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
+
+### 6.3. AQS 组件总结
+
+- **`Semaphore`(信号量)-允许多个线程同时访问:** `synchronized` 和 `ReentrantLock` 都是一次只允许一个线程访问某个资源,`Semaphore`(信号量)可以指定多个线程同时访问某个资源。
+- **`CountDownLatch `(倒计时器):** `CountDownLatch` 是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
+- **`CyclicBarrier`(循环栅栏):** `CyclicBarrier` 和 `CountDownLatch` 非常类似,它也可以实现线程间的技术等待,但是它的功能比 `CountDownLatch` 更加复杂和强大。主要应用场景和 `CountDownLatch` 类似。`CyclicBarrier` 的字面意思是可循环使用(`Cyclic`)的屏障(`Barrier`)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。`CyclicBarrier` 默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用 `await()` 方法告诉 `CyclicBarrier` 我已经到达了屏障,然后当前线程被阻塞。
+
+### 6.4. 用过 CountDownLatch 么?什么场景下用的?
+
+`CountDownLatch` 的作用就是 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。之前在项目中,有一个使用多线程读取多个文件处理的场景,我用到了 `CountDownLatch` 。具体场景是下面这样的:
+
+我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。
+
+为此我们定义了一个线程池和 count 为 6 的`CountDownLatch`对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用`CountDownLatch`对象的 `await()`方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
+
+伪代码是下面这样的:
+
+```java
+public class CountDownLatchExample1 {
+ // 处理文件的数量
+ private static final int threadCount = 6;
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
+ ExecutorService threadPool = Executors.newFixedThreadPool(10);
+ final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
+ for (int i = 0; i < threadCount; i++) {
+ final int threadnum = i;
+ threadPool.execute(() -> {
+ try {
+ //处理文件的业务操作
+ ......
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ //表示一个文件已经被完成
+ countDownLatch.countDown();
+ }
+
+ });
+ }
+ countDownLatch.await();
+ threadPool.shutdown();
+ System.out.println("finish");
+ }
+
+}
+```
+
+**有没有可以改进的地方呢?**
+
+可以使用 `CompletableFuture` 类来改进!Java8 的 `CompletableFuture` 提供了很多对多线程友好的方法,使用它可以很方便地为我们编写多线程程序,什么异步、串行、并行或者等待所有线程执行完任务什么的都非常方便。
+
+```java
+CompletableFuture task1 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+CompletableFuture task6 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+ CompletableFuture headerFuture=CompletableFuture.allOf(task1,.....,task6);
+
+ try {
+ headerFuture.join();
+ } catch (Exception ex) {
+ ......
+ }
+System.out.println("all done. ");
+```
+
+上面的代码还可以接续优化,当任务过多的时候,把每一个 task 都列出来不太现实,可以考虑通过循环来添加任务。
+
+```java
+//文件夹位置
+List filePaths = Arrays.asList(...)
+// 异步处理所有文件
+List> fileFutures = filePaths.stream()
+ .map(filePath -> doSomeThing(filePath))
+ .collect(Collectors.toList());
+// 将他们合并起来
+CompletableFuture allFutures = CompletableFuture.allOf(
+ fileFutures.toArray(new CompletableFuture[fileFutures.size()])
+);
+
+```
+
+## 7 Reference
+
+- 《深入理解 Java 虚拟机》
+- 《实战 Java 高并发程序设计》
+- 《Java 并发编程的艺术》
+- http://www.cnblogs.com/waterystone/p/4920797.html
+- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
+-
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
+
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
diff --git a/docs/java/Multithread/AQS.md "b/docs/java/multi-thread/AQS\345\216\237\347\220\206\344\273\245\345\217\212AQS\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md"
similarity index 100%
rename from docs/java/Multithread/AQS.md
rename to "docs/java/multi-thread/AQS\345\216\237\347\220\206\344\273\245\345\217\212AQS\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md"
diff --git a/docs/java/Multithread/Atomic.md "b/docs/java/multi-thread/Atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md"
similarity index 100%
rename from docs/java/Multithread/Atomic.md
rename to "docs/java/multi-thread/Atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md"
diff --git "a/docs/java/Multithread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md" "b/docs/java/multi-thread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md"
similarity index 100%
rename from "docs/java/Multithread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md"
rename to "docs/java/multi-thread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md"
diff --git "a/docs/java/Multithread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png" "b/docs/java/multi-thread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
similarity index 100%
rename from "docs/java/Multithread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
rename to "docs/java/multi-thread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
diff --git "a/docs/java/multi-thread/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png" "b/docs/java/multi-thread/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png"
new file mode 100644
index 00000000000..24ac1a8cc26
Binary files /dev/null and "b/docs/java/multi-thread/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png"
new file mode 100644
index 00000000000..8b2ede8ab54
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png"
new file mode 100644
index 00000000000..87658aa3f09
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png"
new file mode 100644
index 00000000000..5cc148dd79a
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png"
new file mode 100644
index 00000000000..fc1c7034fdf
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png"
new file mode 100644
index 00000000000..c56521d283e
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png"
new file mode 100644
index 00000000000..bae0dc5b2dc
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png"
new file mode 100644
index 00000000000..c933674fad4
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png"
new file mode 100644
index 00000000000..30c298591bc
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png"
new file mode 100644
index 00000000000..6aebd60b591
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png"
new file mode 100644
index 00000000000..bc661944a0a
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png"
new file mode 100644
index 00000000000..d609943bafe
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png" differ
diff --git a/docs/java/Multithread/images/thread-local/1.png b/docs/java/multi-thread/images/thread-local/1.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/1.png
rename to docs/java/multi-thread/images/thread-local/1.png
diff --git a/docs/java/Multithread/images/thread-local/10.png b/docs/java/multi-thread/images/thread-local/10.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/10.png
rename to docs/java/multi-thread/images/thread-local/10.png
diff --git a/docs/java/Multithread/images/thread-local/11.png b/docs/java/multi-thread/images/thread-local/11.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/11.png
rename to docs/java/multi-thread/images/thread-local/11.png
diff --git a/docs/java/Multithread/images/thread-local/12.png b/docs/java/multi-thread/images/thread-local/12.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/12.png
rename to docs/java/multi-thread/images/thread-local/12.png
diff --git a/docs/java/Multithread/images/thread-local/13.png b/docs/java/multi-thread/images/thread-local/13.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/13.png
rename to docs/java/multi-thread/images/thread-local/13.png
diff --git a/docs/java/Multithread/images/thread-local/14.png b/docs/java/multi-thread/images/thread-local/14.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/14.png
rename to docs/java/multi-thread/images/thread-local/14.png
diff --git a/docs/java/Multithread/images/thread-local/15.png b/docs/java/multi-thread/images/thread-local/15.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/15.png
rename to docs/java/multi-thread/images/thread-local/15.png
diff --git a/docs/java/Multithread/images/thread-local/16.png b/docs/java/multi-thread/images/thread-local/16.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/16.png
rename to docs/java/multi-thread/images/thread-local/16.png
diff --git a/docs/java/Multithread/images/thread-local/17.png b/docs/java/multi-thread/images/thread-local/17.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/17.png
rename to docs/java/multi-thread/images/thread-local/17.png
diff --git a/docs/java/Multithread/images/thread-local/18.png b/docs/java/multi-thread/images/thread-local/18.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/18.png
rename to docs/java/multi-thread/images/thread-local/18.png
diff --git a/docs/java/Multithread/images/thread-local/19.png b/docs/java/multi-thread/images/thread-local/19.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/19.png
rename to docs/java/multi-thread/images/thread-local/19.png
diff --git a/docs/java/Multithread/images/thread-local/2.png b/docs/java/multi-thread/images/thread-local/2.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/2.png
rename to docs/java/multi-thread/images/thread-local/2.png
diff --git a/docs/java/Multithread/images/thread-local/20.png b/docs/java/multi-thread/images/thread-local/20.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/20.png
rename to docs/java/multi-thread/images/thread-local/20.png
diff --git a/docs/java/Multithread/images/thread-local/21.png b/docs/java/multi-thread/images/thread-local/21.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/21.png
rename to docs/java/multi-thread/images/thread-local/21.png
diff --git a/docs/java/Multithread/images/thread-local/22.png b/docs/java/multi-thread/images/thread-local/22.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/22.png
rename to docs/java/multi-thread/images/thread-local/22.png
diff --git a/docs/java/Multithread/images/thread-local/23.png b/docs/java/multi-thread/images/thread-local/23.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/23.png
rename to docs/java/multi-thread/images/thread-local/23.png
diff --git a/docs/java/Multithread/images/thread-local/24.png b/docs/java/multi-thread/images/thread-local/24.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/24.png
rename to docs/java/multi-thread/images/thread-local/24.png
diff --git a/docs/java/Multithread/images/thread-local/25.png b/docs/java/multi-thread/images/thread-local/25.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/25.png
rename to docs/java/multi-thread/images/thread-local/25.png
diff --git a/docs/java/Multithread/images/thread-local/26.png b/docs/java/multi-thread/images/thread-local/26.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/26.png
rename to docs/java/multi-thread/images/thread-local/26.png
diff --git a/docs/java/Multithread/images/thread-local/27.png b/docs/java/multi-thread/images/thread-local/27.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/27.png
rename to docs/java/multi-thread/images/thread-local/27.png
diff --git a/docs/java/Multithread/images/thread-local/28.png b/docs/java/multi-thread/images/thread-local/28.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/28.png
rename to docs/java/multi-thread/images/thread-local/28.png
diff --git a/docs/java/Multithread/images/thread-local/29.png b/docs/java/multi-thread/images/thread-local/29.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/29.png
rename to docs/java/multi-thread/images/thread-local/29.png
diff --git a/docs/java/Multithread/images/thread-local/3.png b/docs/java/multi-thread/images/thread-local/3.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/3.png
rename to docs/java/multi-thread/images/thread-local/3.png
diff --git a/docs/java/Multithread/images/thread-local/30.png b/docs/java/multi-thread/images/thread-local/30.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/30.png
rename to docs/java/multi-thread/images/thread-local/30.png
diff --git a/docs/java/Multithread/images/thread-local/31.png b/docs/java/multi-thread/images/thread-local/31.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/31.png
rename to docs/java/multi-thread/images/thread-local/31.png
diff --git a/docs/java/Multithread/images/thread-local/4.png b/docs/java/multi-thread/images/thread-local/4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/4.png
rename to docs/java/multi-thread/images/thread-local/4.png
diff --git a/docs/java/Multithread/images/thread-local/5.png b/docs/java/multi-thread/images/thread-local/5.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/5.png
rename to docs/java/multi-thread/images/thread-local/5.png
diff --git a/docs/java/Multithread/images/thread-local/6.png b/docs/java/multi-thread/images/thread-local/6.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/6.png
rename to docs/java/multi-thread/images/thread-local/6.png
diff --git a/docs/java/Multithread/images/thread-local/7.png b/docs/java/multi-thread/images/thread-local/7.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/7.png
rename to docs/java/multi-thread/images/thread-local/7.png
diff --git a/docs/java/Multithread/images/thread-local/8.png b/docs/java/multi-thread/images/thread-local/8.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/8.png
rename to docs/java/multi-thread/images/thread-local/8.png
diff --git a/docs/java/Multithread/images/thread-local/9.png b/docs/java/multi-thread/images/thread-local/9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/9.png
rename to docs/java/multi-thread/images/thread-local/9.png
diff --git a/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png b/docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
rename to docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
diff --git a/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png b/docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
rename to docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
diff --git a/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png b/docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
rename to docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
diff --git a/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png b/docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
rename to docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
diff --git a/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png b/docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
rename to docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
diff --git a/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png b/docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
rename to docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
diff --git "a/docs/java/Multithread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png" "b/docs/java/multi-thread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
similarity index 100%
rename from "docs/java/Multithread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
rename to "docs/java/multi-thread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
diff --git "a/docs/java/Multithread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/docs/java/multi-thread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
similarity index 95%
rename from "docs/java/Multithread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
rename to "docs/java/multi-thread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
index 54f4b650aa2..2e904d5fde6 100644
--- "a/docs/java/Multithread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -91,13 +91,13 @@ public class ThreadPoolExecutor extends AbstractExecutorService
**`ScheduledThreadPoolExecutor` 类描述:**
```java
-//ScheduledExecutorService实现了ExecutorService接口
+//ScheduledExecutorService继承ExecutorService接口
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService
```
-
+
#### 3) 异步计算的结果(`Future`)
@@ -107,7 +107,7 @@ public class ScheduledThreadPoolExecutor
### 2.3 Executor 框架的使用示意图
-
+
1. **主线程首先要创建实现 `Runnable` 或者 `Callable` 接口的任务对象。**
2. **把创建完成的实现 `Runnable`/`Callable`接口的 对象直接交给 `ExecutorService` 执行**: `ExecutorService.execute(Runnable command)`)或者也可以把 `Runnable` 对象或`Callable` 对象提交给 `ExecutorService` 执行(`ExecutorService.submit(Runnable task)`或 `ExecutorService.submit(Callable task)`)。
@@ -167,7 +167,7 @@ public class ScheduledThreadPoolExecutor
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
-
+
**`ThreadPoolExecutor` 饱和策略定义:**
@@ -198,7 +198,7 @@ public class ScheduledThreadPoolExecutor
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
**方式一:通过`ThreadPoolExecutor`构造函数实现(推荐)**
-
+
**方式二:通过 Executor 框架的工具类 Executors 来实现**
我们可以创建三种类型的 ThreadPoolExecutor:
@@ -207,7 +207,7 @@ public class ScheduledThreadPoolExecutor
- **CachedThreadPool**
对应 Executors 工具类中的方法如图所示:
-
+
## 四 (重要)ThreadPoolExecutor 使用示例
@@ -341,7 +341,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
现在,我们就分析上面的输出内容来简单分析一下线程池原理。
-**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。**在 4.1 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
+**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。** 在 4.1 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
```java
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
@@ -388,7 +388,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
-
+
@@ -543,7 +543,7 @@ public interface Callable {
#### 4.3.2 `execute()` vs `submit()`
1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
-2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
+2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功** ,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
我们以**`AbstractExecutorService`**接口中的一个 `submit` 方法为例子来看看源代码:
@@ -705,7 +705,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
`FixedThreadPool` 的 `execute()` 方法运行示意图(该图片来源:《Java 并发编程的艺术》):
-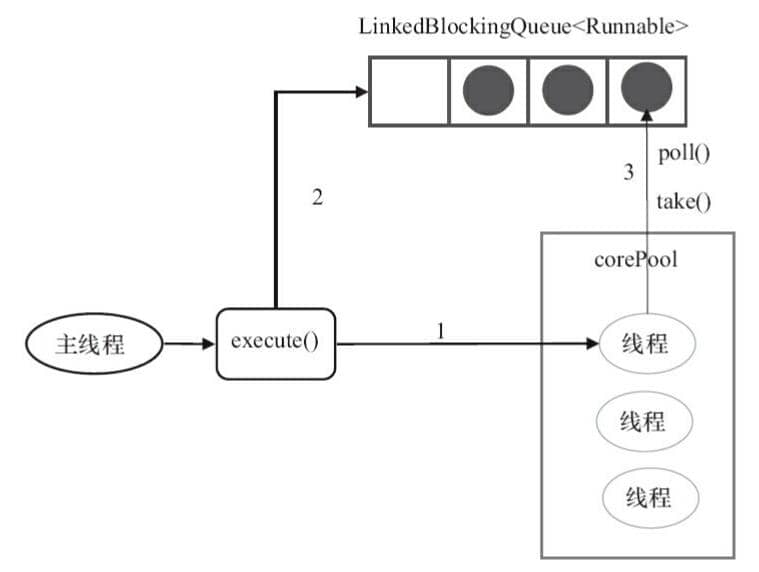
+
**上图说明:**
@@ -755,7 +755,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.2.2 执行任务过程介绍
**`SingleThreadExecutor` 的运行示意图(该图片来源:《Java 并发编程的艺术》):**
-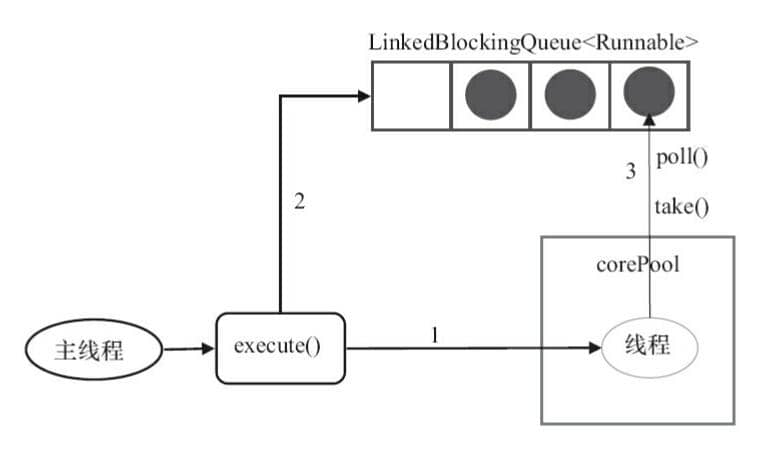
+
**上图说明;**
@@ -799,7 +799,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.3.2 执行任务过程介绍
**CachedThreadPool 的 execute()方法的执行示意图(该图片来源:《Java 并发编程的艺术》):**
-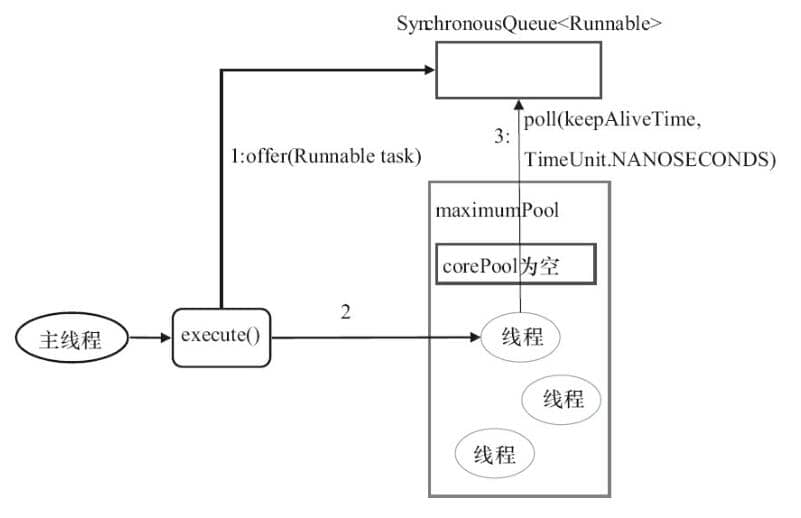
+
**上图说明:**
@@ -830,7 +830,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.2 运行机制
-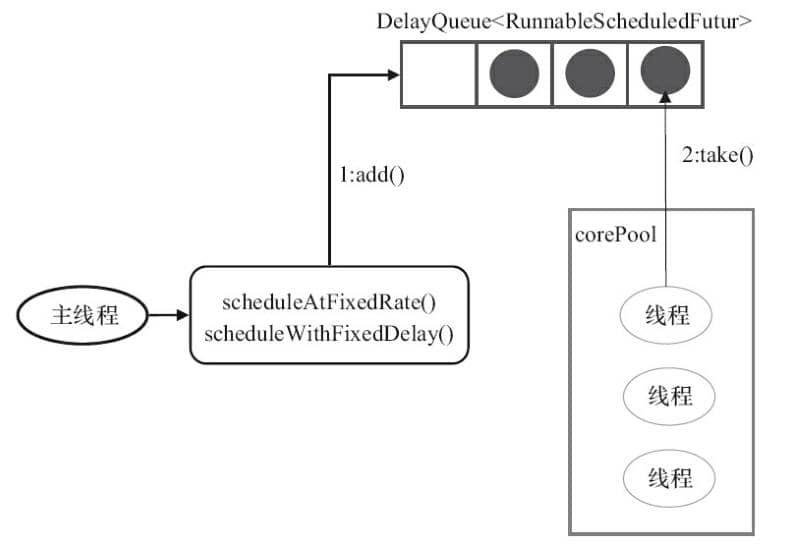
+
**`ScheduledThreadPoolExecutor` 的执行主要分为两大部分:**
@@ -845,7 +845,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.3 ScheduledThreadPoolExecutor 执行周期任务的步骤
-
+
1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask`的 time 大于等于当前系统的时间;
2. 线程 1 执行这个 `ScheduledFutureTask`;
diff --git "a/docs/java/multi-thread/synchronized\345\234\250JDK1.6\344\271\213\345\220\216\347\232\204\345\272\225\345\261\202\344\274\230\345\214\226.md" "b/docs/java/multi-thread/synchronized\345\234\250JDK1.6\344\271\213\345\220\216\347\232\204\345\272\225\345\261\202\344\274\230\345\214\226.md"
new file mode 100644
index 00000000000..c3776c2da21
--- /dev/null
+++ "b/docs/java/multi-thread/synchronized\345\234\250JDK1.6\344\271\213\345\220\216\347\232\204\345\272\225\345\261\202\344\274\230\345\214\226.md"
@@ -0,0 +1,62 @@
+JDK1.6 对锁的实现引入了大量的优化来减少锁操作的开销,如: **偏向锁**、**轻量级锁**、**自旋锁**、**适应性自旋锁**、**锁消除**、**锁粗化** 等等技术。
+
+锁主要存在四中状态,依次是:
+
+1. 无锁状态
+2. 偏向锁状态
+3. 轻量级锁状态
+4. 重量级锁状态
+
+锁🔐会随着竞争的激烈而逐渐升级。
+
+另外,需要注意:**锁可以升级不可降级,即 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁是单向的。** 这种策略是为了提高获得锁和释放锁的效率。
+
+### 偏向锁
+
+**引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉**。
+
+偏向锁的“偏”就是偏心的偏,它的意思是会偏向于第一个获得它的线程,如果在接下来的执行中,该锁没有被其他线程获取,那么持有偏向锁的线程就不需要进行同步!(关于偏向锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。)
+
+#### 偏向锁的加锁
+
+当一个线程访问同步块并获取锁时, 会在锁对象的对象头和栈帧中的锁记录里存储锁偏向的线程ID, 以后该线程进入和退出同步块时不需要进行CAS操作来加锁和解锁, 只需要简单的测试一下锁对象的对象头的MarkWord里是否存储着指向当前线程的偏向锁(线程ID是当前线程), 如果测试成功, 表示线程已经获得了锁; 如果测试失败, 则需要再测试一下MarkWord中偏向锁的标识是否设置成1(表示当前是偏向锁), 如果没有设置, 则使用CAS竞争锁, 如果设置了, 则尝试使用CAS将锁对象的对象头的偏向锁指向当前线程.
+
+#### 偏向锁的撤销
+
+偏向锁使用了一种等到竞争出现才释放锁的机制, 所以当其他线程尝试竞争偏向锁时, 持有偏向锁的线程才会释放锁. 偏向锁的撤销需要等到全局安全点(在这个时间点上没有正在执行的字节码). 首先会暂停持有偏向锁的线程, 然后检查持有偏向锁的线程是否存活, 如果线程不处于活动状态, 则将锁对象的对象头设置为无锁状态; 如果线程仍然活着, 则锁对象的对象头中的MarkWord和栈中的锁记录要么重新偏向于其它线程要么恢复到无锁状态, 最后唤醒暂停的线程(释放偏向锁的线程).
+
+但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
+
+### 轻量级锁
+
+倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的)。**轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。** 关于轻量级锁的加锁和解锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
+
+**轻量级锁能够提升程序同步性能的依据是“对于绝大部分锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用 CAS 操作避免了使用互斥操作的开销。但如果存在锁竞争,除了互斥量开销外,还会额外发生CAS操作,因此在有锁竞争的情况下,轻量级锁比传统的重量级锁更慢!如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁!**
+
+### 自旋锁和自适应自旋
+
+轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
+
+互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。
+
+**一般线程持有锁的时间都不是太长,所以仅仅为了这一点时间去挂起线程/恢复线程是得不偿失的。** 所以,虚拟机的开发团队就这样去考虑:“我们能不能让后面来的请求获取锁的线程等待一会而不被挂起呢?看看持有锁的线程是否很快就会释放锁”。**为了让一个线程等待,我们只需要让线程执行一个忙循环(自旋),这项技术就叫做自旋**。
+
+百度百科对自旋锁的解释:
+
+> 何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
+
+自旋锁在 JDK1.6 之前其实就已经引入了,不过是默认关闭的,需要通过`--XX:+UseSpinning`参数来开启。JDK1.6及1.6之后,就改为默认开启的了。需要注意的是:自旋等待不能完全替代阻塞,因为它还是要占用处理器时间。如果锁被占用的时间短,那么效果当然就很好了!反之,相反!自旋等待的时间必须要有限度。如果自旋超过了限定次数任然没有获得锁,就应该挂起线程。**自旋次数的默认值是10次,用户可以修改`--XX:PreBlockSpin`来更改**。
+
+另外,**在 JDK1.6 中引入了自适应的自旋锁。自适应的自旋锁带来的改进就是:自旋的时间不在固定了,而是和前一次同一个锁上的自旋时间以及锁的拥有者的状态来决定,虚拟机变得越来越“聪明”了**。
+
+### 锁消除
+
+锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。
+
+### 锁粗化
+
+原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小,——只在共享数据的实际作用域才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待线程也能尽快拿到锁。
+
+大部分情况下,上面的原则都是没有问题的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,那么会带来很多不必要的性能消耗。
+
+
diff --git a/docs/java/Multithread/ThreadLocal.md "b/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
similarity index 95%
rename from docs/java/Multithread/ThreadLocal.md
rename to "docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
index 6383ef1dba8..211f7aeeca4 100644
--- a/docs/java/Multithread/ThreadLocal.md
+++ "b/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
@@ -35,7 +35,7 @@
public class ThreadLocalTest {
private List messages = Lists.newArrayList();
- public static final `ThreadLocal` holder = `ThreadLocal`.withInitial(ThreadLocalTest::new);
+ public static final ThreadLocal holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) {
holder.get().messages.add(message);
@@ -70,8 +70,7 @@ size: 0

-
-`Thread`类有一个类型为``ThreadLocal`.`ThreadLocalMap``的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
+`Thread`类有一个类型为`ThreadLocal.ThreadLocalMap`的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
`ThreadLocalMap`有自己的独立实现,可以简单地将它的`key`视作`ThreadLocal`,`value`为代码中放入的值(实际上`key`并不是`ThreadLocal`本身,而是它的一个**弱引用**)。
@@ -79,11 +78,11 @@ size: 0
`ThreadLocalMap`有点类似`HashMap`的结构,只是`HashMap`是由**数组+链表**实现的,而`ThreadLocalMap`中并没有**链表**结构。
-我们还要注意`Entry`, 它的`key`是``ThreadLocal` k` ,继承自`WeakReference, 也就是我们常说的弱引用类型。
+我们还要注意`Entry`, 它的`key`是`ThreadLocal k` ,继承自`WeakReference`, 也就是我们常说的弱引用类型。
### GC 之后key是否为null?
-回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在` `ThreadLocal`.get()`的时候,发生`GC`之后,`key`是否是`null`?
+回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在`ThreadLocal.get()`的时候,发生`GC`之后,`key`是否是`null`?
为了搞清楚这个问题,我们需要搞清楚`Java`的**四种引用类型**:
@@ -110,7 +109,7 @@ public class ThreadLocalDemo {
private static void test(String s,boolean isGC) {
try {
- new `ThreadLocal`<>().set(s);
+ new ThreadLocal<>().set(s);
if (isGC) {
System.gc();
}
@@ -118,11 +117,11 @@ public class ThreadLocalDemo {
Class clz = t.getClass();
Field field = clz.getDeclaredField("threadLocals");
field.setAccessible(true);
- Object `ThreadLocalMap` = field.get(t);
- Class tlmClass = `ThreadLocalMap`.getClass();
+ Object ThreadLocalMap = field.get(t);
+ Class tlmClass = ThreadLocalMap.getClass();
Field tableField = tlmClass.getDeclaredField("table");
tableField.setAccessible(true);
- Object[] arr = (Object[]) tableField.get(`ThreadLocalMap`);
+ Object[] arr = (Object[]) tableField.get(ThreadLocalMap);
for (Object o : arr) {
if (o != null) {
Class entryClass = o.getClass();
@@ -142,8 +141,8 @@ public class ThreadLocalDemo {
结果如下:
```java
-弱引用key:java.lang.`ThreadLocal`@433619b6,值:abc
-弱引用key:java.lang.`ThreadLocal`@418a15e3,值:java.lang.ref.SoftReference@bf97a12
+弱引用key:java.lang.ThreadLocal@433619b6,值:abc
+弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12
--gc后--
弱引用key:null,值:def
```
@@ -162,7 +161,7 @@ new ThreadLocal<>().set(s);
这个问题刚开始看,如果没有过多思考,**弱引用**,还有**垃圾回收**,那么肯定会觉得是`null`。
-其实是不对的,因为题目说的是在做 ``ThreadLocal`.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。
+其实是不对的,因为题目说的是在做 `ThreadLocal.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。

@@ -217,8 +216,8 @@ public class ThreadLocal {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
- static class `ThreadLocalMap` {
- `ThreadLocalMap`(`ThreadLocal` firstKey, Object firstValue) {
+ static class ThreadLocalMap {
+ ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
@@ -230,7 +229,7 @@ public class ThreadLocal {
}
```
-每当创建一个`ThreadLocal`对象,这个``ThreadLocal`.nextHashCode` 这个值就会增长 `0x61c88647` 。
+每当创建一个`ThreadLocal`对象,这个`ThreadLocal.nextHashCode` 这个值就会增长 `0x61c88647` 。
这个值很特殊,它是**斐波那契数** 也叫 **黄金分割数**。`hash`增量为 这个数字,带来的好处就是 `hash` **分布非常均匀**。
@@ -244,7 +243,7 @@ public class ThreadLocal {
> **注明:** 下面所有示例图中,**绿色块**`Entry`代表**正常数据**,**灰色块**代表`Entry`的`key`值为`null`,**已被垃圾回收**。**白色块**表示`Entry`为`null`。
-虽然`ThreadLocalMap`中使用了**黄金分隔数来**作为`hash`计算因子,大大减少了`Hash`冲突的概率,但是仍然会存在冲突。
+虽然`ThreadLocalMap`中使用了**黄金分割数来**作为`hash`计算因子,大大减少了`Hash`冲突的概率,但是仍然会存在冲突。
`HashMap`中解决冲突的方法是在数组上构造一个**链表**结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成**红黑树**。
@@ -403,7 +402,7 @@ private static int prevIndex(int i, int len) {
`java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry()`:
```java
-private void replaceStaleEntry(`ThreadLocal` key, Object value,
+private void replaceStaleEntry(ThreadLocal key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
@@ -687,7 +686,7 @@ private void resize() {

-我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于``ThreadLocal`1`,所以需要继续往后迭代查找。
+我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于`ThreadLocal1`,所以需要继续往后迭代查找。
迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
@@ -698,7 +697,7 @@ private void resize() {
`java.lang.ThreadLocal.ThreadLocalMap.getEntry()`:
```java
-private Entry getEntry(`ThreadLocal` key) {
+private Entry getEntry(ThreadLocal key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
@@ -707,7 +706,7 @@ private Entry getEntry(`ThreadLocal` key) {
return getEntryAfterMiss(key, i, e);
}
-private Entry getEntryAfterMiss(`ThreadLocal` key, int i, Entry e) {
+private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
diff --git "a/docs/java/Multithread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md" "b/docs/java/multi-thread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md"
similarity index 100%
rename from "docs/java/Multithread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md"
rename to "docs/java/multi-thread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md"
diff --git "a/docs/java/Multithread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md" "b/docs/java/multi-thread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md"
similarity index 100%
rename from "docs/java/Multithread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md"
rename to "docs/java/multi-thread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md"
diff --git "a/docs/java/Multithread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md" "b/docs/java/multi-thread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
similarity index 100%
rename from "docs/java/Multithread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
rename to "docs/java/multi-thread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
diff --git a/docs/java/Multithread/best-practice-of-threadpool.md "b/docs/java/multi-thread/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md"
similarity index 100%
rename from docs/java/Multithread/best-practice-of-threadpool.md
rename to "docs/java/multi-thread/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md"
diff --git "a/docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md" "b/docs/java/new-features/Java8foreach\346\214\207\345\215\227.md"
similarity index 100%
rename from "docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md"
rename to "docs/java/new-features/Java8foreach\346\214\207\345\215\227.md"
diff --git "a/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md" "b/docs/java/new-features/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
similarity index 100%
rename from "docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
rename to "docs/java/new-features/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
diff --git a/docs/java/What's New in JDK8/Java8Tutorial.md "b/docs/java/new-features/Java8\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
similarity index 98%
rename from docs/java/What's New in JDK8/Java8Tutorial.md
rename to "docs/java/new-features/Java8\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
index 01e71f5ea74..8cf809f75c8 100644
--- a/docs/java/What's New in JDK8/Java8Tutorial.md
+++ "b/docs/java/new-features/Java8\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
@@ -15,12 +15,12 @@
- [访问字段和静态变量](#访问字段和静态变量)
- [访问默认接口方法](#访问默认接口方法)
- [内置函数式接口\(Built-in Functional Interfaces\)](#内置函数式接口built-in-functional-interfaces)
- - [Predicates](#predicates)
- - [Functions](#functions)
- - [Suppliers](#suppliers)
- - [Consumers](#consumers)
- - [Comparators](#comparators)
- - [Optionals](#optionals)
+ - [Predicate](#predicate)
+ - [Function](#function)
+ - [Supplier](#supplier)
+ - [Consumer](#consumer)
+ - [Comparator](#comparator)
+ - [Optional](#optional)
- [Streams\(流\)](#streams流)
- [Filter\(过滤\)](#filter过滤)
- [Sorted\(排序\)](#sorted排序)
@@ -287,7 +287,7 @@ JDK 1.8 API包含许多内置函数式接口。 其中一些借口在老版本
但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
-#### Predicates
+#### Predicate
Predicate 接口是只有一个参数的返回布尔类型值的 **断言型** 接口。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非):
@@ -340,7 +340,7 @@ Predicate isEmpty = String::isEmpty;
Predicate isNotEmpty = isEmpty.negate();
```
-#### Functions
+#### Function
Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
@@ -382,7 +382,7 @@ Function backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123"
```
-#### Suppliers
+#### Supplier
Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
@@ -391,7 +391,7 @@ Supplier personSupplier = Person::new;
personSupplier.get(); // new Person
```
-#### Consumers
+#### Consumer
Consumer 接口表示要对单个输入参数执行的操作。
@@ -400,7 +400,7 @@ Consumer greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker"));
```
-#### Comparators
+#### Comparator
Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
@@ -414,9 +414,9 @@ comparator.compare(p1, p2); // > 0
comparator.reversed().compare(p1, p2); // < 0
```
-## Optionals
+## Optional
-Optionals不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optionals的工作原理。
+Optional不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optional的工作原理。
Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
diff --git a/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png "b/docs/java/new-features/images/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9~14 \347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247/java\347\211\210\346\234\254\345\217\221\345\270\203.png"
similarity index 100%
rename from docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png
rename to "docs/java/new-features/images/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9~14 \347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247/java\347\211\210\346\234\254\345\217\221\345\270\203.png"
diff --git a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md "b/docs/java/new-features/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9\345\210\26014\347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247.md"
similarity index 99%
rename from docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
rename to "docs/java/new-features/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9\345\210\26014\347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247.md"
index 5b193cd5cac..64d70b3abde 100644
--- a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
+++ "b/docs/java/new-features/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9\345\210\26014\347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247.md"
@@ -109,7 +109,7 @@ Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
-
+
### 字符串加强
diff --git a/docs/network/images/Cut-Trough-Switching_0.gif b/docs/network/images/Cut-Trough-Switching_0.gif
new file mode 100644
index 00000000000..170dc3bbb19
Binary files /dev/null and b/docs/network/images/Cut-Trough-Switching_0.gif differ
diff --git a/docs/network/images/isp.png b/docs/network/images/isp.png
new file mode 100644
index 00000000000..fe5c0e96adb
Binary files /dev/null and b/docs/network/images/isp.png differ
diff --git "a/docs/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png" "b/docs/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png"
new file mode 100644
index 00000000000..a2d24300fcb
Binary files /dev/null and "b/docs/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png" differ
diff --git "a/docs/network/images/\344\274\240\350\276\223\345\261\202.png" "b/docs/network/images/\344\274\240\350\276\223\345\261\202.png"
new file mode 100644
index 00000000000..192af24536b
Binary files /dev/null and "b/docs/network/images/\344\274\240\350\276\223\345\261\202.png" differ
diff --git "a/docs/network/images/\345\272\224\347\224\250\345\261\202.png" "b/docs/network/images/\345\272\224\347\224\250\345\261\202.png"
new file mode 100644
index 00000000000..31e1e447b73
Binary files /dev/null and "b/docs/network/images/\345\272\224\347\224\250\345\261\202.png" differ
diff --git "a/docs/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" "b/docs/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png"
new file mode 100644
index 00000000000..c2b51a7c589
Binary files /dev/null and "b/docs/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" differ
diff --git "a/docs/network/images/\347\211\251\347\220\206\345\261\202.png" "b/docs/network/images/\347\211\251\347\220\206\345\261\202.png"
new file mode 100644
index 00000000000..abb979261c1
Binary files /dev/null and "b/docs/network/images/\347\211\251\347\220\206\345\261\202.png" differ
diff --git "a/docs/network/images/\347\275\221\347\273\234\345\261\202.png" "b/docs/network/images/\347\275\221\347\273\234\345\261\202.png"
new file mode 100644
index 00000000000..376479d7989
Binary files /dev/null and "b/docs/network/images/\347\275\221\347\273\234\345\261\202.png" differ
diff --git "a/docs/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" "b/docs/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png"
new file mode 100644
index 00000000000..6af03daa96a
Binary files /dev/null and "b/docs/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" differ
diff --git "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
deleted file mode 100644
index a20e6f85be7..00000000000
--- "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
+++ /dev/null
@@ -1,420 +0,0 @@
-### 1. [计算机概述 ](#一计算机概述)
-### 2. [物理层 ](#二物理层)
-### 3. [数据链路层 ](#三数据链路层 )
-### 4. [网络层 ](#四网络层 )
-### 5. [运输层 ](#五运输层 )
-### 6. [应用层](#六应用层)
-
-
-## 一计算机概述
-### (1),基本术语
-
-#### 结点 (node):
-
- 网络中的结点可以是计算机,集线器,交换机或路由器等。
-#### 链路(link ):
-
- 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-#### 主机(host):
- 连接在因特网上的计算机.
-#### ISP(Internet Service Provider):
- 因特网服务提供者(提供商).
-#### IXP(Internet eXchange Point):
- 互联网交换点IXP的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。.
-#### RFC(Request For Comments)
- 意思是“请求评议”,包含了关于Internet几乎所有的重要的文字资料。
-#### 广域网WAN(Wide Area Network)
- 任务是通过长距离运送主机发送的数据
-#### 城域网MAN(Metropolitan Area Network)
- 用来将多个局域网进行互连
-
-#### 局域网LAN(Local Area Network)
- 学校或企业大多拥有多个互连的局域网
-#### 个人区域网PAN(Personal Area Network)
- 在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络
-#### 端系统(end system):
- 处在因特网边缘的部分即是连接在因特网上的所有的主机.
-#### 分组(packet ):
- 因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
-#### 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
-#### 带宽(bandwidth):
- 在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
-#### 吞吐量(throughput ):
- 表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
-
-### (2),重要知识点总结
-
- 1,计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。
-
- 2,小写字母i开头的internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。
-
-
+
### 3.3 标记-整理算法
@@ -346,11 +372,12 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
-
### 4.1 Serial 收集器
-Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
- **新生代采用复制算法,老年代采用标记-整理算法。**
+Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
+
+**新生代采用复制算法,老年代采用标记-整理算法。**
+

虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
@@ -358,9 +385,11 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
### 4.2 ParNew 收集器
+
**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
- **新生代采用复制算法,老年代采用标记-整理算法。**
+**新生代采用复制算法,老年代采用标记-整理算法。**
+

它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
@@ -371,13 +400,12 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
-
### 4.3 Parallel Scavenge 收集器
-Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和ParNew都一样。 **那么它有什么特别之处呢?**
+Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 **那么它有什么特别之处呢?**
```
--XX:+UseParallelGC
+-XX:+UseParallelGC
使用 Parallel 收集器+ 老年代串行
@@ -387,17 +415,32 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
```
-**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
+
+**新生代采用复制算法,老年代采用标记-整理算法。**
- **新生代采用复制算法,老年代采用标记-整理算法。**

+**这是 JDK1.8 默认收集器**
+
+使用 java -XX:+PrintCommandLineFlags -version 命令查看
+
+```
+-XX:InitialHeapSize=262921408 -XX:MaxHeapSize=4206742528 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
+java version "1.8.0_211"
+Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
+Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
+```
+
+JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old,如果指定了-XX:+UseParallelGC 参数,则默认指定了-XX:+UseParallelOldGC,可以使用-XX:-UseParallelOldGC 来禁用该功能
### 4.4.Serial Old 收集器
+
**Serial 收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
### 4.5 Parallel Old 收集器
- **Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
+
+**Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
### 4.6 CMS 收集器
@@ -422,7 +465,6 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
### 4.7 G1 收集器
-
**G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.**
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
@@ -432,7 +474,6 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
- **空间整合**:与 CMS 的“标记--清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
-
G1 收集器的运作大致分为以下几个步骤:
- **初始标记**
@@ -440,32 +481,18 @@ G1 收集器的运作大致分为以下几个步骤:
- **最终标记**
- **筛选回收**
-
**G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)**。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
-## 参考
-
-- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
-- https://my.oschina.net/hosee/blog/644618
--
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
-
-
-
-
-
+### 4.8 ZGC 收集器
+与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
+在 ZGC 中出现 Stop The World 的情况会更少!
+详情可以看 : [《新一代垃圾回收器 ZGC 的探索与实践》](https://tech.meituan.com/2020/08/06/new-zgc-practice-in-meituan.html)
+## 参考
+- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
+- https://my.oschina.net/hosee/blog/644618
+-
diff --git "a/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md" "b/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
index 0cae9f0a7f8..1909ad3bbf4 100644
--- "a/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
+++ "b/docs/java/jvm/Java\345\206\205\345\255\230\345\214\272\345\237\237.md"
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [Java 内存区域详解](#java-内存区域详解)
@@ -125,7 +123,7 @@ Java 方法有两种返回方式:
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
-方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。
+方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 `StackOverFlowError` 和 `OutOfMemoryError` 两种错误。
### 2.4 堆
@@ -306,14 +304,16 @@ JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**
### 3.3 对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
-1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
+1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
- 
+ 
2. **直接指针:** 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。

+
+
**这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。**
@@ -413,7 +413,7 @@ private static class CharacterCache {
}
```
-两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。**
+两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
```java
Integer i1 = 33;
@@ -492,13 +492,3 @@ i4=i5+i6 true
-
-
- 深入解析String#intern
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git "a/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md" "b/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md"
index 91c1da9a7cb..db8ee340ca0 100644
--- "a/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md"
+++ "b/docs/java/jvm/[\345\212\240\351\244\220]\345\244\247\347\231\275\350\257\235\345\270\246\344\275\240\350\256\244\350\257\206JVM.md"
@@ -8,7 +8,7 @@
JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,一种规范。通过在实际的计算机上仿真模拟各类计算机功能实现···
-好,其实抛开这么专业的句子不说,就知道JVM其实就类似于一台小电脑运行在windows或者linux这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,可操作系统可以帮我们完成和硬件进行交互的工作。
+好,其实抛开这么专业的句子不说,就知道JVM其实就类似于一台小电脑运行在windows或者linux这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,而操作系统可以帮我们完成和硬件进行交互的工作。

### 1.1 Java文件是如何被运行的
@@ -101,10 +101,10 @@ GC将无用对象从内存中卸载
加载一个Class类的顺序也是有优先级的,类加载器从最底层开始往上的顺序是这样的
1. BootStrap ClassLoader:rt.jar
-2. Extention ClassLoader: 加载扩展的jar包
+2. Extension ClassLoader: 加载扩展的jar包
3. App ClassLoader:指定的classpath下面的jar包
4. Custom ClassLoader:自定义的类加载器
-
+
### 2.3 双亲委派机制
当一个类收到了加载请求时,它是不会先自己去尝试加载的,而是委派给父类去完成,比如我现在要new一个Person,这个Person是我们自定义的类,如果我们要加载它,就会先委派App ClassLoader,只有当父类加载器都反馈自己无法完成这个请求(也就是父类加载器都没有找到加载所需的Class)时,子类加载器才会自行尝试加载
@@ -131,7 +131,7 @@ GC将无用对象从内存中卸载
### 3.2 方法区
-方法区主要的作用技术存放类的元数据信息,常量和静态变量···等。当它存储的信息过大时,会在无法满足内存分配时报错。
+方法区主要的作用是存放类的元数据信息,常量和静态变量···等。当它存储的信息过大时,会在无法满足内存分配时报错。
### 3.3 虚拟机栈和虚拟机堆
@@ -190,7 +190,7 @@ JVM内存会划分为堆内存和非堆内存,堆内存中也会划分为**年
当Eden空间满了之后,会触发一个叫做Minor GC(就是一个发生在年轻代的GC)的操作,存活下来的对象移动到Survivor0区。Survivor0区满后触发 Minor GC,就会将存活对象移动到Survivor1区,此时还会把from和to两个指针交换,这样保证了一段时间内总有一个survivor区为空且to所指向的survivor区为空。经过多次的 Minor GC后仍然存活的对象(**这里的存活判断是15次,对应到虚拟机参数为 -XX:MaxTenuringThreshold 。为什么是15,因为HotSpot会在对象投中的标记字段里记录年龄,分配到的空间仅有4位,所以最多只能记录到15**)会移动到老年代。老年代是存储长期存活的对象的,占满时就会触发我们最常听说的Full GC,期间会停止所有线程等待GC的完成。所以对于响应要求高的应用应该尽量去减少发生Full GC从而避免响应超时的问题。
-而且当老年区执行了full gc之后仍然无法进行对象保存的操作,就会产生OOM,这时候就是虚拟机中的堆内存不足,原因可能会是堆内存设置的大小过小,这个可以通过参数-Xms、-Xms来调整。也可能是代码中创建的对象大且多,而且它们一直在被引用从而长时间垃圾收集无法收集它们。
+而且当老年区执行了full gc之后仍然无法进行对象保存的操作,就会产生OOM,这时候就是虚拟机中的堆内存不足,原因可能会是堆内存设置的大小过小,这个可以通过参数-Xms、-Xmx来调整。也可能是代码中创建的对象大且多,而且它们一直在被引用从而长时间垃圾收集无法收集它们。

@@ -297,7 +297,7 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | |
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 |
-| -Xss | 每个线程的堆栈大小 | | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长)和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了
+| -Xss | 每个线程的堆栈大小 | | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.根据应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长)和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | |-XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | |设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10
| -XX:+DisableExplicitGC | 关闭System.gc() | |这个参数需要严格的测试
@@ -319,7 +319,7 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。简单点来说,你不停地往堆内存里面丢数据,等它剩余大小小于40%了,JVM就会动态申请内存空间不过会小于-Xmx,如果剩余大小大于70%,又会动态缩小不过不会小于–Xms。就这么简单
-开发过程中,通常会将 -Xms 与 -Xmx两个参数的配置相同的值,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源。
+开发过程中,通常会将 -Xms 与 -Xmx两个参数配置成相同的值,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源。
我们执行下面的代码
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png"
new file mode 100644
index 00000000000..88b494732af
Binary files /dev/null and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\344\275\277\347\224\250\345\217\245\346\237\204.png" differ
diff --git "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png"
index 145bd405c21..f954d8a7375 100644
Binary files "a/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" and "b/docs/java/jvm/pictures/java\345\206\205\345\255\230\345\214\272\345\237\237/\345\257\271\350\261\241\347\232\204\350\256\277\351\227\256\345\256\232\344\275\215-\347\233\264\346\216\245\346\214\207\351\222\210.png" differ
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
index 1d0a826f152..37394a92444 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\345\231\250.md"
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [回顾一下类加载过程](#回顾一下类加载过程)
@@ -134,13 +132,5 @@ protected Class loadClass(String name, boolean resolve)
-
-
-### 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
diff --git "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md" "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
index 9330c58166a..41ee988043a 100644
--- "a/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
+++ "b/docs/java/jvm/\347\261\273\345\212\240\350\275\275\350\277\207\347\250\213.md"
@@ -1,7 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
-
- [类的生命周期](#类的生命周期)
@@ -39,7 +35,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
-虚拟机规范多上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
+虚拟机规范上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
**一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。**
@@ -72,7 +68,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
### 初始化
-初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 ` ()`方法的过程。
+初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行初始化方法 ` ()`方法的过程。
对于`()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
@@ -104,7 +100,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
所以,在JVM生命周期类,由jvm自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
-只要想通一点就好了,jdk自带的BootstrapClassLoader,PlatformClassLoader,AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
+只要想通一点就好了,jdk自带的BootstrapClassLoader,ExtClassLoader,AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
**参考**
diff --git "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md" "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
index fe282352150..852b4c4dd8f 100644
--- "a/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
+++ "b/docs/java/jvm/\347\261\273\346\226\207\344\273\266\347\273\223\346\236\204.md"
@@ -46,7 +46,7 @@ ClassFile {
u2 interfaces_count;//接口
u2 interfaces[interfaces_count];//一个类可以实现多个接口
u2 fields_count;//Class 文件的字段属性
- field_info fields[fields_count];//一个类会可以有个字段
+ field_info fields[fields_count];//一个类会可以有多个字段
u2 methods_count;//Class 文件的方法数量
method_info methods[methods_count];//一个类可以有个多个方法
u2 attributes_count;//此类的属性表中的属性数
@@ -149,7 +149,7 @@ public class Employee {
**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
-**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按`implents`(如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
+**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
### 2.6 字段表集合
@@ -172,9 +172,9 @@ public class Employee {
上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型这些都是无法固定的,只能引用常量池中常量来描述。
-**字段的 access_flags 的取值:**
+**字段的 access_flag 的取值:**
-
+
### 2.7 方法表集合
@@ -183,7 +183,7 @@ public class Employee {
method_info methods[methods_count];//一个类可以有个多个方法
```
-methods_count 表示方法的数量,而 method_info 表示的方法表。
+methods_count 表示方法的数量,而 method_info 表示方法表。
Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。
@@ -193,7 +193,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
**方法表的 access_flag 取值:**
-
+
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
@@ -212,13 +212,3 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
-
-
- 《实战 Java 虚拟机》
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
similarity index 93%
rename from docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
rename to "docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
index c987d1497d1..76a3a9768fa 100644
--- a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\345\237\272\347\241\200\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -84,7 +84,7 @@ public class MultiThread {
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
-**总结:** 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
+**总结:** **线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。**
下面是该知识点的扩展内容!
@@ -279,18 +279,18 @@ Process finished with exit code 0
## 9. 说说 sleep() 方法和 wait() 方法区别和共同点?
-- 两者最主要的区别在于:**sleep 方法没有释放锁,而 wait 方法释放了锁** 。
+- 两者最主要的区别在于:**`sleep()` 方法没有释放锁,而 `wait()` 方法释放了锁** 。
- 两者都可以暂停线程的执行。
-- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
-- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。
+- `wait()` 通常被用于线程间交互/通信,`sleep() `通常被用于暂停执行。
+- `wait()` 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 `notify() `或者 `notifyAll()` 方法。`sleep() `方法执行完成后,线程会自动苏醒。或者可以使用 `wait(long timeout)` 超时后线程会自动苏醒。
## 10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
-new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
+new 一个 Thread,线程进入了新建状态。调用 `start()`方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 `start()` 会执行线程的相应准备工作,然后自动执行 ` run() ` 方法的内容,这是真正的多线程工作。 但是,直接执行 `run()` 方法,会把 `run()` 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
-**总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。**
+**总结: 调用 `start()` 方法方可启动线程并使线程进入就绪状态,直接执行 `run()` 方法的话不会以多线程的方式执行。**
## 公众号
diff --git "a/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md" "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
new file mode 100644
index 00000000000..7097b672686
--- /dev/null
+++ "b/docs/java/multi-thread/2020\346\234\200\346\226\260Java\345\271\266\345\217\221\350\277\233\351\230\266\345\270\270\350\247\201\351\235\242\350\257\225\351\242\230\346\200\273\347\273\223.md"
@@ -0,0 +1,1119 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
+
+
+
+
+
+
+- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
+ - [1.synchronized 关键字](#1synchronized-关键字)
+ - [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
+ - [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
+ - [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
+ - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
+ - [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
+ - [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
+ - [1.3.3.总结](#133总结)
+ - [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
+ - [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
+ - [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
+ - [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
+ - [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
+ - [2. volatile 关键字](#2-volatile-关键字)
+ - [2.1. CPU 缓存模型](#21-cpu-缓存模型)
+ - [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
+ - [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
+ - [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
+ - [3. ThreadLocal](#3-threadlocal)
+ - [3.1. ThreadLocal 简介](#31-threadlocal-简介)
+ - [3.2. ThreadLocal 示例](#32-threadlocal-示例)
+ - [3.3. ThreadLocal 原理](#33-threadlocal-原理)
+ - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
+ - [4. 线程池](#4-线程池)
+ - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
+ - [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
+ - [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
+ - [4.4. 如何创建线程池](#44-如何创建线程池)
+ - [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
+ - [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
+ - [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
+ - [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
+ - [4.7 线程池原理分析](#47-线程池原理分析)
+ - [5. Atomic 原子类](#5-atomic-原子类)
+ - [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
+ - [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
+ - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
+ - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
+ - [6. AQS](#6-aqs)
+ - [6.1. AQS 介绍](#61-aqs-介绍)
+ - [6.2. AQS 原理分析](#62-aqs-原理分析)
+ - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
+ - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
+ - [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
+ - [6.3. AQS 组件总结](#63-aqs-组件总结)
+ - [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
+ - [7 Reference](#7-reference)
+ - [公众号](#公众号)
+
+
+
+
+# Java 并发进阶常见面试题总结
+
+## 1.synchronized 关键字
+
+
+
+### 1.1.说一说自己对于 synchronized 关键字的了解
+
+**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
+
+另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
+
+**为什么呢?**
+
+因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
+
+庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 `synchronized` 较大优化,所以现在的 `synchronized` 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
+
+所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 `synchronized` 关键字。
+
+### 1.2. 说说自己是怎么使用 synchronized 关键字
+
+**synchronized 关键字最主要的三种使用方式:**
+
+**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+
+```java
+synchronized void method() {
+ //业务代码
+}
+```
+
+**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
+
+```java
+synchronized void staic method() {
+ //业务代码
+}
+```
+
+**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
+
+```java
+synchronized(this) {
+ //业务代码
+}
+```
+
+**总结:**
+
+- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
+- `synchronized` 关键字加到实例方法上是给对象实例上锁。
+- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
+
+下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
+
+面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
+
+**双重校验锁实现对象单例(线程安全)**
+
+```java
+public class Singleton {
+
+ private volatile static Singleton uniqueInstance;
+
+ private Singleton() {
+ }
+
+ public static Singleton getUniqueInstance() {
+ //先判断对象是否已经实例过,没有实例化过才进入加锁代码
+ if (uniqueInstance == null) {
+ //类对象加锁
+ synchronized (Singleton.class) {
+ if (uniqueInstance == null) {
+ uniqueInstance = new Singleton();
+ }
+ }
+ }
+ return uniqueInstance;
+ }
+}
+```
+
+另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
+
+`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
+
+1. 为 `uniqueInstance` 分配内存空间
+2. 初始化 `uniqueInstance`
+3. 将 `uniqueInstance` 指向分配的内存地址
+
+但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
+
+使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+
+### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
+
+先说结论:**构造方法不能使用 synchronized 关键字修饰。**
+
+构造方法本身就属于线程安全的,不存在同步的构造方法一说。
+
+### 1.3. 讲一下 synchronized 关键字的底层原理
+
+**synchronized 关键字底层原理属于 JVM 层面。**
+
+#### 1.3.1. synchronized 同步语句块的情况
+
+```java
+public class SynchronizedDemo {
+ public void method() {
+ synchronized (this) {
+ System.out.println("synchronized 代码块");
+ }
+ }
+}
+
+```
+
+通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
+
+
+
+从上面我们可以看出:
+
+**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
+
+当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
+
+> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
+>
+> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
+
+在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
+
+在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
+
+#### 1.3.2. `synchronized` 修饰方法的的情况
+
+```java
+public class SynchronizedDemo2 {
+ public synchronized void method() {
+ System.out.println("synchronized 方法");
+ }
+}
+
+```
+
+
+
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
+
+#### 1.3.3.总结
+
+`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
+
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
+
+**不过两者的本质都是对对象监视器 monitor 的获取。**
+
+### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
+
+JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
+
+锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
+
+关于这几种优化的详细信息可以查看下面这几篇文章:
+
+- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
+- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
+
+### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
+
+#### 1.5.1. 两者都是可重入锁
+
+**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
+
+#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
+
+`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
+
+#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
+
+相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
+
+- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
+- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
+- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
+
+> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
+
+**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
+
+## 2. volatile 关键字
+
+我们先要从 **CPU 缓存模型** 说起!
+
+### 2.1. CPU 缓存模型
+
+**为什么要弄一个 CPU 高速缓存呢?**
+
+类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
+
+我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
+
+总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
+
+为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
+
+
+
+**CPU Cache 的工作方式:**
+
+先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
+
+**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
+
+### 2.2. 讲一下 JMM(Java 内存模型)
+
+在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
+
+
+
+要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
+
+所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
+
+
+
+### 2.3. 并发编程的三个重要特性
+
+1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
+2. **可见性** :当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
+3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
+
+### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
+
+`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
+
+- **`volatile` 关键字**是线程同步的**轻量级实现**,所以**`volatile `性能肯定比` synchronized `关键字要好**。但是**`volatile` 关键字只能用于变量而 `synchronized` 关键字可以修饰方法以及代码块**。
+- **`volatile` 关键字能保证数据的可见性,但不能保证数据的原子性。`synchronized` 关键字两者都能保证。**
+- **`volatile`关键字主要用于解决变量在多个线程之间的可见性,而 `synchronized` 关键字解决的是多个线程之间访问资源的同步性。**
+
+## 3. ThreadLocal
+
+### 3.1. ThreadLocal 简介
+
+通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
+
+**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
+
+再举个简单的例子:
+
+比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
+
+### 3.2. ThreadLocal 示例
+
+相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
+
+```java
+import java.text.SimpleDateFormat;
+import java.util.Random;
+
+public class ThreadLocalExample implements Runnable{
+
+ // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
+ private static final ThreadLocal formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
+
+ public static void main(String[] args) throws InterruptedException {
+ ThreadLocalExample obj = new ThreadLocalExample();
+ for(int i=0 ; i<10; i++){
+ Thread t = new Thread(obj, ""+i);
+ Thread.sleep(new Random().nextInt(1000));
+ t.start();
+ }
+ }
+
+ @Override
+ public void run() {
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
+ try {
+ Thread.sleep(new Random().nextInt(1000));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ //formatter pattern is changed here by thread, but it won't reflect to other threads
+ formatter.set(new SimpleDateFormat());
+
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
+ }
+
+}
+
+```
+
+Output:
+
+```
+Thread Name= 0 default Formatter = yyyyMMdd HHmm
+Thread Name= 0 formatter = yy-M-d ah:mm
+Thread Name= 1 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 default Formatter = yyyyMMdd HHmm
+Thread Name= 1 formatter = yy-M-d ah:mm
+Thread Name= 3 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 formatter = yy-M-d ah:mm
+Thread Name= 4 default Formatter = yyyyMMdd HHmm
+Thread Name= 3 formatter = yy-M-d ah:mm
+Thread Name= 4 formatter = yy-M-d ah:mm
+Thread Name= 5 default Formatter = yyyyMMdd HHmm
+Thread Name= 5 formatter = yy-M-d ah:mm
+Thread Name= 6 default Formatter = yyyyMMdd HHmm
+Thread Name= 6 formatter = yy-M-d ah:mm
+Thread Name= 7 default Formatter = yyyyMMdd HHmm
+Thread Name= 7 formatter = yy-M-d ah:mm
+Thread Name= 8 default Formatter = yyyyMMdd HHmm
+Thread Name= 9 default Formatter = yyyyMMdd HHmm
+Thread Name= 8 formatter = yy-M-d ah:mm
+Thread Name= 9 formatter = yy-M-d ah:mm
+```
+
+从输出中可以看出,Thread-0 已经改变了 formatter 的值,但仍然是 thread-2 默认格式化程序与初始化值相同,其他线程也一样。
+
+上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
+
+```java
+ private static final ThreadLocal formatter = new ThreadLocal(){
+ @Override
+ protected SimpleDateFormat initialValue()
+ {
+ return new SimpleDateFormat("yyyyMMdd HHmm");
+ }
+ };
+```
+
+### 3.3. ThreadLocal 原理
+
+从 `Thread`类源代码入手。
+
+```java
+public class Thread implements Runnable {
+ ......
+//与此线程有关的ThreadLocal值。由ThreadLocal类维护
+ThreadLocal.ThreadLocalMap threadLocals = null;
+
+//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
+ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
+ ......
+}
+```
+
+从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是 null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set()`方法。
+
+`ThreadLocal`类的`set()`方法
+
+```java
+ public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+ }
+ ThreadLocalMap getMap(Thread t) {
+ return t.threadLocals;
+ }
+```
+
+通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
+
+**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为 key ,Object 对象为 value 的键值对。**
+
+```java
+ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
+ ......
+}
+```
+
+比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
+
+
+
+`ThreadLocalMap`是`ThreadLocal`的静态内部类。
+
+
+
+### 3.4. ThreadLocal 内存泄露问题
+
+`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
+
+```java
+ static class Entry extends WeakReference> {
+ /** The value associated with this ThreadLocal. */
+ Object value;
+
+ Entry(ThreadLocal k, Object v) {
+ super(k);
+ value = v;
+ }
+ }
+```
+
+**弱引用介绍:**
+
+> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
+>
+> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
+
+## 4. 线程池
+
+### 4.1. 为什么要用线程池?
+
+> **池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
+
+**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
+
+这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
+
+- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
+- **提高响应速度**。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
+- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
+
+### 4.2. 实现 Runnable 接口和 Callable 接口的区别
+
+`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
+
+工具类 `Executors` 可以实现 `Runnable` 对象和 `Callable` 对象之间的相互转换。(`Executors.callable(Runnable task`)或 `Executors.callable(Runnable task,Object resule)`)。
+
+`Runnable.java`
+
+```java
+@FunctionalInterface
+public interface Runnable {
+ /**
+ * 被线程执行,没有返回值也无法抛出异常
+ */
+ public abstract void run();
+}
+```
+
+`Callable.java`
+
+```java
+@FunctionalInterface
+public interface Callable {
+ /**
+ * 计算结果,或在无法这样做时抛出异常。
+ * @return 计算得出的结果
+ * @throws 如果无法计算结果,则抛出异常
+ */
+ V call() throws Exception;
+}
+```
+
+### 4.3. 执行 execute()方法和 submit()方法的区别是什么呢?
+
+1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
+2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
+
+我们以**`AbstractExecutorService`**接口中的一个 `submit` 方法为例子来看看源代码:
+
+```java
+ public Future submit(Runnable task) {
+ if (task == null) throw new NullPointerException();
+ RunnableFuture ftask = newTaskFor(task, null);
+ execute(ftask);
+ return ftask;
+ }
+```
+
+上面方法调用的 `newTaskFor` 方法返回了一个 `FutureTask` 对象。
+
+```java
+ protected RunnableFuture newTaskFor(Runnable runnable, T value) {
+ return new FutureTask(runnable, value);
+ }
+```
+
+我们再来看看`execute()`方法:
+
+```java
+ public void execute(Runnable command) {
+ ...
+ }
+```
+
+### 4.4. 如何创建线程池
+
+《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
+
+> Executors 返回线程池对象的弊端如下:
+>
+> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致 OOM。
+> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
+
+**方式一:通过构造方法实现**
+
+**方式二:通过 Executor 框架的工具类 Executors 来实现**
+我们可以创建三种类型的 ThreadPoolExecutor:
+
+- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
+- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
+- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
+
+对应 Executors 工具类中的方法如图所示:
+
+
+### 4.5 ThreadPoolExecutor 类分析
+
+`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
+
+```java
+ /**
+ * 用给定的初始参数创建一个新的ThreadPoolExecutor。
+ */
+ public ThreadPoolExecutor(int corePoolSize,
+ int maximumPoolSize,
+ long keepAliveTime,
+ TimeUnit unit,
+ BlockingQueue workQueue,
+ ThreadFactory threadFactory,
+ RejectedExecutionHandler handler) {
+ if (corePoolSize < 0 ||
+ maximumPoolSize <= 0 ||
+ maximumPoolSize < corePoolSize ||
+ keepAliveTime < 0)
+ throw new IllegalArgumentException();
+ if (workQueue == null || threadFactory == null || handler == null)
+ throw new NullPointerException();
+ this.corePoolSize = corePoolSize;
+ this.maximumPoolSize = maximumPoolSize;
+ this.workQueue = workQueue;
+ this.keepAliveTime = unit.toNanos(keepAliveTime);
+ this.threadFactory = threadFactory;
+ this.handler = handler;
+ }
+```
+
+**下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。**
+
+#### 4.5.1 `ThreadPoolExecutor`构造函数重要参数分析
+
+**`ThreadPoolExecutor` 3 个最重要的参数:**
+
+- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
+- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
+
+`ThreadPoolExecutor`其他常见参数:
+
+1. **`keepAliveTime`**:当线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁;
+2. **`unit`** : `keepAliveTime` 参数的时间单位。
+3. **`threadFactory`** :executor 创建新线程的时候会用到。
+4. **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
+
+#### 4.5.2 `ThreadPoolExecutor` 饱和策略
+
+**`ThreadPoolExecutor` 饱和策略定义:**
+
+如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
+
+- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
+- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
+- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
+
+举个例子: Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)
+
+### 4.6 一个简单的线程池 Demo
+
+为了让大家更清楚上面的面试题中的一些概念,我写了一个简单的线程池 Demo。
+
+首先创建一个 `Runnable` 接口的实现类(当然也可以是 `Callable` 接口,我们上面也说了两者的区别。)
+
+`MyRunnable.java`
+
+```java
+import java.util.Date;
+
+/**
+ * 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
+ * @author shuang.kou
+ */
+public class MyRunnable implements Runnable {
+
+ private String command;
+
+ public MyRunnable(String s) {
+ this.command = s;
+ }
+
+ @Override
+ public void run() {
+ System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
+ processCommand();
+ System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
+ }
+
+ private void processCommand() {
+ try {
+ Thread.sleep(5000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+
+ @Override
+ public String toString() {
+ return this.command;
+ }
+}
+
+```
+
+编写测试程序,我们这里以阿里巴巴推荐的使用 `ThreadPoolExecutor` 构造函数自定义参数的方式来创建线程池。
+
+`ThreadPoolExecutorDemo.java`
+
+```java
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.ThreadPoolExecutor;
+import java.util.concurrent.TimeUnit;
+
+public class ThreadPoolExecutorDemo {
+
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ for (int i = 0; i < 10; i++) {
+ //创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
+ Runnable worker = new MyRunnable("" + i);
+ //执行Runnable
+ executor.execute(worker);
+ }
+ //终止线程池
+ executor.shutdown();
+ while (!executor.isTerminated()) {
+ }
+ System.out.println("Finished all threads");
+ }
+}
+
+```
+
+可以看到我们上面的代码指定了:
+
+1. `corePoolSize`: 核心线程数为 5。
+2. `maximumPoolSize` :最大线程数 10
+3. `keepAliveTime` : 等待时间为 1L。
+4. `unit`: 等待时间的单位为 TimeUnit.SECONDS。
+5. `workQueue`:任务队列为 `ArrayBlockingQueue`,并且容量为 100;
+6. `handler`:饱和策略为 `CallerRunsPolicy`。
+
+**Output:**
+
+```
+pool-1-thread-2 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-5 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-4 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-1 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-3 Start. Time = Tue Nov 12 20:59:44 CST 2019
+pool-1-thread-5 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-3 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-2 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-4 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-1 End. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-2 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-1 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-4 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-3 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-5 Start. Time = Tue Nov 12 20:59:49 CST 2019
+pool-1-thread-2 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-3 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-4 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-5 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
+
+```
+
+### 4.7 线程池原理分析
+
+承接 4.6 节,我们通过代码输出结果可以看出:**线程池每次会同时执行 5 个任务,这 5 个任务执行完之后,剩余的 5 个任务才会被执行。** 大家可以先通过上面讲解的内容,分析一下到底是咋回事?(自己独立思考一会)
+
+现在,我们就分析上面的输出内容来简单分析一下线程池原理。
+
+**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。**在 4.6 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
+
+```java
+ // 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
+ private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
+
+ private static int workerCountOf(int c) {
+ return c & CAPACITY;
+ }
+
+ private final BlockingQueue workQueue;
+
+ public void execute(Runnable command) {
+ // 如果任务为null,则抛出异常。
+ if (command == null)
+ throw new NullPointerException();
+ // ctl 中保存的线程池当前的一些状态信息
+ int c = ctl.get();
+
+ // 下面会涉及到 3 步 操作
+ // 1.首先判断当前线程池中之行的任务数量是否小于 corePoolSize
+ // 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ if (workerCountOf(c) < corePoolSize) {
+ if (addWorker(command, true))
+ return;
+ c = ctl.get();
+ }
+ // 2.如果当前之行的任务数量大于等于 corePoolSize 的时候就会走到这里
+ // 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去
+ if (isRunning(c) && workQueue.offer(command)) {
+ int recheck = ctl.get();
+ // 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
+ if (!isRunning(recheck) && remove(command))
+ reject(command);
+ // 如果当前线程池为空就新创建一个线程并执行。
+ else if (workerCountOf(recheck) == 0)
+ addWorker(null, false);
+ }
+ //3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
+ //如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
+ else if (!addWorker(command, false))
+ reject(command);
+ }
+```
+
+通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
+
+
+
+现在,让我们在回到 4.6 节我们写的 Demo, 现在应该是不是很容易就可以搞懂它的原理了呢?
+
+没搞懂的话,也没关系,可以看看我的分析:
+
+> 我们在代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的 5 个任务会被放到等待队列中去。当前的 5 个任务之行完成后,才会之行剩下的 5 个任务。
+
+## 5. Atomic 原子类
+
+### 5.1. 介绍一下 Atomic 原子类
+
+`Atomic` 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
+
+所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
+
+并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
+
+
+
+### 5.2. JUC 包中的原子类是哪 4 类?
+
+**基本类型**
+
+使用原子的方式更新基本类型
+
+- `AtomicInteger`:整形原子类
+- `AtomicLong`:长整型原子类
+- `AtomicBoolean`:布尔型原子类
+
+**数组类型**
+
+使用原子的方式更新数组里的某个元素
+
+- `AtomicIntegerArray`:整形数组原子类
+- `AtomicLongArray`:长整形数组原子类
+- `AtomicReferenceArray`:引用类型数组原子类
+
+**引用类型**
+
+- `AtomicReference`:引用类型原子类
+- `AtomicStampedReference`:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- `AtomicMarkableReference` :原子更新带有标记位的引用类型
+
+**对象的属性修改类型**
+
+- `AtomicIntegerFieldUpdater`:原子更新整形字段的更新器
+- `AtomicLongFieldUpdater`:原子更新长整形字段的更新器
+- `AtomicReferenceFieldUpdater`:原子更新引用类型字段的更新器
+
+### 5.3. 讲讲 AtomicInteger 的使用
+
+**AtomicInteger 类常用方法**
+
+```java
+public final int get() //获取当前的值
+public final int getAndSet(int newValue)//获取当前的值,并设置新的值
+public final int getAndIncrement()//获取当前的值,并自增
+public final int getAndDecrement() //获取当前的值,并自减
+public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
+boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
+public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
+```
+
+**AtomicInteger 类的使用示例**
+
+使用 AtomicInteger 之后,不用对 increment() 方法加锁也可以保证线程安全。
+
+```java
+class AtomicIntegerTest {
+ private AtomicInteger count = new AtomicInteger();
+ //使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
+ public void increment() {
+ count.incrementAndGet();
+ }
+
+ public int getCount() {
+ return count.get();
+ }
+}
+
+```
+
+### 5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理
+
+AtomicInteger 线程安全原理简单分析
+
+AtomicInteger 类的部分源码:
+
+```java
+ // setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
+ private static final Unsafe unsafe = Unsafe.getUnsafe();
+ private static final long valueOffset;
+
+ static {
+ try {
+ valueOffset = unsafe.objectFieldOffset
+ (AtomicInteger.class.getDeclaredField("value"));
+ } catch (Exception ex) { throw new Error(ex); }
+ }
+
+ private volatile int value;
+```
+
+AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
+
+CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
+
+关于 Atomic 原子类这部分更多内容可以查看我的这篇文章:并发编程面试必备:[JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s/joa-yOiTrYF67bElj8xqvg)
+
+## 6. AQS
+
+### 6.1. AQS 介绍
+
+AQS 的全称为(`AbstractQueuedSynchronizer`),这个类在` java.util.concurrent.locks `包下面。
+
+
+
+AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 `ReentrantLock`,`Semaphore`,其他的诸如 `ReentrantReadWriteLock`,`SynchronousQueue`,`FutureTask` 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
+
+### 6.2. AQS 原理分析
+
+AQS 原理这部分参考了部分博客,在 5.2 节末尾放了链接。
+
+> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于 AQS 原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
+
+下面大部分内容其实在 AQS 类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
+
+#### 6.2.1. AQS 原理概览
+
+**AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
+
+> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
+
+看个 AQS(AbstractQueuedSynchronizer)原理图:
+
+
+
+AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
+
+```java
+private volatile int state;//共享变量,使用volatile修饰保证线程可见性
+```
+
+状态信息通过 protected 类型的 getState,setState,compareAndSetState 进行操作
+
+```java
+
+//返回同步状态的当前值
+protected final int getState() {
+ return state;
+}
+ // 设置同步状态的值
+protected final void setState(int newState) {
+ state = newState;
+}
+//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
+protected final boolean compareAndSetState(int expect, int update) {
+ return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
+}
+```
+
+#### 6.2.2. AQS 对资源的共享方式
+
+**AQS 定义两种资源共享方式**
+
+- **Exclusive**(独占):只有一个线程能执行,如 `ReentrantLock`。又可分为公平锁和非公平锁:
+ - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
+ - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
+- **Share**(共享):多个线程可同时执行,如` CountDownLatch`、`Semaphore`、`CountDownLatch`、 `CyclicBarrier`、`ReadWriteLock` 我们都会在后面讲到。
+
+`ReentrantReadWriteLock` 可以看成是组合式,因为 `ReentrantReadWriteLock` 也就是读写锁允许多个线程同时对某一资源进行读。
+
+不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
+
+#### 6.2.3. AQS 底层使用了模板方法模式
+
+同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
+
+1. 使用者继承 `AbstractQueuedSynchronizer` 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
+2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
+
+这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
+
+**AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:**
+
+```java
+isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
+tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
+tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
+tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
+tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
+
+```
+
+默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
+
+以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
+
+再以 `CountDownLatch` 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后` countDown()` 一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 `await()` 函数返回,继续后余动作。
+
+一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
+
+推荐两篇 AQS 原理和相关源码分析的文章:
+
+- http://www.cnblogs.com/waterystone/p/4920797.html
+- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
+
+### 6.3. AQS 组件总结
+
+- **`Semaphore`(信号量)-允许多个线程同时访问:** `synchronized` 和 `ReentrantLock` 都是一次只允许一个线程访问某个资源,`Semaphore`(信号量)可以指定多个线程同时访问某个资源。
+- **`CountDownLatch `(倒计时器):** `CountDownLatch` 是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
+- **`CyclicBarrier`(循环栅栏):** `CyclicBarrier` 和 `CountDownLatch` 非常类似,它也可以实现线程间的技术等待,但是它的功能比 `CountDownLatch` 更加复杂和强大。主要应用场景和 `CountDownLatch` 类似。`CyclicBarrier` 的字面意思是可循环使用(`Cyclic`)的屏障(`Barrier`)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。`CyclicBarrier` 默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用 `await()` 方法告诉 `CyclicBarrier` 我已经到达了屏障,然后当前线程被阻塞。
+
+### 6.4. 用过 CountDownLatch 么?什么场景下用的?
+
+`CountDownLatch` 的作用就是 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。之前在项目中,有一个使用多线程读取多个文件处理的场景,我用到了 `CountDownLatch` 。具体场景是下面这样的:
+
+我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。
+
+为此我们定义了一个线程池和 count 为 6 的`CountDownLatch`对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用`CountDownLatch`对象的 `await()`方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
+
+伪代码是下面这样的:
+
+```java
+public class CountDownLatchExample1 {
+ // 处理文件的数量
+ private static final int threadCount = 6;
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
+ ExecutorService threadPool = Executors.newFixedThreadPool(10);
+ final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
+ for (int i = 0; i < threadCount; i++) {
+ final int threadnum = i;
+ threadPool.execute(() -> {
+ try {
+ //处理文件的业务操作
+ ......
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ //表示一个文件已经被完成
+ countDownLatch.countDown();
+ }
+
+ });
+ }
+ countDownLatch.await();
+ threadPool.shutdown();
+ System.out.println("finish");
+ }
+
+}
+```
+
+**有没有可以改进的地方呢?**
+
+可以使用 `CompletableFuture` 类来改进!Java8 的 `CompletableFuture` 提供了很多对多线程友好的方法,使用它可以很方便地为我们编写多线程程序,什么异步、串行、并行或者等待所有线程执行完任务什么的都非常方便。
+
+```java
+CompletableFuture task1 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+CompletableFuture task6 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+ CompletableFuture headerFuture=CompletableFuture.allOf(task1,.....,task6);
+
+ try {
+ headerFuture.join();
+ } catch (Exception ex) {
+ ......
+ }
+System.out.println("all done. ");
+```
+
+上面的代码还可以接续优化,当任务过多的时候,把每一个 task 都列出来不太现实,可以考虑通过循环来添加任务。
+
+```java
+//文件夹位置
+List filePaths = Arrays.asList(...)
+// 异步处理所有文件
+List> fileFutures = filePaths.stream()
+ .map(filePath -> doSomeThing(filePath))
+ .collect(Collectors.toList());
+// 将他们合并起来
+CompletableFuture allFutures = CompletableFuture.allOf(
+ fileFutures.toArray(new CompletableFuture[fileFutures.size()])
+);
+
+```
+
+## 7 Reference
+
+- 《深入理解 Java 虚拟机》
+- 《实战 Java 高并发程序设计》
+- 《Java 并发编程的艺术》
+- http://www.cnblogs.com/waterystone/p/4920797.html
+- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
+-
+
+## 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
+
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
diff --git a/docs/java/Multithread/AQS.md "b/docs/java/multi-thread/AQS\345\216\237\347\220\206\344\273\245\345\217\212AQS\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md"
similarity index 100%
rename from docs/java/Multithread/AQS.md
rename to "docs/java/multi-thread/AQS\345\216\237\347\220\206\344\273\245\345\217\212AQS\345\220\214\346\255\245\347\273\204\344\273\266\346\200\273\347\273\223.md"
diff --git a/docs/java/Multithread/Atomic.md "b/docs/java/multi-thread/Atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md"
similarity index 100%
rename from docs/java/Multithread/Atomic.md
rename to "docs/java/multi-thread/Atomic\345\216\237\345\255\220\347\261\273\346\200\273\347\273\223.md"
diff --git "a/docs/java/Multithread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md" "b/docs/java/multi-thread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md"
similarity index 100%
rename from "docs/java/Multithread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md"
rename to "docs/java/multi-thread/ThreadLocal\357\274\210\346\234\252\345\256\214\346\210\220\357\274\211.md"
diff --git "a/docs/java/Multithread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png" "b/docs/java/multi-thread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
similarity index 100%
rename from "docs/java/Multithread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
rename to "docs/java/multi-thread/images/ThreadLocal\345\206\205\351\203\250\347\261\273.png"
diff --git "a/docs/java/multi-thread/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png" "b/docs/java/multi-thread/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png"
new file mode 100644
index 00000000000..24ac1a8cc26
Binary files /dev/null and "b/docs/java/multi-thread/images/interview-questions/synchronized\345\205\263\351\224\256\345\255\227.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png"
new file mode 100644
index 00000000000..8b2ede8ab54
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/CachedThreadPool-execute.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png"
new file mode 100644
index 00000000000..87658aa3f09
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executors\345\267\245\345\205\267\347\261\273.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png"
new file mode 100644
index 00000000000..5cc148dd79a
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/Executor\346\241\206\346\236\266\347\232\204\344\275\277\347\224\250\347\244\272\346\204\217\345\233\276.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png"
new file mode 100644
index 00000000000..fc1c7034fdf
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/FixedThreadPool.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png"
new file mode 100644
index 00000000000..c56521d283e
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\211\247\350\241\214\345\221\250\346\234\237\344\273\273\345\212\241\346\255\245\351\252\244.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png"
new file mode 100644
index 00000000000..bae0dc5b2dc
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/ScheduledThreadPoolExecutor\346\234\272\345\210\266.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png"
new file mode 100644
index 00000000000..c933674fad4
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/SingleThreadExecutor.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png"
new file mode 100644
index 00000000000..30c298591bc
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/threadpoolexecutor\346\236\204\351\200\240\345\207\275\346\225\260.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png"
new file mode 100644
index 00000000000..6aebd60b591
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\344\273\273\345\212\241\347\232\204\346\211\247\350\241\214\347\233\270\345\205\263\346\216\245\345\217\243.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png"
new file mode 100644
index 00000000000..bc661944a0a
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\345\233\276\350\247\243\347\272\277\347\250\213\346\261\240\345\256\236\347\216\260\345\216\237\347\220\206.png" differ
diff --git "a/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png" "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png"
new file mode 100644
index 00000000000..d609943bafe
Binary files /dev/null and "b/docs/java/multi-thread/images/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223/\347\272\277\347\250\213\346\261\240\345\220\204\344\270\252\345\217\202\346\225\260\344\271\213\351\227\264\347\232\204\345\205\263\347\263\273.png" differ
diff --git a/docs/java/Multithread/images/thread-local/1.png b/docs/java/multi-thread/images/thread-local/1.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/1.png
rename to docs/java/multi-thread/images/thread-local/1.png
diff --git a/docs/java/Multithread/images/thread-local/10.png b/docs/java/multi-thread/images/thread-local/10.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/10.png
rename to docs/java/multi-thread/images/thread-local/10.png
diff --git a/docs/java/Multithread/images/thread-local/11.png b/docs/java/multi-thread/images/thread-local/11.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/11.png
rename to docs/java/multi-thread/images/thread-local/11.png
diff --git a/docs/java/Multithread/images/thread-local/12.png b/docs/java/multi-thread/images/thread-local/12.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/12.png
rename to docs/java/multi-thread/images/thread-local/12.png
diff --git a/docs/java/Multithread/images/thread-local/13.png b/docs/java/multi-thread/images/thread-local/13.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/13.png
rename to docs/java/multi-thread/images/thread-local/13.png
diff --git a/docs/java/Multithread/images/thread-local/14.png b/docs/java/multi-thread/images/thread-local/14.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/14.png
rename to docs/java/multi-thread/images/thread-local/14.png
diff --git a/docs/java/Multithread/images/thread-local/15.png b/docs/java/multi-thread/images/thread-local/15.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/15.png
rename to docs/java/multi-thread/images/thread-local/15.png
diff --git a/docs/java/Multithread/images/thread-local/16.png b/docs/java/multi-thread/images/thread-local/16.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/16.png
rename to docs/java/multi-thread/images/thread-local/16.png
diff --git a/docs/java/Multithread/images/thread-local/17.png b/docs/java/multi-thread/images/thread-local/17.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/17.png
rename to docs/java/multi-thread/images/thread-local/17.png
diff --git a/docs/java/Multithread/images/thread-local/18.png b/docs/java/multi-thread/images/thread-local/18.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/18.png
rename to docs/java/multi-thread/images/thread-local/18.png
diff --git a/docs/java/Multithread/images/thread-local/19.png b/docs/java/multi-thread/images/thread-local/19.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/19.png
rename to docs/java/multi-thread/images/thread-local/19.png
diff --git a/docs/java/Multithread/images/thread-local/2.png b/docs/java/multi-thread/images/thread-local/2.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/2.png
rename to docs/java/multi-thread/images/thread-local/2.png
diff --git a/docs/java/Multithread/images/thread-local/20.png b/docs/java/multi-thread/images/thread-local/20.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/20.png
rename to docs/java/multi-thread/images/thread-local/20.png
diff --git a/docs/java/Multithread/images/thread-local/21.png b/docs/java/multi-thread/images/thread-local/21.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/21.png
rename to docs/java/multi-thread/images/thread-local/21.png
diff --git a/docs/java/Multithread/images/thread-local/22.png b/docs/java/multi-thread/images/thread-local/22.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/22.png
rename to docs/java/multi-thread/images/thread-local/22.png
diff --git a/docs/java/Multithread/images/thread-local/23.png b/docs/java/multi-thread/images/thread-local/23.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/23.png
rename to docs/java/multi-thread/images/thread-local/23.png
diff --git a/docs/java/Multithread/images/thread-local/24.png b/docs/java/multi-thread/images/thread-local/24.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/24.png
rename to docs/java/multi-thread/images/thread-local/24.png
diff --git a/docs/java/Multithread/images/thread-local/25.png b/docs/java/multi-thread/images/thread-local/25.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/25.png
rename to docs/java/multi-thread/images/thread-local/25.png
diff --git a/docs/java/Multithread/images/thread-local/26.png b/docs/java/multi-thread/images/thread-local/26.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/26.png
rename to docs/java/multi-thread/images/thread-local/26.png
diff --git a/docs/java/Multithread/images/thread-local/27.png b/docs/java/multi-thread/images/thread-local/27.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/27.png
rename to docs/java/multi-thread/images/thread-local/27.png
diff --git a/docs/java/Multithread/images/thread-local/28.png b/docs/java/multi-thread/images/thread-local/28.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/28.png
rename to docs/java/multi-thread/images/thread-local/28.png
diff --git a/docs/java/Multithread/images/thread-local/29.png b/docs/java/multi-thread/images/thread-local/29.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/29.png
rename to docs/java/multi-thread/images/thread-local/29.png
diff --git a/docs/java/Multithread/images/thread-local/3.png b/docs/java/multi-thread/images/thread-local/3.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/3.png
rename to docs/java/multi-thread/images/thread-local/3.png
diff --git a/docs/java/Multithread/images/thread-local/30.png b/docs/java/multi-thread/images/thread-local/30.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/30.png
rename to docs/java/multi-thread/images/thread-local/30.png
diff --git a/docs/java/Multithread/images/thread-local/31.png b/docs/java/multi-thread/images/thread-local/31.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/31.png
rename to docs/java/multi-thread/images/thread-local/31.png
diff --git a/docs/java/Multithread/images/thread-local/4.png b/docs/java/multi-thread/images/thread-local/4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/4.png
rename to docs/java/multi-thread/images/thread-local/4.png
diff --git a/docs/java/Multithread/images/thread-local/5.png b/docs/java/multi-thread/images/thread-local/5.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/5.png
rename to docs/java/multi-thread/images/thread-local/5.png
diff --git a/docs/java/Multithread/images/thread-local/6.png b/docs/java/multi-thread/images/thread-local/6.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/6.png
rename to docs/java/multi-thread/images/thread-local/6.png
diff --git a/docs/java/Multithread/images/thread-local/7.png b/docs/java/multi-thread/images/thread-local/7.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/7.png
rename to docs/java/multi-thread/images/thread-local/7.png
diff --git a/docs/java/Multithread/images/thread-local/8.png b/docs/java/multi-thread/images/thread-local/8.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/8.png
rename to docs/java/multi-thread/images/thread-local/8.png
diff --git a/docs/java/Multithread/images/thread-local/9.png b/docs/java/multi-thread/images/thread-local/9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/9.png
rename to docs/java/multi-thread/images/thread-local/9.png
diff --git a/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png b/docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
rename to docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
diff --git a/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png b/docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
rename to docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
diff --git a/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png b/docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
rename to docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
diff --git a/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png b/docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
rename to docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
diff --git a/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png b/docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
rename to docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
diff --git a/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png b/docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
rename to docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
diff --git "a/docs/java/Multithread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png" "b/docs/java/multi-thread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
similarity index 100%
rename from "docs/java/Multithread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
rename to "docs/java/multi-thread/images/threadlocal\346\225\260\346\215\256\347\273\223\346\236\204.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/Java\345\271\266\345\217\221\347\274\226\347\250\213\347\232\204\350\211\272\346\234\257.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/javaguide-\345\271\266\345\217\221.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/java\345\271\266\345\217\221\347\274\226\347\250\213\344\271\213\347\276\216.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\345\256\236\346\210\230Java\351\253\230\345\271\266\345\217\221\347\250\213\345\272\217\350\256\276\350\256\241.png"
diff --git "a/docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png" "b/docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
similarity index 100%
rename from "docs/java/Multithread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
rename to "docs/java/multi-thread/images/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227/\346\267\261\345\205\245\346\265\205\345\207\272Java\345\244\232\347\272\277\347\250\213.png"
diff --git "a/docs/java/Multithread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/docs/java/multi-thread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
similarity index 95%
rename from "docs/java/Multithread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
rename to "docs/java/multi-thread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
index 54f4b650aa2..2e904d5fde6 100644
--- "a/docs/java/Multithread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
+++ "b/docs/java/multi-thread/java\347\272\277\347\250\213\346\261\240\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -91,13 +91,13 @@ public class ThreadPoolExecutor extends AbstractExecutorService
**`ScheduledThreadPoolExecutor` 类描述:**
```java
-//ScheduledExecutorService实现了ExecutorService接口
+//ScheduledExecutorService继承ExecutorService接口
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService
```
-
+
#### 3) 异步计算的结果(`Future`)
@@ -107,7 +107,7 @@ public class ScheduledThreadPoolExecutor
### 2.3 Executor 框架的使用示意图
-
+
1. **主线程首先要创建实现 `Runnable` 或者 `Callable` 接口的任务对象。**
2. **把创建完成的实现 `Runnable`/`Callable`接口的 对象直接交给 `ExecutorService` 执行**: `ExecutorService.execute(Runnable command)`)或者也可以把 `Runnable` 对象或`Callable` 对象提交给 `ExecutorService` 执行(`ExecutorService.submit(Runnable task)`或 `ExecutorService.submit(Callable task)`)。
@@ -167,7 +167,7 @@ public class ScheduledThreadPoolExecutor
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
-
+
**`ThreadPoolExecutor` 饱和策略定义:**
@@ -198,7 +198,7 @@ public class ScheduledThreadPoolExecutor
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
**方式一:通过`ThreadPoolExecutor`构造函数实现(推荐)**
-
+
**方式二:通过 Executor 框架的工具类 Executors 来实现**
我们可以创建三种类型的 ThreadPoolExecutor:
@@ -207,7 +207,7 @@ public class ScheduledThreadPoolExecutor
- **CachedThreadPool**
对应 Executors 工具类中的方法如图所示:
-
+
## 四 (重要)ThreadPoolExecutor 使用示例
@@ -341,7 +341,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
现在,我们就分析上面的输出内容来简单分析一下线程池原理。
-**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。**在 4.1 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
+**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。** 在 4.1 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
```java
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
@@ -388,7 +388,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
-
+
@@ -543,7 +543,7 @@ public interface Callable {
#### 4.3.2 `execute()` vs `submit()`
1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
-2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
+2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功** ,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
我们以**`AbstractExecutorService`**接口中的一个 `submit` 方法为例子来看看源代码:
@@ -705,7 +705,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
`FixedThreadPool` 的 `execute()` 方法运行示意图(该图片来源:《Java 并发编程的艺术》):
-
+
**上图说明:**
@@ -755,7 +755,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.2.2 执行任务过程介绍
**`SingleThreadExecutor` 的运行示意图(该图片来源:《Java 并发编程的艺术》):**
-
+
**上图说明;**
@@ -799,7 +799,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.3.2 执行任务过程介绍
**CachedThreadPool 的 execute()方法的执行示意图(该图片来源:《Java 并发编程的艺术》):**
-
+
**上图说明:**
@@ -830,7 +830,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.2 运行机制
-
+
**`ScheduledThreadPoolExecutor` 的执行主要分为两大部分:**
@@ -845,7 +845,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.3 ScheduledThreadPoolExecutor 执行周期任务的步骤
-
+
1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask`的 time 大于等于当前系统的时间;
2. 线程 1 执行这个 `ScheduledFutureTask`;
diff --git "a/docs/java/multi-thread/synchronized\345\234\250JDK1.6\344\271\213\345\220\216\347\232\204\345\272\225\345\261\202\344\274\230\345\214\226.md" "b/docs/java/multi-thread/synchronized\345\234\250JDK1.6\344\271\213\345\220\216\347\232\204\345\272\225\345\261\202\344\274\230\345\214\226.md"
new file mode 100644
index 00000000000..c3776c2da21
--- /dev/null
+++ "b/docs/java/multi-thread/synchronized\345\234\250JDK1.6\344\271\213\345\220\216\347\232\204\345\272\225\345\261\202\344\274\230\345\214\226.md"
@@ -0,0 +1,62 @@
+JDK1.6 对锁的实现引入了大量的优化来减少锁操作的开销,如: **偏向锁**、**轻量级锁**、**自旋锁**、**适应性自旋锁**、**锁消除**、**锁粗化** 等等技术。
+
+锁主要存在四中状态,依次是:
+
+1. 无锁状态
+2. 偏向锁状态
+3. 轻量级锁状态
+4. 重量级锁状态
+
+锁🔐会随着竞争的激烈而逐渐升级。
+
+另外,需要注意:**锁可以升级不可降级,即 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁是单向的。** 这种策略是为了提高获得锁和释放锁的效率。
+
+### 偏向锁
+
+**引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉**。
+
+偏向锁的“偏”就是偏心的偏,它的意思是会偏向于第一个获得它的线程,如果在接下来的执行中,该锁没有被其他线程获取,那么持有偏向锁的线程就不需要进行同步!(关于偏向锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。)
+
+#### 偏向锁的加锁
+
+当一个线程访问同步块并获取锁时, 会在锁对象的对象头和栈帧中的锁记录里存储锁偏向的线程ID, 以后该线程进入和退出同步块时不需要进行CAS操作来加锁和解锁, 只需要简单的测试一下锁对象的对象头的MarkWord里是否存储着指向当前线程的偏向锁(线程ID是当前线程), 如果测试成功, 表示线程已经获得了锁; 如果测试失败, 则需要再测试一下MarkWord中偏向锁的标识是否设置成1(表示当前是偏向锁), 如果没有设置, 则使用CAS竞争锁, 如果设置了, 则尝试使用CAS将锁对象的对象头的偏向锁指向当前线程.
+
+#### 偏向锁的撤销
+
+偏向锁使用了一种等到竞争出现才释放锁的机制, 所以当其他线程尝试竞争偏向锁时, 持有偏向锁的线程才会释放锁. 偏向锁的撤销需要等到全局安全点(在这个时间点上没有正在执行的字节码). 首先会暂停持有偏向锁的线程, 然后检查持有偏向锁的线程是否存活, 如果线程不处于活动状态, 则将锁对象的对象头设置为无锁状态; 如果线程仍然活着, 则锁对象的对象头中的MarkWord和栈中的锁记录要么重新偏向于其它线程要么恢复到无锁状态, 最后唤醒暂停的线程(释放偏向锁的线程).
+
+但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
+
+### 轻量级锁
+
+倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的)。**轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。** 关于轻量级锁的加锁和解锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
+
+**轻量级锁能够提升程序同步性能的依据是“对于绝大部分锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用 CAS 操作避免了使用互斥操作的开销。但如果存在锁竞争,除了互斥量开销外,还会额外发生CAS操作,因此在有锁竞争的情况下,轻量级锁比传统的重量级锁更慢!如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁!**
+
+### 自旋锁和自适应自旋
+
+轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
+
+互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。
+
+**一般线程持有锁的时间都不是太长,所以仅仅为了这一点时间去挂起线程/恢复线程是得不偿失的。** 所以,虚拟机的开发团队就这样去考虑:“我们能不能让后面来的请求获取锁的线程等待一会而不被挂起呢?看看持有锁的线程是否很快就会释放锁”。**为了让一个线程等待,我们只需要让线程执行一个忙循环(自旋),这项技术就叫做自旋**。
+
+百度百科对自旋锁的解释:
+
+> 何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
+
+自旋锁在 JDK1.6 之前其实就已经引入了,不过是默认关闭的,需要通过`--XX:+UseSpinning`参数来开启。JDK1.6及1.6之后,就改为默认开启的了。需要注意的是:自旋等待不能完全替代阻塞,因为它还是要占用处理器时间。如果锁被占用的时间短,那么效果当然就很好了!反之,相反!自旋等待的时间必须要有限度。如果自旋超过了限定次数任然没有获得锁,就应该挂起线程。**自旋次数的默认值是10次,用户可以修改`--XX:PreBlockSpin`来更改**。
+
+另外,**在 JDK1.6 中引入了自适应的自旋锁。自适应的自旋锁带来的改进就是:自旋的时间不在固定了,而是和前一次同一个锁上的自旋时间以及锁的拥有者的状态来决定,虚拟机变得越来越“聪明”了**。
+
+### 锁消除
+
+锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。
+
+### 锁粗化
+
+原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小,——只在共享数据的实际作用域才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待线程也能尽快拿到锁。
+
+大部分情况下,上面的原则都是没有问题的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,那么会带来很多不必要的性能消耗。
+
+
diff --git a/docs/java/Multithread/ThreadLocal.md "b/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
similarity index 95%
rename from docs/java/Multithread/ThreadLocal.md
rename to "docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
index 6383ef1dba8..211f7aeeca4 100644
--- a/docs/java/Multithread/ThreadLocal.md
+++ "b/docs/java/multi-thread/\344\270\207\345\255\227\350\257\246\350\247\243ThreadLocal\345\205\263\351\224\256\345\255\227.md"
@@ -35,7 +35,7 @@
public class ThreadLocalTest {
private List messages = Lists.newArrayList();
- public static final `ThreadLocal` holder = `ThreadLocal`.withInitial(ThreadLocalTest::new);
+ public static final ThreadLocal holder = ThreadLocal.withInitial(ThreadLocalTest::new);
public static void add(String message) {
holder.get().messages.add(message);
@@ -70,8 +70,7 @@ size: 0

-
-`Thread`类有一个类型为``ThreadLocal`.`ThreadLocalMap``的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
+`Thread`类有一个类型为`ThreadLocal.ThreadLocalMap`的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
`ThreadLocalMap`有自己的独立实现,可以简单地将它的`key`视作`ThreadLocal`,`value`为代码中放入的值(实际上`key`并不是`ThreadLocal`本身,而是它的一个**弱引用**)。
@@ -79,11 +78,11 @@ size: 0
`ThreadLocalMap`有点类似`HashMap`的结构,只是`HashMap`是由**数组+链表**实现的,而`ThreadLocalMap`中并没有**链表**结构。
-我们还要注意`Entry`, 它的`key`是``ThreadLocal` k` ,继承自`WeakReference, 也就是我们常说的弱引用类型。
+我们还要注意`Entry`, 它的`key`是`ThreadLocal k` ,继承自`WeakReference`, 也就是我们常说的弱引用类型。
### GC 之后key是否为null?
-回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在` `ThreadLocal`.get()`的时候,发生`GC`之后,`key`是否是`null`?
+回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在`ThreadLocal.get()`的时候,发生`GC`之后,`key`是否是`null`?
为了搞清楚这个问题,我们需要搞清楚`Java`的**四种引用类型**:
@@ -110,7 +109,7 @@ public class ThreadLocalDemo {
private static void test(String s,boolean isGC) {
try {
- new `ThreadLocal`<>().set(s);
+ new ThreadLocal<>().set(s);
if (isGC) {
System.gc();
}
@@ -118,11 +117,11 @@ public class ThreadLocalDemo {
Class clz = t.getClass();
Field field = clz.getDeclaredField("threadLocals");
field.setAccessible(true);
- Object `ThreadLocalMap` = field.get(t);
- Class tlmClass = `ThreadLocalMap`.getClass();
+ Object ThreadLocalMap = field.get(t);
+ Class tlmClass = ThreadLocalMap.getClass();
Field tableField = tlmClass.getDeclaredField("table");
tableField.setAccessible(true);
- Object[] arr = (Object[]) tableField.get(`ThreadLocalMap`);
+ Object[] arr = (Object[]) tableField.get(ThreadLocalMap);
for (Object o : arr) {
if (o != null) {
Class entryClass = o.getClass();
@@ -142,8 +141,8 @@ public class ThreadLocalDemo {
结果如下:
```java
-弱引用key:java.lang.`ThreadLocal`@433619b6,值:abc
-弱引用key:java.lang.`ThreadLocal`@418a15e3,值:java.lang.ref.SoftReference@bf97a12
+弱引用key:java.lang.ThreadLocal@433619b6,值:abc
+弱引用key:java.lang.ThreadLocal@418a15e3,值:java.lang.ref.SoftReference@bf97a12
--gc后--
弱引用key:null,值:def
```
@@ -162,7 +161,7 @@ new ThreadLocal<>().set(s);
这个问题刚开始看,如果没有过多思考,**弱引用**,还有**垃圾回收**,那么肯定会觉得是`null`。
-其实是不对的,因为题目说的是在做 ``ThreadLocal`.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。
+其实是不对的,因为题目说的是在做 `ThreadLocal.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。

@@ -217,8 +216,8 @@ public class ThreadLocal {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
- static class `ThreadLocalMap` {
- `ThreadLocalMap`(`ThreadLocal` firstKey, Object firstValue) {
+ static class ThreadLocalMap {
+ ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
@@ -230,7 +229,7 @@ public class ThreadLocal {
}
```
-每当创建一个`ThreadLocal`对象,这个``ThreadLocal`.nextHashCode` 这个值就会增长 `0x61c88647` 。
+每当创建一个`ThreadLocal`对象,这个`ThreadLocal.nextHashCode` 这个值就会增长 `0x61c88647` 。
这个值很特殊,它是**斐波那契数** 也叫 **黄金分割数**。`hash`增量为 这个数字,带来的好处就是 `hash` **分布非常均匀**。
@@ -244,7 +243,7 @@ public class ThreadLocal {
> **注明:** 下面所有示例图中,**绿色块**`Entry`代表**正常数据**,**灰色块**代表`Entry`的`key`值为`null`,**已被垃圾回收**。**白色块**表示`Entry`为`null`。
-虽然`ThreadLocalMap`中使用了**黄金分隔数来**作为`hash`计算因子,大大减少了`Hash`冲突的概率,但是仍然会存在冲突。
+虽然`ThreadLocalMap`中使用了**黄金分割数来**作为`hash`计算因子,大大减少了`Hash`冲突的概率,但是仍然会存在冲突。
`HashMap`中解决冲突的方法是在数组上构造一个**链表**结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成**红黑树**。
@@ -403,7 +402,7 @@ private static int prevIndex(int i, int len) {
`java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry()`:
```java
-private void replaceStaleEntry(`ThreadLocal` key, Object value,
+private void replaceStaleEntry(ThreadLocal key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
@@ -687,7 +686,7 @@ private void resize() {

-我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于``ThreadLocal`1`,所以需要继续往后迭代查找。
+我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于`ThreadLocal1`,所以需要继续往后迭代查找。
迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
@@ -698,7 +697,7 @@ private void resize() {
`java.lang.ThreadLocal.ThreadLocalMap.getEntry()`:
```java
-private Entry getEntry(`ThreadLocal` key) {
+private Entry getEntry(ThreadLocal key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
@@ -707,7 +706,7 @@ private Entry getEntry(`ThreadLocal` key) {
return getEntryAfterMiss(key, i, e);
}
-private Entry getEntryAfterMiss(`ThreadLocal` key, int i, Entry e) {
+private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
diff --git "a/docs/java/Multithread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md" "b/docs/java/multi-thread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md"
similarity index 100%
rename from "docs/java/Multithread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md"
rename to "docs/java/multi-thread/\345\210\233\345\273\272\347\272\277\347\250\213\347\232\204\345\207\240\347\247\215\346\226\271\345\274\217\346\200\273\347\273\223.md"
diff --git "a/docs/java/Multithread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md" "b/docs/java/multi-thread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md"
similarity index 100%
rename from "docs/java/Multithread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md"
rename to "docs/java/multi-thread/\345\244\232\347\272\277\347\250\213\345\255\246\344\271\240\346\214\207\345\215\227.md"
diff --git "a/docs/java/Multithread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md" "b/docs/java/multi-thread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
similarity index 100%
rename from "docs/java/Multithread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
rename to "docs/java/multi-thread/\345\271\266\345\217\221\345\256\271\345\231\250\346\200\273\347\273\223.md"
diff --git a/docs/java/Multithread/best-practice-of-threadpool.md "b/docs/java/multi-thread/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md"
similarity index 100%
rename from docs/java/Multithread/best-practice-of-threadpool.md
rename to "docs/java/multi-thread/\346\213\277\346\235\245\345\215\263\347\224\250\347\232\204\347\272\277\347\250\213\346\261\240\346\234\200\344\275\263\345\256\236\350\267\265.md"
diff --git "a/docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md" "b/docs/java/new-features/Java8foreach\346\214\207\345\215\227.md"
similarity index 100%
rename from "docs/java/What's New in JDK8/Java8foreach\346\214\207\345\215\227.md"
rename to "docs/java/new-features/Java8foreach\346\214\207\345\215\227.md"
diff --git "a/docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md" "b/docs/java/new-features/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
similarity index 100%
rename from "docs/java/What's New in JDK8/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
rename to "docs/java/new-features/Java8\346\225\231\347\250\213\346\216\250\350\215\220.md"
diff --git a/docs/java/What's New in JDK8/Java8Tutorial.md "b/docs/java/new-features/Java8\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
similarity index 98%
rename from docs/java/What's New in JDK8/Java8Tutorial.md
rename to "docs/java/new-features/Java8\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
index 01e71f5ea74..8cf809f75c8 100644
--- a/docs/java/What's New in JDK8/Java8Tutorial.md
+++ "b/docs/java/new-features/Java8\346\226\260\347\211\271\346\200\247\346\200\273\347\273\223.md"
@@ -15,12 +15,12 @@
- [访问字段和静态变量](#访问字段和静态变量)
- [访问默认接口方法](#访问默认接口方法)
- [内置函数式接口\(Built-in Functional Interfaces\)](#内置函数式接口built-in-functional-interfaces)
- - [Predicates](#predicates)
- - [Functions](#functions)
- - [Suppliers](#suppliers)
- - [Consumers](#consumers)
- - [Comparators](#comparators)
- - [Optionals](#optionals)
+ - [Predicate](#predicate)
+ - [Function](#function)
+ - [Supplier](#supplier)
+ - [Consumer](#consumer)
+ - [Comparator](#comparator)
+ - [Optional](#optional)
- [Streams\(流\)](#streams流)
- [Filter\(过滤\)](#filter过滤)
- [Sorted\(排序\)](#sorted排序)
@@ -287,7 +287,7 @@ JDK 1.8 API包含许多内置函数式接口。 其中一些借口在老版本
但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
-#### Predicates
+#### Predicate
Predicate 接口是只有一个参数的返回布尔类型值的 **断言型** 接口。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非):
@@ -340,7 +340,7 @@ Predicate isEmpty = String::isEmpty;
Predicate isNotEmpty = isEmpty.negate();
```
-#### Functions
+#### Function
Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
@@ -382,7 +382,7 @@ Function backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123"
```
-#### Suppliers
+#### Supplier
Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
@@ -391,7 +391,7 @@ Supplier personSupplier = Person::new;
personSupplier.get(); // new Person
```
-#### Consumers
+#### Consumer
Consumer 接口表示要对单个输入参数执行的操作。
@@ -400,7 +400,7 @@ Consumer greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker"));
```
-#### Comparators
+#### Comparator
Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
@@ -414,9 +414,9 @@ comparator.compare(p1, p2); // > 0
comparator.reversed().compare(p1, p2); // < 0
```
-## Optionals
+## Optional
-Optionals不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optionals的工作原理。
+Optional不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optional的工作原理。
Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
diff --git a/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png "b/docs/java/new-features/images/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9~14 \347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247/java\347\211\210\346\234\254\345\217\221\345\270\203.png"
similarity index 100%
rename from docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png
rename to "docs/java/new-features/images/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9~14 \347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247/java\347\211\210\346\234\254\345\217\221\345\270\203.png"
diff --git a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md "b/docs/java/new-features/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9\345\210\26014\347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247.md"
similarity index 99%
rename from docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
rename to "docs/java/new-features/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9\345\210\26014\347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247.md"
index 5b193cd5cac..64d70b3abde 100644
--- a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
+++ "b/docs/java/new-features/\344\270\200\346\226\207\345\270\246\344\275\240\347\234\213\351\201\215JDK9\345\210\26014\347\232\204\351\207\215\350\246\201\346\226\260\347\211\271\346\200\247.md"
@@ -109,7 +109,7 @@ Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
-
+
### 字符串加强
diff --git a/docs/network/images/Cut-Trough-Switching_0.gif b/docs/network/images/Cut-Trough-Switching_0.gif
new file mode 100644
index 00000000000..170dc3bbb19
Binary files /dev/null and b/docs/network/images/Cut-Trough-Switching_0.gif differ
diff --git a/docs/network/images/isp.png b/docs/network/images/isp.png
new file mode 100644
index 00000000000..fe5c0e96adb
Binary files /dev/null and b/docs/network/images/isp.png differ
diff --git "a/docs/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png" "b/docs/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png"
new file mode 100644
index 00000000000..a2d24300fcb
Binary files /dev/null and "b/docs/network/images/\344\270\203\345\261\202\344\275\223\347\263\273\347\273\223\346\236\204\345\233\276.png" differ
diff --git "a/docs/network/images/\344\274\240\350\276\223\345\261\202.png" "b/docs/network/images/\344\274\240\350\276\223\345\261\202.png"
new file mode 100644
index 00000000000..192af24536b
Binary files /dev/null and "b/docs/network/images/\344\274\240\350\276\223\345\261\202.png" differ
diff --git "a/docs/network/images/\345\272\224\347\224\250\345\261\202.png" "b/docs/network/images/\345\272\224\347\224\250\345\261\202.png"
new file mode 100644
index 00000000000..31e1e447b73
Binary files /dev/null and "b/docs/network/images/\345\272\224\347\224\250\345\261\202.png" differ
diff --git "a/docs/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" "b/docs/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png"
new file mode 100644
index 00000000000..c2b51a7c589
Binary files /dev/null and "b/docs/network/images/\346\225\260\346\215\256\351\223\276\350\267\257\345\261\202.png" differ
diff --git "a/docs/network/images/\347\211\251\347\220\206\345\261\202.png" "b/docs/network/images/\347\211\251\347\220\206\345\261\202.png"
new file mode 100644
index 00000000000..abb979261c1
Binary files /dev/null and "b/docs/network/images/\347\211\251\347\220\206\345\261\202.png" differ
diff --git "a/docs/network/images/\347\275\221\347\273\234\345\261\202.png" "b/docs/network/images/\347\275\221\347\273\234\345\261\202.png"
new file mode 100644
index 00000000000..376479d7989
Binary files /dev/null and "b/docs/network/images/\347\275\221\347\273\234\345\261\202.png" differ
diff --git "a/docs/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" "b/docs/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png"
new file mode 100644
index 00000000000..6af03daa96a
Binary files /dev/null and "b/docs/network/images/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\347\202\271\346\200\273\347\273\223/\344\270\207\347\273\264\347\275\221\347\232\204\345\244\247\350\207\264\345\267\245\344\275\234\345\267\245\347\250\213.png" differ
diff --git "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md" "b/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
deleted file mode 100644
index a20e6f85be7..00000000000
--- "a/docs/network/\345\271\262\350\264\247\357\274\232\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234\347\237\245\350\257\206\346\200\273\347\273\223.md"
+++ /dev/null
@@ -1,420 +0,0 @@
-### 1. [计算机概述 ](#一计算机概述)
-### 2. [物理层 ](#二物理层)
-### 3. [数据链路层 ](#三数据链路层 )
-### 4. [网络层 ](#四网络层 )
-### 5. [运输层 ](#五运输层 )
-### 6. [应用层](#六应用层)
-
-
-## 一计算机概述
-### (1),基本术语
-
-#### 结点 (node):
-
- 网络中的结点可以是计算机,集线器,交换机或路由器等。
-#### 链路(link ):
-
- 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-#### 主机(host):
- 连接在因特网上的计算机.
-#### ISP(Internet Service Provider):
- 因特网服务提供者(提供商).
-#### IXP(Internet eXchange Point):
- 互联网交换点IXP的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。.
-#### RFC(Request For Comments)
- 意思是“请求评议”,包含了关于Internet几乎所有的重要的文字资料。
-#### 广域网WAN(Wide Area Network)
- 任务是通过长距离运送主机发送的数据
-#### 城域网MAN(Metropolitan Area Network)
- 用来将多个局域网进行互连
-
-#### 局域网LAN(Local Area Network)
- 学校或企业大多拥有多个互连的局域网
-#### 个人区域网PAN(Personal Area Network)
- 在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络
-#### 端系统(end system):
- 处在因特网边缘的部分即是连接在因特网上的所有的主机.
-#### 分组(packet ):
- 因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
-#### 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
-#### 带宽(bandwidth):
- 在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
-#### 吞吐量(throughput ):
- 表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
-
-### (2),重要知识点总结
-
- 1,计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。
-
- 2,小写字母i开头的internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。
-
-

 -
-  -
-  +
+ 
 -### 联系我
+### 捐赠支持
-
+项目的发展离不开你的支持,如果 JavaGuide 帮助到了你找到自己满意的 offer,请作者喝杯咖啡吧 ☕ 后续会继续完善更新!加油!
-### Contributor
+[点击捐赠支持作者](https://www.yuque.com/snailclimb/dr6cvl/mr44yt#vu3ok)
-下面是笔主收集的一些对本仓库提过有价值的pr或者issue的朋友,人数较多,如果你也对本仓库提过不错的pr或者issue的话,你可以加我的微信与我联系。下面的排名不分先后!
+### 联系我
-
-
-### 联系我
+### 捐赠支持
-
+项目的发展离不开你的支持,如果 JavaGuide 帮助到了你找到自己满意的 offer,请作者喝杯咖啡吧 ☕ 后续会继续完善更新!加油!
-### Contributor
+[点击捐赠支持作者](https://www.yuque.com/snailclimb/dr6cvl/mr44yt#vu3ok)
-下面是笔主收集的一些对本仓库提过有价值的pr或者issue的朋友,人数较多,如果你也对本仓库提过不错的pr或者issue的话,你可以加我的微信与我联系。下面的排名不分先后!
+### 联系我
-
-  -
-
-
-  -
-**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
-
-一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
-
-
-
-**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
-
-一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
-
- -
-**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
-
-入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
-
-
-
-**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
-
-和《算法图解》类似的算法趣味入门书籍。
-
-### 经典
-
-
-
-**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
-
-入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
-
-
-
-**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
-
-和《算法图解》类似的算法趣味入门书籍。
-
-### 经典
-
- -
-**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
-
-我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
-
-再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
-
-> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
-
-
-
-**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
-
-我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
-
-再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
-
-> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
-
- -
-**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
-
-经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
-
-很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
-
-
-
-
-
-**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
-
-经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
-
-很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
-
-
-
- -
-**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
-
-被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
-
-
-
-**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
-
-被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
-
- -
-**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
-
-
-
-**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
-
-### 面试
-
-
-
-**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
-
-这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
-
-《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
-
-
-
-
-
-
-
-**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
-
-
-
-**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
-
-### 面试
-
-
-
-**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
-
-这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
-
-《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
-
-
-
-
-
- -
-**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
-
-题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
-
-
-
-
-
-**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
-
-题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
-
-
-
- -
-
-
-**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
-
-这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
-
-## 网站推荐
-
-我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
-
-### [LeetCode](https://leetcode-cn.com/)
-
-[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
-
-- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
-- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
-
-
-### [牛客网](https://www.nowcoder.com)
-
-**[在线编程](https://www.nowcoder.com/activity/oj):**
-
-- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
-- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
-- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
-- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
-- .......
-
-**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/docs/database/MySQL Index.md b/docs/database/MySQL Index.md
index df3f0a05149..8003a69faa3 100644
--- a/docs/database/MySQL Index.md
+++ b/docs/database/MySQL Index.md
@@ -24,7 +24,7 @@
5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
-6. 避免 where 子句中对宇段施加函数,这会造成无法命中索引。
+6. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
@@ -75,7 +75,7 @@ select username , age from user where username = 'Java' and age = 22
## 选择索引和编写利用这些索引的查询的3个原则
1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
-2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序1/0不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
+2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序 I/O 不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
问是很慢的。
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index 8fd54b7d490..efd1561a08a 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -98,7 +98,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
**两者的对比:**
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
5. ......
@@ -148,7 +148,7 @@ set global query_cache_size=600000;
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
```sql
select sql_no_cache count(*) from usr;
```
@@ -159,12 +159,12 @@ select sql_no_cache count(*) from usr;
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
-### 事物的四大特性(ACID)
+### 事务的四大特性(ACID)
-
+
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+2. **一致性(Consistency):** 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
new file mode 100644
index 00000000000..bc4c6d0cca7
--- /dev/null
+++ "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
@@ -0,0 +1 @@
+
-
-
-
-**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
-
-这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
-
-## 网站推荐
-
-我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
-
-### [LeetCode](https://leetcode-cn.com/)
-
-[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
-
-- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
-- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
-
-
-### [牛客网](https://www.nowcoder.com)
-
-**[在线编程](https://www.nowcoder.com/activity/oj):**
-
-- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
-- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
-- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
-- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
-- .......
-
-**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/docs/database/MySQL Index.md b/docs/database/MySQL Index.md
index df3f0a05149..8003a69faa3 100644
--- a/docs/database/MySQL Index.md
+++ b/docs/database/MySQL Index.md
@@ -24,7 +24,7 @@
5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
-6. 避免 where 子句中对宇段施加函数,这会造成无法命中索引。
+6. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
@@ -75,7 +75,7 @@ select username , age from user where username = 'Java' and age = 22
## 选择索引和编写利用这些索引的查询的3个原则
1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
-2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序1/0不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
+2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序 I/O 不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
问是很慢的。
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index 8fd54b7d490..efd1561a08a 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -98,7 +98,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
**两者的对比:**
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
5. ......
@@ -148,7 +148,7 @@ set global query_cache_size=600000;
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
```sql
select sql_no_cache count(*) from usr;
```
@@ -159,12 +159,12 @@ select sql_no_cache count(*) from usr;
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
-### 事物的四大特性(ACID)
+### 事务的四大特性(ACID)
-
+
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+2. **一致性(Consistency):** 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
diff --git "a/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio" "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
new file mode 100644
index 00000000000..bc4c6d0cca7
--- /dev/null
+++ "b/docs/database/Redis/images/\347\274\223\345\255\230\350\257\273\345\206\231\347\255\226\347\225\245/cache-aside-read.drawio"
@@ -0,0 +1 @@
+